Trong môi trường kinh doanh dựa trên dữ liệu ngày nay, các tổ chức phải đối mặt với thách thức chuẩn bị và chuyển đổi hiệu quả lượng lớn dữ liệu cho mục đích phân tích và khoa học dữ liệu. Các doanh nghiệp cần xây dựng kho dữ liệu và hồ dữ liệu dựa trên dữ liệu hoạt động. Điều này được thúc đẩy bởi nhu cầu tập trung và tích hợp dữ liệu đến từ các nguồn khác nhau.
Đồng thời, dữ liệu vận hành thường bắt nguồn từ các ứng dụng được hỗ trợ bởi kho lưu trữ dữ liệu cũ. Việc hiện đại hóa các ứng dụng yêu cầu kiến trúc vi dịch vụ, do đó cần phải hợp nhất dữ liệu từ nhiều nguồn để xây dựng một kho lưu trữ dữ liệu hoạt động. Nếu không hiện đại hóa, các ứng dụng cũ có thể phải chịu chi phí bảo trì ngày càng tăng. Hiện đại hóa các ứng dụng liên quan đến việc thay đổi công cụ cơ sở dữ liệu cơ bản thành cơ sở dữ liệu dựa trên tài liệu hiện đại như MongoDB.
Hai nhiệm vụ này (xây dựng hồ dữ liệu hoặc kho dữ liệu và hiện đại hóa ứng dụng) liên quan đến việc di chuyển dữ liệu, sử dụng quy trình trích xuất, biến đổi và tải (ETL). Công việc ETL là một chức năng chính để có một quy trình được cấu trúc tốt để thành công.
Keo AWS là một dịch vụ tích hợp dữ liệu không có máy chủ giúp dễ dàng khám phá, chuẩn bị, di chuyển và tích hợp dữ liệu từ nhiều nguồn để phân tích, học máy (ML) và phát triển ứng dụng. Bản đồ MongoDB là một bộ tích hợp cơ sở dữ liệu đám mây và dịch vụ dữ liệu kết hợp xử lý giao dịch, tìm kiếm dựa trên mức độ liên quan, phân tích thời gian thực và đồng bộ hóa dữ liệu từ thiết bị di động đến đám mây trong một kiến trúc tích hợp và trang nhã.
Bằng cách sử dụng AWS Glue với MongoDB Atlas, các tổ chức có thể hợp lý hóa các quy trình ETL của họ. Với giải pháp cơ sở dữ liệu an toàn, có thể mở rộng và được quản lý hoàn toàn, MongoDB Atlas cung cấp một môi trường linh hoạt và đáng tin cậy để lưu trữ và quản lý dữ liệu vận hành. Cùng với nhau, AWS Glue ETL và MongoDB Atlas là một giải pháp mạnh mẽ dành cho các tổ chức đang tìm cách tối ưu hóa cách họ xây dựng hồ dữ liệu và kho dữ liệu, đồng thời hiện đại hóa các ứng dụng của họ, nhằm cải thiện hiệu suất kinh doanh, giảm chi phí, đồng thời thúc đẩy tăng trưởng và thành công.
Trong bài đăng này, chúng tôi trình bày cách di chuyển dữ liệu từ Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) chuyển vào MongoDB Atlas bằng cách sử dụng AWS Glue ETL và cách trích xuất dữ liệu từ MongoDB Atlas vào kho dữ liệu dựa trên Amazon S3.
Tổng quan về giải pháp
Trong bài đăng này, chúng tôi khám phá các trường hợp sử dụng sau:
- Trích xuất dữ liệu từ MongoDB – MongoDB là cơ sở dữ liệu phổ biến được hàng nghìn khách hàng sử dụng để lưu trữ dữ liệu ứng dụng trên quy mô lớn. Khách hàng doanh nghiệp có thể tập trung và tích hợp dữ liệu đến từ nhiều kho lưu trữ dữ liệu bằng cách xây dựng kho dữ liệu và kho dữ liệu. Quá trình này liên quan đến việc trích xuất dữ liệu từ các cửa hàng dữ liệu hoạt động. Khi dữ liệu ở một nơi, khách hàng có thể nhanh chóng sử dụng dữ liệu đó cho nhu cầu kinh doanh thông minh hoặc cho ML.
