Robolawer. Tín dụng: Giữa hành trình
Nếu bạn đọc tác phẩm của tôi, bạn có thể biết rằng tôi xuất bản các bài viết của mình đầu tiên và quan trọng nhất trong bản tin AI của tôi, Cầu thuật toán. Điều bạn có thể không biết là mỗi Chủ nhật, tôi xuất bản một chuyên mục đặc biệt mà tôi gọi là “những gì bạn có thể đã bỏ lỡ”, nơi tôi xem xét mọi thứ đã xảy ra trong tuần với các phân tích giúp bạn hiểu được tin tức.
Thỏa thuận trị giá 10 tỷ USD của Microsoft-OpenAI
báo cáo Semafor hai tuần trước, nếu mọi thứ diễn ra theo đúng kế hoạch, Microsoft sẽ chốt thỏa thuận đầu tư 10 tỷ đô la với OpenAI trước cuối tháng XNUMX (Satya Nadella, CEO của Microsoft, đã công bố quan hệ đối tác mở rộng chính thức vào thứ Hai).
Đã có một số thông tin sai lệch về thỏa thuận ngụ ý rằng các nhà điều hành OpenAI không chắc chắn về khả năng tồn tại lâu dài của công ty. Tuy nhiên, nó sau đó đã được làm rõ rằng thỏa thuận trông như thế này:
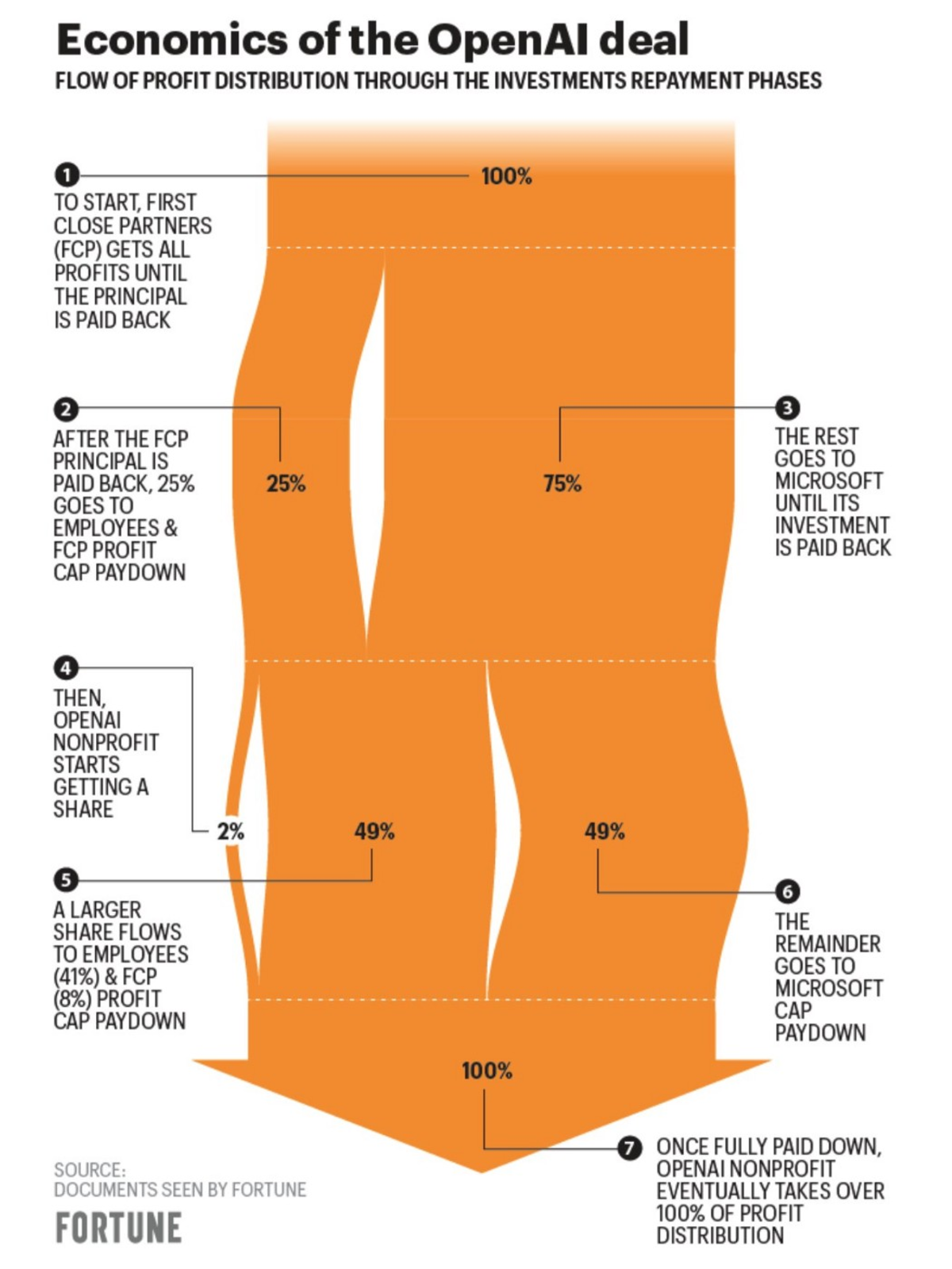
Tín dụng: Vận may
Leo L'Orange, người viết The Neuron, giải thích rằng “một khi 92 tỷ đô la lợi nhuận cộng với 13 tỷ đô la đầu tư ban đầu được hoàn trả cho Microsoft và một khi các nhà đầu tư mạo hiểm khác kiếm được 150 tỷ đô la, tất cả vốn chủ sở hữu sẽ quay trở lại OpenAI.”
Mọi người bị chia rẽ. Một số người cho rằng thỏa thuận này “hay ho” hoặc “thú vị”, trong khi những người khác nói rằng nó “kỳ quặc” và “điên rồ”. Những gì tôi cảm nhận được bằng con mắt không phải chuyên gia của mình là OpenAI và Sam Altman do tin tưởng (một số người sẽ nói quá tin tưởng) khả năng dài hạn của công ty để đạt được mục tiêu của mình.
