Незважаючи на, здавалося б, нестримне впровадження LLM у галузях, вони є одним із компонентів ширшої технологічної екосистеми, яка живить нову хвилю ШІ. У багатьох випадках використання штучного інтелекту для розмови потрібні такі LLM, як Llama 2, Flan T5 і Bloom, щоб відповідати на запити користувачів. Ці моделі покладаються на параметричні знання, щоб відповісти на запитання. Модель вивчає ці знання під час навчання та кодує їх у параметрах моделі. Щоб оновити ці знання, ми повинні перепідготовити LLM, що займає багато часу та грошей.
На щастя, ми також можемо використовувати знання джерел, щоб інформувати наших LLM. Вихідні знання - це інформація, яка надходить до LLM через підказку введення. Одним із популярних підходів до надання джерельних знань є Retrieval Augmented Generation (RAG). Використовуючи RAG, ми отримуємо відповідну інформацію із зовнішнього джерела даних і передаємо цю інформацію в LLM.
У цій публікації в блозі ми розглянемо, як розгортати LLM, наприклад Llama-2, за допомогою Amazon Sagemaker JumpStart і підтримувати наші LLM актуальною інформацією через Retrieval Augmented Generation (RAG) за допомогою векторної бази даних Pinecone, щоб запобігти галюцинаціям ШІ. .
Retrieval Augmented Generation (RAG) в Amazon SageMaker
Pinecone оброблятиме пошуковий компонент RAG, але вам потрібні ще два критичні компоненти: десь для запуску висновку LLM і десь для запуску моделі вбудовування.
Amazon SageMaker Studio — це інтегроване середовище розробки (IDE), яке надає єдиний візуальний веб-інтерфейс, де ви можете отримати доступ до спеціально створених інструментів для виконання всіх розробок машинного навчання (ML). Він забезпечує SageMaker JumpStart, який є центром моделей, де користувачі можуть знаходити, переглядати та запускати певну модель у своєму обліковому записі SageMaker. Він надає попередньо підготовлені, загальнодоступні та пропрієтарні моделі для широкого діапазону типів проблем, у тому числі основні моделі.
Amazon SageMaker Studio забезпечує ідеальне середовище для розробки конвеєрів LLM із підтримкою RAG. Спочатку за допомогою консолі AWS перейдіть до Amazon SageMaker, створіть домен SageMaker Studio та відкрийте блокнот Jupyter Studio.
Передумови
Виконайте такі необхідні кроки:
- Налаштуйте Amazon SageMaker Studio.
- Підключення до домену Amazon SageMaker.
- Підпишіться на безкоштовну векторну базу даних Pinecone.
- Необхідні бібліотеки: SageMaker Python SDK, клієнт Pinecone
Покрокове керівництво рішенням
Використовуючи блокнот SageMaker Studio, нам спочатку потрібно встановити необхідні бібліотеки:
Розгортання LLM
У цій публікації ми обговорюємо два підходи до розгортання LLM. Перший - через HuggingFaceModel об'єкт. Ви можете використовувати це під час розгортання LLM (і вбудовуваних моделей) безпосередньо з центру моделі Hugging Face.
Наприклад, ви можете створити розгорнуту конфігурацію для google/flan-t5-xl моделі, як показано на наступному знімку екрана:
Під час розгортання моделей безпосередньо з Hugging Face ініціалізуйте my_model_configuration з наступним:
- An
envconfig повідомляє нам, яку модель ми хочемо використовувати та для якого завдання. - Наше виконання SageMaker
roleдає нам дозвіл на розгортання нашої моделі. - An
image_uriце конфігурація зображення, спеціально призначена для розгортання LLM з Hugging Face.
Крім того, SageMaker має набір моделей, безпосередньо сумісних із простішими JumpStartModel об'єкт. Багато популярних LLM, як-от Llama 2, підтримуються цією моделлю, яку можна ініціалізувати, як показано на наступному знімку екрана:
Для обох версій my_model, розгорніть їх, як показано на наступному знімку екрана:
З нашою ініціалізованою кінцевою точкою LLM ви можете почати надсилати запити. Формат наших запитів може відрізнятися (зокрема, між розмовними та нерозмовними LLM), але процес загалом однаковий. Для моделі Hugging Face виконайте наступне:
Ви можете знайти рішення в GitHub сховище.
Згенерована відповідь, яку ми тут отримуємо, не має особливого сенсу — це галюцинація.
