AWS Glue Studio este acum integrat cu AWS Glue Databrew. AWS Glue Studio este o interfață grafică care facilitează crearea, rularea și monitorizarea lucrărilor de extragere, transformare și încărcare (ETL) în AWS Adeziv. DataBrew este un instrument vizual de pregătire a datelor care vă permite să curățați și să normalizați datele fără a scrie niciun cod. Cele peste 200 de transformări pe care le oferă sunt acum disponibile pentru a fi utilizate într-o lucrare vizuală AWS Glue Studio.
În DataBrew, a reţetă este un set de pași de transformare a datelor pe care îi puteți crea interactiv în interfața sa vizuală intuitivă. În această postare, veți vedea cum să utilizați construirea unei rețete în DataBrew și apoi să o aplicați ca parte a unui job ETL vizual AWS Glue Studio.
Utilizatorii DataBrew existenți vor beneficia, de asemenea, de pe urma acestei integrări — acum vă puteți rula rețetele ca parte a unui flux de lucru vizual mai amplu cu toate celelalte componente pe care le oferă AWS Glue Studio, pe lângă faptul că puteți utiliza configurația avansată a jobului și cea mai recentă versiune a motorului AWS Glue .
Această integrare aduce beneficii distincte utilizatorilor existenți ai ambelor instrumente:
- Aveți o vedere centralizată în AWS Glue Studio a diagramei ETL generale, de la capăt la capăt
- Puteți defini interactiv o rețetă, văzând valorile, statisticile și distribuția pe consola DataBrew, apoi reutilizați acea logică de procesare testată și versiunea în lucrările vizuale AWS Glue Studio.
- Puteți orchestra mai multe rețete DataBrew într-o lucrare AWS Glue ETL sau chiar mai multe lucrări folosind fluxurile de lucru AWS Glue
- Rețetele DataBrew pot folosi acum funcțiile de lucru AWS Glue, cum ar fi marcaje pentru procesarea incrementală a datelor, reîncercări automate, scalare automată sau gruparea fișierelor mici pentru o eficiență mai mare
Prezentare generală a soluțiilor
În cazul nostru de utilizare fictiv, cerința este de a curăța un set de date sintetice privind declarațiile medicale creat pentru această postare, care are unele probleme de calitate a datelor introduse intenționat pentru a demonstra capabilitățile DataBrew privind pregătirea datelor. Apoi datele despre revendicări sunt ingerate în catalog (deci sunt vizibile pentru analiști), după ce sunt îmbogățite cu câteva detalii relevante despre furnizorii de servicii medicale corespunzători provenind dintr-o sursă separată.
Soluția constă într-o lucrare vizuală AWS Glue Studio care citește două fișiere CSV cu revendicări și, respectiv, furnizori. Lucrarea aplică o rețetă a primei pentru a aborda problemele de calitate, selecta coloanele din a doua, unește ambele seturi de date și, în final, stochează rezultatul pe Serviciul Amazon de stocare simplă (Amazon S3), creând un tabel în catalog, astfel încât datele de ieșire să poată fi utilizate de alte instrumente precum Amazon Atena.
Creați o rețetă DataBrew
Începeți prin a înregistra depozitul de date pentru dosarul de revendicări. Acest lucru vă va permite să construiți rețeta în editorul său interactiv folosind datele reale, astfel încât să puteți evalua rezultatul transformărilor pe măsură ce le definiți.
- Descărcați fișierul CSV de revendicări utilizând următorul link: alabama_claims_data_Jun2023.csv.
- Pe consola DataBrew, alegeți Datasets în panoul de navigare, apoi alegeți Conectați un nou set de date.
- Alegeți opțiunea Fișier încărcat.
- Pentru Numele setului de date, introduce
Alabama claims. - Pentru Selectați un fișier de încărcat, alegeți fișierul pe care tocmai l-ați descărcat pe computer.
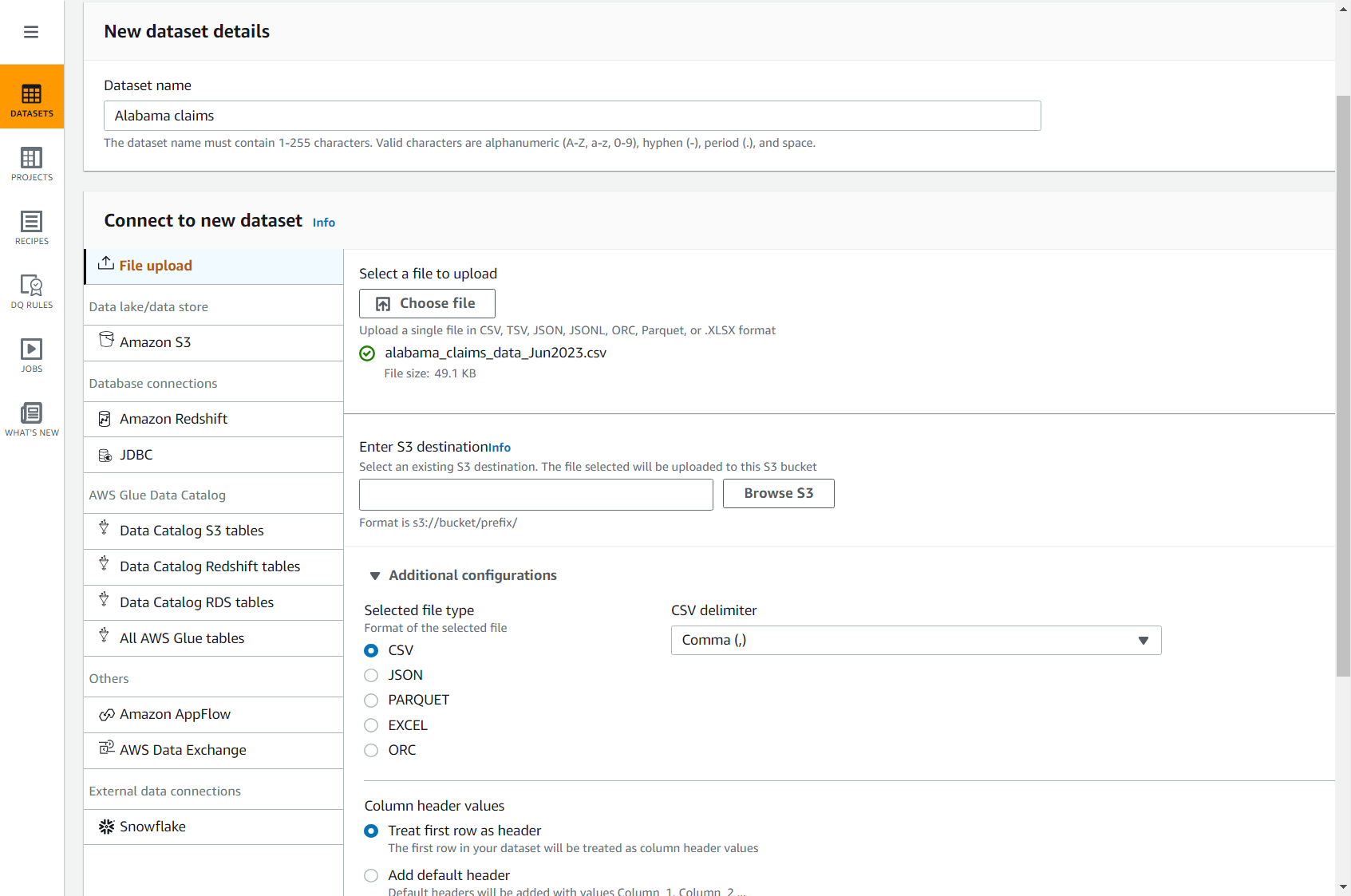
- Pentru Introduceți destinația S3, introduceți sau căutați o grupă în contul dvs. și Regiune.
- Lăsați restul opțiunilor în mod implicit (CSV separat cu virgulă și cu antet) și finalizați crearea setului de date.
- Alege Proiect în panoul de navigare, apoi alegeți Creați un proiect.
- Pentru Numele proiectului, numeste
ClaimsCleanup. - În Detalii reteta, Pentru Reteta atasata, alege Creați o nouă rețetă, numeste
ClaimsCleanup-recipe, și alegețiAlabama claimssetul de date pe care tocmai l-ați creat.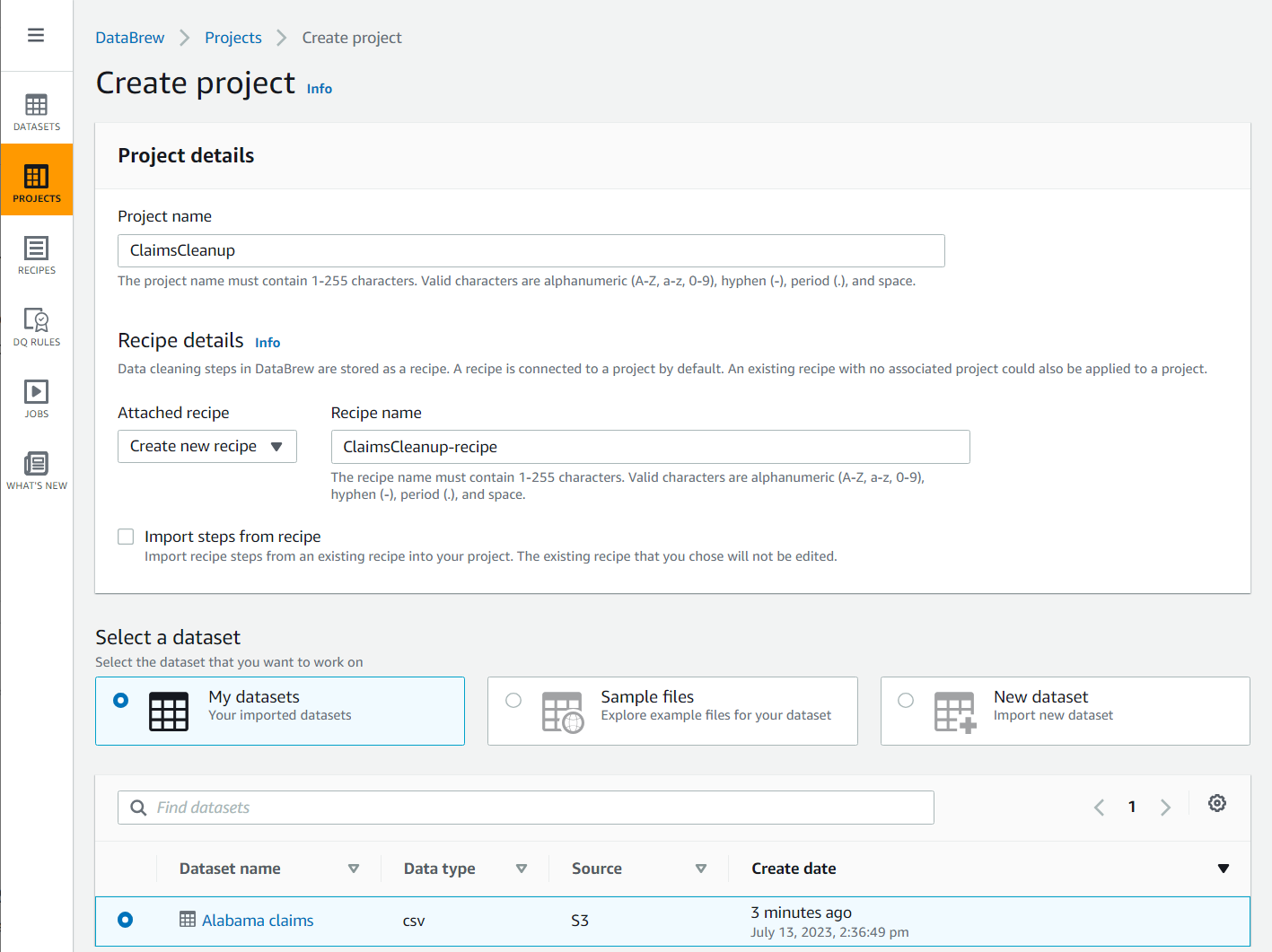
- Selectați un rol potrivit pentru DataBrew sau creați unul nou și finalizați crearea proiectului.
