Ca practic toți clienții, doriți să cheltuiți cât mai puțin posibil, în timp ce obțineți cea mai bună performanță posibilă. Aceasta înseamnă că trebuie să acordați atenție raportului preț-performanță. Cu Amazon RedShift, poți să-ți iei tortul și să-l mănânci și tu! Amazon Redshift oferă un cost pe utilizator de până la 4.9 ori mai mic și o performanță preț-performanță de până la 7.9 ori mai bună decât alte depozite de date în cloud pe sarcini de lucru din lumea reală, folosind tehnici avansate, cum ar fi scalarea simultană, pentru a susține sute de utilizatori concurenți, codificare îmbunătățită a șirurilor pentru performanță mai rapidă a interogărilor , și Amazon Redshift fără server îmbunătățiri de performanță. Citiți mai departe pentru a înțelege de ce contează prețul-performanță și cum Amazon Redshift preț-performanță este o măsură a cât costă obținerea unui anumit nivel de performanță a sarcinii de lucru, și anume rentabilitatea investiției (rentabilitatea investiției).
Deoarece atât prețul, cât și performanța intră în calculul preț-performanță, există două moduri de a gândi la preț-performanță. Prima modalitate este de a menține prețul constant: dacă aveți 1 USD de cheltuit, câtă performanță obțineți de la depozitul dvs. de date? O bază de date cu un raport preț-performanță mai bun va oferi performanțe mai bune pentru fiecare dolar cheltuit. Prin urmare, atunci când mențineți prețul constant atunci când comparați două depozite de date care costă același, baza de date cu o performanță preț-preț mai bună va rula interogările dvs. mai rapid. Al doilea mod de a privi raportul preț-performanță este de a menține performanța constantă: dacă aveți nevoie ca volumul de muncă să se termine în 10 minute, cât va costa? O bază de date cu un preț-performanță mai bun îți va rula volumul de lucru în 10 minute la un cost mai mic. Prin urmare, atunci când mențineți performanța constantă atunci când comparați două depozite de date care sunt dimensionate pentru a oferi aceeași performanță, baza de date cu un preț-performanță mai bun va costa mai puțin și vă va economisi bani.
În cele din urmă, un alt aspect important al raportului preț-performanță este predictibilitatea. A ști cât va costa depozitul dvs. de date pe măsură ce crește numărul de utilizatori ai depozitului de date este crucial pentru planificare. Nu numai că ar trebui să ofere cel mai bun preț-performanță astăzi, ci și să se extindă în mod previzibil și să ofere cel mai bun preț-performanță pe măsură ce se adaugă mai mulți utilizatori și încărcături de lucru. Un depozit de date ideal ar trebui să aibă scară liniară—scalarea depozitului de date pentru a oferi de două ori mai mult debitul de interogări ar trebui, în mod ideal, să coste de două ori mai mult (sau mai puțin).
În această postare, împărtășim rezultatele de performanță pentru a ilustra modul în care Amazon Redshift oferă un preț-performanță semnificativ mai bun în comparație cu depozitele de date alternative de top. Aceasta înseamnă că, dacă cheltuiți aceeași sumă pe Amazon Redshift ca și pe unul dintre aceste alte depozite de date, veți obține performanțe mai bune cu Amazon Redshift. Alternativ, dacă dimensionați clusterul Redshift pentru a oferi aceeași performanță, veți vedea costuri mai mici în comparație cu aceste alternative.
Preț-performanță pentru sarcinile de lucru din lumea reală
Puteți utiliza Amazon Redshift pentru a alimenta o diversitate foarte largă de sarcini de lucru, de la procesarea în loturi a rapoartelor bazate pe extragere, transformare și încărcare (ETL) complexe și analize de streaming în timp real până la tablouri de bord de business intelligence (BI) cu latență redusă care trebuie să deservească sute sau chiar mii de utilizatori în același timp, cu timpi de răspuns sub secunde și tot ce se află între ele. Una dintre modalitățile prin care îmbunătățim continuu raportul preț-performanță pentru clienții noștri este să revizuim în mod constant telemetria performanței software și hardware din flota Redshift, căutând oportunități și cazuri de utilizare pentru clienți în care putem îmbunătăți și mai mult performanța Amazon Redshift.
Câteva exemple recente de optimizări ale performanței determinate de telemetria flotei includ:
- Optimizări ale interogărilor șirurilor – Analizând modul în care Amazon Redshift a procesat diferite tipuri de date în flota Redshift, am constatat că optimizarea interogărilor cu un număr mare de șiruri ar aduce beneficii semnificative sarcinilor de lucru ale clienților noștri. (Discutăm acest lucru în detaliu mai târziu în această postare.)