Надання додаткового контексту LLM
Llama 2 намагається відповісти на наше запитання виключно на основі внутрішніх параметричних знань. Очевидно, що параметри моделі не зберігають відомості про те, які екземпляри ми можемо за допомогою керованого точкового навчання в SageMaker.
Щоб правильно відповісти на це питання, ми повинні скористатися джерельними знаннями. Тобто ми надаємо додаткову інформацію LLM через підказку. Давайте додамо цю інформацію безпосередньо як додатковий контекст для моделі.
Тепер ми бачимо правильну відповідь на запитання; це було легко! Однак навряд чи користувач буде вставляти контексти у свої підказки, він би вже знав відповідь на своє запитання.
Замість того, щоб вручну вставляти єдиний контекст, автоматично ідентифікуйте відповідну інформацію з більшої бази даних інформації. Для цього вам знадобиться Retrieval Augmented Generation.
Доповнена генерація пошуку
За допомогою Retrieval Augmented Generation ви можете закодувати базу даних інформації у векторний простір, де близькість між векторами представляє їх релевантність/семантичну подібність. Використовуючи цей векторний простір як базу знань, ви можете перетворити новий запит користувача, закодувати його в той самий векторний простір і отримати найбільш релевантні записи, проіндексовані раніше.
Після отримання цих відповідних записів виберіть декілька з них і включіть їх у підказку LLM як додатковий контекст, забезпечуючи LLM дуже релевантними джерельними знаннями. Це двоетапний процес, де:
- Індексація заповнює векторний індекс інформацією з набору даних.
- Отримання відбувається під час запиту, де ми отримуємо відповідну інформацію з векторного індексу.
Обидва кроки вимагають моделі вбудовування, щоб перевести наш зрозумілий людині простий текст у семантичний векторний простір. Використовуйте високоефективний трансформатор речень MiniLM від Hugging Face, як показано на наступному знімку екрана. Ця модель не є LLM і тому не ініціалізується так само, як наша модель Llama 2.
У hub_config, вкажіть ідентифікатор моделі, як показано на знімку екрана вище, але для цього завдання використовуйте функцію вилучення, оскільки ми генеруємо векторні вбудовування, а не текст, як наш LLM. Після цього ініціалізуйте конфігурацію моделі за допомогою HuggingFaceModel як і раніше, але цього разу без образу LLM і з деякими параметрами версії.
Ви можете знову розгорнути модель за допомогою deploy, використовуючи менший (тільки ЦП) екземпляр ml.t2.large. Модель MiniLM є крихітною, тому їй не потрібно багато пам’яті та не потрібен графічний процесор, оскільки вона може швидко створювати вбудовування навіть на центральному процесорі. Якщо потрібно, ви можете запустити модель швидше на GPU.
Щоб створити вбудовування, використовуйте predict і передати список контекстів для кодування через inputs ключ, як показано:
Передаються два контексти введення, повертаючи два вбудованих вектора контексту, як показано:
len(out)
2
Розмірність вбудовування моделі MiniLM становить 384 це означає, що кожен вектор, що вбудовує вихідні дані MiniLM, повинен мати розмірність 384. Однак, дивлячись на довжину наших вставок, ви побачите наступне:
len(out[0]), len(out[1])
(8, 8)
Два списки містять по вісім пунктів. MiniLM спочатку обробляє текст на етапі токенізації. Ця токенізація перетворює наш зрозумілий людині звичайний текст у список ідентифікаторів токенів, які можна прочитати моделлю. У вихідних функціях моделі ви можете побачити вбудовування на рівні маркерів. одне з цих вкладень показує очікувану розмірність 384 як показано:
len(out[0][0])
384
Перетворіть ці вбудовування на рівні маркерів у вбудовування на рівні документа, використовуючи середні значення для кожного векторного виміру, як показано на наступній ілюстрації.
