เช่นเดียวกับลูกค้าแทบทุกคน คุณต้องการใช้จ่ายให้น้อยที่สุดเท่าที่จะเป็นไปได้พร้อมกับได้รับประสิทธิภาพที่ดีที่สุดเท่าที่จะเป็นไปได้ ซึ่งหมายความว่าคุณต้องใส่ใจกับประสิทธิภาพด้านราคา กับ อเมซอน Redshift, คุณสามารถกินเค้กและกินมันได้เช่นกัน! Amazon RedShift มีราคาต่อผู้ใช้ที่ต่ำกว่าถึง 4.9 เท่า และประสิทธิภาพด้านราคาที่ดีกว่าถึง 7.9 เท่าเมื่อเทียบกับคลังข้อมูลบนคลาวด์อื่นๆ บนปริมาณงานในโลกแห่งความเป็นจริงโดยใช้เทคนิคขั้นสูง เช่น การปรับขนาดการทำงานพร้อมกันเพื่อรองรับผู้ใช้หลายร้อยคนพร้อมกัน การเข้ารหัสสตริงที่ได้รับการปรับปรุงเพื่อประสิทธิภาพการสืบค้นที่รวดเร็วยิ่งขึ้น , และ Amazon Redshift แบบไร้เซิร์ฟเวอร์ การปรับปรุงประสิทธิภาพ อ่านต่อเพื่อทำความเข้าใจว่าเหตุใดประสิทธิภาพด้านราคาจึงมีความสำคัญ และวิธีที่ Amazon RedShift ด้านประสิทธิภาพด้านราคาเป็นตัววัดต้นทุนในการได้รับประสิทธิภาพปริมาณงานในระดับใดระดับหนึ่ง ซึ่งก็คือ ROI ด้านประสิทธิภาพ (ผลตอบแทนจากการลงทุน)
เนื่องจากทั้งราคาและประสิทธิภาพรวมอยู่ในการคำนวณประสิทธิภาพราคา มีสองวิธีในการคิดเกี่ยวกับประสิทธิภาพด้านราคา วิธีแรกคือการคงราคาไว้คงที่ หากคุณมีเงิน 1 ดอลลาร์ที่ใช้จ่าย คุณจะได้รับประสิทธิภาพเท่าใดจากคลังข้อมูลของคุณ ฐานข้อมูลที่มีประสิทธิภาพด้านราคาที่ดีกว่าจะมอบประสิทธิภาพที่ดีขึ้นสำหรับการใช้จ่ายทุกๆ 1 ดอลลาร์ ดังนั้นเมื่อถือราคาคงที่เมื่อเปรียบเทียบคลังข้อมูล XNUMX แห่งที่มีต้นทุนเท่ากัน ฐานข้อมูลที่มีประสิทธิภาพด้านราคาดีกว่าจะเรียกใช้คำสั่งของคุณได้เร็วขึ้น. วิธีที่สองในการดูราคา-ประสิทธิภาพคือการรักษาประสิทธิภาพให้คงที่: หากคุณต้องการให้ปริมาณงานของคุณเสร็จสิ้นภายใน 10 นาที จะต้องเสียค่าใช้จ่ายเท่าไร ฐานข้อมูลที่มีประสิทธิภาพด้านราคาดีกว่าจะเรียกใช้ปริมาณงานของคุณภายใน 10 นาทีด้วยต้นทุนที่ต่ำกว่า ดังนั้นเมื่อรักษาประสิทธิภาพให้คงที่เมื่อเปรียบเทียบคลังข้อมูล XNUMX แห่งที่มีขนาดให้ประสิทธิภาพเท่ากัน ฐานข้อมูลที่มีประสิทธิภาพด้านราคาดีกว่าจะเสียค่าใช้จ่ายน้อยลงและประหยัดเงิน
สุดท้ายนี้ อีกแง่มุมที่สำคัญของประสิทธิภาพด้านราคาก็คือความสามารถในการคาดการณ์ได้ การรู้ว่าคลังข้อมูลของคุณมีค่าใช้จ่ายเท่าไรเมื่อจำนวนผู้ใช้คลังข้อมูลเพิ่มขึ้นเป็นสิ่งสำคัญสำหรับการวางแผน ไม่เพียงแต่จะมอบประสิทธิภาพด้านราคาที่ดีที่สุดในปัจจุบันเท่านั้น แต่ยังควรปรับขนาดที่คาดการณ์ได้และมอบประสิทธิภาพด้านราคาที่ดีที่สุดเมื่อมีผู้ใช้และปริมาณงานเพิ่มมากขึ้น คลังข้อมูลในอุดมคติควรมี สเกลเชิงเส้น—การปรับขนาดคลังข้อมูลของคุณเพื่อส่งมอบปริมาณงานการสืบค้นเป็นสองเท่าควรมีต้นทุนเพิ่มขึ้นสองเท่า (หรือน้อยกว่า)
ในโพสต์นี้ เราแชร์ผลลัพธ์ด้านประสิทธิภาพเพื่อแสดงให้เห็นว่า Amazon RedShift มอบประสิทธิภาพด้านราคาที่ดีขึ้นอย่างมากได้อย่างไร เมื่อเทียบกับคลังข้อมูลบนระบบคลาวด์ทางเลือกชั้นนำ ซึ่งหมายความว่าหากคุณใช้จ่ายกับ Amazon RedShift เท่ากับที่คุณใช้ในคลังข้อมูลอื่นๆ เหล่านี้ คุณจะได้รับประสิทธิภาพที่ดีขึ้นด้วย Amazon RedShift หรืออีกทางหนึ่ง หากคุณปรับขนาดคลัสเตอร์ RedShift เพื่อให้มีประสิทธิภาพเท่าเดิม คุณจะเห็นต้นทุนที่ต่ำกว่าเมื่อเทียบกับทางเลือกอื่นเหล่านี้
ประสิทธิภาพด้านราคาสำหรับปริมาณงานในโลกแห่งความเป็นจริง
