У цю еру великих даних організації в усьому світі постійно шукають інноваційні способи отримання цінності та інформації зі своїх величезних наборів даних. Apache Spark забезпечує масштабованість і швидкість, необхідні для ефективної обробки великих обсягів даних.
Amazon EMR це провідне в галузі хмарне рішення для великих даних для обробки петабайтних даних, інтерактивної аналітики та машинного навчання (ML) з використанням фреймворків з відкритим кодом, таких як Apache Spark, Вулик апачів та Престо. Amazon EMR — найкраще місце для запуску Apache Spark. Ви можете швидко й без зусиль створювати керовані кластери Spark із Консоль управління AWS, Інтерфейс командного рядка AWS (AWS CLI) або Amazon EMR API. Ви також можете використовувати додаткові функції Amazon EMR, зокрема швидку Служба простого зберігання Amazon (Amazon S3) підключення за допомогою файлової системи Amazon EMR (EMRFS), інтеграція з Amazon EC2 Spot ринок і Клей AWS Каталог даних і кероване масштабування EMR для додавання чи видалення екземплярів із вашого кластера. Amazon EMR Studio це інтегроване середовище розробки (IDE), яке спрощує для науковців та інженерів даних розробку, візуалізацію та налагодження програм обробки даних і науки про дані, написаних на R, Python, Scala та PySpark. EMR Studio надає повністю керовані блокноти Jupyter і такі інструменти, як Spark UI і YARN Timeline Service, щоб спростити налагодження.
Щоб розкрити потенціал, прихований у сховищах даних, важливо вийти за рамки традиційної аналітики. Увійдіть у generative AI, передову технологію, яка поєднує машинне навчання з креативністю для створення людського тексту, мистецтва та навіть коду. Amazon Bedrock це найпростіший спосіб створювати та масштабувати генеративні програми ШІ за допомогою базових моделей (FM). Amazon Bedrock — це повністю керована служба, яка робить доступними FM від Amazon і провідних компаній штучного інтелекту через API, тож ви можете швидко експериментувати з різноманітними FM на ігровому майданчику та використовувати єдиний API для висновків незалежно від обраних вами моделей, надаючи ви гнучкість у використанні FM від різних провайдерів і бути в курсі останніх версій моделі з мінімальними змінами коду.
У цій публікації ми досліджуємо, як ви можете посилити свою аналітику даних за допомогою генеративного штучного інтелекту за допомогою Amazon EMR, Amazon Bedrock і pyspark-ai бібліотека. Бібліотека pyspark-ai — це англійський SDK для Apache Spark. Він приймає інструкції англійською мовою та компілює їх у об’єкти PySpark, такі як DataFrames. Це спрощує роботу зі Spark, дозволяючи вам зосередитися на отриманні цінності з ваших даних.
Огляд рішення
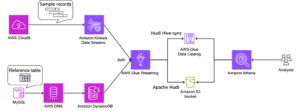
На наступній діаграмі показано архітектуру використання генеративного ШІ з Amazon EMR і Amazon Bedrock.

EMR Studio — це веб-інтерфейс IDE для повністю керованих ноутбуків Jupyter, які працюють на кластерах EMR. Ми взаємодіємо з EMR Studio Workspaces, підключеними до запущеного кластера EMR, і запускаємо блокнот, наданий як частина цієї публікації. Ми використовуємо Нью-Йоркське таксі дані, щоб отримати інформацію про різні поїздки на таксі, які здійснюють користувачі. Ми ставимо запитання природною мовою на додаток до даних, завантажених у Spark DataFrame. Потім бібліотека pyspark-ai використовує Amazon Titan Text FM від Amazon Bedrock для створення запиту SQL на основі запитання природною мовою. Бібліотека pyspark-ai приймає SQL-запит, виконує його за допомогою Spark SQL і повертає результати користувачеві.