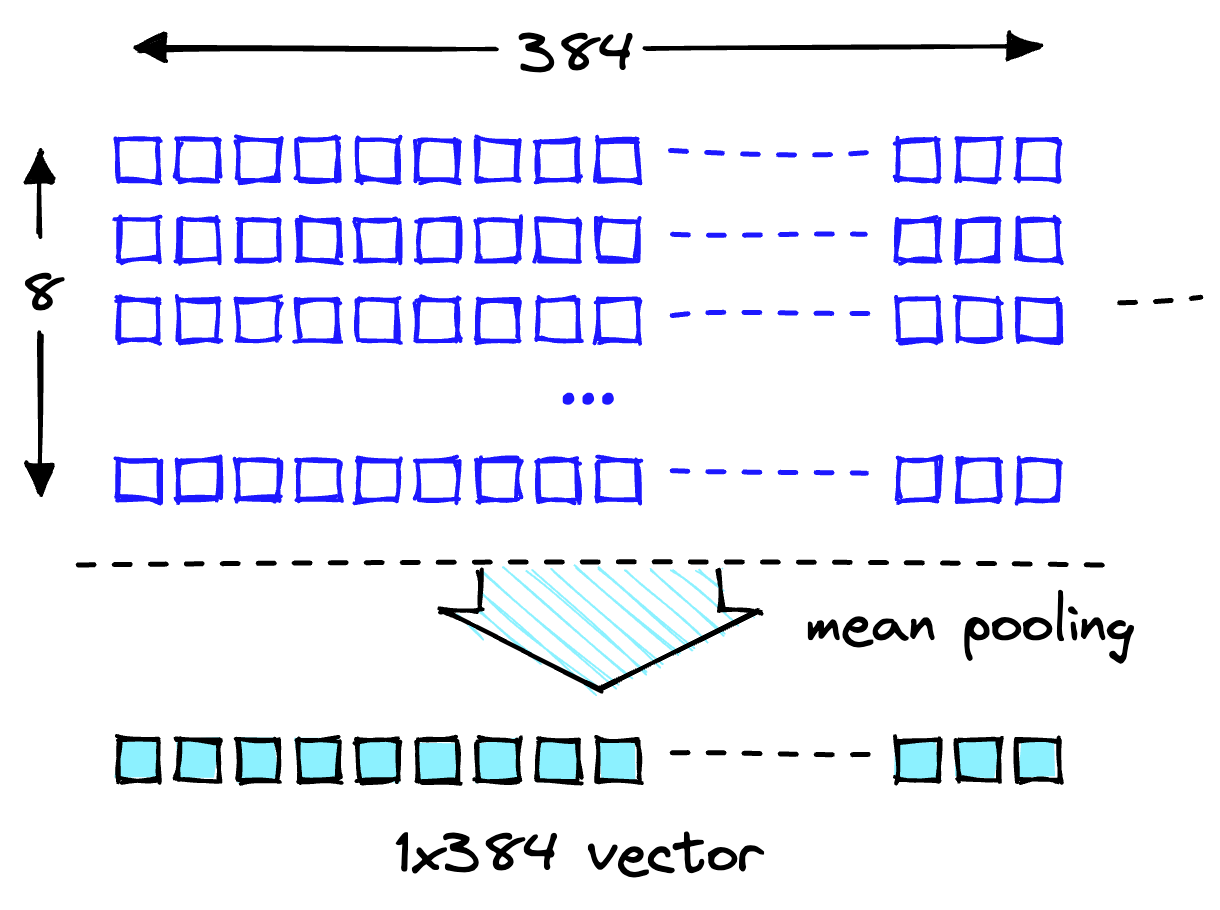
Операція об’єднання середніх для отримання одного 384-вимірного вектора.
З двома 384-вимірними векторними вкладеннями, по одному для кожного вхідного тексту. Щоб полегшити наше життя, об’єднайте процес кодування в одну функцію, як показано на наступному знімку екрана:
Завантаження набору даних
Завантажте розділ поширених запитань Amazon SageMaker як базу знань, щоб отримати дані, які містять стовпці запитань і відповідей.

Завантажте поширені запитання про Amazon SageMaker
Виконуючи пошук, шукайте лише відповіді, щоб ви могли опустити стовпець запитання. Подробиці дивіться в блокноті.
Наш набір даних і конвеєр для вбудовування готові. Тепер все, що нам потрібно, це десь зберігати ці вбудовування.
Індексація
Векторна база даних Pinecone зберігає вбудовані вектори та здійснює ефективний пошук у масштабі. Для створення бази даних вам знадобиться безкоштовний ключ API від Pinecone.
Після підключення до векторної бази даних Pinecone створіть єдиний векторний індекс (подібний до таблиці в традиційних БД). Назвіть індекс retrieval-augmentation-aws і вирівняйте індекс dimension та metric параметри з тими, що вимагаються моделлю вбудовування (у цьому випадку MiniLM).
