ความสำคัญของคลังข้อมูลและการวิเคราะห์ที่ดำเนินการบนแพลตฟอร์มคลังข้อมูลได้เพิ่มขึ้นอย่างต่อเนื่องในช่วงหลายปีที่ผ่านมา โดยธุรกิจจำนวนมากหันมาใช้ระบบเหล่านี้เป็นภารกิจสำคัญสำหรับการตัดสินใจในการดำเนินงานระยะสั้นและการวางแผนเชิงกลยุทธ์ระยะยาว ตามเนื้อผ้า คลังข้อมูลจะถูกรีเฟรชเป็นชุดตามรอบ ตัวอย่างเช่น รายเดือน รายสัปดาห์ หรือรายวัน เพื่อให้ธุรกิจสามารถรับข้อมูลเชิงลึกที่หลากหลายจากคลังข้อมูลเหล่านั้น
องค์กรหลายแห่งตระหนักว่าการนำเข้าข้อมูลแบบเกือบเรียลไทม์พร้อมกับการวิเคราะห์ขั้นสูงเปิดโอกาสใหม่ๆ ตัวอย่างเช่น สถาบันการเงินสามารถคาดการณ์ได้ว่าการทำธุรกรรมผ่านบัตรเครดิตเป็นการฉ้อฉลหรือไม่โดยการเรียกใช้โปรแกรมตรวจจับความผิดปกติในโหมดเกือบเรียลไทม์แทนที่จะเป็นโหมดแบทช์
ในโพสต์นี้เราจะแสดงวิธีการ อเมซอน Redshift สามารถนำเสนอการประมวลผลแบบสตรีมและการคาดการณ์ของแมชชีนเลิร์นนิง (ML) ทั้งหมดในแพลตฟอร์มเดียว
Amazon Redshift เป็นคลังข้อมูลบนคลาวด์ที่รวดเร็ว ปรับขนาดได้ ปลอดภัย และมีการจัดการเต็มรูปแบบ ซึ่งทำให้การวิเคราะห์ข้อมูลทั้งหมดของคุณเป็นเรื่องง่ายและคุ้มค่าโดยใช้ SQL มาตรฐาน
Amazon RedShift ML ทำให้นักวิเคราะห์ข้อมูลและนักพัฒนาฐานข้อมูลสามารถสร้าง ฝึกฝน และใช้โมเดล ML ได้อย่างง่ายดายโดยใช้คำสั่ง SQL ที่คุ้นเคยในคลังข้อมูล Amazon Redshift
เรารู้สึกตื่นเต้นที่จะเปิดตัว การส่งผ่านข้อมูลสตรีมมิ่งของ Amazon Redshift for สตรีมข้อมูล Amazon Kinesis และ Amazon Managed Streaming สำหรับ Apache Kafka (Amazon MSK) ซึ่งช่วยให้คุณสามารถนำเข้าข้อมูลได้โดยตรงจากสตรีมข้อมูล Kinesis หรือหัวข้อ Kafka โดยไม่ต้องจัดลำดับข้อมูลใน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน S3). การนำเข้าการสตรีมของ Amazon Redshift ช่วยให้คุณมีเวลาแฝงต่ำตามลำดับวินาที ในขณะที่นำเข้าข้อมูลหลายร้อยเมกะไบต์ไปยังคลังข้อมูลของคุณ
โพสต์นี้สาธิตวิธีการที่ Amazon Redshift ซึ่งเป็นคลังข้อมูลบนคลาวด์ช่วยให้คุณสร้างการคาดการณ์ ML แบบเกือบเรียลไทม์ได้โดยใช้การนำเข้าการสตรีมของ Amazon Redshift และคุณสมบัติ Redshift ML ด้วยภาษา SQL ที่คุ้นเคย
ภาพรวมโซลูชัน
เมื่อทำตามขั้นตอนที่ระบุไว้ในโพสต์นี้ คุณจะสามารถตั้งค่าแอปพลิเคชันผู้ผลิตสตรีมเมอร์บน อเมซอน อีลาสติก คอมพิวท์ คลาวด์ อินสแตนซ์ (Amazon EC2) ที่จำลองธุรกรรมบัตรเครดิตและพุชข้อมูลไปยัง Kinesis Data Streams แบบเรียลไทม์ คุณตั้งค่ามุมมองที่เป็นรูปธรรมของ Amazon Redshift Streaming Ingestion บน Amazon Redshift ซึ่งได้รับข้อมูลการสตรีม คุณฝึกฝนและสร้างโมเดล Redshift ML เพื่อสร้างการอนุมานตามเวลาจริงกับข้อมูลการสตรีม
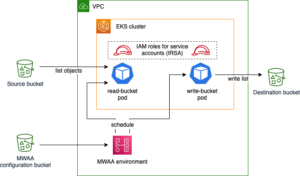
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรมและโฟลว์กระบวนการ
กระบวนการทีละขั้นตอนมีดังนี้:
- อินสแตนซ์ EC2 จำลองแอปพลิเคชันธุรกรรมบัตรเครดิต ซึ่งจะแทรกธุรกรรมบัตรเครดิตลงในสตรีมข้อมูล Kinesis
- สตรีมข้อมูลจะเก็บข้อมูลธุรกรรมบัตรเครดิตที่เข้ามา
- มุมมองที่เป็นรูปธรรมของ Amazon Redshift Streaming Ingestion จะถูกสร้างขึ้นด้านบนของสตรีมข้อมูล ซึ่งจะนำเข้าข้อมูลการสตรีมไปยัง Amazon Redshift โดยอัตโนมัติ
- คุณสร้าง ฝึก และปรับใช้โมเดล ML โดยใช้ Redshift ML โมเดล Redshift ML ได้รับการฝึกโดยใช้ข้อมูลธุรกรรมในอดีต
- คุณแปลงข้อมูลการสตรีมและสร้างการคาดการณ์ ML
- คุณสามารถแจ้งเตือนลูกค้าหรืออัปเดตแอปพลิเคชันเพื่อลดความเสี่ยง
การฝึกปฏิบัตินี้ใช้ข้อมูลการสตรีมธุรกรรมบัตรเครดิต ข้อมูลธุรกรรมบัตรเครดิตเป็นข้อมูลสมมติและอ้างอิงจาก จำลอง. ชุดข้อมูลลูกค้ายังเป็นข้อมูลสมมติและสร้างขึ้นด้วยฟังก์ชันข้อมูลแบบสุ่ม
เบื้องต้น
- สร้างคลัสเตอร์ Amazon Redshift.
