V sodobnem svetu se večina podjetij zanaša na moč velikih podatkov in analitike, da spodbudijo svojo rast, strateške naložbe in sodelovanje strank. Veliki podatki so osnovna stalnica v ciljanem oglaševanju, prilagojenem trženju, priporočilih za izdelke, ustvarjanju vpogledov, optimizaciji cen, analizi razpoloženja, napovedni analitiki in še veliko več.
Podatki se pogosto zbirajo iz več virov, preoblikujejo, shranjujejo in obdelujejo v podatkovnih jezerih on-prem ali on-cloud. Medtem ko je začetni vnos podatkov razmeroma nepomemben in ga je mogoče doseči s skripti po meri, razvitimi v podjetju, ali tradicionalnimi orodji ETL (Extract Transform Load), težava hitro postane prehibo zapletena in draga za rešitev, saj morajo podjetja:
- Upravljajte celoten življenjski cikel podatkov – za namene vzdrževanja in skladnosti
- Optimizirajte shranjevanje – za zmanjšanje povezanih stroškov
- Poenostavite arhitekturo – s ponovno uporabo računalniške infrastrukture
- Postopno obdelujte podatke – z močnim upravljanjem stanja
- Uporabite iste pravilnike za paketne in pretočne podatke – brez podvajanja napora
- Prehod med On-prem in Cloud – z najmanj truda
Je kje Apaški Gobblin, odprtokodni sistem za upravljanje podatkov in integracijo. Apache Gobblin zagotavlja neprimerljive zmogljivosti, ki jih je mogoče uporabiti v celoti ali delno, odvisno od potreb podjetja.
