Одним із найкорисніших прикладних шаблонів для генеративних робочих навантажень AI є Retrieval Augmented Generation (RAG). У шаблоні RAG ми знаходимо фрагменти еталонного вмісту, пов’язані з підказкою введення, виконуючи пошук подібності у вбудовуваннях. Вбудовування фіксують інформаційний вміст у тексті, дозволяючи моделям обробки природної мови (NLP) працювати з мовою в числовій формі. Вбудовування — це лише вектори чисел з плаваючою комою, тому ми можемо проаналізувати їх, щоб відповісти на три важливі запитання: чи змінюються наші довідкові дані з часом? Чи змінюються з часом питання, які ставлять користувачі? І, нарешті, наскільки добре наші довідкові дані охоплюють поставлені запитання?
У цьому дописі ви дізнаєтесь про деякі міркування щодо векторного аналізу вбудованого аналізу та виявлення сигналів дрейфу вбудованого. Оскільки вбудовування є важливим джерелом даних для моделей NLP загалом і генеративних рішень штучного інтелекту зокрема, нам потрібен спосіб виміряти, чи змінюються наші вбудовування з часом (дрейфують). У цій публікації ви побачите приклад виконання виявлення дрейфу на вбудованих векторах за допомогою методу кластеризації з великими мовними моделями (LLMS), розгорнутими з Amazon SageMaker JumpStart. Ви також зможете вивчити ці концепції на двох наданих прикладах, включаючи наскрізний зразок програми або, за бажанням, підмножину програми.
Огляд RAG
Команда ганчірка візерунок дає змогу отримувати знання із зовнішніх джерел, таких як PDF-документи, вікі-статті або стенограми розмов, а потім використовувати ці знання для доповнення підказок, що надсилаються до LLM. Це дозволяє LLM посилатися на більш релевантну інформацію під час генерації відповіді. Наприклад, якщо ви запитуєте магістра права, як приготувати шоколадне печиво, це може містити інформацію з вашої власної бібліотеки рецептів. У цьому шаблоні текст рецепту перетворюється на вектори вбудовування за допомогою моделі вбудовування та зберігається у векторній базі даних. Вхідні запитання перетворюються на вбудовування, а потім векторна база даних виконує пошук схожості, щоб знайти пов’язаний вміст. Потім запитання та довідкові дані переходять у підказку для LLM.
Давайте детальніше розглянемо вектори вбудовування, які створюються, і те, як виконувати дрейфовий аналіз цих векторів.
Аналіз векторів вкладення