- กำหนดค่าคลัสเตอร์เพื่อใช้ Redshift ML.
- สร้างบัญชีตัวแทน an AWS Identity และการจัดการการเข้าถึง (IAM) ผู้ใช้
- อัปเดตบทบาท IAM ที่แนบมากับคลัสเตอร์ Redshift เพื่อรวมสิทธิ์ในการเข้าถึงสตรีมข้อมูล Kinesis สำหรับข้อมูลเพิ่มเติมเกี่ยวกับนโยบายที่จำเป็น โปรดดูที่ เริ่มต้นใช้งานการส่งผ่านข้อมูลแบบสตรีม.
- สร้างอินสแตนซ์ EC5.4 ขนาด m2xlarge. เราทดสอบแอปพลิเคชัน Producer ด้วยอินสแตนซ์ m5.4xlarge แต่คุณสามารถใช้อินสแตนซ์ประเภทอื่นได้ฟรี เมื่อสร้างอินสแตนซ์ ให้ใช้ไฟล์ amzn2-ami-kernel-5.10-hvm-2.0.20220426.0-x86_64-gp2 อามิ
- เพื่อให้แน่ใจว่า Python3 ได้รับการติดตั้งในอินสแตนซ์ EC2 ให้รันคำสั่งต่อไปนี้เพื่อตรวจสอบเวอร์ชันของ Python ของคุณ (โปรดทราบว่าสคริปต์การแยกข้อมูลใช้งานได้กับ Python 3 เท่านั้น):
- ติดตั้งแพ็คเกจอ้างอิงต่อไปนี้เพื่อรันโปรแกรมจำลอง:
- กำหนดค่า Amazon EC2 โดยใช้ตัวแปร เช่น ข้อมูลรับรอง AWS ที่สร้างขึ้นสำหรับผู้ใช้ IAM ที่สร้างขึ้นในขั้นตอนที่ 3 ด้านบน ภาพหน้าจอต่อไปนี้แสดงตัวอย่างการใช้ aws กำหนดค่า.

ตั้งค่าสตรีมข้อมูล Kinesis
Amazon Kinesis Data Streams เป็นบริการสตรีมข้อมูลตามเวลาจริงที่ปรับขนาดได้จำนวนมากและทนทาน สามารถเก็บข้อมูลกิกะไบต์ต่อวินาทีอย่างต่อเนื่องจากแหล่งข้อมูลหลายแสนแห่ง เช่น การคลิกสตรีมของเว็บไซต์ การสตรีมเหตุการณ์ฐานข้อมูล ธุรกรรมทางการเงิน ฟีดโซเชียลมีเดีย บันทึกด้านไอที และเหตุการณ์การติดตามตำแหน่ง ข้อมูลที่รวบรวมมีหน่วยเป็นมิลลิวินาทีเพื่อเปิดใช้งานกรณีการใช้งานการวิเคราะห์ตามเวลาจริง เช่น แดชบอร์ดตามเวลาจริง การตรวจจับความผิดปกติแบบเรียลไทม์ การกำหนดราคาแบบไดนามิก และอื่นๆ เราใช้ Kinesis Data Streams เพราะเป็นโซลูชันแบบไร้เซิร์ฟเวอร์ที่สามารถปรับขนาดตามการใช้งาน
สร้างสตรีมข้อมูล Kinesis
ก่อนอื่น คุณต้องสร้างสตรีมข้อมูล Kinesis เพื่อรับข้อมูลการสตรีม:
- บนคอนโซล Amazon Kinesis ให้เลือก สตรีมข้อมูล ในบานหน้าต่างนำทาง
- Choose สร้างสตรีมข้อมูล.
- สำหรับ ชื่อสตรีมข้อมูลป้อน
cust-payment-txn-stream. - สำหรับ โหมดความจุให้เลือก ตามความต้องการ.

