Tìm các cột tương tự trong một hồ dữ liệu có các ứng dụng quan trọng trong việc làm sạch và chú thích dữ liệu, khớp lược đồ, khám phá dữ liệu và phân tích trên nhiều nguồn dữ liệu. Việc không thể tìm và phân tích chính xác dữ liệu từ các nguồn khác nhau có thể là kẻ giết người hiệu quả tiềm ẩn đối với tất cả mọi người từ nhà khoa học dữ liệu, nhà nghiên cứu y tế, học giả cho đến nhà phân tích tài chính và chính phủ.
Các giải pháp thông thường liên quan đến tìm kiếm từ khóa từ vựng hoặc đối sánh cụm từ thông dụng, dễ gặp phải các vấn đề về chất lượng dữ liệu như tên cột vắng mặt hoặc các quy ước đặt tên cột khác nhau trên các bộ dữ liệu khác nhau (ví dụ: zip_code, zcode, postalcode).
Trong bài đăng này, chúng tôi trình bày giải pháp tìm kiếm các cột tương tự dựa trên tên cột, nội dung cột hoặc cả hai. Giải pháp sử dụng gần đúng thuật toán hàng xóm gần nhất có sẵn trong Dịch vụ Tìm kiếm Mở của Amazon để tìm kiếm các cột tương tự về mặt ngữ nghĩa. Để tạo thuận lợi cho việc tìm kiếm, chúng tôi tạo các biểu diễn đối tượng (phần nhúng) cho các cột riêng lẻ trong kho dữ liệu bằng cách sử dụng các mô hình Transformer được đào tạo trước từ thư viện câu biến in Amazon SageMaker. Cuối cùng, để tương tác và trực quan hóa kết quả từ giải pháp của mình, chúng tôi xây dựng một giao diện tương tác Hợp lý hóa ứng dụng web chạy trên Cổng xa AWS.
Chúng tôi bao gồm một hướng dẫn mã để bạn triển khai các tài nguyên nhằm chạy giải pháp trên dữ liệu mẫu hoặc dữ liệu của riêng bạn.
Tổng quan về giải pháp
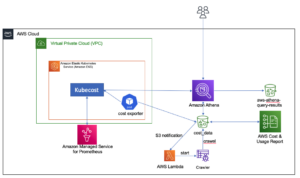
Sơ đồ kiến trúc sau đây minh họa quy trình làm việc hai giai đoạn để tìm các cột giống nhau về mặt ngữ nghĩa. Giai đoạn đầu tiên chạy một Chức năng bước AWS quy trình công việc tạo nhúng từ các cột dạng bảng và xây dựng chỉ mục tìm kiếm Dịch vụ Tìm kiếm Mở. Giai đoạn thứ hai, hay giai đoạn suy luận trực tuyến, chạy ứng dụng Streamlit thông qua Fargate. Ứng dụng web thu thập các truy vấn tìm kiếm đầu vào và truy xuất từ chỉ mục Dịch vụ tìm kiếm mở các cột gần đúng k-tương tự nhất cho truy vấn.

Hình 1. Kiến trúc giải pháp
Quy trình làm việc tự động tiến hành theo các bước sau:
- Người dùng tải các tập dữ liệu dạng bảng lên một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), bộ chứa này sẽ gọi một AWS Lambda bắt đầu quy trình làm việc Step Functions.
- Quy trình làm việc bắt đầu với một Keo AWS công việc chuyển đổi các tệp CSV thành Sàn gỗ Apache định dạng dữ liệu.
- Công việc Xử lý SageMaker tạo các phần nhúng cho từng cột bằng cách sử dụng các mô hình được đào tạo trước hoặc các mô hình nhúng cột tùy chỉnh. Công việc Xử lý SageMaker lưu các phần nhúng cột cho mỗi bảng trong Amazon S3.
- Một hàm Lambda tạo miền và cụm Dịch vụ OpenSearch để lập chỉ mục các phần nhúng cột được tạo ở bước trước.
- Cuối cùng, một ứng dụng web Streamlit tương tác được triển khai với Fargate. Ứng dụng web cung cấp giao diện cho người dùng nhập truy vấn để tìm kiếm miền Dịch vụ Tìm kiếm Mở cho các cột tương tự.
Bạn có thể tải xuống hướng dẫn mã từ GitHub để thử giải pháp này trên dữ liệu mẫu hoặc dữ liệu của riêng bạn. Hướng dẫn về cách triển khai các tài nguyên cần thiết cho hướng dẫn này có sẵn trên Github.
điều kiện tiên quyết
Để thực hiện giải pháp này, bạn cần những điều sau đây:
- An Tài khoản AWS.
- Làm quen cơ bản với các dịch vụ AWS như Bộ công cụ phát triển đám mây AWS (AWS CDK), Lambda, Dịch vụ tìm kiếm mở và Xử lý SageMaker.
