У поході до потужніших, швидших, менших і менш енергоспоживаючих систем закон Мура дав програмному забезпеченню безкоштовну поїздку протягом приблизно 30 років виключно на еволюцію напівпровідникових процесів. Обчислювальне обладнання щороку забезпечувало кращі показники продуктивності/площі/потужності, дозволяючи програмному забезпеченню розширювати складність і надавати більше можливостей без недоліків. Потім легкі перемоги стали менш легкими. Більш просунуті процеси продовжували забезпечувати більшу кількість воріт на одиницю площі, але виграш у продуктивності та потужності почав згасати. Оскільки наші очікування щодо інновацій не закінчилися, досягнення апаратної архітектури стали більш важливими для того, щоб усунути слабину.

Драйвери для збільшення кількості ядер
Перший крок у цьому напрямку використовував багатоядерні процесори для прискорення загальної пропускної здатності за допомогою потоків або віртуалізації поєднання одночасних завдань між ядрами, зменшуючи енергоспоживання за потреби шляхом простою або вимкнення неактивних ядер. Багатоядерність сьогодні є стандартом, і тенденція до багатоядерності (навіть більше процесорів на чіпі) вже очевидна в параметрах інстанцій сервера, доступних у хмарних платформах AWS, Azure, Alibaba та інших.
Багатоядерні/багатоядерні архітектури є кроком вперед, але паралелізм через кластери ЦП є грубим і має власні обмеження продуктивності та потужності завдяки закону Амдала. Архітектури стали більш різнорідними, додавши прискорювачі для зображення, аудіо та інших спеціальних потреб. Прискорювачі штучного інтелекту також підштовхнули дрібнозернистий паралелізм, перейшовши до систолічних масивів та інших предметно-спеціальних методів. Це працювало досить добре, доки не з’явився ChatGPT зі 175 мільярдами параметрів, а GPT-3 перетворився на GPT-4 зі 100 трильйонами параметрів – на порядки складніші за сучасні системи штучного інтелекту – запровадивши ще більше спеціалізованих функцій прискорення в прискорювачах штучного інтелекту.
На іншому фронті мультисенсорні системи в автомобільних додатках тепер інтегруються в єдині SoC для покращення обізнаності про навколишнє середовище та покращення PPA. Тут нові рівні автономності в автомобільній промисловості залежать від об’єднання вхідних сигналів від декількох типів датчиків в одному пристрої в підсистемах, що відтворюються в 2X, 4X або 8X.
За словами Міхала Сівінського (CMO в Arteris), місячні обговорення з кількома командами дизайнерів щодо широкого спектру додатків показують, що ці команди активно звертаються до вищих основних параметрів, щоб досягти можливостей, продуктивності та потужності. Він каже мені, що вони також бачать прискорення цієї тенденції. Удосконалення процесів все ще сприяє підрахунку воріт SoC, але відповідальність за досягнення цілей продуктивності та потужності тепер твердо в руках архітекторів.
Більше ядер, більше з’єднань
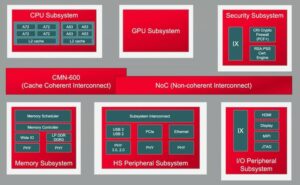
Більша кількість ядер на чіпі означає більше з’єднань даних між цими ядрами. У межах прискорювача між сусідніми елементами обробки, до локального кешу, до прискорювачів для розрідженої матриці та іншої спеціалізованої обробки. Додайте ієрархічний зв’язок між плитками прискорювача та шинами системного рівня. Додайте підключення для зберігання ваги на чіпі, декомпресії, трансляції, збору та повторного стиснення. Додайте підключення HBM для робочого кешу. За потреби додайте двигун синтезу.
Кластер керування на основі процесора має підключатися до кожної з цих реплікованих підсистем і до всіх звичайних функцій – кодеків, керування пам’яттю, острів безпеки та корінь довіри, якщо це доцільно, UCIe, якщо використовується багаточіплетна реалізація, PCIe для високосмугового вводу-виводу. і Ethernet або оптоволокно для роботи в мережі.
Це багато взаємозв’язків, які мають прямі наслідки для товарності продукту. У процесах нижче 16 нм інфраструктура NoC тепер займає 10-12% площі. Що ще важливіше, як магістраль зв’язку між ядрами, вона може мати значний вплив на продуктивність і потужність. Існує реальна небезпека того, що неоптимальна реалізація змарнує очікувану продуктивність архітектури та приріст потужності, або, що ще гірше, призведе до численних циклів перепроектування для конвергенції. Проте пошук гарної реалізації в складному плані SoC все ще залежить від повільної оптимізації методом проб і помилок у і без того жорстких графіках проектування. Нам потрібно зробити стрибок до фізично свідомого дизайну NoC, щоб гарантувати повну продуктивність і підтримку живлення від складних ієрархій NoC, і нам потрібно зробити цю оптимізацію швидше.