V tem razdelku se bomo poglobili v različne zmožnosti Apache Gobblin, ki pomagajo pri reševanju prej opisanih izzivov.
Upravljanje celotnega življenjskega cikla podatkov
Apache Gobblin ponuja paleto zmogljivosti za izdelavo podatkovnih cevovodov, ki podpirajo celotno zbirko operacij življenjskega cikla podatkov na nizih podatkov.
- Zaužijte podatke – od več virov do ponorov, od baz podatkov, API-jev Rest, strežnikov FTP/SFTP, datotek, CRM-jev, kot sta Salesforce in Dynamics, itd.
- Podvajanje podatkov – med več podatkovnimi jezeri s specializiranimi zmogljivostmi za porazdeljeni datotečni sistem Hadoop prek Distcp-NG.
- Čiščenje podatkov – uporaba pravilnikov hrambe, kot so časovno zasnovani, najnovejši K, različice ali kombinacija pravilnikov.
Gobblinov logični cevovod je sestavljen iz 'Vira', ki določa porazdelitev dela in ustvarja 'Delovne enote.' Te 'delovne enote' se nato prevzamejo za izvedbo kot 'naloge', ki vključujejo ekstrakcijo, pretvorbo, preverjanje kakovosti in pisanje podatkov na cilj. Zadnji korak, 'Objava podatkov', potrdi uspešno izvedbo cevovoda in atomsko potrdi izhodne podatke, če cilj to podpira.
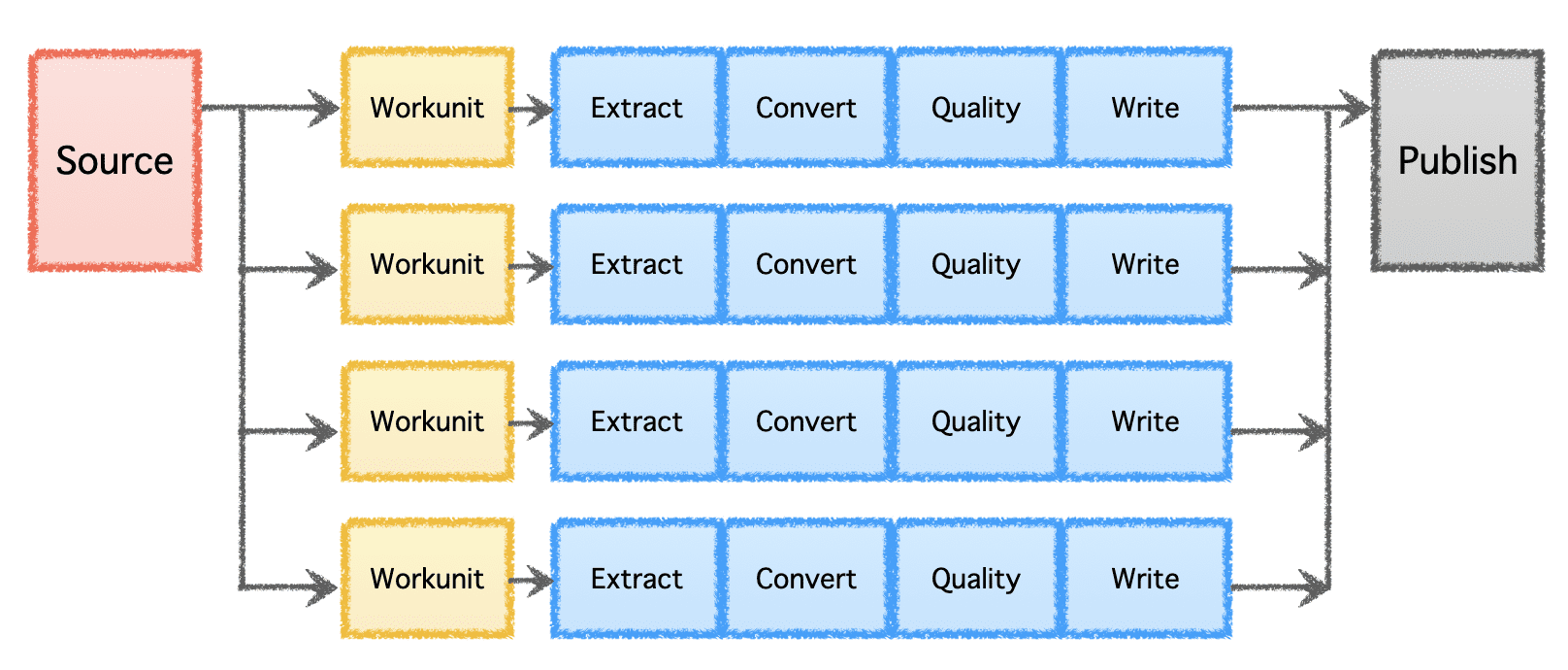
Slika avtorja
Optimizirajte shranjevanje
Apache Gobblin lahko pomaga zmanjšati količino pomnilnika, potrebnega za podatke, s pomočjo naknadne obdelave podatkov po zaužitju ali replikacije s stiskanjem ali pretvorbo formata.
