Pe măsură ce ingineria datelor devine din ce în ce mai complexă, organizațiile caută noi modalități de a-și eficientiza fluxurile de lucru de procesare a datelor. Mulți ingineri de date folosesc astăzi Apache Airflow pentru a construi, programa și monitoriza conductele de date.
Cu toate acestea, pe măsură ce volumul de date crește, gestionarea și scalarea acestor conducte poate deveni o sarcină descurajantă. Fluxuri de lucru gestionate de Amazon pentru Apache Airflow (Amazon MWAA) poate ajuta la simplificarea procesului de construire, rulare și gestionare a conductelor de date. Oferind Apache Airflow ca o platformă complet gestionată, Amazon MWAA le permite inginerilor de date să se concentreze pe construirea fluxurilor de lucru de date în loc să se preocupe de infrastructură.
Astăzi, întreprinderile și organizațiile au nevoie de modalități eficiente și rentabile de a procesa cantități mari de date. Amazon EMR fără server este o soluție rentabilă și scalabilă pentru procesarea datelor mari, care poate gestiona volume mari de date. Furnizorul Amazon din Apache Airflow vine cu operatori EMR Serverless și este deja inclus în Amazon MWAA, facilitând inginerilor de date să construiască conducte de procesare a datelor scalabile și fiabile. Puteți utiliza EMR Serverless pentru a rula joburi Spark pe date și puteți utiliza Amazon MWAA pentru a gestiona fluxurile de lucru și dependențele dintre aceste joburi. Această integrare poate ajuta, de asemenea, la reducerea costurilor prin scalarea automată a resurselor necesare procesării datelor.
Amazon Athena este un serviciu de analiză interactiv, fără server, construit pe framework-uri open-source, care acceptă formate open-table și fișiere. Puteți utiliza SQL standard pentru a interacționa cu datele. Athena, un serviciu de analiză fără server și interactiv, face acest lucru posibil fără a fi nevoie de a gestiona o infrastructură complexă.
În această postare, folosim Amazon MWAA, EMR Serverless și Athena pentru a construi o conductă completă de procesare a datelor end-to-end.
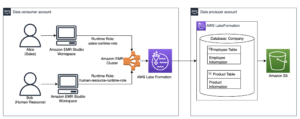
Prezentare generală a soluțiilor
Următoarea diagramă ilustrează arhitectura soluției.
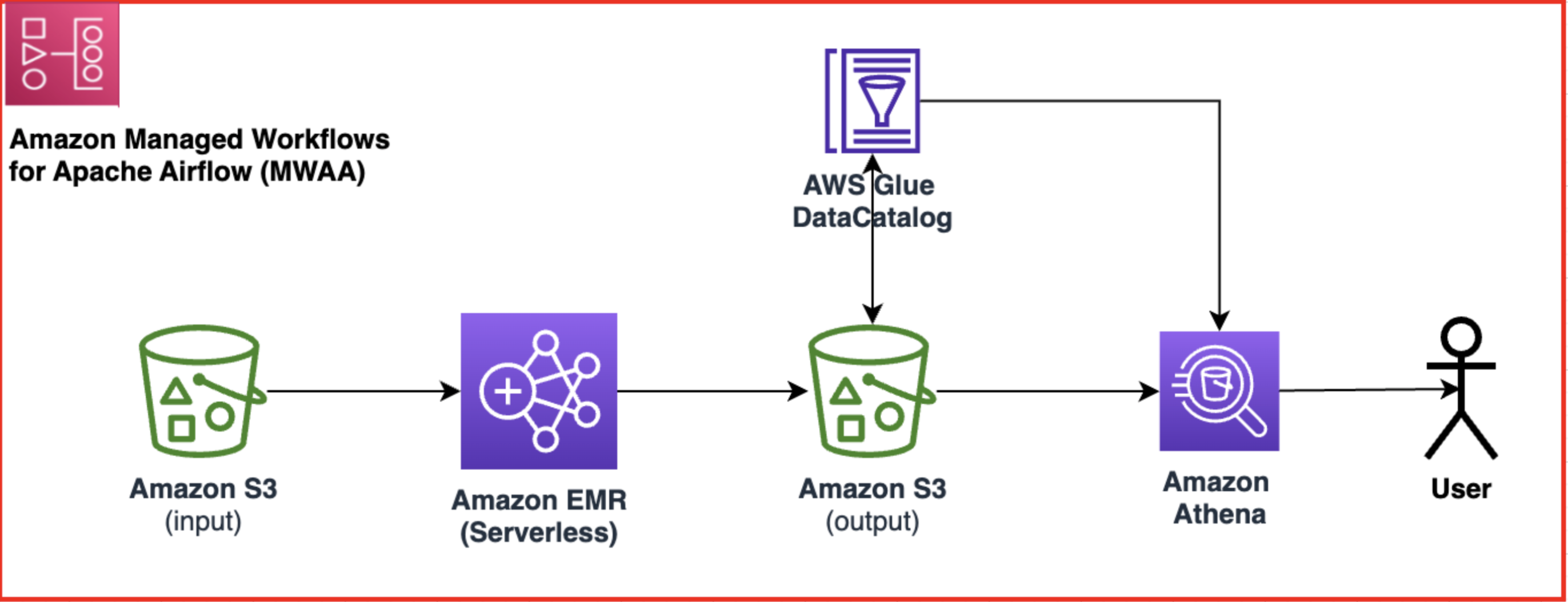
Fluxul de lucru include următorii pași:
- Creați un flux de lucru Amazon MWAA care preia date din intrarea dvs Serviciul Amazon de stocare simplă Găleată (Amazon S3)
- Utilizați EMR Serverless pentru a procesa datele stocate în Amazon S3. EMR Serverless crește sau reduce automat în funcție de volumul de lucru, astfel încât nu trebuie să vă faceți griji cu privire la furnizarea sau gestionarea vreunei infrastructuri.
- Utilizați EMR Serverless pentru a transforma datele utilizând codul PySpark și apoi stocați datele transformate înapoi în compartimentul dvs. S3.
- Utilizați Athena pentru a crea un tabel extern bazat pe setul de date S3 și rulați interogări pentru a analiza datele transformate. Athena folosește AWS Adeziv Catalog de date pentru a stoca metadatele tabelului.
Cerințe preliminare
Ar trebui să aveți următoarele condiții preliminare:
Pregătirea datelor
Pentru a ilustra utilizarea joburilor EMR Serverless cu Apache Spark prin Amazon MWAA și validarea datelor folosind Athena, folosim setul de date de taxi NYC disponibil public. Descărcați următoarele seturi de date pe mașina dvs. locală:
- Înregistrări de călătorie cu taxiul verde și cu taxiul galben – Înregistrări de călătorie pentru taxiurile galbene și verzi, care includ informații precum datele și orele de preluare și predare, locații, distanțe de călătorie și tipuri de plată. În exemplul nostru, folosim cele mai recente fișiere Parquet pentru 2022.
- Set de date pentru căutarea zonei Taxi – Un set de date care furnizează ID-urile locației și detaliile zonei corespunzătoare pentru taxiuri.
În pașii următori, încărcăm aceste seturi de date pe Amazon S3.
Creați resurse de soluție
Această secțiune prezintă pașii pentru configurarea procesării și transformării datelor.
Creați o aplicație EMR Serverless
Puteți crea una sau mai multe aplicații EMR Serverless care utilizează cadre de analiză open source, cum ar fi Apache Spark sau Apache Hive. Spre deosebire de EMR pe EC2, nu trebuie să ștergeți sau să închideți aplicațiile EMR Serverless. Aplicația EMR Serverless este doar o definiție și, odată creată, poate fi reutilizată atât timp cât este necesar. Acest lucru face conducta MWAA mai simplă, deoarece acum trebuie doar să trimiteți locuri de muncă la o aplicație EMR Serverless pre-creată.