Щоб почати вставляти дані, виконайте наступне:
Ви можете розпочати запит до індексу з запитання з попередньої публікації.
Наведені вище результати показують, що ми повертаємо релевантні контексти, щоб допомогти нам відповісти на наше запитання. Оскільки ми top_k = 1, index.query повернув верхній результат поряд із метаданими, які читаються Managed Spot Training can be used with all instances supported in Amazon.
Доповнення підказки
Використовуйте отримані контексти, щоб розширити підказку та визначити максимальну кількість контексту для передачі в LLM. Використовувати 1000 обмеження символів, щоб ітеративно додавати кожен повернутий контекст до підказки, доки ви не перевищите довжину вмісту.
Доповнення підказки
Годуйте context_str у підказку LLM, як показано на наступному знімку екрана:
[Введення]: які екземпляри я можу використовувати з керованим точковим навчанням у SageMaker? [Вихід]: виходячи з наданого контексту, ви можете використовувати кероване точкове навчання з усіма екземплярами, які підтримуються в Amazon SageMaker. Отже, відповідь така: усі екземпляри підтримуються в Amazon SageMaker.
Логіка працює, тому об’єднайте її в одну функцію, щоб усе було чисто.
Тепер ви можете ставити такі запитання, як показано нижче:
Прибирати
Щоб уникнути небажаних витрат, видаліть модель і кінцеву точку.
Висновок
У цій публікації ми познайомили вас із RAG із відкритим доступом до LLM на SageMaker. Ми також показали, як розгортати моделі Amazon SageMaker Jumpstart за допомогою Llama 2, LLM Hugging Face за допомогою Flan T5 і вбудовувати моделі за допомогою MiniLM.
Ми реалізували повний наскрізний конвеєр RAG, використовуючи наші моделі відкритого доступу та векторний індекс Pinecone. Використовуючи це, ми показали, як звести до мінімуму галюцинації та підтримувати знання LLM в актуальному стані, і в кінцевому підсумку підвищити користувацький досвід і довіру до наших систем.
Щоб запустити цей приклад самостійно, клонуйте це сховище GitHub і виконайте попередні кроки за допомогою Блокнот із відповідями на запитання на GitHub.
Про авторів
 Ведант джайн є старшим спеціалістом зі штучного інтелекту/ML, який працює над стратегічними ініціативами Generative AI. До того як приєднатися до AWS, Vedant обіймав посади зі спеціальності ML/Data Science в різних компаніях, таких як Databricks, Hortonworks (нині Cloudera) і JP Morgan Chase. Окрім роботи, Ведант захоплюється створенням музики, скелелазінням, використанням науки для змістовного життя та вивченням кухонь усього світу.
Ведант джайн є старшим спеціалістом зі штучного інтелекту/ML, який працює над стратегічними ініціативами Generative AI. До того як приєднатися до AWS, Vedant обіймав посади зі спеціальності ML/Data Science в різних компаніях, таких як Databricks, Hortonworks (нині Cloudera) і JP Morgan Chase. Окрім роботи, Ведант захоплюється створенням музики, скелелазінням, використанням науки для змістовного життя та вивченням кухонь усього світу.
 Джеймс Бріггс є штатним захисником розробників у Pinecone, який спеціалізується на векторному пошуку та AI/ML. Він допомагає розробникам і компаніям розробляти власні рішення GenAI за допомогою онлайн-навчання. До Pinecone Джеймс працював над штучним інтелектом для невеликих технологічних стартапів і відомих фінансових корпорацій. Поза роботою Джеймс має пристрасть до подорожей і захоплення новими пригодами, починаючи від серфінгу та підводного плавання до тайського боксу та бій-джиу.
Джеймс Бріггс є штатним захисником розробників у Pinecone, який спеціалізується на векторному пошуку та AI/ML. Він допомагає розробникам і компаніям розробляти власні рішення GenAI за допомогою онлайн-навчання. До Pinecone Джеймс працював над штучним інтелектом для невеликих технологічних стартапів і відомих фінансових корпорацій. Поза роботою Джеймс має пристрасть до подорожей і захоплення новими пригодами, починаючи від серфінгу та підводного плавання до тайського боксу та бій-джиу.