- Nhập dữ liệu vào MongoDB – MongoDB cũng đóng vai trò là cơ sở dữ liệu không có SQL để lưu trữ dữ liệu ứng dụng và xây dựng kho lưu trữ dữ liệu hoạt động. Việc hiện đại hóa các ứng dụng thường liên quan đến việc di chuyển kho vận hành sang MongoDB. Khách hàng sẽ cần trích xuất dữ liệu hiện có từ cơ sở dữ liệu quan hệ hoặc từ các tệp phẳng. Các ứng dụng dành cho thiết bị di động và web thường yêu cầu các kỹ sư dữ liệu xây dựng các đường dẫn dữ liệu để tạo một chế độ xem dữ liệu duy nhất trong Atlas trong khi nhập dữ liệu từ nhiều nguồn riêng lẻ. Trong quá trình di chuyển này, họ sẽ cần tham gia các cơ sở dữ liệu khác nhau để tạo tài liệu. Thao tác nối phức tạp này sẽ cần sức mạnh tính toán một lần đáng kể. Các nhà phát triển cũng cần xây dựng điều này một cách nhanh chóng để di chuyển dữ liệu.
AWS Glue rất hữu ích trong những trường hợp này nhờ mô hình trả tiền theo mức sử dụng và khả năng chạy các phép biến đổi phức tạp trên các bộ dữ liệu khổng lồ. Nhà phát triển có thể sử dụng AWS Glue Studio để tạo các đường dẫn dữ liệu như vậy một cách hiệu quả.
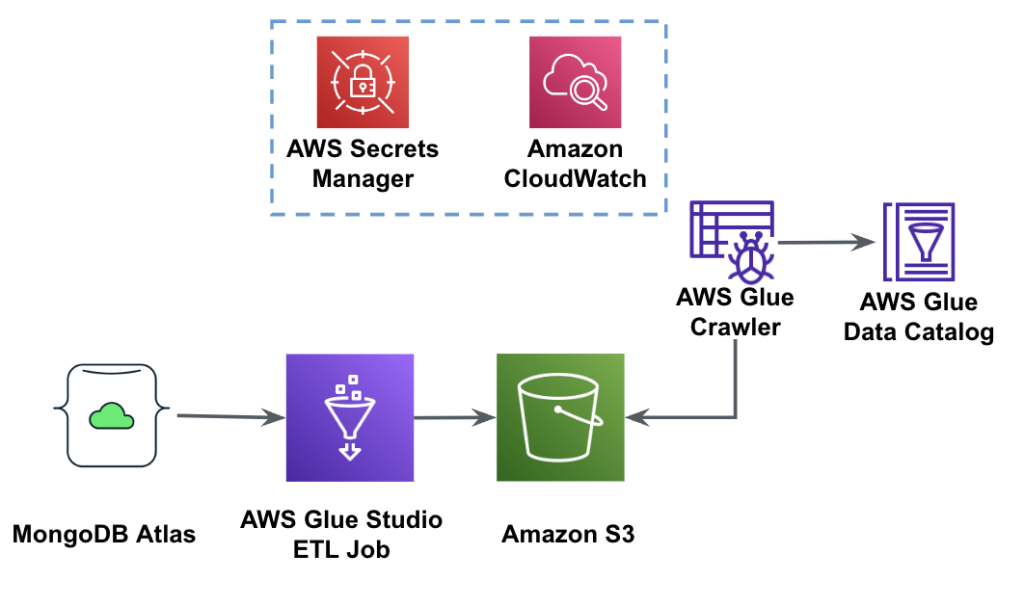
Sơ đồ sau đây cho thấy quy trình trích xuất dữ liệu từ MongoDB Atlas vào bộ chứa S3 bằng AWS Glue Studio.
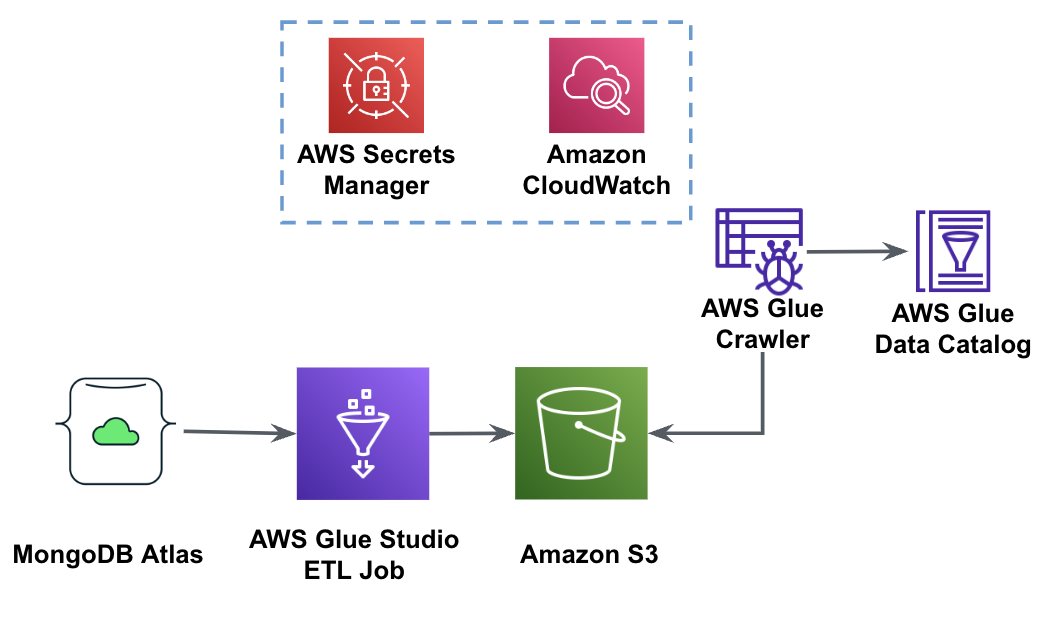
Để triển khai kiến trúc này, bạn sẽ cần một cụm MongoDB Atlas, một bộ chứa S3 và một Quản lý truy cập và nhận dạng AWS (IAM) cho AWS Glue. Để định cấu hình các tài nguyên này, hãy tham khảo các bước điều kiện tiên quyết trong phần sau Repo GitHub.
