Slika avtorja
Podatkovna znanost je interdisciplinarno področje, ki se v veliki meri opira na pridobivanje vpogledov in sprejemanje premišljenih odločitev iz ogromnih količin podatkov. Eno temeljnih orodij v orodju podatkovnega znanstvenika je SQL (Structured Query Language), programski jezik, zasnovan za upravljanje in manipulacijo relacijskih baz podatkov.
V tem članku se bom osredotočil na eno najmočnejših funkcij SQL: združevanja.
SQL Joins vam omogočajo združevanje podatkov iz več tabel baze podatkov na podlagi skupnih stolpcev. Tako lahko združite informacije in ustvarite smiselne povezave med povezanimi nabori podatkov.
Obstaja več vrste združevanj SQL:
- Notranji pridružite
- Levi zunanji spoj
- Desni zunanji spoj
- Popoln zunanji spoj
- Križni spoj
Razložimo vsako vrsto.
Notranje združevanje vrne samo vrstice, kjer je ujemanje v obeh tabelah, ki se združujeta. Združuje vrstice iz dveh tabel na podlagi skupnega ključa ali stolpca, pri čemer zavrže vrstice, ki se ne ujemajo.
To si predstavljamo na naslednji način.
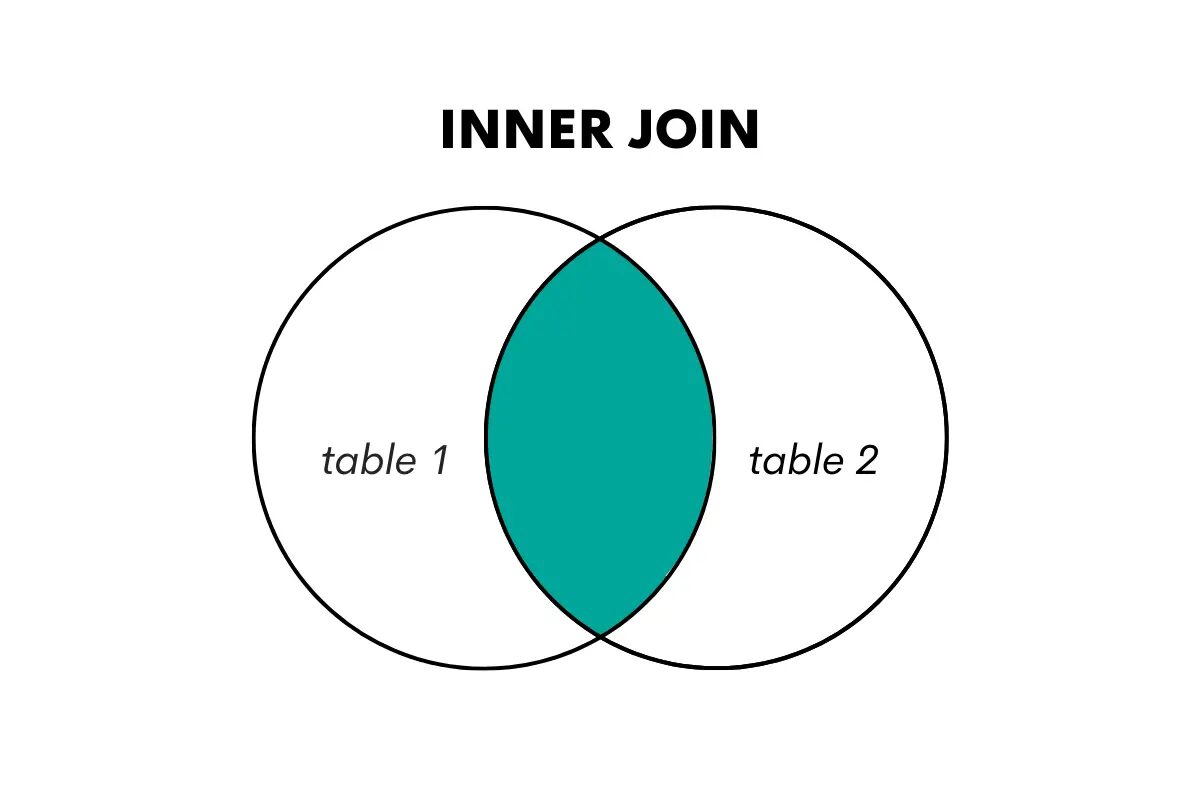
Slika avtorja
V SQL se ta vrsta združevanja izvede z uporabo ključnih besed JOIN ali INNER JOIN.
Levo zunanje združevanje vrne vse vrstice iz leve (ali prve) tabele in ujemajoče se vrstice iz desne (ali druge) tabele. Če ujemanja ni, vrne vrednosti NULL za stolpce iz desne tabele.
To si lahko predstavljamo takole.
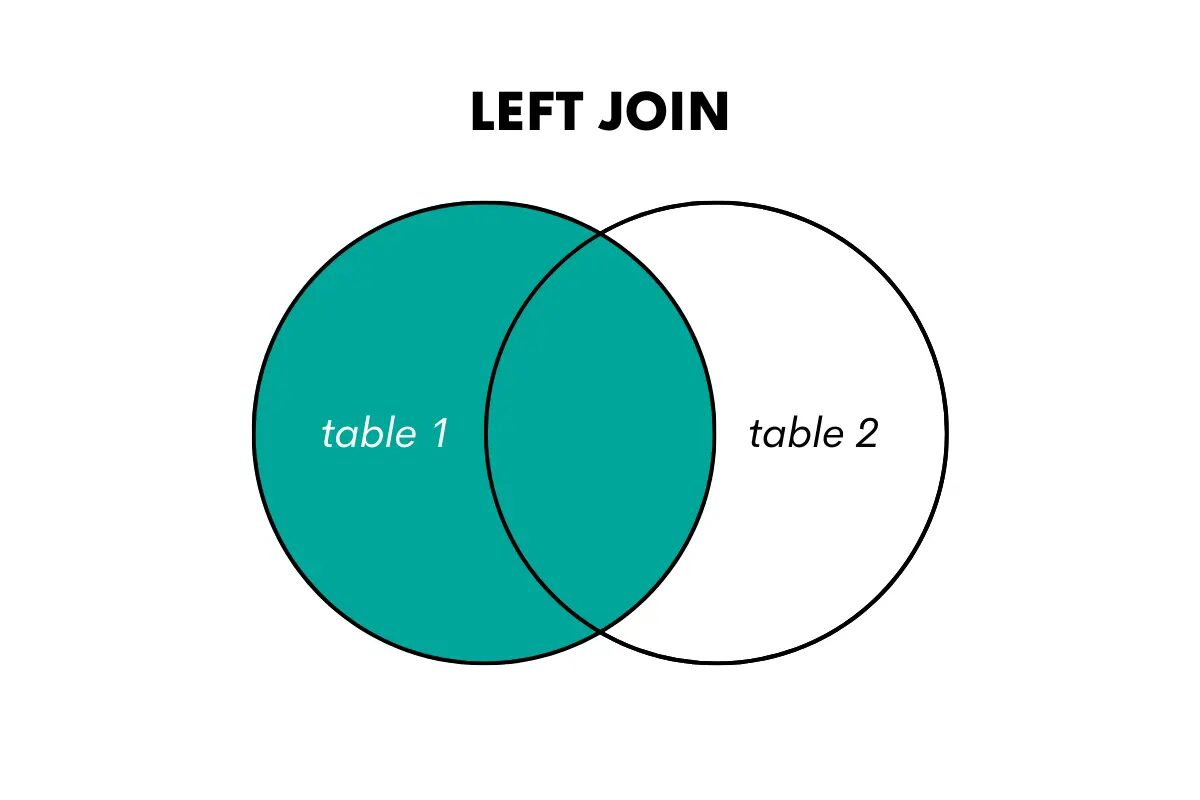
Slika avtorja
Če želite to združevanje uporabiti v SQL, lahko to storite z uporabo ključnih besed LEFT OUTER JOIN ali LEFT JOIN. Tukaj je članek, ki govori o levo združevanje proti levemu zunanjemu združevanju.
