Bild av författare
Datavetenskap är ett tvärvetenskapligt område som är starkt beroende av att extrahera insikter och fatta välgrundade beslut från stora mängder data. Ett av de grundläggande verktygen i en datavetares verktygslåda är SQL (Structured Query Language), ett programmeringsspråk designat för att hantera och manipulera relationsdatabaser.
I den här artikeln kommer jag att fokusera på en av de mest kraftfulla funktionerna i SQL: joins.
SQL Joins låter dig kombinera data från flera databastabeller baserat på vanliga kolumner. På så sätt kan du slå samman information och skapa meningsfulla kopplingar mellan relaterade datauppsättningar.
Det finns flera typer av SQL-kopplingar:
- Inre koppling
- Vänster yttre skarv
- Höger yttre fog
- Full ytterskarv
- Kors gå med
Låt oss förklara varje typ.
En inre sammanfogning returnerar endast de rader där det finns en matchning i båda tabellerna som sammanfogas. Den kombinerar rader från två tabeller baserade på en delad nyckel eller kolumn, vilket tar bort icke-matchande rader.
Vi visualiserar detta på följande sätt.
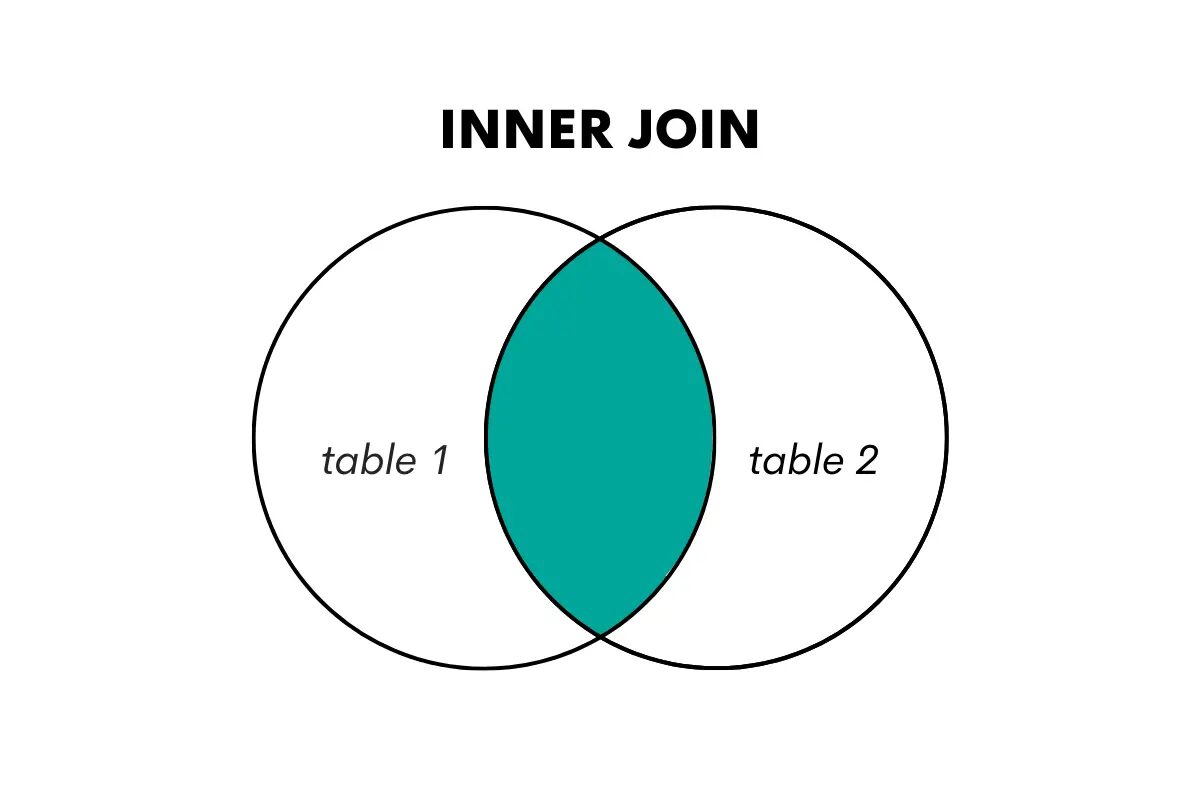
Bild av författare
I SQL utförs denna typ av join med hjälp av nyckelorden JOIN eller INNER JOIN.
En vänster yttre koppling returnerar alla rader från den vänstra (eller första) tabellen och de matchade raderna från den högra (eller andra) tabellen. Om det inte finns någon matchning returnerar den NULL-värden för kolumnerna från den högra tabellen.
Vi kan visualisera det så här.
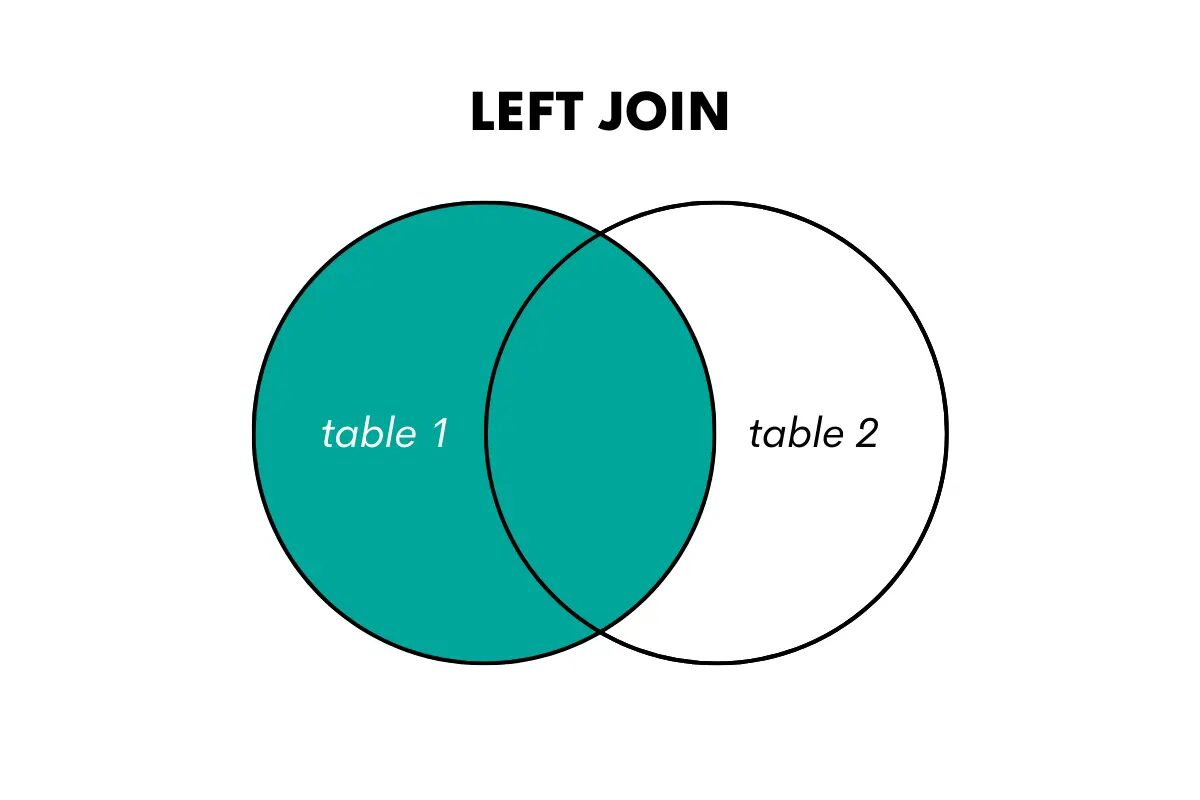
Bild av författare
När du vill använda denna join i SQL kan du göra det genom att använda nyckelorden LEFT OUTER JOIN eller LEFT JOIN. Här är en artikel som handlar om vänster sammanfogning vs vänster yttre sammanfogning.