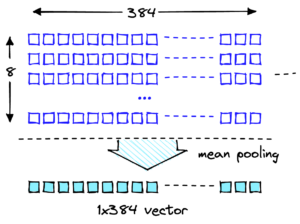
Вектори вбудовування є числовими представленнями наших даних, тому аналіз цих векторів може дати розуміння наших довідкових даних, які пізніше можна використовувати для виявлення потенційних сигналів дрейфу. Вектори вбудовування представляють елемент у n-вимірному просторі, де n часто велике. Наприклад, модель GPT-J 6B, використана в цій публікації, створює вектори розміром 4096. Щоб виміряти дрейф, припустимо, що наша програма фіксує вбудовані вектори як для довідкових даних, так і для вхідних запитів.
Ми починаємо з виконання зменшення розмірності за допомогою аналізу головних компонентів (PCA). PCA намагається зменшити кількість вимірів, зберігаючи більшу частину дисперсії в даних. У цьому випадку ми намагаємося знайти кількість вимірів, яка зберігає 95% дисперсії, яка повинна охоплювати будь-що в межах двох стандартних відхилень.
Потім ми використовуємо K-Means для визначення набору центрів кластерів. K-Means намагається згрупувати точки разом у кластери таким чином, щоб кожен кластер був відносно компактним, а кластери були максимально віддалені один від одного.
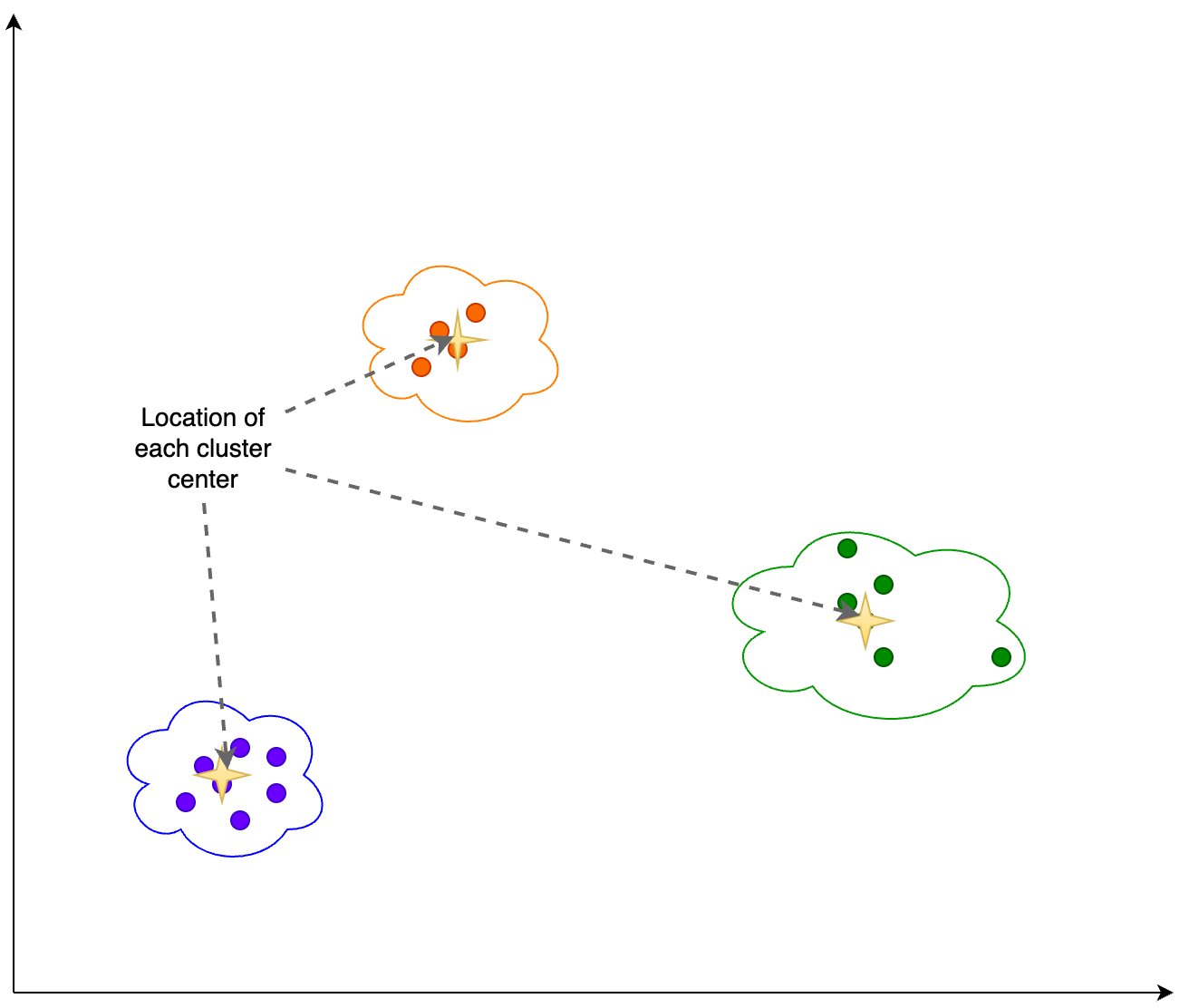
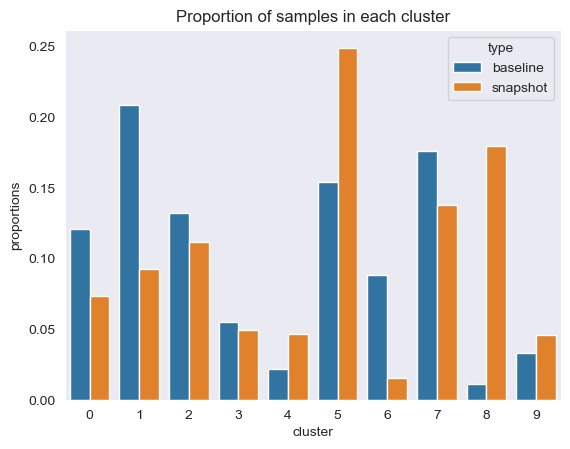
Ми обчислюємо таку інформацію на основі результатів кластеризації, показаних на наступному малюнку:
- Кількість параметрів у PCA, які пояснюють 95% дисперсії
- Розташування кожного центру кластера, або центроїда
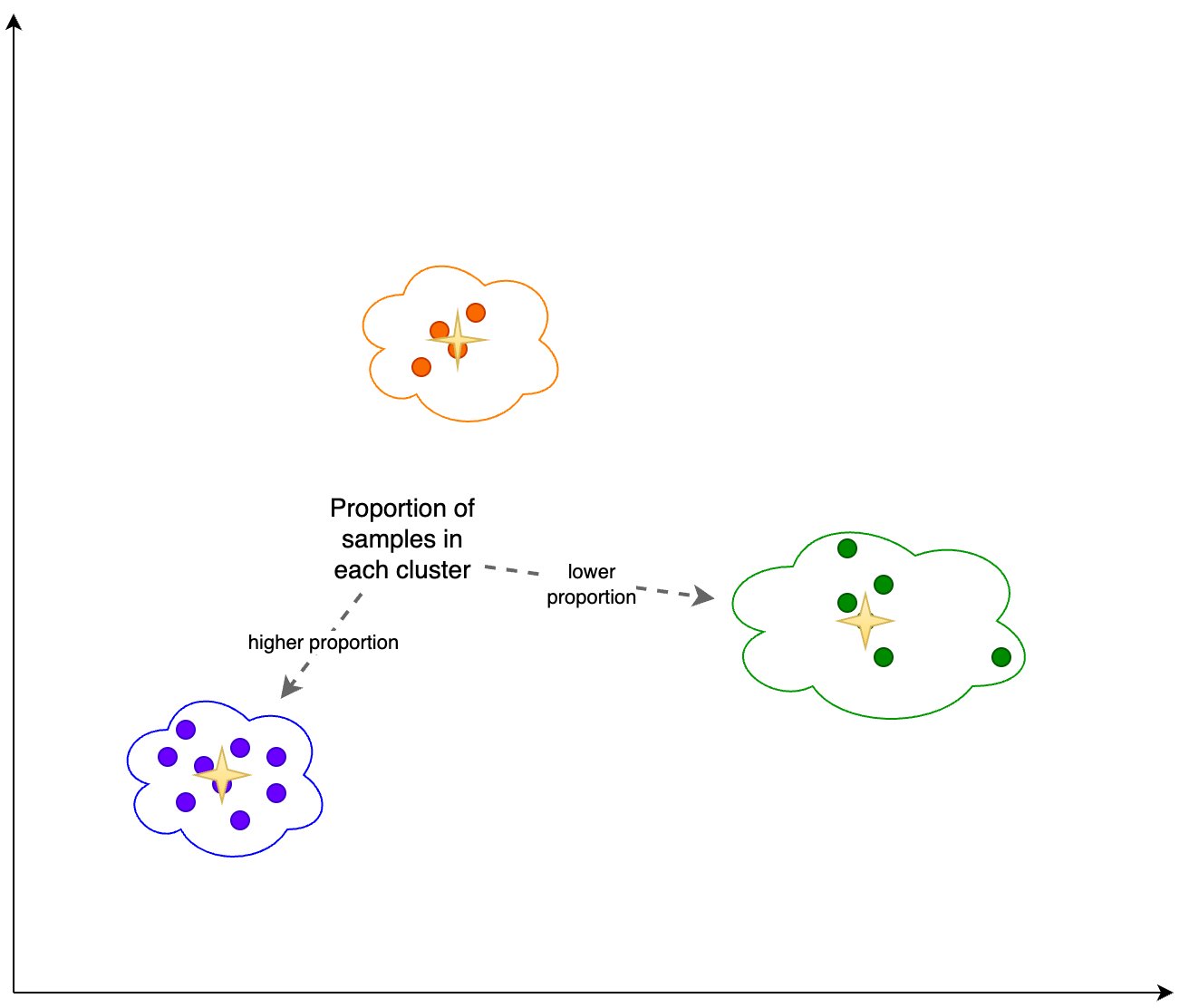
Крім того, ми дивимося на частку (вищу чи меншу) вибірок у кожному кластері, як показано на наступному малюнку.
Нарешті, ми використовуємо цей аналіз, щоб обчислити наступне:
- Інерція – Інерція – це сума квадратів відстаней до центроїдів кластера, яка вимірює, наскільки добре дані були згруповані за допомогою K-Means.
- Силуетна партитура – Оцінка силуету є мірою перевірки узгодженості в межах кластерів і варіюється від -1 до 1. Значення, близьке до 1, означає, що точки в кластері знаходяться близько до інших точок у тому ж кластері та далеко від точки інших кластерів. Візуальне представлення партитури силуету можна побачити на наступному малюнку.

Ми можемо періодично отримувати цю інформацію для моментальних знімків вбудовування як для вихідних довідкових даних, так і для підказок. Отримання цих даних дозволяє нам аналізувати потенційні сигнали дрейфу впровадження.