- สำหรับตัวเลือกที่เหลือ ให้เลือกตัวเลือกเริ่มต้นและทำตามคำแนะนำเพื่อตั้งค่าให้เสร็จสมบูรณ์
- เก็บ ARN สำหรับสตรีมข้อมูลที่สร้างขึ้นเพื่อใช้ในส่วนถัดไปเมื่อกำหนดนโยบาย IAM ของคุณ

ตั้งค่าการอนุญาต
สำหรับแอปพลิเคชันการสตรีมเพื่อเขียนไปยัง Kinesis Data Streams แอปพลิเคชันนั้นจำเป็นต้องมีสิทธิ์เข้าถึง Kinesis คุณสามารถใช้คำชี้แจงนโยบายต่อไปนี้เพื่อให้สิทธิ์แก่กระบวนการจำลองที่คุณตั้งค่าไว้ในส่วนถัดไปในการเข้าถึงสตรีมข้อมูล ใช้ ARN ของสตรีมข้อมูลที่คุณบันทึกไว้ในขั้นตอนที่แล้ว
กำหนดค่าผู้ผลิตสตรีม
ก่อนที่เราจะใช้ข้อมูลการสตรีมใน Amazon Redshift เราจำเป็นต้องมีแหล่งข้อมูลการสตรีมที่เขียนข้อมูลไปยังสตรีมข้อมูล Kinesis โพสต์นี้ใช้ตัวสร้างข้อมูลที่สร้างขึ้นเองและ AWS SDK สำหรับ Python (Boto3) เพื่อเผยแพร่ข้อมูลไปยังสตรีมข้อมูล สำหรับคำแนะนำในการตั้งค่า โปรดดูที่ เครื่องจำลองผู้ผลิต. กระบวนการจำลองนี้เผยแพร่ข้อมูลการสตรีมไปยังสตรีมข้อมูลที่สร้างขึ้นในขั้นตอนก่อนหน้า (cust-payment-txn-stream).
กำหนดค่าผู้ใช้สตรีม
ส่วนนี้พูดถึงการกำหนดค่าผู้ใช้สตรีม (มุมมองการนำเข้าการสตรีม Amazon Redshift)
Amazon Redshift Streaming Ingestion ให้เวลาแฝงต่ำและความเร็วสูงในการนำเข้าข้อมูลการสตรีมจาก Kinesis Data Streams ไปยังมุมมองที่เป็นรูปธรรมของ Amazon Redshift คุณสามารถกำหนดค่าคลัสเตอร์ Amazon Redshift ของคุณเพื่อเปิดใช้งานการส่งผ่านข้อมูลแบบสตรีมมิ่ง และสร้างมุมมองที่เป็นรูปธรรมด้วยการรีเฟรชอัตโนมัติ โดยใช้คำสั่ง SQL ตามที่อธิบายไว้ใน การสร้างมุมมองที่เป็นรูปธรรมใน Amazon Redshift. กระบวนการรีเฟรชมุมมอง Materialized อัตโนมัติจะนำเข้าข้อมูลการสตรีมหลายร้อยเมกะไบต์ต่อวินาทีจาก Kinesis Data Streams ไปยัง Amazon Redshift ส่งผลให้เข้าถึงข้อมูลภายนอกได้อย่างรวดเร็วและได้รับการรีเฟรชอย่างรวดเร็ว
หลังจากสร้าง Materialized View แล้ว คุณสามารถเข้าถึงข้อมูลของคุณจากสตรีมข้อมูลได้โดยใช้ SQL และทำให้ไปป์ไลน์ข้อมูลของคุณง่ายขึ้นด้วยการสร้างมุมมอง Materialized ที่ด้านบนสุดของสตรีมโดยตรง
ทำตามขั้นตอนต่อไปนี้เพื่อกำหนดค่า Amazon Redshift การสตรีมมุมมองจริง:
- ใน IAM Console เลือกนโยบายในบานหน้าต่างนำทาง
- Choose สร้างนโยบาย.
- สร้างนโยบาย IAM ใหม่ที่เรียกว่า
KinesisStreamPolicy. สำหรับข้อกำหนดนโยบายการสตรีม โปรดดูที่ เริ่มต้นใช้งานการส่งผ่านข้อมูลแบบสตรีม. - ในบานหน้าต่างนำทาง เลือก บทบาท.
- เลือกสร้างบทบาท
- เลือก บริการ AWS และเลือก Redshift และ Redshift ปรับแต่งได้.
