Суреш є технічним керівником із глибоким технічним досвідом у напівпровідниках, штучному інтелекті, кібербезпеці, Інтернеті речей, апаратному забезпеченні, програмному забезпеченні тощо. Він провів 20 років у цій галузі, останнім часом обіймав посаду виконавчого директора з відкритим вихідним кодом. довіряти розробці чіпів в Інституті технологічних інновацій, Абу-Дабі та в інших напівпровідникових компаніях зі списку Fortune 500, таких як Intel, Qualcomm і MediaTek на різних керівних посадах, де він досліджував і розробляв високопродуктивні, енергоефективні, постквантові безпечні, безпечні мікрочіпи/системи на чіпах (SoC)/прискорювачі для центрів обробки даних, клієнтів, смартфонів, мереж, Інтернету речей і AI/ML. Він брав участь у Falcon LLM (рейтинг № 1 у huggingface) і був провідним архітектором спеціальної апаратної платформи ШІ (скасовано – пріоритети змінено). Він має понад 15 патентів США та опублікував/доповідав на більш ніж 20+ конференціях.
Суреш є технічним керівником із глибоким технічним досвідом у напівпровідниках, штучному інтелекті, кібербезпеці, Інтернеті речей, апаратному забезпеченні, програмному забезпеченні тощо. Він провів 20 років у цій галузі, останнім часом обіймав посаду виконавчого директора з відкритим вихідним кодом. довіряти розробці чіпів в Інституті технологічних інновацій, Абу-Дабі та в інших напівпровідникових компаніях зі списку Fortune 500, таких як Intel, Qualcomm і MediaTek на різних керівних посадах, де він досліджував і розробляв високопродуктивні, енергоефективні, постквантові безпечні, безпечні мікрочіпи/системи на чіпах (SoC)/прискорювачі для центрів обробки даних, клієнтів, смартфонів, мереж, Інтернету речей і AI/ML. Він брав участь у Falcon LLM (рейтинг № 1 у huggingface) і був провідним архітектором спеціальної апаратної платформи ШІ (скасовано – пріоритети змінено). Він має понад 15 патентів США та опублікував/доповідав на більш ніж 20+ конференціях.
Суреш також активно обіймає керівну посаду в RISC-V International, де він очолює Trusted Computing Group з розробки можливостей конфіденційного обчислення RISC-V і очолює групу AI/ML з розробки апаратного прискорення RISC-V для робочих навантажень RISC-V, таких як Transformer Large Language Models, які використовуються в додатках ChatGPT. Він також консультує стартапи та компанії венчурного капіталу щодо підтримки прийняття інвестиційних рішень, стратегії продукту, належної перевірки технологій тощо.
Він отримав ступінь MBA в INSEAD, ступінь магістра в Birla Institute of Technology & Science Pilani, сертифікат системної інженерії в MIT, сертифікат штучного інтелекту в Стенфорді та сертифікат функціональної безпеки автомобіля від TÜV SÜD.
Розкажіть про свою компанію
"Мастиська А.І” (Mastiṣka на санскриті означає «мозок») — це компанія, що займається штучним інтелектом і зосереджена на створенні комп’ютерів, схожих на мозок, для більш ефективного запуску базових моделей для сценаріїв використання Generative AI майбутнього.
Які проблеми ви вирішуєте?
Враховуючи переваги штучного інтелекту/генерального штучного інтелекту, попит на нього лише зростатиме, як і його побічні ефекти на нашу планету. Як ми можемо зменшити або нейтралізувати побічні ефекти ШІ на нашій планеті? Уловлювання вуглецю та ядерна енергетика рухаються у правильному напрямку. Але нам потрібно фундаментально переглянути те, як ми робимо штучний інтелект, чи це неправильний спосіб робити тонни множення матриць?
Наш мозок може навчатися та виконувати багато завдань паралельно, споживаючи 10 Вт і менше, але чому ці системи ШІ споживають 10 мегават для навчання моделей?
Можливо, майбутнє чекає енергозберігаючі архітектури, такі як нейроморфні архітектури та трансформатори на основі нейронної мережі, які є найближчими до людського мозку, які можуть споживати в 100-1000 разів менше енергії, отже зменшуючи витрати на використання ШІ, тим самим демократизуючи його та зберігаючи наш планета.
Поточні виклики, з якими ми стикаємося з ШІ, а саме: а) доступність, б) доступність, в) доступність і г) екологічна безпека, а також деякі рекомендації щодо їх вирішення.