Hình dưới đây cho thấy quy trình tải dữ liệu từ bộ chứa S3 vào MongoDB Atlas bằng AWS Glue.
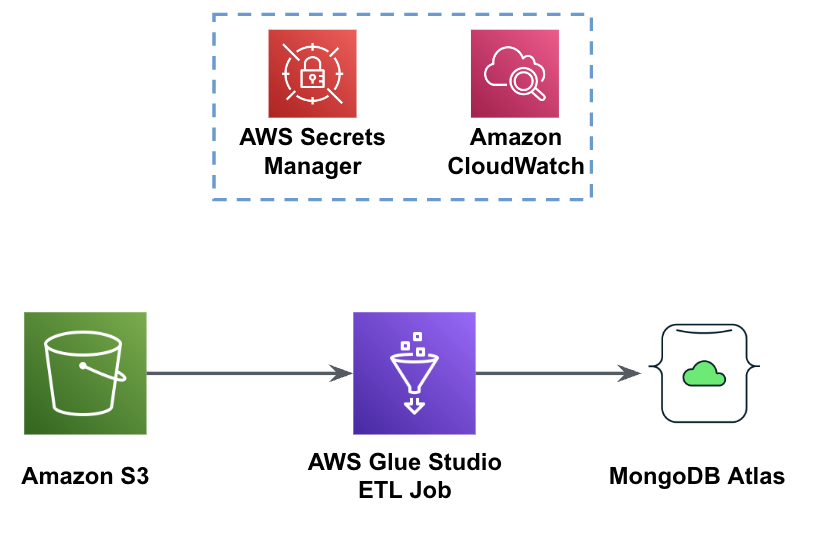
Các điều kiện tiên quyết giống nhau là cần thiết ở đây: bộ chứa S3, vai trò IAM và cụm MongoDB Atlas.
Tải dữ liệu từ Amazon S3 lên MongoDB Atlas bằng AWS Glue
Các bước sau đây mô tả cách tải dữ liệu từ bộ chứa S3 vào MongoDB Atlas bằng công việc AWS Glue. Quá trình trích xuất từ MongoDB Atlas sang Amazon S3 rất giống nhau, ngoại trừ tập lệnh được sử dụng. Chúng tôi gọi ra sự khác biệt giữa hai quá trình.
- Tạo một cụm miễn phí trong Bản đồ MongoDB.
- Tải lên tệp JSON mẫu vào thùng S3 của bạn.
- Tạo công việc AWS Glue Studio mới bằng Trình chỉnh sửa tập lệnh Spark tùy chọn.

- Tùy thuộc vào việc bạn muốn tải hay trích xuất dữ liệu từ cụm MongoDB Atlas, hãy nhập tải tập lệnh or trích xuất kịch bản trong trình chỉnh sửa tập lệnh AWS Glue Studio.
Ảnh chụp màn hình sau đây hiển thị một đoạn mã để tải dữ liệu vào cụm MongoDB Atlas.

Mã sử dụng Quản lý bí mật AWS để truy xuất tên cụm MongoDB Atlas, tên người dùng và mật khẩu. Sau đó, nó tạo ra một DynamicFrame đối với bộ chứa S3 và tên tệp được chuyển đến tập lệnh dưới dạng tham số. Mã truy xuất cơ sở dữ liệu và tên bộ sưu tập từ cấu hình tham số công việc. Cuối cùng, mã viết DynamicFrame đến cụm MongoDB Atlas bằng cách sử dụng các tham số đã truy xuất.