Aceasta va crea o sesiune folosind un subset configurabil de date. După ce a inițializat sesiunea, puteți observa că unele celule au valori nevalide sau lipsă.
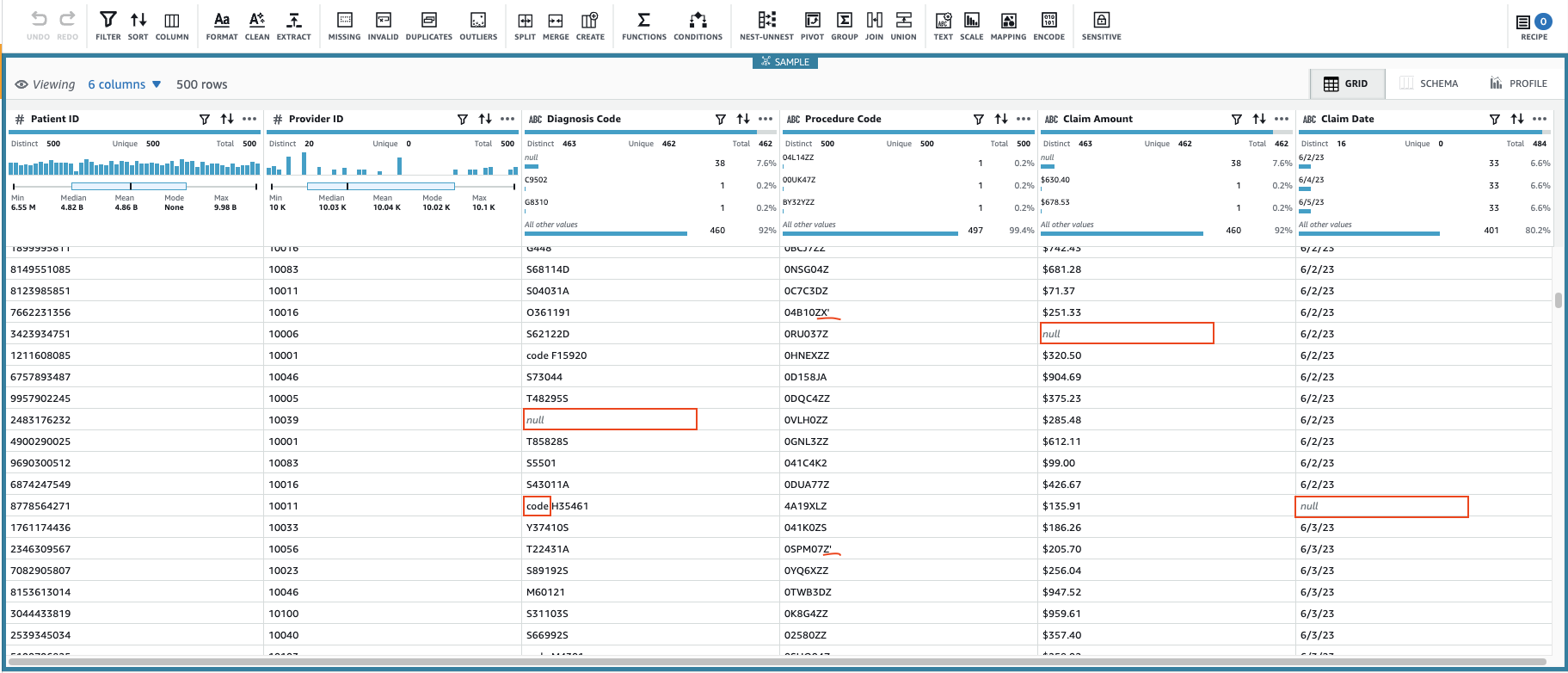
Pe lângă valorile lipsă din coloane Cod de diagnostic, Suma de revendicare, și Data revendicării, unele valori din date au câteva caractere suplimentare: Cod de diagnostic valorile sunt uneori prefixate cu „cod” (spațiu inclus) și Cod de procedură valorile sunt uneori urmate de ghilimele simple.
Suma de revendicare valorile vor fi probabil folosite pentru unele calcule, deci convertiți în număr și Date de revendicare ar trebui convertit în tipul de dată.
Acum că am identificat problemele de calitate a datelor de rezolvat, trebuie să decidem cum să tratăm fiecare caz.
Există mai multe moduri în care puteți adăuga pași de rețetă, inclusiv folosind meniul contextual coloanei, bara de instrumente din partea de sus sau din rezumatul rețetei. Folosind ultima metodă, puteți căuta tipul de pas indicat pentru a replica rețeta creată în această postare.
Suma de revendicare este esențial pentru acest caz de utilizare, iar decizia este de a elimina astfel de rânduri.
- Adăugați pasul Eliminați valorile lipsă.
- Pentru Coloana sursă, alege Suma de revendicare.
- Lăsați acțiunea implicită Ștergeți rândurile cu valori lipsă Și alegeți Aplică pentru al salva.
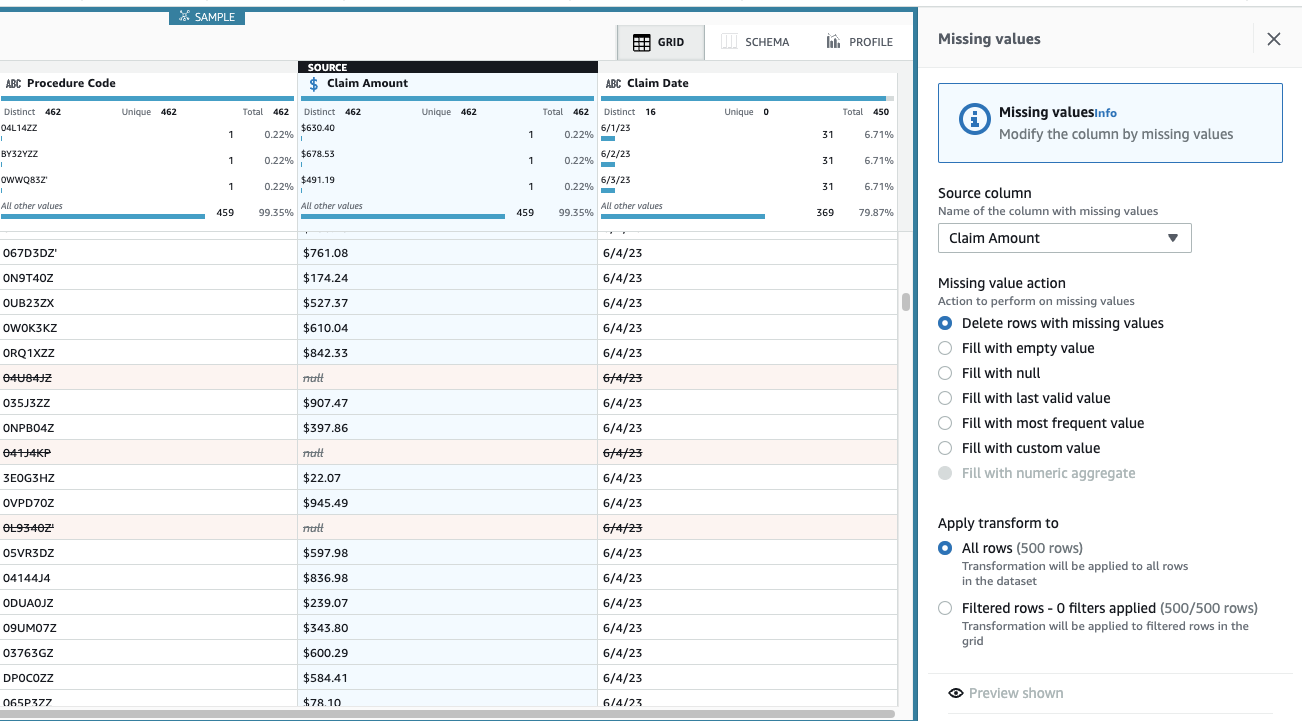
Vizualizarea este acum actualizată pentru a reflecta aplicația pas, iar rândurile cu sume lipsă nu mai sunt acolo.
Cod de diagnostic poate fi gol, deci acest lucru este acceptat, dar în cazul Data revendicării, vrem să avem o estimare rezonabilă. Rândurile din date sunt sortate în ordine cronologică, astfel încât să puteți imputa datele lipsă utilizând valoarea validă de previzualizare din rândurile precedente. Presupunând că fiecare zi are revendicări, cea mai mare eroare ar fi atribuirea acesteia zilei de previzualizare dacă ar fi prima revendicare din acea zi care lipsește data; în scopuri ilustrative, să considerăm că eroarea potențială este acceptabilă.