În mod implicit, Aplicația EMR Serverless se va porni automat la trimiterea jobului și se va opri automat când este inactivă timp de 15 minute, în mod implicit, pentru a asigura eficiența costurilor. Puteți modifica durata de inactivitate sau puteți alege să dezactivați funcția.
Pentru a crea o aplicație folosind consola EMR Serverless, urmați instrucțiunile din „Creați o aplicație EMR Serverless". Notați ID-ul aplicației, deoarece îl vom folosi în pașii următori.
![]()
Creați o găleată S3 și foldere
Parcurgeți următorii pași pentru a vă configura compartimentul și folderele S3:
- Pe consola Amazon S3, creați o cupă S3 pentru a stoca setul de date.
- Notați numele găleții S3 pentru a o utiliza în pașii ulterioare.
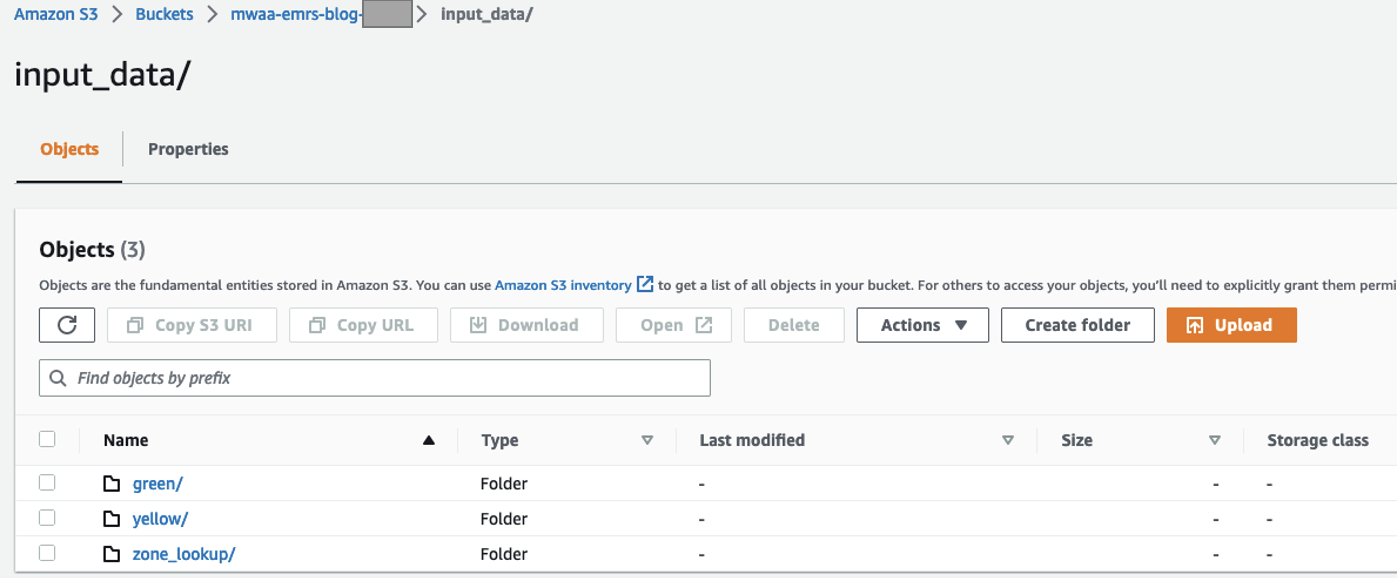
- Creați o
input_datafolder pentru stocarea datelor de intrare. - În acel folder, creați trei foldere separate, câte unul pentru fiecare set de date:
green,yellow, șizone_lookup.