- Một tập dữ liệu dạng bảng để tạo chỉ mục tìm kiếm. Bạn có thể mang theo dữ liệu dạng bảng của riêng mình hoặc tải xuống bộ dữ liệu mẫu trên GitHub.
Xây dựng chỉ mục tìm kiếm
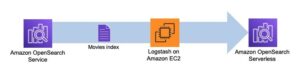
Giai đoạn đầu tiên xây dựng chỉ mục công cụ tìm kiếm cột. Hình dưới đây minh họa quy trình công việc Step Functions chạy giai đoạn này.

Hình 2 – Quy trình làm việc của chức năng bước – nhiều mô hình nhúng
Bộ dữ liệu
Trong bài đăng này, chúng tôi xây dựng một chỉ mục tìm kiếm để bao gồm hơn 400 cột từ hơn 25 bộ dữ liệu dạng bảng. Các bộ dữ liệu bắt nguồn từ các nguồn công khai sau:
Để biết danh sách đầy đủ các bảng có trong chỉ mục, hãy xem hướng dẫn về mã trên GitHub.
Bạn có thể mang tập dữ liệu dạng bảng của riêng mình để bổ sung dữ liệu mẫu hoặc tạo chỉ mục tìm kiếm của riêng bạn. Chúng tôi bao gồm hai hàm Lambda bắt đầu quy trình làm việc Step Functions để tạo chỉ mục tìm kiếm cho các tệp CSV riêng lẻ hoặc một loạt tệp CSV tương ứng.
Chuyển đổi CSV sang Sàn gỗ
Các tệp CSV thô được chuyển đổi sang định dạng dữ liệu Parquet bằng AWS Glue. Sàn gỗ là định dạng tệp định dạng theo cột được ưa thích trong phân tích dữ liệu lớn cung cấp khả năng nén và mã hóa hiệu quả. Trong các thử nghiệm của chúng tôi, định dạng dữ liệu Parquet giúp giảm đáng kể kích thước bộ nhớ so với các tệp CSV thô. Chúng tôi cũng đã sử dụng Parquet làm định dạng dữ liệu phổ biến để chuyển đổi các định dạng dữ liệu khác (ví dụ: JSON và NDJSON) vì nó hỗ trợ các cấu trúc dữ liệu lồng nhau nâng cao.
Tạo nhúng cột dạng bảng
Để trích xuất các phần nhúng cho các cột bảng riêng lẻ trong bộ dữ liệu dạng bảng mẫu trong bài đăng này, chúng tôi sử dụng các mô hình được đào tạo trước sau đây từ sentence-transformers thư viện. Đối với các mô hình bổ sung, xem Người mẫu được đào tạo trước.
Công việc Xử lý SageMaker chạy create_embeddings.py(mã) cho một mô hình duy nhất. Để trích xuất các nội dung nhúng từ nhiều mô hình, quy trình công việc sẽ chạy các công việc Xử lý SageMaker song song như được hiển thị trong quy trình làm việc Step Functions. Chúng tôi sử dụng mô hình để tạo hai bộ nhúng:
- cột_tên_embeddings – Nhúng tên cột (tiêu đề)
- cột_content_embeddings – Nhúng trung bình của tất cả các hàng trong cột
Để biết thêm thông tin về quy trình nhúng cột, hãy xem hướng dẫn mã trên GitHub.
Một giải pháp thay thế cho bước Xử lý SageMaker là tạo một biến đổi lô SageMaker để nhận các phần nhúng cột trên tập dữ liệu lớn. Điều này sẽ yêu cầu triển khai mô hình tới điểm cuối SageMaker. Để biết thêm thông tin, xem Sử dụng biến đổi hàng loạt.
Lập chỉ mục nhúng với OpenSearch Service
Ở bước cuối cùng của giai đoạn này, một hàm Lambda thêm các phần nhúng cột vào Dịch vụ tìm kiếm mở gần đúng k-Láng giềng gần nhất (kNN) chỉ mục tìm kiếm. Mỗi mô hình được gán chỉ mục tìm kiếm riêng. Để biết thêm thông tin về các tham số chỉ mục tìm kiếm kNN gần đúng, hãy xem k-NN.
Suy luận trực tuyến và tìm kiếm ngữ nghĩa với một ứng dụng web
Giai đoạn thứ hai của quy trình làm việc chạy một Hợp lý hóa ứng dụng web nơi bạn có thể cung cấp thông tin đầu vào và tìm kiếm các cột tương tự về mặt ngữ nghĩa được lập chỉ mục trong Dịch vụ Tìm kiếm Mở. Tầng ứng dụng sử dụng một Cân bằng tải ứng dụng, Fargate và Lambda. Cơ sở hạ tầng ứng dụng được tự động triển khai như một phần của giải pháp.