- Stiskanje – naknadna obdelava podatkov za odstranitev podvojenih podatkov na podlagi vseh polj ali ključnih polj zapisov, obrezovanje podatkov, da se ohrani samo en zapis z najnovejšim časovnim žigom z istim ključem.
- Avro v ORC – kot specializirani mehanizem za pretvorbo formata za pretvorbo priljubljenega formata Avro, ki temelji na vrstici, v hiperoptimiziran format ORC, ki temelji na stolpcih.
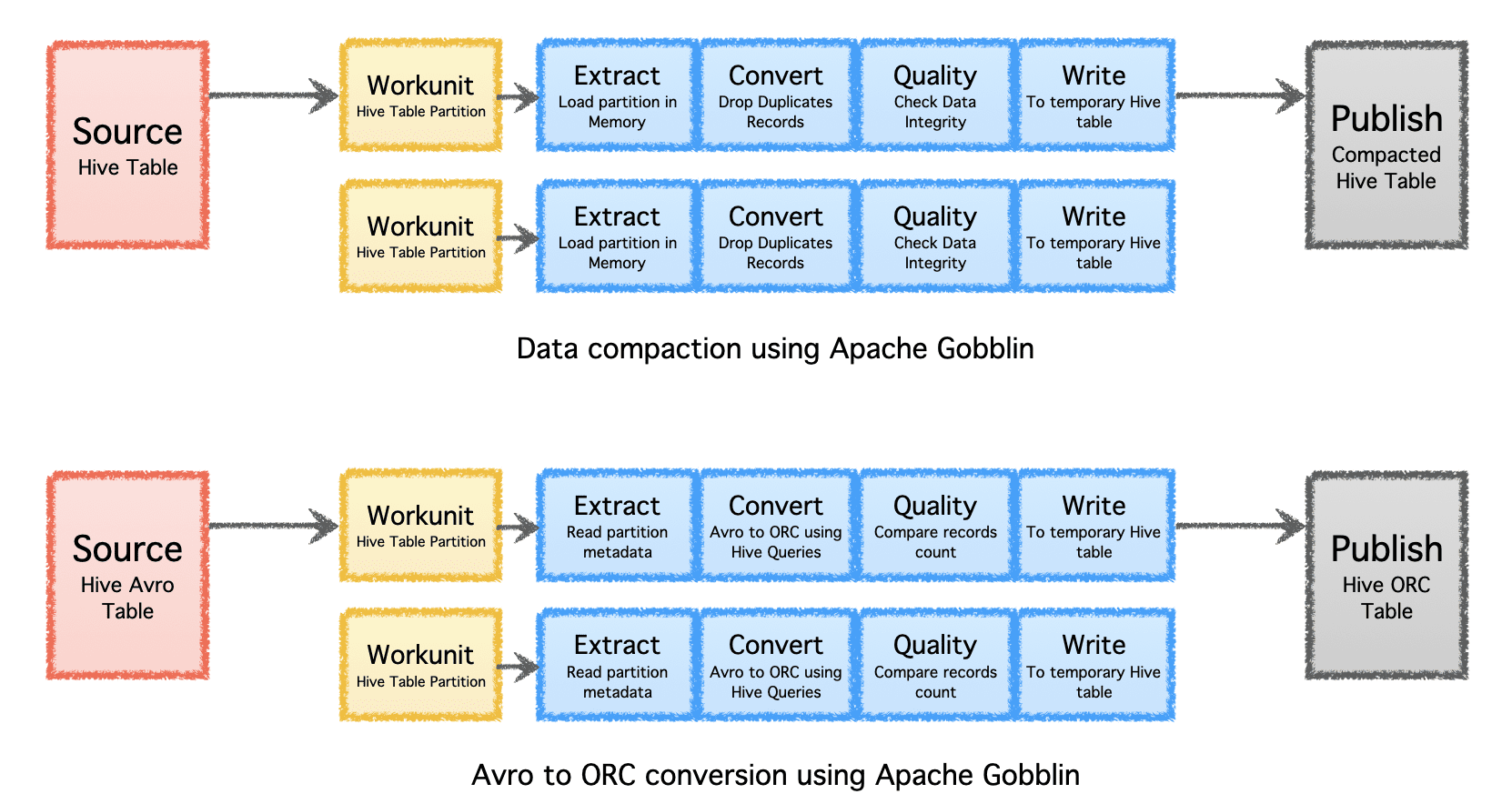
Slika avtorja
Poenostavite arhitekturo
Podjetja raje vzpostavijo ali razvijejo svojo podatkovno infrastrukturo, odvisno od stopnje podjetja (od začetka do podjetja), zahtev glede obsega in njihove ustrezne arhitekture. Apache Gobblin je zelo prilagodljiv in podpira več izvedbenih modelov.
- Samostojni način – za izvajanje kot samostojen proces na goli kovinski škatli, tj. en sam gostitelj za preproste primere uporabe in situacije z nizkimi zahtevami.
- Način MapReduce – za izvajanje kot opravilo MapReduce na infrastrukturi Hadoop za velike podatkovne primere za obdelavo naborov podatkov v petabajtni lestvici.
- Način gruče: samostojen – za delovanje kot gruča, ki jo podpirata Apache Helix in Apache Zookeeper na nizu golih strojev ali gostiteljev za obvladovanje velikega obsega neodvisno od ogrodja Hadoop MR.
- Cluster Mode: Yarn – za delovanje kot gruča na izvornem Yarn brez ogrodja Hadoop MR.
- Cluster Mode: AWS – za delovanje kot gruča v Amazonovi javni ponudbi v oblaku, tj. AWS za infrastrukture, ki gostujejo na AWS.