Puteți descărca și lucra cu cele mai recente seturi de date disponibile. Pentru testarea noastră, folosim următoarele fișiere:
-
green/folderul are fișierulgreen_tripdata_2022-06.parquet -
yellow/folderul are fișierulyellow_tripdata_2022-06.parquet -
zone_lookup/folderul are fișierultaxi_zone_lookup.csv
Configurați scripturile Amazon MWAA DAG
Parcurgeți următorii pași pentru a configura scripturile DAG:
- Descărcați următoarele scripturi pe mașina dvs. locală:
- cerințe.txt – O dependență Python este orice pachet sau distribuție care nu este inclusă în instalarea de bază Apache Airflow pentru versiunea dvs. Apache Airflow din mediul dvs. Amazon MWAA. Pentru această postare, folosim Boto3
version >=1.23.9. - blog_dag_mwaa_emrs_ny_taxi.py – Acest script face parte din Amazon MWAA DAG și constă din următoarele sarcini:
yellow_taxi_zone_lookup,green_taxi_zone_lookup, șiny_taxi_summary,. Aceste sarcini implică rularea joburilor Spark pentru a căuta zone de taxi și generarea unui rezumat de date . - green_zone.py – Acest script PySpark citește fișierele de date pentru cursele cu taxiul verde și căutarea zonei, efectuează o operație de unire pentru a le combina și generează un fișier de ieșire care conține cursele cu taxiul verde cu informații despre zonă. Utilizează vizualizări temporare pentru
df_greenșidf_zonecadre de date, efectuează îmbinări pe coloană și cumulează date precum numărul de pasageri, distanța călătoriei și valoarea tarifului. În cele din urmă, creeazăoutput_datafolderul din compartimentul S3 specificat pentru a scrie cadrul de date rezultat,df_green_zone, ca fișiere Parquet. - yellow_zone.py – Acest script PySpark procesează fișierele de date privind cursa cu taxiul galben și căutarea zonei, unindu-le pentru a genera un fișier de ieșire care conține cursele cu taxiul galben cu informații despre zonă. Scriptul acceptă un nume de compartiment S3 furnizat de utilizator și inițiază o sesiune Spark cu numele aplicației
yellow_zone. Citește fișierele taxi galbene și fișierul de căutare a zonei din compartimentul S3 specificat, creează vizualizări temporare, efectuează o alăturare pe baza ID-ului locației și calculează statistici precum numărul de pasageri, distanța călătoriei și valoarea tarifului. În cele din urmă, creeazăoutput_datafolderul din compartimentul S3 specificat pentru a scrie cadrul de date rezultat,df_yellow_zone, ca fișiere Parquet. - ny_taxi_summary.py – Acest script PySpark procesează
green_zoneșiyellow_zonefișiere pentru a agrega statistici privind cursele cu taxiul, gruparea datelor în funcție de zonele de servicii și ID-urile locației. Necesită un nume de găleată S3 ca argument în linia de comandă, creează o sesiune SparkSession numităny_taxi_summary, citește fișierele din S3, efectuează o îmbinare și generează un nou cadru de date numitny_taxi_summary. Acesta creează un folder output_data în compartimentul S3 specificat pentru a scrie cadrul de date rezultat în noile fișiere Parquet.
- cerințe.txt – O dependență Python este orice pachet sau distribuție care nu este inclusă în instalarea de bază Apache Airflow pentru versiunea dvs. Apache Airflow din mediul dvs. Amazon MWAA. Pentru această postare, folosim Boto3
- Pe computerul local, actualizați
blog_dag_mwaa_emrs_ny_taxi.pyscript cu următoarele informații:- Actualizați-vă numele compartimentului S3 în următoarele două rânduri:
- Actualizați-vă numele rolului ARN:
- Actualizați ID-ul aplicației fără server EMR. Utilizați ID-ul aplicației creat mai devreme.
- Încărcați
requirements.txtfișier în compartimentul S3 creat mai devreme
- În compartimentul S3, creați un folder numit
dagsși încărcați actualizatblog_dag_mwaa_emrs_ny_taxi.pyfișier de pe mașina dvs. locală.