Ứng dụng này cho phép bạn cung cấp đầu vào và tìm kiếm các tên cột, nội dung cột hoặc cả hai tương tự về mặt ngữ nghĩa. Ngoài ra, bạn có thể chọn mô hình nhúng và số lân cận gần nhất để trả về từ tìm kiếm. Ứng dụng nhận đầu vào, nhúng đầu vào với mô hình đã chỉ định và sử dụng tìm kiếm kNN trong OpenSearch Service để tìm kiếm các phần nhúng cột được lập chỉ mục và tìm các cột giống nhất với đầu vào đã cho. Kết quả tìm kiếm được hiển thị bao gồm tên bảng, tên cột và điểm tương đồng cho các cột được xác định, cũng như vị trí của dữ liệu trong Amazon S3 để khám phá thêm.
Hình dưới đây cho thấy một ví dụ về ứng dụng web. Trong ví dụ này, chúng tôi đã tìm kiếm các cột trong hồ dữ liệu của chúng tôi có các cột tương tự Column Names (loại trọng tải) Để district (khối hàng). Ứng dụng được sử dụng all-MiniLM-L6-v2 như mô hình nhúng và đã trở lại 10 (k) hàng xóm gần nhất từ chỉ mục Dịch vụ Tìm kiếm Mở của chúng tôi.
Ứng dụng đã trở lại transit_district, city, boroughvà location dưới dạng bốn cột giống nhau nhất dựa trên dữ liệu được lập chỉ mục trong Dịch vụ tìm kiếm mở. Ví dụ này cho thấy khả năng của phương pháp tìm kiếm để xác định các cột giống nhau về mặt ngữ nghĩa trên các bộ dữ liệu.

Hình 3: Giao diện người dùng ứng dụng web
Làm sạch
Để xóa tài nguyên do AWS CDK tạo trong hướng dẫn này, hãy chạy lệnh sau:
cdk destroy --allKết luận
Trong bài đăng này, chúng tôi đã trình bày quy trình làm việc từ đầu đến cuối để xây dựng công cụ tìm kiếm ngữ nghĩa cho các cột dạng bảng.
Bắt đầu ngay hôm nay trên dữ liệu của riêng bạn với hướng dẫn mã của chúng tôi có sẵn trên GitHub. Nếu bạn muốn trợ giúp tăng tốc việc sử dụng ML trong các sản phẩm và quy trình của mình, vui lòng liên hệ với Phòng thí nghiệm Giải pháp Máy học của Amazon.
Về các tác giả
![]() Kachi Odoemen là Nhà khoa học ứng dụng tại AWS AI. Anh xây dựng các giải pháp AI/ML để giải quyết các vấn đề kinh doanh cho khách hàng AWS.
Kachi Odoemen là Nhà khoa học ứng dụng tại AWS AI. Anh xây dựng các giải pháp AI/ML để giải quyết các vấn đề kinh doanh cho khách hàng AWS.
![]() Taylor McNally là Kiến trúc sư học sâu tại Phòng thí nghiệm giải pháp học máy của Amazon. Anh giúp khách hàng từ nhiều ngành khác nhau xây dựng giải pháp tận dụng AI/ML trên AWS. Anh ấy thích một tách cà phê ngon, hoạt động ngoài trời và dành thời gian cho gia đình và chú chó năng động của mình.
Taylor McNally là Kiến trúc sư học sâu tại Phòng thí nghiệm giải pháp học máy của Amazon. Anh giúp khách hàng từ nhiều ngành khác nhau xây dựng giải pháp tận dụng AI/ML trên AWS. Anh ấy thích một tách cà phê ngon, hoạt động ngoài trời và dành thời gian cho gia đình và chú chó năng động của mình.
![]() Austin Welch là Nhà khoa học dữ liệu trong Phòng thí nghiệm giải pháp ML của Amazon. Anh ấy phát triển các mô hình deep learning tùy chỉnh để giúp các khách hàng thuộc khu vực công của AWS đẩy nhanh quá trình áp dụng AI và đám mây của họ. Trong thời gian rảnh rỗi, anh ấy thích đọc sách, đi du lịch và jiu-jitsu.
Austin Welch là Nhà khoa học dữ liệu trong Phòng thí nghiệm giải pháp ML của Amazon. Anh ấy phát triển các mô hình deep learning tùy chỉnh để giúp các khách hàng thuộc khu vực công của AWS đẩy nhanh quá trình áp dụng AI và đám mây của họ. Trong thời gian rảnh rỗi, anh ấy thích đọc sách, đi du lịch và jiu-jitsu.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- có khả năng
- Giới thiệu
- vắng mặt
- đẩy nhanh tiến độ
- tăng tốc
- chính xác
- ngang qua
- thêm vào
- Ngoài ra
- Thêm
- Nhận con nuôi
- tiên tiến
- AI
- AI / ML
- Tất cả
- cho phép
- thay thế
- đàn bà gan dạ
- Học máy Amazon
- Phòng thí nghiệm giải pháp Amazon ML
- Các nhà phân tích
- phân tích
- phân tích
- và
- Apache
- Các Ứng Dụng
- các ứng dụng
- áp dụng
- phương pháp tiếp cận
- kiến trúc
- giao
- Tự động
- tự động
- có sẵn
- Trung bình cộng
- AWS
- Keo AWS
- dựa
- bởi vì
- lớn
- Dữ Liệu Lớn.