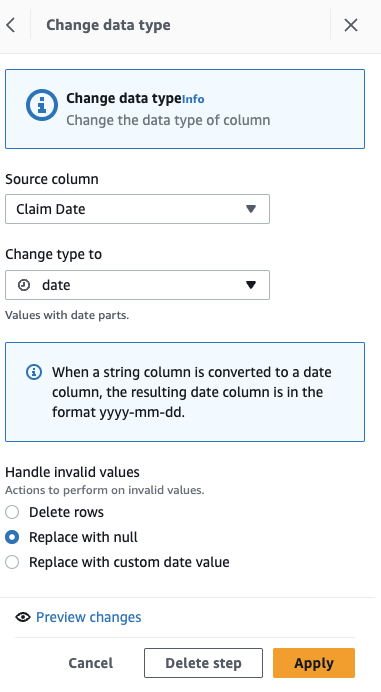
Mai întâi, convertiți coloana din șir în tip de dată.
- Adăugați pasul Schimbați tipul.
- Alege Data revendicării ca coloana si data ca tip, apoi alegeți Aplică.
- Acum pentru a face imputarea datelor lipsă, adăugați pasul Completați sau imputați valorile lipsă.
- Selectați Completați cu ultima valoare validă ca acțiune și alegeți Data revendicării ca sursă.
- Alege Previzualizați modificările pentru a-l valida, apoi alege Aplică pentru a salva pasul.
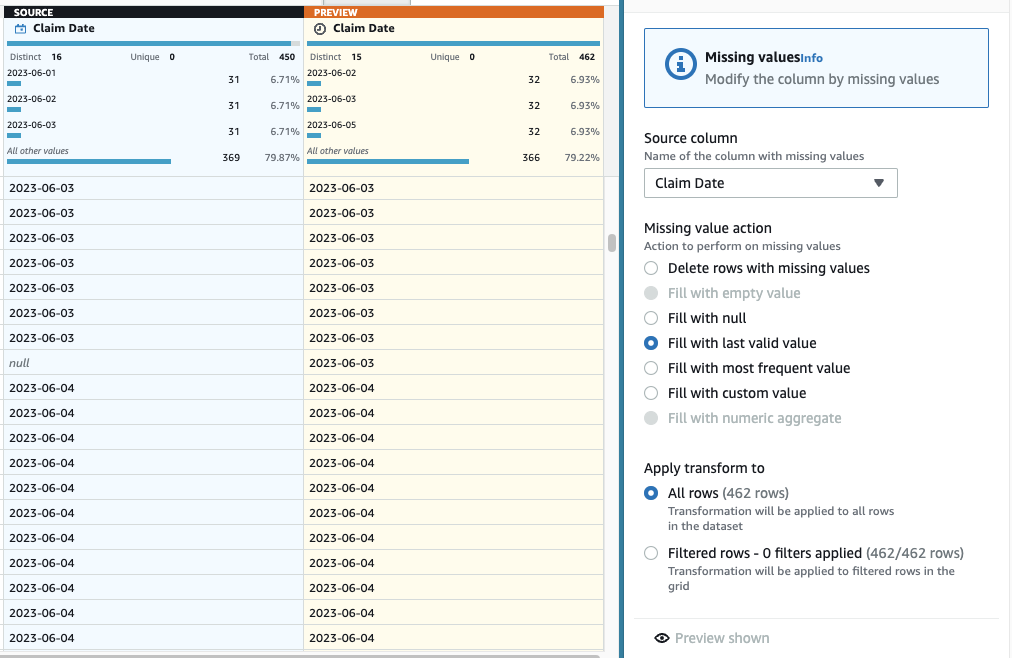
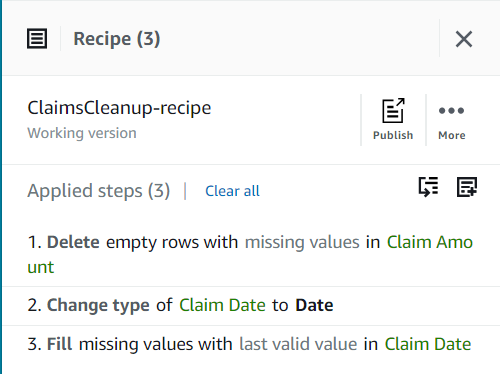
Până acum, rețeta ta ar trebui să aibă trei pași, așa cum se arată în următoarea captură de ecran.
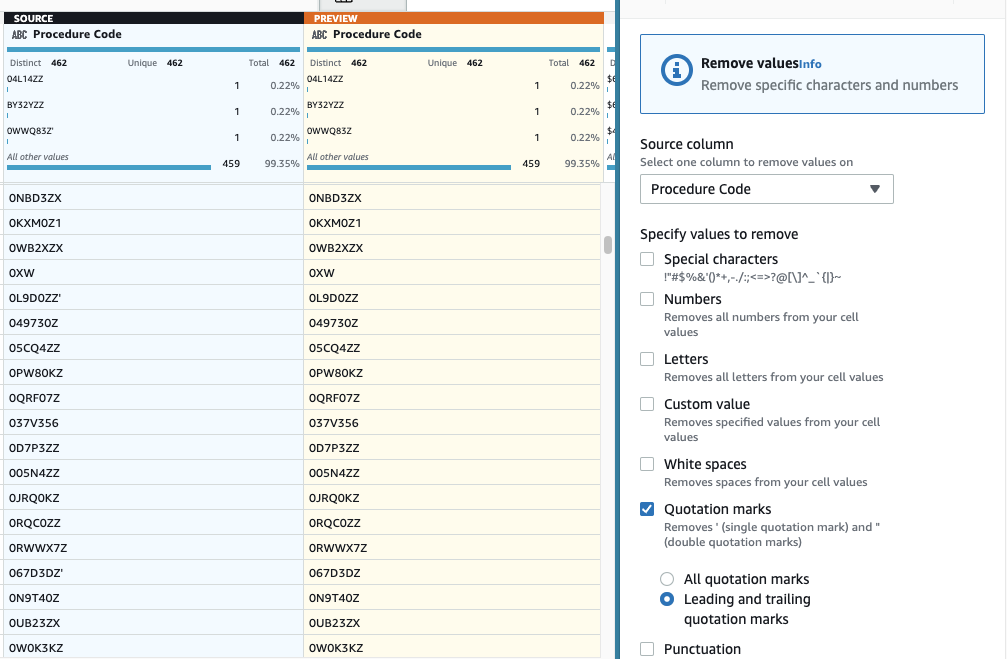
- Apoi, adăugați pasul Eliminați ghilimele.
- Alege Cod de procedură coloană și selectați Ghilimelele de început și de sfârșit.
- Previzualizează pentru a verifica că are efectul dorit și aplică noul pas.
- Adăugați pasul Eliminați caracterele speciale.
- Alege Suma de revendicare coloană și pentru a fi mai specific, selectați Caractere speciale personalizate și intră
$pentru Introduceți caractere speciale personalizate.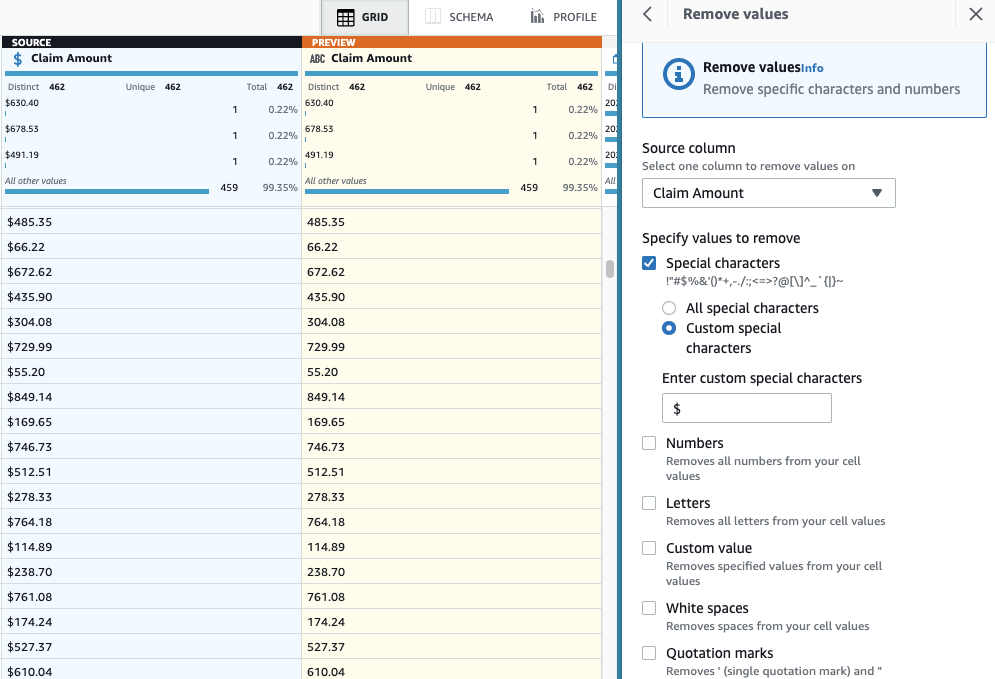
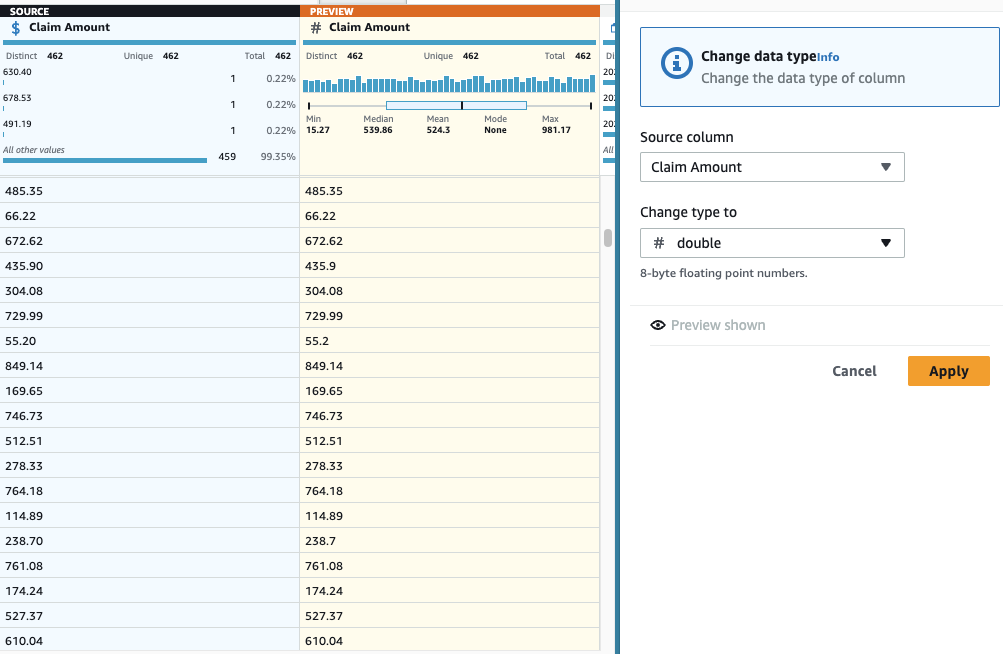
- Adauga o Schimbați tipul calcă pe coloană Suma de revendicare Și alegeți dubla ca tip.
