I den moderna världen förlitar sig de flesta företag på kraften i big data och analyser för att driva tillväxt, strategiska investeringar och kundengagemang. Big data är den underliggande konstanten i den riktade annonsen, personlig marknadsföring, produktrekommendationer, generering av insikter, prisoptimeringar, sentimentanalys, prediktiv analys och mycket mer.
Data samlas ofta in från flera källor, omvandlas, lagras och bearbetas på datasjöar on-prem eller on-cloud. Även om det initiala intaget av data är relativt trivialt och kan uppnås genom anpassade skript som utvecklats internt eller traditionella ETL-verktyg (Extract Transform Load), blir problemet snabbt oöverkomligt komplext och dyrt att lösa eftersom företagen måste:
- Hantera hela datalivscykeln – för hushålls- och efterlevnadsändamål
- Optimera lagring – för att minska tillhörande kostnader
- Förenkla arkitekturen – genom återanvändning av datorinfrastruktur
- Bearbeta data stegvis – genom kraftfull statlig förvaltning
- Tillämpa samma policyer på batch- och streamdata – utan dubbelarbete
- Migrera mellan On-prem och Cloud – med minsta möjliga ansträngning
Det är där Apache Gobblin, ett datahanterings- och integrationssystem med öppen källkod kommer in. Apache Gobblin erbjuder oöverträffade möjligheter som kan användas helt eller delvis beroende på verksamhetens behov.
