Зображення на Freepik
Розмовний ШІ стосується віртуальних агентів і чат-ботів, які імітують людські взаємодії та можуть залучати людей до розмови. Використання розмовного штучного інтелекту швидко стає способом життя – від запиту Alexa до «знайти найближчий ресторан» попросити Siri "створити нагадування", віртуальні помічники та чат-боти часто використовуються для відповідей на запитання споживачів, вирішення скарг, бронювання тощо.
Розробка цих віртуальних помічників вимагає значних зусиль. Однак розуміння та вирішення ключових проблем може оптимізувати процес розробки. Я використовував свій власний досвід у створенні зрілого чат-бота для рекрутингової платформи як орієнтир, щоб пояснити основні проблеми та відповідні рішення.
Щоб створити розмовний чат-бот AI, розробники можуть використовувати такі фреймворки, як RASA, Lex від Amazon або Dialogflow від Google для створення чат-ботів. Більшість віддають перевагу RASA, коли планують спеціальні зміни або бот знаходиться на стадії зрілості, оскільки це фреймворк з відкритим кодом. Інші рамки також підходять як відправна точка.
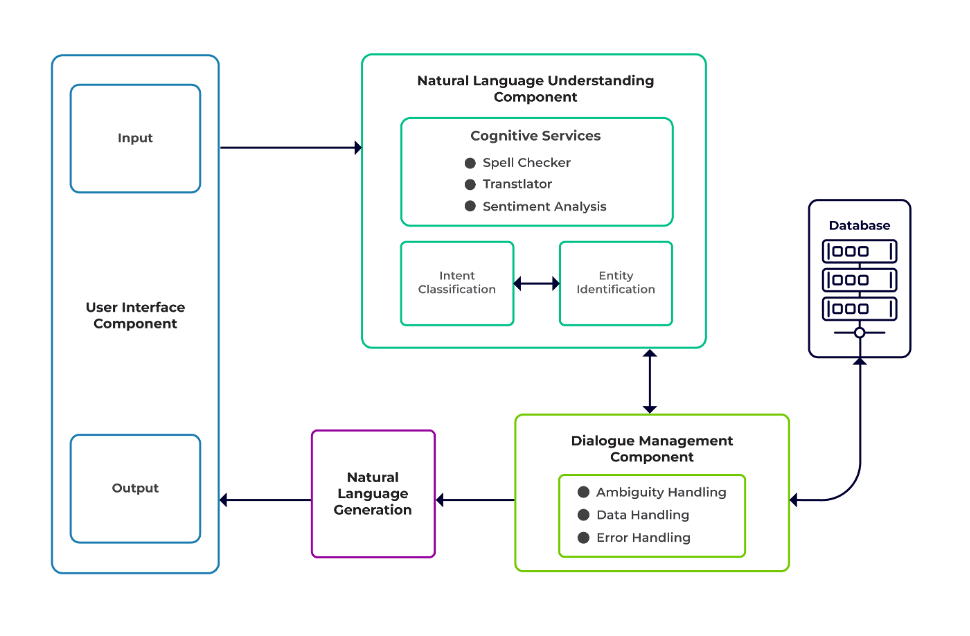
Завдання можна класифікувати як три основні компоненти чат-бота.
Розуміння природної мови (NLU) це здатність бота розуміти людський діалог. Він виконує класифікацію намірів, вилучення об’єктів і отримання відповідей.
Менеджер діалогу відповідає за набір дій, які необхідно виконати на основі поточного та попереднього набору введених користувачем даних. Він приймає наміри та сутності як вхідні дані (як частину попередньої розмови) і визначає наступну відповідь.
Генерація природної мови (NLG) це процес створення письмових або усних речень із заданих даних. Він оформляє відповідь, яка потім представляється користувачеві.
Зображення з Talentica Software
Недостатньо даних
Коли розробники замінюють FAQ або інші системи підтримки чат-ботом, вони отримують пристойну кількість навчальних даних. Але те саме не відбувається, коли вони створюють бота з нуля. У таких випадках розробники генерують навчальні дані синтетично.
Що ж робити?
Генератор даних на основі шаблонів може генерувати пристойну кількість запитів користувачів для навчання. Коли чат-бот буде готовий, власники проекту можуть надати його обмеженій кількості користувачів, щоб покращити навчальні дані та оновити їх протягом певного періоду.
Невідповідний вибір моделі
Відповідний вибір моделі та навчальні дані мають вирішальне значення для отримання найкращих результатів вилучення намірів і сутностей. Розробники зазвичай навчають чат-ботів певній мові та домену, і більшість доступних попередньо навчених моделей часто є доменно-спеціальними та навчаються однією мовою.