Якщо ми передбачимо в майбутньому, деякі корисні концепції AGI продемонстровано у фільмі «ЇЇ», де персонаж «Саманта» – розмовний агент, який є природним, розуміє емоції, виявляє емпатію, є чудовим другим пілотом на роботі — і працює на портативних пристроїв цілий день, то нам, можливо, доведеться вирішити наведені нижче проблеми прямо зараз.
Проблема 1: навчання LLM може коштувати від 150 тис. до 10+ мільйонів доларів, і це дозволяє лише тим, хто має більші кишені, розробляти ШІ. Крім того, вартість висновків також величезна (коштує в 10 разів більше, ніж веб-пошук)
—> Нам потрібно покращити енергоефективність моделей/апаратного забезпечення, щоб демократизувати ШІ на благо людства.
Проблема 2. Запуск величезних моделей AI для розмовних агентів або систем рекомендацій завдає шкоди навколишньому середовищу з точки зору споживання електроенергії та охолодження.
—> Нам потрібно покращити енергоефективність моделей/обладнання, щоб зберегти нашу планету для наших дітей.
Питання 3. Людський мозок здатний працювати багатозадачно, але споживає лише 10 Вт замість мегават.
—> Можливо, нам слід швидше будувати машини, схожі на наш мозок, а не звичайні матричні множники.
Людство може процвітати лише за допомогою стійких інновацій, а не шляхом вирубування всіх лісів і кип’ятіння океанів в ім’я інновацій. Ми повинні захистити нашу планету заради благополуччя наших дітей і майбутніх поколінь…
Які сфери застосування ваші найсильніші?
Навчання та визначення базових моделей на основі Transformer (і майбутньої нейронної архітектури) з у 50-100 разів більшою енергоефективністю порівняно з сучасними рішеннями на основі GPU.
Що не дає спати вашим клієнтам вночі?
Проблеми для клієнтів, які зараз використовують інші продукти:
Споживання електроенергії для навчання величезних мовних моделей зашкалює, наприклад, навчання LLM із параметрами 13B на текстових токенах 390B на 200 графічних процесорах протягом 7 днів коштує 151,744 XNUMX дол. https://lnkd.in/g6Vc5cz3). І навіть більші моделі з параметрами 100+B коштують $10+M лише за навчання. Потім платіть за висновок кожного разу, коли надходить новий запит.
Споживання води для охолодження, дослідники з Каліфорнійського університету в Ріверсайді оцінили вплив на навколишнє середовище подібної до ChatGPT послуги та кажуть, що вона ковтає 500 мілілітрів води (близько того, що міститься в 16-унційній пляшці води) кожного разу, коли ви запитуєте серії від 5 до 50 підказок або запитань. Діапазон змінюється залежно від місця розташування серверів і пори року. Оцінка включає непряме використання води, яке компанії не вимірюють, наприклад, для охолодження електростанцій, які забезпечують центри обробки даних електроенергією. (Джерело: https://lnkd.in/gybcxX8C)
Питання для тих, хто не користується поточними продуктами:
Не можу дозволити собі капітальні витрати на придбання обладнання
Не можу дозволити собі користуватися хмарними службами
Не можу впроваджувати інновації чи використовувати AI — застряг на моделі послуг, яка усуває будь-яку конкурентну перевагу
Як виглядає конкурентний ландшафт і як ви виділяєте його?
- Графічні процесори домінують у навчанні, хоча спеціалізовані ASIC також конкурують у цьому сегменті
- Висновок Cloud & Edge має забагато доступних варіантів
Цифровий, аналоговий, фотонний — як завгодно, люди намагаються вирішити ту саму проблему.
Чи можете ви поділитися своїми думками щодо поточного стану архітектури чіпів для AI/ML, тобто, що ви бачите як найбільш важливі тенденції та можливості прямо зараз?
Наступні тренди:
Тенденція 1: 10 років тому глибоке навчання на апаратному забезпеченні процвітало, а тепер те саме обладнання гальмує прогрес. Через величезну вартість апаратного забезпечення та витрат на електроенергію для роботи моделей отримати доступ до апаратного забезпечення стало проблемою. Лише компанії з глибокими кишенями можуть собі це дозволити і стають монополіями.
Тенденція 2: Тепер, коли ці моделі є, нам потрібно використовувати їх для практичних цілей, щоб збільшити навантаження на логічний висновок, дозволяючи процесорам із прискорювачами ШІ знову вийти в центр уваги.