I det här avsnittet kommer vi att fördjupa oss i de olika funktionerna hos Apache Gobblin som hjälper till att hantera de utmaningar som beskrivits tidigare.
Hantera hela datalivscykeln
Apache Gobblin tillhandahåller ett spektrum av funktioner för att konstruera datapipelines som stöder hela uppsättningen av datalivscykeloperationer på datamängder.
- Ta in data – från flera källor till sänkor, allt från databaser, Rest API:er, FTP/SFTP-servrar, Filers, CRMs som Salesforce och Dynamics och mer.
- Replikera data – mellan flera datasjöar med specialiserade möjligheter för Hadoop Distributed File System via Distcp-NG.
- Rensa data – med hjälp av lagringspolicyer som tidsbaserad, senaste K, versionerad eller en kombination av policyer.
Gobblins logiska pipeline består av en "Källa" som bestämmer fördelningen av arbetet och skapar "Workunits". Dessa 'Workunits' plockas sedan upp för exekvering som 'Tasks', vilket inkluderar extrahering, konvertering, kvalitetskontroll och skrivning av data till destinationen. Det sista steget, 'Data Publish', validerar den framgångsrika exekveringen av pipelinen och atomiskt befäster utdata, om destinationen stöder det.
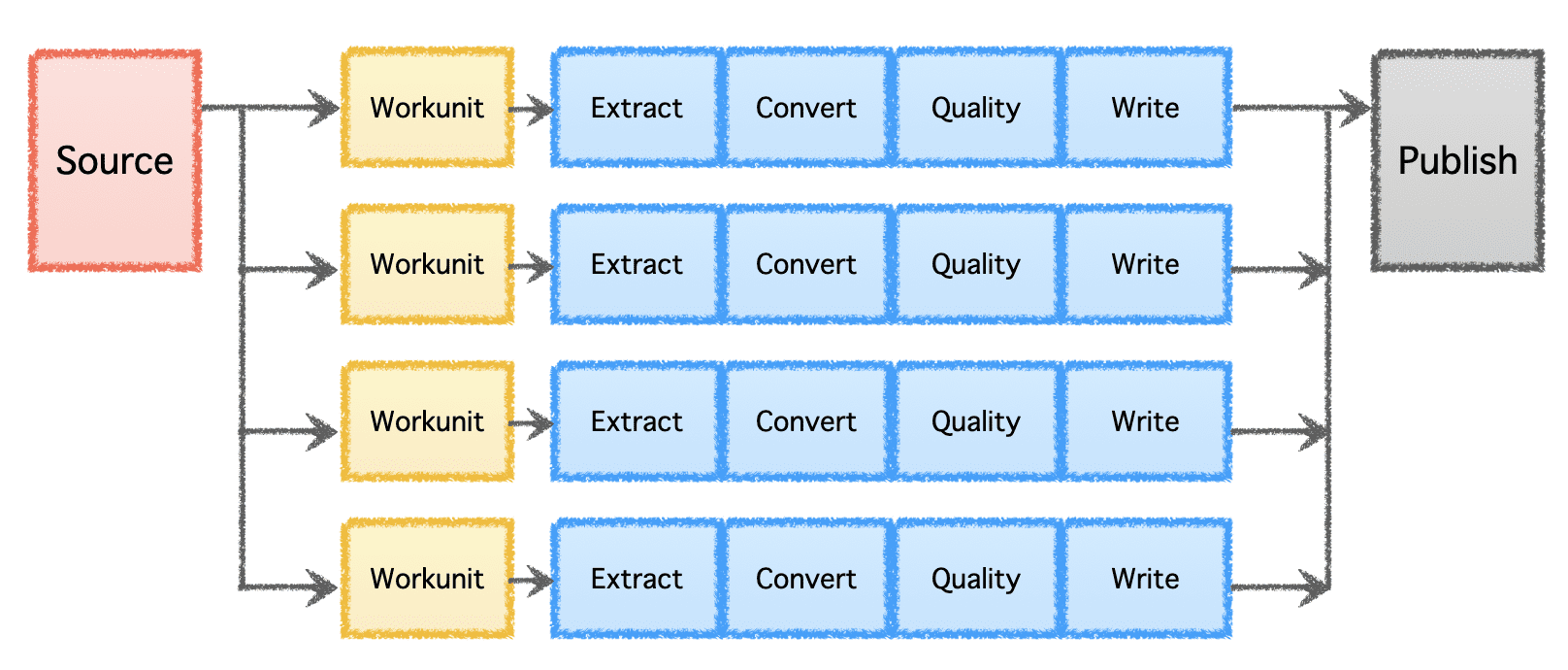
Bild av författare
Optimera lagring
Apache Gobblin kan hjälpa till att minska mängden lagring som behövs för data genom efterbearbetning av data efter intag eller replikering genom komprimering eller formatkonvertering.