Desni spoj je nasprotje levega spoja. Vrne vse vrstice iz desne tabele in ujemajoče se vrstice iz leve tabele. Če ni ujemanja, vrne vrednosti NULL za stolpce iz leve tabele.
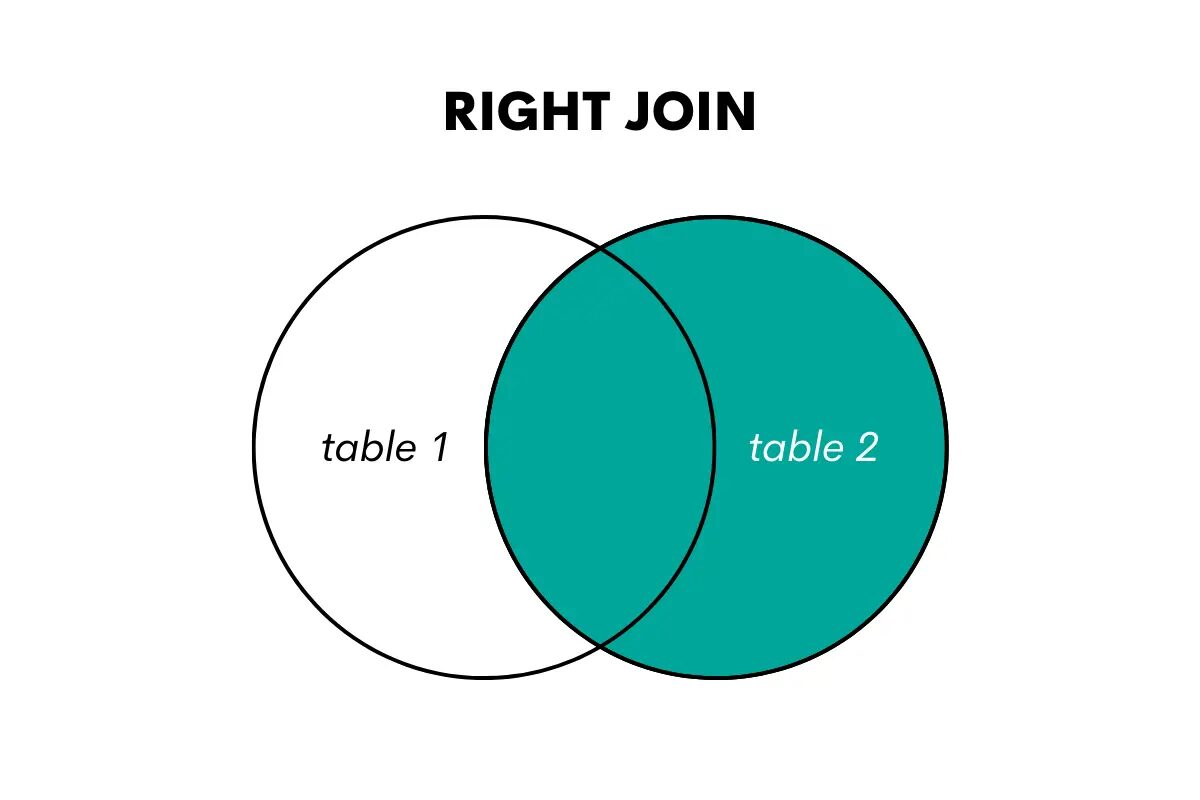
Slika avtorja
V SQL se ta vrsta združevanja izvede z uporabo ključnih besed RIGHT OUTER JOIN ali RIGHT JOIN.
Polno zunanje združevanje vrne vse vrstice iz obeh tabel, ujemajoče se vrstice, kjer je to mogoče, in izpolnjevanje vrednosti NULL za neujemajoče se vrstice.
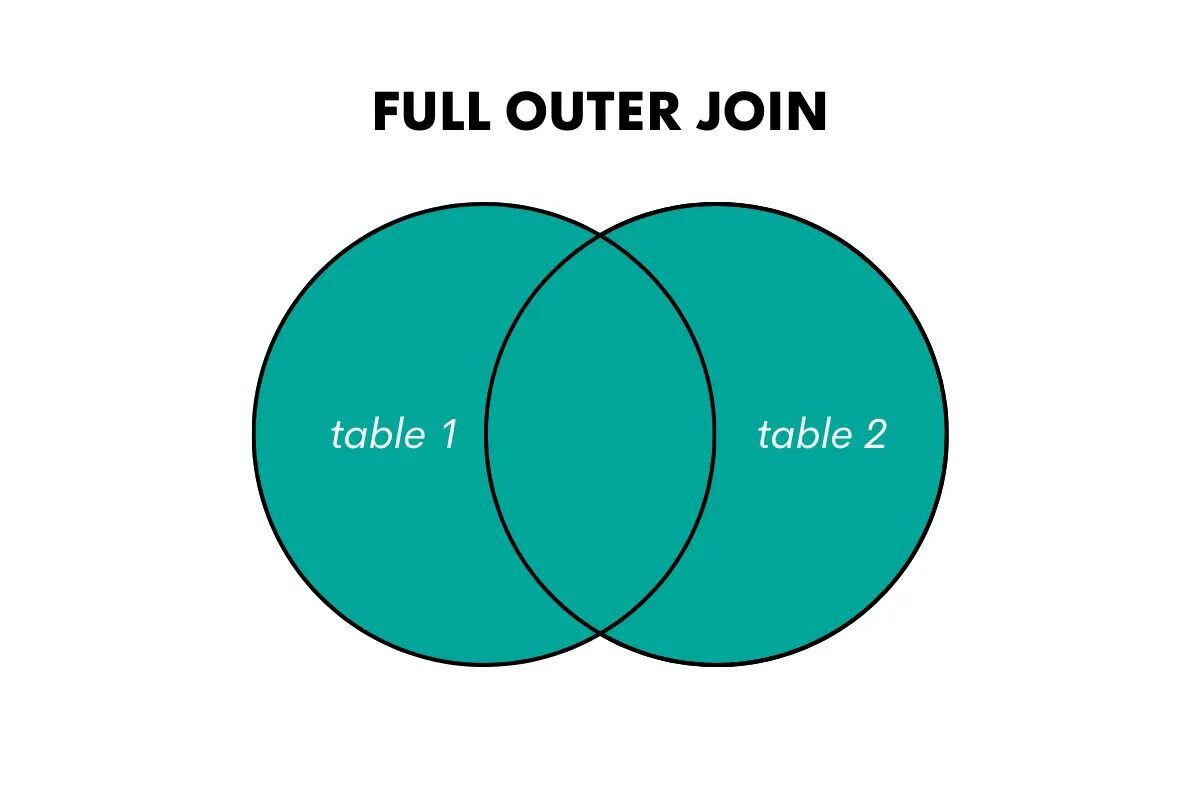
Slika avtorja
Ključne besede v SQL za to združevanje so FULL OUTER JOIN ali FULL JOIN.