คุณสามารถใช้ Amazon RedShift เพื่อขับเคลื่อนปริมาณงานที่หลากหลายได้ ตั้งแต่การประมวลผลเป็นชุดของรายงานที่แยก การแปลง และโหลด (ETL) ที่ซับซ้อน และการวิเคราะห์การสตรีมแบบเรียลไทม์ไปจนถึงแดชบอร์ด Business Intelligence (BI) ที่มีความหน่วงต่ำ จำเป็นต้องให้บริการผู้ใช้หลายร้อยหรือหลายพันคนในเวลาเดียวกันด้วยเวลาตอบสนองเสี้ยววินาที และทุกอย่างในระหว่างนั้น วิธีหนึ่งที่เราปรับปรุงประสิทธิภาพด้านราคาสำหรับลูกค้าของเราอย่างต่อเนื่องคือการตรวจสอบการวัดและส่งข้อมูลทางไกลด้านประสิทธิภาพของซอฟต์แวร์และฮาร์ดแวร์จากกลุ่ม Redshift อย่างต่อเนื่อง โดยมองหาโอกาสและกรณีการใช้งานของลูกค้าที่เราสามารถปรับปรุงประสิทธิภาพของ Amazon RedShift ต่อไปได้
ตัวอย่างล่าสุดของการเพิ่มประสิทธิภาพการทำงานที่ขับเคลื่อนโดยการตรวจวัดระยะไกลของยานพาหนะ ได้แก่:
- การเพิ่มประสิทธิภาพแบบสอบถามสตริง – จากการวิเคราะห์วิธีที่ Amazon RedShift ประมวลผลข้อมูลประเภทต่างๆ ในฟลีต Redshift เราพบว่าการเพิ่มประสิทธิภาพการสืบค้นที่มีสตริงจำนวนมากจะก่อให้เกิดประโยชน์อย่างมากต่อปริมาณงานของลูกค้าของเรา (เราจะหารือเรื่องนี้โดยละเอียดเพิ่มเติมในโพสต์นี้)
- มุมมองที่เป็นรูปธรรมอัตโนมัติ – เราพบว่าลูกค้า Amazon RedShift มักจะเรียกใช้การสืบค้นจำนวนมากที่มีรูปแบบการสืบค้นย่อยทั่วไป ตัวอย่างเช่น แบบสอบถามที่แตกต่างกันหลายรายการอาจรวมสามตารางเดียวกันโดยใช้เงื่อนไขการรวมเดียวกัน ขณะนี้ Amazon RedShift สามารถสร้างและรักษามุมมองที่เป็นรูปธรรมได้โดยอัตโนมัติ จากนั้นจึงเขียนการสืบค้นใหม่อย่างโปร่งใสเพื่อใช้มุมมองที่เป็นรูปธรรมโดยใช้แมชชีนเลิร์นนิง มุมมองที่เป็นรูปธรรมอัตโนมัติ คุณสมบัติระบบอัตโนมัติใน Amazon RedShift เมื่อเปิดใช้งาน มุมมองที่เป็นรูปธรรมอัตโนมัติสามารถเพิ่มประสิทธิภาพการสืบค้นอย่างโปร่งใสสำหรับการสืบค้นซ้ำ ๆ โดยที่ผู้ใช้ไม่ต้องดำเนินการใด ๆ (โปรดทราบว่ามุมมองที่เป็นรูปธรรมแบบอัตโนมัติไม่ได้ถูกนำมาใช้ในผลลัพธ์การวัดประสิทธิภาพใดๆ ที่กล่าวถึงในโพสต์นี้)
- ปริมาณงานที่เกิดขึ้นพร้อมกันสูง – กรณีการใช้งานที่เพิ่มมากขึ้นที่เราเห็นคือการใช้ Amazon RedShift เพื่อให้บริการปริมาณงานที่เหมือนแดชบอร์ด ปริมาณงานเหล่านี้มีลักษณะเฉพาะด้วยเวลาตอบสนองคำค้นหาที่ต้องการเป็นวินาทีหลักเดียวหรือน้อยกว่า โดยมีผู้ใช้หลายสิบหรือหลายร้อยรายเรียกใช้คำค้นหาพร้อมกันโดยมีรูปแบบการใช้งานที่แหลมคมและมักจะคาดเดาไม่ได้ ตัวอย่างต้นแบบของสิ่งนี้คือแดชบอร์ด BI ที่ได้รับการสนับสนุนจาก Amazon RedShift ซึ่งมีปริมาณการรับส่งข้อมูลที่เพิ่มขึ้นอย่างรวดเร็วในเช้าวันจันทร์เมื่อมีผู้ใช้จำนวนมากเริ่มต้นสัปดาห์
โดยเฉพาะอย่างยิ่งปริมาณงานที่เกิดพร้อมกันสูงมีการนำไปใช้งานได้กว้างมาก โดยเฉพาะอย่างยิ่งปริมาณงานคลังข้อมูลส่วนใหญ่ทำงานพร้อมกัน และไม่ใช่เรื่องแปลกที่ผู้ใช้หลายร้อยหรือหลายพันรายจะเรียกใช้การสืบค้นบน Amazon RedShift ในเวลาเดียวกัน Amazon RedShift ได้รับการออกแบบมาเพื่อให้คาดการณ์เวลาตอบกลับการสืบค้นได้และรวดเร็ว Redshift Serverless ทำสิ่งนี้ให้คุณโดยอัตโนมัติโดยเพิ่มและลบการประมวลผลตามที่จำเป็นเพื่อให้เวลาตอบกลับคำค้นหารวดเร็วและคาดการณ์ได้ ซึ่งหมายความว่าแดชบอร์ดที่สนับสนุนโดย Redshift Serverless ซึ่งโหลดได้อย่างรวดเร็วเมื่อมีผู้ใช้หนึ่งหรือสองคนเข้าถึงจะยังคงโหลดอย่างรวดเร็วแม้ว่าผู้ใช้หลายคนจะโหลดแดชบอร์ดในเวลาเดียวกันก็ตาม