- สร้างบทบาทใหม่ที่เรียกว่า
redshift-streaming-roleพร้อมแนบกรมธรรม์KinesisStreamPolicy. - สร้างสคีมาภายนอกเพื่อแมปกับ Kinesis Data Streams :
ตอนนี้คุณสามารถสร้างมุมมองที่เป็นรูปธรรมเพื่อใช้ข้อมูลสตรีม คุณสามารถใช้ประเภทข้อมูล SUPER เพื่อจัดเก็บเพย์โหลดในรูปแบบ JSON หรือใช้ฟังก์ชัน Amazon Redshift JSON เพื่อแยกวิเคราะห์ข้อมูล JSON ออกเป็นแต่ละคอลัมน์ สำหรับโพสต์นี้ เราใช้วิธีที่ XNUMX เนื่องจากมีการกำหนดสคีมาไว้อย่างดี
- สร้างมุมมองที่เป็นรูปธรรมของการนำเข้าสตรีมมิง
cust_payment_tx_stream. ด้วยการระบุ AUTO REFRESH YES ในโค้ดต่อไปนี้ คุณสามารถเปิดใช้การรีเฟรชอัตโนมัติของมุมมองการส่งผ่านข้อมูลแบบสตรีมมิ่ง ซึ่งช่วยประหยัดเวลาโดยหลีกเลี่ยงการสร้างไปป์ไลน์ข้อมูล:
โปรดทราบว่า json_extract_path_text มีความยาวจำกัดที่ 64 KB นอกจากนี้ from_varbye ยังกรองบันทึกที่มีขนาดใหญ่กว่า 65KB
- รีเฟรชข้อมูล
Amazon Redshift สตรีมมุมมองที่เป็นรูปธรรมได้รับการรีเฟรชอัตโนมัติโดย Amazon Redshift สำหรับคุณ ด้วยวิธีนี้ คุณไม่ต้องกังวลเกี่ยวกับความเก่าของข้อมูล ด้วยการรีเฟรชอัตโนมัติของ Materialized View ข้อมูลจะถูกโหลดไปยัง Amazon Redshift โดยอัตโนมัติเมื่อพร้อมใช้งานในสตรีม หากคุณเลือกที่จะดำเนินการนี้ด้วยตนเอง ให้ใช้คำสั่งต่อไปนี้:
- ทีนี้ลองค้นหาการสตรีมข้อมูลจริงเพื่อดูข้อมูลตัวอย่าง:

- ตรวจสอบจำนวนบันทึกที่อยู่ในมุมมองการสตรีมตอนนี้:

ตอนนี้คุณตั้งค่ามุมมองการนำเข้าการสตรีมของ Amazon Redshift เสร็จแล้ว ซึ่งจะได้รับการอัปเดตอย่างต่อเนื่องด้วยข้อมูลธุรกรรมบัตรเครดิตที่เข้ามา ในการตั้งค่าของฉัน ฉันพบว่ามีเรกคอร์ดประมาณ 67,000 รายการถูกดึงเข้าสู่มุมมองการสตรีมในเวลาที่ฉันรันคิวรีแบบเลือกจำนวน หมายเลขนี้อาจแตกต่างออกไปสำหรับคุณ
เรดชิฟต์ ML
ด้วย Redshift ML คุณสามารถนำโมเดล ML ที่ฝึกไว้ล่วงหน้าหรือสร้างโมเดลขึ้นมาเอง สำหรับข้อมูลเพิ่มเติม โปรดดูที่ การใช้แมชชีนเลิร์นนิงใน Amazon Redshift.
ในโพสต์นี้ เราฝึกและสร้างโมเดล ML โดยใช้ชุดข้อมูลย้อนหลัง ข้อมูลประกอบด้วย tx_fraud ฟิลด์ที่ตั้งค่าสถานะการทำธุรกรรมในอดีตว่าเป็นการฉ้อโกงหรือไม่ เราสร้างโมเดล ML ภายใต้การดูแลโดยใช้ Redshift Auto ML ซึ่งเรียนรู้จากชุดข้อมูลนี้และคาดการณ์ธุรกรรมที่เข้ามาเมื่อธุรกรรมเหล่านั้นถูกเรียกใช้ผ่านฟังก์ชันการคาดคะเน
ในส่วนต่อไปนี้ เราจะแสดงวิธีการตั้งค่าชุดข้อมูลย้อนหลังและข้อมูลลูกค้า
โหลดชุดข้อมูลประวัติ
ตารางประวัติมีเขตข้อมูลมากกว่าแหล่งข้อมูลการสตรีม ฟิลด์เหล่านี้มีการใช้จ่ายล่าสุดของลูกค้าและคะแนนความเสี่ยงของเทอร์มินัล เช่น จำนวนธุรกรรมฉ้อโกงที่คำนวณโดยการแปลงข้อมูลการสตรีม นอกจากนี้ยังมีตัวแปรตามหมวดหมู่ เช่น การทำธุรกรรมในช่วงวันหยุดสุดสัปดาห์หรือการทำธุรกรรมในช่วงกลางคืน
ในการโหลดข้อมูลประวัติ ให้รันคำสั่งโดยใช้ โปรแกรมแก้ไขแบบสอบถาม Amazon Redshift.
สร้างตารางประวัติการทำธุรกรรมด้วยรหัสต่อไปนี้ สามารถดู DDL ได้ที่ GitHub.
ตรวจสอบจำนวนธุรกรรมที่โหลด:
ตรวจสอบแนวโน้มธุรกรรมการฉ้อโกงและไม่ฉ้อโกงรายเดือน:
สร้างและโหลดข้อมูลลูกค้า
ตอนนี้เราสร้างตารางลูกค้าและโหลดข้อมูล ซึ่งมีอีเมลและหมายเลขโทรศัพท์ของลูกค้า รหัสต่อไปนี้สร้างตาราง โหลดข้อมูล และตัวอย่างตาราง ตาราง DDL มีอยู่บน GitHub.