У цьому рішенні ви можете створювати та налаштовувати необхідні ресурси у своєму обліковому записі AWS за допомогою AWS CloudFormation шаблон. Шаблон створює Клей AWS бази даних і таблиць, відро S3, VPC та інше Управління ідентифікацією та доступом AWS (IAM), які використовуються в рішенні.
Шаблон створено, щоб продемонструвати, як використовувати EMR Studio з пакетом pyspark-ai і Amazon Bedrock, і не призначений для виробничого використання без змін. Крім того, шаблон використовує us-east-1 Регіон і може не працювати в інших регіонах без змін. Шаблон створює ресурси, які несуть витрати, поки вони використовуються. Виконайте кроки очищення в кінці цієї публікації, щоб видалити ресурси та уникнути непотрібних витрат.
Передумови
Перш ніж запускати стек CloudFormation, переконайтеся, що у вас є:
- Обліковий запис AWS, який надає доступ до сервісів AWS
- Користувач IAM із ключем доступу та секретним ключем для налаштування AWS CLI, а також дозволами на створення ролі IAM, політик IAM і стеків у AWS CloudFormation
- Модель Titan Text G1 – Express наразі знаходиться в попередньому перегляді, тому вам потрібен доступ до попереднього перегляду, щоб використовувати її як частину цієї публікації
Створюйте ресурси за допомогою AWS CloudFormation
CloudFormation створює такі ресурси AWS:
- Стек VPC із приватними та публічними підмережами для використання з EMR Studio, таблицями маршрутизації та шлюзом NAT.
- Кластер EMR із встановленим Python 3.9. Ми використовуємо завантажувальну дію для встановлення Python 3.9 та інших відповідних пакетів, таких як залежності pyspark-ai та Amazon Bedrock. (Для отримання додаткової інформації зверніться до початковий скрипт.)
- Відро S3 для робочого простору EMR Studio та зберігання ноутбуків.
- Ролі й політики IAM для налаштування EMR Studio, доступу до Amazon Bedrock і запущених ноутбуків
Щоб почати, виконайте такі дії:
- Вибирати Стек запуску:

- Select Я визнаю, що цей шаблон може створювати ресурси IAM.
На створення стека CloudFormation потрібно приблизно 20–30 хвилин. Ви можете стежити за його прогресом на консолі AWS CloudFormation. Коли його статус читає CREATE_COMPLETE, ваш обліковий запис AWS матиме ресурси, необхідні для впровадження цього рішення.
Створити EMR Studio
Тепер ви можете створити EMR Studio та Workspace для роботи з кодом блокнота. Виконайте наступні дії:
- На консолі EMR Studio виберіть Створити студію.
- Введіть Назва студії as
GenAI-EMR-Studioі надати опис. - У Мережа та безпека розділі вкажіть наступне:
- для VPC, виберіть VPC, який ви створили як частину стека CloudFormation, який ви розгорнули. Отримайте ідентифікатор VPC за допомогою вихідних даних CloudFormation для ключа VPCID.
- для Підмережі, виберіть усі чотири підмережі.
- для Безпека та доступвиберіть Спеціальна група безпеки.
- для Група безпеки кластера/кінцевої точкивиберіть
EMRSparkAI-Cluster-Endpoint-SG. - для Група безпеки робочого просторувиберіть
EMRSparkAI-Workspace-SG.
- У Роль служби студії розділі вкажіть наступне:
- для Authenticationвиберіть AWS Identity and Access Management (IAM).
- для Сервісна роль AWS IAMвиберіть
EMRSparkAI-StudioServiceRole.
- У Зберігання робочого простору розділ, перегляньте та виберіть відро S3 для зберігання, починаючи з
emr-sparkai-<account-id>. - Вибирати Створити студію.

- Коли EMR Studio буде створено, виберіть посилання нижче URL-адреса доступу до студії для доступу до студії.

- Коли ти в Студії, вибирай Створіть робочу область.