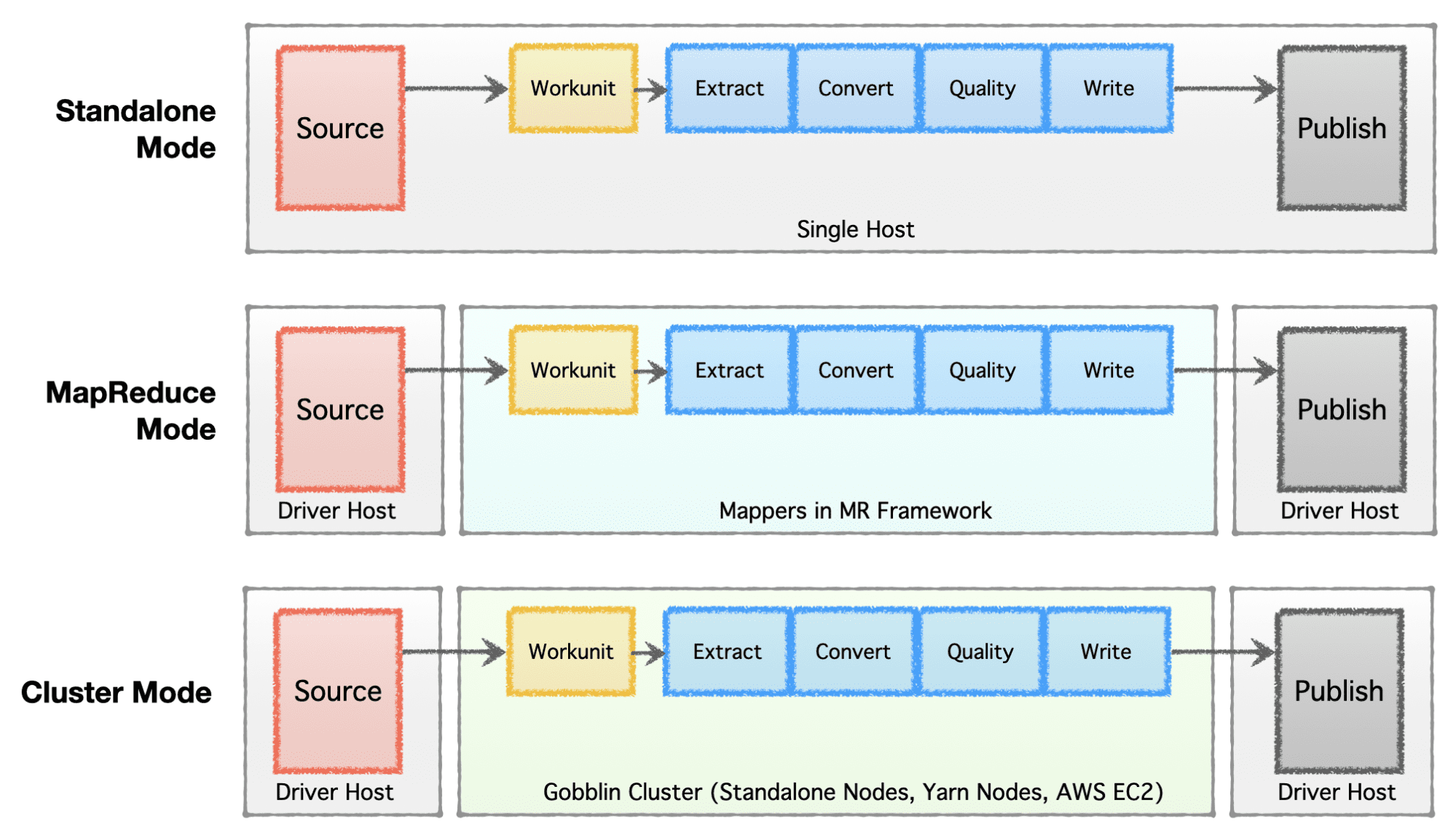
Slika avtorja
Postopno obdelajte podatke
V velikem obsegu z več podatkovnimi kanali in velikim obsegom je treba podatke obdelovati v serijah in skozi čas. Zato so potrebne kontrolne točke, da se lahko podatkovni cevovodi nadaljujejo od tam, kjer so zadnjič končali, in nadaljujejo naprej. Apache Gobblin podpira nizke in visoke vodne žige ter podpira robustno semantiko upravljanja stanja prek State Store na HDFS, AWS S3, MySQL in bolj pregledno.