En högerfogning är motsatsen till en vänsterfogning. Den returnerar alla rader från den högra tabellen och de matchade raderna från den vänstra tabellen. Om det inte finns någon matchning returnerar den NULL-värden för kolumnerna från den vänstra tabellen.
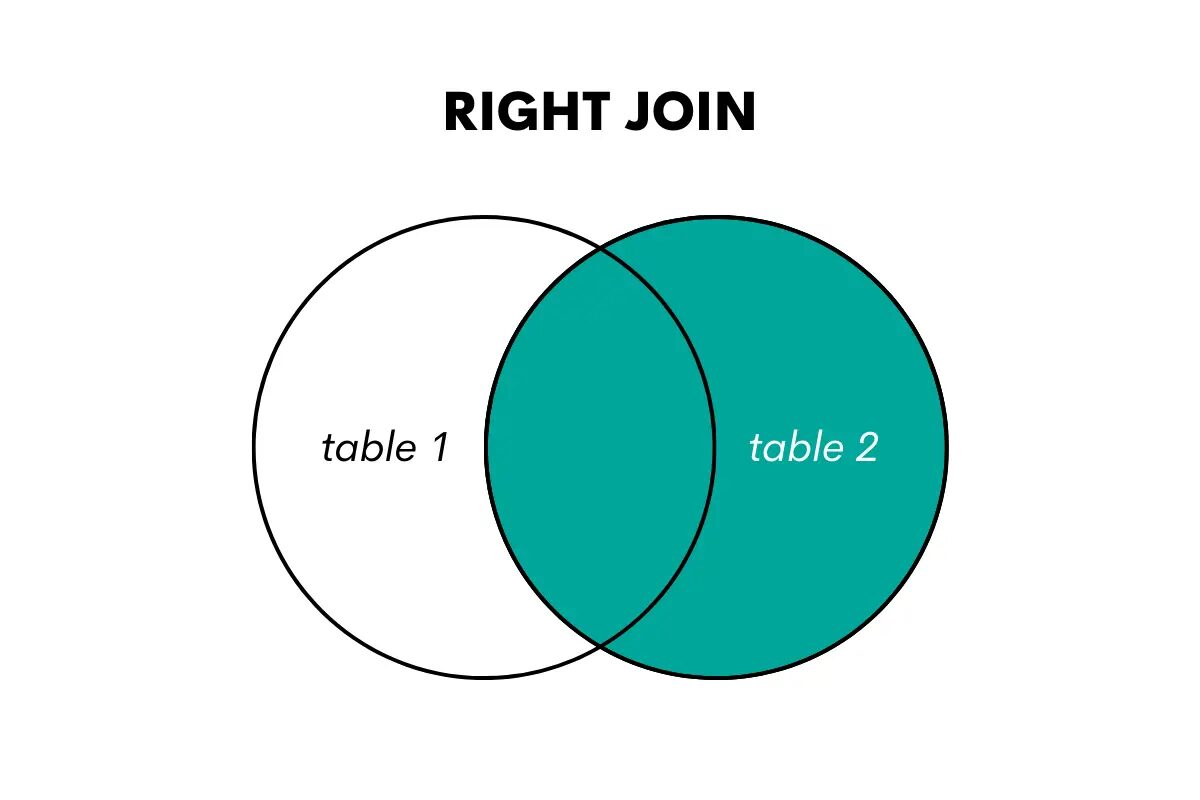
Bild av författare
I SQL utförs denna jointyp med nyckelorden RIGHT OUTER JOIN eller RIGHT JOIN.
En fullständig yttre koppling returnerar alla rader från båda tabellerna, matchande rader där det är möjligt och fyll i NULL-värden för icke-matchande rader.