- Komprimering – efterbearbetning av data för att deduplicera baserat på alla fält eller nyckelfält i posterna, trimma data för att bara behålla en post med den senaste tidsstämpeln med samma nyckel.
- Avro till ORC – som en specialiserad formatkonverteringsmekanism för att konvertera det populära radbaserade Avro-formatet till ett hyperoptimerat kolumnbaserat ORC-format.
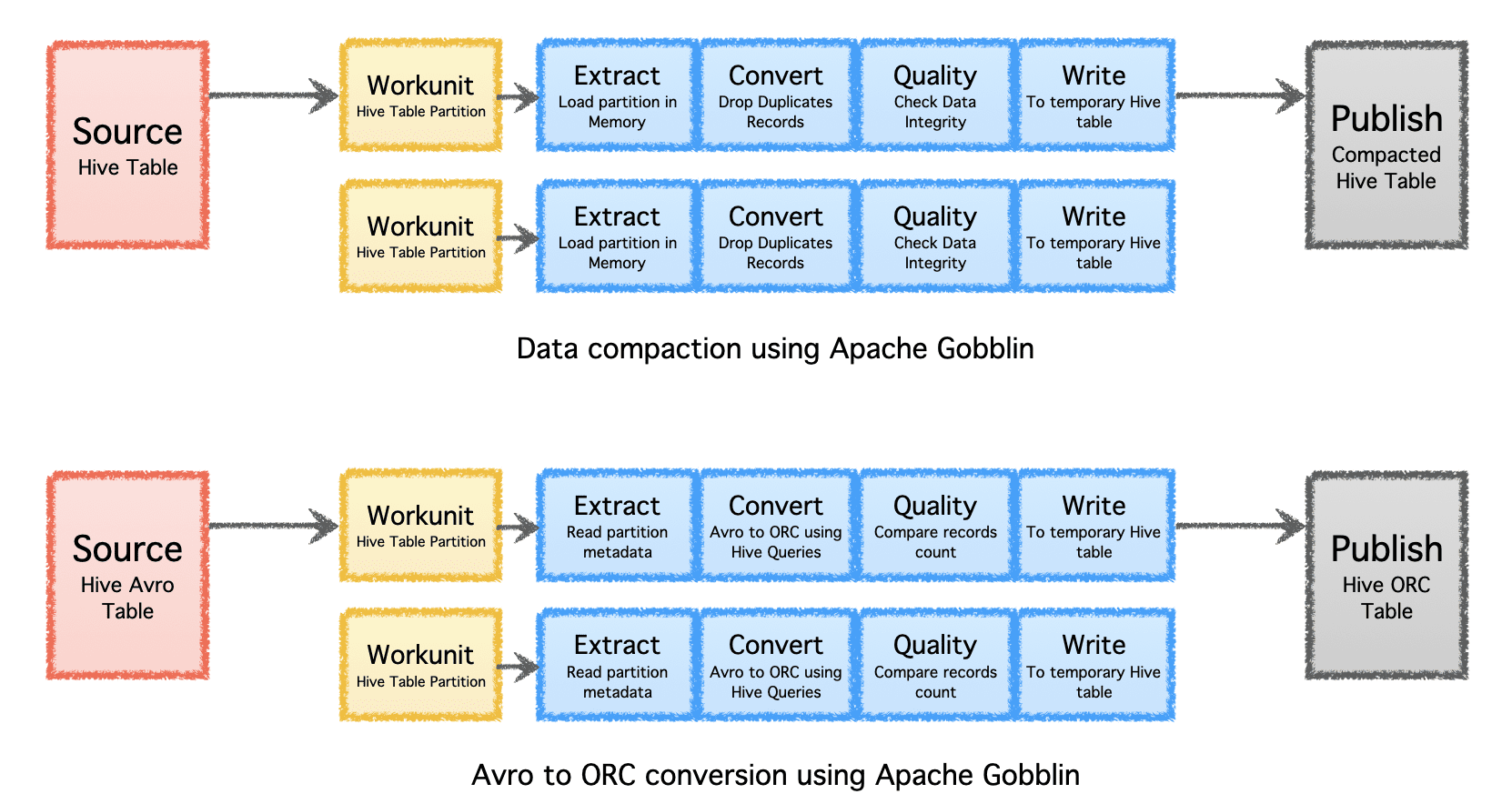
Bild av författare
Förenkla arkitekturen
Beroende på företagets stadie (start till företag), skalkrav och deras respektive arkitektur, föredrar företag att installera eller utveckla sin datainfrastruktur. Apache Gobblin är mycket flexibel och stöder flera exekveringsmodeller.
- Fristående läge – att köras som en fristående process på en bar metalllåda, dvs en enda värd för enkla användningsfall och lågkrävande situationer.
- MapReduce Mode – att köra som ett MapReduce-jobb på Hadoop-infrastruktur för big data-fall för att hantera datauppsättningar i Petabyte-skala.
- Klusterläge: Fristående – att köras som ett kluster med stöd av Apache Helix och Apache Zookeeper på en uppsättning maskiner eller värdar av ren metall för att hantera storskalighet oberoende av Hadoop MR-ramverket.
- Cluster Mode: Yarn – att köras som ett kluster på inbyggt garn utan Hadoop MR-ramverket.
- Cluster Mode: AWS – att köra som ett kluster på Amazons publika molnerbjudande, dvs. AWS för infrastrukturer på AWS.
