Представляємо упакований BERT для 2x прискорення навчання з опрацювання природної мови
Перегляньте цей новий алгоритм упаковки BERT для більш ефективного навчання.
By Доктор Маріо Майкл Крелл, головний керівник машинного навчання в Graphcore & Матей Косець, фахівець із застосування штучного інтелекту в Graphcore

Зображення автора.
Використовуючи новий алгоритм упаковки, ми пришвидшили обробку природної мови більш ніж у 2 рази під час навчання BERT-Large. Наша нова техніка упаковки усуває заповнення, що забезпечує значно ефективніші обчислення.
Ми підозрюємо, що це також можна застосувати до моделей геноміки та згортання білка та інших моделей із перекошеним розподілом довжини, щоб зробити набагато ширший вплив у різних галузях промисловості та застосуваннях.
Ми представили високоефективний алгоритм упаковки гістограм невід’ємних найменших квадратів Graphcore (або NNLSHP), а також наш алгоритм BERT, застосований до упакованих послідовностей, у новій статті [1].
Обчислювальні витрати в НЛП через заповнення послідовності
Ми почали досліджувати нові способи оптимізації навчання BERT, працюючи над нещодавнім подання тестів у MLPerf™. Метою було розробити корисні оптимізації, які можна було б легко застосувати в реальних програмах. BERT був природним вибором як однієї з моделей, на яку слід зосередитися для цих оптимізацій, оскільки він широко використовується в промисловості та багатьма нашими клієнтами.
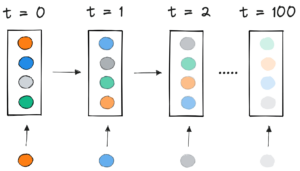
Нас справді здивувало, коли ми дізналися, що в нашій навчальній програмі BERT-Large, яка використовує набір даних Вікіпедії, 50% токенів у наборі даних були заповненими, що призвело до великої витрати обчислень.
Послідовності заповнення, щоб вирівняти їх усі до однакової довжини, є поширеним підходом, який використовується для графічних процесорів, але ми подумали, що варто спробувати інший підхід.
Послідовності мають велику варіацію довжини з двох причин:
- Основні дані Вікіпедії показують велику варіацію довжини документа
- Сама попередня обробка BERT випадковим чином зменшує розмір вилучених документів, які об’єднуються для створення навчальної послідовності
Заповнення довжини до максимальної довжини 512 призводить до того, що 50% усіх токенів є маркерами доповнення. Заміна 50% заповнення реальними даними може призвести до того, що на 50% більше даних буде оброблено з тими самими обчислювальними зусиллями, а отже, у 2 рази прискориться за оптимальних умов.

Рисунок 1: Розповсюдження набору даних Вікіпедії. Зображення автора.
Це специфічно для Вікіпедії? Ні.
Ну, тоді це специфічно для мови? Ні.
Фактично, спотворений розподіл довжини зустрічається скрізь: у мові, геноміці та згортанні білка. На рисунках 2 і 3 показано розподіл для наборів даних SQuAD 1.1 і наборів даних GLUE.

Рисунок 2: Гістограма довжини послідовності набору даних SQuAD 1.1 BERT перед навчанням для максимальної довжини послідовності 384. Зображення автора.