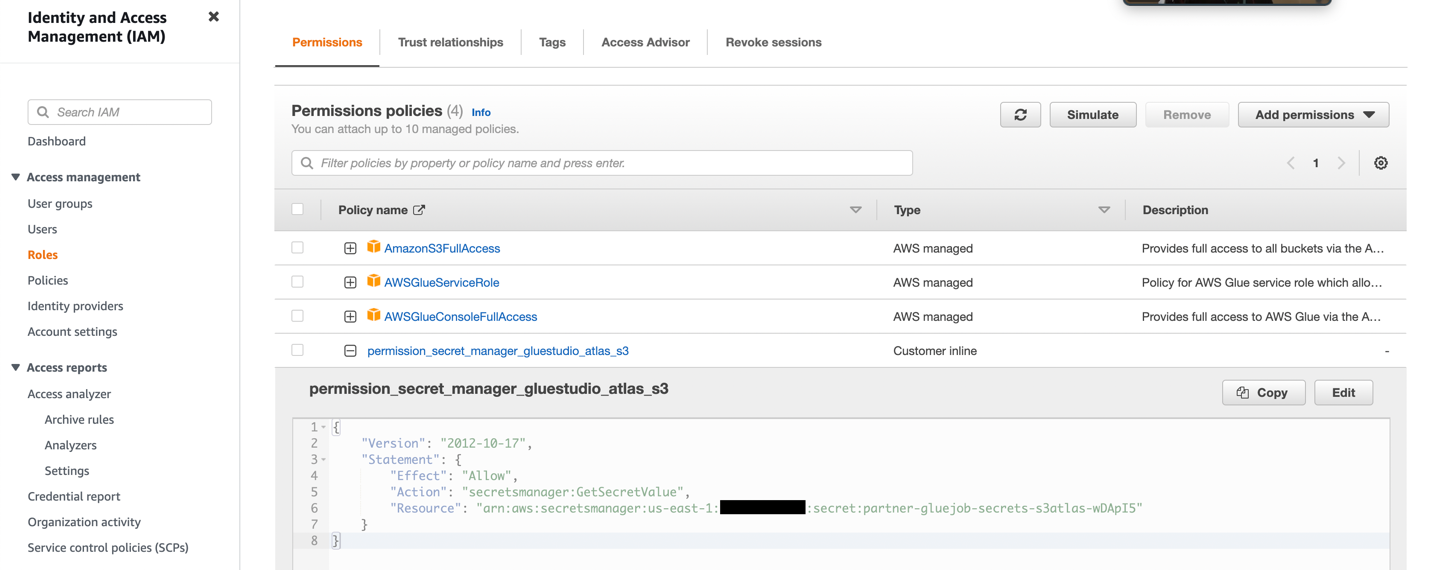
- Tạo vai trò IAM với các quyền như trong ảnh chụp màn hình sau.
Để biết thêm chi tiết, hãy tham khảo Định cấu hình vai trò IAM cho công việc ETL của bạn.
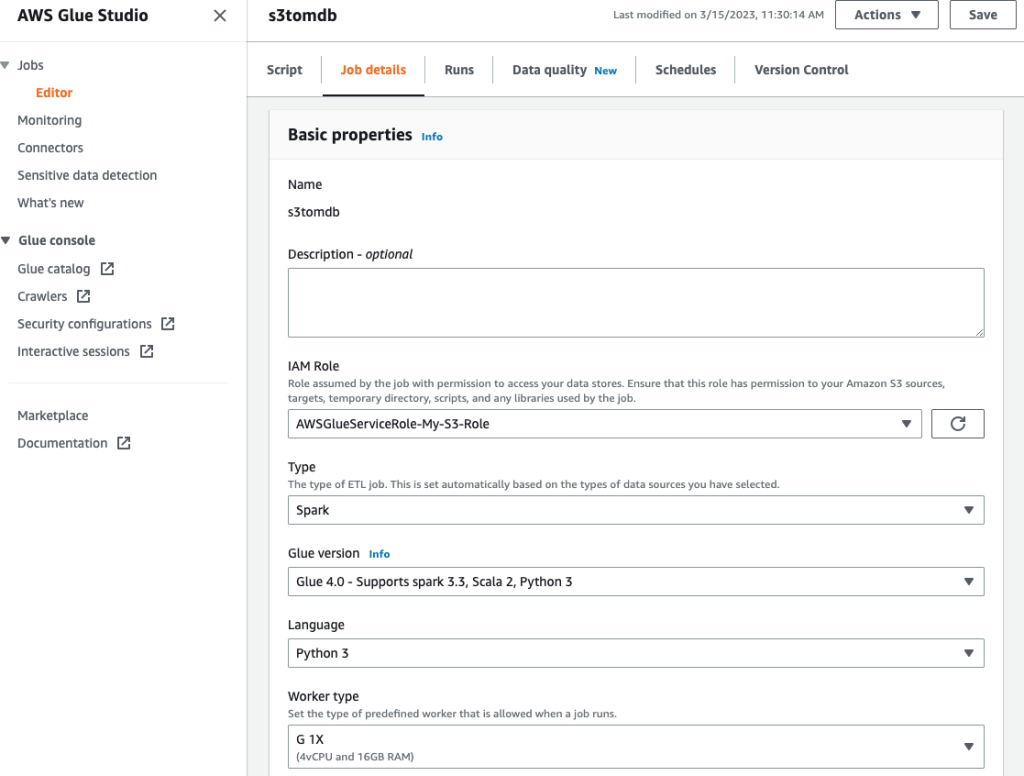
- Đặt tên cho công việc và cung cấp vai trò IAM được tạo ở bước trước trên Chi tiết công việc tab.