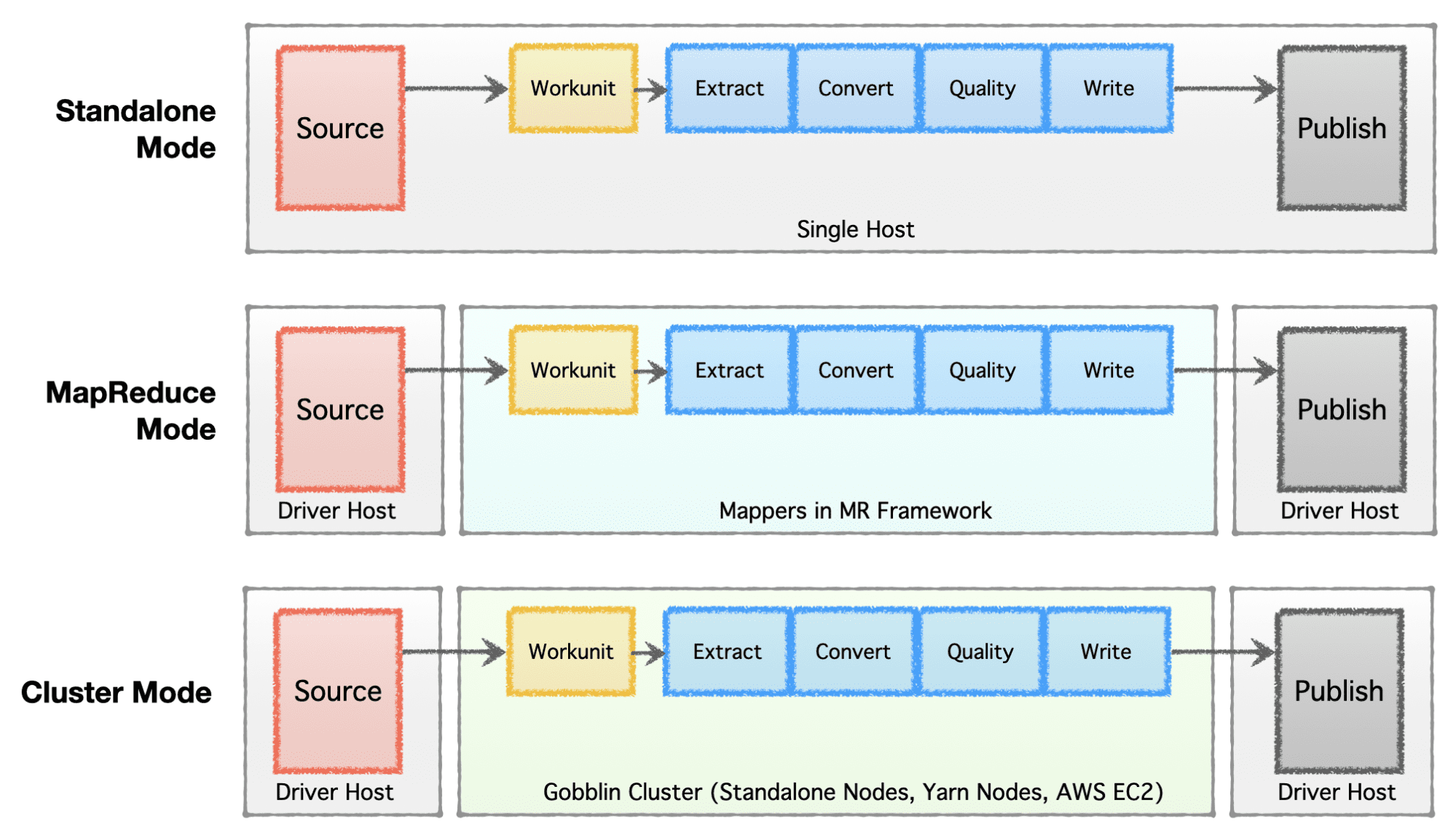
Bild av författare
Bearbeta data stegvis
I en betydande skala med flera datapipelines och hög volym behöver data bearbetas i omgångar och över tid. Därför kräver det kontrollpunkter så att datapipelines kan återupptas från där de slutade förra gången och fortsätta framåt. Apache Gobblin stöder låga och höga vattenstämplar och stöder robust semantik för tillståndshantering via State Store på HDFS, AWS S3, MySQL och mer transparent.