Рисунок 3: Гістограми довжини послідовності набору даних GLUE для максимальної довжини послідовності 128. Зображення автора.
Як ми можемо обробляти різні довжини, уникаючи зайвих обчислювальних витрат?
Сучасні підходи вимагають різних обчислювальних ядер для різної довжини або для того, щоб інженер програмно видаляв доповнення, а потім повторно додавав їх знову для кожного блоку уваги та обчислення втрат. Економія обчислень за рахунок розширення коду та ускладнення його не була привабливою, тому ми шукали щось краще. Хіба ми не можемо просто об’єднати кілька послідовностей у пакет максимальної довжини й обробити все разом? Виявляється, можемо!
Для цього підходу потрібні три ключові складові:
- Ефективний алгоритм для вирішення, які зразки об’єднати, щоб залишилося якомога менше заповнення
- Налаштування моделі BERT для обробки пакетів замість послідовностей
- І налаштування гіперпараметрів
Упаковка
Спочатку здавалося малоймовірним, що ви зможете дуже ефективно упакувати великий набір даних, такий як Вікіпедія. Ця проблема широко відома як bin-packing. Навіть якщо упаковка обмежена трьома або менше послідовностями, результуюча проблема все одно буде сильно NP-повною, не маючи ефективного алгоритмічного рішення. Існуючі евристичні алгоритми пакування не були перспективними, оскільки вони мали складність принаймні O(n журнал(n)), де n це кількість послідовностей (~16 млн для Вікіпедії). Нас цікавили підходи, які б добре масштабувалися до мільйонів послідовностей.
Два прийоми допомогли нам значно зменшити складність:
- Обмеження кількості послідовностей у пакеті до трьох (для нашого першого підходу до вирішення)
- Робота виключно з гістограмою довжини послідовності з одним відрізком для кожної довжини, що зустрічається
Наша максимальна довжина послідовності становила 512. Отже, перехід до гістограми зменшив розмірність і складність із 16 мільйонів послідовностей до 512 одиниць довжини. Дозвіл максимум трьох послідовностей у пакеті зменшив кількість дозволених комбінацій довжини до 22K. Це вже включало трюк, щоб вимагати сортування послідовностей за довжиною в пакеті. То чому б не спробувати 4 послідовності? Це збільшило кількість комбінацій з 22K до 940K, що було занадто багато для нашого першого підходу до моделювання. Крім того, глибина 3 вже досягла надзвичайно високої ефективності пакування.
Спочатку ми думали, що використання більше ніж трьох послідовностей у пакеті збільшить накладні витрати на обчислення та вплине на поведінку конвергенції під час навчання. Однак для підтримки таких програм, як логічний висновок, які вимагають ще швидшого пакування в реальному часі, ми розробили високоефективний алгоритм упакування гістограми невід’ємних найменших квадратів (NNLSHP).
Упаковка невід’ємної гістограми найменших квадратів (NNLSHP)
Упаковка в бункер досить часто формулюється як задача математичної оптимізації. Однак з 16 мільйонами послідовностей (або більше) це не практично. Одні проблемні змінні перевищили б пам'ять більшості машин. Математична програма для підходу на основі гістограми досить акуратна. Для простоти ми вибрали підхід найменших квадратів (Ax=b) з вектором гістограми b. Ми розширили його, запросивши вектор стратегії x бути невід’ємним і додавати ваги, щоб дозволити незначні заповнення.
Складною частиною була стратегічна матриця. Кожен стовпець має максимальну суму три і кодує, які послідовності упаковуються разом, щоб точно відповідати бажаній загальній довжині; 512 у нашому випадку. Рядки кодують кожну з потенційних комбінацій для досягнення загальної довжини. Вектор стратегії x це те, що ми шукали, яке описує, як часто ми обираємо будь-яку з 20 тисяч комбінацій. Цікаво, що зрештою було обрано лише близько 600 комбінацій. Щоб отримати точне рішення, важлива стратегія x має бути додатним цілим числом, але ми зрозуміли, що наближене округлене рішення лише з невід’ємними x було достатньо. Щоб отримати приблизне рішення, можна використати простий готовий розв’язувач, щоб отримати результат протягом 30 секунд.