เพื่อจำลองปริมาณงานประเภทนี้ เราใช้เกณฑ์มาตรฐานที่ได้รับจาก TPC-DS พร้อมชุดข้อมูลขนาด 100 GB TPC-DS เป็นเกณฑ์มาตรฐานอุตสาหกรรมที่มีการสืบค้นคลังข้อมูลทั่วไปที่หลากหลาย ด้วยขนาดที่ค่อนข้างเล็กเพียง 100 GB การสืบค้นในการวัดประสิทธิภาพนี้จะทำงานบน Redshift Serverless ในเวลาเฉลี่ยไม่กี่วินาที ซึ่งเป็นตัวแทนของสิ่งที่ผู้ใช้โหลดแดชบอร์ด BI แบบโต้ตอบคาดหวัง เราทำการทดสอบเบนช์มาร์กนี้พร้อมกันระหว่าง 1–200 ครั้ง โดยจำลองผู้ใช้ระหว่าง 1–200 คนที่พยายามโหลดแดชบอร์ดในเวลาเดียวกัน นอกจากนี้เรายังทำการทดสอบซ้ำกับคลังข้อมูลบนคลาวด์ทางเลือกยอดนิยมหลายแห่งที่รองรับการขยายขนาดโดยอัตโนมัติ (หากคุณคุ้นเคยกับโพสต์นี้ Amazon Redshift ยังคงเป็นผู้นำในด้านประสิทธิภาพราคาเราไม่ได้รวมคู่แข่ง A เนื่องจากไม่รองรับการขยายขนาดโดยอัตโนมัติ) เราวัดเวลาตอบกลับโดยเฉลี่ยของคำค้นหา ซึ่งหมายถึงระยะเวลาที่ผู้ใช้รอให้ข้อความค้นหาเสร็จสิ้น (หรือแดชบอร์ดโหลด) ผลลัพธ์จะแสดงในแผนภูมิต่อไปนี้
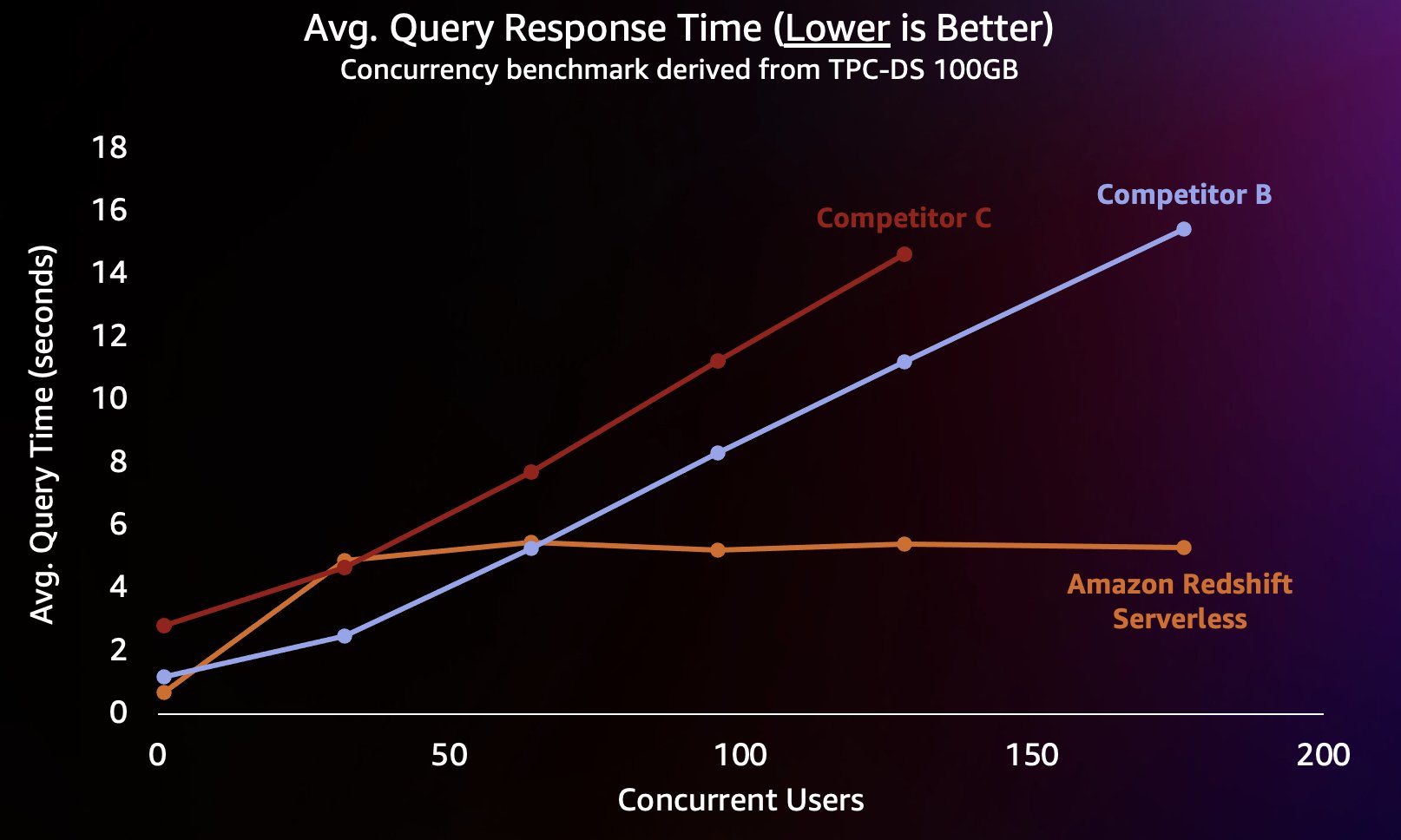
คู่แข่ง B ปรับขนาดได้ดีจนกระทั่งมีการสืบค้นพร้อมกันประมาณ 64 รายการ ซึ่ง ณ จุดนี้ไม่สามารถให้การประมวลผลเพิ่มเติมและการสืบค้นเริ่มเข้าคิว ส่งผลให้เวลาตอบสนองการสืบค้นเพิ่มขึ้น แม้ว่าคู่แข่ง C จะสามารถปรับขนาดได้โดยอัตโนมัติ แต่จะปรับขนาดให้ปริมาณงานการสืบค้นต่ำกว่าทั้ง Amazon Redshift และคู่แข่ง B และไม่สามารถรักษารันไทม์การสืบค้นให้ต่ำได้ นอกจากนี้ ยังไม่สนับสนุนการคิวคิวเมื่อประมวลผลไม่เพียงพอ ซึ่งทำให้ไม่สามารถขยายขนาดเกินผู้ใช้ประมาณ 128 คนพร้อมกัน การส่งคำถามเพิ่มเติมนอกเหนือจากนี้จะถูกปฏิเสธโดยระบบ
ที่นี่ Redshift Serverless สามารถรักษาเวลาตอบกลับการสืบค้นให้ค่อนข้างสม่ำเสมอที่ประมาณ 5 วินาที แม้ว่าผู้ใช้หลายร้อยรายกำลังเรียกใช้การสืบค้นในเวลาเดียวกันก็ตาม เวลาตอบสนองการสืบค้นโดยเฉลี่ยสำหรับคู่แข่ง B และ C เพิ่มขึ้นอย่างต่อเนื่องเมื่อโหลดในคลังข้อมูลเพิ่มขึ้น ซึ่งส่งผลให้ผู้ใช้ต้องรอนานขึ้น (สูงสุด 16 วินาที) เพื่อให้การสืบค้นกลับมาเมื่อคลังข้อมูลไม่ว่าง ซึ่งหมายความว่า หากผู้ใช้พยายามรีเฟรชแดชบอร์ด (ซึ่งอาจส่งการสืบค้นพร้อมกันหลายรายการเมื่อโหลดซ้ำ) Amazon RedShift จะสามารถรักษาเวลาในการโหลดแดชบอร์ดให้สอดคล้องกันมากขึ้น แม้ว่าแดชบอร์ดจะถูกโหลดโดยผู้อื่นหลายสิบหรือหลายร้อยราย ผู้ใช้ในเวลาเดียวกัน
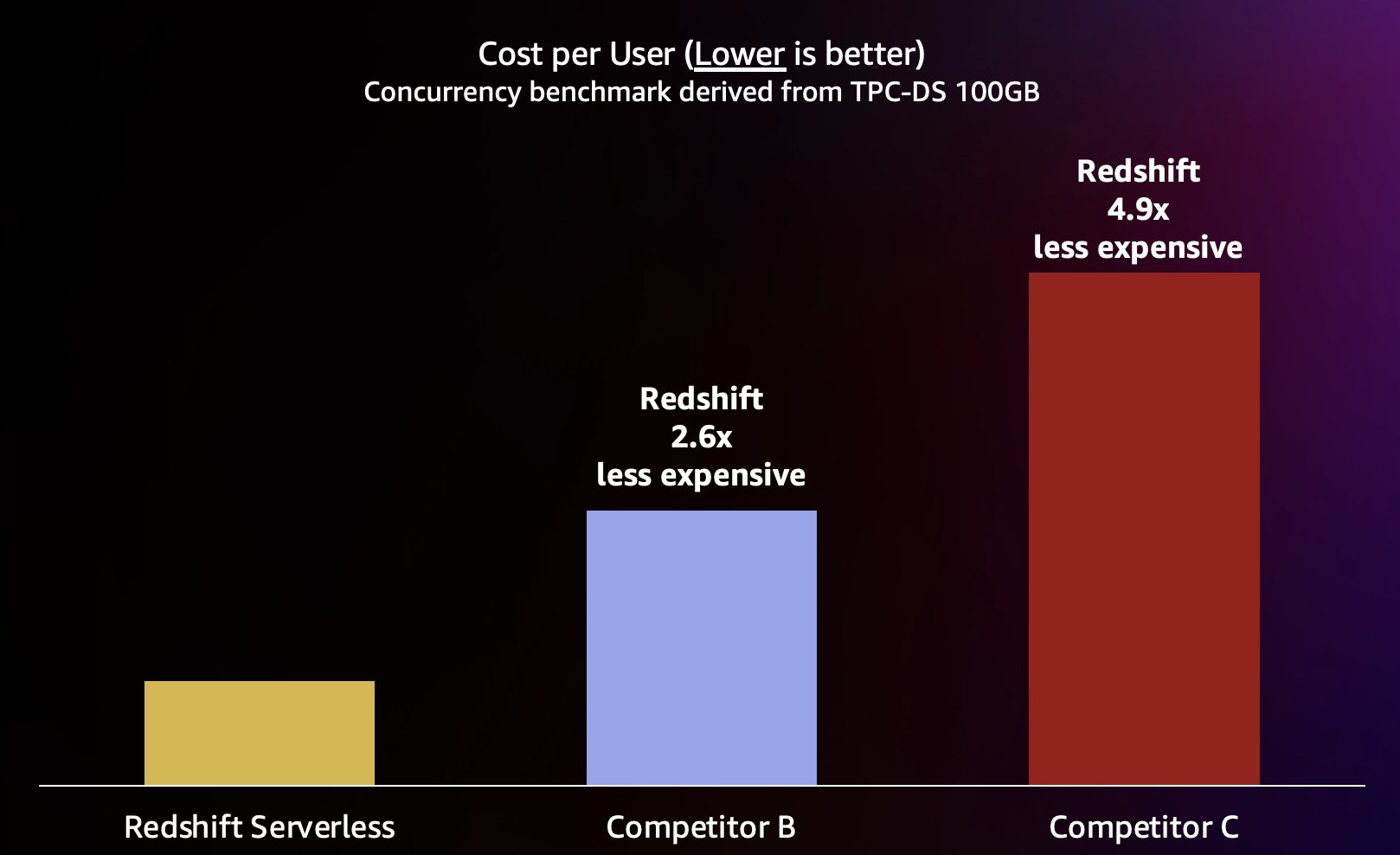
เนื่องจาก Amazon RedShift สามารถส่งมอบปริมาณการสืบค้นที่สูงมากสำหรับการสืบค้นแบบสั้น (ดังที่เราเขียนไว้ใน Amazon Redshift ยังคงเป็นผู้นำในด้านประสิทธิภาพราคา) นอกจากนี้ยังสามารถจัดการกับการทำงานพร้อมกันที่สูงขึ้นเหล่านี้ได้ เมื่อขยายขนาดออกอย่างมีประสิทธิภาพมากขึ้น และด้วยต้นทุนที่ลดลงอย่างมาก ในการหาปริมาณ เราจะดูที่ประสิทธิภาพราคาโดยใช้การเผยแพร่ ราคาตามความต้องการ สำหรับแต่ละคลังสินค้าในการทดสอบก่อนหน้า ดังแสดงในแผนภูมิต่อไปนี้ เป็นที่น่าสังเกตว่าการใช้ อินสแตนซ์แบบเหมาจ่าย (RI)โดยเฉพาะ RI ระยะเวลา 3 ปีที่ซื้อพร้อมตัวเลือกการชำระเงินล่วงหน้าทั้งหมด มีต้นทุนต่ำสุดในการรัน Amazon RedShift บนคลัสเตอร์ที่จัดเตรียมไว้ ส่งผลให้ได้ประสิทธิภาพราคาสัมพันธ์ที่ดีที่สุดเมื่อเทียบกับตัวเลือกตามความต้องการหรือตัวเลือก RI อื่นๆ