Тенденція 3: Стартапи намагаються придумати альтернативне представлення чисел з плаваючою комою, що традиційний формат IEEE, такий як логарифмічний і положений, є хорошим, але недостатнім. Оптимізація простору дизайну PPA$ вибухає, коли ми намагаємося оптимізувати одне, а інше йде на розкид.
Тенденція 4: Галузь відходить від моделі штучного інтелекту на основі сервісів до розміщення власних приватних моделей у власних приміщеннях, але доступ до обладнання є проблемою через дефіцит поставок, санкції тощо
Поточний стан справ:
Доступність апаратного забезпечення та даних сприяла розвитку штучного інтелекту 10 років тому, тепер те саме апаратне забезпечення його як би гальмує — дозвольте мені пояснити
З тих пір, як процесори працювали жалюгідно, а графічні процесори були перепрофільовані для штучного інтелекту, сталося багато речей
Компанії займаються 4 сегментами штучного інтелекту/ML, а саме: 1) хмарне навчання, 2) хмарне обстеження, 3) периферійне обґрунтування та 4) периферійне навчання (об’єднане навчання для чутливих до конфіденційності програм).
Цифровий та аналоговий
Навчальна сторона – безліч компаній, які розробляють графічні процесори, прискорювачі для клієнтів на основі RISC-V, мікросхеми пластинчастого масштабу (850K ядер) тощо, де не вистачає традиційних процесорів (їхнє загальне призначення). Сторона висновку – прискорювачі NN доступні від усіх виробників у смартфонах, ноутбуках та інших периферійних пристроях.
Аналогові мемристорні архітектури також з'явилися деякий час тому.
Ми вважаємо, що процесори можуть бути дуже хорошими в висновках, якщо ми покращимо їх за допомогою прискорення, наприклад матричних розширень
Сторона речей RISC-V:
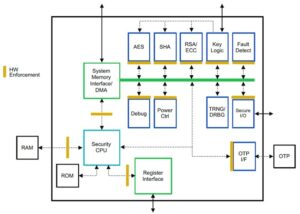
Що стосується RISC-V, ми розробляємо прискорювачі для матричних операцій та інших нелінійних операцій, щоб усунути можливі вузькі місця для робочих навантажень трансформаторів. Вузькі місця фон Неймана також вирішуються шляхом розробки пам’яті, наближеної до обчислювальної, що зрештою робить процесори з прискоренням штучного інтелекту правильним вибором для висновків.
Можливості:
Є унікальні можливості для заповнення ринку фундаментних моделей. Приклад. OpenAI згадує, що їм не вдалося забезпечити достатньо обчислень штучного інтелекту (графічних процесорів), щоб продовжувати просувати свої сервіси ChatGPT... і в новинах повідомляється, що вартість електроенергії в 10 разів перевищує вартість звичайного пошуку в Інтернеті та 500 мл води для охолодження систем. для кожного запиту. Тут є ринок, який потрібно заповнити — це не ніша, а весь ринок, який демократизує штучний інтелект, вирішуючи всі згадані вище проблеми: а) доступність, б) доступність, в) доступність і г) екологічна безпека
Над якими новими функціями/технологіями ви працюєте?
Ми будуємо мозок, як комп’ютер, використовуючи нейромодрофічні методи та підлаштовуючи моделі, щоб скористатися перевагами енергоефективного апаратного забезпечення, повторно використовуючи безліч доступних відкритих фреймворків
Яким, на вашу думку, буде розвиватися або змінюватися сектор AI/ML протягом наступних 12-18 місяців?
Оскільки попит на графічні процесори різко зріс (вартістю близько 30 тисяч доларів), а деякі країни світу стикаються з санкціями на придбання цих графічних процесорів, деякі частини світу відчувають, що вони заморожені в дослідженнях і розробках ШІ без доступу до графічних процесорів. Альтернативні апаратні платформи збираються захопити ринок.
Можливо, моделі почнуть скорочуватися — користувальницькі моделі або навіть принципово щільність інформації зросте
Те саме запитання, але як щодо зростання та змін у наступні 3-5 років?
a) ЦП із розширеннями ШІ захоплять ринок висновків ШІ
b) Моделі стануть гнучкими, а параметри впадуть із збільшенням щільності інформації з 16% до 90%.
c) Енергоефективність покращується, викиди CO2 зменшуються
d) З’являються нові архітектури
e) витрати на апаратне забезпечення та витрати на енергію знижуються, тому бар’єр входу для невеликих компаній до створення та навчання моделей стає доступним
f) люди говорять про момент до AGI, але моїм орієнтиром була б персонажна Саманта (розмовний ШІ) у фільмі «вона».. Це малоймовірно, враховуючи високу вартість розширення
Які проблеми можуть вплинути або обмежити розвиток сектору AI/ML?