- Vizualizări automatizate materializate – Am descoperit că clienții Amazon Redshift execută adesea multe interogări care au modele comune de subinterogare. De exemplu, mai multe interogări diferite pot uni aceleași trei tabele folosind aceeași condiție de îmbinare. Amazon Redshift este acum capabil să creeze și să mențină automat vizualizări materializate și apoi să rescrie în mod transparent interogări pentru a utiliza vizualizările materializate folosind programul învățat automat. vizualizare automatizată materializată funcția autonomics în Amazon Redshift. Când sunt activate, vizualizările materializate automatizate pot crește în mod transparent performanța interogărilor pentru interogări repetitive fără nicio intervenție a utilizatorului. (Rețineți că vizualizările materializate automatizate nu au fost utilizate în niciunul dintre rezultatele de referință discutate în această postare).
- Sarcini de lucru cu concurență ridicată – Un caz de utilizare în creștere pe care îl vedem este utilizarea Amazon Redshift pentru a servi sarcini de lucru asemănătoare tablourilor de bord. Aceste sarcini de lucru sunt caracterizate de timpi de răspuns la interogări doriti de secunde cu o singură cifră sau mai puțin, cu zeci sau sute de utilizatori concurenți care execută interogări simultan, cu un model de utilizare înțepător și adesea imprevizibil. Exemplul prototip al acestui lucru este un tablou de bord BI susținut de Amazon Redshift, care are o creștere a traficului luni dimineața, când un număr mare de utilizatori își încep săptămâna.
În special, sarcinile de lucru cu concurență ridicată au o aplicabilitate foarte largă: majoritatea sarcinilor de lucru din depozitul de date funcționează în mod simultan și nu este neobișnuit ca sute sau chiar mii de utilizatori să execute interogări pe Amazon Redshift în același timp. Amazon Redshift a fost conceput pentru a menține timpii de răspuns la interogări predictibili și rapidi. Redshift Serverless face acest lucru automat pentru dvs., adăugând și eliminând calcularea după cum este necesar pentru a menține timpii de răspuns la interogări rapid și previzibil. Aceasta înseamnă că un tablou de bord susținut de Redshift Serverless care se încarcă rapid atunci când este accesat de unul sau doi utilizatori va continua să se încarce rapid chiar și atunci când mulți utilizatori îl încarcă în același timp.