Tuy nhiên, như Will Knight viết đối với WIRED, "không rõ những sản phẩm nào có thể được xây dựng trên công nghệ này." OpenAI phải sớm tìm ra một mô hình kinh doanh khả thi.
Thay đổi đối với ChatGPT: Các tính năng mới và khả năng kiếm tiền
OpenAI đã cập nhật ChatGPT vào ngày 9 tháng 15 (từ lần cập nhật trước vào ngày XNUMX tháng XNUMX). Giờ đây, chatbot đã “cải thiện tính thực tế” và bạn có thể dừng nó ở thế hệ giữa.
Họ cũng đang làm việc trên một “phiên bản chuyên nghiệp của ChatGPT” (có tin đồn là sẽ ra mắt tại $ 42 / tháng) với tư cách là chủ tịch của OpenAI Greg Brockman công bố vào ngày 11 tháng XNUMX. Đây là ba tính năng chính:
“Luôn có sẵn (không có cửa sổ mất điện).
Phản hồi nhanh từ ChatGPT (nghĩa là không điều chỉnh).
Bao nhiêu tin nhắn bạn cần (ít nhất gấp 2 lần giới hạn thông thường hàng ngày).”
Để đăng ký danh sách chờ, bạn phải điền vào mẫu nơi họ hỏi bạn, trong số những thứ khác, bạn sẵn sàng trả bao nhiêu (và bao nhiêu là quá nhiều).
Nếu bạn có kế hoạch thực hiện nó một cách nghiêm túc, bạn nên xem xét việc đi sâu vào ngăn xếp sản phẩm của OpenAI với Kho lưu trữ sách dạy nấu ăn OpenAI. Bojan Tunguz nói đó là “repo thịnh hành nhất trên GitHub tháng này.” Luôn luôn là một dấu hiệu tốt.
ChatGPT, nhà khoa học giả mạo
ChatGPT đã đi vào lĩnh vực khoa học. Kareem Carr đã đăng một ảnh chụp màn hình vào thứ Năm của một bài báo mà ChatGPT là đồng tác giả.