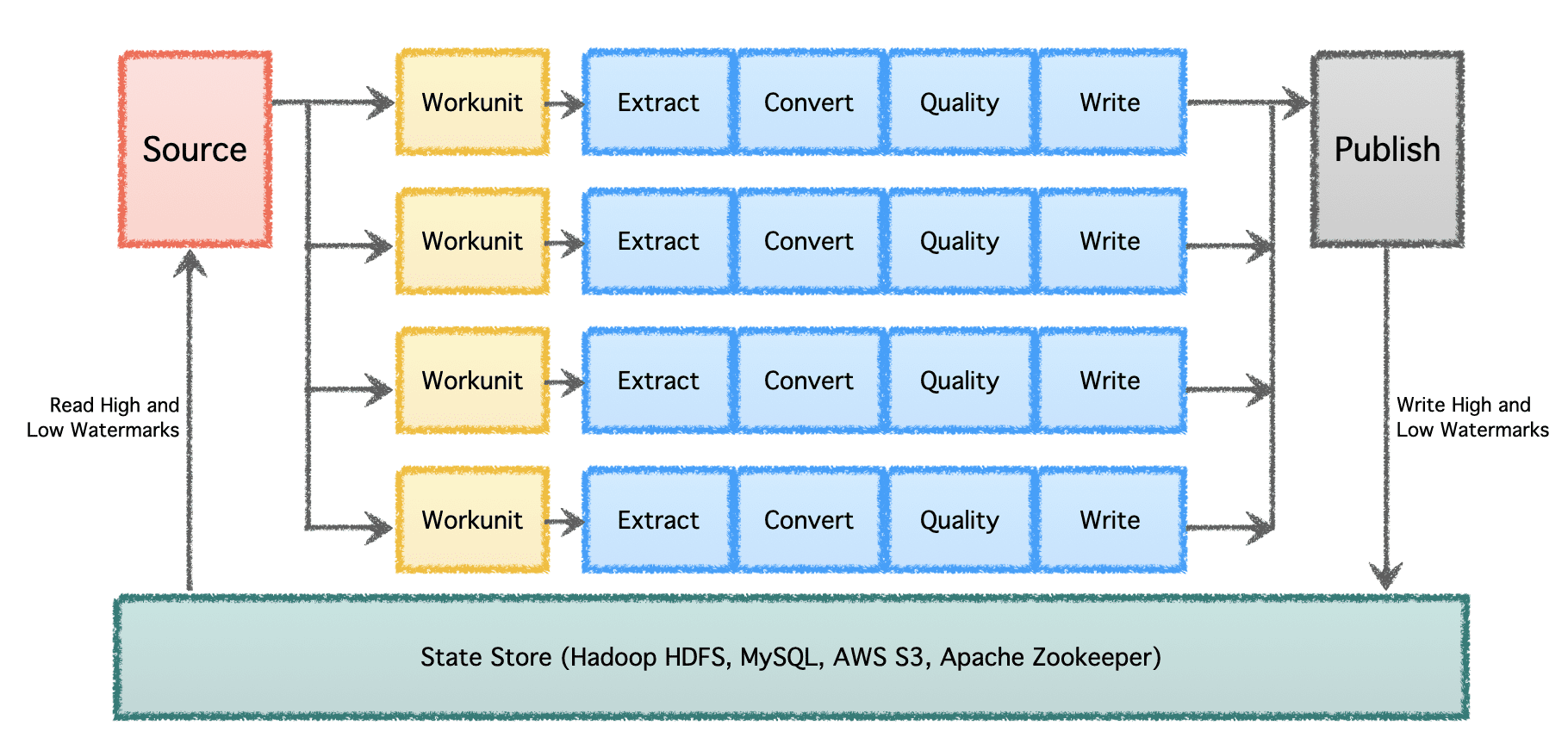
Slika avtorja
Enaki pravilniki o paketnih in tokovnih podatkih
Večino podatkovnih cevovodov je treba danes zapisati dvakrat, enkrat za paketne podatke in spet za skoraj črtne ali pretočne podatke. Podvoji trud in uvede nedoslednosti v politikah in algoritmih, ki se uporabljajo za različne vrste cevovodov. Apache Gobblin to rešuje tako, da uporabnikom omogoči, da enkrat ustvarijo cevovod in ga zaženejo na paketnih in pretočnih podatkih, če se uporabljajo v načinu Gobblin Cluster, Gobblin v načinu AWS ali Gobblin v načinu Yarn.
Selitev med On-prem in Cloud
Zaradi vsestranskih načinov, ki se lahko izvajajo lokalno na enem samem polju, gruči vozlišč ali oblaku, je Apache Gobblin mogoče namestiti in uporabljati lokalno in v oblaku. Zato omogoča uporabnikom, da enkrat napišejo svoje podatkovne cevovode in jih skupaj z uvedbami Gobblin preprosto preselijo med lokalno uporabo in oblakom, na podlagi posebnih potreb.
Zaradi svoje zelo prilagodljive arhitekture, zmogljivih funkcij in izjemnega obsega količin podatkov, ki jih lahko podpira in obdeluje, se Apache Gobblin uporablja v proizvodni infrastrukturi velika tehnološka podjetja in je obvezna oprema za vsako današnjo uvedbo velike podatkovne infrastrukture.