ข้อมูลทดสอบของเรามีลูกค้าประมาณ 5,000 ราย ภาพหน้าจอต่อไปนี้แสดงตัวอย่างข้อมูลลูกค้า

สร้างโมเดล ML
ตารางธุรกรรมบัตรย้อนหลังของเรามีข้อมูล 6 เดือน ซึ่งตอนนี้เราใช้เพื่อฝึกและทดสอบโมเดล ML
โมเดลใช้ฟิลด์ต่อไปนี้เป็นอินพุต:
เราได้รับ tx_fraud เป็นเอาต์พุต
เราแบ่งข้อมูลนี้เป็นชุดข้อมูลการฝึกอบรมและการทดสอบ ธุรกรรมระหว่าง 2022-04-01 ถึง 2022-07-31 ใช้สำหรับชุดฝึกอบรม การทำธุรกรรมระหว่าง 2022-08-01 ถึง 2022-09-30 ใช้สำหรับชุดทดสอบ
มาสร้างโมเดล ML โดยใช้ SQL ที่คุ้นเคยกัน สร้างคำสั่ง MODEL. เราใช้รูปแบบพื้นฐานของคำสั่ง Redshift ML วิธีการต่อไปนี้ใช้ ระบบนำร่องอัตโนมัติของ Amazon SageMakerซึ่งดำเนินการเตรียมข้อมูล วิศวกรรมคุณลักษณะ การเลือกรุ่น และการฝึกอบรมให้คุณโดยอัตโนมัติ ระบุชื่อบัคเก็ต S3 ของคุณที่มีรหัส
ฉันเรียกรุ่น ML ว่า Cust_cc_txn_fdและฟังก์ชันการทำนายเป็น fn_customer_cc_fd. ส่วนคำสั่ง FROM แสดงคอลัมน์อินพุตจากตารางประวัติ public.cust_payment_tx_history. พารามิเตอร์เป้าหมายถูกกำหนดเป็น tx_fraudซึ่งเป็นตัวแปรเป้าหมายที่เราพยายามทำนาย IAM_Role ถูกตั้งค่าเป็นค่าเริ่มต้นเนื่องจากคลัสเตอร์ได้รับการกำหนดค่าด้วยบทบาทนี้ ถ้าไม่ คุณต้องระบุบทบาท ARN ของคลัสเตอร์ Amazon Redshift ของคุณ ฉันตั้ง max_runtime เป็น 3,600 วินาที ซึ่งเป็นเวลาที่เราให้กับ SageMaker ในการดำเนินการให้เสร็จสิ้น Redshift ML ปรับใช้โมเดลที่ดีที่สุดซึ่งระบุในกรอบเวลานี้
ขึ้นอยู่กับความซับซ้อนของโมเดลและจำนวนข้อมูล อาจใช้เวลาสักครู่เพื่อให้โมเดลพร้อมใช้งาน หากคุณพบว่าการเลือกรุ่นของคุณไม่เสร็จสมบูรณ์ ให้เพิ่มค่าสำหรับ max_runtime. คุณสามารถตั้งค่าสูงสุด 9999
คำสั่ง CREATE MODEL ถูกรันแบบอะซิงโครนัส ซึ่งหมายความว่ารันอยู่เบื้องหลัง คุณสามารถใช้ โชว์โมเดล คำสั่งเพื่อดูสถานะของโมเดล เมื่อสถานะแสดงเป็นพร้อม แสดงว่าโมเดลได้รับการฝึกอบรมและปรับใช้แล้ว
ภาพหน้าจอต่อไปนี้แสดงผลลัพธ์ของเรา



จากผลลัพธ์ ฉันเห็นว่าโมเดลได้รับการยอมรับอย่างถูกต้องว่าเป็น BinaryClassification, และ F1 ได้รับเลือกเป็นวัตถุประสงค์ เดอะ คะแนน F1 เป็นเมตริกที่พิจารณาทั้งสองอย่าง ความแม่นยำและความจำ. จะส่งกลับค่าระหว่าง 1 (ความแม่นยำที่สมบูรณ์แบบและการเรียกคืน) และ 0 (คะแนนต่ำสุดที่เป็นไปได้) ในกรณีของฉันคือ 0.91 ยิ่งค่าสูงเท่าใด ประสิทธิภาพของโมเดลก็จะยิ่งดีขึ้นเท่านั้น
ลองทดสอบโมเดลนี้ด้วยชุดข้อมูลทดสอบ เรียกใช้คำสั่งต่อไปนี้ ซึ่งดึงข้อมูลการคาดการณ์ตัวอย่าง:

เราเห็นว่าค่าบางอย่างตรงกันและค่าบางอย่างไม่ตรงกัน ลองเปรียบเทียบการคาดการณ์กับความจริงพื้นฐาน:

เราตรวจสอบว่าโมเดลใช้งานได้และคะแนน F1 อยู่ในเกณฑ์ดี เรามาสร้างการคาดการณ์เกี่ยวกับข้อมูลการสตรีมกัน
ทำนายธุรกรรมที่ฉ้อโกง
เนื่องจากโมเดล Redshift ML พร้อมใช้งาน เราจึงสามารถใช้โมเดลดังกล่าวเพื่อเรียกใช้การคาดการณ์เทียบกับการนำเข้าข้อมูลการสตรีม ชุดข้อมูลที่ผ่านมามีฟิลด์มากกว่าที่เรามีในแหล่งข้อมูลการสตรีม แต่เป็นเพียงการวัดความใหม่และความถี่รอบตัวลูกค้าและความเสี่ยงของเทอร์มินัลสำหรับธุรกรรมที่เป็นการฉ้อโกง
เราสามารถใช้การแปลงบนข้อมูลการสตรีมได้อย่างง่ายดายโดยการฝัง SQL ไว้ในมุมมอง สร้าง มุมมองแรกซึ่งรวบรวมข้อมูลการสตรีมในระดับลูกค้า จากนั้นสร้าง มุมมองที่สองซึ่งรวบรวมข้อมูลการสตรีมที่ระดับเทอร์มินัล และ มุมมองที่สามซึ่งรวมข้อมูลธุรกรรมขาเข้ากับข้อมูลรวมของลูกค้าและเทอร์มินัล และเรียกใช้ฟังก์ชันการคาดการณ์ทั้งหมดในที่เดียว รหัสสำหรับมุมมองที่สามมีดังนี้:
เรียกใช้คำสั่ง SELECT ในมุมมอง:
เมื่อคุณเรียกใช้คำสั่ง SELECT ซ้ำๆ ธุรกรรมบัตรเครดิตล่าสุดจะผ่านการแปลงร่างและการคาดคะเน ML ในเวลาใกล้เคียงเรียลไทม์
สิ่งนี้แสดงให้เห็นถึงพลังของ Amazon Redshift—ด้วยคำสั่ง SQL ที่ใช้งานง่าย คุณสามารถแปลงข้อมูลการสตรีมได้โดยใช้ฟังก์ชันหน้าต่างที่ซับซ้อนและใช้โมเดล ML เพื่อคาดการณ์ธุรกรรมที่เป็นการฉ้อโกงทั้งหมดในขั้นตอนเดียว โดยไม่ต้องสร้างไปป์ไลน์ข้อมูลที่ซับซ้อนหรือสร้างและจัดการ โครงสร้างพื้นฐานเพิ่มเติม
ขยายโซลูชัน
เนื่องจากการสตรีมข้อมูลและการคาดคะเน ML เกิดขึ้นในเวลาเกือบเรียลไทม์ คุณจึงสร้างกระบวนการทางธุรกิจเพื่อแจ้งเตือนลูกค้าได้โดยใช้ บริการแจ้งเตือนแบบง่ายของ Amazon (Amazon SNS) หรือคุณสามารถล็อคบัญชีบัตรเครดิตของลูกค้าในระบบปฏิบัติการ
โพสต์นี้ไม่ได้ลงรายละเอียดเกี่ยวกับการดำเนินการเหล่านี้ แต่หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับการสร้างโซลูชันที่ขับเคลื่อนด้วยเหตุการณ์โดยใช้ Amazon Redshift โปรดดูข้อมูลต่อไปนี้ พื้นที่เก็บข้อมูล GitHub.
ทำความสะอาด
เพื่อหลีกเลี่ยงค่าใช้จ่ายในอนาคต ให้ลบทรัพยากรที่สร้างขึ้นเป็นส่วนหนึ่งของโพสต์นี้
สรุป
ในโพสต์นี้ เราได้สาธิตวิธีตั้งค่าสตรีมข้อมูล Kinesis กำหนดค่าโปรดิวเซอร์และเผยแพร่ข้อมูลไปยังสตรีม จากนั้นสร้างมุมมอง Amazon Redshift Streaming Ingestion และสืบค้นข้อมูลใน Amazon Redshift หลังจากที่ข้อมูลอยู่ในคลัสเตอร์ Amazon Redshift แล้ว เราได้สาธิตวิธีฝึกโมเดล ML และสร้างฟังก์ชันการคาดการณ์และนำไปใช้กับข้อมูลการสตรีมเพื่อสร้างการคาดการณ์ที่ใกล้เคียงกับเวลาจริง
หากคุณมีข้อเสนอแนะหรือคำถามใด ๆ โปรดแสดงความคิดเห็น
เกี่ยวกับผู้เขียน
 ภาณุ ปิตตัมปัลลี เป็น Analytics Specialist Solutions Architect ซึ่งตั้งอยู่ในเมืองดัลลาส เขาเชี่ยวชาญในการสร้างโซลูชันการวิเคราะห์ ภูมิหลังของเขาอยู่ในคลังข้อมูล—สถาปัตยกรรม การพัฒนา และการบริหาร เขาอยู่ในสายงานข้อมูลและการวิเคราะห์มานานกว่า 15 ปี
ภาณุ ปิตตัมปัลลี เป็น Analytics Specialist Solutions Architect ซึ่งตั้งอยู่ในเมืองดัลลาส เขาเชี่ยวชาญในการสร้างโซลูชันการวิเคราะห์ ภูมิหลังของเขาอยู่ในคลังข้อมูล—สถาปัตยกรรม การพัฒนา และการบริหาร เขาอยู่ในสายงานข้อมูลและการวิเคราะห์มานานกว่า 15 ปี
 ประวีณ กวีนิพนธ์ เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญด้านการวิเคราะห์อาวุโสที่ AWS จากดัลลัส เขาช่วยลูกค้าสร้างโซลูชันการวิเคราะห์ที่มีประสิทธิภาพ ประสิทธิภาพ และปรับขนาดได้ เขาทำงานกับการสร้างฐานข้อมูลและโซลูชันคลังข้อมูลมากว่า 15 ปี
ประวีณ กวีนิพนธ์ เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญด้านการวิเคราะห์อาวุโสที่ AWS จากดัลลัส เขาช่วยลูกค้าสร้างโซลูชันการวิเคราะห์ที่มีประสิทธิภาพ ประสิทธิภาพ และปรับขนาดได้ เขาทำงานกับการสร้างฐานข้อมูลและโซลูชันคลังข้อมูลมากว่า 15 ปี
 ริเทช กุมาร สิงหา เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญด้านการวิเคราะห์จากซานฟรานซิสโก เขาช่วยลูกค้าสร้างคลังข้อมูลที่ปรับขนาดได้และโซลูชันบิ๊กดาต้ามานานกว่า 16 ปี เขาชอบที่จะออกแบบและสร้างโซลูชันแบบ end-to-end ที่มีประสิทธิภาพบน AWS ในเวลาว่าง เขาชอบอ่านหนังสือ เดินเล่น และเล่นโยคะ