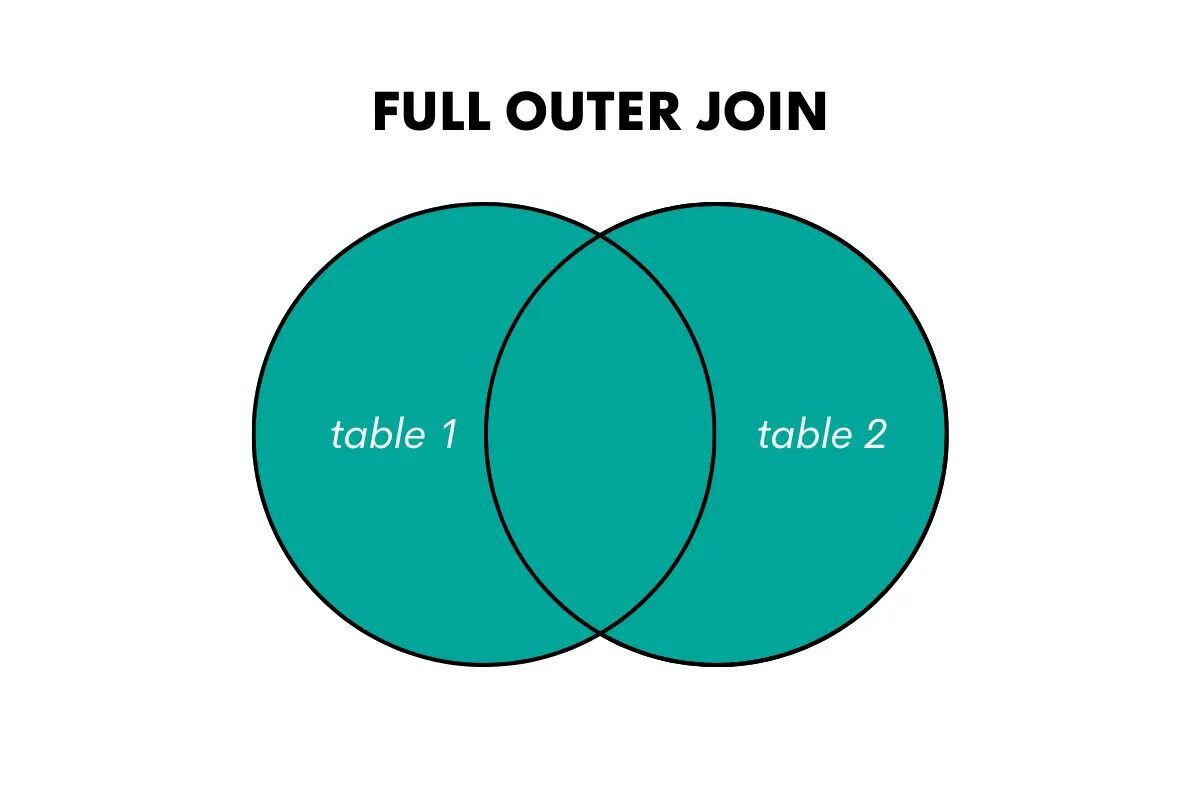
Bild av författare
Nyckelorden i SQL för denna join är FULL OUTER JOIN eller FULL JOIN.
Denna typ av koppling kombinerar alla rader från en tabell med alla rader från den andra tabellen. Med andra ord returnerar den den kartesiska produkten, dvs alla möjliga kombinationer av de två tabellernas rader.
Här är visualiseringen som gör det lättare att förstå.
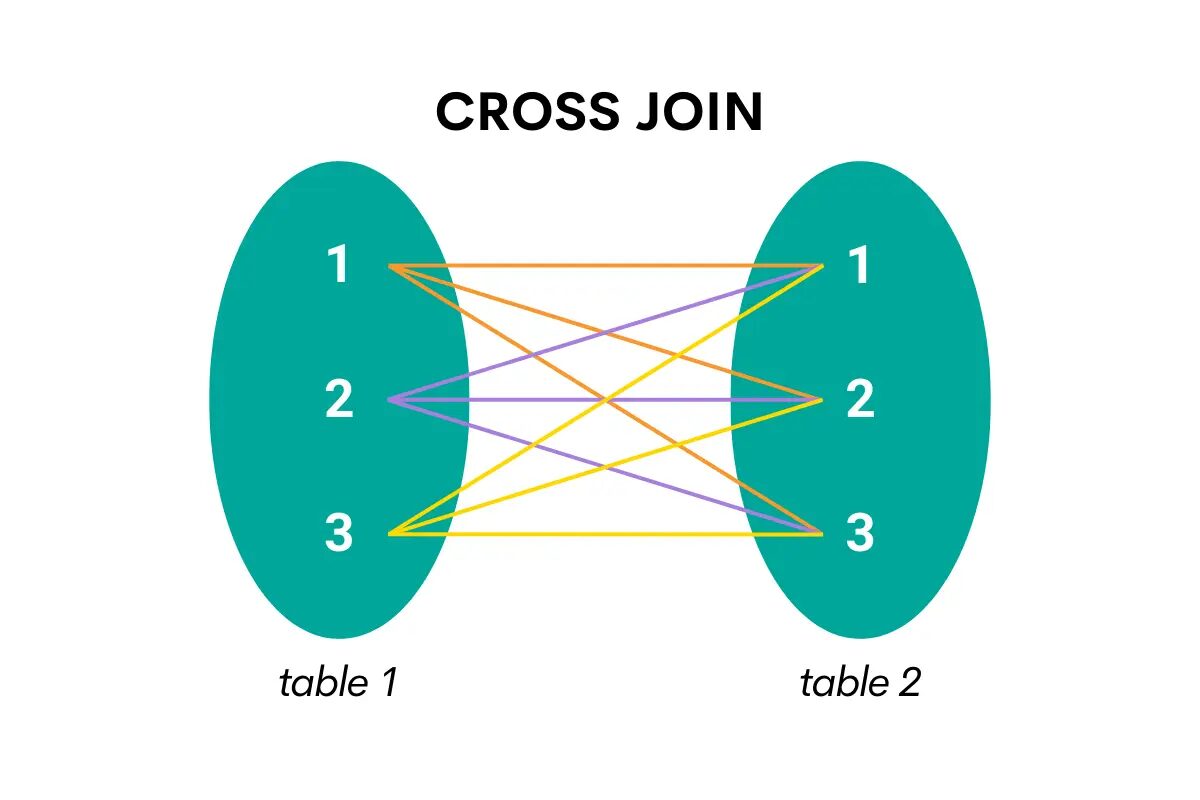
Bild av författare
Vid korskoppling i SQL är nyckelordet CROSS JOIN.
För att utföra en join i SQL måste du ange tabellerna vi vill ansluta, kolumnerna som används för matchning och vilken typ av join vi vill utföra. Den grundläggande syntaxen för att sammanfoga tabeller i SQL är följande:
SELECT columns
FROM table1
JOIN table2
ON table1.column = table2.column;
Detta exempel visar hur man använder JOIN.
Du refererar till den första (eller vänster) tabellen i FROM-satsen. Sedan följer du den med JOIN och refererar till den andra (eller högra) tabellen.
Sedan kommer anslutningsvillkoret i ON-klausulen. Det är här du anger vilka kolumner du ska använda för att sammanfoga de två tabellerna. Vanligtvis är det en delad kolumn som är en primärnyckel i en tabell och den främmande nyckeln i den andra tabellen.