Також можуть бути випадки змішаних мов, коли люди є поліглотами. Вони можуть вводити запити змішаною мовою. Наприклад, у регіоні з домінуванням французів люди можуть використовувати тип англійської мови, який є сумішшю французької та англійської.
Що ж робити?
Використання моделей, навчених кількома мовами, може зменшити проблему. Попередньо навчена модель, як-от LaBSE (вбудовування речень Берта з незалежною мовою), може бути корисною в таких випадках. LaBSE навчається більш ніж 109 мовами за завданням на схожість речень. Модель вже знає подібні слова іншою мовою. У нашому проекті це спрацювало дуже добре.
Неправильне вилучення сутності
Чат-боти вимагають, щоб суб’єкти визначали, які дані шукає користувач. Ці сутності включають час, місце, особу, предмет, дату тощо. Однак боти можуть не ідентифікувати сутність із природної мови:
Той самий контекст, але різні сутності. Наприклад, боти можуть сплутати місце як сутність, коли користувач вводить «Ім’я студентів з IIT Delhi», а потім «Ім’я студентів з Бенгалуру».
Сценарії, коли сутності неправильно передбачувані з низькою достовірністю. Наприклад, бот може визначити IIT Delhi як місто з низькою достовірністю.
Часткове вилучення сутності за допомогою моделі машинного навчання. Якщо користувач вводить «студенти з IIT Delhi», модель може ідентифікувати лише «IIT» лише як сутність замість «IIT Delhi».
Введення з одного слова без контексту можуть заплутати моделі машинного навчання. Наприклад, таке слово, як «Рішікеш», може означати як назву людини, так і місто.
Що ж робити?
Вирішенням може бути додавання додаткових прикладів навчання. Але є межа, після якої додавання більше не допоможе. Крім того, це нескінченний процес. Іншим рішенням може бути визначення шаблонів регулярних виразів за допомогою попередньо визначених слів, щоб допомогти отримати сутності з відомим набором можливих значень, як-от місто, країна тощо.
Моделі мають нижчу впевненість, коли вони не впевнені щодо передбачення сутності. Розробники можуть використовувати це як тригер для виклику спеціального компонента, який може виправити об’єкт із низьким рівнем впевненості. Розглянемо наведений вище приклад. Якщо ІІТ Делі прогнозується як місто з низькою достовірністю, то користувач завжди може шукати його в базі даних. Після невдачі знайти передбачену сутність у Місто таблиці, модель переходить до інших таблиць і, зрештою, знаходить її в Інститут таблиці, що призводить до виправлення сутності.
Неправильна класифікація намірів
Кожне повідомлення користувача має певний намір, пов’язаний з ним. Оскільки наміри визначають наступний курс дій бота, правильна класифікація запитів користувачів із наміром є надзвичайно важливою. Однак розробники повинні ідентифікувати наміри з мінімальною плутаниною між намірами. Інакше можуть бути випадки, викликані плутаниною. Наприклад, "Покажіть мені відкриті вакансії» проти “Покажіть мені кандидатів на відкриті вакансії».
Що ж робити?
Є два способи відрізнити заплутані запити. По-перше, розробник може ввести піднамір. По-друге, моделі можуть обробляти запити на основі ідентифікованих сутностей.
Доменно-спеціальний чат-бот має бути закритою системою, де він має чітко визначити, на що він здатний, а на що ні. Розробники повинні виконувати розробку поетапно, плануючи доменно-спеціальні чат-боти. На кожному етапі вони можуть ідентифікувати непідтримувані функції чат-бота (через непідтримуваний намір).
Вони також можуть визначити, що чат-бот не може обробити в плані «поза межами». Але можуть бути випадки, коли бот плутається через непідтримуваний намір і намір поза межами області видимості. Для таких сценаріїв має бути встановлений резервний механізм, за якого, якщо впевненість намірів нижча за порогове значення, модель може ефективно працювати з резервним наміром для обробки випадків плутанини.
Коли бот визначає мету повідомлення користувача, він повинен надіслати відповідь. Бот вирішує відповідь на основі певного набору визначених правил і історій. Наприклад, правило може бути таким же простим, як і повним "доброго ранку" коли користувач вітається "Привіт". Однак найчастіше розмови з чат-ботами включають подальшу взаємодію, і їхні відповіді залежать від загального контексту розмови.
Що ж робити?
Щоб впоратися з цим, чат-боти подають приклади реальних розмов під назвою Stories. Однак користувачі не завжди взаємодіють належним чином. Зрілий чат-бот повинен витончено впоратися з усіма такими відхиленнями. Дизайнери та розробники можуть гарантувати це, якщо вони не просто зосереджуються на щасливому шляху під час написання історій, а й працюють над нещасливими шляхами.