Ta vrsta združevanja združuje vse vrstice iz ene tabele z vsemi vrsticami iz druge tabele. Z drugimi besedami, vrne kartezični produkt, tj. vse možne kombinacije vrstic obeh tabel.
Tukaj je vizualizacija, ki bo olajšala razumevanje.
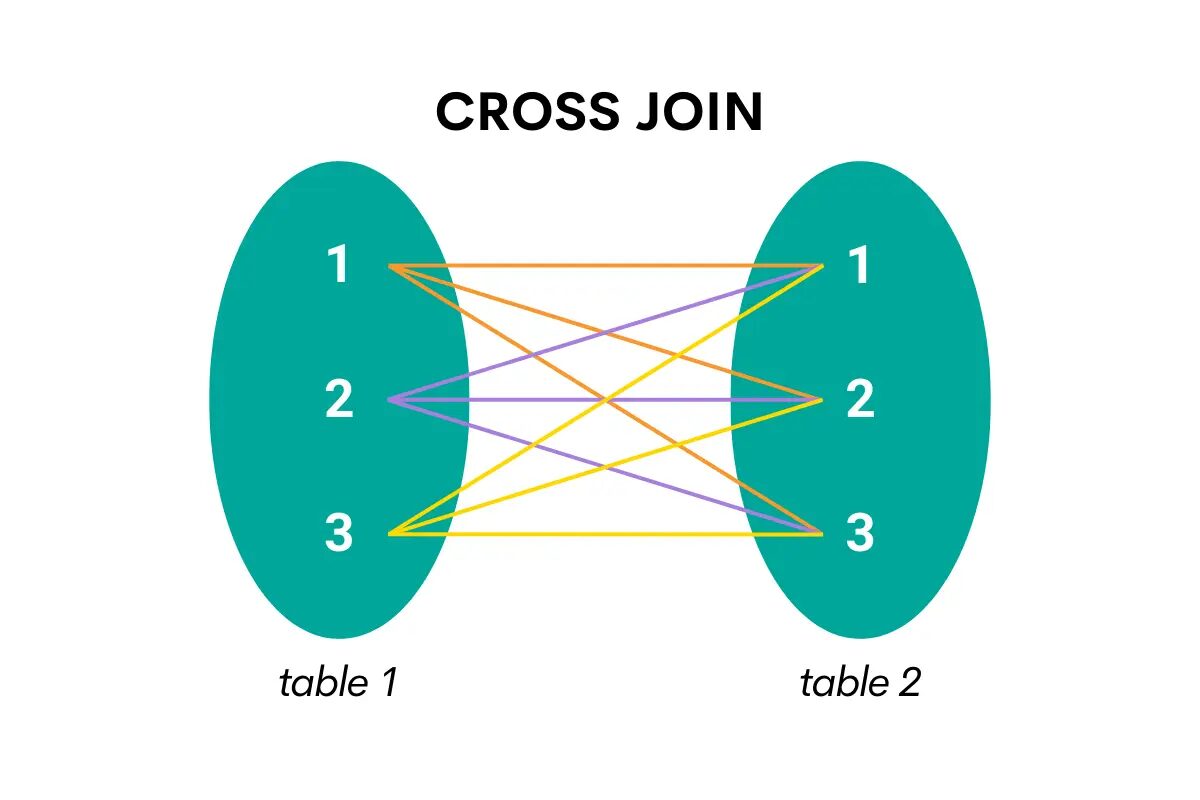
Slika avtorja
Pri navzkrižnem združevanju v SQL je ključna beseda CROSS JOIN.
Če želite izvesti združevanje v SQL, morate podati tabele, ki jih želimo združiti, stolpce, ki se uporabljajo za ujemanje, in vrsto združevanja, ki ga želimo izvesti. Osnovna sintaksa za združevanje tabel v SQL je naslednja:
SELECT columns
FROM table1
JOIN table2
ON table1.column = table2.column;
Ta primer prikazuje, kako uporabljati JOIN.
Sklicujete se na prvo (ali levo) tabelo v členu FROM. Nato mu sledite z JOIN in se sklicujete na drugo (ali desno) tabelo.
Nato sledi pogoj združevanja v klavzuli ON. Tukaj določite, katere stolpce boste uporabili za združevanje dveh tabel. Običajno je to stolpec v skupni rabi, ki je primarni ključ v eni tabeli in tuji ključ v drugi tabeli.
Opomba: primarni ključ je edinstven identifikator za vsak zapis v tabeli. Tuji ključ vzpostavi povezavo med dvema tabelama, tj. stolpec v drugi tabeli se sklicuje na prvo tabelo. Na primerih vam bomo pokazali, kaj to pomeni.
Če želite uporabiti LEFT JOIN, RIGHT JOIN ali FULL JOIN, uporabite le te ključne besede namesto JOIN – vse ostalo v kodi je popolnoma enako!
Pri CROSS JOIN so stvari nekoliko drugačne. V svoji naravi je združiti vse kombinacije vrstic iz obeh tabel. Zato klavzula ON ni potrebna, sintaksa pa izgleda takole.
SELECT columns
FROM table1
CROSS JOIN table2;
Z drugimi besedami, preprosto se sklicujete na eno tabelo v FROM in na drugo v CROSS JOIN.