- Bạn có thể để các tham số còn lại làm mặc định, như minh họa trong ảnh chụp màn hình sau.
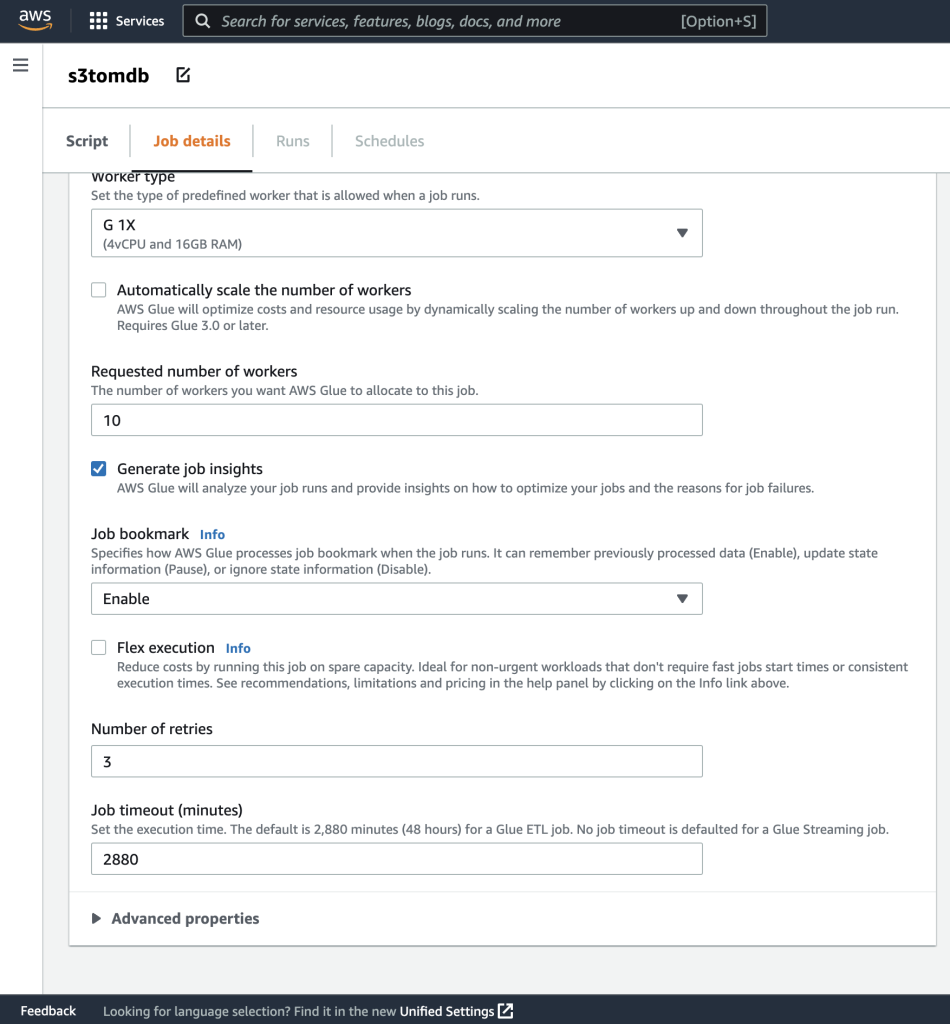
- Tiếp theo, xác định các tham số công việc mà tập lệnh sử dụng và cung cấp các giá trị mặc định.