Nhưng tại sao lại cho rằng ChatGPT là một công cụ? “Mọi người đang bắt đầu coi ChatGPT như thể nó là một nền tảng khoa học chân chính, được chứng nhận tốt. cộng tác viên,” Gary Marcus giải thích trong một bài Substack. “Các nhà khoa học, xin đừng để chatbot của bạn trở thành đồng tác giả,” anh ấy cầu xin.
Đáng lo ngại hơn là những trường hợp không tiết lộ việc sử dụng AI. Các nhà khoa học tìm được, tìm thấy, tìm ra rằng họ không thể xác định một cách đáng tin cậy các bản tóm tắt được viết bởi ChatGPT — sự nhảm nhí hùng hồn của nó đánh lừa ngay cả các chuyên gia trong lĩnh vực của họ. Như Sandra Wachter, người “nghiên cứu công nghệ và quy định” tại Oxford, nói với Holly Else cho một phần về Thiên nhiên:
“Nếu bây giờ chúng ta đang ở trong tình huống mà các chuyên gia không thể xác định điều gì là đúng hay sai, thì chúng ta sẽ mất đi người trung gian mà chúng ta rất cần để hướng dẫn chúng ta vượt qua các chủ đề phức tạp.”
Thách thức của ChatGPT đối với giáo dục
ChatGPT đã bị cấm tại các trung tâm giáo dục trên toàn cầu (ví dụ: Trường công lập New York, Đại học Úcvà giảng viên Vương quốc Anh đang nghĩ về nó). Như tôi đã tranh luận trong một bài luận trước, Tôi không nghĩ đây là quyết định khôn ngoan nhất mà chỉ là một phản ứng do chưa chuẩn bị cho sự phát triển nhanh chóng của AI thế hệ mới.
Kevin Roose của NYT lập luận rằng “tiềm năng của [ChatGPT] như một công cụ giáo dục lớn hơn những rủi ro của nó.” Terence Tao, nhà toán học vĩ đại, đồng ý: “Về lâu dài, chống lại điều này dường như là vô ích; có lẽ điều mà chúng tôi với tư cách là giảng viên cần làm là chuyển sang chế độ kiểm tra “sách mở, AI mở”.
nhụy hoa Giada, nhà đạo đức học chính tại Hugging Face, giải thích thách thức mà các trường gặp phải với ChatGPT:
“Thật không may, hệ thống giáo dục dường như buộc phải thích nghi với những công nghệ mới này. Tôi nghĩ đó là một phản ứng có thể hiểu được, vì chưa có nhiều việc được thực hiện để dự đoán, giảm thiểu hoặc xây dựng các giải pháp thay thế để giải quyết các vấn đề có thể xảy ra. Các công nghệ đột phá thường yêu cầu giáo dục người dùng bởi vì chúng không thể đơn giản là ném vào mọi người một cách không kiểm soát được.”
Câu cuối cùng đó nắm bắt một cách hoàn hảo vấn đề nảy sinh ở đâu và giải pháp tiềm năng nằm ở đâu. Chúng tôi phải nỗ lực hơn nữa để giáo dục người dùng về cách thức hoạt động của công nghệ này cũng như những gì có thể và không nên làm với chúng. Đó là cách tiếp cận mà Catalonia đã thực hiện. BẰNG Báo cáo của Francesc Bracero và Carina Farreras cho La Vanguardia:
“Ở Catalonia, Bộ Giáo dục sẽ không cấm nó 'trong toàn bộ hệ thống và đối với tất cả mọi người, vì đây sẽ là một biện pháp không hiệu quả.' Theo các nguồn tin từ Bộ, tốt hơn hết là yêu cầu các trung tâm giáo dục sử dụng AI, 'thứ có thể cung cấp nhiều kiến thức và lợi ích.'”