Малюнок 4: Приклад стратегічної матриці для послідовності довжиною 8 і глибиною упаковки 3. Рядки означають послідовності довжиною 1–8, які упаковуються разом, а стовпці означають усі можливі комбінації довжини в пачці без певного порядку. Зображення автора.
Зрештою, нам довелося виправити деякі зразки, яким не було призначено стратегію, але їх було мінімально. Ми також розробили варіант розв’язувача, який передбачає, що кожна послідовність упаковується, можливо, із заповненням, і має вагу, що залежить від заповнення. Це зайняло набагато більше часу, і рішення було не набагато кращим.
Упаковка найкоротшої гістограми
NNLSHP запропонував нам достатній підхід до пакування. Однак нам було цікаво, чи теоретично ми можемо отримати швидший онлайн-підхід і усунути обмеження на об’єднання лише 3 послідовностей.
Тому ми черпали натхнення з існуючих алгоритмів пакування, але все ж зосередилися на гістограмах.
Є чотири компоненти для нашого першого алгоритму, найкоротшого пакета-першої гістограми (SPFHP):
- Дійте на гістограмі від найдовшої послідовності до найкоротшої
- Якщо поточна довжина послідовності не вміщується в жодному наборі, почніть новий набір пакетів
- Якщо є кілька підходів, візьміть пакет, де сума довжини послідовності є найменшою, і відповідно змініть кількість
- Ще раз перевірте відповідність решти підрахунків
Цей підхід був найпростішим для реалізації та займав лише 0.02 секунди.
Варіант полягав у тому, щоб взяти найбільшу суму довжини послідовності замість найкоротшої та розділити кількість, щоб отримати більш ідеальні відповідності. Загалом це не сильно змінило ефективність, але значно збільшило складність коду.
Як працює пакування гістограми за найкоротшим пакетом. Анімація автора.
Вікіпедія, SQuAD 1.1, результати пакування GLUE
Таблиці 1, 2 і 3 показують результати упаковки двох запропонованих нами алгоритмів. Глибина упаковки описує максимальну кількість упакованих послідовностей. Глибина упаковки 1 є базовою реалізацією BERT. Максимальна глибина упакування, якщо обмеження не встановлено, позначається додатковим «max». The кількість пачок описує довжину нового упакованого набору даних. Ефективність це відсоток реальних токенів у упакованому наборі даних. The фактор упаковки описує кінцеве потенційне прискорення порівняно з глибиною пакування 1.
У нас було чотири основні спостереження:
- Чим більш спотворений розподіл, тим більші переваги упаковки.
- Усі набори даних виграють від упаковки. Деякі навіть більш ніж у 2 рази.
- SPFHP стає більш ефективним, коли глибина упаковки не обмежена.
- Для максимальної кількості 3 упакованих послідовностей, чим складніший NNLSHP, тим він ефективніший (99.75 проти 89.44).

Таблиця 1: Ключові результати продуктивності запропонованих алгоритмів пакування (SPFHP і NNLSHP) у Вікіпедії. Зображення автора.

Таблиця 2: Результати продуктивності запропонованих алгоритмів упаковки для попереднього навчання SQUaD 1.1 BERT. Зображення автора.

Таблиця 3: Результати продуктивності запропонованих алгоритмів пакування для набору даних GLUE. Відображаються лише базова лінія та результати пакування SPFHP без обмеження глибини пакування. Зображення автора.
Регулювання обробки BERT
Щось цікаве в архітектурі BERT полягає в тому, що більшість обробки відбувається на рівні маркерів, що означає, що вона не заважає нашому пакуванню. Є лише чотири компоненти, які потребують коригування: маска уваги, втрата MLM, втрата NSP і точність.
Ключем для всіх чотирьох підходів до обробки різної кількості послідовностей була векторизація та використання максимальної кількості послідовностей, які можна об’єднати. Для уваги, ми вже мали маску для вирішення питання про відступ. Розширення цього на кілька послідовностей було простим, як можна побачити в наступному псевдокоді TensorFlow. Концепція полягає в тому, що ми переконалися, що увага обмежена окремими послідовностями і не може виходити за межі цього.
Зразок коду маски уваги.