- Ca ultim pas, pentru a elimina prefixul „cod” de prisos, adăugați a Înlocuiți valoarea sau modelul Etapa.
- Alegeți coloana Cod de diagnostic, Și pentru Introduceți valoarea personalizată, introduce
code(cu un spațiu la capăt).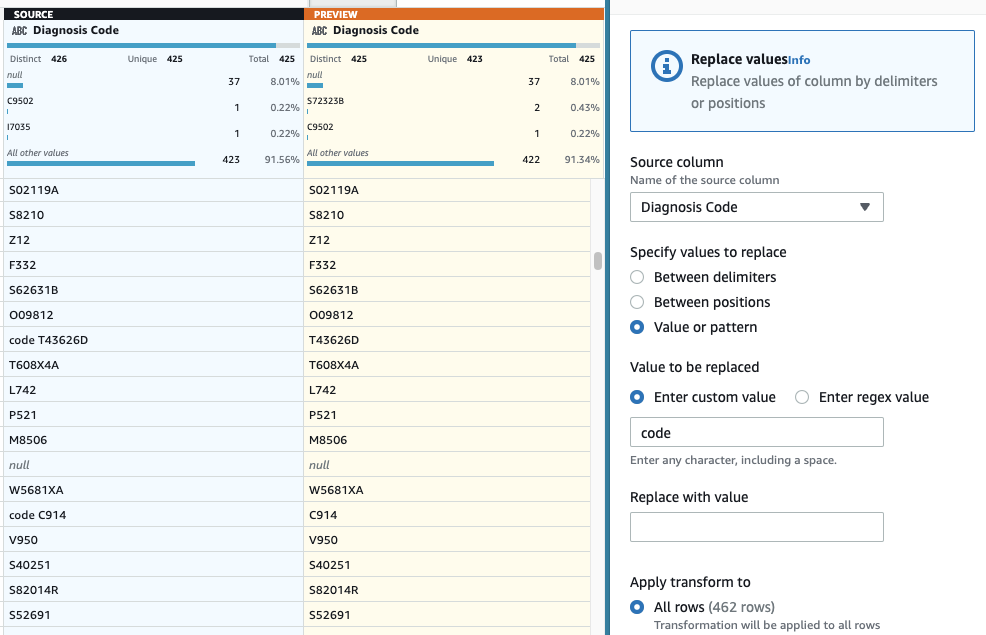
Acum că ați abordat toate problemele de calitate a datelor identificate pe eșantion, publicați proiectul ca rețetă.
- Alege Publica în Rețetă panoul, introduceți o descriere opțională și finalizați publicația.
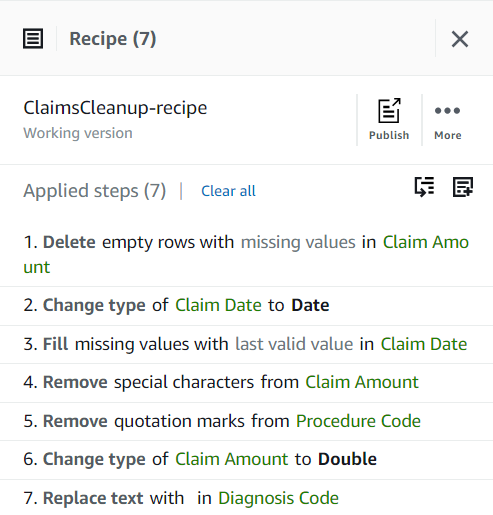
De fiecare dată când publicați, va crea o versiune diferită a rețetei. Mai târziu, vei putea alege ce versiune a rețetei să folosești.
Creați o lucrare ETL vizuală în AWS Glue Studio
Apoi, creați jobul care utilizează rețeta. Parcurgeți următorii pași:
- Pe consola AWS Glue Studio, alegeți ETL vizual în panoul de navigare.
- Alege Vizual cu o pânză goală și creați jobul vizual.
- În partea de sus a jobului, înlocuiți „Lucrări fără titlu” cu un nume la alegere.
- Pe detalii job fila, specificați un rol pe care îl va folosi jobul.
Acesta trebuie să fie un Gestionarea identității și accesului AWS (EU SUNT) rol potrivit pentru AWS Glue cu permisiuni pentru Amazon S3 și AWS Glue Data Catalog. Rețineți că rolul folosit anterior pentru DataBrew nu este utilizabil pentru lucrări de rulare, deci nu va fi listat pe Rolul IAM meniu derulant aici.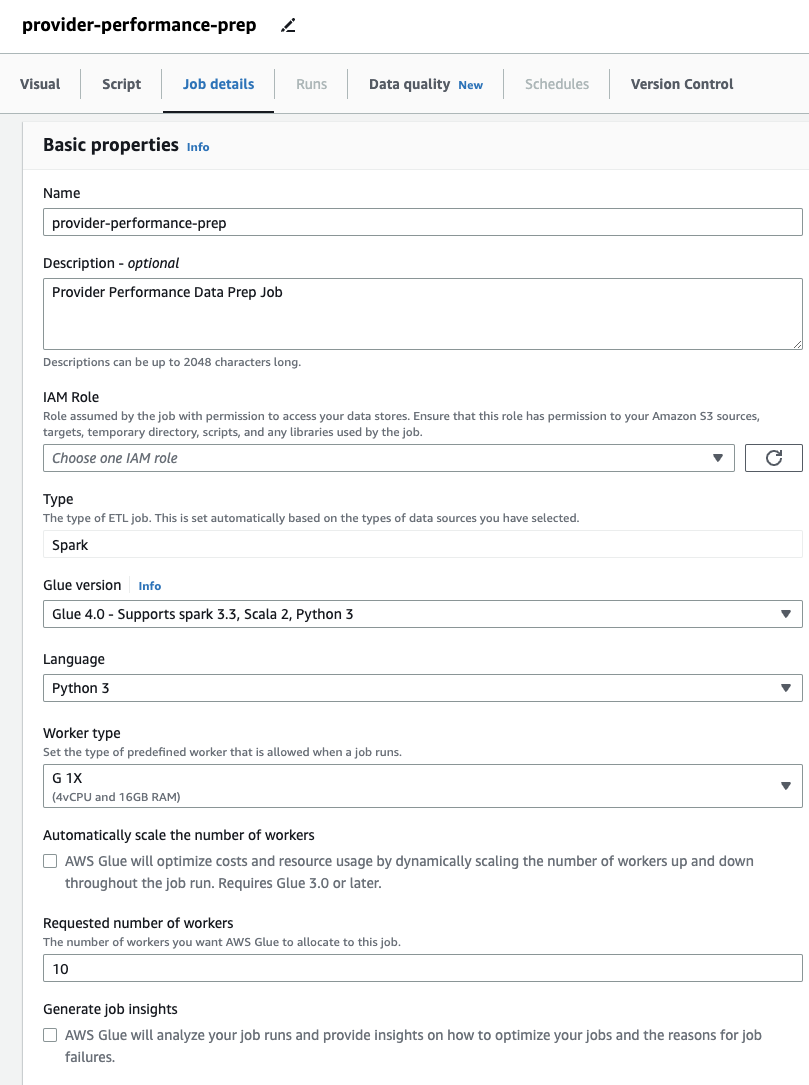
Dacă ați folosit înainte numai lucrări DataBrew, observați că în AWS Glue Studio, puteți alege setările de performanță și cost, inclusiv dimensiunea lucrătorului, scalarea automată și Execuție flexibilă, precum și să folosească cel mai recent timp de execuție AWS Glue 4.0 și să beneficieze de îmbunătățirile semnificative ale performanței pe care le aduce. Pentru acest loc de muncă, puteți utiliza setările implicite, dar reduceți numărul solicitat de lucrători în interesul cumpătării. Pentru acest exemplu, doi lucrători vor face. - Pe Vizual fila, adăugați o sursă S3 și denumiți-o
Providers. - Pentru URL S3, introduce
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.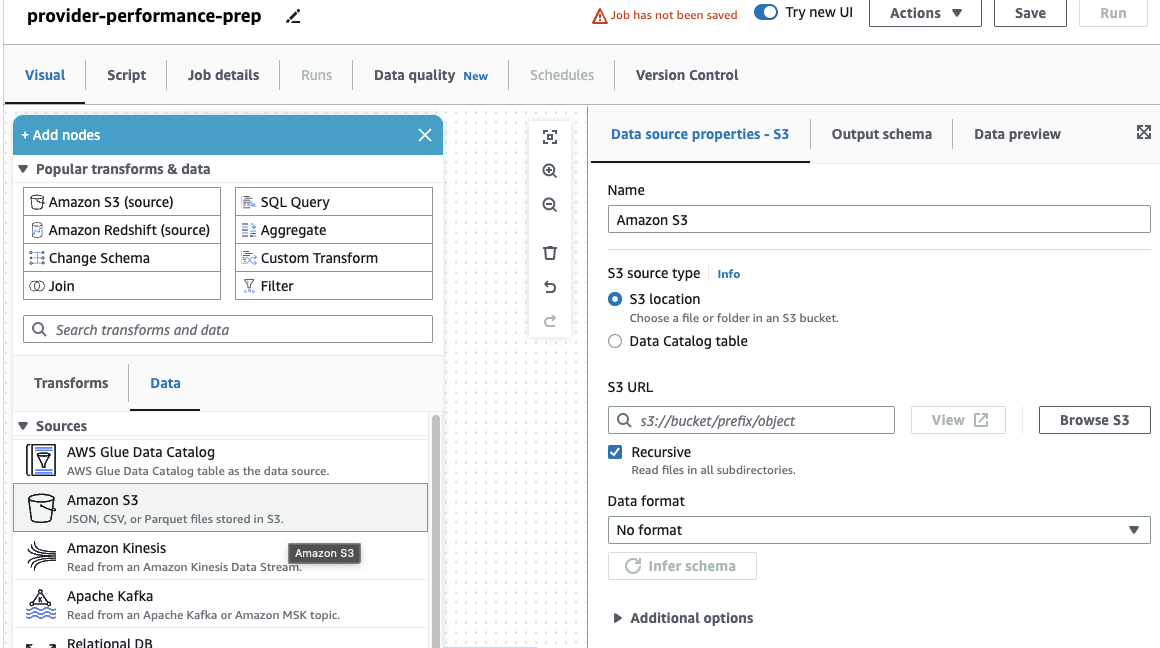
- Selectați formatul ca CSV Și alegeți Deduceți schema.