a) Доступ до обладнання
b) Витрати на енергію та витрати на охолодження та шкоду навколишньому середовищу
Також читайте:
Інтерв'ю з генеральним директором: Девід Мур з Pragmatic
Інтерв’ю з генеральним директором: доктор Мегалі Чопра з Sandbox Semiconductor
Інтерв'ю з генеральним директором: д-р Дж. Провайн з компанії Aligned Carbon
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://semiwiki.com/ceo-interviews/338703-ceo-interview-suresh-sugumar-of-mastiska-ai/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 150
- 20
- 20 роки
- 200
- 50
- 500
- 7
- a
- Здатний
- МЕНЮ
- вище
- Абу-Дабі
- прискорення
- прискорювачі
- доступ
- доступність
- активно
- адреса
- адресований
- адресація
- Перевага
- Справи
- знову
- Агент
- агенти
- AGI
- назад
- AI
- Моделі AI
- ai дослідження
- Системи ШІ
- випадки використання ai
- AI / ML
- вирівняні
- ВСІ
- Дозволити
- дозволяє
- по
- Також
- альтернатива
- дивовижний
- an
- та
- Інший
- будь-який
- де-небудь
- додаток
- застосування
- архітектура
- ЕСТЬ
- області
- Прибуває
- штучний
- штучний інтелект
- AS
- Asics
- запитати
- At
- автомобільний
- наявність
- доступний
- геть
- b
- бар'єр
- заснований
- BE
- ставати
- стає
- становлення
- було
- буття
- Вірити
- нижче
- еталонний тест
- користь
- Переваги
- між
- За
- вузькі місця
- пов'язаний
- Brain
- мізки
- будувати
- Створюємо
- але
- купити
- by
- Каліфорнія
- CAN
- скасовано
- можливості
- здатний
- капітал
- захоплення
- вуглець
- уловлювання вуглецю
- випадків
- Центри
- Генеральний директор
- Інтерв’ю генерального директора
- сертифікат
- виклик
- проблеми
- зміна
- змінилися
- заміна
- характер
- ChatGPT
- діти
- чіп
- Чіпси
- вибір
- Чопра
- клієнт
- близько
- ближче
- хмара
- кластер
- co2
- Приходити
- Компанії
- компанія
- порівняний
- конкурувати
- конкурентоспроможний
- обчислення
- комп'ютер
- комп'ютери
- обчислення
- поняття
- конференції
- споживати
- споживання
- продовжувати
- внесок
- діалоговий
- розмовний ШІ
- Прохолодно
- Коштувати
- витрати
- може
- створювати
- Поточний
- Поточний стан
- В даний час
- виготовлений на замовлення
- клієнт
- Клієнти
- різання
- Кібербезпека
- дані
- центрів обробки даних
- Дата-центр
- Девід
- день
- Днів
- рішення
- глибокий
- глибоке навчання
- глибше
- Попит
- демократизувати
- Демократизувати
- продемонстрований
- Щільність
- Залежно
- дизайн
- розвивати
- розвиненою
- розвивається
- розробка
- прилади
- -Дабі
- диференціювати
- старанність
- напрям
- Директор
- do
- робить
- справи
- доларів
- Не знаю
- вниз
- dr
- Падіння
- два
- зароблений
- край
- ефекти
- ефективність
- ефективний
- продуктивно
- електрика
- споживання електроенергії
- усунутий
- Усуває
- емоції
- Співпереживання
- енергія
- енергоефективності
- Машинобудування
- підвищувати
- досить
- Весь
- запис
- Навколишнє середовище
- навколишній
- передбачення
- оцінити
- оцінка
- і т.д.