- mang lại
- xây dựng
- Xây dựng
- xây dựng
- kinh doanh
- Làm sạch
- đám mây
- áp dụng đám mây
- cụm
- mã
- Cà Phê
- thu thập
- Cột
- Cột
- Chung
- so
- liên lạc
- nội dung
- công ước
- chuyển đổi
- chuyển đổi
- tạo
- tạo ra
- tạo ra
- Cup
- khách hàng
- khách hàng
- dữ liệu
- Phân tích dữ liệu
- Hồ dữ liệu
- chất lượng dữ liệu
- nhà khoa học dữ liệu
- bộ dữ liệu
- sâu
- học kĩ càng
- chứng minh
- chứng minh
- triển khai
- triển khai
- triển khai
- phá hủy
- Phát triển
- phát triển
- khác nhau
- phát hiện
- khác biệt
- khác nhau
- Dog
- miền
- tải về
- mỗi
- hiệu quả
- hiệu quả
- Cuối cùng đến cuối
- Điểm cuối
- Động cơ
- Ether (ETH)
- mọi người
- ví dụ
- thăm dò
- trích xuất
- tạo điều kiện
- Tính quen thuộc
- gia đình
- Tính năng
- Hình
- Tập tin
- Các tập tin
- cuối cùng
- Cuối cùng
- tài chính
- Tìm kiếm
- tìm kiếm
- Tên
- tiếp theo
- định dạng
- từ
- Full
- chức năng
- chức năng
- xa hơn
- được
- được
- tốt
- Chính phủ
- tiêu đề
- giúp đỡ
- giúp
- Độ đáng tin của
- Hướng dẫn
- HTML
- HTTPS
- xác định
- xác định
- thực hiện
- quan trọng
- in
- không có khả năng
- bao gồm
- bao gồm
- chỉ số
- hệ thống riêng biệt,
- các ngành công nghiệp
- thông tin
- Cơ sở hạ tầng
- bắt đầu
- Đồng tu
- đầu vào
- hướng dẫn
- tương tác
- tương tác
- Giao thức
- viện dẫn
- liên quan
- các vấn đề
- IT
- Việc làm
- việc làm
- json
- phòng thí nghiệm
- hồ
- lớn
- lớp
- học tập
- tận dụng
- Thư viện
- Danh sách
- tải
- . Các địa điểm
- máy
- học máy
- phù hợp
- y khoa
- ML
- kiểu mẫu
- mô hình
- chi tiết
- hầu hết
- nhiều
- tên
- tên
- đặt tên
- Cần
- người hàng xóm
- con số
- cung cấp
- Trực tuyến
- Nền tảng khác
- ngoài trời
- riêng
- Song song
- thông số
- một phần
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- xin vui lòng
- Bài đăng
- tiềm năng
- ưa thích
- trình bày
- trước
- vấn đề
- tiền thu được
- quá trình
- Quy trình
- xử lý
- Sản xuất
- Sản phẩm
- cho
- cung cấp
- công khai
- chất lượng
- Nguyên
- Reading
- nhận
- đều đặn
- đại diện cho
- yêu cầu
- cần phải
- nhà nghiên cứu
- Thông tin
- tương ứng
- Kết quả
- trở lại
- chạy
- chạy
- nhà làm hiền triết
- Nhà khoa học
- các nhà khoa học
- Tìm kiếm
- công cụ tìm kiếm
- tìm kiếm
- Thứ hai
- ngành
- dịch vụ
- DỊCH VỤ
- bộ
- thể hiện
- Chương trình
- có ý nghĩa
- tương tự
- Đơn giản
- duy nhất
- Kích thước máy
- giải pháp
- Giải pháp
- động SOLVE
- nguồn
- quy định
- Traineeship
- bắt đầu
- Bước
- Các bước
- là gắn
- như vậy
- Hỗ trợ
- apt
- bàn
- Sản phẩm
- cung cấp their dịch
- Thông qua
- thời gian
- đến
- bây giờ
- Chuyển đổi
- máy biến áp
- Đi du lịch
- hướng dẫn
- sử dụng
- người sử dang
- Giao diện người dùng
- khác nhau
- web
- Ứng dụng web
- cái nào
- quy trình làm việc
- sẽ
- trên màn hình
- zephyrnet