Acum schema este listată pe Schema de ieșire fila folosind antetul fișierului.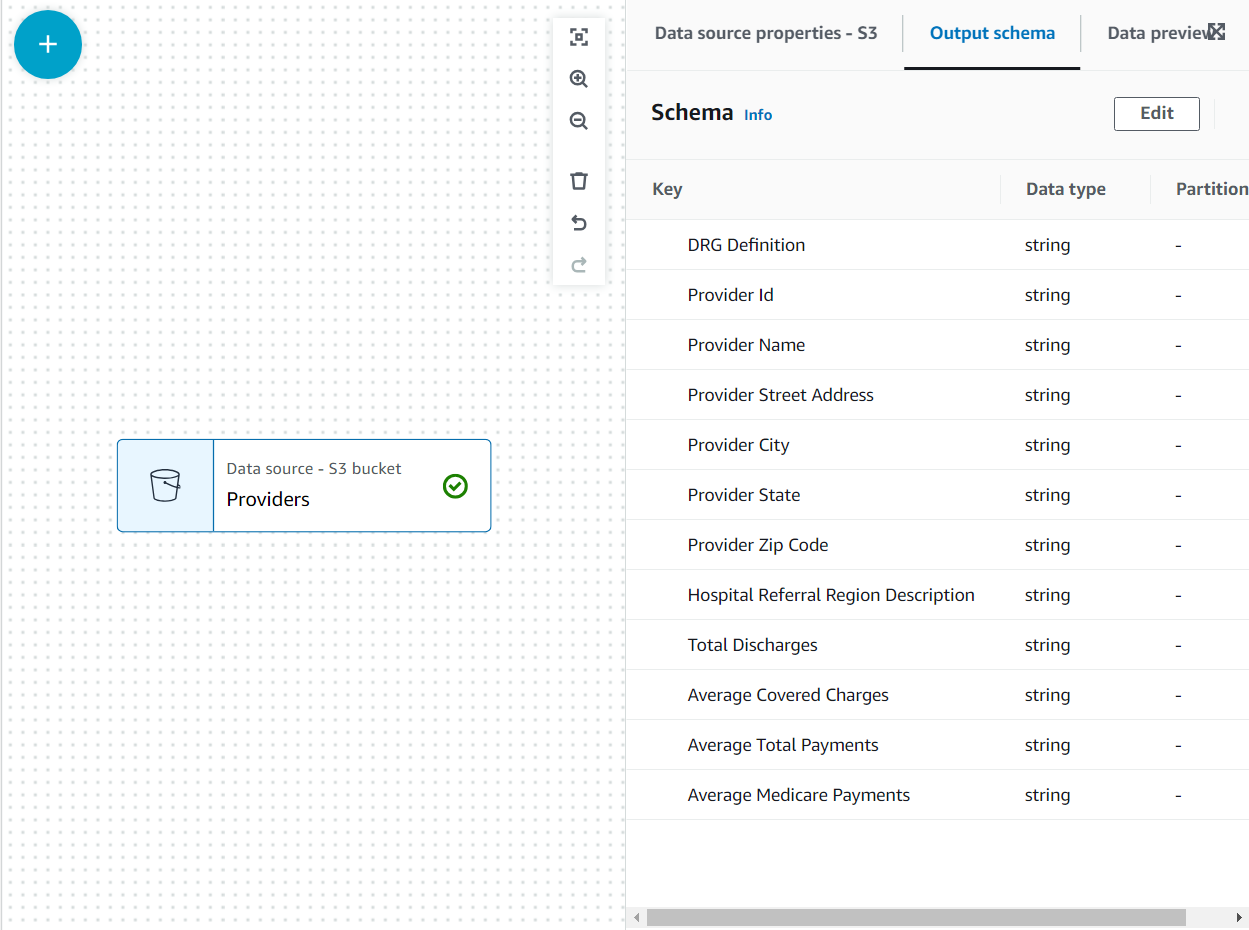
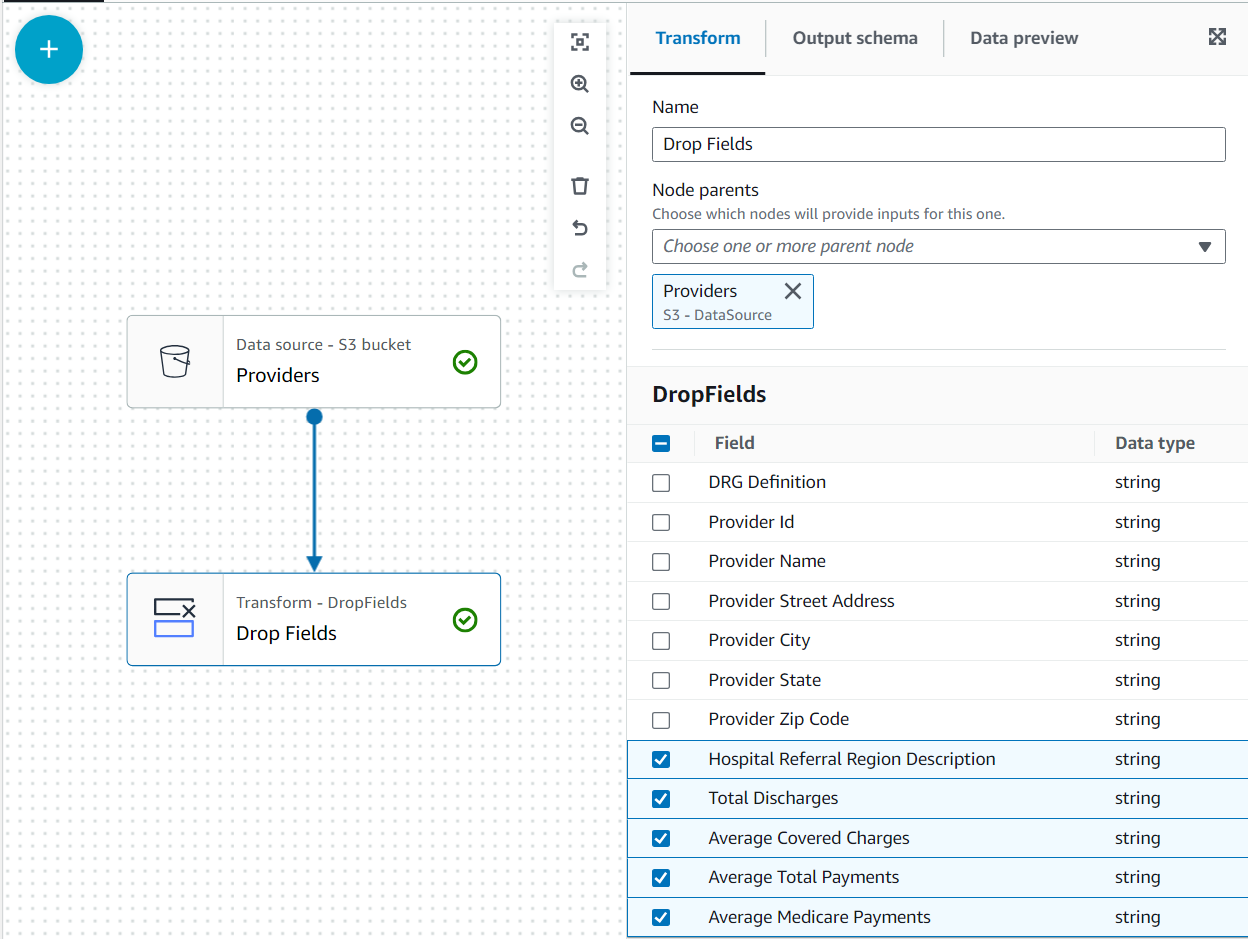
În acest caz de utilizare, decizia este că nu sunt necesare toate coloanele din setul de date furnizorilor, așa că le putem elimina pe restul.
- Cu Furnizori nodul selectat, adăugați a Drop Fields transform (dacă nu ați selectat nodul părinte, acesta nu va avea unul; în acest caz, atribuiți manual nodul părinte).
- Selectați toate câmpurile după Codul poștal al furnizorului.
Ulterior, acestor date li se vor alătura revendicările pentru statul Alabama care utilizează furnizorul; totuși, acel al doilea set de date nu are starea specificată. Putem folosi cunoștințele despre date pentru a optimiza unirea prin filtrarea datelor de care avem cu adevărat nevoie.
- Adauga o Filtru transforma ca un copil al Drop Fields.