Obs! En primärnyckel är en unik identifierare för varje post i en tabell. En främmande nyckel upprättar en länk mellan två tabeller, dvs det är en kolumn i den andra tabellen som refererar till den första tabellen. Vi visar dig i exemplen vad det betyder.
Om du vill använda LEFT JOIN, RIGHT JOIN eller FULL JOIN, använder du bara dessa nyckelord istället för JOIN – allt annat i koden är exakt detsamma!
Saker och ting är lite annorlunda med CROSS JOIN. I sin natur är att sammanfoga alla radernas kombinationer från båda tabellerna. Det är därför ON-satsen inte behövs, och syntaxen ser ut så här.
SELECT columns
FROM table1
CROSS JOIN table2;
Med andra ord refererar du helt enkelt till en tabell i FROM och den andra i CROSS JOIN.
Alternativt kan du referera till båda tabellerna i FROM och separera dem med ett kommatecken – detta är en förkortning för CROSS JOIN.
SELECT columns
FROM table1, table2;Det finns också ett specifikt sätt att sammanfoga borden – sammanfoga bordet med sig själv. Detta kallas också att själv gå med i bordet.
Det är inte precis en distinkt typ av join, eftersom vilken som helst av de tidigare nämnda jointyperna också kan användas för självanslutning.
Syntaxen för självanslutning liknar det jag visade dig tidigare. Den största skillnaden är att samma tabell refereras till i FROM och JOIN.
SELECT columns
FROM table1 t1
JOIN table1 t2
ON t1.column = t2.column;
Du måste också ge tabellen två alias för att skilja dem åt. Det du gör är att förena bordet med sig självt och behandla det som två bord.
Jag ville bara nämna detta här, men jag ska inte gå in på mer detaljer. Om du är intresserad av att gå med själv, se den här illustrerade guiden om själv gå med i SQL.
Det är dags att visa dig hur allt jag nämnde fungerar i praktiken. Jag ska använda SQL JOIN intervjufrågor från StrataScratch för att visa upp varje distinkt typ av join i SQL.
1. JOIN Exempel
Denna fråga från Microsoft vill att du listar varje projekt och beräknar projektets budget av medarbetaren.
Dyra projekt
"Ges en lista över projekt och anställda som är mappade till varje projekt, beräkna efter mängden projektbudget som tilldelats varje anställd . Resultatet ska inkludera projekttiteln och projektbudgeten avrundat till närmaste heltal. Ordna din lista efter projekt med den högsta budgeten per anställd först.”
Data
Frågan ger två tabeller.
ms_projects
| id: | int |
| Titel: | varchar |
| budget: | int |
ms_emp_projects
| emp_id: | int |
| project_id: | int |
Nu, kolumn-id i tabellen ms_projects är tabellens primärnyckel. Samma kolumn finns i tabellen ms_emp_projects, om än med ett annat namn: project_id. Detta är tabellens främmande nyckel, som refererar till den första tabellen.
Jag kommer att använda dessa två kolumner för att sammanfoga tabellerna i min lösning.
Koda
SELECT title AS project, ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;
Jag slog ihop de två borden med JOIN. Bordet ms_projects refereras i FROM, medan ms_emp_projects refereras efter JOIN. Jag har gett båda tabellerna ett alias, så att jag inte kan använda tabellens långa namn senare.
Nu måste jag ange i vilka kolumner jag vill gå med i tabellerna. Jag har redan nämnt vilka kolumner som är primärnyckeln i en tabell och den främmande nyckeln i en annan tabell, så jag använder dem här.
Jag är lika med dessa två kolumner eftersom jag vill få all data där projekt-ID är detsamma. Jag använde också tabellernas alias framför varje kolumn.
Nu när jag har tillgång till data i båda tabellerna kan jag lista kolumner i SELECT. Den första kolumnen är projektnamnet och den andra kolumnen beräknas.
Denna beräkning använder funktionen COUNT() för att räkna antalet anställda i varje projekt. Sedan delar jag varje projekts budget med antalet anställda. Jag konverterar också resultatet till decimaler och avrundar det till noll decimaler.
Produktion
Här är vad frågan returnerar.
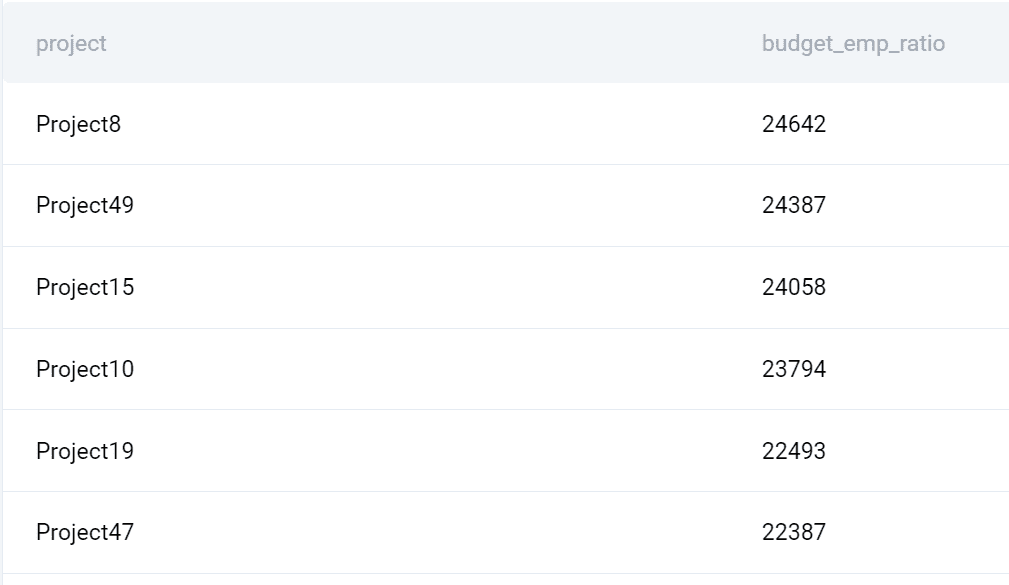
2. LEFT JOIN Exempel
Låt oss öva på detta gå med på Airbnb intervjufråga. Den vill att du ska hitta antalet beställningar, antalet kunder och den totala kostnaden för beställningar för varje stad.
Kundbeställningar och detaljer
"Hitta antalet beställningar, antalet kunder och den totala kostnaden för beställningar för varje stad. Inkludera endast städer som har gjort minst 5 beställningar och räkna alla kunder i varje stad även om de inte lagt en beställning.