ดังนั้น Amazon RedShift ไม่เพียงแต่สามารถมอบประสิทธิภาพที่ดีขึ้นในการทำงานพร้อมกันที่สูงขึ้นเท่านั้น แต่ยังสามารถทำได้ด้วยต้นทุนที่ต่ำลงอย่างมากอีกด้วย จุดข้อมูลแต่ละจุดในแผนภูมิราคา-ประสิทธิภาพเทียบเท่ากับต้นทุนในการรันการวัดประสิทธิภาพพร้อมกันที่ระบุ เนื่องจากราคา-ประสิทธิภาพเป็นเส้นตรง เราจึงสามารถแบ่งต้นทุนในการเรียกใช้การวัดประสิทธิภาพพร้อมกันใดๆ ด้วยการทำงานพร้อมกัน (จำนวนผู้ใช้ที่ใช้งานพร้อมกันในแผนภูมินี้) เพื่อบอกเราว่าการเพิ่มต้นทุนผู้ใช้ใหม่แต่ละรายสำหรับการวัดประสิทธิภาพนี้จะเป็นเท่าใด
ผลลัพธ์ก่อนหน้านี้สามารถทำซ้ำได้โดยตรง ข้อความค้นหาทั้งหมดที่ใช้ในการวัดประสิทธิภาพมีอยู่ในของเรา พื้นที่เก็บข้อมูล GitHub และประสิทธิภาพวัดได้โดยการเปิดตัวคลังข้อมูล เปิดใช้งาน Concurrency Scaling บน Amazon Redshift (หรือคุณสมบัติการปรับขนาดอัตโนมัติที่เกี่ยวข้องในคลังข้อมูลอื่นๆ) โหลดข้อมูลนอกกรอบ (ไม่มีการปรับแต่งด้วยตนเองหรือการตั้งค่าเฉพาะฐานข้อมูล) จากนั้นเรียกใช้ สตรีมการสืบค้นพร้อมกันพร้อมกันตั้งแต่ 1–200 ในขั้นตอนที่ 32 ในแต่ละคลังข้อมูล repo GitHub เดียวกันอ้างอิงข้อมูล TPC-DS ที่สร้างไว้ล่วงหน้า (และไม่ได้แก้ไข) ใน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) ในขนาดต่างๆ โดยใช้ชุดสร้างข้อมูล TPC-DS อย่างเป็นทางการ
การเพิ่มประสิทธิภาพเวิร์กโหลดที่มีสตริงจำนวนมาก
ตามที่กล่าวไว้ข้างต้น ทีม Amazon RedShift มองหาโอกาสใหม่ๆ อย่างต่อเนื่องเพื่อมอบประสิทธิภาพด้านราคาที่ดียิ่งขึ้นให้กับลูกค้าของเรา การปรับปรุงอย่างหนึ่งที่เราเปิดตัวเมื่อเร็วๆ นี้ซึ่งปรับปรุงประสิทธิภาพอย่างมากคือการเพิ่มประสิทธิภาพที่เร่งประสิทธิภาพการสืบค้นข้อมูลสตริง ตัวอย่างเช่น คุณอาจต้องการค้นหารายได้ทั้งหมดที่เกิดจากร้านค้าปลีกที่ตั้งอยู่ในนิวยอร์กซิตี้ด้วยข้อความค้นหา เช่น SELECT sum(price) FROM sales WHERE city = ‘New York’. แบบสอบถามนี้กำลังใช้เพรดิเคตเหนือข้อมูลสตริง (city = ‘New York’). ดังที่คุณสามารถจินตนาการได้ การประมวลผลข้อมูลแบบสตริงมีอยู่ทั่วไปในแอปพลิเคชันคลังข้อมูล
เพื่อวัดความถี่ที่ปริมาณงานของลูกค้าเข้าถึงสตริง เราได้ทำการวิเคราะห์โดยละเอียดเกี่ยวกับการใช้งานประเภทข้อมูลสตริงโดยใช้การตรวจวัดระยะไกลของฟลีตของคลัสเตอร์ลูกค้านับหมื่นที่จัดการโดย Amazon RedShift การวิเคราะห์ของเราระบุว่าใน 90% ของคลัสเตอร์ คอลัมน์สตริงประกอบด้วยอย่างน้อย 30% ของคอลัมน์ทั้งหมด และใน 50% ของคลัสเตอร์ คอลัมน์สตริงประกอบด้วยอย่างน้อย 50% ของคอลัมน์ทั้งหมด นอกจากนี้ การสืบค้นส่วนใหญ่ทั้งหมดทำงานบนแพลตฟอร์มคลังข้อมูลบนระบบคลาวด์ของ Amazon RedShift ซึ่งเข้าถึงคอลัมน์สตริงอย่างน้อยหนึ่งคอลัมน์ ปัจจัยที่สำคัญอีกประการหนึ่งคือข้อมูลสตริงมักจะมีจำนวนสมาชิกต่ำมาก ซึ่งหมายความว่าคอลัมน์ประกอบด้วยชุดค่าที่ไม่ซ้ำกันที่ค่อนข้างเล็ก ตัวอย่างเช่น แม้ว่าก orders ตารางที่แสดงข้อมูลการขายอาจมีแถวหลายพันล้านแถว order_status คอลัมน์ภายในตารางนั้นอาจมีค่าที่ไม่ซ้ำกันเพียงไม่กี่ค่าจากแถวหลายพันล้านแถว เช่น pending, in processและ completed.