Фізично обізнані конструкції NoC відповідають закону Мура
Можливо, закон Мура ще не мертвий, але прогрес у продуктивності та потужності сьогодні походить від архітектури та з’єднання NoC, а не від процесу. Архітектура висуває більше ядер прискорювачів, більше прискорювачів усередині прискорювачів і більше реплікації підсистеми на кристалі. Усе це збільшує складність внутрішньокристального з’єднання. У міру того, як проекти збільшують кількість ядер і переходять до геометрії процесу 16 нм і нижче, численні міжсистемні з’єднання NoC, що охоплюють SoC та її підсистеми, можуть підтримувати повний потенціал цих складних конструкцій лише за умови оптимальної реалізації проти фізичних і часових обмежень – через фізично обізнану мережу. на дизайн мікросхеми.
Якщо вас також турбують ці тенденції, ви можете дізнатися більше про технологію Arteris FlexNoC 5 IP ТУТ.
Поділитися цим дописом через:
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://semiwiki.com/artificial-intelligence/326727-interconnect-under-the-spotlight-as-core-counts-accelerate/
- :є
- $UP
- 100
- a
- МЕНЮ
- прискорювати
- прискорення
- прискорення
- прискорювач
- прискорювачі
- через
- активно
- просунутий
- аванси
- проти
- AI
- Системи ШІ
- Alibaba
- ВСІ
- Дозволити
- вже
- та
- з'явився
- застосування
- відповідний
- архітектура
- ЕСТЬ
- ПЛОЩА
- AS
- At
- аудіо
- автомобільний
- доступний
- обізнаність
- AWS
- Лазурний
- ширина смуги
- BE
- ставати
- нижче
- між
- Мільярд
- віщати
- автобусів
- by
- cache
- CAN
- здатний
- ChatGPT
- чіп
- хмара
- кластер
- CMO
- Приходити
- Комунікація
- комплекс
- складність
- обчислення
- одночасно
- З'єднуватися
- Зв'язки
- зв'язок
- Наслідки
- обмеження
- триває
- контроль
- сходяться
- Core
- центральний процесор
- НЕБЕЗПЕЧНО
- дані
- мертвий
- доставляти
- поставляється
- залежить
- дизайн
- конструкцій
- пристрій
- різний
- прямий
- напрям
- обговорення
- вниз
- недоліки
- кожен
- Рано
- елементи
- двигун
- Навколишнє середовище
- Навіть
- Кожен
- еволюція
- еволюціонує
- Розширювати
- очікування
- очікуваний
- швидше
- риси
- виявлення
- твердо
- для
- Вперед
- Безкоштовна
- від
- перед
- Повний
- Функції
- злиття
- прибуток
- Цілі
- добре
- гарантувати
- Обробка
- Руки
- апаратні засоби
- Мати
- допомога
- тут
- Високий
- вище
- Шосе
- HTTPS
- зображення
- Impact
- реалізація
- реалізовані
- важливо
- поліпшений
- in
- неактивний
- Augmenter
- зростаючий
- Інфраструктура
- інновація
- екземпляр
- Інтеграція
- IP
- острів
- IT
- ЙОГО
- стрибати
- закон
- УЧИТЬСЯ
- рівень
- рівні
- рамки
- місцевий
- серія
- зробити
- управління
- березня
- Матриця
- макс-ширина
- Зустрічатися
- засідання
- пам'ять
- Метрика
- може бути
- місяць
- більше
- рухатися
- переміщення
- множинний
- Необхідність
- необхідний
- потреби
- мережу
- мережа
- Нові
- численний
- of
- on
- Опції
- замовлень
- Інше
- інші
- власний
- параметри
- продуктивність
- фізичний
- Фізично
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- пошта
- потенціал
- влада
- Живлення
- досить
- процес
- процеси
- обробка
- Product
- суто
- штовхнув
- Натискання
- діапазон
- швидше
- реальний
- зниження
- тиражувати
- копіювання
- відповідальність
- результат
- Ride
- корінь
- Безпека
- напівпровідник
- значний
- з
- один
- слабкий
- сповільнювати
- менше
- So
- Софтвер
- розріджена матриця
- спеціалізований
- Прожектор
- standard
- почалася
- Крок
- Як і раніше
- Стоп
- зберігання
- Запропонує
- підтримка
- система
- Systems
- завдання
- команди
- методи
- Технологія
- розповідає
- Що
- Команда
- Ці
- через
- пропускна здатність
- синхронізація
- до
- сьогодні
- сьогоднішній
- Усього:
- Trend
- Тенденції
- трильйон
- Довіряйте
- Поворот
- Типи
- при
- блок
- через
- вага
- ДОБРЕ
- який
- широкий
- Широкий діапазон
- волі
- Перемоги
- з
- в
- робочий
- рік
- років
- зефірнет