Виявлення дрейфу впровадження
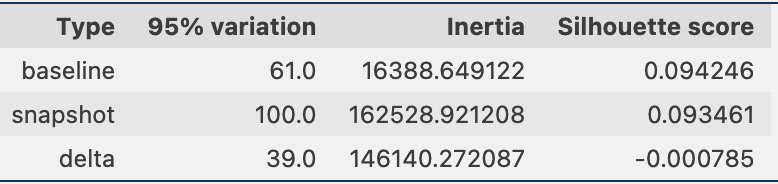
Періодично ми можемо порівнювати інформацію про кластеризацію за допомогою миттєвих знімків даних, які включають вбудовування довідкових даних і підказки. По-перше, ми можемо порівняти кількість вимірів, необхідних для пояснення 95% варіацій у вбудованих даних, інерції та оцінці силуету від кластеризації. Як ви можете бачити в наведеній нижче таблиці, порівняно з базовою лінією, останній знімок вбудовування вимагає ще 39 параметрів для пояснення дисперсії, що вказує на те, що наші дані є більш розпорошеними. Інерція зросла, вказуючи на те, що зразки знаходяться в сукупності далі від своїх центрів кластерів. Крім того, оцінка силуету знизилася, що вказує на те, що кластери не так чітко визначені. Для оперативних даних це може означати, що типи запитань, які надходять у систему, охоплюють більше тем.
Далі, на наступному малюнку ми можемо побачити, як частка зразків у кожному кластері змінювалася з часом. Це може показати нам, чи наші нові довідкові дані загалом подібні до попереднього набору чи охоплюють нові області.
Нарешті, ми можемо побачити, чи рухаються центри кластерів, що вказує на дрейф інформації в кластерах, як показано в наступній таблиці.

Охоплення довідкових даних для питань, що надходять
Ми також можемо оцінити, наскільки наші довідкові дані відповідають вхідним запитанням. Для цього ми призначаємо кожне вбудовування підказки кластеру довідкових даних. Ми обчислюємо відстань від кожної підказки до відповідного центру та розглядаємо середнє значення, медіану та стандартне відхилення цих відстаней. Ми можемо зберігати цю інформацію та бачити, як вона змінюється з часом.
На наступному малюнку показано приклад аналізу відстані між оперативним вбудовуванням і довідковими центрами обробки даних у часі.

Як бачите, середнє значення, медіана та стандартне відхилення статистичних відстаней між оперативними вбудовуваннями та довідковими центрами обробки даних зменшуються між початковою базовою лінією та останнім знімком. Хоча абсолютне значення відстані важко інтерпретувати, ми можемо використовувати тенденції, щоб визначити, чи покращується або погіршується семантичне перекриття між довідковими даними та вхідними запитаннями з часом.
Зразок заяви
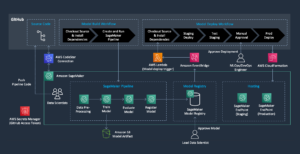
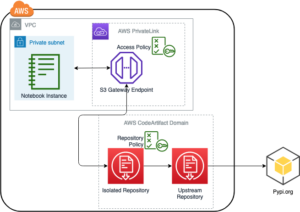
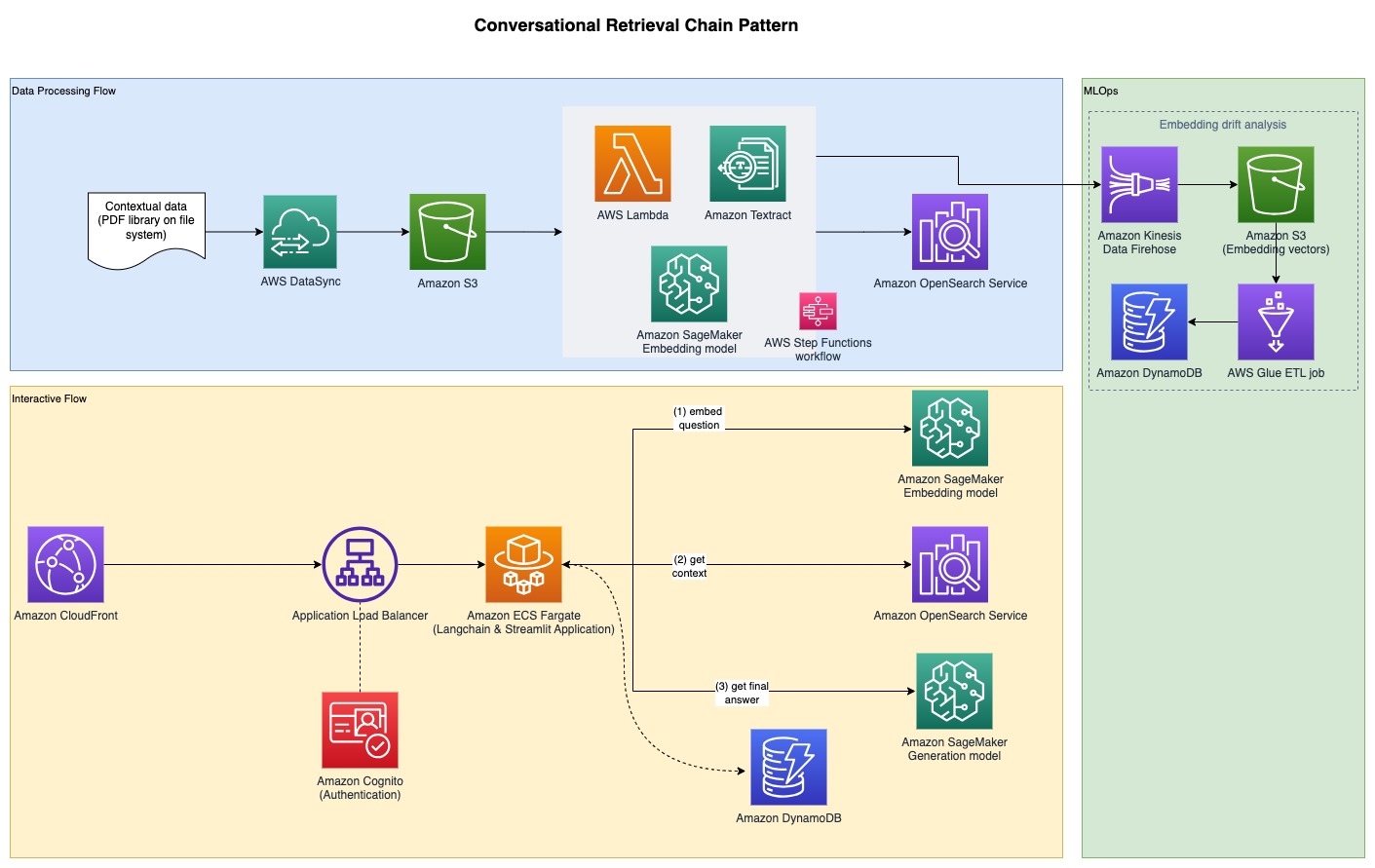
Щоб зібрати експериментальні результати, про які йдеться в попередньому розділі, ми створили зразок програми, яка реалізує шаблон RAG за допомогою моделей вбудовування та генерації, розгорнутих через SageMaker JumpStart і розміщених на Amazon SageMaker кінцеві точки в реальному часі.