Pentru a simula acest tip de sarcină de lucru, am folosit un benchmark derivat din TPC-DS cu un set de date de 100 GB. TPC-DS este un standard de referință în industrie, care include o varietate de interogări tipice din depozitul de date. La această scară relativ mică de 100 GB, interogările din acest benchmark rulează pe Redshift Serverless într-o medie de câteva secunde, ceea ce este reprezentativ pentru ceea ce se așteaptă utilizatorii care încarcă un tablou de bord interactiv BI. Am rulat între 1-200 de teste concurente ale acestui benchmark, simulând între 1-200 de utilizatori care încearcă să încarce un tablou de bord în același timp. De asemenea, am repetat testul împotriva mai multor depozite de date în cloud alternative populare care acceptă și scalarea automată (dacă sunteți familiarizat cu postarea Amazon Redshift își continuă liderul preț-performanță, nu am inclus concurentul A deoarece nu acceptă scalarea automată). Am măsurat timpul mediu de răspuns la interogare, adică cât de mult ar aștepta un utilizator ca interogările să se termine (sau să se încarce tabloul de bord). Rezultatele sunt prezentate în graficul următor.
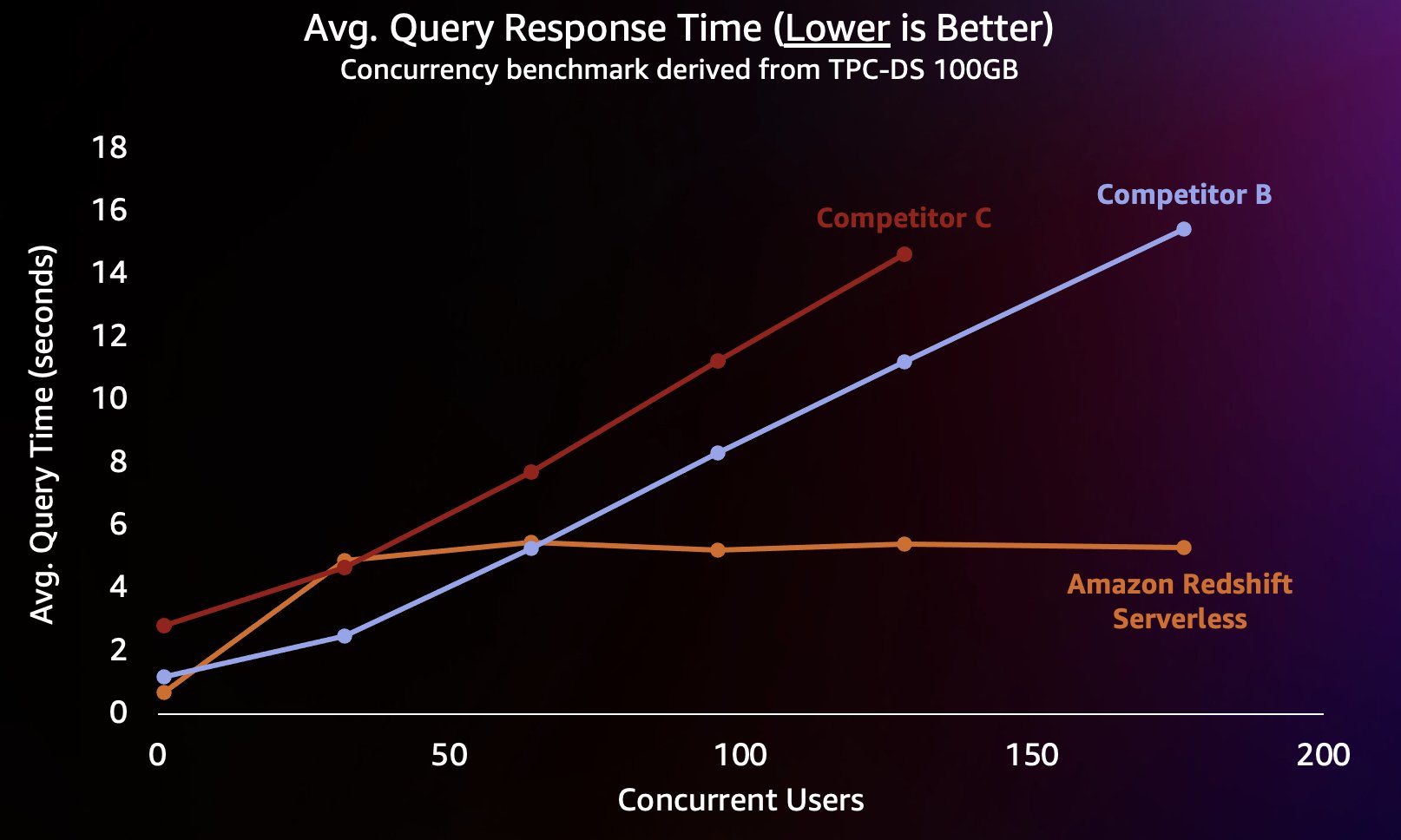
Competitorul B se scalează bine până la aproximativ 64 de interogări concurente, moment în care nu este în măsură să ofere calcule suplimentare, iar interogările încep să intre în coadă, ceea ce duce la timpi de răspuns la interogări mai mari. Deși Competitor C este capabil să se scaleze automat, se scalează la un debit mai mic al interogărilor decât Amazon Redshift și Competitor B și nu este capabil să mențină un timp de execuție scăzut al interogărilor. În plus, nu acceptă interogări de așteptare atunci când epuizează calculul, ceea ce îl împiedică să crească peste aproximativ 128 de utilizatori concurenți. Trimiterea de interogări suplimentare dincolo de aceasta este respinsă de sistem.
Aici, Redshift Serverless este capabil să mențină timpul de răspuns la interogare relativ consistent, la aproximativ 5 secunde, chiar și atunci când sute de utilizatori execută interogări în același timp. Timpii medii de răspuns la interogări pentru concurenții B și C cresc constant pe măsură ce încărcarea depozitelor crește, ceea ce duce la nevoia utilizatorilor de a aștepta mai mult (până la 16 secunde) pentru ca interogările lor să revină atunci când depozitul de date este ocupat. Aceasta înseamnă că, dacă un utilizator încearcă să reîmprospăteze un tablou de bord (care poate chiar trimite mai multe interogări simultane atunci când este reîncărcat), Amazon Redshift ar putea menține timpii de încărcare a tabloului de bord mult mai consistenti, chiar dacă tabloul de bord este încărcat de zeci sau sute de alte persoane. utilizatorii în același timp.
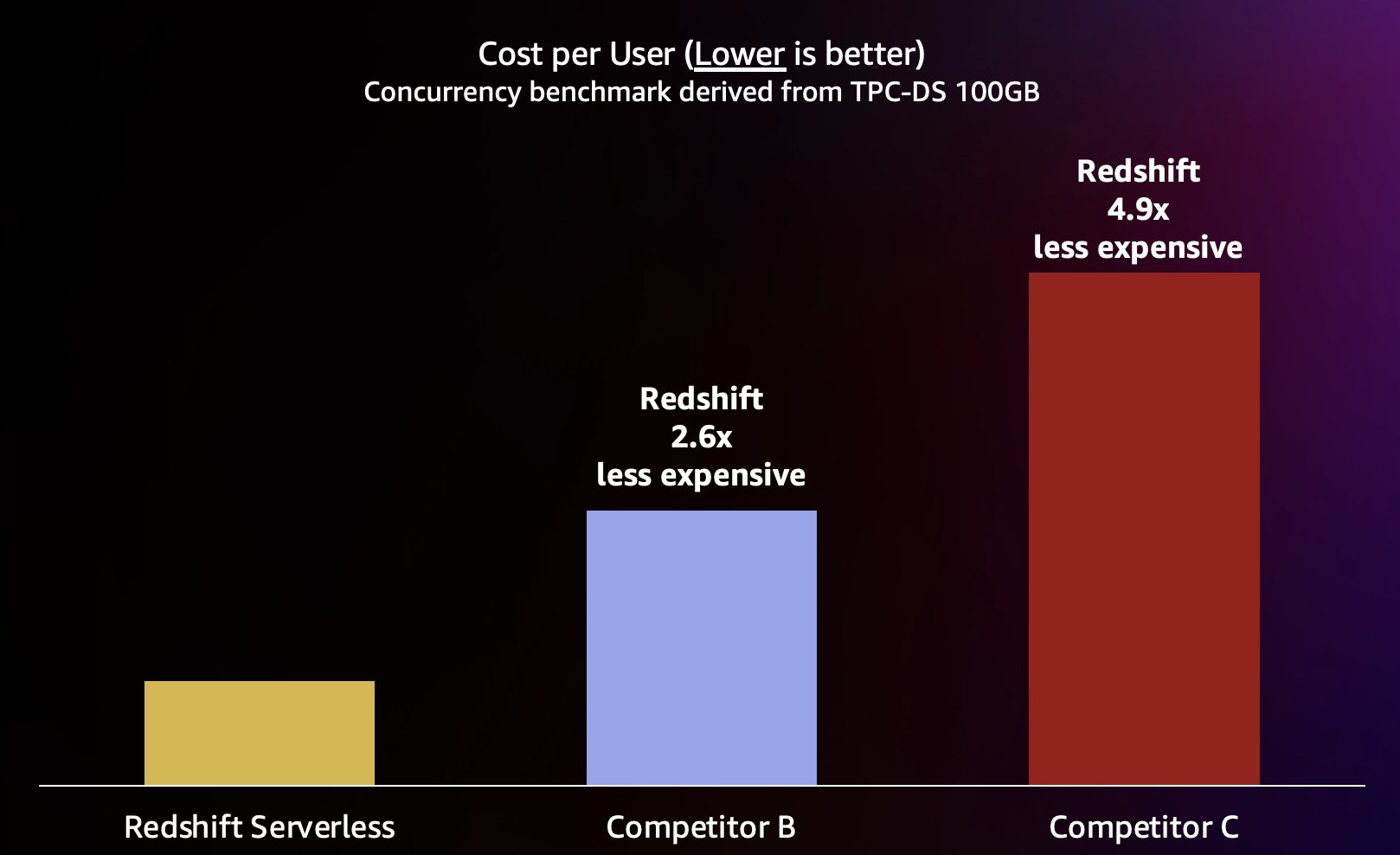