Skriv ut varje beräkning tillsammans med motsvarande stadsnamn."
Data
Du får tabellerna kunder, och ordrar.
kunder
| id: | int |
| förnamn: | varchar |
| efternamn: | varchar |
| stad: | varchar |
| adress: | varchar |
| telefonnummer: | varchar |
ordrar
| id: | int |
| kund_id: | int |
| orderdatum: | datum Tid |
| Orderdetaljer: | varchar |
| total_order_cost: | int |
De delade kolumnerna är id från tabellen kunder och cust_id från tabellen ordrar. Jag kommer att använda dessa kolumner för att gå med i tabellerna.
Koda
Så här löser du denna fråga med LEFT JOIN.
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
Jag hänvisar till tabellen kunder in FROM (detta är vårt vänstra bord) och LEFT JOIN det med ordrar på kund-ID-kolumnerna.
Nu kan jag välja stad, använda COUNT() för att få antalet beställningar och kunder per stad, och använda SUM() för att beräkna den totala beställningskostnaden per stad.
För att få alla dessa beräkningar efter stad, grupperar jag resultatet efter stad.
Det finns en extra begäran i frågan: "Inkludera endast städer som har gjort minst 5 beställningar..." Jag använder HAVING för att endast visa städer med fem eller fler beställningar för att uppnå det.
Frågan är varför jag använde VÄNSTER GÅ och inte JOIN? Ledtråden ligger i frågan:"...och räkna alla kunder i varje stad även om de inte lagt en beställning." Det är möjligt att inte alla kunder har lagt beställningar. Det betyder att jag vill visa alla kunder från bordet kunder, vilket perfekt passar definitionen av LEFT JOIN.
Hade jag använt JOIN hade resultatet blivit fel, eftersom jag hade saknat de kunder som inte lagt några beställningar.
Obs: Komplexiteten hos joins i SQL återspeglas inte i deras syntax utan i deras semantik! Som du såg skrivs varje koppling på samma sätt, bara nyckelordet ändras. Men varje koppling fungerar på olika sätt och kan därför visa olika resultat beroende på data. På grund av det är det avgörande att du till fullo förstår vad varje medlem gör och väljer den som kommer att ge exakt det du vill ha!
Produktion
Låt oss nu ta en titt på utgången.

3. RIGHT JOIN Exempel
RIGHT JOIN är spegelbilden av LEFT JOIN. Det är därför jag enkelt kunde ha löst det tidigare problemet med RIGHT JOIN. Låt mig visa dig hur du gör.
Data
Borden förblir desamma; Jag använder bara en annan typ av join.
Koda
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id GROUP BY c.city
HAVING COUNT(o.id) >=5;
Här är vad som har ändrats. När jag använder RIGHT JOIN ändrade jag ordningen på tabellerna. Nu bordet ordrar blir den vänstra och bordet kunder den rätta. Sammanfogningsvillkoret förblir detsamma. Jag ändrade bara ordningen på kolumnerna för att återspegla ordningen på tabellerna, men det är inte nödvändigt att göra det.
Genom att byta ordning på borden och använda RIGHT JOIN kommer jag återigen att visa alla kunder, även om de inte har lagt några beställningar.
Resten av frågan är densamma som i föregående exempel. Detsamma gäller utgången.
Obs: I praktiken HÖGER GÅ MED används relativt sällan. LEFT JOIN verkar mer naturligt för SQL-användare, så de använder det mycket oftare. Allt som kan göras med RIGHT JOIN kan också göras med LEFT JOIN. På grund av det finns det ingen specifik situation där RIGHT JOIN kan föredras.
Produktion
4. FULL GÅNG Exempel
Frågan från Salesforce och Tesla vill att du ska räkna nettoskillnaden mellan antalet produktföretag som lanserades 2020 och antalet produktföretag som lanserades föregående år.
Nya produkter
"Du får en tabell över produktlanseringar per företag per år. Skriv en fråga för att räkna nettoskillnaden mellan antalet produktföretag som lanserades 2020 och antalet produktföretag som lanserades föregående år. Skriv ut namnet på företagen och en nettoskillnad av nettoprodukter som släppts för 2020 jämfört med föregående år.”
Data
Frågan ger en tabell med följande kolumner.
bil_lanser
| år: | int |
| Företagsnamn: | varchar |
| produktnamn: | varchar |
Hur i helvete ska jag gå med i bord när det bara finns ett bord? Hmm, låt oss se det också!
Koda
Den här frågan är lite mer komplicerad, så jag kommer att avslöja den gradvis.
SELECT company_name, product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;
Den första SELECT-satsen hittar företaget och produktnamnet 2020. Denna fråga kommer senare att omvandlas till en underfråga.
Frågan vill att du ska hitta skillnaden mellan 2020 och 2019. Så låt oss skriva samma fråga men för 2019.
SELECT company_name, product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019;
Jag ska nu göra dessa frågor till underfrågor och gå med i dem med FULL OUTER JOIN.
SELECT *
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name;
Underfrågor kan behandlas som tabeller och kan därför sammanfogas. Jag gav den första underfrågan ett alias och placerade den i FROM-satsen. Sedan använder jag FULL OUTER JOIN för att sammanfoga den med den andra underfrågan i företagsnamnkolumnen.
Genom att använda den här typen av SQL join kommer jag att få alla företag och produkter under 2020 sammanslagna med alla företag och produkter under 2019.