Lahko pa se sklicujete na obe tabeli v FROM in ju ločite z vejico – to je okrajšava za CROSS JOIN.
SELECT columns
FROM table1, table2;Obstaja tudi en poseben način združevanja tabel – združevanje tabele same s seboj. To se imenuje tudi samopridruževanje tabeli.
To ni ravno posebna vrsta združevanja, saj je mogoče katero koli od prej omenjenih vrst združevanja uporabiti tudi za samozdruževanje.
Sintaksa za samozdruževanje je podobna tisti, ki sem vam jo pokazal prej. Glavna razlika je v tem, da se v FROM in JOIN sklicuje ista tabela.
SELECT columns
FROM table1 t1
JOIN table1 t2
ON t1.column = t2.column;
Poleg tega morate tabeli dati dva vzdevka, da ju ločite. To, kar počnete, je, da tabelo združite s samo seboj in jo obravnavate kot dve tabeli.
Tukaj sem samo želel omeniti to, vendar se ne bom spuščal v nadaljnje podrobnosti. Če vas zanima samopridruževanje, si oglejte ta ilustrirani vodnik na samopridruževanje v SQL.
Čas je, da vam pokažem, kako vse, kar sem omenil, deluje v praksi. bom uporabil Vprašanja za intervju SQL JOIN iz StrataScratch za predstavitev vsake posebne vrste združevanja v SQL.
1. Primer JOIN
To vprašanje Microsofta želi, da navedete vsak projekt in izračunate proračun projekta po zaposlenem.
Dragi projekti
»Glede na seznam projektov in zaposlenih, preslikanih na vsak projekt, izračunajte znesek proračuna projekta, dodeljenega vsakemu zaposlenemu. Izhod mora vsebovati naslov projekta in proračun projekta, zaokrožen na najbližje celo število. Najprej razvrstite seznam po projektih z najvišjim proračunom na zaposlenega.«
datum
Vprašanje podaja dve tabeli.
ms_projects
| id: | int |
| Naslov: | varchar |
| proračun: | int |
ms_emp_projects
| emp_id: | int |
| project_id: | int |
Zdaj pa ID stolpca v tabeli ms_projects je primarni ključ tabele. Isti stolpec najdete v tabeli ms_emp_projects, čeprav z drugačnim imenom: project_id. To je tuji ključ tabele, ki se sklicuje na prvo tabelo.
Ta dva stolpca bom uporabil za združevanje tabel v svoji rešitvi.
Koda
SELECT title AS project, ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;
Dve tabeli sem združil z JOIN. Miza ms_projects se sklicuje na FROM, medtem ko ms_emp_projects se sklicuje po JOIN. Obema tabelama sem dal vzdevek, kar mi omogoča, da pozneje ne bom uporabljal dolgih imen tabel.
Zdaj moram določiti stolpce, v katerih želim združiti tabele. Omenil sem že, kateri stolpci so primarni ključ v eni tabeli in tuji ključ v drugi tabeli, zato jih bom uporabil tukaj.
Ta dva stolpca izenačujem, ker želim dobiti vse podatke, pri katerih je ID projekta enak. Uporabil sem tudi vzdevke tabel pred vsakim stolpcem.
Zdaj, ko imam dostop do podatkov v obeh tabelah, lahko navedem stolpce v SELECT. Prvi stolpec je ime projekta, drugi stolpec pa je izračunan.
Ta izračun uporablja funkcijo COUNT() za štetje števila zaposlenih po vsakem projektu. Nato proračun vsakega projekta razdelim na število zaposlenih. Rezultat pretvorim tudi v decimalne vrednosti in zaokrožim na nič decimalnih mest.
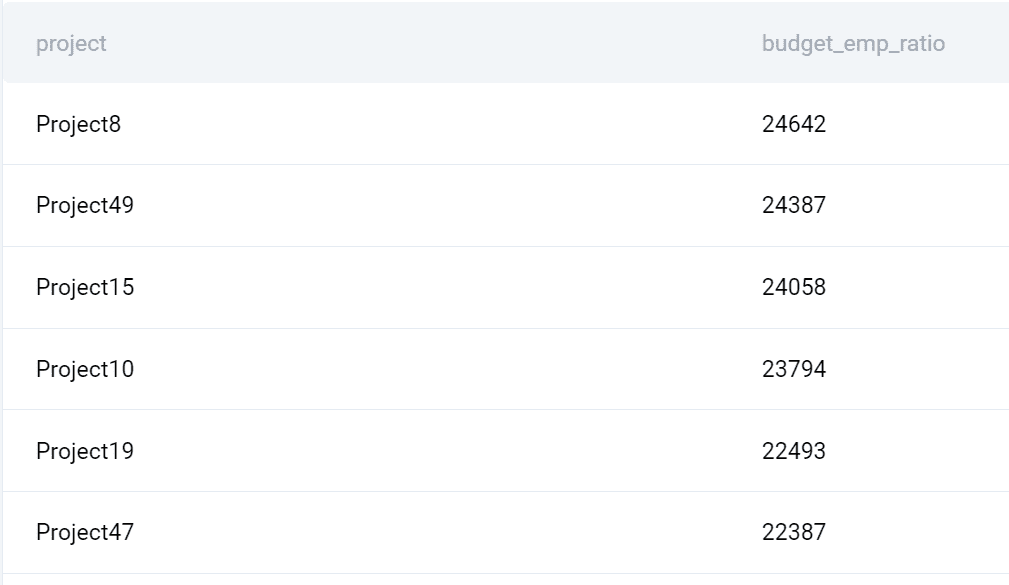
izhod
Tukaj je tisto, kar vrne poizvedba.
2. Primer LEFT JOIN
Vadimo to združevanje na Vprašanje za intervju za Airbnb. Želi, da najdete število naročil, število strank in skupne stroške naročil za vsako mesto.
Naročila strank in podrobnosti
»Poiščite število naročil, število strank in skupne stroške naročil za vsako mesto. Vključite samo mesta, ki so oddala vsaj 5 naročil, in preštejte vse stranke v vsakem mestu, tudi če niso oddali naročila.
Izpišite vsak izračun skupaj z ustreznim imenom mesta.«
datum
Dobili ste mize stranke, in naročila.
stranke
| id: | int |
| ime: | varchar |
| priimek: | varchar |
| mesto: | varchar |
| naslov: | varchar |
| telefonska številka: | varchar |
naročila
| id: | int |
| cust_id: | int |
| datum naročila: | Datum čas |
| podrobnosti naročila: | varchar |
| skupni_strošek_naročila: | int |
Stolpci v skupni rabi so ID-ji iz tabele stranke in cust_id iz tabele naročila. Te stolpce bom uporabil za združevanje tabel.