 Сінь Хуан є старшим прикладним науковим співробітником Amazon SageMaker JumpStart і вбудованих алгоритмів Amazon SageMaker. Він зосереджується на розробці масштабованих алгоритмів машинного навчання. Його дослідницькі інтереси стосуються обробки природної мови, пояснюваного глибокого навчання на табличних даних і надійного аналізу непараметричної просторово-часової кластеризації. Він опублікував багато статей на конференціях ACL, ICDM, KDD і Королівського статистичного товариства: серія A.
Сінь Хуан є старшим прикладним науковим співробітником Amazon SageMaker JumpStart і вбудованих алгоритмів Amazon SageMaker. Він зосереджується на розробці масштабованих алгоритмів машинного навчання. Його дослідницькі інтереси стосуються обробки природної мови, пояснюваного глибокого навчання на табличних даних і надійного аналізу непараметричної просторово-часової кластеризації. Він опублікував багато статей на конференціях ACL, ICDM, KDD і Королівського статистичного товариства: серія A.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/mitigate-hallucinations-through-retrieval-augmented-generation-using-pinecone-vector-database-llama-2-from-amazon-sagemaker-jumpstart/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 16
- 17
- 19
- 23
- 32
- 7
- 8
- 9
- 90
- a
- МЕНЮ
- вище
- доступ
- За
- рахунки
- через
- додавати
- Додатковий
- Додаткова інформація
- Прийняття
- пригод
- адвокат
- знову
- AI
- випадки використання ai
- AI / ML
- алгоритми
- вирівнювати
- ВСІ
- по
- вже
- Також
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Студія Amazon SageMaker
- Amazon Web Services
- кількість
- an
- аналіз
- та
- відповідь
- Відповіді
- будь-який
- API
- додаток
- прикладної
- підхід
- підходи
- ЕСТЬ
- ПЛОЩА
- навколо
- AS
- запитати
- At
- Спроби
- збільшення
- збільшено
- автоматичний
- автоматично
- доступний
- AWS
- база
- заснований
- BE
- оскільки
- перед тим
- починати
- між
- Блог
- Цвісти
- обидва
- ширше
- будувати
- вбудований
- підприємства
- але
- by
- CAN
- захоплення
- випадок
- випадків
- символи
- вантажі
- погоня
- очистити
- очевидно
- сходження
- Cloudera
- Кластеризація
- Колонка
- Колони
- Компанії
- сумісний
- повний
- компонент
- Компоненти
- конференції
- підключений
- Консоль
- містити
- містить
- зміст
- контекст
- контексти
- діалоговий
- розмовний ШІ
- конвертувати
- корпорації
- виправити
- правильно
- центральний процесор
- створювати
- критичний
- В даний час
- дані
- Database
- Збір даних
- Дата
- DBS
- вирішувати
- глибокий
- глибоке навчання
- розгортання
- розгортання
- Розробник
- розробників
- розвивається
- розробка
- Розмір
- безпосередньо
- обговорювати
- do
- робить
- байдуже
- Ні
- домен
- Дон
- Падіння
- під час
- кожен
- Раніше
- легше
- екосистема
- Освіта
- ефективний
- продуктивно
- вбудовування
- обіймаючи
- кодування
- кінець
- кінець в кінець
- Кінцева точка
- підвищувати
- Навколишнє середовище
- встановлений
- Ефір (ETH)
- Навіть
- приклад
- перевищувати
- виконання
- очікуваний
- досвід
- дослідити
- Дослідження
- обширний
- зовнішній
- витяг
- Face
- швидше
- риси
- Fed
- кілька
- фінансування
- знайти
- закінчення
- Перший
- Поплавок
- фокусується
- після
- для
- формат
- фонд
- Безкоштовна
- від
- функція
- в цілому
- генерується
- породжує
- покоління
- генеративний
- Генеративний ШІ
- отримати
- GitHub
- Давати
- даний
- дає
- Go
- йде
- GPU
- Гід
- обробляти
- відбувається
- Мати
- he
- Герой
- допомога
- тут
- дуже
- його
- Як
- How To
- Однак
- HTTPS
- хуан
- Концентратор
- HuggingFace
- читається людиною
- i
- IAM
- ID
- ідеальний
- ідентифікувати
- ідентифікатори
- if
- зображення
- реалізовані
- імпорт
- in
- включати
- У тому числі
- Augmenter
- індекс
- індексований
- промисловості
- повідомити
- інформація
- ініціативи
- вхід
- витрати
- встановлювати
- екземпляр
- випадки
- інтегрований
- інтереси
- інтерфейс
- внутрішній
- в
- введені
- IT
- пунктів
- Джеймс
- приєднання
- jp morgan
- JP Morgan Chase
- JPG
- тримати
- ключ
- Знати
- знання
- мова
- великий
- більше
- запуск
- вести
- вивчення
- довжина
- libraries
- життя
- як
- МЕЖА
- список
- списки
- Місце проживання
- Лама
- логіка
- подивитися
- шукати
- серія
- машина
- навчання за допомогою машини
- зробити
- Робить
- вдалося
- вручну
- багато
- матч
- сірники
- максимальний
- максимальна сума
- Може..