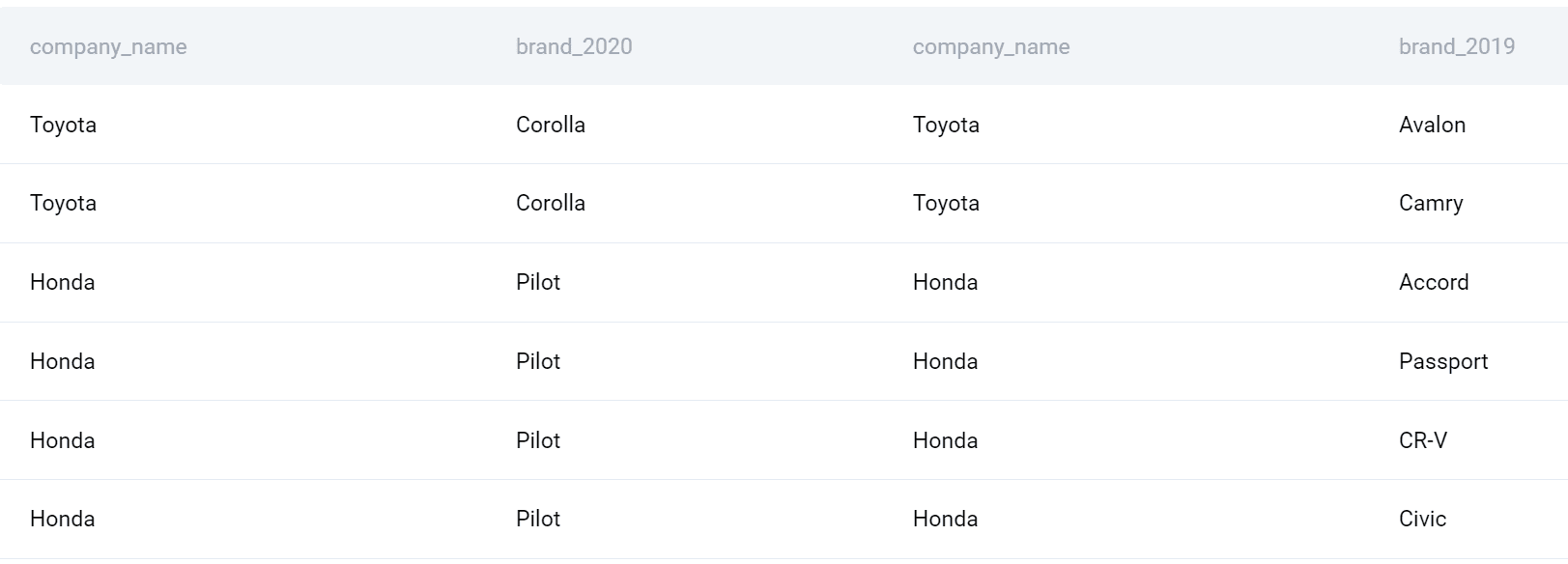
Nu kan jag slutföra min fråga. Låt oss välja företagets namn. Jag kommer också att använda COUNT()-funktionen för att hitta antalet produkter som lanseras varje år och sedan subtrahera det för att få skillnaden. Slutligen ska jag gruppera produktionen efter företag och sortera den också efter företag i alfabetisk ordning.
Här är hela frågan.
SELECT a.company_name, (COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_products
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name
GROUP BY a.company_name
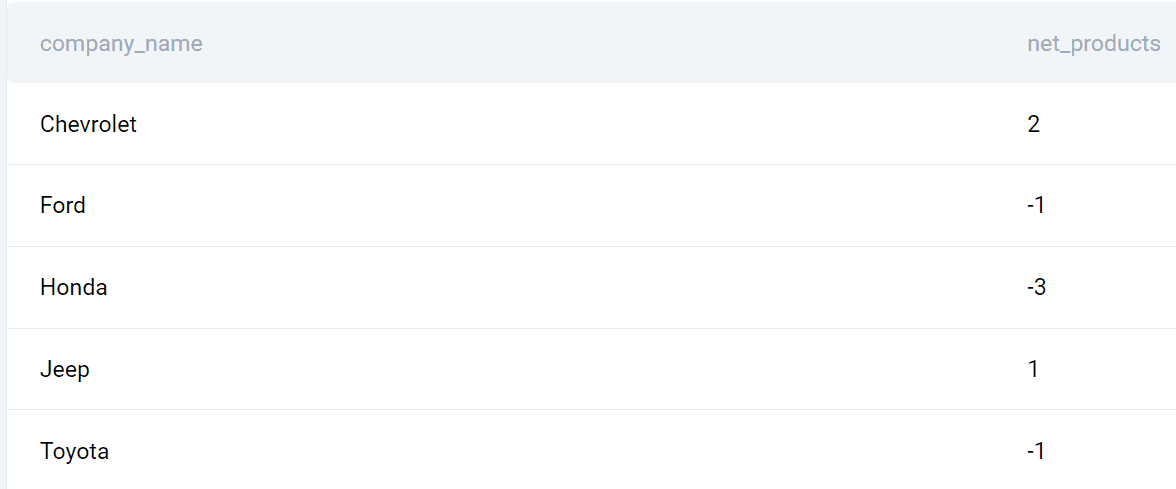
ORDER BY company_name;Produktion
Här är listan över företag och de lanserade produkternas skillnader mellan 2020 och 2019.
5. CROSS JOIN Exempel
Denna fråga från Deloitte är bra för att visa hur CROSS JOIN fungerar.
Max två nummer
"Med tanke på en enda kolumn med tal, överväg alla möjliga permutationer av två tal förutsatt att par av tal (x,y) och (y,x) är två olika permutationer. Hitta sedan det maximala av de två talen för varje permutation.
Skriv ut tre kolumner: den första siffran, den andra siffran och det maximala av de två."
Frågan vill att du ska hitta alla möjliga permutationer av två tal förutsatt att par av tal (x,y) och (y,x) är två olika permutationer. Sedan måste vi hitta det maximala antalet för varje permutation.
Data
Frågan ger oss en tabell med en kolumn.
deloitte_numbers
| Nummer: | int |
Koda
Denna kod är ett exempel på CROSS JOIN, men också på self join.
SELECT dn1.number AS number1, dn2.number AS number2, CASE WHEN dn1.number > dn2.number THEN dn1.number ELSE dn2.number END AS max_number
FROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
Jag refererar till tabellen i FROM och ger den ett alias. Sedan CROSS JOIN den med sig själv genom att referera till den efter CROSS JOIN och ge bordet ett annat alias.
Nu är det möjligt att använda ett bord eftersom de är två. Jag väljer kolumnnumret från varje tabell. Sedan använder jag CASE-satsen för att ställa in ett villkor som visar det maximala antalet av de två talen.
Varför används CROSS JOIN här? Kom ihåg att det är en typ av SQL-join som visar alla kombinationer av alla rader från alla tabeller. Det är precis vad frågan ställer sig!