Koda
Tukaj je opisano, kako rešiti to vprašanje z uporabo LEFT JOIN.
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
Sklicujem se na tabelo stranke v FROM (to je naša leva tabela) in LEFT JOIN z naročila v stolpcih ID stranke.
Zdaj lahko izberem mesto, uporabim COUNT(), da dobim število naročil in strank glede na mesto, in uporabim SUM(), da izračunam skupne stroške naročil glede na mesto.
Da bi dobili vse te izračune po mestih, združim rezultate po mestih.
V vprašanju je ena dodatna zahteva: »Vključi samo mesta, ki so naredila vsaj 5 naročil ...« Za dosego tega uporabljam HAVING, da prikažem samo mesta s petimi ali več naročili.
Vprašanje je, zakaj sem uporabil LEVO JOIN in ne PRIDRUŽITE? Namig je v vprašanju: »…in preštejte vse stranke v vsakem mestu, tudi če niso oddale naročila.« Možno je, da niso vse stranke oddale naročila. To pomeni, da želim prikazati vse stranke iz tabele stranke, ki popolnoma ustreza definiciji LEFT JOIN.
Če bi uporabil JOIN, bi bil rezultat napačen, saj bi zamudil kupce, ki niso oddali nobenega naročila.
Opomba: Kompleksnost združevanj v SQL se ne odraža v njihovi sintaksi, temveč v semantiki! Kot ste videli, je vsako združevanje napisano na enak način, le ključna beseda se spremeni. Vendar pa vsako združevanje deluje drugače in zato lahko izpiše različne rezultate, odvisno od podatkov. Zaradi tega je ključnega pomena, da popolnoma razumete, kaj počne posamezno združevanje, in izberete tisto, ki bo vrnilo točno to, kar želite!
izhod
Zdaj pa si poglejmo izhod.

3. Primer RIGHT JOIN
RIGHT JOIN je zrcalna slika LEFT JOIN-a. Zato bi prejšnjo težavo zlahka rešil z uporabo RIGHT JOIN. Naj vam pokažem, kako to storiti.
datum
Tabele ostanejo enake; Uporabil bom samo drugo vrsto pridružitve.
Koda
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id GROUP BY c.city
HAVING COUNT(o.id) >=5;
Evo, kaj se je spremenilo. Ker uporabljam RIGHT JOIN, sem zamenjal vrstni red tabel. Zdaj pa miza naročila postane leva in miza stranke tisti pravi. Pogoj pridružitve ostaja enak. Pravkar sem zamenjal vrstni red stolpcev, da odraža vrstni red tabel, vendar to ni potrebno.
S preklopom vrstnega reda tabel in uporabo RIGHT JOIN bom ponovno izpisal vse stranke, tudi če niso oddali nobenega naročila.
Preostali del poizvedbe je enak kot v prejšnjem primeru. Enako velja za izhod.
Opomba: V praksi je PRAV PRIDRUŽI SE se relativno redko uporablja. LEFT JOIN se uporabnikom SQL zdi bolj naraven, zato ga uporabljajo veliko pogosteje. Vse, kar lahko storite z RIGHT JOIN, lahko storite tudi z LEFT JOIN. Zaradi tega ni nobene posebne situacije, kjer bi bila prednostna RIGHT JOIN.
izhod
4. Primer FULL JOIN
Vprašanje Salesforce in Tesla želi, da preštejete neto razliko med številom izdelkov, ki so bila lansirana leta 2020, in številom izdelkov, ki so bila lansirana v prejšnjem letu.
Novi izdelki
»Dobljena vam je tabela lansiranj izdelkov po podjetjih po letih. Napišite poizvedbo za štetje neto razlike med številom izdelkov, ki so bila ustanovljena leta 2020, in številom izdelkov, ki so bila lansirana v prejšnjem letu. Izpišite imena podjetij in neto razliko neto produktov, izdanih za leto 2020, v primerjavi s prejšnjim letom.”
datum
Vprašanje vsebuje eno tabelo z naslednjimi stolpci.
car_launches
| leto: | int |
| ime podjetja: | varchar |
| ime izdelka: | varchar |
Kako za vraga naj združim mize, ko je samo ena miza? Hmm, poglejmo še to!
Koda
Ta poizvedba je malo bolj zapletena, zato jo bom razkrival postopoma.
SELECT company_name, product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;
Prvi stavek SELECT najde podjetje in ime izdelka v letu 2020. Ta poizvedba bo pozneje spremenjena v podpoizvedbo.
Vprašanje želi, da poiščete razliko med letoma 2020 in 2019. Napišimo torej isto poizvedbo, vendar za leto 2019.
SELECT company_name, product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019;
Zdaj bom te poizvedbe spremenil v podpoizvedbe in jih združil z uporabo FULL OUTER JOIN.
SELECT *
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name;
Podpoizvedbe je mogoče obravnavati kot tabele in jih je zato mogoče združiti. Prvi podpoizvedbi sem dal vzdevek in jo postavil v klavzulo FROM. Nato uporabim FULL OUTER JOIN, da ga združim z drugo podpoizvedbo v stolpcu z imenom podjetja.
Z uporabo te vrste pridružitve SQL bom vsa podjetja in izdelke leta 2020 združil z vsemi podjetji in izdelki leta 2019.