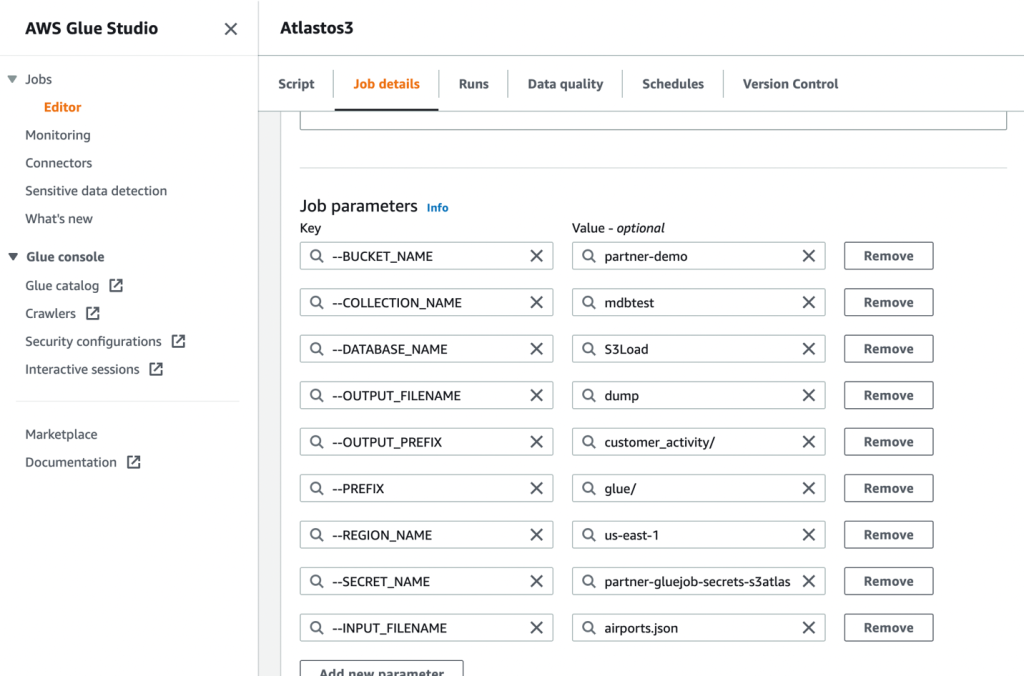
- Lưu công việc và chạy nó.
- Để xác nhận chạy thành công, hãy quan sát nội dung của bộ sưu tập cơ sở dữ liệu MongoDB Atlas nếu đang tải dữ liệu hoặc bộ chứa S3 nếu bạn đang thực hiện trích xuất.



Ảnh chụp màn hình sau đây cho thấy kết quả tải dữ liệu thành công từ bộ chứa Amazon S3 vào cụm MongoDB Atlas. Dữ liệu hiện có sẵn cho các truy vấn trong MongoDB Atlas UI.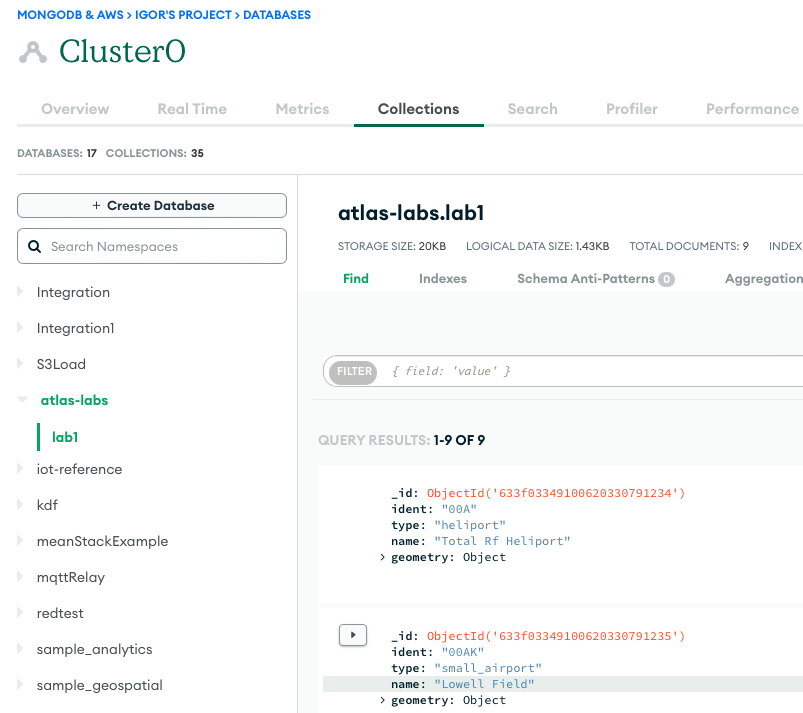
- Để khắc phục sự cố lần chạy của bạn, hãy xem lại amazoncloudwatch nhật ký sử dụng liên kết trên công việc chạy tab.