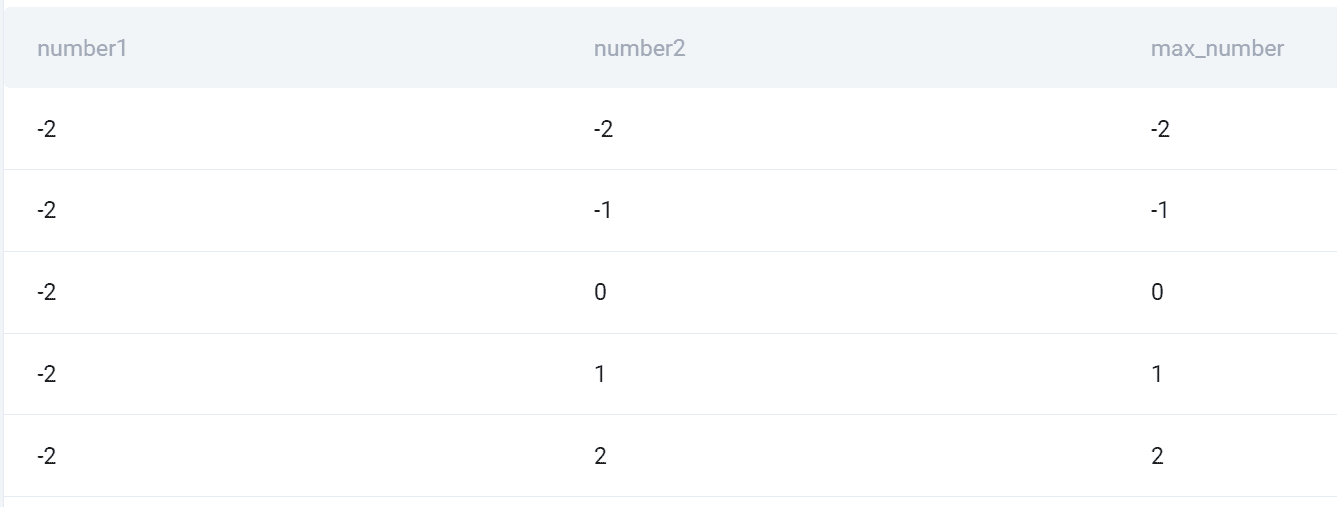
Produktion
Här är ögonblicksbilden av alla kombinationer och det högre antalet av de två.
Nu när du vet hur man använder SQL-anslutningar är frågan hur man använder den kunskapen inom datavetenskap.
SQL Joins spelar en avgörande roll i datavetenskapliga uppgifter som datautforskning, datarensning och funktionsteknik.
Här är några exempel på hur SQL-kopplingar kan utnyttjas:
- Kombinera data: Genom att sammanfoga tabeller kan du sammanföra olika datakällor, vilket gör att du kan analysera relationer och korrelationer över flera datamängder. Att till exempel sammanfoga ett kundbord med en transaktionstabell kan ge insikter om kundernas beteende och köpmönster.
- Datavalidering: Joins kan användas för att validera datakvalitet och integritet. Genom att jämföra data från olika tabeller kan du identifiera inkonsekvenser, saknade värden eller extremvärden. Detta hjälper dig med datarensning och säkerställer att data som används för analys är korrekta och tillförlitliga.
- Funktionsteknik: Joins kan vara avgörande för att skapa nya funktioner för maskininlärningsmodeller. Genom att slå samman relevanta tabeller kan du extrahera meningsfull information och generera funktioner som fångar viktiga relationer i datan. Detta kan förbättra prediktiva kraften hos dina modeller.
- Aggregation och analys: Joins gör att du kan utföra komplexa aggregationer och analyser över flera tabeller. Genom att kombinera data från olika källor kan du få en heltäckande bild av data och få värdefulla insikter. Att till exempel slå samman en försäljningstabell med en produkttabell kan hjälpa dig att analysera försäljningsresultat efter produktkategori eller region.
Som jag redan nämnt visas inte komplexiteten i sammanfogningar i deras syntax. Du såg att syntaxen är relativt okomplicerad.
De bästa metoderna för joins återspeglar också det, eftersom de inte handlar om själva kodningen utan vad join gör och hur den fungerar.
För att få ut så mycket som möjligt av kopplingar i SQL, överväg följande bästa praxis.
- Förstå dina data: Bekanta dig med strukturen och relationerna i din data. Detta hjälper dig att välja lämplig typ av sammanfogning och välja rätt kolumner för matchning.
- Använd index: Om dina tabeller är stora eller ofta sammanfogade, överväg att lägga till index på de kolumner som används för att gå med. Index kan avsevärt förbättra frågeprestanda.
- Var uppmärksam på prestanda: Att sammanfoga stora bord eller flera bord kan vara beräkningsmässigt dyrt. Optimera dina frågor genom att filtrera data, använda lämpliga kopplingstyper och överväga användningen av tillfälliga tabeller eller underfrågor.
- Testa och validera: Verifiera alltid dina anslutningsresultat för att säkerställa korrekthet. Utför förnuftskontroller och verifiera att de sammanfogade uppgifterna stämmer överens med dina förväntningar och affärslogik.
SQL Joins är ett grundläggande koncept som ger dig som datavetare möjlighet att slå samman och analysera data från flera källor. Genom att förstå de olika typerna av SQL-kopplingar, behärska deras syntax och utnyttja dem effektivt, kan datavetare låsa upp värdefulla insikter, validera datakvalitet och driva datadrivet beslutsfattande.
Jag visade dig hur du gör i fem exempel. Nu är det upp till dig att utnyttja kraften i SQL och gå med i dina datavetenskapliga projekt och uppnå bättre resultat.