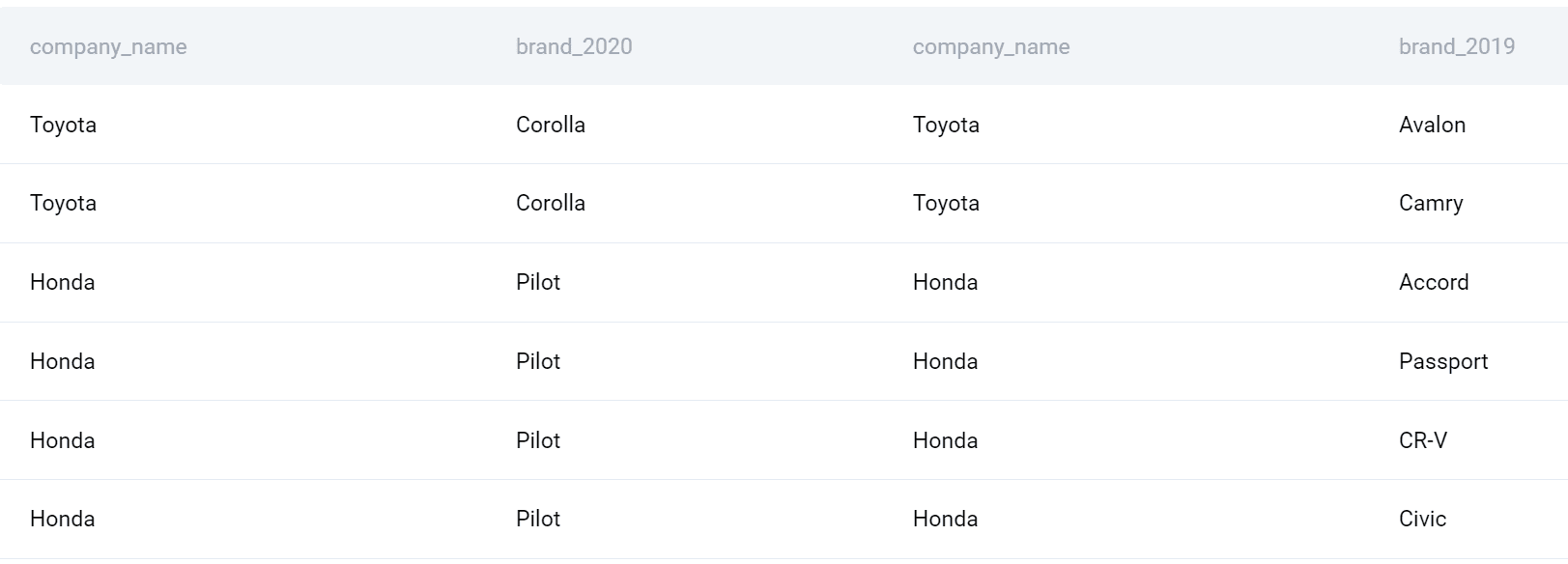
Zdaj lahko dokončam svojo poizvedbo. Izberimo ime podjetja. Prav tako bom uporabil funkcijo COUNT(), da poiščem število izdelkov, lansiranih v posameznem letu, in ga nato odštejem, da dobim razliko. Nazadnje bom rezultate združil po podjetjih in jih razvrstil tudi po podjetjih po abecedi.
Tukaj je celotna poizvedba.
SELECT a.company_name, (COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_products
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name
GROUP BY a.company_name
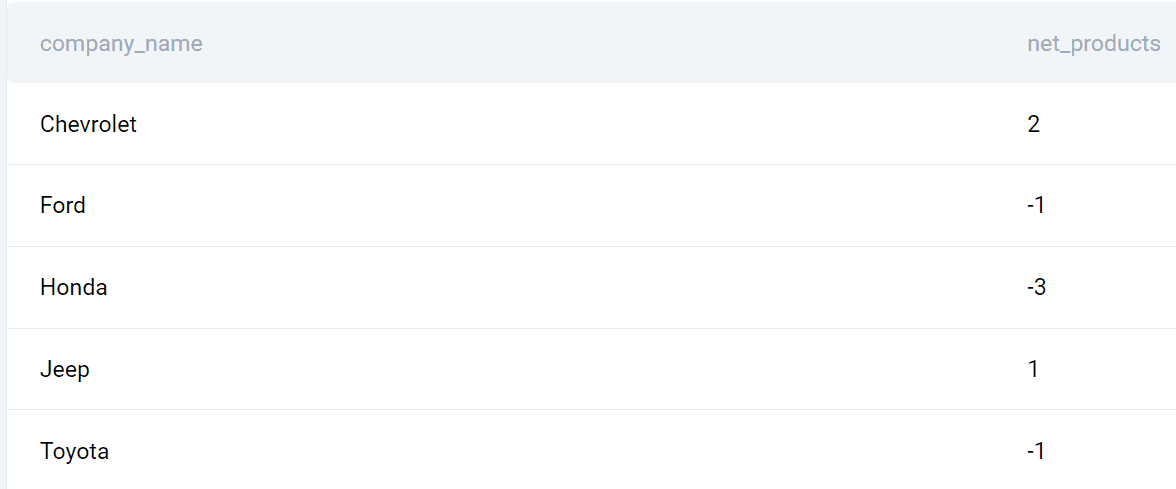
ORDER BY company_name;izhod
Tukaj je seznam podjetij in razlika med lansiranimi izdelki med letoma 2020 in 2019.
5. Primer KRIŽNEGA SPAJANJA
To vprašanje Deloitta je odličen za prikaz delovanja CROSS JOIN.
Največ dve številki
»Glede na en stolpec števil upoštevajte vse možne permutacije dveh števil ob predpostavki, da sta para števil (x,y) in (y,x) dve različni permutaciji. Nato za vsako permutacijo poiščite največje število obeh števil.
Izpiši tri stolpce: prvo število, drugo število in največje število obeh."
Vprašanje želi, da poiščete vse možne permutacije dveh števil ob predpostavki, da sta para števil (x,y) in (y,x) dve različni permutaciji. Nato moramo najti največje število za vsako permutacijo.
datum
Vprašanje nam daje eno tabelo z enim stolpcem.
deloitte_numbers
| številka: | int |
Koda
Ta koda je primer navzkrižnega združevanja, pa tudi samozdruževanja.
SELECT dn1.number AS number1, dn2.number AS number2, CASE WHEN dn1.number > dn2.number THEN dn1.number ELSE dn2.number END AS max_number
FROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
Na tabelo se sklicujem v FROM in ji dam en vzdevek. Nato jo navzkrižno združim s samim seboj, tako da jo navedem za CROSS JOIN in tabeli dam drug vzdevek.
Zdaj je mogoče uporabiti eno mizo, saj sta dve. Iz vsake tabele izberem številko stolpca. Nato uporabim stavek CASE, da nastavim pogoj, ki bo pokazal največje število obeh števil.
Zakaj se tukaj uporablja CROSS JOIN? Ne pozabite, da gre za vrsto združevanja SQL, ki bo prikazalo vse kombinacije vseh vrstic iz vseh tabel. Točno to je vprašanje!