- додавати
emr-genaiяк назву робочого простору та виберіть Створіть робочу область. - Коли робочу область буде створено, виберіть її назву, щоб запустити робочу область (переконайтеся, що ви вимкнули блокувальники спливаючих вікон).

Аналітика великих даних за допомогою Apache Spark з Amazon EMR і генеративним штучним інтелектом
Тепер, коли ми завершили необхідні налаштування, ми можемо почати виконувати аналіз великих даних за допомогою Apache Spark з Amazon EMR і generative AI.
Як перший крок, ми завантажуємо блокнот із необхідним кодом і прикладами для роботи з варіантом використання. Ми використовуємо набір даних NY Taxi, який містить інформацію про поїздки на таксі.
- Завантажте файл блокнота NYTaxi.ipynb і завантажте його у свою робочу область, вибравши піктограму завантаження.

- Після імпорту блокнота відкрийте блокнот і виберіть
PySparkяк ядро.
PySpark AI за замовчуванням використовує ChatGPT4.0 OpenAI як модель LLM, але ви також можете підключати моделі з Amazon Bedrock, Amazon SageMaker JumpStartта інші моделі сторонніх виробників. У цій публікації ми покажемо, як інтегрувати модель Amazon Bedrock Titan для генерації запитів SQL і запустити її за допомогою Apache Spark в Amazon EMR.
- Щоб розпочати роботу з блокнотом, вам потрібно пов’язати робочу область із обчислювальним рівнем. Для цього виберіть обчислення на панелі навігації та виберіть кластер EMR, створений стеком CloudFormation.

- Налаштуйте параметри Python для використання оновленого пакета Python 3.9 з Amazon EMR:
- Імпортуйте необхідні бібліотеки:
- Після імпорту бібліотек ви можете визначити модель LLM з Amazon Bedrock. У цьому випадку ми використовуємо amazon.titan-text-express-v1. Вам потрібно ввести URL-адресу кінцевої точки регіону та Amazon Bedrock на основі вашого доступу до попереднього перегляду для моделі Titan Text G1 – Express.
- Підключіть Spark AI до моделі Amazon Bedrock LLM для створення SQL-запитів на основі запитань природною мовою:
Тут ми ініціалізували Spark AI з verbose=False; Ви також можете встановити verbose=True, щоб побачити більше деталей.
Тепер ви можете читати дані NYC Taxi у Spark DataFrame і використовувати потужність генеративного штучного інтелекту в Spark.
- Наприклад, ви можете запитати кількість записів у наборі даних:
Отримуємо таку відповідь:
Внутрішнє використання Spark AI LangChain і ланцюжок SQL, які приховують складність від кінцевих користувачів, які працюють із запитами в Spark.
У блокноті є ще кілька прикладів сценаріїв для дослідження потужності генеративного ШІ за допомогою Apache Spark і Amazon EMR.
Прибирати
Вилийте вміст відра S3 emr-sparkai-<account-id>, видаліть робочу область EMR Studio, створену в рамках цієї публікації, а потім видаліть стек CloudFormation, який ви розгорнули.
Висновок
Ця публікація показала, як ви можете посилити свою аналітику великих даних за допомогою Apache Spark з Amazon EMR і Amazon Bedrock. Пакет штучного інтелекту PySpark дозволяє отримувати значущу інформацію з ваших даних. Це допомагає скоротити час розробки та аналізу, зменшуючи час на написання запитів вручну та дозволяючи вам зосередитися на бізнес-випадку використання.
Про авторів
 Саурабх Бхутяні є головним архітектором рішень спеціаліста з аналітики в AWS. Він захоплений новими технологіями. Він приєднався до AWS у 2019 році та працює з клієнтами, щоб надавати архітектурні рекомендації для запуску сценаріїв використання генеративного штучного інтелекту, масштабованих аналітичних рішень і архітектур сіті даних із використанням таких сервісів AWS, як Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, і Amazon DataZone.