Več podrobnosti o Apache Gobblin in o tem, kako ga uporabljati, najdete na https://gobblin.apache.org
Abhishek Tiwari je višji vodja pri LinkedInu, ki vodi organizacijo Big Data Pipelines v podjetju. Je tudi podpredsednik Apache Gobblin pri Apache Software Foundation in član British Computer Society.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- doseže
- naslavljanje
- oglas
- po
- Pomoč
- algoritmi
- vsi
- Dovoli
- znesek
- Analiza
- analitika
- in
- Apache
- API-ji
- uporabna
- Arhitektura
- povezan
- Avtor
- AWS
- Backed
- temeljijo
- postane
- med
- Big
- Big Podatki
- Pasovi
- Britanski
- poslovni
- podjetja
- Zmogljivosti
- primeri
- izzivi
- preverjanje
- Cloud
- Grozd
- kombinacija
- Podjetja
- podjetje
- kompleksna
- skladnost
- računalnik
- računalništvo
- stalna
- gradnjo
- naprej
- Pretvorba
- pretvorbo
- ustvari
- po meri
- stranka
- Angažiranje strank
- datum
- podatkovna infrastruktura
- Upravljanje podatkov
- baze podatkov
- nabor podatkov
- Odvisno
- razporejeni
- uvajanje
- razmestitve
- destinacija
- Podrobnosti
- določa
- razvili
- drugačen
- porazdeljena
- distribucija
- dinamika
- enostavno
- prizadevanje
- sodelovanje
- Podjetje
- Eter (ETH)
- razvijajo
- izvedba
- drago
- ekstrakt
- pridobivanje
- ekstremna
- Lastnosti
- kolega
- Področja
- file
- končna
- prilagodljiv
- format
- je pokazala,
- Fundacija
- Okvirni
- iz
- gorivo
- polno
- generacija
- Rast
- Hadoop
- ročaj
- pomoč
- visoka
- zelo
- gostitelj
- gostila
- Kako
- Kako
- HTTPS
- in
- vključujejo
- Neodvisni
- Infrastruktura
- infrastruktura
- začetna
- vpogledi
- integracija
- Predstavlja
- naložbe
- IT
- Job
- KDnuggets
- Imejte
- Ključne
- velika
- Zadnja
- Zadnji
- vodi
- obremenitev
- nizka
- Stroji
- upravljanje
- upravitelj
- Trženje
- Mehanizem
- kovinski
- selitev
- način
- modeli
- sodobna
- načini
- več
- Najbolj
- več
- Must-have
- MySQL
- materni
- potrebna
- potrebe
- Najnovejši
- vozlišča
- ponujanje
- ONE
- open source
- operacije
- Organizacija
- opisano
- deli
- Prilagojene
- izbrali
- plinovod
- platon
- Platonova podatkovna inteligenca
- PlatoData
- politike
- Popular
- moč
- močan
- Napovedna analiza
- raje
- Predsednik
- prej
- Cena
- problem
- Postopek
- Izdelek
- proizvodnja
- zagotavlja
- javnega
- Javni oblak
- objavijo
- kakovost
- hitro
- obsegu
- Priporočila
- zapis
- evidence
- zmanjša
- relativno
- replikacija
- Zahteve
- tisti,
- REST
- Nadaljuj
- zadrževanje
- robusten
- Run
- prodajni center
- Enako
- Lestvica
- skaliranje
- skripte
- Oddelek
- semantika
- višji
- sentiment
- nastavite
- pomemben
- Enostavno
- sam
- situacije
- So
- Društvo
- Software
- SOLVE
- Rešuje
- vir
- Viri
- specializirani
- specifična
- Stage
- samostojna
- zagon
- Država
- Korak
- shranjevanje
- trgovina
- shranjeni
- Strateško
- tok
- pretakanje
- uspešno
- apartma
- podpora
- Podpira
- sistem
- ciljno
- Naloge
- Tehnologija
- O
- njihove
- zato
- skozi
- čas
- Časovni žig
- do
- danes
- orodja
- tradicionalna
- Transform
- preoblikovati
- Vrste
- osnovni
- neprimerljivo
- uporaba
- Uporabniki
- različnih
- vsestranski
- preko
- Podpredsednica
- Obseg
- prostornine
- ki
- medtem
- bo
- brez
- delo
- svet
- pisati
- pisanje
- pisni
- zefirnet