Bạn thân của học sinh: Cơ sở dữ liệu về lỗi ChatGPT
Gary Marcus và Ernest Davis đã thành lập một “theo dõi lỗi” để nắm bắt và phân loại lỗi mà các mô hình ngôn ngữ như ChatGPT mắc phải (đây là thông tin thêm về lý do tại sao họ biên soạn tài liệu này và họ dự định làm gì với nó).
Cơ sở dữ liệu là công khai và bất cứ ai cũng có thể tham gia. Đó là một nguồn tài nguyên tuyệt vời cho phép nghiên cứu nghiêm ngặt về cách các mô hình này hoạt động sai và cách mọi người có thể tránh sử dụng sai. Đây là một ví dụ vui nhộn về lý do tại sao điều này lại quan trọng:
OpenAI nhận thức được điều này và muốn chống lại thông tin sai lệch và xuyên tạc: “Dự báo khả năng lạm dụng các mô hình ngôn ngữ cho các chiến dịch thông tin sai lệch — và cách giảm thiểu rủi ro".
Thông tin mới
Sam Altman ám chỉ tại một sự chậm trễ trong việc phát hành GPT-4 trong một cuộc trò chuyện với Connie Loizos, biên tập viên thung lũng silicon tại TechCrunch. Altman nói rằng “nói chung, chúng tôi sẽ phát hành công nghệ chậm hơn nhiều so với mong muốn của mọi người. Chúng ta sẽ ngồi trên nó lâu hơn nữa…” Đây là ý kiến của tôi:
(Altman cũng cho biết có một mô hình video đang hoạt động!)
Thông tin sai lệch về GPT-4
Có một tuyên bố “GPT-4 = 100T” đang lan truyền khắp nơi trên mạng xã hội (tôi hầu như đã thấy nó trên Twitter và LinkedIn). Trong trường hợp bạn chưa nhìn thấy nó, nó trông như thế này:
Hoặc này:
Tất cả đều là các phiên bản hơi khác nhau của cùng một nội dung: Một biểu đồ trực quan hấp dẫn thu hút sự chú ý và sự hấp dẫn mạnh mẽ với so sánh GPT-4/GPT-3 (họ sử dụng GPT-3 làm proxy cho ChatGPT).
Tôi nghĩ chia sẻ những tin đồn và suy đoán và đóng khung chúng như vậy là được (Tôi cảm thấy một phần trách nhiệm cho việc này), nhưng đăng thông tin không thể kiểm chứng với giọng điệu có thẩm quyền và không có tài liệu tham khảo là điều đáng trách.
Những người làm điều này không phải là vô dụng và nguy hiểm như ChatGPT với tư cách là nguồn thông tin — và có nhiều động lực mạnh mẽ hơn để tiếp tục làm điều đó. Hãy coi chừng điều này vì nó sẽ làm ô nhiễm mọi kênh thông tin về AI trong tương lai.
Luật sư người máy
Joshua Browder, Giám đốc điều hành tại DoNotPay, đã đăng cái này vào ngày 9 tháng XNUMX:
Vì không thể khác được, tuyên bố táo bạo này đã tạo ra rất nhiều cuộc tranh luận đến mức Twitter hiện gắn cờ tweet bằng một liên kết đến Trang của Tòa án tối cao về các mặt hàng bị cấm.
Ngay cả khi cuối cùng họ không thể làm điều đó vì lý do pháp lý, thì vẫn đáng để xem xét câu hỏi từ quan điểm đạo đức và xã hội. Điều gì xảy ra nếu hệ thống AI mắc lỗi nghiêm trọng? Có thể những người không có quyền truy cập để một luật sư được hưởng lợi từ một phiên bản trưởng thành của công nghệ này?
Kiện tụng chống lại khuếch tán ổn định đã bắt đầu
Matthew Butterick đã xuất bản điều này vào ngày 13 tháng XNUMX:
“Thay mặt cho ba người tuyệt vời nguyên đơn nghệ sĩ - Sarah Andersen, Kelly McKernanvà Karla Ortiz — chúng tôi đã đệ đơn kiện tập thể chống lại AI ổn định, DeviantArtvà giữa hành trình cho việc sử dụng của họ khuếch tán ổn định, một công cụ ghép ảnh của thế kỷ 21 phối lại các tác phẩm có bản quyền của hàng triệu nghệ sĩ có tác phẩm được sử dụng làm dữ liệu đào tạo.”