Саурабх Бхутяні є головним архітектором рішень спеціаліста з аналітики в AWS. Він захоплений новими технологіями. Він приєднався до AWS у 2019 році та працює з клієнтами, щоб надавати архітектурні рекомендації для запуску сценаріїв використання генеративного штучного інтелекту, масштабованих аналітичних рішень і архітектур сіті даних із використанням таких сервісів AWS, як Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, і Amazon DataZone.
 Жорстокий Вардан є старшим архітектором рішень AWS, який спеціалізується на аналітиці. Має понад 8 років досвіду роботи у сфері великих даних та науки про дані. Він захоплений тим, щоб допомогти клієнтам засвоїти найкращі практики та отримати інформацію з їхніх даних.
Жорстокий Вардан є старшим архітектором рішень AWS, який спеціалізується на аналітиці. Має понад 8 років досвіду роботи у сфері великих даних та науки про дані. Він захоплений тим, щоб допомогти клієнтам засвоїти найкращі практики та отримати інформацію з їхніх даних.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/use-generative-ai-with-amazon-emr-amazon-bedrock-and-english-sdk-for-apache-spark-to-unlock-insights/
- : має
- :є
- : ні
- $UP
- 1
- 10
- 100
- 107
- 11
- 20
- 200
- 2019
- 320
- 500
- 521
- 7
- 8
- 9
- 990
- a
- МЕНЮ
- доступ
- управління доступом
- рахунки
- визнавати
- дію
- додавати
- Додатковий
- Додатково
- прийняти
- AI
- випадки використання ai
- ВСІ
- Дозволити
- дозволяє
- Також
- Amazon
- Амазонка Афіна
- Amazon EMR
- Amazon SageMaker
- Amazon Web Services
- суми
- an
- аналіз
- аналітика
- та
- відповідь
- будь-який
- Apache
- Apache Spark
- API
- застосування
- приблизно
- архітектурний
- архітектура
- ЕСТЬ
- Art
- AS
- запитати
- Юрист
- At
- доступний
- уникнути
- AWS
- AWS CloudFormation
- Клей AWS
- Формування озера AWS
- назад
- заснований
- КРАЩЕ
- передового досвіду
- За
- Великий
- Великий даних
- Bootstrap
- будувати
- бізнес
- але
- button
- by
- CAN
- випадок
- випадків
- каталог
- ланцюг
- Зміни
- вантажі
- Вибирати
- Вибираючи
- Місто
- хмара
- хмарні великі дані
- кластер
- код
- комбінати
- Компанії
- повний
- Зроблено
- складність
- обчислення
- підключений
- зв'язок
- Консоль
- постійно
- містить
- зміст
- витрати
- створювати
- створений
- створює
- креативність
- В даний час
- Клієнти
- передовий
- дані
- Analytics даних
- обробка даних
- наука про дані
- Database
- набори даних
- Дата
- дефолт
- визначати
- демонструвати
- залежно
- розгорнути
- дрейф
- description
- призначений
- деталі
- розвивати
- розробка
- різний
- інвалід
- відкрити
- do
- продуктивно
- легко
- кінець
- Кінцева точка
- Машинобудування
- Інженери
- англійська
- забезпечувати
- Що натомість? Створіть віртуальну версію себе у
- вхід
- Навколишнє середовище
- Епоха
- істотний
- Ефір (ETH)
- Навіть
- приклад
- Приклади
- досвід
- експеримент
- дослідити
- експрес
- витяг
- ШВИДКО
- риси
- кілька
- поле
- філе
- остаточний
- Перший
- Гнучкість
- Сфокусувати
- стежити
- після
- для
- освіта
- фонд
- чотири
- каркаси
- від
- повністю
- g1
- гарнер
- шлюз
- породжувати
- покоління
- генеративний
- Генеративний ШІ
- отримати
- дає
- Go
- керівництво
- Мати
- he
- допомога
- допомогу
- допомагає
- прихований
- приховувати
- Як
- How To
- HTTP
- HTTPS
- i
- IAM
- ICON
- ID
- Особистість
- управління ідентифікацією та доступом
- ілюструє
- здійснювати
- імпорт
- in
- В інших
- У тому числі
- провідний в галузі
- інформація
- інноваційний
- вхід
- розуміння
- встановлювати
- випадки
- інструкції
- інтегрувати
- інтегрований
- інтеграція
- призначених
- взаємодіяти
- інтерактивний
- внутрішньо
- в
- IT
- ЙОГО
- приєднався
- JPG
- тримати
- ключ
- Знати
- озеро
- мова
- великий
- останній
- запуск
- шар
- провідний
- вивчення
- libraries
- бібліотека
- як
- Лінія
- LINK
- загрузка
- машина
- навчання за допомогою машини
- зробити
- РОБОТИ
- вдалося
- управління
- керівництво
- ринок
- Може..