Взаємодія користувачів із чат-ботами значною мірою залежить від відповідей чат-ботів. Користувачі можуть втратити інтерес, якщо відповіді будуть надто автоматизованими або надто знайомими. Наприклад, користувачеві може не сподобатися відповідь на зразок «Ви ввели неправильний запит» через неправильне введення, навіть якщо відповідь правильна. Відповідь тут не відповідає персоні помічника.
Що ж робити?
Чат-бот служить помічником і повинен мати певну персону та тон голосу. Вони мають бути привітними та скромними, і розробники мають відповідним чином планувати розмови та висловлювання. Відповіді не повинні звучати робототехнічно або механічно. Наприклад, бот може сказати: «Вибачте, здається, я не маю жодних деталей. Чи не могли б ви ще раз ввести свій запит?» для усунення неправильного введення.
Чат-боти на основі LLM (Large Language Model), такі як ChatGPT і Bard, є кардинальними інноваціями та покращили можливості розмовного ШІ. Вони не тільки вміють вести відкриті людські розмови, але й можуть виконувати різні завдання, як-от резюмування тексту, написання абзаців тощо, чого раніше можна було досягти лише за допомогою конкретних моделей.
Однією з проблем традиційних систем чат-ботів є класифікація кожного речення за наміром і відповідне рішення щодо відповіді. Такий підхід не практичний. Відповіді на кшталт «Вибачте, я не зміг вас зателефонувати» часто викликають роздратування. Системи чат-ботів без наміру — це шлях вперед, і LLM можуть втілити це в реальність.
LLM можуть легко досягти найсучасніших результатів у загальному розпізнаванні іменованих сутностей, за винятком розпізнавання певних предметних сутностей. Змішаний підхід до використання LLM з будь-якою структурою чат-бота може надихнути на створення більш зрілої та надійної системи чат-бота.
Завдяки останнім досягненням і постійним дослідженням розмовного ШІ чат-боти стають кращими з кожним днем. Такі сфери, як виконання складних завдань із кількома цілями, як-от «Забронювати рейс до Мумбаї та організувати таксі до Дадара», привертають велику увагу.
Незабаром персоналізовані розмови будуть відбуватися на основі характеристик користувача, щоб підтримувати його зацікавленість. Наприклад, якщо бот виявляє, що користувач незадоволений, він перенаправляє розмову до справжнього агента. Крім того, з постійно зростаючими даними чат-ботів методи глибокого навчання, такі як ChatGPT, можуть автоматично генерувати відповіді на запити, використовуючи базу знань.
Суман Саурав є спеціалістом з обробки даних у компанії Talentica Software, яка займається розробкою програмного забезпечення. Він є випускником NIT Agartala з більш ніж 8-річним досвідом розробки та впровадження революційних рішень штучного інтелекту з використанням NLP, розмовного штучного інтелекту та генеративного штучного інтелекту.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- : має
- :є
- : ні
- :де
- 8
- a
- здатність
- МЕНЮ
- вище
- відповідно
- Achieve
- досягнутий
- через
- дії
- додати
- Додатково
- адреса
- адресація
- досягнення
- після
- Агент
- агенти
- AI
- AI чат
- Alexa
- ВСІ
- вже
- Також
- випускники
- завжди
- кількість
- an
- та
- Інший
- відповідь
- будь-який
- підхід
- ЕСТЬ
- області
- AS
- запитувач
- Помічник
- помічники
- асоційований
- At
- увагу
- автоматично
- доступний
- уникнути
- назад
- база
- заснований
- BE
- становлення
- істоти
- нижче
- КРАЩЕ
- Краще
- Бот
- обидва
- боти
- будувати
- але
- by
- call
- званий
- CAN
- не може
- можливості
- здатний
- випадків
- категоризація
- певний
- проблеми
- Зміни
- характеристика
- Chatbot
- chatbots
- ChatGPT
- Місто
- класифікація
- класифікований
- очевидно
- закрито
- компанія
- скарги
- комплекс
- компонент
- Компоненти
- осягнути
- довіра
- спутаний
- заплутаний
- замішання
- Вважати
- контекст
- безперервний
- Розмова
- діалоговий
- розмовний ШІ
- розмови
- виправити
- правильно
- Відповідний
- може
- країна
- курс
- створювати
- створення
- вирішальне значення
- Поточний
- виготовлений на замовлення
- дані
- вчений даних
- Database
- Дата
- день
- пристойний
- Вирішивши
- глибокий
- глибоке навчання
- визначати
- певний
- Делі
- залежати
- дрейф
- дизайн
- Дизайнери
- проектування
- деталі
- Розробник
- розробників
- розробка
- діалоговий потік
- Діалог
- різний
- диференціювати
- do
- Ні
- домен
- Не знаю
- кожен
- Раніше
- легко
- зусилля
- вбудовування
- Нескінченний
- займатися
- зайнятий
- зачеплення
- англійська
- підвищувати
- Що натомість? Створіть віртуальну версію себе у
- юридичні особи
- суб'єкта
- і т.д.