Додаток має три основні компоненти:
- Ми використовуємо інтерактивний потік, який включає інтерфейс користувача для захоплення підказок у поєднанні з рівнем оркестровки RAG за допомогою LangChain.
- Потік обробки даних витягує дані з PDF-документів і створює вбудовування, які зберігаються в Служба Amazon OpenSearch. Ми також використовуємо їх у остаточному компоненті аналізу дрейфу вбудовування програми.
- Вбудовування зафіксовано в Служба простого зберігання Amazon (Amazon S3) через Amazon Kinesis Data Firehoseі запускаємо комбінацію Клей AWS завдання вилучення, трансформації та завантаження (ETL) і блокноти Jupyter для виконання аналізу вбудовування.
Наступна діаграма ілюструє наскрізну архітектуру.
Повний зразок коду доступний на GitHub. Наданий код доступний у двох різних шаблонах:
- Зразок програми з повним стеком із інтерфейсом Streamlit – Це надає наскрізну програму, включаючи інтерфейс користувача, який використовує Streamlit для захоплення підказок, у поєднанні з рівнем оркестровки RAG, використовуючи LangChain, що працює на Служба еластичних контейнерів Amazon (Amazon ECS) с AWS Fargate
- Серверний додаток – Для тих, хто не хоче розгортати повний стек додатків, ви можете додатково вибрати розгортання лише серверної частини Набір хмарних розробок AWS (AWS CDK), а потім використовуйте наданий блокнот Jupyter, щоб виконати оркестровку RAG за допомогою LangChain
Щоб створити надані шаблони, є кілька передумов, детально описаних у наступних розділах, починаючи з розгортання генеративних моделей і моделей вбудовування тексту, а потім переходячи до додаткових передумов.
Розгортайте моделі через SageMaker JumpStart
Обидва шаблони припускають розгортання моделі вбудовування та генеративної моделі. Для цього ви розгорнете дві моделі від SageMaker JumpStart. Перша модель, GPT-J 6B, використовується як модель вбудовування, а друга модель, Falcon-40b, використовується для генерації тексту.
Ви можете розгорнути кожну з цих моделей за допомогою SageMaker JumpStart з Консоль управління AWS, Студія Amazon SageMaker, або програмно. Для отримання додаткової інформації див Як використовувати моделі фундаменту JumpStart. Щоб спростити розгортання, ви можете використовувати надається зошит отримані з блокнотів, автоматично створених SageMaker JumpStart. Цей ноутбук отримує моделі з концентратора SageMaker JumpStart ML і розгортає їх у двох окремих кінцевих точках SageMaker у реальному часі.
Зразок блокнота також має розділ очищення. Поки що не запускайте цей розділ, оскільки він видалить щойно розгорнуті кінцеві точки. Ви завершите очищення в кінці проходження.
Після підтвердження успішного розгортання кінцевих точок ви готові до розгортання повного зразка програми. Однак, якщо ви більше зацікавлені в дослідженні лише серверної частини та блокнотів аналізу, ви можете додатково розгорнути лише це, про що йдеться в наступному розділі.
Варіант 1. Розгорніть лише серверну програму
Цей шаблон дозволяє розгортати лише серверне рішення та взаємодіяти з ним за допомогою блокнота Jupyter. Використовуйте цей шаблон, якщо не хочете створювати повний зовнішній інтерфейс.
Передумови
Ви повинні мати такі передумови:
- Розгорнуто кінцеву точку моделі SageMaker JumpStart – Розгорніть моделі на кінцевих точках SageMaker у реальному часі за допомогою SageMaker JumpStart, як описано раніше
- Параметри розгортання – Запишіть наступне:
- Назва кінцевої точки текстової моделі – Ім’я кінцевої точки моделі генерації тексту, розгорнутої за допомогою SageMaker JumpStart
- Назва кінцевої точки моделі вбудовування – Ім’я кінцевої точки моделі вбудовування, розгорнутої за допомогою SageMaker JumpStart
Розгорніть ресурси за допомогою AWS CDK
Використовуйте параметри розгортання, зазначені в попередньому розділі, щоб розгорнути стек AWS CDK. Додаткову інформацію про встановлення AWS CDK див Початок роботи з AWS CDK.
Переконайтеся, що Docker встановлено та запущено на робочій станції, яка використовуватиметься для розгортання AWS CDK. Відноситься до Отримати Docker для отримання додаткових вказівок.
Крім того, ви можете ввести контекстні значення у файл під назвою cdk.context.json в pattern1-rag/cdk каталог і запустити cdk deploy BackendStack --exclusively.
Розгортання роздрукує результати, деякі з яких знадобляться для запуску ноутбука. Перш ніж розпочати запитання та відповіді, вставте довідкові документи, як показано в наступному розділі.
Вставити довідкові документи
Для цього підходу RAG довідкові документи спочатку вбудовуються з моделлю вбудовування тексту та зберігаються у векторній базі даних. У цьому рішенні було створено конвеєр прийому, який приймає документи PDF.
An Обчислювальна хмара Amazon Elastic (Amazon EC2) створено екземпляр для прийому PDF-документа та Еластична файлова система Amazon Файлова система (Amazon EFS) встановлена на примірнику EC2 для збереження PDF-документів. Ан AWS DataSync завдання виконується щогодини, щоб отримати PDF-документи, знайдені в шляху файлової системи EFS, і завантажити їх у сегмент S3, щоб розпочати процес вбудовування тексту. Цей процес вбудовує довідкові документи та зберігає вбудовування в OpenSearch Service. Він також зберігає архів вбудовування у відро S3 через Kinesis Data Firehose для подальшого аналізу.
Щоб отримати довідкові документи, виконайте такі дії:
- Отримайте зразковий ідентифікатор екземпляра EC2, який було створено (див. вихідні дані AWS CDK
JumpHostId) і підключіться за допомогою Менеджер сеансів, здатність Менеджер систем AWS. Інструкції див Підключіться до свого екземпляра Linux за допомогою AWS Systems Manager Session Manager. - Перейдіть до каталогу
/mnt/efs/fs1, де змонтовано файлову систему EFS, і створіть папку під назвоюingest: - Додайте свої довідкові PDF-документи до
ingestкаталог.
Завдання DataSync налаштовано на завантаження всіх файлів, знайдених у цьому каталозі, до Amazon S3, щоб почати процес вбудовування.
Завдання DataSync виконується за погодинним розкладом; ви можете за бажанням запустити завдання вручну, щоб негайно розпочати процес вбудовування PDF-документів, які ви додали.
- Щоб запустити завдання, знайдіть ідентифікатор завдання у вихідних даних AWS CDK
DataSyncTaskIDта почати завдання із значеннями за замовчуванням.