Deoarece Amazon Redshift este capabil să ofere un debit foarte mare de interogări pentru interogări scurte (cum am scris despre Amazon Redshift își continuă liderul preț-performanță), este, de asemenea, capabil să gestioneze aceste concurențe mai mari atunci când se extinde mai eficient și, prin urmare, la un cost semnificativ mai mic. Pentru a cuantifica acest lucru, ne uităm la preț-performanță folosind publicat prețuri la cerere pentru fiecare dintre depozitele din testul precedent, prezentate în graficul următor. Este demn de remarcat faptul că folosirea Instanțe rezervate (RI), în special RI-urile pe 3 ani achiziționate cu opțiunea de plată în avans, au cel mai mic cost pentru a rula Amazon Redshift pe clustere Provisioned, rezultând cea mai bună performanță-preț relativă în comparație cu opțiunile la cerere sau cu alte opțiuni RI.

Deci, Amazon Redshift nu numai că este capabil să ofere performanțe mai bune la concurențe mai mari, ci și poate face acest lucru la un cost semnificativ mai mic. Fiecare punct de date din graficul preț-performanță este echivalent cu costul de rulare a benchmarkului la concurența specificată. Deoarece prețul-performanță este liniară, putem împărți costul pentru rularea benchmark-ului la orice concurență la concurență (numărul de utilizatori concurenți din acest grafic) pentru a ne spune cât costă adăugarea fiecărui utilizator nou pentru acest benchmark special.
Rezultatele precedente sunt ușor de reprodus. Toate interogările utilizate în benchmark sunt disponibile în nostru GitHub depozit iar performanța este măsurată prin lansarea unui depozit de date, activarea Concurrency Scaling pe Amazon Redshift (sau caracteristica corespunzătoare de scalare automată pe alte depozite), încărcarea datelor din cutie (fără reglare manuală sau configurare specifică bazei de date) și apoi rularea unui flux simultan de interogări la concurențe de la 1 la 200 în pași de 32 pe fiecare depozit de date. Același repo GitHub face referire la date TPC-DS pregenerate (și nemodificate). Serviciul Amazon de stocare simplă (Amazon S3) la diferite scale folosind kitul oficial de generare de date TPC-DS.
Optimizarea sarcinilor de lucru grele de șiruri
După cum am menționat mai devreme, echipa Amazon Redshift caută în permanență noi oportunități pentru a oferi clienților noștri un preț-performanță și mai bun. O îmbunătățire pe care am lansat-o recent și anume îmbunătățirea semnificativă a performanței este o optimizare care accelerează performanța interogărilor asupra datelor șirurilor. De exemplu, ați putea dori să găsiți veniturile totale generate de magazinele de vânzare cu amănuntul situate în New York City cu o interogare precum SELECT sum(price) FROM sales WHERE city = ‘New York’. Această interogare aplică un predicat peste șir de date (city = ‘New York’). După cum vă puteți imagina, procesarea datelor șirurilor este omniprezentă în aplicațiile de depozit de date.