Nó bắt đầu - những bước đầu tiên hứa hẹn sẽ là một cuộc chiến lâu dài để kiểm duyệt việc đào tạo và sử dụng AI tổng quát. Tôi đồng ý với động cơ: “AI cần phải công bằng & đạo đức cho mọi người.”
Nhưng, như nhiều người khác, Tôi đã tìm thấy điểm không chính xác trong bài đăng trên blog. Nó đi sâu vào các kỹ thuật của Khuếch tán ổn định nhưng không giải thích chính xác một số bit. Liệu điều này có chủ ý như một phương tiện để thu hẹp khoảng cách kỹ thuật cho những người không biết — và không có thời gian để tìm hiểu — về cách thức hoạt động của công nghệ này (hoặc như một phương tiện để mô tả công nghệ theo cách có lợi cho họ hay không) ) hoặc một sai lầm có thể dẫn đến suy đoán.
Tôi đã tranh luận trong một bài báo trước rằng ngay bây giờ cuộc đụng độ giữa nghệ thuật AI và các nghệ sĩ truyền thống đang gây xúc động mạnh mẽ. Các câu trả lời cho vụ kiện này sẽ không có gì khác biệt. Chúng ta sẽ phải đợi ban giám khảo quyết định kết quả.
CNET xuất bản các bài báo do AI tạo ra
chủ nghĩa tương lai báo cáo điều này một vài tuần trước:
"CNET, một cửa hàng tin tức công nghệ nổi tiếng ồ ạt, đã âm thầm sử dụng sự trợ giúp của “công nghệ tự động hóa” - một cách nói hoa mỹ cho AI - trên một làn sóng mới các bài báo giải thích về tài chính.
Gael Breton, người đầu tiên phát hiện ra điều này, đã viết một phân tích sâu hơn vào thứ Sáu. Anh ấy giải thích rằng Google dường như không cản trở lưu lượng truy cập vào những bài đăng này. “Hiện tại nội dung AI đã ổn chưa?” anh ấy hỏi.
Tôi thấy đó là quyết định của CNET để tiết lộ đầy đủ việc sử dụng AI trong bài viết của họ một tiền lệ tốt. Có bao nhiêu người hiện đang xuất bản nội dung bằng AI mà không tiết lộ nội dung đó? Tuy nhiên, hậu quả là mọi người có thể mất việc nếu điều này xảy ra (như tôi và nhiều người khác, dự đoán). Nó đã xảy ra rồi:
Tôi hoàn toàn đồng ý với Tweet này từ Santiago:
RLHF để tạo ảnh
Nếu học tăng cường thông qua phản hồi của con người hoạt động đối với các mô hình ngôn ngữ, thì tại sao không phải đối với chuyển văn bản thành hình ảnh? Đó là những gì PickaPic đang cố gắng đạt được.
Bản demo là dành cho mục đích nghiên cứu nhưng có thể là một bổ sung thú vị cho Khuếch tán ổn định hoặc DALL-E (Midjourney làm điều gì đó tương tự - chúng hướng dẫn nội bộ mô hình để tạo ra hình ảnh đẹp và nghệ thuật).
Một công thức để “làm cho Siri/Alexa tốt hơn gấp 10 lần”
Các công thức kết hợp các mô hình AI tổng quát khác nhau để tạo ra một số mô hình tốt hơn so với tổng của các phần:
Alberto Romero là một nhà văn tự do tập trung vào công nghệ và AI. Anh ấy viết Cầu thuật toán, một bản tin giúp những người không chuyên về kỹ thuật hiểu được tin tức và sự kiện về AI. Anh ấy cũng là nhà phân tích công nghệ tại CambrianAI, nơi anh ấy chuyên về các mô hình ngôn ngữ lớn.