Після того, як вбудовування створено, ви можете розпочати запитання та відповіді на RAG через блокнот Jupyter, як показано в наступному розділі.
Питання та відповіді з використанням зошита Jupyter
Виконайте такі дії:
- Отримайте назву екземпляра блокнота SageMaker із вихідних даних AWS CDK
NotebookInstanceNameі підключіться до JupyterLab з консолі SageMaker. - Перейдіть до каталогу
fmops/full-stack/pattern1-rag/notebooks/. - Відкрийте та запустіть блокнот
query-llm.ipynbв екземплярі блокнота для виконання запитань і відповідей за допомогою RAG.
Обов’язково використовуйте conda_python3 ядро для ноутбука.
Цей шаблон корисний для вивчення серверного рішення без необхідності надання додаткових передумов, необхідних для програми з повним стеком. У наступному розділі розглядається реалізація програми з повним стеком, включаючи компоненти інтерфейсу та серверної частини, щоб забезпечити інтерфейс користувача для взаємодії з вашою генеративною програмою ШІ.
Варіант 2. Розгорніть зразок програми з повним стеком із інтерфейсом Streamlit
Цей шаблон дозволяє розгортати рішення з інтерфейсом користувача для запитань і відповідей.
Передумови
Щоб розгорнути зразок програми, ви повинні мати такі передумови:
- Розгорнуто кінцеву точку моделі SageMaker JumpStart – Розгорніть моделі на кінцевих точках SageMaker у реальному часі за допомогою SageMaker JumpStart, як описано в попередньому розділі, використовуючи надані блокноти.
- Зона розміщення Amazon Route 53 - Створіть Амазонський маршрут 53 загальнодоступна зона використовувати для цього рішення. Ви також можете використовувати існуючу загальнодоступну зону Route 53, наприклад
example.com. - Сертифікат AWS Certificate Manager – Положення an Менеджер сертифікатів AWS (ACM) TLS-сертифікат для доменного імені зони розміщення Route 53 і відповідних субдоменів, таких як
example.comта*.example.comдля всіх субдоменів. Інструкції див Запит на державний сертифікат. Цей сертифікат використовується для налаштування HTTPS Amazon CloudFront і вихідний балансир навантаження. - Параметри розгортання – Запишіть наступне:
- Спеціальне доменне ім’я зовнішньої програми – Спеціальне доменне ім’я, яке використовується для доступу до зовнішнього зразка програми. Надане доменне ім’я використовується для створення DNS-запису Route 53, який вказує на зовнішній розподіл CloudFront; наприклад,
app.example.com. - Настроюване доменне ім’я джерела балансування навантаження – Спеціальне доменне ім’я, яке використовується для джерела балансування навантаження розподілу CloudFront. Надане доменне ім’я використовується для створення DNS-запису Route 53, що вказує на початковий балансувальник навантаження; наприклад,
app-lb.example.com. - Ідентифікатор зони розміщено на маршруті 53 – Ідентифікатор розміщеної зони Route 53 для розміщення наданих користувацьких доменних імен; наприклад,
ZXXXXXXXXYYYYYYYYY. - Назва розміщеної зони маршруту 53 – Ім’я розміщеної зони Route 53 для розміщення наданих користувацьких доменних імен; наприклад,
example.com. - ACM сертифікат ARN – ARN сертифіката ACM, який буде використовуватися з наданим нестандартним доменом.
- Назва кінцевої точки текстової моделі – Ім’я кінцевої точки моделі генерації тексту, розгорнутої за допомогою SageMaker JumpStart.
- Назва кінцевої точки моделі вбудовування – Ім’я кінцевої точки моделі вбудовування, розгорнутої за допомогою SageMaker JumpStart.
- Спеціальне доменне ім’я зовнішньої програми – Спеціальне доменне ім’я, яке використовується для доступу до зовнішнього зразка програми. Надане доменне ім’я використовується для створення DNS-запису Route 53, який вказує на зовнішній розподіл CloudFront; наприклад,
Розгорніть ресурси за допомогою AWS CDK
Використовуйте параметри розгортання, зазначені в попередніх вимогах, щоб розгорнути стек AWS CDK. Для отримання додаткової інформації див Початок роботи з AWS CDK.
Переконайтеся, що Docker встановлено та запущено на робочій станції, яка використовуватиметься для розгортання AWS CDK.
У попередньому коді -c представляє контекстне значення у формі обов’язкових передумов, наданих під час введення. Крім того, ви можете ввести контекстні значення у файл під назвою cdk.context.json в pattern1-rag/cdk каталог і запустити cdk deploy --all.
Зауважте, що ми вказуємо регіон у файлі bin/cdk.ts. Для налаштування журналів доступу до ALB потрібен указаний регіон. Ви можете змінити цей регіон перед розгортанням.
Розгортання роздрукує URL-адресу для доступу до програми Streamlit. Перш ніж ви зможете почати запитання та відповіді, вам потрібно вставити довідкові документи, як показано в наступному розділі.
Вставте довідкові документи
Для підходу RAG довідкові документи спочатку вбудовуються з моделлю вбудовування тексту та зберігаються у векторній базі даних. У цьому рішенні було створено конвеєр прийому, який приймає документи PDF.
Як ми обговорювали в першому варіанті розгортання, приклад екземпляра EC2 було створено для прийому документа PDF, а файлова система EFS монтується на екземплярі EC2 для збереження документів PDF. Завдання DataSync виконується щогодини, щоб отримати PDF-документи, знайдені на шляху файлової системи EFS, і завантажити їх у сегмент S3, щоб розпочати процес вбудовування тексту. Цей процес вбудовує довідкові документи та зберігає вбудовування в OpenSearch Service. Він також зберігає архів вбудовування у відро S3 через Kinesis Data Firehose для подальшого аналізу.
Щоб отримати довідкові документи, виконайте такі дії:
- Отримайте зразковий ідентифікатор екземпляра EC2, який було створено (див. вихідні дані AWS CDK
JumpHostId) і підключіться за допомогою менеджера сеансів. - Перейдіть до каталогу
/mnt/efs/fs1, де змонтовано файлову систему EFS, і створіть папку під назвоюingest: - Додайте свої довідкові PDF-документи до
ingestкаталог.
Завдання DataSync налаштовано на завантаження всіх файлів, знайдених у цьому каталозі, до Amazon S3, щоб почати процес вбудовування.
Завдання DataSync виконується за погодинним розкладом. За потреби ви можете запустити завдання вручну, щоб негайно розпочати процес вбудовування PDF-документів, які ви додали.
- Щоб запустити завдання, знайдіть ідентифікатор завдання у вихідних даних AWS CDK
DataSyncTaskIDта почати завдання із значеннями за замовчуванням.