Pentru a cuantifica cât de des accesează sarcinile de lucru ale clienților șiruri, am efectuat o analiză detaliată a utilizării tipului de date șir folosind telemetria flotei de zeci de mii de clustere de clienți gestionate de Amazon Redshift. Analiza noastră indică faptul că în 90% dintre clustere, coloanele șiruri constituie cel puțin 30% din toate coloanele, iar în 50% dintre grupuri, coloanele șiruri constituie cel puțin 50% din toate coloanele. În plus, majoritatea interogărilor rulează pe platforma de depozit de date cloud Amazon Redshift accesează cel puțin o coloană de șir. Un alt factor important este acela că datele șirurilor au foarte adesea cardinalitate scăzută, ceea ce înseamnă că coloanele conțin un set relativ mic de valori unice. De exemplu, deși an orders tabelul care reprezintă datele vânzărilor poate conține miliarde de rânduri, an order_status coloana din acel tabel poate conține doar câteva valori unice pe acele miliarde de rânduri, cum ar fi pending, in process, și completed.
În momentul scrierii acestui articol, majoritatea coloanelor cu șiruri din Amazon Redshift sunt comprimate cu LZO or ZSTD algoritmi. Aceștia sunt algoritmi buni de compresie de uz general, dar nu sunt proiectați pentru a profita de datele șirurilor de cardinalitate scăzută. În special, ele necesită ca datele să fie decomprimate înainte de a fi operate și sunt mai puțin eficiente în utilizarea lățimii de bandă a memoriei hardware. Pentru datele cu cardinalitate scăzută, există un alt tip de codificare care poate fi mai optimă: BYTEDICT. Această codificare folosește o schemă de codificare a dicționarului care permite motorului bazei de date să funcționeze direct peste date comprimate, fără a fi nevoie să le decomprimați mai întâi.
Pentru a îmbunătăți și mai mult raportul preț-performanță pentru sarcinile de lucru grele de șiruri, Amazon Redshift introduce acum îmbunătățiri suplimentare de performanță care accelerează scanările și evaluările predicatelor, peste coloanele de șiruri cu cardinalitate scăzută, care sunt codificate ca BYTEDICT, între 5 și 63 de ori mai rapid (vezi rezultatele în secțiunea următoare) în comparație cu codificări alternative de compresie, cum ar fi LZO sau ZSTD. Amazon Redshift realizează această îmbunătățire a performanței prin vectorizarea scanărilor pe coloane ușoare, eficiente din punct de vedere CPU, codificate BYTEDICT și cu cardinalitate scăzută. Aceste optimizări ale procesării șirurilor folosesc eficient lățimea de bandă a memoriei oferită de hardware-ul modern, permițând analiza în timp real asupra datelor șirurilor. Aceste capacități de performanță recent introduse sunt optime pentru coloanele de șir de cardinalitate scăzută (până la câteva sute de valori unice de șir).
Puteți beneficia automat de această nouă îmbunătățire a șirurilor de înaltă performanță prin activare optimizarea automată a tabelului în depozitul dvs. de date Amazon Redshift. Dacă nu aveți optimizarea automată a tabelelor activată pe tabelele dvs., puteți primi recomandări de la Consilier Amazon Redshift în consola Amazon Redshift pe adecvarea unei coloane de șir pentru codificarea BYTEDICT. De asemenea, puteți defini tabele noi care au coloane de șir de cardinalitate scăzută cu codificare BYTEDICT. Îmbunătățirile șirurilor din Amazon Redshift sunt acum disponibile în toate regiunile AWS unde Amazon Redshift este disponibil.
Rezultate de performanță
Pentru a măsura impactul asupra performanței al îmbunătățirilor noastre de șir, am generat un set de date de 10 TB (Tera Byte) care a constat din date de șir de cardinalitate scăzută. Am generat trei versiuni ale datelor utilizând șiruri scurte, medii și lungi, corespunzătoare celei de-a 25-a, 50-a și 75-a percentile de lungimi de șir din telemetria flotei Amazon Redshift. Am încărcat aceste date în Amazon Redshift de două ori, codificându-le într-un caz folosind compresia LZO și în altul folosind compresia BYTEDICT. În cele din urmă, am măsurat performanța interogărilor grele de scanare care returnează multe rânduri (90% din tabel), un număr mediu de rânduri (50% din tabel) și câteva rânduri (1% din tabel) peste aceste rânduri scăzute. -seturi de date șiruri de cardinalitate. Rezultatele performanței sunt rezumate în următorul grafic.

Interogările cu predicate care se potrivesc cu un procent ridicat de rânduri au înregistrat îmbunătățiri de 5-30 de ori cu noua codificare BYTEDICT vectorizată în comparație cu LZO, în timp ce interogările cu predicate care se potrivesc cu un procent mic de rânduri au înregistrat îmbunătățiri de 10-63 de ori în acest benchmark intern.