- Numeste
Alabama providersși adăugați o condiție pe care statul trebuie să o îndeplineascăAL.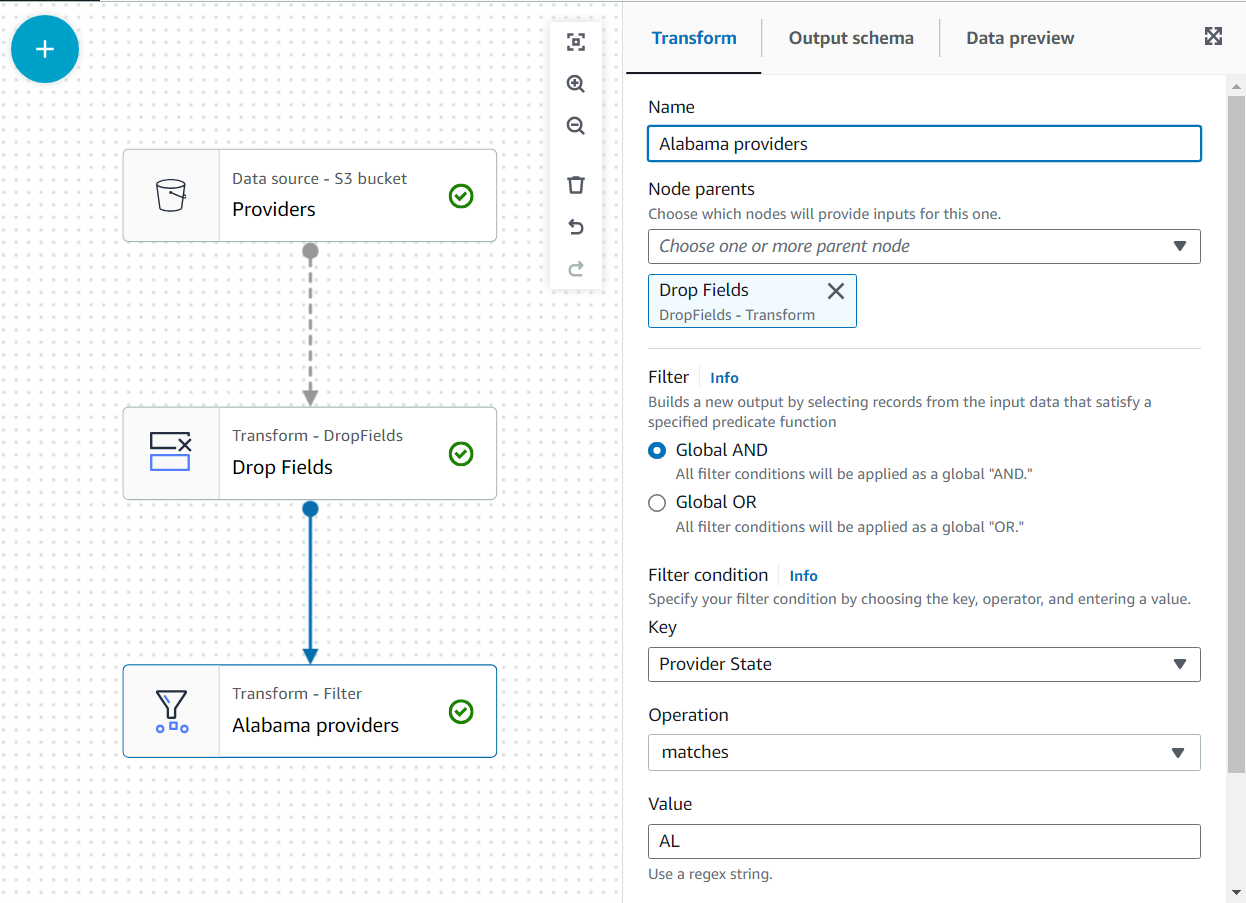
- Adăugați a doua sursă (o nouă sursă S3) și denumiți-o
Alabama claims. - Pentru a intra în URL S3, deschideți DataBrew într-o filă separată de browser, alegeți Seturi de date în panoul de navigare și copiați pe tabel locația afișată pe tabel pentru susține Alabama (copiați textul care începe cu s3://, nu linkul http asociat). Apoi înapoi la lucrarea vizuală, lipiți-o ca URL S3; dacă este corect, veți vedea în Schema de ieșire fila câmpurile de date listate.
- Selectați formatul CSV și deduceți schema așa cum ați făcut-o cu cealaltă sursă.
- Fiind copil al acestei surse, căutați în Adăugați noduri meniu pentru
recipeȘi alegeți Rețetă de pregătire a datelor.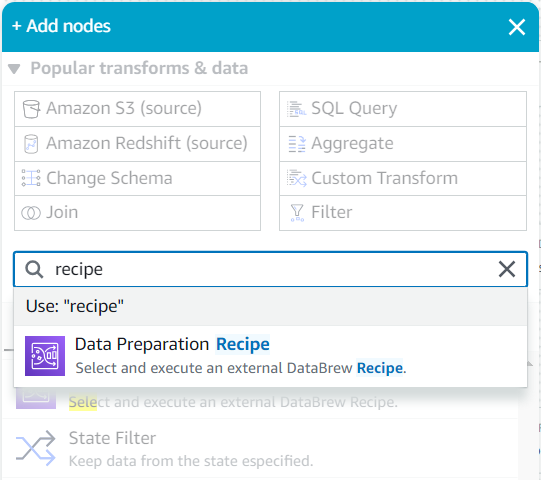
- În proprietățile acestui nou nod, dați-i numele
Claim cleanup recipeși alegeți rețeta și versiunea pe care le-ați publicat anterior. - Puteți examina pașii rețetei aici și puteți utiliza linkul către DataBrew pentru a face modificări dacă este necesar.
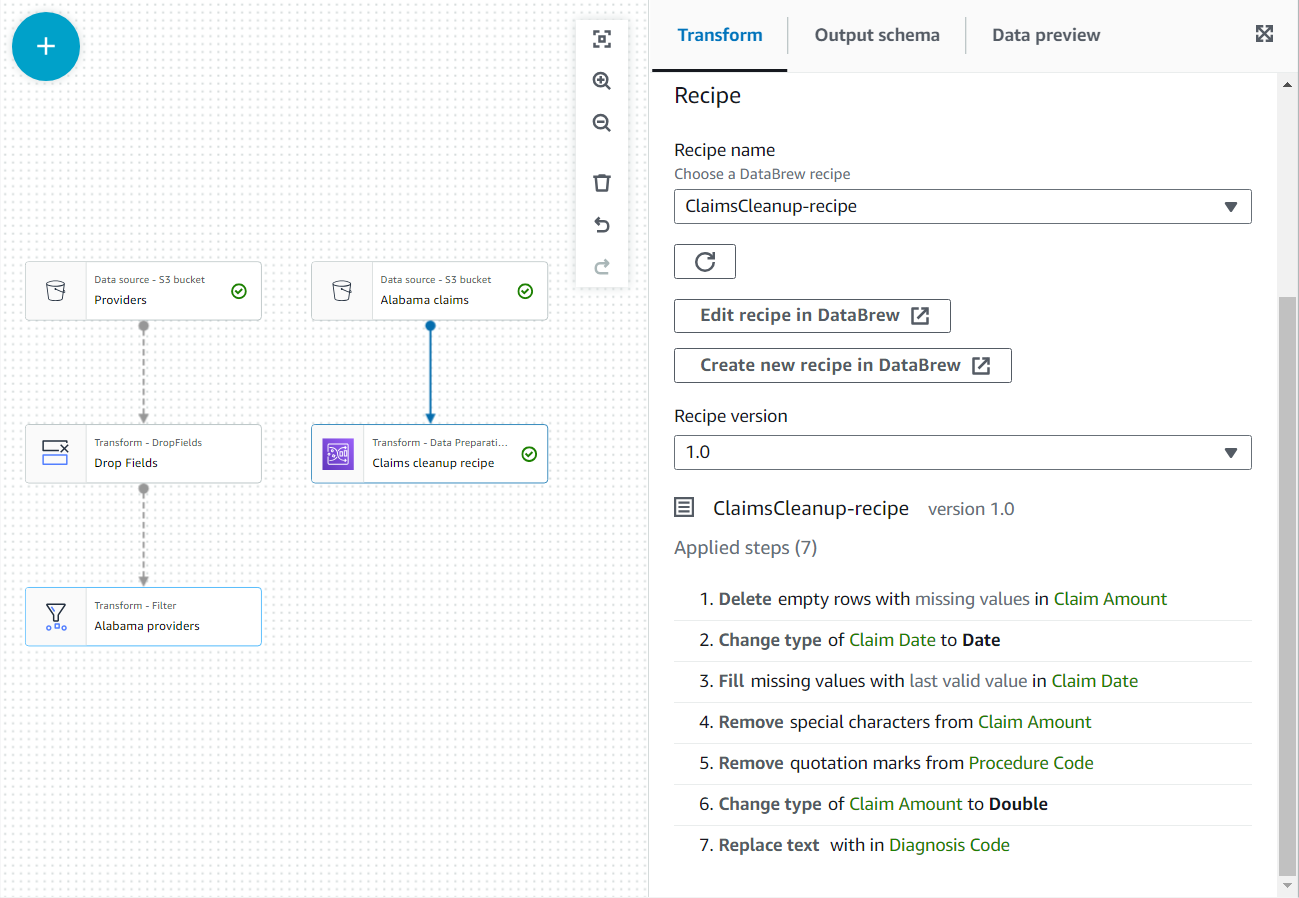
- Adauga o Alatura-te nod și selectați ambele Furnizori din Alabama și Revendicați rețete de curățare ca părinte.
- Adăugați o condiție de alăturare egală cu ID-ul furnizorului din ambele surse.
- Ca ultim pas, adăugați un nod S3 ca țintă (rețineți că primul listat când căutați este sursa; asigurați-vă că selectați versiunea care este listată ca țintă).
- În configurația nodului, lăsați formatul implicit JSON și introduceți o adresă URL S3 pe care rolul jobului are permisiunea de a scrie.
În plus, faceți datele de ieșire disponibile ca tabel în catalog.
- În Opțiuni de actualizare a catalogului de date secțiunea, selectați a doua opțiune Creați un tabel în Catalogul de date și, la rulările ulterioare, actualizați schema și adăugați noi partiții, apoi selectați o bază de date pe care aveți permisiunea de a crea tabele.