Питання і відповідь
Після того, як довідкові документи вставлено, ви можете розпочати запитання та відповіді на RAG, відвідавши URL-адресу для доступу до програми Streamlit. Ан Амазонка Когніто використовується рівень автентифікації, тому для першого доступу до програми потрібно створити обліковий запис користувача в пулі користувачів Amazon Cognito, розгорнутому через AWS CDK (див. вихідні дані AWS CDK для імені пулу користувачів). Інструкції щодо створення користувача Amazon Cognito див Створення нового користувача в Консолі керування AWS.
Вставити аналіз дрейфу
У цьому розділі ми покажемо вам, як виконати дрейфовий аналіз, спочатку створивши базову лінію вбудованих довідкових даних і швидких вбудованих даних, а потім створивши знімок вбудованих даних з часом. Це дає вам змогу порівняти базові вбудовування з вбудовуваннями знімків.
Створіть базову лінію вбудовування для довідкових даних і підказки
Щоб створити базову лінію вбудовування довідкових даних, відкрийте консоль AWS Glue і виберіть завдання ETL embedding-drift-analysis. Встановіть параметри для завдання ETL таким чином і запустіть завдання:
- Установка
--job_typeдоBASELINE. - Установка
--out_tableдо Amazon DynamoDB таблиця для довідкових даних вбудовування. (Див. вихід AWS CDKDriftTableReferenceдля назви таблиці.) - Установка
--centroid_tableдо таблиці DynamoDB для довідкових даних центроїда. (Див. вихід AWS CDKCentroidTableReferenceдля назви таблиці.) - Установка
--data_pathдо відра S3 з префіксом; наприклад,s3:///embeddingarchive/. (Див. вихід AWS CDKBucketNameдля назви відра.)
Аналогічно, використовуючи роботу ETL embedding-drift-analysis, створіть базову лінію вбудовування підказок. Встановіть параметри для завдання ETL таким чином і запустіть завдання:
- Установка
--job_typeдоBASELINE - Установка
--out_tableдо таблиці DynamoDB для оперативного вбудовування даних. (Див. вихід AWS CDKDriftTablePromptsNameдля назви таблиці.) - Установка
--centroid_tableдо таблиці DynamoDB для оперативних даних центроїда. (Див. вихід AWS CDKCentroidTablePromptsдля назви таблиці.) - Установка
--data_pathдо відра S3 з префіксом; наприклад,s3:///promptarchive/. (Див. вихід AWS CDKBucketNameдля назви відра.)
Створіть знімок вбудовування для довідкових даних і підказки
Після введення додаткової інформації в службу OpenSearch запустіть завдання ETL embedding-drift-analysis ще раз, щоб зробити знімок вбудованих довідкових даних. Параметри будуть такими ж, як і завдання ETL, яке ви запустили для створення базової лінії вбудовування довідкових даних, як показано в попередньому розділі, за винятком налаштування --job_type параметр до SNAPSHOT.
Подібним чином, щоб зробити знімок вбудованих підказок, запустіть завдання ETL embedding-drift-analysis знову. Параметри будуть такими самими, як і завдання ETL, яке ви запустили для створення базової лінії вбудовування для підказок, як показано в попередньому розділі, за винятком налаштування --job_type параметр до SNAPSHOT.
Порівняйте базову лінію зі знімком
Щоб порівняти базову лінію вбудовування та знімок для довідкових даних і підказок, скористайтеся наданим блокнотом pattern1-rag/notebooks/drift-analysis.ipynb.
Щоб переглянути порівняння вбудовування довідкових даних або підказок, змініть змінні назви таблиці DynamoDB (tbl та c_tbl) у блокноті до відповідної таблиці DynamoDB для кожного запуску блокнота.
Змінна блокнота tbl має бути змінено на відповідну назву дрейфової таблиці. Нижче наведено приклад того, де налаштувати змінну в блокноті.

Назви таблиць можна отримати наступним чином:
- Для еталонних даних вбудовування отримайте ім’я дрейфової таблиці з вихідних даних AWS CDK
DriftTableReference - Для швидкого вбудовування даних отримайте ім’я дрейфової таблиці з вихідних даних AWS CDK
DriftTablePromptsName
Крім того, блокнот змінна c_tbl має бути змінено на відповідну назву таблиці центроїдів. Нижче наведено приклад того, де налаштувати змінну в блокноті.

Назви таблиць можна отримати наступним чином:
- Для еталонних даних вбудовування отримайте назву таблиці центроїда з вихідних даних AWS CDK
CentroidTableReference - Для швидкого вбудовування даних отримайте назву таблиці центроїда з виведення AWS CDK
CentroidTablePrompts
Проаналізуйте оперативну відстань від довідкових даних
Спочатку запустіть завдання AWS Glue embedding-distance-analysis. Це завдання з’ясовує, до якого кластера, з оцінки K-Means вбудованих довідкових даних, належить кожне підказка. Потім він обчислює середнє значення, медіану та стандартне відхилення відстані від кожної підказки до центру відповідного кластера.
Можна запускати зошит pattern1-rag/notebooks/distance-analysis.ipynb щоб побачити тенденції в показниках відстані з часом. Це дасть вам уявлення про загальну тенденцію розподілу швидких відстаней вбудовування.
Зошит pattern1-rag/notebooks/prompt-distance-outliers.ipynb це блокнот AWS Glue, який шукає викиди, що може допомогти вам визначити, чи отримуєте ви більше підказок, не пов’язаних із довідковими даними.
Відстежуйте показники подібності
Усі оцінки схожості з OpenSearch Service зареєстровані Amazon CloudWatch під rag простір імен. Приладова панель RAG_Scores показує середній бал і загальну кількість отриманих балів.
Прибирати
Щоб уникнути майбутніх витрат, видаліть усі створені вами ресурси.
Видаліть розгорнуті моделі SageMaker
Зверніться до розділу очищення надав приклад зошита щоб видалити розгорнуті моделі SageMaker JumpStart, або ви можете видалити моделі на консолі SageMaker.
Видаліть ресурси AWS CDK
Якщо ви ввели свої параметри в a cdk.context.json файл, очистіть таким чином:
Якщо ви ввели свої параметри в командному рядку та розгорнули лише серверну програму (бекенд-стек AWS CDK), очистіть так:
Якщо ви ввели свої параметри в командному рядку та розгорнули повне рішення (інтерфейсний і внутрішній стеки AWS CDK), очистіть наступним чином:
Висновок
У цій публікації ми надали робочий приклад програми, яка фіксує вектори вбудовування як для довідкових даних, так і для підказок у шаблоні RAG для генеративного ШІ. Ми показали, як виконати аналіз кластеризації, щоб визначити, чи змінюються довідкові дані чи дані підказки з часом, і наскільки добре довідкові дані охоплюють типи запитань, які задають користувачі. Якщо ви виявите дрейф, це може надати сигнал про те, що середовище змінилося, і ваша модель отримує нові вхідні дані, для обробки яких вона може бути неоптимізованою. Це дозволяє проводити проактивну оцінку поточної моделі щодо змін вхідних даних.