Redshift Serverless preț-performanță
Pe lângă rezultatele de performanță de concurență ridicată prezentate în această postare, am folosit și benchmark-ul Cloud Data Warehouse derivat din TPC-DS pentru a compara performanța preț-performanță a Redshift Serverless cu alte depozite de date folosind un set de date mai mare de 3TB. Am ales depozite de date cu prețuri similare, în acest caz cu 10% din 32 USD pe oră, folosind prețuri la cerere disponibile public. Aceste rezultate arată că, la fel ca instanțele Amazon Redshift RA3, Redshift Serverless oferă un preț-performanță mai bun în comparație cu alte depozite de date cloud de top. Ca întotdeauna, aceste rezultate pot fi replicate folosind scripturile noastre SQL din nostru GitHub depozit.

Vă încurajăm să încercați Amazon Redshift folosind propriul dvs dovada de concept sarcinile de lucru ca cea mai bună modalitate de a vedea cum Amazon Redshift poate satisface nevoile dvs. de analiză a datelor.
Găsiți cel mai bun preț-performanță pentru sarcinile dvs. de lucru
Benchmark-urile utilizate în această postare sunt derivate din standardul de referință TPC-DS din industrie și au următoarele caracteristici:
- Schema și datele sunt utilizate nemodificate din TPC-DS.
- Interogările sunt generate folosind kitul oficial TPC-DS cu parametrii de interogare generați utilizând semințele aleatorii implicite ale kitului TPC-DS. Variantele de interogare aprobate de TPC sunt utilizate pentru un depozit dacă depozitul nu acceptă dialectul SQL al interogării implicite TPC-DS.
- Testul include cele 99 de interogări TPC-DS SELECT. Nu include pași de întreținere și debit.
- Pentru testul de concurență unic de 3TB, au fost executate trei porțiuni de alimentare, iar cea mai bună rulare este luată pentru fiecare depozit de date.
- Preț-performanță pentru interogările TPC-DS este calculată ca cost pe oră (USD) înmulțit cu durata de execuție a benchmark-ului în ore, ceea ce este echivalent cu costul de rulare a benchmark-ului. Cel mai recent preț publicat la cerere este utilizat pentru toate depozitele de date și nu prețul pentru Instanțele rezervate, așa cum sa menționat mai devreme.
Numim acest lucru etalonul Cloud Data Warehouse și puteți reproduce cu ușurință rezultatele benchmark-urilor precedente folosind scripturile, interogările și datele disponibile în GitHub depozit. Este derivat din benchmark-urile TPC-DS descrise în această postare și, ca atare, nu este comparabilă cu rezultatele TPC-DS publicate, deoarece rezultatele testelor noastre nu sunt conforme cu specificațiile oficiale.
Concluzie
Amazon Redshift se angajează să ofere cel mai bun preț-performanță din industrie pentru cea mai mare varietate de sarcini de lucru. Redshift Serverless se scalează liniar cu cel mai bun (cel mai mic) preț-performanță, susținând sute de utilizatori concurenți, menținând în același timp timpi de răspuns la interogări consecvenți. Pe baza rezultatelor testelor discutate în această postare, Amazon Redshift are o performanță preț-performanță de până la 2.6 ori mai bună, la același nivel de concurență, comparativ cu cel mai apropiat concurent (competitorul B). După cum am menționat mai devreme, utilizarea Instanțelor rezervate cu opțiunea inițială de 3 ani vă oferă cel mai mic cost pentru a rula Amazon Redshift, rezultând o performanță relativă și mai bună a prețului comparativ cu prețul la cerere pe care l-am folosit în această postare. Abordarea noastră pentru îmbunătățirea continuă a performanței implică o combinație unică de obsesia clienților de a înțelege cazurile de utilizare ale clienților și blocajele de scalabilitate asociate acestora, împreună cu analiza continuă a datelor flotei pentru a identifica oportunitățile de a face optimizări semnificative ale performanței.
Fiecare sarcină de lucru are caracteristici unice, așa că, dacă abia ați început, a dovada de concept este cea mai bună modalitate de a înțelege cum Amazon Redshift vă poate reduce costurile, oferind în același timp performanțe mai bune. Când rulați propria dovadă a conceptului, este important să vă concentrați pe valorile potrivite: debitul de interogări (numărul de interogări pe oră), timpul de răspuns și raportul preț-performanță. Puteți lua o decizie bazată pe date rulând o dovadă de concept pe cont propriu sau cu asistență de la AWS sau a partener de integrare a sistemelor și consultanță.
Pentru a fi la curent cu cele mai recente evoluții din Amazon Redshift, urmați Ce este nou în Amazon Redshift Hrăni.
Despre autori
 Stefan Gromoll este inginer senior de performanță în echipa Amazon Redshift, unde este responsabil pentru măsurarea și îmbunătățirea performanței Redshift. În timpul liber, îi place să gătească, să se joace cu cei trei băieți ai săi și să taie lemne de foc.
Stefan Gromoll este inginer senior de performanță în echipa Amazon Redshift, unde este responsabil pentru măsurarea și îmbunătățirea performanței Redshift. În timpul liber, îi place să gătească, să se joace cu cei trei băieți ai săi și să taie lemne de foc.