ในขณะที่เขียนบทความนี้ คอลัมน์สตริงส่วนใหญ่ใน Amazon RedShift จะถูกบีบอัดด้วย ลซ or ZSTD อัลกอริธึม เหล่านี้เป็นอัลกอริธึมการบีบอัดที่ใช้งานทั่วไปได้ดี แต่ไม่ได้ออกแบบมาเพื่อใช้ประโยชน์จากข้อมูลสตริงที่มีคาร์ดินัลตี้ต่ำ โดยเฉพาะอย่างยิ่ง พวกเขาจำเป็นต้องคลายการบีบอัดข้อมูลก่อนที่จะดำเนินการ และมีประสิทธิภาพน้อยลงในการใช้แบนด์วิธหน่วยความจำฮาร์ดแวร์ สำหรับข้อมูลที่มีคาร์ดินัลลิตี้ต่ำ มีการเข้ารหัสอีกประเภทหนึ่งที่อาจเหมาะสมที่สุดมากกว่า: ไบต์. การเข้ารหัสนี้ใช้รูปแบบการเข้ารหัสพจนานุกรมที่ช่วยให้กลไกฐานข้อมูลทำงานโดยตรงบนข้อมูลที่บีบอัดโดยไม่จำเป็นต้องขยายขนาดก่อน
เพื่อปรับปรุงประสิทธิภาพด้านราคาสำหรับปริมาณงานที่มีสตริงจำนวนมาก Amazon Redshift ขอแนะนำการปรับปรุงประสิทธิภาพเพิ่มเติมที่เร่งความเร็วการสแกนและการประเมินภาคแสดง เหนือคอลัมน์สตริงคาร์ดินัลลิตีต่ำที่เข้ารหัสเป็น BYTEDICT เร็วขึ้นระหว่าง 5–63 เท่า (ดูผลลัพธ์ใน หัวข้อถัดไป) เมื่อเปรียบเทียบกับการเข้ารหัสการบีบอัดทางเลือก เช่น LZO หรือ ZSTD Amazon Redshift ประสบความสำเร็จในการปรับปรุงประสิทธิภาพนี้โดยการสแกนแบบเวกเตอร์บนคอลัมน์สตริงสตริงที่มีคาร์ดินัลตี้ต่ำ เข้ารหัส BYTEDICT และมีน้ำหนักเบา มีประสิทธิภาพ CPU การเพิ่มประสิทธิภาพการประมวลผลสตริงเหล่านี้ทำให้การใช้แบนด์วิดท์หน่วยความจำที่ฮาร์ดแวร์สมัยใหม่ได้รับอย่างมีประสิทธิภาพ ทำให้สามารถวิเคราะห์ข้อมูลสตริงแบบเรียลไทม์ได้ ความสามารถด้านประสิทธิภาพที่เพิ่งเปิดตัวเหล่านี้เหมาะสมที่สุดสำหรับคอลัมน์สตริงที่มีคาร์ดินัลตี้ต่ำ (ค่าสตริงที่ไม่ซ้ำกันสูงสุดสองสามร้อยค่า)
คุณจะได้รับประโยชน์โดยอัตโนมัติจากการปรับปรุงสตริงประสิทธิภาพสูงใหม่นี้โดยการเปิดใช้งาน การเพิ่มประสิทธิภาพตารางอัตโนมัติ ในคลังข้อมูล Amazon RedShift ของคุณ หากคุณไม่ได้เปิดใช้งานการเพิ่มประสิทธิภาพตารางอัตโนมัติบนตารางของคุณ คุณสามารถรับคำแนะนำจาก ที่ปรึกษา Amazon Redshift ในคอนโซล Amazon RedShift เกี่ยวกับความเหมาะสมของคอลัมน์สตริงสำหรับการเข้ารหัส BYTEDICT คุณยังสามารถกำหนดตารางใหม่ที่มีคอลัมน์สตริงที่มีจำนวนสมาชิกต่ำด้วยการเข้ารหัส BYTEDICT การปรับปรุงสตริงใน Amazon RedShift พร้อมใช้งานแล้วในทุกภูมิภาคของ AWS Amazon Redshift พร้อมให้บริการแล้ว.
ผลการดำเนินงาน
เพื่อวัดผลกระทบด้านประสิทธิภาพการทำงานของการปรับปรุงสตริงของเรา เราได้สร้างชุดข้อมูลขนาด 10 TB (Tera Byte) ที่ประกอบด้วยข้อมูลสตริงที่มีคาร์ดินัลตี้ต่ำ เราสร้างข้อมูลสามเวอร์ชันโดยใช้สตริงแบบสั้น กลาง และยาว ซึ่งสอดคล้องกับเปอร์เซ็นต์ไทล์ที่ 25, 50 และ 75 ของความยาวสตริงจากการวัดทางไกลของฟลีตของ Amazon Redshift เราโหลดข้อมูลนี้ลงใน Amazon RedShift สองครั้ง โดยเข้ารหัสในกรณีหนึ่งโดยใช้การบีบอัด LZO และอีกกรณีหนึ่งใช้การบีบอัด BYTEDICT สุดท้ายนี้ เราวัดประสิทธิภาพของข้อความค้นหาที่มีการสแกนจำนวนมากซึ่งส่งคืนแถวจำนวนมาก (90% ของตาราง) จำนวนแถวขนาดกลาง (50% ของตาราง) และสองสามแถว (1% ของตาราง) ที่สูงกว่าค่าต่ำเหล่านี้ ชุดข้อมูลสตริง -cardinality ผลการดำเนินงานสรุปได้ในแผนภูมิต่อไปนี้

การสืบค้นที่มีเพรดิเคตที่ตรงกับเปอร์เซ็นต์ของแถวที่สูงได้รับการปรับปรุง 5–30 เท่าด้วยการเข้ารหัส BYTEDICT แบบเวกเตอร์ใหม่เมื่อเปรียบเทียบกับ LZO ในขณะที่การสืบค้นที่มีเพรดิเคตที่ตรงกับเปอร์เซ็นต์ที่ต่ำของแถวได้รับการปรับปรุง 10–63 ครั้งในการวัดประสิทธิภาพภายในนี้
RedShift Serverless ประสิทธิภาพด้านราคา
นอกเหนือจากผลลัพธ์ประสิทธิภาพการทำงานพร้อมกันสูงที่นำเสนอในโพสต์นี้แล้ว เรายังใช้เกณฑ์มาตรฐาน Cloud Data Warehouse ที่ได้มาจาก TPC-DS เพื่อเปรียบเทียบราคาประสิทธิภาพด้านราคาของ Redshift Serverless กับคลังข้อมูลอื่นๆ ที่ใช้ชุดข้อมูลขนาด 3TB ที่ใหญ่กว่า เราเลือกคลังข้อมูลที่มีราคาใกล้เคียงกัน ในกรณีนี้ภายใน 10% ของ 32 ดอลลาร์ต่อชั่วโมง โดยใช้ราคาตามความต้องการที่เปิดเผยต่อสาธารณะ ผลลัพธ์เหล่านี้แสดงให้เห็นว่า Redshift Serverless มอบประสิทธิภาพด้านราคาที่ดีกว่า เช่นเดียวกับอินสแตนซ์ Amazon RedShift RA3 เมื่อเทียบกับคลังข้อมูลบนคลาวด์ชั้นนำอื่นๆ และเช่นเคย ผลลัพธ์เหล่านี้สามารถจำลองแบบได้โดยใช้สคริปต์ SQL ในของเรา พื้นที่เก็บข้อมูล GitHub.