Про авторів
 Абдуллахі Олаойє є старшим архітектором рішень в Amazon Web Services (AWS). Абдуллахі має ступінь магістра з комп’ютерних мереж Університету штату Вічіта та є автором публікацій, який обіймав посади в різних технологічних сферах, таких як DevOps, модернізація інфраструктури та ШІ. Зараз він зосереджений на Generative AI і відіграє ключову роль у допомозі підприємствам розробляти та створювати передові рішення на основі Generative AI. За межами сфери технологій він знаходить радість у мистецтві дослідження. Коли він не розробляє рішення штучного інтелекту, він із задоволенням подорожує з родиною, щоб досліджувати нові місця.
Абдуллахі Олаойє є старшим архітектором рішень в Amazon Web Services (AWS). Абдуллахі має ступінь магістра з комп’ютерних мереж Університету штату Вічіта та є автором публікацій, який обіймав посади в різних технологічних сферах, таких як DevOps, модернізація інфраструктури та ШІ. Зараз він зосереджений на Generative AI і відіграє ключову роль у допомозі підприємствам розробляти та створювати передові рішення на основі Generative AI. За межами сфери технологій він знаходить радість у мистецтві дослідження. Коли він не розробляє рішення штучного інтелекту, він із задоволенням подорожує з родиною, щоб досліджувати нові місця.
 Ренді ДеФо є старшим головним архітектором рішень в AWS. Він має ступінь MSEE Мічиганського університету, де працював над комп’ютерним зором для автономних транспортних засобів. Він також має ступінь магістра ділового адміністрування в Університеті штату Колорадо. Ренді обіймав різні посади в технологічному просторі, починаючи від розробки програмного забезпечення та закінчуючи управлінням продуктами. In увійшов у сферу великих даних у 2013 році та продовжує досліджувати цю сферу. Він активно працює над проектами у сфері машинного навчання та виступає з доповідями на численних конференціях, зокрема Strata та GlueCon.
Ренді ДеФо є старшим головним архітектором рішень в AWS. Він має ступінь MSEE Мічиганського університету, де працював над комп’ютерним зором для автономних транспортних засобів. Він також має ступінь магістра ділового адміністрування в Університеті штату Колорадо. Ренді обіймав різні посади в технологічному просторі, починаючи від розробки програмного забезпечення та закінчуючи управлінням продуктами. In увійшов у сферу великих даних у 2013 році та продовжує досліджувати цю сферу. Він активно працює над проектами у сфері машинного навчання та виступає з доповідями на численних конференціях, зокрема Strata та GlueCon.
 Шелбі Айгенброде є головним архітектором рішень спеціалістів із штучного інтелекту та машинного навчання в Amazon Web Services (AWS). Вона працює в технологіях протягом 24 років, охоплюючи різні галузі, технології та ролі. Наразі вона зосереджується на поєднанні свого досвіду DevOps і ML у сфері MLOps, щоб допомогти клієнтам доставляти та керувати робочими навантаженнями ML у масштабі. Маючи понад 35 патентів, наданих у різних технологічних областях, вона має пристрасть до постійних інновацій та використання даних для досягнення результатів бізнесу. Шелбі є співавтором і викладачем спеціалізації з практичних наук про дані на Coursera. Вона також є співдиректором відділу Women In Big Data (WiBD) у Денвері. У вільний час вона любить проводити час з родиною, друзями та надмірно активними собаками.
Шелбі Айгенброде є головним архітектором рішень спеціалістів із штучного інтелекту та машинного навчання в Amazon Web Services (AWS). Вона працює в технологіях протягом 24 років, охоплюючи різні галузі, технології та ролі. Наразі вона зосереджується на поєднанні свого досвіду DevOps і ML у сфері MLOps, щоб допомогти клієнтам доставляти та керувати робочими навантаженнями ML у масштабі. Маючи понад 35 патентів, наданих у різних технологічних областях, вона має пристрасть до постійних інновацій та використання даних для досягнення результатів бізнесу. Шелбі є співавтором і викладачем спеціалізації з практичних наук про дані на Coursera. Вона також є співдиректором відділу Women In Big Data (WiBD) у Денвері. У вільний час вона любить проводити час з родиною, друзями та надмірно активними собаками.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/monitor-embedding-drift-for-llms-deployed-from-amazon-sagemaker-jumpstart/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 100
- 2%
- 2013
- 24
- 35%
- 39
- 4
- 53
- 62
- 7
- 9
- 90
- 95%
- a
- Здатний
- МЕНЮ
- абсолют
- доступ
- рахунки
- ACM
- через
- активно
- доданий
- доповнення
- Додатковий
- Додаткова інформація
- Додатково
- знову
- проти
- сукупність
- AI
- Вирівнює
- ВСІ
- Дозволити
- дозволяє
- Також
- хоча
- Amazon
- Амазонка Когніто
- Amazon EC2
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- Веб-служби Amazon (AWS)
- an
- аналіз
- аналізувати
- Аналізуючи
- та
- відповідь
- відповідь
- все
- застосовно
- додаток
- підхід
- відповідний
- архітектура
- архів
- ЕСТЬ
- ПЛОЩА
- області
- Art
- статті
- AS
- запитати
- запитувач
- допомагати
- припустити
- At
- збільшення
- збільшено
- Authentication
- автор
- автоматично
- автономний
- автономні транспортні засоби
- доступний
- середній
- уникнути
- геть
- AWS
- Клей AWS
- Backend
- фон
- свінг
- заснований
- Базова лінія
- BE
- оскільки
- було
- перед тим
- буття
- належить
- Краще
- між
- За
- Великий
- Великий даних
- органів
- обидва
- широко
- будувати
- побудований
- бізнес
- by
- обчислювати
- обчислює
- call
- званий
- CAN
- можливості
- захоплення
- захоплений
- захвати
- захопивши
- випадок
- CD
- Центр
- Центри
- сертифікат
- зміна
- змінилися
- Зміни
- заміна
- Глава
- вантажі
- чіп
- шоколад
- Вибирати
- очистити
- близько
- ближче
- хмара
- кластер
- Кластеризація
- код
- Колорадо
- поєднання
- комбінований
- об'єднання
- майбутній
- компактний
- порівняти
- порівняний
- порівняння
- повний
- компонент
- Компоненти
- обчислення
- комп'ютер
- Комп'ютерне бачення
- поняття
- конференції
- налаштувати