 Ravi Animi este un lider senior de management de produs în echipa Amazon Redshift și gestionează mai multe domenii funcționale ale serviciului de depozit de date în cloud Amazon Redshift, inclusiv performanță, analiză spațială, asimilare în flux și strategii de migrare. Are experiență în baze de date relaționale, baze de date multidimensionale, tehnologii IoT, servicii de infrastructură de stocare și calcul și, mai recent, ca fondator de startup, folosind AI/învățare profundă, viziune computerizată și robotică.
Ravi Animi este un lider senior de management de produs în echipa Amazon Redshift și gestionează mai multe domenii funcționale ale serviciului de depozit de date în cloud Amazon Redshift, inclusiv performanță, analiză spațială, asimilare în flux și strategii de migrare. Are experiență în baze de date relaționale, baze de date multidimensionale, tehnologii IoT, servicii de infrastructură de stocare și calcul și, mai recent, ca fondator de startup, folosind AI/învățare profundă, viziune computerizată și robotică.
 Aamer Shah este inginer senior în echipa Amazon Redshift Service.
Aamer Shah este inginer senior în echipa Amazon Redshift Service.
 Sanket Hase este manager de dezvoltare software în echipa Amazon Redshift Service.
Sanket Hase este manager de dezvoltare software în echipa Amazon Redshift Service.
 Orestis Polychroniou este inginer principal în echipa Amazon Redshift Service.
Orestis Polychroniou este inginer principal în echipa Amazon Redshift Service.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :are
- :este
- :nu
- :Unde
- $UP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- Capabil
- Despre Noi
- Accelerează
- acces
- accesate
- Realizeaza
- peste
- adăugat
- adăugare
- plus
- Suplimentar
- avansat
- Avantaj
- oferite
- împotriva
- algoritmi
- TOATE
- permite
- de asemenea
- alternativă
- alternative
- Cu toate ca
- mereu
- Amazon
- Amazon Web Services
- sumă
- an
- analiză
- Google Analytics
- analiza
- și
- O alta
- Orice
- aplicatii
- Aplicarea
- abordare
- SUNT
- domenii
- în jurul
- AS
- aspect
- asociate
- At
- atenţie
- Auto
- Automata
- Automat
- în mod automat
- disponibil
- in medie
- AWS
- b
- Lățime de bandă
- bazat
- BE
- deoarece
- înainte
- începe
- fiind
- Benchmark
- valori de referință
- beneficia
- CEL MAI BUN
- Mai bine
- între
- Dincolo de
- miliarde
- atât
- blocaje
- Cutie
- aduce
- larg
- afaceri
- business intelligence
- ocupat
- dar
- by
- CAKE
- calculată
- calcul
- apel
- CAN
- capacități
- caz
- cazuri
- Caracteristici
- caracterizat
- Diagramă
- mărunt
- a ales
- Oraș
- Cloud
- Grup
- Coloană
- Coloane
- combinaţie
- comise
- Comun
- comparabil
- comparaţie
- comparație
- compararea
- concurent
- concurenți
- complex
- se conforma
- Calcula
- calculator
- Computer Vision
- concept
- concurent
- condiție
- efectuat
- consistent
- Consoleze
- constant
- mereu
- constitui
- consultant
- conţine
- continuu
- continua
- continuă
- continuu
- continuu
- gătit
- Corespunzător
- A costat
- Cheltuieli
- cuplat
- crea
- crucial
- client
- clienţii care
- tablou de bord
- tablouri de bord
- de date
- analiza datelor
- Analiza datelor
- de prelucrare a datelor
- set de date
- depozit de date
- depozite de date
- Pe bază de date
- Baza de date
- baze de date
- seturi de date
- Data
- decizie
- Mod implicit
- defini
- livra
- livrarea
- Oferă
- Derivat
- descris
- proiectat
- dorit
- detaliu
- detaliat
- Dezvoltare
- evoluții
- diferit
- direct
- discuta
- discutat
- Diversitate
- împărţi
- do
- face
- Nu
- Dont
- condus
- fiecare
- Mai devreme
- cu ușurință
- mânca
- Eficace
- eficient
- eficient
- activat
- permițând
- încuraja
- Motor
- inginer
- sporită
- sporire
- îmbunătățiri
- Intrați
- Echivalent
- mai ales
- Eter (ETH)
- evaluări
- Chiar
- tot
- exemplu
- exemple
- aștepta
- experienţă
- extrage
- factor
- familiar
- departe
- FAST
- mai repede
- Caracteristică
- puțini
- În cele din urmă
- Găsi
- termina
- First
- FLOTA
- Concentra
- urma
- următor
- Pentru
- găsit
- fondator
- din
- funcțional
- mai mult
- scop general
- generată
- generaţie
- obține
- obtinerea
- GitHub
- oferă
- merge
- bine
- În creştere
- creste
- manipula
- Piese metalice
- Avea
- având în
- he
- Înalt
- superior
- lui
- deţine
- deținere
- oră
- ORE
- Cum
- HTML
- http
- HTTPS
- sută
- sute
- ideal
- ideal
- identifica
- if
- ilustra
- imagina
- Impactul
- important
- aspect important
- îmbunătăţi
- îmbunătățit
- îmbunătățire
- îmbunătățiri
- îmbunătățirea
- in
- include
- include
- Inclusiv
- Crește
- a crescut
- Creșteri
- indică
- industria
- Infrastructură
- instanță
- cazuri
- integrare
- Inteligență
- interactiv
- intern
- intervenţie
- în
- introdus
- introducerea
- investiţie
- implică
- IoT
- IT
- ESTE
- alătura
- jpg
- doar
- A pastra
- trusă
- Cunoaștere
- mare
- mai mare
- mai tarziu
- Ultimele
- cele mai recente dezvoltări
- a lansat
- lansare
- lider
- conducere
- învăţare
- cel mai puțin
- mai puțin
- Nivel
- categorie ușoară
- ca
- mic
- încărca
- încărcare
- loturile
- situat
- Lung
- mai lung
- Uite
- cautati
- Jos
- LOWER
- cel mai mic
- menține
- mentine
- întreținere
- Majoritate
- face
- gestionate
- administrare
- manager
- gestionează
- manual
- multe
- Meci
- materie
- Mai..