Ảnh chụp màn hình sau đây cho thấy rằng công việc đã chạy thành công, với các chi tiết bổ sung như liên kết đến nhật ký CloudWatch.

Kết luận
Trong bài đăng này, chúng tôi đã mô tả cách trích xuất và nhập dữ liệu vào MongoDB Atlas bằng AWS Glue.
Với các tác vụ AWS Glue ETL, giờ đây chúng tôi có thể truyền dữ liệu từ MongoDB Atlas sang các nguồn tương thích với AWS Glue và ngược lại. Bạn cũng có thể mở rộng giải pháp để xây dựng phân tích bằng các dịch vụ AWS AI và ML.
Để tìm hiểu thêm, hãy tham khảo Kho GitHub để biết hướng dẫn từng bước và mã mẫu. bạn có thể mua Bản đồ MongoDB trên Thị trường AWS.
Về các tác giả

Igor Alekseev là Kiến trúc sư giải pháp đối tác cấp cao tại AWS trong lĩnh vực Dữ liệu và Phân tích. Trong vai trò của mình, Igor đang làm việc với các đối tác chiến lược giúp họ xây dựng các kiến trúc phức tạp, được tối ưu hóa cho AWS. Trước khi gia nhập AWS, với tư cách là Kiến trúc sư dữ liệu/giải pháp, anh ấy đã triển khai nhiều dự án trong miền Dữ liệu lớn, bao gồm một số kho dữ liệu trong hệ sinh thái Hadoop. Là một Kỹ sư dữ liệu, anh ấy đã tham gia vào việc áp dụng AI/ML để phát hiện gian lận và tự động hóa văn phòng.
 Babu Srinivasan là Kiến trúc sư giải pháp đối tác cấp cao tại MongoDB. Trong vai trò hiện tại của mình, anh ấy đang làm việc với AWS để xây dựng các tích hợp kỹ thuật và kiến trúc tham chiếu cho các giải pháp AWS và MongoDB. Ông có hơn hai thập kỷ kinh nghiệm về Cơ sở dữ liệu và công nghệ Đám mây. Anh đam mê cung cấp các giải pháp kỹ thuật cho khách hàng làm việc với nhiều Nhà tích hợp hệ thống toàn cầu (GSIs) trên nhiều khu vực địa lý.
Babu Srinivasan là Kiến trúc sư giải pháp đối tác cấp cao tại MongoDB. Trong vai trò hiện tại của mình, anh ấy đang làm việc với AWS để xây dựng các tích hợp kỹ thuật và kiến trúc tham chiếu cho các giải pháp AWS và MongoDB. Ông có hơn hai thập kỷ kinh nghiệm về Cơ sở dữ liệu và công nghệ Đám mây. Anh đam mê cung cấp các giải pháp kỹ thuật cho khách hàng làm việc với nhiều Nhà tích hợp hệ thống toàn cầu (GSIs) trên nhiều khu vực địa lý.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- : có
- :là
- 100
- 11
- a
- có khả năng
- Giới thiệu
- truy cập
- ngang qua
- thêm vào
- AI
- AI / ML
- Ngoài ra
- đàn bà gan dạ
- số lượng
- an
- phân tích
- và
- Các Ứng Dụng
- Phát triển ứng dụng
- các ứng dụng
- Nộp đơn
- ứng dụng
- kiến trúc
- LÀ
- AS
- At
- bản địa đồ
- Tự động hóa
- có sẵn
- AWS
- Keo AWS
- Thị trường AWS
- được hậu thuẫn
- dựa
- được
- giữa
- lớn
- Dữ Liệu Lớn.