เราขอแนะนำให้คุณลองใช้ Amazon RedShift โดยใช้ของคุณเอง พิสูจน์แนวคิด ปริมาณงานเป็นวิธีที่ดีที่สุดในการดูว่า Amazon RedShift สามารถตอบสนองความต้องการด้านการวิเคราะห์ข้อมูลของคุณได้อย่างไร
ค้นหาประสิทธิภาพราคาที่ดีที่สุดสำหรับปริมาณงานของคุณ
การวัดประสิทธิภาพที่ใช้ในโพสต์นี้มาจากการวัดประสิทธิภาพ TPC-DS ที่เป็นมาตรฐานอุตสาหกรรม และมีคุณสมบัติดังต่อไปนี้:
- สคีมาและข้อมูลถูกใช้โดยไม่มีการแก้ไขจาก TPC-DS
- การสืบค้นถูกสร้างขึ้นโดยใช้ชุด TPC-DS อย่างเป็นทางการพร้อมพารามิเตอร์การสืบค้นที่สร้างขึ้นโดยใช้เมล็ดสุ่มเริ่มต้นของชุด TPC-DS ตัวแปรแบบสอบถามที่ได้รับการอนุมัติจาก TPC จะใช้สำหรับคลังสินค้า ถ้าคลังสินค้าไม่สนับสนุนภาษา SQL ของแบบสอบถาม TPC-DS เริ่มต้น
- การทดสอบประกอบด้วยแบบสอบถาม 99 TPC-DS SELECT ไม่รวมขั้นตอนการบำรุงรักษาและปริมาณงาน
- สำหรับการทดสอบการทำงานพร้อมกันขนาด 3TB เดี่ยว จะมีการรันการใช้พลังงานสามครั้ง และดำเนินการที่ดีที่สุดสำหรับคลังข้อมูลแต่ละแห่ง
- ประสิทธิภาพราคาสำหรับการสืบค้น TPC-DS คำนวณเป็นต้นทุนต่อชั่วโมง (USD) คูณรันไทม์การวัดประสิทธิภาพในหน่วยชั่วโมง ซึ่งเทียบเท่ากับต้นทุนในการรันการวัดประสิทธิภาพ ราคาตามความต้องการที่เผยแพร่ล่าสุดใช้สำหรับคลังข้อมูลทั้งหมด และไม่ใช่ราคาอินสแตนซ์แบบเหมาจ่ายตามที่ระบุไว้ก่อนหน้านี้
เราเรียกสิ่งนี้ว่าการวัดประสิทธิภาพ Cloud Data Warehouse และคุณสามารถสร้างผลลัพธ์การวัดประสิทธิภาพก่อนหน้าได้อย่างง่ายดายโดยใช้สคริปต์ การสืบค้น และข้อมูลที่มีอยู่ในของเรา พื้นที่เก็บข้อมูล GitHub. ได้มาจากการวัดประสิทธิภาพ TPC-DS ตามที่อธิบายไว้ในโพสต์นี้ ดังนั้นจึงไม่สามารถเทียบเคียงได้กับผลลัพธ์ของ TPC-DS ที่เผยแพร่ เนื่องจากผลการทดสอบของเราไม่เป็นไปตามข้อกำหนดอย่างเป็นทางการ
สรุป
Amazon RedShift มุ่งมั่นที่จะมอบประสิทธิภาพราคาที่ดีที่สุดในอุตสาหกรรมสำหรับปริมาณงานที่หลากหลายที่สุด Redshift Serverless ปรับขนาดเชิงเส้นด้วยประสิทธิภาพราคาที่ดีที่สุด (ต่ำสุด) โดยรองรับผู้ใช้หลายร้อยคนพร้อมกันในขณะที่ยังคงรักษาเวลาตอบกลับคำค้นหาที่สม่ำเสมอ จากผลการทดสอบที่กล่าวถึงในโพสต์นี้ Amazon RedShift มีประสิทธิภาพด้านราคาที่ดีขึ้นถึง 2.6 เท่าในระดับการทำงานพร้อมกันเดียวกัน เมื่อเปรียบเทียบกับคู่แข่งที่ใกล้ที่สุด (คู่แข่ง B) ดังที่ได้กล่าวไว้ก่อนหน้านี้ การใช้อินสแตนซ์แบบเหมาจ่ายพร้อมตัวเลือกล่วงหน้าทั้งหมด 3 ปีจะทำให้คุณมีต้นทุนที่ต่ำที่สุดในการรัน Amazon RedShift ส่งผลให้ราคาและประสิทธิภาพสัมพันธ์กันดียิ่งขึ้นเมื่อเปรียบเทียบกับราคาอินสแตนซ์ตามความต้องการที่เราใช้ในโพสต์นี้ แนวทางของเราในการปรับปรุงประสิทธิภาพอย่างต่อเนื่องนั้นเกี่ยวข้องกับการผสมผสานระหว่างความหลงใหลของลูกค้าในการทำความเข้าใจกรณีการใช้งานของลูกค้าและปัญหาคอขวดของความสามารถในการปรับขนาดที่เกี่ยวข้อง ควบคู่ไปกับการวิเคราะห์ข้อมูลกลุ่มยานพาหนะอย่างต่อเนื่องเพื่อระบุโอกาสในการเพิ่มประสิทธิภาพการทำงานที่สำคัญ
ปริมาณงานแต่ละอย่างมีลักษณะเฉพาะ ดังนั้นหากคุณเพิ่งเริ่มต้น ก พิสูจน์แนวคิด เป็นวิธีที่ดีที่สุดในการทำความเข้าใจว่า Amazon RedShift สามารถลดต้นทุนของคุณพร้อมทั้งมอบประสิทธิภาพที่ดีขึ้นได้อย่างไร เมื่อดำเนินการพิสูจน์แนวคิดของคุณเอง สิ่งสำคัญคือต้องมุ่งเน้นไปที่ตัวชี้วัดที่ถูกต้อง—ปริมาณการสืบค้น (จำนวนการสืบค้นต่อชั่วโมง) เวลาตอบสนอง และประสิทธิภาพด้านราคา คุณสามารถตัดสินใจโดยอาศัยข้อมูลโดยดำเนินการพิสูจน์แนวคิดด้วยตนเองหรือ ด้วยความช่วยเหลือ จาก AWS หรือ บูรณาการระบบและพันธมิตรที่ปรึกษา.