- Atribui
alabama_claimsca nume și alegeți Data revendicării ca cheie de partiție (aceasta este în scop ilustrativ; un tabel mic ca acesta nu are nevoie cu adevărat de partiții dacă alte date nu vor fi adăugate mai târziu).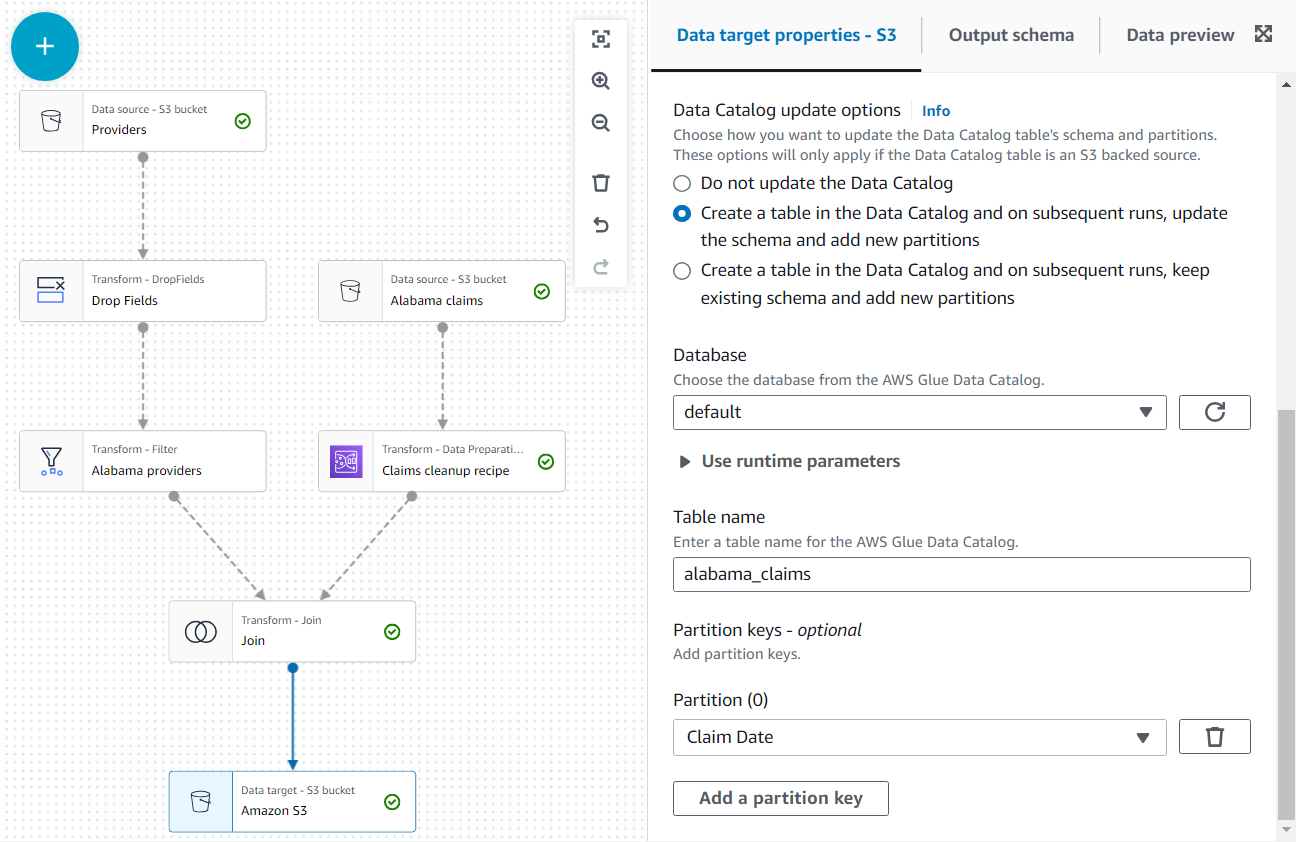
- Acum puteți salva și rula lucrarea.
- Pe Rulează fila, puteți urmări procesul și puteți vedea valorile detaliate ale jobului utilizând linkul ID job.
Lucrarea ar trebui să dureze câteva minute.
- Când lucrarea este finalizată, navigați la consola Athena.
- Căutați masa
alabama_claimsîn baza de date pe care ați selectat-o și, folosind meniul contextual, alegeți Tabelul de previzualizare, care va rula o instrucțiune simplă SELECT * SQL pe tabel.
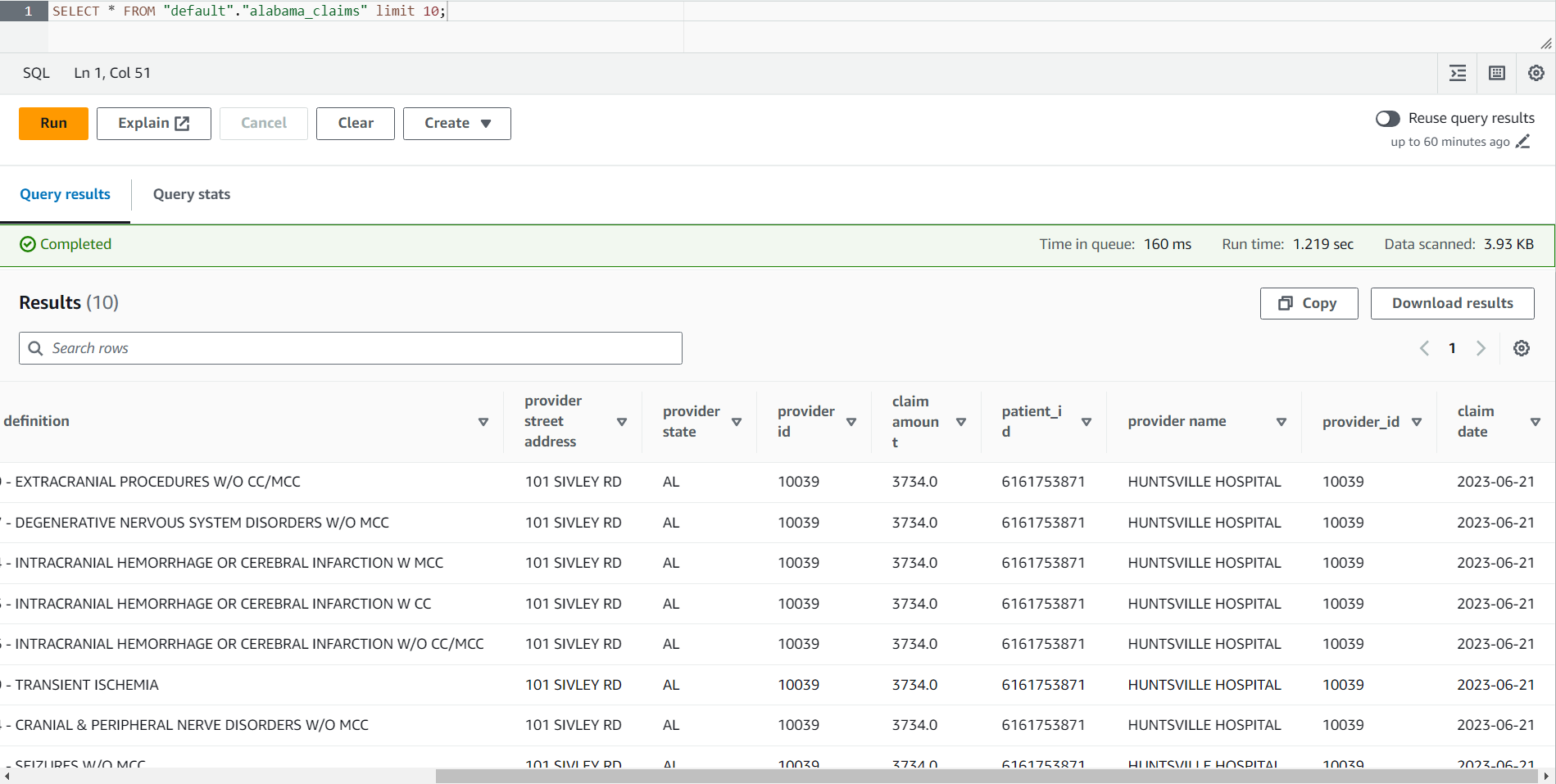
Puteți vedea în rezultatul lucrării că datele au fost curățate de rețeta DataBrew și îmbogățite prin alăturarea AWS Glue Studio.
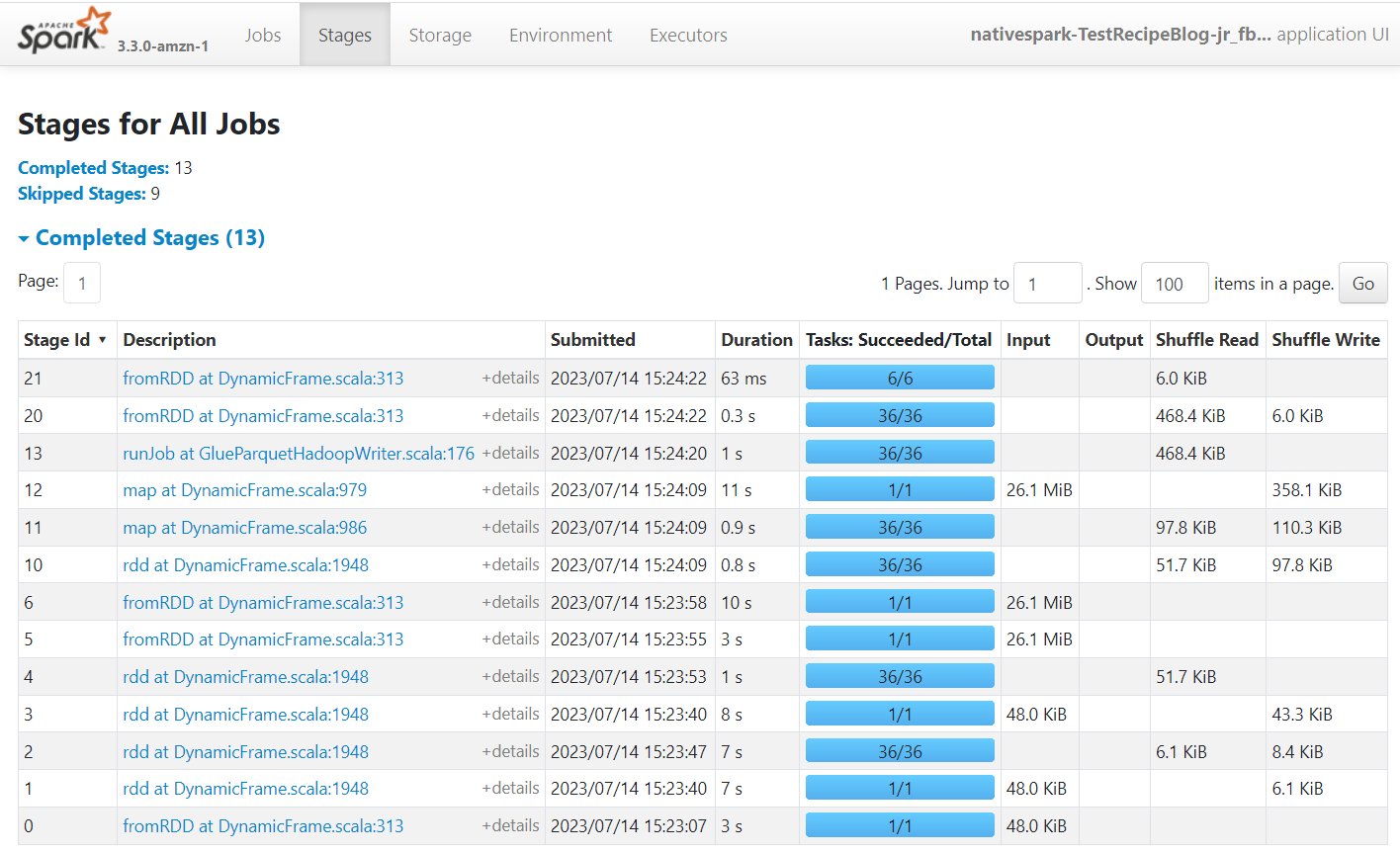
Apache Spark este motorul care rulează joburile create pe AWS Glue Studio. Folosind interfața de utilizare Spark pe jurnalele de evenimente pe care le produce, puteți vedea informații despre planul și rularea jobului, ceea ce vă poate ajuta să înțelegeți cum funcționează jobul dvs. și potențialele blocaje ale performanței. De exemplu, pentru această lucrare pe un set de date mare, l-ați putea folosi pentru a compara impactul filtrării explicite a stării furnizorului înainte de a face unirea sau pentru a identifica dacă puteți beneficia de adăugarea unei transformări Autobalance pentru a îmbunătăți paralelismul.