- sens
- mijloace
- măsura
- măsurat
- măsurare
- mediu
- Întâlni
- Memorie
- menționat
- ar putea
- migrațiune
- minute
- Modern
- luni
- bani
- mai mult
- În plus
- cele mai multe
- mult
- și anume
- Nevoie
- necesar
- nevoilor
- Nou
- New York
- New York City
- recent
- următor
- Nu.
- nota
- notat
- observând
- acum
- număr
- of
- oficial
- de multe ori
- on
- La cerere
- ONE
- afară
- funcionar
- operat
- Oportunităţi
- optimă
- optimizare
- optimizarea
- Opțiune
- Opţiuni
- or
- Altele
- al nostru
- afară
- peste
- propriu
- parametrii
- special
- Model
- modele
- Plătește
- plată
- pentru
- procent
- performanță
- planificare
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- joc
- Punct
- Popular
- posibil
- Post
- putere
- predictibil
- prezentat
- previne
- preţ
- de stabilire a prețurilor
- Principal
- prelucrate
- prelucrare
- Produs
- management de produs
- dovadă
- dovada de concept
- furniza
- public
- publicat
- cumparate
- interogări
- repede
- aleator
- Citeste
- lumea reală
- în timp real
- a primi
- recent
- recent
- Recomandări
- referințe
- regiuni
- Respins..
- relativ
- relativ
- eliminarea
- repetat
- repetitiv
- replicat
- Rapoarte
- reprezentant
- reprezentând
- necesita
- rezervat
- răspuns
- responsabil
- rezultând
- REZULTATE
- cu amănuntul
- reveni
- venituri
- revizuiască
- dreapta
- robotica
- ROI
- Alerga
- funcţionare
- ruleaza
- de vânzări
- acelaşi
- Economisiți
- văzut
- scalabilitate
- Scară
- cântare
- scalare
- scanări
- schemă
- script-uri
- Al doilea
- secunde
- Secțiune
- vedea
- sămânţă
- senior
- servi
- serverless
- serviciu
- Servicii
- set
- configurarea
- câteva
- Distribuie
- Pantaloni scurți
- să
- Arăta
- indicat
- semnificativ
- semnificativ
- asemănător
- simplu
- simultan
- singur
- Mărimea
- dimensionat
- mic
- So
- Software
- de dezvoltare de software
- spațial
- specificație
- specificată
- viteză
- petrece
- uzat
- cui
- SQL
- Începe
- început
- lansare
- şedere
- în mod constant
- paşi
- depozitare
- magazine
- simplu
- strategii
- curent
- de streaming
- Şir
- prezenta
- astfel de
- potrivire
- a sustine
- De sprijin
- sistem
- tabel
- Lua
- luate
- echipă
- tehnici de
- Tehnologii
- spune
- zeci
- test
- teste
- decât
- acea
- lor
- apoi
- Acolo.
- prin urmare
- Acestea
- ei
- crede
- acest
- aceste
- mii
- trei
- debit
- timp
- ori
- la
- astăzi
- Total
- trafic
- Transforma
- transparent
- încerca
- încercat
- De două ori
- Două
- tip
- Tipuri
- tipic
- omniprezent
- incapabil
- neobișnuit
- înţelege
- unic
- imprevizibil
- până la
- us
- Folosire
- USD
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- utilizări
- folosind
- Valori
- varietate
- diverse
- foarte
- vizualizari
- practic
- viziune
- aștepta
- vrea
- Depozit
- a fost
- Cale..
- modalități de
- we
- web
- servicii web
- săptămână
- BINE
- au fost
- Ce
- cand
- întrucât
- care
- în timp ce
- de ce
- larg
- voi
- cu
- în
- fără
- valoare
- ar
- scris
- scris
- York
- tu
- Ta
- zephyrnet