ริเทช กุมาร สิงหา เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญด้านการวิเคราะห์จากซานฟรานซิสโก เขาช่วยลูกค้าสร้างคลังข้อมูลที่ปรับขนาดได้และโซลูชันบิ๊กดาต้ามานานกว่า 16 ปี เขาชอบที่จะออกแบบและสร้างโซลูชันแบบ end-to-end ที่มีประสิทธิภาพบน AWS ในเวลาว่าง เขาชอบอ่านหนังสือ เดินเล่น และเล่นโยคะ
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/near-real-time-fraud-detection-using-amazon-redshift-streaming-ingestion-with-amazon-kinesis-data-streams-and-amazon-redshift-ml/
- 000
- ลูกค้า 000 ราย
- 1
- 10
- 100
- 11
- 67
- 7
- 9
- a
- สามารถ
- เกี่ยวกับเรา
- ข้างบน
- เข้า
- ลงชื่อเข้าใช้
- บรรลุ
- การกระทำ
- เพิ่มเติม
- การบริหาร
- สูง
- หลังจาก
- กับ
- เตือนภัย
- ทั้งหมด
- ช่วยให้
- อเมซอน
- Amazon EC2
- อเมซอน Kinesis
- จำนวน
- นักวิเคราะห์
- วิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- และ
- การตรวจจับความผิดปกติ
- อาปาเช่
- การใช้งาน
- ใช้
- การประยุกต์ใช้
- สถาปัตยกรรม
- รอบ
- แนบ
- รถยนต์
- อัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- หลีกเลี่ยง
- AWS
- พื้นหลัง
- ตาม
- ขั้นพื้นฐาน
- เพราะ
- จะกลายเป็น
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- ใหญ่
- ข้อมูลขนาดใหญ่
- นำมาซึ่ง
- สร้าง
- การก่อสร้าง
- ธุรกิจ
- กระบวนการทางธุรกิจ
- ธุรกิจ
- โทรศัพท์
- ที่เรียกว่า
- โทร
- จับ
- บัตร
- กรณี
- กรณี
- ตัวอักษร
- โหลด
- ตรวจสอบ
- Choose
- เมือง
- เมฆ
- Cluster
- รหัส
- คอลัมน์
- รวม
- มา
- ความคิดเห็น
- เปรียบเทียบ
- สมบูรณ์
- เสร็จสิ้น
- ซับซ้อน
- ความซับซ้อน
- คำนวณ
- พิจารณา
- ปลอบใจ
- บริโภค
- ผู้บริโภค
- มี
- ค่าใช้จ่ายที่มีประสิทธิภาพ
- ได้
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- หนังสือรับรอง
- เครดิต
- บัตรเครดิต
- ลูกค้า
- ข้อมูลลูกค้า
- ลูกค้า
- รอบ
- ประจำวัน
- ดัลลัส
- ข้อมูล
- การเตรียมข้อมูล
- คลังข้อมูล
- คลังข้อมูล
- ฐานข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- วันที่
- การตัดสินใจ
- ค่าเริ่มต้น
- การกำหนด
- ส่งมอบ
- แสดงให้เห็นถึง
- ขึ้นอยู่กับ
- ปรับใช้
- นำไปใช้
- Deploys
- อธิบาย
- ออกแบบ
- รายละเอียด
- การตรวจพบ
- นักพัฒนา
- พัฒนาการ
- ต่าง
- โดยตรง
- ไม่
- การทำ
- Dont
- Dow
- พลวัต
- อย่างง่ายดาย
- ง่ายต่อการใช้งาน
- ผล
- ที่มีประสิทธิภาพ
- อีเมล
- ทำให้สามารถ
- ช่วยให้
- จบสิ้น
- ชั้นเยี่ยม
- เข้าสู่
- อีเธอร์ (ETH)
- เหตุการณ์
- เหตุการณ์
- ตัวอย่าง
- ตื่นเต้น
- ภายนอก
- การสกัด
- f1
- คุ้นเคย
- FAST
- ลักษณะ
- คุณสมบัติ
- ข้อเสนอแนะ
- สนาม
- สาขา
- ฟิลเตอร์
- ทางการเงิน
- หา
- ธง
- ไหล
- ปฏิบัติตาม
- ดังต่อไปนี้
- ดังต่อไปนี้
- ฟอร์ม
- รูป
- พบ
- FRAME
- ฟรานซิส
- การหลอกลวง
- การตรวจจับการฉ้อโกง
- ฟรี
- เวลา
- ราคาเริ่มต้นที่
- อย่างเต็มที่
- ฟังก์ชัน
- ฟังก์ชั่น
- อนาคต
- สร้าง
- สร้าง
- การสร้าง
- เครื่องกำเนิดไฟฟ้า
- ได้รับ
- ให้
- Go
- ดี
- ให้
- พื้น
- บัญชีกลุ่ม
- มี
- ช่วย
- จะช่วยให้
- สูงกว่า
- เน้น
- ทางประวัติศาสตร์
- ประวัติ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- HTTPS
- ร้อย
- AMI
- ระบุ
- เอกลักษณ์
- ความสำคัญ
- in
- ประกอบด้วย
- ขาเข้า
- เพิ่ม
- ที่เพิ่มขึ้น
- เป็นรายบุคคล