Nate Rosidi är datavetare och inom produktstrategi. Han är också adjungerad professor som undervisar i analys och är grundaren av StrataScratch, en plattform som hjälper datavetare att förbereda sig för sina intervjuer med riktiga intervjufrågor från toppföretag. Ta kontakt med honom Twitter: StrataScratch or LinkedIn.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Fordon / elbilar, Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- BlockOffsets. Modernisera miljökompensation ägande. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/08/sql-data-science-understanding-leveraging-joins.html?utm_source=rss&utm_medium=rss&utm_campaign=sql-for-data-science-understanding-and-leveraging-joins
- :är
- :inte
- :var
- $UPP
- 1
- 11
- 12
- 13
- 2019
- 2020
- 7
- 8
- a
- Om oss
- tillgång
- Tillgång till data
- exakt
- Uppnå
- tvärs
- tillsats
- tillägg
- Efter
- igen
- aggregation
- Justerar
- Alla
- allokeras
- tillåter
- tillåta
- tillåter
- längs
- redan
- också
- alltid
- mängd
- mängder
- an
- analys
- analytics
- analysera
- och
- Annan
- vilken som helst
- något
- lämpligt
- ÄR
- Artikeln
- AS
- At
- b
- baserat
- grundläggande
- BE
- därför att
- blir
- varit
- Där vi får lov att vara utan att konstant prestera,
- BÄST
- bästa praxis
- Bättre
- mellan
- båda
- föra
- budget
- företag
- men
- by
- beräkna
- beräknat
- kallas
- KAN
- fånga
- Vid
- Kategori
- ändrats
- Förändringar
- Kontroller
- Välja
- Städer
- Stad
- Rengöring
- koda
- Kodning
- Kolumn
- Kolonner
- COM
- kombinationer
- kombinera
- kombinerar
- kombinera
- kommer
- Gemensam
- Företag
- företag
- jämfört
- jämförande
- komplex
- Komplexiteten
- komplicerad
- omfattande
- begrepp
- aktuella
- tillstånd
- Kontakta
- Anslutningar
- Tänk
- med tanke på
- konvertera
- Motsvarande
- Pris
- skapa
- Skapa
- Cross
- avgörande
- kund
- kundbeteende
- Kunder
- datum
- Datakvalitet
- datavetenskap
- datavetare
- data driven
- Databas
- databaser
- datauppsättningar
- Beslutsfattande
- beslut
- definition
- beroende
- utformade
- detalj
- DID
- Skillnaden
- olika
- distinkt
- skilja på
- do
- gör
- inte
- gör
- gjort
- driv
- e
- varje
- Tidigare
- lättare
- lätt
- effektivt
- annars
- Anställd
- anställda
- bemyndigar
- möjliggöra
- möjliggör
- änden
- Teknik
- förbättra
- säkerställa
- säkerställer
- lika
- upprättar
- Även
- allt
- exakt
- exempel
- exempel
- förväntningar
- dyra
- Förklara
- utforskning
- extra
- extrahera
- Leverans
- Funktioner
- få
- fält
- fyllning
- filtrering
- avsluta
- Slutligen
- hitta
- fynd
- Förnamn
- fem
- Flyta
- Fokus
- följer
- efter
- följer
- För
- utländska
- hittade
- grundare
- ofta
- från
- främre
- full
- fullständigt
- fungera
- grundläggande
- ytterligare
- Få
- generera
- skaffa sig
- Ge
- ges
- ger
- Ge
- Går
- kommer
- gradvis
- stor
- Grupp
- styra
- sele
- Har
- har
- he
- kraftigt
- hjälpa
- hjälpa
- hjälper
- här.
- högre
- högsta
- honom
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- i
- SJUK
- ID
- identifierare
- identifiera
- if
- bild
- med Esport
- förbättra
- in
- I andra
- innefattar
- index
- informationen
- informeras
- insikter
- istället
- instrumental
- integritet
- intresserad
- Intervju
- intervjufrågor
- Intervjuer
- in
- IT
- DESS
- sig
- delta
- fogade
- sammanfogning
- Fogar
- jpg
- bara
- KDnuggets
- Nyckel
- nyckelord
- Vet
- kunskap
- språk
- Large
- senare
- lanserades
- lanserar
- inlärning
- t minst
- vänster
- hävstångs
- tycka om
- LINK
- Lista
- liten
- Logiken
- Lång
- se
- UTSEENDE
- Maskinen
- maskininlärning
- gjord
- Huvudsida
- göra
- Framställning
- hantera
- manipulerings
- Mastering
- Match
- matchas
- matchande
- maximal
- me
- meningsfull
- betyder
- nämnts
- Sammanfoga
- sammanslagning
- kanske
- spegel
- Mirror Image
- missade
- saknas
- modeller
- mer
- mest
- mycket
- multipel
- my
- namn
- namn
- Natural
- Natur
- nödvändigt för
- Behöver
- behövs
- netto
- Nya
- Nya funktioner
- Nej
- nu
- antal
- nummer
- of
- Ofta
- on
- ONE
- endast
- motsatt
- Optimera
- or
- beställa
- ordrar
- Övriga
- vår
- ut
- produktion
- par
- mönster
- för
- utföra
- prestanda
- utfört
- utför
- Plats
- platser
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Spela
- snälla du
- möjlig
- kraft
- den mäktigaste
- praktiken
- praxis
- föredragen
- Förbered
- föregående
- primär
- Problem
- Produkt
- Produkter
- Professor
- Programmering
- projektet
- projekt
- ge
- ger
- inköp
- kvalitet
- sökfrågor
- fråga
- frågor
- sällan
- verklig
- post
- referenser
- erat
- reflektera
- reflekterad
- region
- relaterad
- Förhållanden
- relativt
- frigörs
- relevanta
- pålitlig
- ihåg
- begära
- REST
- resultera
- Resultat
- avkastning
- återgår
- avslöjar
- höger
- Roll
- rund
- s
- försäljning
- Salesforce
- Samma
- såg
- Vetenskap
- Forskare
- vetenskapsmän
- Andra
- se
- verkar
- SJÄLV
- separat
- in
- flera
- delas
- stenografi
- skall
- show
- visa
- visade
- visar
- Visar
- signifikant
- liknande
- helt enkelt
- enda
- Situationen
- Snapshot
- So
- lösning
- LÖSA
- Källor
- specifik
- SQL
- .
- bo
- okomplicerad
- Strategi
- struktur
- strukturerade
- sådana
- bytte
- syntax
- T1
- bord
- Talks
- uppgifter
- Undervisning
- temporär
- testa
- den där
- Smakämnen
- deras
- Dem
- sedan
- Där.
- därför
- Dessa
- de
- detta
- tre
- tid
- Titel
- till
- tillsammans
- Verktygslåda
- verktyg
- topp
- Totalt
- transaktion
- behandlad
- behandling
- vände
- två
- Typ
- typer
- förstå
- förståelse
- unika
- låsa
- us
- användning
- Begagnade
- användare
- användningar
- med hjälp av
- vanligen
- utnyttja
- BEKRÄFTA
- godkännande
- Värdefulla
- Värden
- olika
- Omfattande
- verifiera
- utsikt
- visualisering
- vs
- vill
- ville
- önskar
- vill
- Sätt..
- we
- Vad
- när
- som
- medan
- Hela
- varför
- kommer
- med
- inom
- ord
- fungerar
- skriva
- skriven
- Fel
- X
- år
- dig
- Din
- själv
- zephyrnet
- noll-