- значущим
- сітці
- мінімальний
- протокол
- ML
- модель
- Моделі
- монітор
- більше
- найбільш
- ім'я
- Природний
- Природна мова
- навігація
- необхідно
- Необхідність
- необхідний
- мережа
- Нові
- Нові технології
- ноутбук
- ноутбуки
- зараз
- номер
- NY
- Нью-Йорк
- об'єкти
- спостереження
- of
- Пропозиції
- on
- відкрити
- з відкритим вихідним кодом
- or
- організації
- Інше
- виходи
- над
- огляд
- пакет
- пакети
- pane
- параметри
- частина
- пристрасний
- виконанні
- Дозволи
- місце
- plato
- Інформація про дані Платона
- PlatoData
- дитячий майданчик
- штекер
- Політика
- спливаючий
- пошта
- потенціал
- влада
- практики
- попередній перегляд
- Головний
- приватний
- процес
- обробка
- Production
- прогрес
- забезпечувати
- за умови
- провайдери
- забезпечує
- громадськість
- Python
- запити
- питання
- питань
- швидко
- R
- Читати
- облік
- зменшити
- зниження
- послатися
- Незалежно
- регіон
- райони
- доречний
- видаляти
- вимагається
- ресурси
- відповідь
- результати
- атракціони
- Роль
- ролі
- Маршрут
- прогін
- біг
- пробіжки
- мудрець
- масштаб
- масштабованість
- масштабовані
- шкала
- Масштабування
- сценарії
- наука
- Вчені
- Sdk
- Грати короля карти - безкоштовно Nijumi логічна гра гри
- секрет
- безпеку
- побачити
- вибрати
- старший
- обслуговування
- Послуги
- комплект
- установка
- Показувати
- показав
- простий
- спростити
- один
- So
- рішення
- Рішення
- Source
- Іскритися
- спеціаліст
- спеціалізується
- швидкість
- SQL
- стек
- Стеки
- старт
- почалася
- Починаючи
- Статус
- Крок
- заходи
- зберігання
- просто
- студія
- підмережі
- такі
- Надзарядка
- Переконайтеся
- система
- таблиця
- прийняті
- приймає
- Технології
- Технологія
- шаблон
- текст
- Що
- Команда
- їх
- Їх
- потім
- вони
- третя сторона
- це
- думка
- через
- час
- Терміни
- велетень
- до
- інструменти
- топ
- традиційний
- ui
- при
- відімкнути
- оновлений
- URL
- використання
- використання випадку
- використовуваний
- користувач
- користувачі
- використовує
- використання
- значення
- різноманітність
- різний
- величезний
- візуалізувати
- шлях..
- способи
- we
- Web
- веб-сервіси
- Web-Based
- коли
- який
- в той час як
- волі
- з
- в
- без
- Work
- робочий
- працює
- світовий
- запис
- письмовий
- років
- йорк
- ви
- вашу
- зефірнет