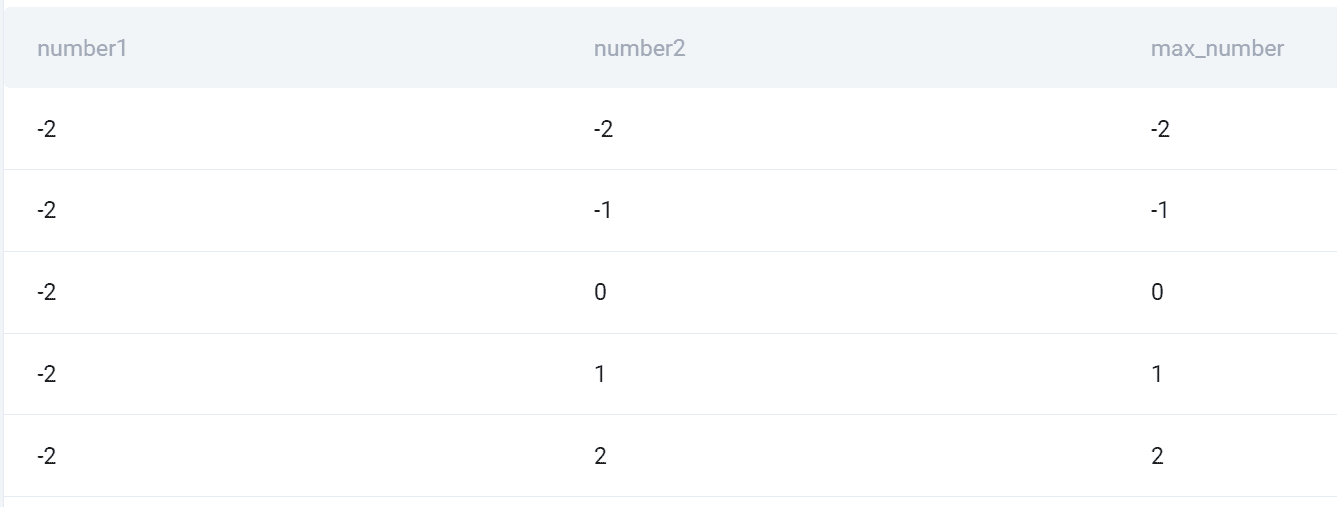
izhod
Tukaj je posnetek vseh kombinacij in večje število obeh.
Zdaj, ko veste, kako uporabljati združevanja SQL, je vprašanje, kako to znanje uporabiti v podatkovni znanosti.
SQL Joins igrajo ključno vlogo pri nalogah podatkovne znanosti, kot so raziskovanje podatkov, čiščenje podatkov in inženiring funkcij.
Tukaj je nekaj primerov, kako je mogoče izkoristiti združevanja SQL:
- Združevanje podatkov: Združevanje tabel vam omogoča, da združite različne vire podatkov, kar vam omogoča analizo odnosov in korelacije v več nizih podatkov. Na primer, združevanje tabele strank s tabelo transakcij lahko zagotovi vpogled v vedenje strank in nakupovalne vzorce.
- Potrditev podatkov: Spoji se lahko uporabljajo za preverjanje kakovosti in celovitosti podatkov. S primerjavo podatkov iz različnih tabel lahko ugotovite nedoslednosti, manjkajoče vrednosti ali izstopajoče vrednosti. To vam pomaga pri čiščenju podatkov in zagotavlja, da so podatki, uporabljeni za analizo, točni in zanesljivi.
- Inženiring funkcij: Spoji so lahko ključni pri ustvarjanju novih funkcij za modele strojnega učenja. Z združevanjem ustreznih tabel lahko izvlečete pomembne informacije in ustvarite funkcije, ki zajamejo pomembna razmerja znotraj podatkov. To lahko poveča napovedno moč vaših modelov.
- Združevanje in analiza: Združevanja vam omogočajo izvajanje kompleksnih združevanj in analiz v več tabelah. S kombiniranjem podatkov iz različnih virov lahko pridobite celovit vpogled v podatke in pridobite dragocene vpoglede. Če na primer združite prodajno tabelo s tabelo izdelkov, vam lahko pomaga analizirati uspešnost prodaje po kategoriji izdelkov ali regiji.
Kot sem že omenil, se kompleksnost združevanj ne pokaže v njihovi sintaksi. Videli ste, da je sintaksa razmeroma enostavna.
To odražajo tudi najboljše prakse za združevanja, saj se ne ukvarjajo s samim kodiranjem, ampak s tem, kaj združevanje počne in kako deluje.
Če želite kar najbolje izkoristiti združevanja v SQL, upoštevajte naslednje najboljše prakse.
- Razumevanje vaših podatkov: Seznanite se s strukturo in odnosi v svojih podatkih. To vam bo pomagalo izbrati ustrezno vrsto združevanja in izbrati prave stolpce za ujemanje.
- Uporabite indekse: Če so vaše tabele velike ali se pogosto združujejo, razmislite o dodajanju indeksov v stolpce, ki se uporabljajo za združevanje. Indeksi lahko znatno izboljšajo zmogljivost poizvedb.
- Bodite pozorni na uspešnost: Združevanje velikih tabel ali več tabel je lahko računsko drago. Optimizirajte svoje poizvedbe s filtriranjem podatkov, uporabo ustreznih vrst združevanja in upoštevanjem uporabe začasnih tabel ali podpoizvedb.
- Preizkusite in potrdite: Vedno potrdite svoje rezultate pridružitve, da zagotovite pravilnost. Izvedite preverjanje razumnosti in preverite, ali so združeni podatki v skladu z vašimi pričakovanji in poslovno logiko.
SQL Joins so temeljni koncept, ki vam kot podatkovnemu znanstveniku omogoča združevanje in analizo podatkov iz več virov. Z razumevanjem različnih vrst združevanj SQL, obvladovanjem njihove sintakse in njihovo učinkovito uporabo lahko podatkovni znanstveniki odklenejo dragocene vpoglede, potrdijo kakovost podatkov in spodbudijo sprejemanje odločitev na podlagi podatkov.
V petih primerih sem vam pokazal, kako to storiti. Zdaj je na vas, da izkoristite moč SQL in pridružitev za svoje projekte podatkovne znanosti in dosežete boljše rezultate.
Nate Rosidi je podatkovni znanstvenik in v strategiji izdelkov. Je tudi izredni profesor, ki poučuje analitiko in je ustanovitelj StrataScratch, platforma, ki pomaga podatkovnim znanstvenikom pri pripravi na intervjuje z resničnimi vprašanji za intervjuje vrhunskih podjetij. Povežite se z njim Twitter: StrataScratch or LinkedIn.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Avtomobili/EV, Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- BlockOffsets. Posodobitev okoljskega offset lastništva. Dostopite tukaj.