Рисунок 5: Приклад маски нуль-один
Для розрахунку втрат, в принципі, ми розпаковуємо послідовності та обчислюємо окремі втрати, зрештою отримуючи середнє значення втрат за послідовностями (замість пакетів).
Для втрати MLM код виглядає так:
Зразок коду розрахунку збитків.
Для втрат NSP і точності принцип однаковий. У наших загальнодоступних прикладах ви можете знайти відповідний код у нашій компанії Фреймворк PopART.
Накладні витрати на Вікіпедію та оцінка прискорення
З нашою модифікацією BERT у нас виникло два запитання:
- Скільки накладних витрат це приносить із собою?
- Наскільки накладні витрати залежать від максимальної кількості послідовностей, зібраних у пакет?
Оскільки підготовка даних у BERT може бути громіздкою, ми використали ярлик і скомпілювали код для кількох різних глибин пакування та порівняли відповідні (виміряні) цикли. Результати відображені в таблиці 4. С накладні витрати, ми позначаємо відсоткове зниження пропускної здатності через зміни в моделі, щоб увімкнути упаковку (наприклад, схема маскування для уваги та змінений розрахунок втрат). The реалізовано прискорення це комбінація прискорення за рахунок упаковки ( фактор упаковки) і зниження пропускної здатності через накладні витрати.

Таблиця 4: Оціночне порівняння прискорення запропонованих алгоритмів пакування (SPFHP і NNLSHP) у Вікіпедії. Зображення автора.
Завдяки техніці векторизації накладні витрати є напрочуд малими, і немає жодних недоліків у упаковці багатьох послідовностей разом.
Гіперпараметри-коригування
З пакуванням ми подвоюємо ефективний розмір партії (в середньому). Це означає, що нам потрібно налаштувати тренувальні гіперпараметри. Простий трюк полягає в тому, щоб скоротити кількість накопичень градієнта вдвічі, щоб зберегти той самий ефективний середній розмір партії, що й до навчання. Використовуючи контрольні параметри з попередньо підготовленими контрольними точками, ми можемо побачити, що криві точності повністю збігаються.

Рисунок 6: Порівняння кривих навчання для упакованої та неупакованої обробки з зменшений розмір партії для упакованого підходу. Зображення автора.
Точність збігається: втрата навчання MLM може дещо відрізнятися на початку, але швидко надолужує. Ця початкова різниця могла виникнути через невеликі коригування рівнів уваги, які могли бути зміщені в бік коротких послідовностей у попередньому тренуванні.
Щоб уникнути уповільнення, іноді допомагає зберегти вихідний розмір пакета незмінним і налаштувати гіперпараметри на збільшений ефективний розмір пакета (подвоєний). Основними гіперпараметрами, які слід враховувати, є бета-параметри та швидкість навчання. Одним із поширених підходів є подвоєння розміру партії, що в нашому випадку знизило продуктивність. Дивлячись на статистику оптимізатора LAMB, ми можемо довести, що збільшення бета-параметра до ступеня коефіцієнта упаковки відповідає послідовному навчанню кількох партій, щоб підтримувати порівнянність імпульсу та швидкості.

Рисунок 7: Порівняння кривих навчання для упакованої та неупакованої обробки з евристика застосовується. Зображення автора.
Наші експерименти показали, що переведення бета-фактора в двійку є хорошою евристикою. У цьому сценарії не очікується, що криві збігаються, оскільки збільшення розміру партії зазвичай зменшує швидкість конвергенції в сенсі вибірок/епох, доки не буде досягнуто цільової точності.
Тепер питання полягає в тому, чи справді ми отримаємо очікуване прискорення в практичному сценарії?