Nguyên. Đăng lại với sự cho phép.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/2023/02/chatgpt-gpt4-generative-ai-news.html?utm_source=rss&utm_medium=rss&utm_campaign=chatgpt-gpt-4-and-more-generative-ai-news
- 11
- 7
- 9
- a
- có khả năng
- Có khả năng
- Giới thiệu
- về nó
- tóm tắt
- Theo
- Đạt được
- ngang qua
- thích ứng
- Ngoài ra
- lợi thế
- chống lại
- AI
- nghệ thuật ai
- thuật toán
- Tất cả
- cho phép
- Đã
- thay thế
- luôn luôn
- trong số
- phân tích
- phân tích
- và
- công bố
- dự đoán
- bất kỳ ai
- hấp dẫn
- phương pháp tiếp cận
- Nghệ thuật
- bài viết
- nghệ thuật
- Nghệ sĩ
- sự chú ý
- có sẵn
- trở lại
- cấm
- đẹp
- bởi vì
- trước
- được
- hưởng lợi
- Lợi ích
- BEST
- Hơn
- giữa
- Hãy coi chừng
- Tỷ
- Blog
- đậm
- Sách
- CẦU
- xây dựng
- kinh doanh
- mô hình kinh doanh
- cuộc gọi
- Chiến dịch
- không thể
- nắm bắt
- chụp
- trường hợp
- trường hợp
- Trung tâm
- giám đốc điều hành
- thách thức
- Kênh
- đặc trưng
- chatbot
- chatbot
- ChatGPT
- xin
- Sự xung đột
- Phân loại
- Đóng
- CNET
- Đồng tác giả
- Cột
- COM
- Của công ty
- sự so sánh
- phức tạp
- Hãy xem xét
- xem xét
- nội dung
- Conversation
- có thể
- Couple
- Tòa án
- tạo
- tín dụng
- tiền thưởng
- dall's
- Nguy hiểm
- dữ liệu
- Cơ sở dữ liệu
- Davis
- nhiều
- quyết định
- sâu
- sâu sắc hơn
- chậm trễ
- Nhu cầu
- bộ
- Xác định
- Phát triển
- khác nhau
- Lôi thôi
- tiết lộ
- Tiết lộ
- công bố thông tin
- làm mất thông tin
- gây rối
- Chia
- tài liệu
- Không
- làm
- miền
- dont
- suốt trong
- kiếm được
- biên tập viên
- giáo dục
- Đào tạo
- Tư vấn Giáo dục
- nỗ lực
- Kỹ lưỡng
- vào
- Toàn bộ
- sự bình đẳng
- lỗi
- Ether (ETH)
- đạo đức
- Ngay cả
- sự kiện
- Mỗi
- mọi người
- tất cả mọi thứ
- ví dụ
- Thực thi
- các chuyên gia
- Giải thích
- Giải thích
- thêm
- Mắt
- Đối mặt
- không
- công bằng
- giả mạo
- NHANH
- Tính năng
- thông tin phản hồi
- lĩnh vực
- chiến đấu
- Hình
- Cuối cùng
- tài chính
- Tìm kiếm
- Tên
- những bước đầu tiên
- cờ
- tập trung
- quan trọng nhất
- Forward
- tìm thấy
- freelance
- người bạn
- từ
- đầy đủ
- khoảng cách
- Gary
- Tổng Quát
- thế hệ
- Trí tuệ nhân tạo
- GitHub
- được
- toàn cầu
- Go
- Các mục tiêu
- Đi
- đi
- tốt
- đồ thị
- tuyệt vời
- Phát triển
- hướng dẫn
- đã xảy ra
- xảy ra
- giúp đỡ
- giúp
- vui vẻ
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTML
- HTTPS
- Nhân loại
- xác định
- hình ảnh
- hình ảnh
- bao hàm
- in
- Ưu đãi
- Thông tin
- thông tin
- ban đầu
- Cố ý
- thú vị
- nội bộ
- đầu tư
- Các nhà đầu tư
- IT
- Tháng
- Tháng một
- việc làm
- Xe đẩy
- Giữ