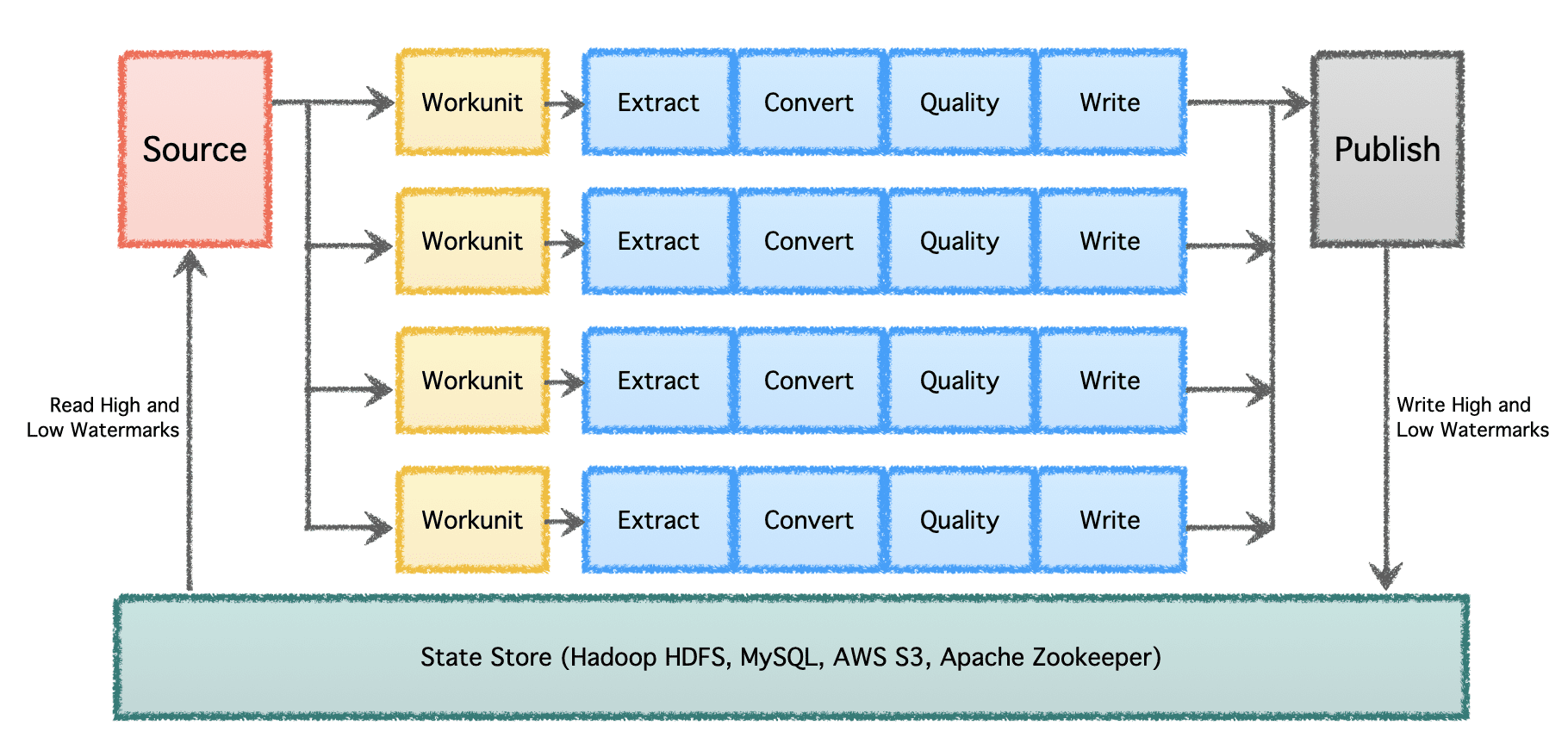
Bild av författare
Samma policyer för batch- och streamdata
De flesta datapipelines idag måste skrivas två gånger, en gång för batchdata och igen för near-line eller strömmande data. Det fördubblar ansträngningen och introducerar inkonsekvenser i policyer och algoritmer som tillämpas på olika typer av pipelines. Apache Gobblin löser detta genom att tillåta användare att skapa en pipeline en gång och köra den på både batch- och streamdata om den används i Gobblin Cluster-läge, Gobblin på AWS-läge eller Gobblin på garn-läge.
Migrera mellan On-prem och Cloud
På grund av dess mångsidiga lägen som kan köras on-prem på en enda box, ett kluster av noder eller molnet – Apache Gobblin kan distribueras och användas on-prem och på molnet. Därför tillåter användare att skriva sina datapipelines en gång och migrera dem tillsammans med Gobblin-distributioner enkelt mellan on-prem och moln, baserat på specifika behov.
På grund av sin mycket flexibla arkitektur, kraftfulla funktioner och den extrema omfattningen av datavolymer som den kan stödja och bearbeta, används Apache Gobblin i produktionsinfrastrukturen för stora teknikföretag och är ett måste för all implementering av big data-infrastruktur idag.