- значити
- значущим
- засоби
- пам'ять
- метадані
- метод
- мінімізувати
- Пом'якшити
- ML
- модель
- Моделі
- гроші
- більше
- Morgan
- найбільш
- багато
- множинний
- музика
- повинен
- ім'я
- Природний
- Природна мова
- Обробка природних мов
- Необхідність
- потреби
- Нові
- наступний
- nlp
- ноутбук
- зараз
- нумпі
- об'єкт
- of
- on
- ONE
- онлайн
- онлайн освіта
- тільки
- відкрити
- операція
- or
- порядок
- OS
- інакше
- наші
- з
- вихід
- виходи
- поза
- власний
- документи
- параметри
- приватність
- особливо
- проходити
- Пройшов
- пристрасть
- пристрасний
- виконувати
- виконанні
- Дозволи
- картина
- трубопровід
- одноколірний
- plato
- Інформація про дані Платона
- PlatoData
- популярний
- позиції
- пошта
- Живлення
- прогноз
- Прогнози
- Прогноз
- переважним
- запобігати
- попередній перегляд
- попередній
- раніше
- попередній
- Проблема
- процес
- процеси
- обробка
- профіль
- підказок
- власником
- за умови
- забезпечує
- забезпечення
- публічно
- опублікований
- Python
- піторх
- запити
- питання
- питань
- швидко
- діапазон
- ранжування
- готовий
- отримання
- облік
- райони
- доречний
- покладатися
- Сховище
- представляє
- вимагати
- вимагається
- дослідження
- Реагувати
- результат
- результати
- повертати
- повернення
- міцний
- Rock
- Роль
- королівський
- прогін
- пробіжки
- мудрець
- то ж
- say
- масштабовані
- шкала
- наука
- вчений
- рахунок
- Екран
- Sdk
- Пошук
- пошук
- побачити
- вибрати
- старший
- сенс
- пропозиція
- Серія
- Серія A
- Послуги
- комплект
- Повинен
- Показувати
- показав
- показаний
- Шоу
- сторона
- аналогічний
- з
- один
- Розмір
- невеликий
- менше
- So
- суспільство
- виключно
- рішення
- Рішення
- деякі
- десь
- Source
- Простір
- спеціаліст
- спеціалізується
- Спеціальність
- конкретно
- Spot
- Персонал
- Стартапи
- статистичний
- Крок
- заходи
- Стоп
- зберігати
- магазинів
- Стратегічний
- рядок
- студія
- такі
- підтримка
- Підтриманий
- Опори
- система
- Systems
- T
- таблиця
- приймає
- Завдання
- технології
- технологічні стартапи
- Технологія
- розповідає
- текст
- тайський
- ніж
- Що
- Команда
- Площа
- світ
- їх
- Їх
- отже
- Ці
- вони
- речі
- це
- ті
- через
- час
- до
- знак
- Токенізація
- занадто
- інструменти
- топ
- традиційний
- Навчання
- трансформатор
- Трансформатори
- перетворення
- переводити
- Подорож
- Довіряйте
- два
- Типи
- Зрештою
- навряд чи
- нестримний.
- до
- небажаний
- Оновити
- URI
- us
- використання
- використовуваний
- користувач
- User Experience
- користувачі
- використання
- Цінності
- різний
- версія
- через
- візуальний
- чекати
- покрокове керівництво
- хотіти
- було
- хвиля
- шлях..
- we
- Web
- веб-сервіси
- Web-Based
- Що
- коли
- який
- в той час як
- широкий
- Широкий діапазон
- волі
- з
- без
- Work
- працював
- робочий
- працює
- світ
- б
- обернути
- X
- так
- ви
- вашу
- зефірнет