- Hiệp sĩ
- Biết
- kiến thức
- Ngôn ngữ
- lớn
- Họ
- vụ kiện
- luật sư
- LEARN
- học tập
- Hợp pháp
- LIMIT
- LINK
- dài
- lâu
- NHÌN
- thua
- Rất nhiều
- Chủ yếu
- làm cho
- LÀM CHO
- nhiều
- nhiều người
- Marcus
- ồ ạt
- Vấn đề
- trưởng thành
- có nghĩa
- đo
- Phương tiện truyền thông
- trung bình
- chỉ đơn thuần là
- tin nhắn
- microsoft
- giữa hành trình
- Bộ
- Thông tin sai
- sai lầm
- Giảm nhẹ
- Chế độ
- kiểu mẫu
- mô hình
- Thứ Hai
- chi tiết
- Động lực
- di chuyển
- Thiên nhiên
- Cần
- nhu cầu
- Mới
- Các tính năng mới
- Công nghệ mới
- tin tức
- Tin tức
- Đăng ký bản tin
- phi kỹ thuật
- Chính thức
- Được rồi
- mở
- OpenAI
- Nền tảng khác
- Khác
- nếu không thì
- Kết quả
- Oxford
- Giấy
- tham gia
- các bộ phận
- Trả
- người
- có lẽ
- cho phép
- mảnh
- kế hoạch
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- cầu xin
- xin vui lòng
- thêm
- Điểm
- Phổ biến
- có thể
- Bài đăng
- đăng
- bài viết
- tiềm năng
- Tiền lệ
- trước
- Hiệu trưởng
- có lẽ
- Vấn đề
- vấn đề
- Sản phẩm
- Sản phẩm
- Lợi nhuận
- cấm
- Hứa hẹn
- cho
- Proxy
- công khai
- xuất bản
- Xuất bản
- mục đích
- câu hỏi
- lặng lẽ
- phản ứng
- Đọc
- lý do
- công thức
- giảm
- tài liệu tham khảo
- đều đặn
- học tăng cường
- phát hành
- nghiên cứu
- tài nguyên
- chịu trách nhiệm
- kết quả
- xem xét
- nghiêm ngặt
- rủi ro
- Robot
- Tin đồn
- Nói
- Sam
- tương tự
- Satya Nadella
- Trường học
- dường như
- đèn giao thông
- ý nghĩa
- kết án
- nghiêm trọng
- định
- chia sẻ
- nên
- đăng ký
- Silicon
- Silicon Valley
- tương tự
- đơn giản
- kể từ khi
- tình hình
- hơi khác nhau
- chậm rãi
- Mạng xã hội
- truyền thông xã hội
- giải pháp
- Giải pháp
- một số
- một cái gì đó
- Chẳng bao lâu
- nguồn
- đặc biệt
- chuyên
- suy đoán
- ổn định
- ngăn xếp
- Bắt đầu
- Các bước
- Dừng
- mạnh mẽ
- mạnh mẽ hơn
- mạnh mẽ
- Học tập
- như vậy
- hệ thống
- Hãy
- công nghệ cao
- tin tức công nghệ
- TechCrunch
- Kỹ thuật
- Công nghệ
- Công nghệ
- Sản phẩm
- cung cấp their dịch
- điều
- điều
- Suy nghĩ
- số ba
- Thông qua
- thời gian
- đến
- TẤN
- quá
- công cụ
- hàng đầu
- Chủ đề
- truyền thống
- giao thông
- Hội thảo
- điều trị
- xu hướng
- đúng
- NIỀM TIN
- kêu riu ríu
- kiểu chữ
- dễ hiểu
- Cập nhật
- cập nhật
- us
- sử dụng
- người sử dang
- Người sử dụng
- thung lũng
- liên doanh
- phiên bản
- khả năng tồn tại
- khả thi
- Video
- chờ đợi
- Sóng
- tuần
- tuần
- Điều gì
- liệu
- cái nào
- CHÚNG TÔI LÀ
- sẽ
- sẵn sàng
- cửa sổ
- không có
- Công việc
- đang làm việc
- công trinh
- giá trị
- sẽ
- nhà văn
- viết
- trên màn hình
- zephyrnet