- ข้อมูล
- โครงสร้างพื้นฐาน
- อินพุต
- แทรก
- ข้อมูลเชิงลึก
- ติดตั้ง
- ตัวอย่าง
- สถาบัน
- คำแนะนำการใช้
- สนใจ
- IT
- ร่วม
- JSON
- Kafka
- สตรีมข้อมูล Kinesis
- ภาษา
- ที่มีขนาดใหญ่
- ความแอบแฝง
- ล่าสุด
- เปิดตัว
- การเรียนรู้
- ทิ้ง
- ความยาว
- ชั้น
- LIMIT
- การ จำกัด
- โหลด
- โหลด
- ระยะยาว
- ต่ำ
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- ทำ
- ทำให้
- การจัดการ
- การจัดการ
- ด้วยมือ
- หลาย
- แผนที่
- อย่างมากมาย
- การจับคู่
- matplotlib
- แม็กซ์
- วิธี
- ภาพบรรยากาศ
- วิธี
- เมตริก
- ตัวชี้วัด
- บรรเทา
- ML
- โหมด
- แบบ
- โมเดล
- รายเดือน
- เดือน
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ย้าย
- ชื่อ
- การเดินเรือ
- จำเป็นต้อง
- ความต้องการ
- ใหม่
- ถัดไป
- การประกาศ
- จำนวน
- มึน
- วัตถุประสงค์
- ONE
- เปิด
- การดำเนินการ
- การดำเนินงาน
- การดำเนินการ
- โอกาส
- Options
- ใบสั่ง
- องค์กร
- อื่นๆ
- ที่ระบุไว้
- แพคเกจ
- หมีแพนด้า
- บานหน้าต่าง
- พารามิเตอร์
- ส่วนหนึ่ง
- สมบูรณ์
- ดำเนินการ
- การปฏิบัติ
- ดำเนินการ
- สิทธิ์
- โทรศัพท์
- สถานที่
- การวางแผน
- เวที
- แพลตฟอร์ม
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- กรุณา
- นโยบาย
- นโยบาย
- เป็นไปได้
- โพสต์
- อำนาจ
- ความแม่นยำ
- คาดการณ์
- คำทำนาย
- การคาดการณ์
- คาดการณ์
- ก่อน
- การตั้งราคา
- กระบวนการ
- กระบวนการ
- ผู้ผลิต
- โครงการ
- ให้
- ให้
- สาธารณะ
- ประกาศ
- หลาม
- คำถาม
- อย่างรวดเร็ว
- สุ่ม
- การอ่าน
- พร้อม
- จริง
- เรียลไทม์
- ข้อมูลตามเวลาจริง
- ตระหนักถึง
- รับ
- ที่ได้รับ
- เมื่อเร็ว ๆ นี้
- ได้รับการยอมรับ
- บันทึก
- ซ้ำแล้วซ้ำเล่า
- แทนที่
- จำเป็นต้องใช้
- ทรัพยากร
- แหล่งข้อมูล
- REST
- ผลสอบ
- รับคืน
- ความเสี่ยง
- บทบาท
- วิ่ง
- วิ่ง
- sagemaker
- ซาน
- ซานฟรานซิสโก
- ที่ปรับขนาดได้
- ขนาด
- ภาพหน้าจอ
- SDK
- ทะเลบอร์น
- ที่สอง
- วินาที
- Section
- ส่วน
- ปลอดภัย
- เลือก
- การเลือก
- serverless
- บริการ
- ชุด
- การตั้งค่า
- การตั้งค่า
- การติดตั้ง
- ระยะสั้น
- โชว์
- แสดงให้เห็นว่า
- ง่าย
- ลดความซับซ้อน
- จำลอง
- So
- สังคม
- โซเชียลมีเดีย
- ทางออก
- โซลูชัน
- บาง
- แหล่ง
- แหล่งที่มา
- ผู้เชี่ยวชาญ
- ความเชี่ยวชาญ
- ใช้จ่าย
- แยก
- SQL
- ระยะ
- มาตรฐาน
- ข้อความที่เริ่ม
- สถานะ
- คำแถลง
- งบ
- Status
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- จัดเก็บ
- ร้านค้า
- ยุทธศาสตร์
- กระแส
- ที่พริ้ว
- สตรีมมิ่งบริการ
- ลำธาร
- อย่างเช่น
- ยิ่งใหญ่
- ระบบ
- ระบบ
- ตาราง
- เอา
- ใช้เวลา
- พูดคุย
- เป้า
- สถานีปลายทาง
- ทดสอบ
- พื้นที่
- ที่สาม
- พัน
- ตลอด
- เวลา
- การประทับเวลา
- ไปยัง
- ด้านบน
- หัวข้อ
- ตามธรรมเนียม
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- การทำธุกรรม
- ธุรกรรม
- การทำธุรกรรม
- แปลง
- การแปลง
- การเปลี่ยนแปลง
- เทรนด์
- บันทึก
- ให้กับคุณ
- การใช้
- ใช้
- ผู้ใช้งาน
- การตรวจสอบ
- ความคุ้มค่า
- ความคุ้มค่า
- ต่างๆ
- สิ่งที่เป็นจริง
- รุ่น
- รายละเอียด
- ยอดวิว
- ที่เดิน
- คำแนะนำ
- คลังสินค้า
- การจัดเก็บสินค้า
- Website
- สุดสัปดาห์
- รายสัปดาห์
- อะไร
- ที่
- ในขณะที่
- วิกิพีเดีย
- จะ
- ไม่มี
- ทำงาน
- การทำงาน
- โรงงาน
- เขียน
- ปี
- โยคะ
- ของคุณ
- ลมทะเล