- Ефір (ETH)
- Навіть
- врешті-решт
- Кожен
- приклад
- виконавчий
- Виконавчий директор
- існувати
- експертиза
- Вибухає
- Розширення
- Face
- облицювання
- сокіл
- швидше
- почуття
- заповнювати
- фірми
- плаваючий
- увагу
- ніжка
- для
- передбачити
- формат
- стан
- фонд
- каркаси
- від
- заморожені
- підживлюється
- функціональний
- принципово
- майбутнє
- Загальне
- покоління
- генеративний
- Генеративний ШІ
- даний
- Go
- йде
- буде
- добре
- Графічні процесори
- Group
- Зростання
- Зростання
- апаратні засоби
- Мати
- he
- отже
- тут
- Високий
- тримає
- хостинг
- Як
- HTTPS
- величезний
- HuggingFace
- людина
- Людство
- IEEE
- if
- зображення
- Impact
- удосконалювати
- поліпшується
- in
- В інших
- includes
- Augmenter
- промисловість
- інформація
- оновлювати
- інновація
- інновації
- замість
- Інститут
- Intel
- Інтелект
- Міжнародне покриття
- інтернет
- інтерв'ю
- інвестиції
- КАТО
- IT
- ЙОГО
- просто
- Діти
- Дитина
- відсутність
- ландшафт
- мова
- ноутбуки
- великий
- більше
- вести
- Керівництво
- УЧИТЬСЯ
- вивчення
- дозволяти
- Важіль
- використання
- як
- ліхтарик
- МЕЖА
- загрузка
- розташований
- подивитися
- виглядає як
- знизити
- Машинки для перманенту
- Робить
- виробник
- багато
- ринок
- ринки
- Матриця
- макс-ширина
- Може..
- може бути
- MBA
- me
- сенс
- засоби
- вимір
- пам'яті
- згаданий
- може бути
- мільйона
- мільйонів доларів
- MIT
- модель
- Моделі
- момент
- монополії
- місяців
- більше
- найбільш
- фільм
- переміщення
- MS
- повинен
- my
- ім'я
- а саме
- Природний
- Необхідність
- на основі мережі
- мережа
- Нейронний
- Нові
- новини
- наступний
- ніша
- ніч
- спритний
- зараз
- ядерний
- Атомна енергетика
- номер
- океани
- of
- on
- ONE
- тільки
- відкрити
- з відкритим вихідним кодом
- OpenAI
- операції
- Можливості
- оптимізація
- Оптимізувати
- Опції
- or
- Інше
- наші
- з
- власний
- сторінка
- Паралельні
- параметр
- параметри
- частини
- Патенти
- Платити
- Люди
- може бути
- планета
- рослин
- платформа
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- безліч
- плюс
- кишені
- точка
- положення
- це можливо
- влада
- електростанції
- Практичний
- друк
- приватний
- Проблема
- проблеми
- Product
- Продукти
- профіль
- прогрес
- підказок
- захист
- мета
- цілей
- Штовхати
- Ставить
- Qualcomm
- питання
- питань
- діапазон
- ранг
- Читати
- нещодавно
- Рекомендація
- рекомендації
- зменшити
- зниження
- регулярний
- Звіти
- запросити
- дослідження
- дослідження і розробка
- Дослідники
- право
- прибережна смуга
- ролі
- дах
- прогін
- біг
- пробіжки
- сейф
- Безпека
- то ж
- Санкції
- sandbox
- зберегти
- економія
- say
- Масштабування
- наука
- Пошук
- Сезон
- сектор
- безпечний
- побачити
- сегменти
- напівпровідник
- Напівпровідникові прилади
- Серія
- сервери
- обслуговування
- Послуги
- виступаючої
- Поділитись
- дефіцит
- Повинен
- показав
- Шоу
- сторона
- значний
- з
- менше
- смартфон
- смартфонів
- So
- Софтвер
- Рішення
- Розв’язування
- деякі
- Source
- Простір
- спеціалізований
- відпрацьований
- Станфорд
- старт
- Стартапи
- стан
- Стратегія
- найсильніший
- такі
- поставка
- підтримка
- сталого
- Systems
- снасті
- вирішення проблем
- пошиття одягу
- Приймати
- балаканина
- завдання
- технічний
- Технологія
- технологічні інновації
- terms
- текст
- ніж
- Що
- Команда
- Майбутнє
- інформація
- світ
- їх
- Їх
- потім
- Там.
- тим самим
- Ці
- вони
- речі
- це
- ті
- хоча?
- Процвітати
- час
- до
- сьогоднішній
- Жетони
- завтра
- занадто
- топ
- кидати
- традиційний
- поїзд
- Навчання
- трансформатор
- Трансформатори
- Тенденції
- Довірений
- намагатися
- намагається
- при
- розумієш
- університет
- Університет Каліфорнії
- навряд чи
- us
- Використання
- використання
- використовуваний
- використання
- різний
- підприємство
- венчурний капітал
- Фірми венчурного капіталу
- дуже
- з
- було
- вода
- шлях..
- we
- Web
- Добробут
- були
- Що
- коли
- який
- ВООЗ
- чому
- волі
- з
- без
- Work
- робочий
- світ
- б
- Неправильно
- років
- ви
- вашу
- зефірнет