Mer information om Apache Gobblin och hur man använder den finns på https://gobblin.apache.org
Abhishek Tiwari är Senior Manager på LinkedIn och leder företagets Big Data Pipelines-organisation. Han är också vicepresident för Apache Gobblin vid Apache Software Foundation och medlem i British Computer Society.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- uppnås
- adresse
- Annons
- Efter
- Stöd
- algoritmer
- Alla
- tillåta
- mängd
- analys
- analytics
- och
- Apache
- API: er
- tillämpas
- arkitektur
- associerad
- Författaren
- AWS
- dragen tillbaka
- baserat
- blir
- mellan
- Stor
- Stora data
- Box
- Brittiska
- företag
- företag
- kapacitet
- fall
- utmaningar
- kontroll
- cloud
- kluster
- kombination
- Företag
- företag
- komplex
- Efterlevnad
- dator
- databehandling
- konstant
- konstruera
- fortsätta
- Konvertering
- konvertera
- skapar
- beställnings
- kund
- Kundförlovning
- datum
- datainfrastruktur
- datahantering
- databaser
- datauppsättningar
- beroende
- utplacerade
- utplacering
- distributioner
- destination
- detaljer
- bestämd
- utvecklade
- olika
- distribueras
- fördelning
- Dynamiken
- lätt
- ansträngning
- ingrepp
- Företag
- Eter (ETH)
- utvecklas
- utförande
- dyra
- extrahera
- extraktion
- extrem
- Funktioner
- Kompis
- Fält
- Fil
- slutlig
- flexibel
- format
- hittade
- fundament
- Ramverk
- från
- Bränsle
- full
- generering
- Tillväxt
- Hadoop
- hantera
- hjälpa
- Hög
- höggradigt
- värd
- värd
- Hur ser din drömresa ut
- How To
- HTTPS
- in
- innefattar
- oberoende
- Infrastruktur
- infrastruktur
- inledande
- insikter
- integrering
- Introducerar
- Investeringar
- IT
- Jobb
- KDnuggets
- Ha kvar
- Nyckel
- Large
- Efternamn
- senaste
- ledande
- läsa in
- Låg
- Maskiner
- ledning
- chef
- Marknadsföring
- mekanism
- metall
- migrera
- Mode
- modeller
- Modern Konst
- lägen
- mer
- mest
- multipel
- Måste-ha
- MySQL
- nativ
- behövs
- behov
- Senaste
- noder
- erbjuda
- ONE
- öppen källkod
- Verksamhet
- organisation
- skisse
- reservdelar till din klassiker
- personlig
- plockade
- rörledning
- plato
- Platon Data Intelligence
- PlatonData
- Strategier
- Populära
- kraft
- den mäktigaste
- Predictive Analytics
- föredra
- VD
- tidigare
- pris
- Problem
- process
- Produkt
- Produktion
- ger
- allmän
- Offentligt moln
- publicera
- kvalitet
- snabbt
- som sträcker sig
- rekommendationer
- post
- register
- minska
- relativt
- replikation
- Krav
- att
- REST
- Fortsätt
- retentionstid
- robusta
- Körning
- Salesforce
- Samma
- Skala
- skalning
- skript
- §
- semantik
- senior
- känsla
- in
- signifikant
- Enkelt
- enda
- situationer
- So
- Samhället
- Mjukvara
- LÖSA
- Löser
- Källa
- Källor
- specialiserad
- specifik
- Etapp
- fristående
- start
- Ange
- Steg
- förvaring
- lagra
- lagras
- Strategisk
- ström
- streaming
- framgångsrik
- svit
- stödja
- Stöder
- system
- riktade
- uppgifter
- Teknologi
- Smakämnen
- deras
- därför
- Genom
- tid
- tidsstämpel
- till
- i dag
- verktyg
- traditionell
- Förvandla
- transformerad
- typer
- underliggande
- enastående
- användning
- användare
- olika
- mångsidig
- via
- Vice President
- volym
- volymer
- som
- medan
- kommer
- utan
- Arbete
- världen
- skriva
- skrivning
- skriven
- zephyrnet