- xây dựng
- Xây dựng
- kinh doanh
- kinh doanh thông minh
- hiệu quả kinh doanh
- các doanh nghiệp
- by
- cuộc gọi
- CAN
- trường hợp
- thách thức
- thay đổi
- đám mây
- cụm
- mã
- bộ sưu tập
- kết hợp
- đến
- đến
- phức tạp
- Tính
- Cấu hình
- Xác nhận
- hợp nhất
- xây dựng
- nội dung
- tiếp tục
- Chi phí
- tạo
- tạo ra
- tạo ra
- tạo
- Current
- khách hàng
- dữ liệu
- kỹ sư dữ liệu
- tích hợp dữ liệu
- Hồ dữ liệu
- khoa học dữ liệu
- Kho dữ liệu
- hướng dữ liệu
- Cơ sở dữ liệu
- cơ sở dữ liệu
- bộ dữ liệu
- thập kỷ
- Mặc định
- chứng minh
- mô tả
- mô tả
- chi tiết
- Phát hiện
- phát triển
- Phát triển
- sự khác biệt
- khác nhau
- khám phá
- khác biệt
- tài liệu
- miền
- lái xe
- điều khiển
- suốt trong
- hệ sinh thái
- biên tập viên
- hiệu quả
- Động cơ
- ky sư
- Kỹ sư
- đăng ký hạng mục thi
- Doanh nghiệp
- khách hàng doanh nghiệp
- Môi trường
- Ether (ETH)
- ngoại lệ
- hiện tại
- kinh nghiệm
- khám phá
- thêm
- trích xuất
- khai thác
- Đối mặt
- Hình
- Tập tin
- Các tập tin
- Cuối cùng
- bằng phẳng
- linh hoạt
- tiếp theo
- Trong
- gian lận
- phát hiện gian lận
- Miễn phí
- từ
- đầy đủ
- chức năng
- địa lý
- Toàn cầu
- Tăng trưởng
- Hadoop
- tiện dụng
- có
- he
- giúp đỡ
- tại đây
- của mình
- Độ đáng tin của
- Hướng dẫn
- HTML
- http
- HTTPS
- lớn
- IAM
- Bản sắc
- if
- thực hiện
- thực hiện
- nâng cao
- in
- Bao gồm
- tăng
- đầu vào
- hướng dẫn
- tích hợp
- tích hợp
- hội nhập
- tích hợp
- Sự thông minh
- trong
- liên quan
- tham gia
- IT
- ITS
- Việc làm
- việc làm
- tham gia
- tham gia
- json
- Key
- hồ
- lớn
- LEARN
- học tập
- Rời bỏ
- Legacy
- Lượt thích
- LINK
- liên kết
- tải
- tải
- tìm kiếm
- máy
- học máy
- bảo trì
- LÀM CHO
- quản lý
- quản lý
- nhiều
- thị trường
- Có thể..
- di chuyển
- di cư
- ML
- di động
- kiểu mẫu
- hiện đại
- hiện đại hóa
- hiện đại hóa
- MongoDB
- chi tiết
- di chuyển
- phong trào
- nhiều
- tên
- tên
- Cần
- cần thiết
- nhu cầu
- Mới
- tại
- tuân theo
- of
- Office
- thường
- on
- ONE
- hoạt động
- hoạt động
- Tối ưu hóa
- Tùy chọn
- or
- gọi món
- tổ chức
- ra
- thông số
- đối tác
- Đối tác
- thông qua
- đam mê
- Mật khẩu
- hiệu suất
- biểu diễn
- quyền
- Nơi
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Phổ biến
- Bài đăng
- quyền lực
- mạnh mẽ
- Chuẩn bị
- chuẩn bị
- điều kiện tiên quyết
- trước
- Trước khi
- quá trình
- Quy trình
- xử lý
- dự án
- cung cấp
- cung cấp
- mục đích
- truy vấn
- Mau
- thời gian thực
- giảm
- đáng tin cậy
- yêu cầu
- đòi hỏi
- Thông tin
- REST của
- Kết quả
- xem xét
- Vai trò
- chạy
- tương tự
- khả năng mở rộng
- Quy mô
- Khoa học
- ảnh chụp màn hình
- Tìm kiếm
- an toàn
- cao cấp
- Không có máy chủ
- phục vụ
- dịch vụ
- DỊCH VỤ
- một số
- thể hiện
- Chương trình
- có ý nghĩa
- tương tự
- Đơn giản
- duy nhất
- giải pháp
- Giải pháp
- nguồn
- Bước
- Các bước
- là gắn
- hàng
- cửa hàng
- đơn giản
- Chiến lược
- đối tác chiến lược
- hợp lý hóa
- phòng thu
- thành công
- thành công
- thành công
- Thành công
- như vậy
- bộ
- cung cấp
- đồng bộ hóa
- hệ thống
- nhiệm vụ
- Kỹ thuật
- Công nghệ
- hơn
- việc này
- Sản phẩm
- cung cấp their dịch
- Them
- sau đó
- Kia là
- họ
- điều này
- hàng ngàn
- thời gian
- đến
- hôm nay
- bên nhau
- giao dịch
- chuyển
- Chuyển đổi
- biến đổi
- biến đổi
- XOAY
- hai
- ui
- cơ bản
- sử dụng
- đã sử dụng
- người sử dang
- sử dụng
- Các giá trị
- rất
- Xem
- muốn
- là
- we
- web
- là
- khi nào
- liệu
- cái nào
- trong khi
- sẽ
- với
- không có
- quy trình làm việc
- đang làm việc
- sẽ
- bạn
- trên màn hình
- zephyrnet