În mod implicit, jobul va stoca jurnalele de evenimente Apache Spark sub cale s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. Pentru a vizualiza joburile, trebuie să instalați un server de istoric folosind una dintre metodele disponibile.
A curăța
Dacă nu mai aveți nevoie de această soluție, puteți șterge fișierele generate pe Amazon S3, tabelul creat de job, rețeta DataBrew și jobul AWS Glue.
Concluzie
În această postare, am arătat cum puteți utiliza AWS DataBrew pentru a crea o rețetă utilizând editorul interactiv furnizat și apoi folosiți rețeta publicată ca parte a unui job ETL vizual AWS Glue Studio. Am inclus câteva exemple de sarcini obișnuite care sunt necesare la pregătirea datelor și la ingerarea datelor în tabelele AWS Glue Catalog.
Acest exemplu a folosit o singură rețetă în lucrarea vizuală, dar este posibil să folosiți mai multe rețete în diferite părți ale procesului ETL, precum și reutilizarea aceleiași rețete pentru mai multe lucrări.
Aceste soluții AWS Glue vă permit să creați în mod eficient conducte ETL avansate, care sunt ușor de construit și întreținut, totul fără a scrie niciun cod. Puteți începe să creați soluții care combină ambele instrumente astăzi.
Despre autori
 Mihail Smirnov este inginer senior software dezvoltător în echipa AWS Glue și face parte din echipa de dezvoltare AWS Glue DataBrew. În afara muncii, interesele sale includ să învețe să cânte la chitară și să călătorească cu familia.
Mihail Smirnov este inginer senior software dezvoltător în echipa AWS Glue și face parte din echipa de dezvoltare AWS Glue DataBrew. În afara muncii, interesele sale includ să învețe să cânte la chitară și să călătorească cu familia.
 Gonzalo Herreros este un arhitect senior Big Data în echipa AWS Glue. Cu sediul în Dublin, Irlanda, el ajută clienții să reușească cu soluții de date mari bazate pe AWS Glue. În timpul liber, îi plac jocurile de societate și ciclismul.
Gonzalo Herreros este un arhitect senior Big Data în echipa AWS Glue. Cu sediul în Dublin, Irlanda, el ajută clienții să reușească cu soluții de date mari bazate pe AWS Glue. În timpul liber, îi plac jocurile de societate și ciclismul.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. Automobile/VE-uri, carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- BlockOffsets. Modernizarea proprietății de compensare a mediului. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- :are
- :este
- :nu
- $UP
- 10
- 100
- 12
- 15%
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- Capabil
- Despre Noi
- acceptabil
- admis
- acces
- Cont
- Acțiune
- curent
- adăuga
- adăugat
- adăugare
- plus
- adresa
- avansat
- După
- Alabama
- TOATE
- permite
- de asemenea
- Amazon
- Amazon Web Services
- Sume
- an
- analiști
- și
- Orice
- Apache
- Apache Spark
- aplicație
- Aplică
- SUNT
- AS
- asociate
- At
- autor
- Auto
- Automat
- disponibil
- AWS
- AWS Adeziv
- înapoi
- bazat
- BE
- înainte
- fiind
- beneficia
- Beneficiile
- Mare
- Datele mari
- necompletat
- bord
- Consiliul de Jocuri
- marcajele
- atât
- Aduce
- browser-ul
- construi
- dar
- by
- CAN
- capacități
- caz
- catalog
- Celule
- centralizat
- Schimbare
- Modificări
- caractere
- copil
- alegere
- Alege
- pretinde
- creanțe
- cod
- Coloană
- Coloane
- combina
- venire
- Comun
- comparaţie
- Completă
- componente
- calculator
- condiție
- Configuraţie
- Lua în considerare
- constă
- Consoleze
- context
- converti
- convertit
- corecta
- Corespunzător
- A costat
- ar putea
- crea
- a creat
- Crearea
- creaţie
- personalizat
- clienţii care
- de date
- Pregătirea datelor
- de prelucrare a datelor
- calitatea datelor
- Baza de date
- seturi de date
- Data
- Date
- zi
- afacere
- decide
- decizie
- Mod implicit
- demonstra
- descriere
- dorit
- detaliat
- detalii
- dev
- Dezvoltare
- echipă de dezvoltare
- FĂCUT
- diferit
- distinct
- distribuire
- do
- Nu
- face
- Dolar
- dubla
- Picătură
- Dublin
- fiecare
- uşor
- editor
- efect
- în mod eficient
- permite
- capăt
- Motor
- inginer
- îmbogățit
- îmbogățitor
- Intrați
- eroare
- esenţial
- Eter (ETH)
- evalua
- Chiar
- eveniment
- Fiecare
- in fiecare zi
- exemplu
- exemple
- existent
- suplimentar
- extrage
- familie
- departe
- DESCRIERE
- puțini
- Domenii
- Fișier
- Fişiere
- umple
- filtru
- filtrare
- În cele din urmă
- First
- a urmat
- următor
- Pentru
- format
- din
- mai mult
- Jocuri
- generată
- Da
- mai mare
- Avea
- he
- ajutor
- ajută
- aici
- lui
- istorie
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- IAM
- ID
- identificat
- identifica
- Identitate
- if
- Impactul
- îmbunătăţi
- îmbunătățiri
- in
- include
- inclus
- Inclusiv
- indicată
- intrare
- perspective
- instala
- instanță
- integrate
- integrare
- interactiv
- interes
- interese
- interfaţă
- în
- introdus
- intuitiv
- Irlanda
- probleme de
- IT
- ESTE
- Loc de munca
- Locuri de munca
- alătura
- alăturat
- jpg
- JSON
- doar
- A pastra
- Cheie
- cunoştinţe
- mare
- mai mare
- cea mai mare
- Nume
- mai tarziu
- Ultimele
- învăţare
- Părăsi
- ca
- Probabil
- LINK
- listat
- încărca
- locaţie
- logică
- mai lung
- menține
- face
- FACE
- manual
- Meci
- medical
- Meniu
- metodă
- Metode
- Metrici
- minute
- dispărut
- monitor
- mai mult
- multiplu
- trebuie sa
- nume
- Navigaţi
- Navigare
- Nevoie
- necesar
- nevoilor
- Nou
- Nu.
- nod
- Înștiințare..
- acum
- număr
- of
- on
- ONE
- afară
- deschide
- Optimizați
- Opțiune
- Opţiuni
- or
- comandă
- Altele
- al nostru
- producție
- exterior
- peste
- global
- pâine
- parte
- piese
- cale
- performanță
- efectuarea
- permisiune
- permisiuni
- plan
- Plato
- Informații despre date Platon
- PlatoData
- Joaca
- posibil
- Post
- potenţial
- pregătire
- Anunţ
- Previews
- proces
- prelucrare
- produce
- proiect
- proprietăţi
- prevăzut
- furnizorul
- furnizori
- furnizează
- Publicare
- publica
- publicat
- scop
- scopuri
- calitate
- Citate
- într-adevăr
- rezonabil
- reţetă
- Recipes, Romania
- reduce
- reflecta
- regiune
- înregistrare
- scoate
- înlocui
- solicitat
- necesar
- cerință
- respectiv
- REST
- rezultat
- REZULTATE
- reutilizarea
- revizuiască
- Rol
- Alerga
- ruleaza
- acelaşi
- Economisiți
- Scară
- scalare
- Caută
- Al doilea
- Secțiune
- vedea
- vedere
- selectate
- distinct
- Servicii
- sesiune
- set
- setări
- să
- a arătat
- indicat
- semna
- semnificativ
- simplu
- singur
- Mărimea
- mic
- So
- până acum
- Software
- soluţie
- soluţii
- unele
- Sursă
- Surse
- Spaţiu
- Scânteie
- special
- specific
- specificată
- SQL
- Începe
- Pornire
- Stat
- Declarație
- statistică
- Pas
- paşi
- depozitare
- stoca
- simplu
- Şir
- studio
- ulterior
- reuși
- astfel de
- potrivit
- REZUMAT
- sigur
- sintetic
- tabel
- Lua
- Ţintă
- sarcini
- echipă
- testat
- acea
- Sursa
- Statul
- Lor
- apoi
- Acolo.
- acest
- trei
- timp
- la
- astăzi
- instrument
- Unelte
- top
- urmări
- Transforma
- Transformare
- transformări
- Traveling
- Două
- tip
- ui
- în
- înţelege
- Actualizează
- actualizat
- URL-ul
- utilizabil
- utilizare
- carcasa de utilizare
- utilizat
- utilizatorii
- utilizări
- folosind
- VALIDA
- valoare
- Valori
- verifica
- versiune
- Vizualizare
- vizibil
- vrea
- a fost
- modalități de
- we
- web
- servicii web
- BINE
- au fost
- cand
- care
- voi
- cu
- fără
- Apartamente
- lucrător
- muncitorii
- flux de lucru
- ar
- scrie
- scris
- tu
- Ta
- zephyrnet
- Zip