- конфігурування
- З'єднуватися
- міркування
- узгодженість
- Консоль
- Контейнер
- зміст
- контекст
- триває
- безперервний
- перероблений
- печиво
- Core
- Відповідний
- Coursera
- охоплення
- покритий
- покриття
- охоплює
- створювати
- створений
- створює
- створення
- Поточний
- В даний час
- виготовлений на замовлення
- Клієнти
- передовий
- приладова панель
- дані
- центрів обробки даних
- обробка даних
- наука про дані
- Database
- зменшується
- за замовчуванням
- певний
- видаляти
- доставляти
- Денвер
- розгортання
- розгорнути
- розгортання
- розгортання
- розгортає
- Отриманий
- знищити
- докладно
- виявляти
- Виявлення
- Визначати
- розробка
- відхилення
- DevOps
- схема
- різний
- важкий
- Розмір
- розміри
- обговорювалися
- розійшлися
- відстань
- Віддалений
- розподіл
- DNS
- do
- Docker
- документ
- документація
- собаки
- домен
- Доменне ім'я
- ДОМЕННІ ІМЕНА
- домени
- Не знаю
- вниз
- управляти
- кожен
- Вставляти
- вбудований
- вбудовування
- кінець
- кінець в кінець
- Кінцева точка
- кінцеві точки
- Машинобудування
- Що натомість? Створіть віртуальну версію себе у
- увійшов
- підприємств
- Навколишнє середовище
- Ефір (ETH)
- оцінювати
- оцінка
- Кожен
- приклад
- Приклади
- виняток
- існуючий
- експериментальний
- Пояснювати
- дослідження
- дослідити
- Дослідження
- зовнішній
- витяг
- Виписки
- сім'я
- далеко
- Рисунок
- філе
- Файли
- остаточний
- в кінці кінців
- знайти
- знахідки
- Перший
- плаваючий
- потік
- увагу
- фокусування
- після
- слідує
- для
- форма
- знайдений
- фонд
- друзі
- від
- Frontend
- Повний
- майбутнє
- збирати
- Загальне
- породжує
- покоління
- генеративний
- Генеративний ШІ
- генеративна модель
- отримати
- отримання
- Давати
- Go
- пішов
- надається
- Group
- керівництво
- обробляти
- Мати
- he
- Герой
- допомога
- її
- вище
- його
- тримає
- господар
- відбувся
- годину
- Як
- How To
- Однак
- HTML
- HTTP
- HTTPS
- Концентратор
- ID
- ідентифікувати
- if
- ілюструє
- негайно
- реалізація
- implements
- важливо
- in
- включати
- includes
- У тому числі
- Вхідний
- вказувати
- вказуючи
- промисловості
- інерція
- інформація
- Інфраструктура
- початковий
- інновація
- вхід
- витрати
- розуміння
- установка
- екземпляр
- інструкції
- взаємодіяти
- взаємодіючих
- інтерактивний
- зацікавлений
- інтерфейс
- в
- IT
- ЙОГО
- робота
- Джобс
- радість
- JPG
- Jupyter Notebook
- просто
- ключ
- Kinesis Data Firehose
- знання
- мова
- великий
- пізніше
- останній
- шар
- УЧИТЬСЯ
- вивчення
- дозволяє
- бібліотека
- Сподобалося
- Лінія
- Linux
- llm
- загрузка
- розташування
- увійшли
- подивитися
- ВИГЛЯДИ
- знизити
- машина
- навчання за допомогою машини
- зробити
- управляти
- управління
- менеджер
- вручну
- Може..
- MBA
- значити
- засоби
- вимір
- заходи
- Метрика
- Мічиган
- може бути
- ML
- MLOps
- модель
- Моделі
- модернізація
- монітор
- більше
- найбільш
- переміщення
- множинний
- повинен
- ім'я
- Імена
- Природний
- Природна мова
- Обробка природних мов
- Необхідність
- необхідний
- нужденних
- мережа
- Нові
- новіший
- наступний
- nlp
- ноутбук
- ноутбуки
- зазначив,
- номер
- номера
- численний
- of
- часто
- on
- тільки
- відкрити
- оптимізований
- варіант
- or
- оркестровка
- порядок
- Походження
- Інше
- наші
- з
- Результати
- викладені
- вихід
- виходи
- над
- загальний
- перекриття
- власний
- параметр
- параметри
- приватність
- пристрасть
- Патенти
- шлях
- Викрійки
- моделі
- виконувати
- виконанні
- частин
- трубопровід
- місця
- plato
- Інформація про дані Платона
- PlatoData
- відіграє
- точка
- точок
- басейн
- позиції
- це можливо
- пошта
- потенціал
- Харчування
- Практичний
- попередній
- передумови
- представлений
- заповідників
- консервування
- попередній
- раніше
- Головний
- друк
- Проактивний
- процес
- обробка
- Product
- Управління продуктом
- проектів
- підказок
- частка
- забезпечувати
- за умови
- забезпечує
- забезпечення
- громадськість
- опублікований
- Тягне
- питання
- питань
- ганчіркою
- діапазони
- ранжування
- готовий
- реального часу
- царство
- рецепт
- запис
- зменшити
- скорочення
- послатися
- посилання
- регіон
- пов'язаний
- щодо
- доречний
- представляти
- подання
- представляє
- вимагається
- Вимагається
- ресурси
- відповідь
- результати
- пошук
- Роль
- ролі
- Маршрут
- прогін
- біг
- пробіжки
- мудрець
- то ж
- зберегти
- шкала
- розклад
- наука
- рахунок
- безліч
- Пошук
- пошук
- другий
- розділ
- розділам
- побачити
- бачив
- вибрати
- смисловий
- старший
- сенс
- посланий
- окремий
- обслуговування
- Послуги
- Сесія
- комплект
- установка
- кілька
- вона
- Повинен
- Показувати
- показав
- показаний
- Шоу
- Сигнал
- сигнали
- аналогічний
- простий
- спростити
- Розмір
- Знімок
- So
- Софтвер
- розробка програмного забезпечення
- рішення
- Рішення
- деякі
- Source
- Джерела
- Простір
- напруга
- спеціаліст
- зазначений
- витрачати
- в квадраті
- стек
- Стеки
- standard
- старт
- почалася
- Починаючи
- стан
- статистика
- заходи
- зберігання
- зберігати
- зберігати
- успішний
- такі
- сума
- Переконайтеся
- система
- Systems
- таблиця
- Приймати
- Завдання
- техніка
- Технології
- Технологія
- текст
- генерація тексту
- Що
- Команда
- інформація
- Джерело
- їх
- Їх
- потім
- Там.
- Ці
- це
- ті
- три
- через
- час
- TLS
- до
- разом
- теми
- Усього:
- Перетворення
- Подорож
- Trend
- Тенденції
- намагається
- намагатися
- два
- Типи
- при
- університет
- Мічиганський університет
- URL
- us
- використання
- використовуваний
- корисний
- користувач
- Інтерфейс користувача
- користувачі
- використання
- перевірка достовірності
- значення
- Цінності
- змінна
- змінні
- різноманітність
- різний
- вектор
- вектори
- Транспортні засоби
- через
- бачення
- візуальний
- покрокове керівництво
- хотіти
- було
- шлях..
- we
- Web
- веб-сервіси
- ДОБРЕ
- коли
- Чи
- який
- в той час як
- волі
- з
- в
- без
- жінки
- Work
- працював
- робочий
- робоча станція
- гірше
- б
- років
- ще
- ви
- вашу
- зефірнет
- зона