- vir: https://www.kdnuggets.com/2023/08/sql-data-science-understanding-leveraging-joins.html?utm_source=rss&utm_medium=rss&utm_campaign=sql-for-data-science-understanding-and-leveraging-joins
- : je
- :ne
- :kje
- $GOR
- 1
- 11
- 12
- 13
- 2019
- 2020
- 7
- 8
- a
- O meni
- dostop
- Dostop do podatkov
- natančna
- Doseči
- čez
- dodajanje
- dodatek
- po
- spet
- združevanje
- Poravnava
- vsi
- dodeljenih
- omogočajo
- Dovoli
- omogoča
- skupaj
- že
- Prav tako
- vedno
- znesek
- zneski
- an
- Analiza
- analitika
- analizirati
- in
- Še ena
- kaj
- karkoli
- primerno
- SE
- članek
- AS
- At
- b
- temeljijo
- Osnovni
- BE
- ker
- postane
- bilo
- počutje
- BEST
- najboljše prakse
- Boljše
- med
- tako
- prinašajo
- proračun
- poslovni
- vendar
- by
- izračun
- izračuna
- se imenuje
- CAN
- zajemanje
- primeru
- Kategorija
- spremenilo
- Spremembe
- Pregledi
- Izberite
- Mesta
- mesto
- čiščenje
- Koda
- Kodiranje
- Stolpec
- Stolpci
- COM
- kombinacije
- združujejo
- združuje
- združevanje
- prihaja
- Skupno
- Podjetja
- podjetje
- v primerjavi z letom
- primerjavo
- kompleksna
- kompleksnost
- zapleten
- celovito
- Koncept
- zaskrbljen
- stanje
- Connect
- povezave
- Razmislite
- upoštevamo
- pretvorbo
- Ustrezno
- strošek
- ustvarjajo
- Ustvarjanje
- Cross
- ključnega pomena
- stranka
- vedenje kupcev
- Stranke, ki so
- datum
- kakovosti podatkov
- znanost o podatkih
- podatkovni znanstvenik
- Podatkov usmerjenih
- Baze podatkov
- baze podatkov
- nabor podatkov
- Odločanje
- odločitve
- opredelitev
- Odvisno
- zasnovan
- Podatki
- DID
- Razlika
- drugačen
- izrazit
- razlikovati
- do
- ne
- Ne
- tem
- opravljeno
- pogon
- e
- vsak
- prej
- lažje
- enostavno
- učinkovito
- ostalo
- Zaposlen
- Zaposleni
- pooblašča
- omogočajo
- omogočanje
- konec
- Inženiring
- okrepi
- zagotovitev
- zagotavlja
- enako
- vzpostavlja
- Tudi
- vse
- točno
- Primer
- Primeri
- pričakovanja
- drago
- Pojasnite
- raziskovanje
- dodatna
- ekstrakt
- Feature
- Lastnosti
- Nekaj
- Polje
- polnjenje
- filtriranje
- dokončati
- končno
- Najdi
- najdbe
- prva
- pet
- Plavaj
- Osredotočite
- sledi
- po
- sledi
- za
- tuji
- je pokazala,
- Ustanovitelj
- pogosto
- iz
- spredaj
- polno
- v celoti
- funkcija
- temeljna
- nadalje
- Gain
- ustvarjajo
- dobili
- Daj
- dana
- daje
- Giving
- goes
- dogaja
- postopoma
- veliko
- skupina
- vodi
- plezalni pas
- Imajo
- ob
- he
- močno
- pomoč
- pomoč
- Pomaga
- tukaj
- več
- najvišja
- ga
- Kako
- Kako
- Vendar
- HTTPS
- i
- Bom
- ID
- identifikator
- identificirati
- if
- slika
- Pomembno
- izboljšanje
- in
- V drugi
- vključujejo
- indekse
- Podatki
- obvestila
- vpogledi
- Namesto
- instrumental
- celovitost
- zainteresirani
- Intervju
- vprašanja za intervju
- Intervjuji
- v
- IT
- ITS
- sam
- pridružite
- pridružil
- pridružil
- Pridružuje
- jpg
- samo
- KDnuggets
- Ključne
- ključne besede
- Vedite
- znanje
- jezik
- velika
- pozneje
- začela
- izstrelki
- učenje
- vsaj
- levo
- vzvod
- kot
- LINK
- Seznam
- malo
- Logika
- Long
- Poglej
- POGLEDI
- stroj
- strojno učenje
- je
- Glavne
- Znamka
- Izdelava
- upravljanje
- manipuliranje
- Mastering
- Stave
- ujema
- ujemanje
- največja
- me
- smiselna
- pomeni
- omenjeno
- Spoji
- združitev
- morda
- ogledalo
- Zrcalna slika
- zamudili
- manjka
- modeli
- več
- Najbolj
- veliko
- več
- my
- Ime
- Imena
- naravna
- Narava
- potrebno
- Nimate
- potrebna
- net
- Novo
- Nove funkcije
- št
- zdaj
- Številka
- številke
- of
- pogosto
- on
- ONE
- samo
- Nasprotno
- Optimizirajte
- or
- Da
- naročila
- Ostalo
- naši
- ven
- izhod
- parov
- vzorci
- za
- opravlja
- performance
- opravljeno
- opravlja
- Kraj
- Mesta
- platforma
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Predvajaj
- prosim
- mogoče
- moč
- močan
- praksa
- vaje
- prednostno
- Pripravimo
- prejšnja
- primarni
- problem
- Izdelek
- Izdelki
- Učitelj
- Programiranje
- Projekt
- projekti
- zagotavljajo
- zagotavlja
- nakup
- kakovost
- poizvedbe
- vprašanje
- vprašanja
- redko
- pravo
- zapis
- reference
- sklicevanje
- odražajo
- odsevalo
- okolica
- povezane
- Razmerja
- relativno
- sprosti
- pomembno
- zanesljiv
- ne pozabite
- zahteva
- REST
- povzroči
- Rezultati
- vrnitev
- vrne
- razkrivajo
- Pravica
- vloga
- krog
- s
- prodaja
- prodajni center
- Enako
- Videl
- Znanost
- Znanstvenik
- Znanstveniki
- drugi
- glej
- Zdi se,
- SAMO
- ločena
- nastavite
- več
- deli
- stenografija
- shouldnt
- Prikaži
- predstavitev
- je pokazala,
- Prikaz
- Razstave
- bistveno
- Podoben
- preprosto
- sam
- Razmere
- Posnetek
- So
- Rešitev
- SOLVE
- Viri
- specifična
- SQL
- Izjava
- bivanje
- naravnost
- Strategija
- Struktura
- strukturirano
- taka
- preklopi
- sintaksa
- T1
- miza
- pogovori
- Naloge
- poučevanje
- začasna
- Test
- da
- O
- njihove
- Njih
- POTEM
- Tukaj.
- zato
- te
- jih
- ta
- 3
- čas
- Naslov
- do
- skupaj
- Toolbox
- orodja
- vrh
- Skupaj za plačilo
- transakcija
- zdravljeni
- zdravljenje
- Obrnjen
- dva
- tip
- Vrste
- razumeli
- razumevanje
- edinstven
- odklepanje
- us
- uporaba
- Rabljeni
- Uporabniki
- uporablja
- uporabo
- navadno
- uporabiti
- POTRDI
- potrjevanje
- dragocene
- Vrednote
- različnih
- Popravljeno
- preverjanje
- Poglej
- vizualizacija
- vs
- želeli
- hotel
- želim
- želi
- način..
- we
- Kaj
- kdaj
- ki
- medtem
- celoti
- zakaj
- bo
- z
- v
- besede
- deluje
- pisati
- pisni
- Napačen
- X
- leto
- jo
- Vaša rutina za
- sami
- zefirnet
- nič