หากต้องการติดตามการพัฒนาล่าสุดใน Amazon RedShift โปรดติดตาม มีอะไรใหม่ใน Amazon RedShift อาหาร
เกี่ยวกับผู้แต่ง
 สเตฟาน โกรโมลล์ เป็นวิศวกรประสิทธิภาพอาวุโสของทีม Amazon RedShift ซึ่งเขารับผิดชอบในการวัดและปรับปรุงประสิทธิภาพของ Redshift ในเวลาว่าง เขาชอบทำอาหาร เล่นกับลูกชายทั้งสามคน และสับฟืน
สเตฟาน โกรโมลล์ เป็นวิศวกรประสิทธิภาพอาวุโสของทีม Amazon RedShift ซึ่งเขารับผิดชอบในการวัดและปรับปรุงประสิทธิภาพของ Redshift ในเวลาว่าง เขาชอบทำอาหาร เล่นกับลูกชายทั้งสามคน และสับฟืน
 ราวี อานิมิ เป็นผู้นำการจัดการผลิตภัณฑ์อาวุโสในทีม Amazon RedShift และจัดการส่วนการทำงานต่างๆ ของบริการคลังข้อมูลบนคลาวด์ของ Amazon RedShift รวมถึงประสิทธิภาพ การวิเคราะห์เชิงพื้นที่ การนำเข้าแบบสตรีม และกลยุทธ์การย้ายข้อมูล เขามีประสบการณ์เกี่ยวกับฐานข้อมูลเชิงสัมพันธ์ ฐานข้อมูลหลายมิติ เทคโนโลยี IoT บริการโครงสร้างพื้นฐานการจัดเก็บข้อมูลและการประมวลผล และล่าสุดในฐานะผู้ก่อตั้งสตาร์ทอัพที่ใช้ AI/การเรียนรู้เชิงลึก คอมพิวเตอร์วิทัศน์ และหุ่นยนต์
ราวี อานิมิ เป็นผู้นำการจัดการผลิตภัณฑ์อาวุโสในทีม Amazon RedShift และจัดการส่วนการทำงานต่างๆ ของบริการคลังข้อมูลบนคลาวด์ของ Amazon RedShift รวมถึงประสิทธิภาพ การวิเคราะห์เชิงพื้นที่ การนำเข้าแบบสตรีม และกลยุทธ์การย้ายข้อมูล เขามีประสบการณ์เกี่ยวกับฐานข้อมูลเชิงสัมพันธ์ ฐานข้อมูลหลายมิติ เทคโนโลยี IoT บริการโครงสร้างพื้นฐานการจัดเก็บข้อมูลและการประมวลผล และล่าสุดในฐานะผู้ก่อตั้งสตาร์ทอัพที่ใช้ AI/การเรียนรู้เชิงลึก คอมพิวเตอร์วิทัศน์ และหุ่นยนต์
 อาเมอร์ ชาห์ เป็นวิศวกรอาวุโสในทีม Amazon RedShift Service
อาเมอร์ ชาห์ เป็นวิศวกรอาวุโสในทีม Amazon RedShift Service
 สันเกต ฮาเซ เป็นผู้จัดการฝ่ายพัฒนาซอฟต์แวร์ในทีม Amazon RedShift Service
สันเกต ฮาเซ เป็นผู้จัดการฝ่ายพัฒนาซอฟต์แวร์ในทีม Amazon RedShift Service
 โอเรสติส โพลีโครนิอู เป็นวิศวกรหลักในทีม Amazon RedShift Service
โอเรสติส โพลีโครนิอู เป็นวิศวกรหลักในทีม Amazon RedShift Service
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 10
- 100
- 16
- 32
- 7
- 9
- a
- สามารถ
- เกี่ยวกับเรา
- เร่ง
- เข้า
- Accessed
- ประสบความสำเร็จ
- ข้าม
- ที่เพิ่ม
- เพิ่ม
- นอกจากนี้
- เพิ่มเติม
- สูง
- ความได้เปรียบ
- จ่ายได้
- กับ
- อัลกอริทึม
- ทั้งหมด
- ช่วยให้
- ด้วย
- ทางเลือก
- ทางเลือก
- แม้ว่า
- เสมอ
- อเมซอน
- Amazon Web Services
- จำนวน
- an
- การวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- และ
- อื่น
- ใด
- การใช้งาน
- การประยุกต์ใช้
- เข้าใกล้
- เป็น
- พื้นที่
- รอบ
- AS
- แง่มุม
- ที่เกี่ยวข้อง
- At
- ความสนใจ
- รถยนต์
- อัตโนมัติ
- อัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- เฉลี่ย
- AWS
- b
- แบนด์วิดธ์
- ตาม
- BE
- เพราะ
- ก่อน
- เริ่ม
- กำลัง
- มาตรฐาน
- มาตรฐาน
- ประโยชน์
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- เกิน
- พันล้าน
- ทั้งสอง
- คอขวด
- กล่อง
- นำมาซึ่ง
- กว้าง
- ธุรกิจ
- ระบบธุรกิจอัจฉริยะ
- ไม่ว่าง
- แต่
- by
- เค้ก
- คำนวณ
- การคำนวณ
- โทรศัพท์
- CAN
- ความสามารถในการ
- กรณี
- กรณี
- ลักษณะ
- ลักษณะ
- แผนภูมิ
- การสับ
- เลือก
- เมือง
- เมฆ
- Cluster
- คอลัมน์
- คอลัมน์
- การผสมผสาน
- มุ่งมั่น
- ร่วมกัน
- เทียบเคียง
- เปรียบเทียบ
- เมื่อเทียบกับ
- เปรียบเทียบ
- คู่แข่ง
- คู่แข่ง
- ซับซ้อน
- ปฏิบัติตาม
- คำนวณ
- คอมพิวเตอร์
- วิสัยทัศน์คอมพิวเตอร์
- แนวคิด
- พร้อมกัน
- สภาพ
- ดำเนินการ
- คงเส้นคงวา
- ปลอบใจ
- คงที่
- ไม่หยุดหย่อน
- เป็น
- การให้คำปรึกษา
- บรรจุ
- เรื่อย
- ต่อ
- อย่างต่อเนื่อง
- ต่อเนื่องกัน
- อย่างต่อเนื่อง
- การปรุงอาหาร
- ตรงกัน
- ราคา
- ค่าใช้จ่าย
- ควบคู่
- สร้าง
- สำคัญมาก
- ลูกค้า
- ลูกค้า
- หน้าปัด
- แดชบอร์ด
- ข้อมูล
- การวิเคราะห์ข้อมูล
- วิเคราะห์ข้อมูล
- การประมวลผล
- ชุดข้อมูล
- คลังข้อมูล
- คลังข้อมูล
- ที่ขับเคลื่อนด้วยข้อมูล
- ฐานข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- วันที่
- การตัดสินใจ
- ค่าเริ่มต้น
- กำหนด
- ส่งมอบ
- การส่งมอบ
- มอบ
- ที่ได้มา
- อธิบาย
- ได้รับการออกแบบ
- ที่ต้องการ
- รายละเอียด
- รายละเอียด
- พัฒนาการ
- การพัฒนา
- ต่าง
- โดยตรง
- สนทนา
- กล่าวถึง
- ความหลากหลาย
- แบ่ง
- do
- ทำ
- ไม่
- Dont
- ขับเคลื่อน
- แต่ละ
- ก่อน
- อย่างง่ายดาย
- กิน
- มีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- เปิดการใช้งาน
- การเปิดใช้งาน
- ส่งเสริม
- เครื่องยนต์
- วิศวกร
- ที่เพิ่มขึ้น
- หัตถการด้านการเสริมความงาม
- ปรับปรุง
- เข้าสู่
- เท่ากัน
- โดยเฉพาะอย่างยิ่ง
- อีเธอร์ (ETH)
- การประเมินผล
- แม้
- ทุกอย่าง
- ตัวอย่าง
- ตัวอย่าง
- คาดหวัง
- ประสบการณ์
- สารสกัด
- ปัจจัย
- คุ้นเคย
- ไกล
- FAST
- เร็วขึ้น
- ลักษณะ
- สองสาม
- ในที่สุด
- หา
- เสร็จสิ้น
- ชื่อจริง
- FLEET
- โฟกัส
- ปฏิบัติตาม
- ดังต่อไปนี้
- สำหรับ
- พบ
- ผู้สร้าง
- ราคาเริ่มต้นที่
- การทำงาน
- ต่อไป
- จุดประสงค์ทั่วไป
- สร้าง
- รุ่น
- ได้รับ
- ได้รับ
- GitHub
- จะช่วยให้
- ไป
- ดี
- การเจริญเติบโต
- เติบโต
- จัดการ
- ฮาร์ดแวร์
- มี
- มี
- he
- จุดสูง
- สูงกว่า
- ของเขา
- ถือ
- โฮลดิ้ง
- ชั่วโมง
- ชั่วโมง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- HTML
- ที่ http
- HTTPS
- ร้อย
- ร้อย
- ในอุดมคติ
- ความนึกคิด
- แยกแยะ
- if
- แสดง
- ภาพ
- ส่งผลกระทบ
- สำคัญ
- ด้านที่สำคัญ
- ปรับปรุง
- การปรับปรุง
- การปรับปรุง
- การปรับปรุง
- การปรับปรุง
- in
- ประกอบด้วย
- รวมถึง
- รวมทั้ง
- เพิ่ม
- เพิ่มขึ้น
- เพิ่มขึ้น
- บ่งชี้ว่า
- ของอุตสาหกรรม
- โครงสร้างพื้นฐาน
- ตัวอย่าง
- อินสแตนซ์
- บูรณาการ
- Intelligence
- การโต้ตอบ
- ภายใน
- การแทรกแซง
- เข้าไป
- แนะนำ
- แนะนำ
- การลงทุน
- ที่เกี่ยวข้องกับการ
- IOT
- IT
- ITS
- ร่วม
- jpg
- เพียงแค่
- เก็บ
- ชุด
- รู้ดี
- ใหญ่
- ที่มีขนาดใหญ่
- ต่อมา
- ล่าสุด
- การพัฒนาล่าสุด
- เปิดตัว
- การเปิดตัว
- ผู้นำ
- ชั้นนำ
- การเรียนรู้
- น้อยที่สุด
- น้อยลง
- ชั้น
- มีน้ำหนักเบา
- กดไลก์
- น้อย
- โหลด
- โหลด
- โหลด
- ที่ตั้งอยู่
- นาน
- อีกต่อไป
- ดู
- ที่ต้องการหา
- ต่ำ
- ลด
- ต่ำที่สุด
- เก็บรักษา
- การบำรุงรักษา
- การบำรุงรักษา
- ส่วนใหญ่
- ทำ
- การจัดการ
- การจัดการ
- ผู้จัดการ
- จัดการ
- คู่มือ
- หลาย
- การจับคู่
- เรื่อง
- อาจ..