Рисунок 8: Порівняння кривих навчання для упакованої та розпакованої обробки в оптимізоване налаштування. Зображення автора.
Так ми робимо! Ми отримали додаткове прискорення, оскільки стиснули передачу даних.
Висновок
Складання речень разом може заощадити обчислювальні зусилля та навколишнє середовище. Цю техніку можна реалізувати в будь-якому фреймворку, включаючи PyTorch і TensorFlow. Ми отримали явне 2-кратне прискорення та, попутно, розширили сучасні алгоритми пакування.
Інші програми, які нам цікаві, — це геноміка та згортання білків, де можна спостерігати схожі розподіли даних. Трансформатори зору також можуть бути цікавою областю для застосування упакованих зображень різного розміру. Які програми, на вашу думку, будуть працювати добре? Ми будемо раді почути від вас!
Отримайте доступ до коду на GitHub
Дякую
Дякуємо нашим колегам із групи розробки програм Graphcore, Шенг Фу та Мрінал Айєр, за їхній внесок у цю роботу, а також дякую Дугласу Орру з дослідницької групи Graphcore за його цінний відгук.
посилання
[1] M. Kosec, S. Fu, MM Krell, Упаковка: Назустріч 2x NLP BERT Acceleration (2021), arXiv
Доктор Маріо Майкл Крелл є головним керівником машинного навчання в Graphcore. Маріо досліджував і розробляв алгоритми машинного навчання більше 12 років, створюючи програмне забезпечення для таких різноманітних галузей, як робототехніка, автомобілебудування, телекомунікації та охорона здоров’я. У Graphcore він сприяв нашому вражаючому Подання MLPerf і має пристрасть до прискорення нових нестандартних моделей, таких як наближені байєсівські обчислення для статистичного аналізу даних COVID-19.
Матей Косець є спеціалістом із застосування штучного інтелекту в Graphcore в Пало-Альто. Раніше він працював науковцем із штучного інтелекту з автономного водіння в NIO у Сан-Хосе та має ступінь магістра з аеронавтики та астронавтики в Стенфордському університеті.
Оригінал. Повідомлено з дозволу.
За темою:
- "
- &
- 2021
- 7
- Додатковий
- повітроплавання
- AI
- алгоритм
- алгоритми
- ВСІ
- Дозволити
- аналіз
- анімація
- додаток
- застосування
- архітектура
- ПЛОЩА
- навколо
- Art
- автоматичний
- автомобільний
- автономний
- Базова лінія
- еталонний тест
- бета
- зміна
- код
- Колонка
- загальний
- обчислення
- внесок
- COVID-19
- створення
- Поточний
- Клієнти
- дані
- аналіз даних
- наука про дані
- глибоке навчання
- розвивати
- DID
- Розмір
- Директор
- документація
- водіння
- Ефективний
- ефективність
- інженер
- Машинобудування
- Навколишнє середовище
- Перший
- відповідати
- виправляти
- Сфокусувати
- Рамки
- геномика
- добре
- Графічні процесори
- охорона здоров'я
- Високий
- Як
- HTTPS
- зображення
- Impact
- У тому числі
- Augmenter
- промисловості
- промисловість
- натхнення
- інтерв'ю
- дослідити
- IT
- робота
- ключ
- знання
- мова
- великий
- вести
- УЧИТЬСЯ
- вивчення
- рівень
- обмеженою
- любов
- навчання за допомогою машини
- Робить
- маска
- матч
- мільйона
- ML
- модель
- Імпульс
- Природна мова
- Обробка природних мов
- нерозбавлений
- Нейронний
- nlp
- номера
- онлайн
- відкрити
- з відкритим вихідним кодом
- Інше
- Папір
- продуктивність
- влада
- Головний
- програма
- Білок
- громадськість
- Python
- піторх
- ставки
- реального часу
- Причини
- зменшити
- регресія
- дослідження
- результати
- робототехніка
- Сан -
- Сан - Хосе
- економія
- шкала
- наука
- Вчені
- Пошук
- обраний
- сенс
- комплект
- установка
- Короткий
- простий
- Розмір
- невеликий
- So
- Софтвер
- швидкість
- розкол
- Станфорд
- Стенфордський університет
- старт
- стан
- статистика
- історії
- Стратегія
- підтримка
- Мета
- зв'язок
- тензорний потік
- знак
- Жетони
- топ
- Навчання
- університет
- us
- VeloCity
- бачення
- Вікіпедія
- в
- Work
- працює
- вартість
- X
- років