- Навіть
- врешті-решт
- постійно збільшується
- Кожен
- кожен день
- приклад
- Приклади
- досвід
- Пояснювати
- витяг
- видобуток
- FAIL
- відсутності
- знайомий
- ШВИДКО
- риси
- Fed
- знайти
- знахідки
- політ
- Сфокусувати
- для
- Вперед
- Рамки
- каркаси
- французька
- від
- Загальне
- породжувати
- породжує
- покоління
- генеративний
- Генеративний ШІ
- generator
- отримати
- отримання
- даний
- добре
- Google,
- гарантувати
- обробляти
- Обробка
- траплятися
- щасливий
- Мати
- має
- he
- сильно
- допомога
- корисний
- тут
- Як
- How To
- Однак
- HTTPS
- людина
- скромний
- i
- ідентифікований
- ідентифікує
- ідентифікувати
- if
- реалізації
- поліпшений
- in
- включати
- інновації
- вхід
- витрати
- вселяти
- екземпляр
- замість
- призначених
- намір
- взаємодіяти
- взаємодія
- Взаємодії
- інтерес
- в
- вводити
- IT
- JPG
- просто
- KDnuggets
- тримати
- ключ
- Дитина
- знання
- відомий
- знає
- мова
- мови
- великий
- останній
- вивчення
- життя
- як
- МЕЖА
- обмеженою
- втрачати
- низький
- знизити
- машина
- навчання за допомогою машини
- основний
- зробити
- Робить
- матч
- зрілий
- Може..
- me
- значити
- механічний
- механізм
- повідомлення
- може бути
- мінімальний
- змішувати
- змішаний
- модель
- Моделі
- більше
- Більше того
- найбільш
- багато
- множинний
- Мумбаї
- повинен
- my
- ім'я
- Названий
- Природний
- Природна мова
- наступний
- NLG
- nlp
- nlu
- немає
- номер
- of
- часто
- on
- один раз
- тільки
- відкрити
- з відкритим вихідним кодом
- or
- Інше
- інакше
- наші
- над
- загальний
- Власники
- частина
- шлях
- стежки
- моделі
- Люди
- виконувати
- виконується
- виступає
- period
- людина
- Персоналізовані
- фаза
- фаз
- місце
- план
- планування
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- будь ласка
- точка
- положення
- володіти
- це можливо
- Практичний
- передвіщений
- прогноз
- надавати перевагу
- представлений
- попередній
- Проблема
- продовжити
- процес
- Product
- розробка продукту
- проект
- запити
- питань
- R
- раса
- готовий
- реальний
- Реальність
- насправді
- визнання
- набір
- зменшити
- посилання
- відноситься
- регіон
- покладатися
- нагадування
- замінювати
- вимагати
- Вимагається
- дослідження
- рішення
- відповідь
- відповіді
- відповідальний
- в результаті
- результати
- революційний
- міцний
- Правило
- Правила
- то ж
- say
- сценарії
- вчений
- подряпати
- Пошук
- Грати короля карти - безкоштовно Nijumi логічна гра гри
- Здається,
- вибір
- послати
- пропозиція
- служить
- комплект
- Поділитись
- Повинен
- аналогічний
- простий
- з
- один
- Siri
- Софтвер
- рішення
- Рішення
- деякі
- Звучати
- конкретний
- говорять
- Стажування
- Починаючи
- впроваджений
- історії
- раціоналізувати
- Студентам
- істотний
- такі
- підходящий
- підтримка
- системи підтримки
- Переконайтеся
- синтетично
- система
- Systems
- T
- таблиця
- Приймати
- приймає
- Завдання
- завдання
- методи
- текст
- ніж
- Що
- Команда
- їх
- Їх
- потім
- Там.
- Ці
- вони
- це
- хоча?
- три
- поріг
- час
- до
- TONE
- Тон голосу
- занадто
- традиційний
- поїзд
- навчений
- Навчання
- викликати
- два
- тип
- Типи
- розуміння
- модернізація
- використання
- використовуваний
- користувач
- користувачі
- використання
- зазвичай
- Цінності
- через
- Віртуальний
- Голос
- vs
- W
- шлях..
- способи
- вітальний
- ДОБРЕ
- Що
- коли
- коли б ні
- який
- в той час як
- волі
- з
- слово
- слова
- Work
- працював
- б
- лист
- письмовий
- Неправильно
- років
- ви
- вашу
- зефірнет