- ความหมาย
- วิธี
- วัด
- วัด
- การวัด
- กลาง
- พบ
- หน่วยความจำ
- กล่าวถึง
- อาจ
- การโยกย้าย
- นาที
- ทันสมัย
- วันจันทร์
- เงิน
- ข้อมูลเพิ่มเติม
- ยิ่งไปกว่านั้น
- มากที่สุด
- มาก
- คือ
- จำเป็นต้อง
- จำเป็น
- ความต้องการ
- ใหม่
- นิวยอร์ก
- เมืองนิวยอร์ก
- ใหม่
- ถัดไป
- ไม่
- หมายเหตุ
- เด่น
- สังเกต
- ตอนนี้
- จำนวน
- of
- เป็นทางการ
- มักจะ
- on
- ตามความต้องการ
- ONE
- เพียง
- ทำงาน
- การดำเนินการ
- โอกาส
- ดีที่สุด
- การเพิ่มประสิทธิภาพ
- การเพิ่มประสิทธิภาพ
- ตัวเลือกเสริม (Option)
- Options
- or
- อื่นๆ
- ของเรา
- ออก
- เกิน
- ของตนเอง
- พารามิเตอร์
- ในสิ่งที่สนใจ
- แบบแผน
- รูปแบบ
- ชำระ
- การชำระเงิน
- ต่อ
- เปอร์เซ็นต์
- การปฏิบัติ
- การวางแผน
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- จุด
- ยอดนิยม
- เป็นไปได้
- โพสต์
- อำนาจ
- ทายได้
- นำเสนอ
- ป้องกัน
- ราคา
- การตั้งราคา
- หลัก
- การประมวลผล
- การประมวลผล
- ผลิตภัณฑ์
- การจัดการผลิตภัณฑ์
- พิสูจน์
- พิสูจน์แนวคิด
- ให้
- สาธารณชน
- การตีพิมพ์
- ซื้อ
- คำสั่ง
- อย่างรวดเร็ว
- สุ่ม
- อ่าน
- โลกแห่งความจริง
- เรียลไทม์
- รับ
- เมื่อเร็ว ๆ นี้
- เมื่อเร็ว ๆ นี้
- แนะนำ
- การอ้างอิง
- ภูมิภาค
- ถูกปฏิเสธ..
- ญาติ
- สัมพัทธ์
- ลบ
- ซ้ำแล้วซ้ำอีก
- ซ้ำ
- การจำลองแบบ
- รายงาน
- ตัวแทน
- เป็นตัวแทนของ
- ต้องการ
- ลิขสิทธิ์
- คำตอบ
- รับผิดชอบ
- ส่งผลให้
- ผลสอบ
- ค้าปลีก
- กลับ
- รายได้
- ทบทวน
- ขวา
- หุ่นยนต์
- ผลตอบแทนการลงทุน
- วิ่ง
- วิ่ง
- ทำงาน
- ขาย
- เดียวกัน
- ลด
- เห็น
- scalability
- ขนาด
- ตาชั่ง
- ปรับ
- สแกน
- โครงการ
- สคริปต์
- ที่สอง
- วินาที
- Section
- เห็น
- เมล็ดพันธุ์
- ระดับอาวุโส
- ให้บริการ
- serverless
- บริการ
- บริการ
- ชุด
- การติดตั้ง
- หลาย
- Share
- สั้น
- น่า
- โชว์
- แสดง
- สำคัญ
- อย่างมีความหมาย
- เหมือนกับ
- ง่าย
- พร้อมกัน
- เดียว
- ขนาด
- ขนาด
- เล็ก
- So
- ซอฟต์แวร์
- การพัฒนาซอฟต์แวร์
- เกี่ยวกับอวกาศ
- สเปค
- ที่ระบุไว้
- ความเร็ว
- ใช้จ่าย
- การใช้จ่าย
- ขัดขวาง
- SQL
- เริ่มต้น
- ข้อความที่เริ่ม
- การเริ่มต้น
- เข้าพัก
- ไม่หยุดหย่อน
- ขั้นตอน
- การเก็บรักษา
- ร้านค้า
- ซื่อตรง
- กลยุทธ์
- กระแส
- ที่พริ้ว
- เชือก
- ส่ง
- อย่างเช่น
- ความเหมาะสม
- สนับสนุน
- ที่สนับสนุน
- ระบบ
- ตาราง
- เอา
- นำ
- ทีม
- เทคนิค
- เทคโนโลยี
- บอก
- เมตริกซ์
- ทดสอบ
- การทดสอบ
- กว่า
- ที่
- พื้นที่
- ของพวกเขา
- แล้วก็
- ที่นั่น
- ดังนั้น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- คิด
- นี้
- เหล่านั้น
- พัน
- สาม
- ปริมาณงาน
- เวลา
- ครั้ง
- ไปยัง
- ในวันนี้
- รวม
- การจราจร
- แปลง
- โปร่งใส
- ลอง
- พยายาม
- สองครั้ง
- สอง
- ชนิด
- ชนิด
- ตามแบบฉบับ
- แพร่หลาย
- ไม่สามารถ
- ผิดปกติ
- เข้าใจ
- เป็นเอกลักษณ์
- ทายไม่ถูก
- จนกระทั่ง
- us
- การใช้
- USD
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้งาน
- ผู้ใช้
- ใช้
- การใช้
- ความคุ้มค่า
- ความหลากหลาย
- ต่างๆ
- มาก
- ยอดวิว
- จวน
- วิสัยทัศน์
- รอ
- ต้องการ
- คลังสินค้า
- คือ
- ทาง..
- วิธี
- we
- เว็บ
- บริการเว็บ
- สัปดาห์
- ดี
- คือ
- อะไร
- เมื่อ
- แต่ทว่า
- ที่
- ในขณะที่
- ทำไม
- กว้าง
- จะ
- กับ
- ภายใน
- ไม่มี
- คุ้มค่า
- จะ
- การเขียน
- เขียน
- นิวยอร์ก
- เธอ
- ของคุณ
- ลมทะเล