- Pe consola Amazon S3, creați un folder nou numit
scriptsîn compartimentul S3 și încărcați scripturile în acest folder de pe mașina dvs. locală.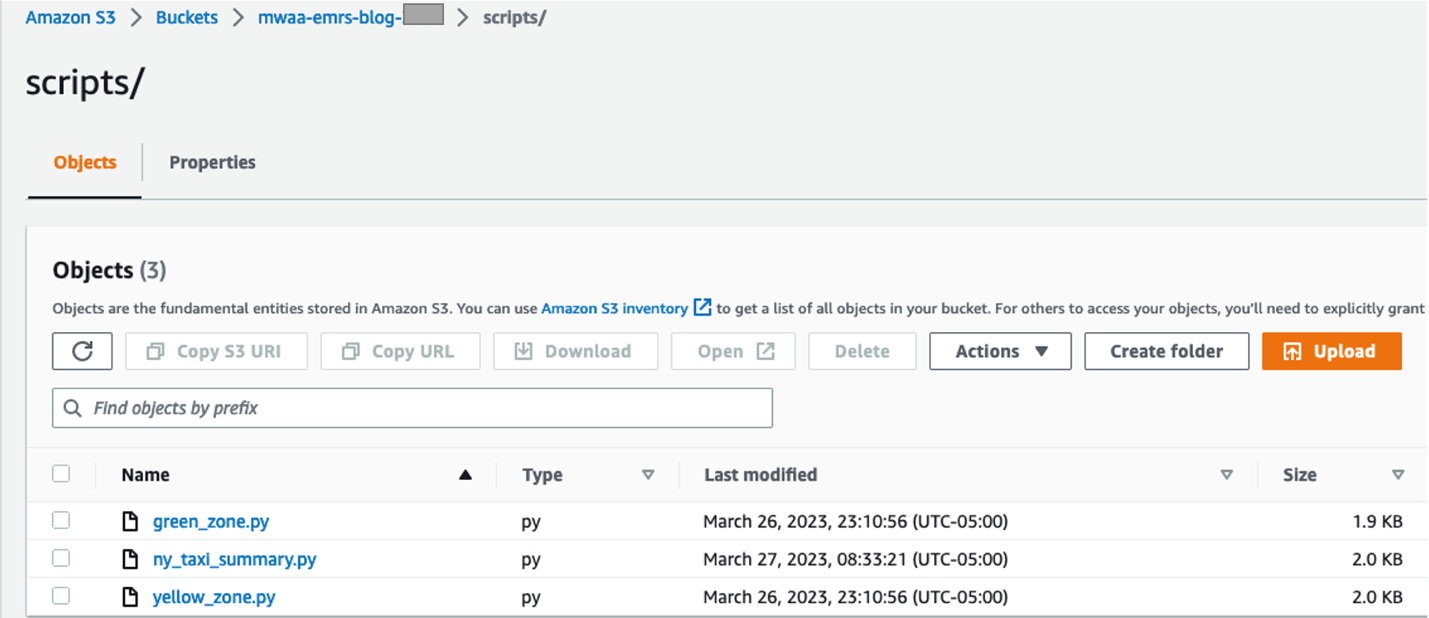
Creați un mediu Amazon MWAA
Pentru a crea un mediu Airflow, parcurgeți următorii pași:
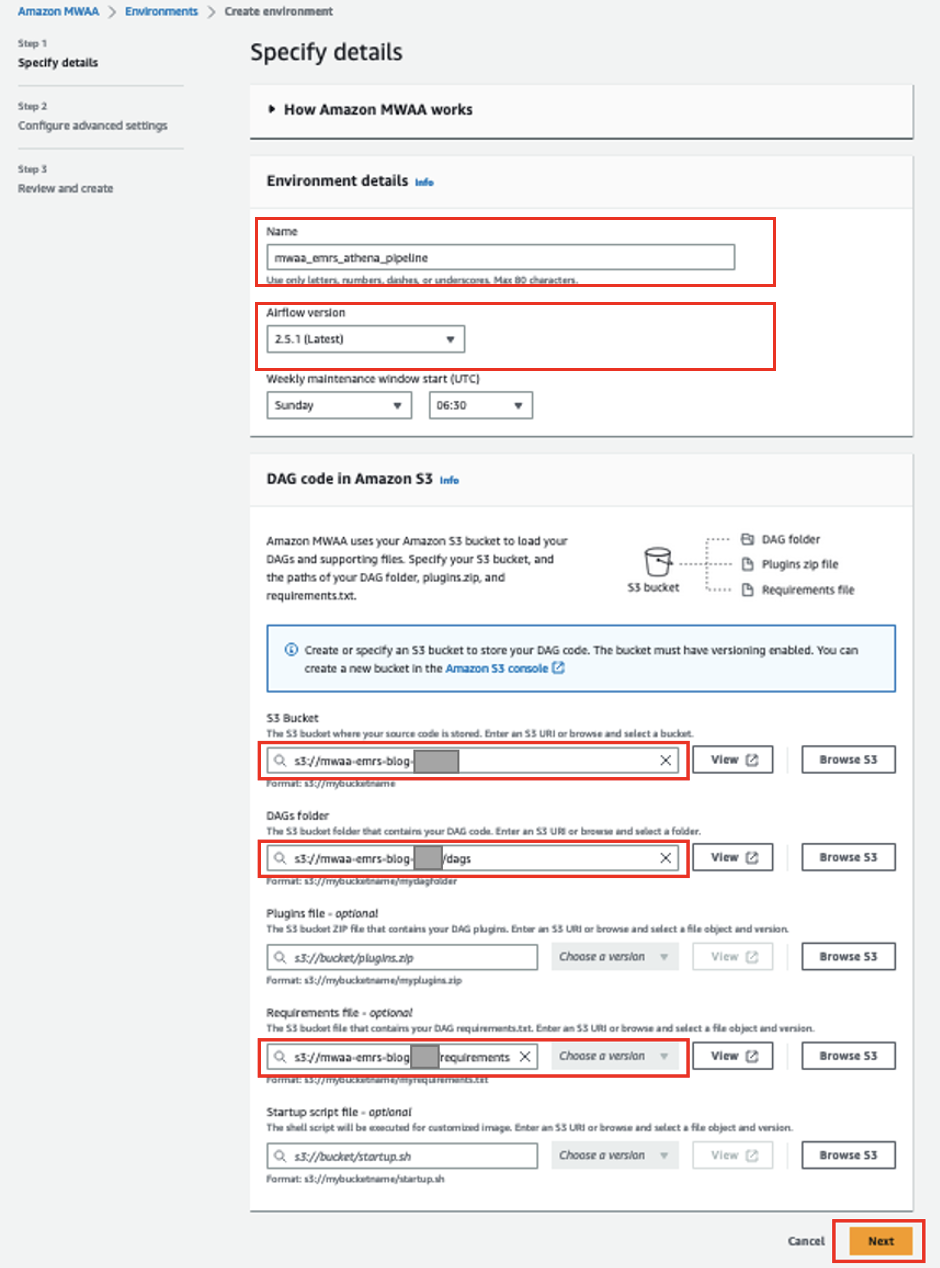
- Pe consola Amazon MWAA, alegeți Creați mediu.

- Pentru Nume si Prenume, introduce
mwaa_emrs_athena_pipeline. - Pentru Versiunea cu flux de aer, alege cea mai recentă versiune (pentru această postare, 2.5.1).
- Pentru Găleată S3, introduceți calea către bucket-ul dvs. S3.
- Pentru Dosarul DAGs, intră pe calea către tine
dagsdosar. - Pentru Dosarul de cerințe, intrați pe calea către
requirements.txtfișier. - Alege Pagina Următoare →.
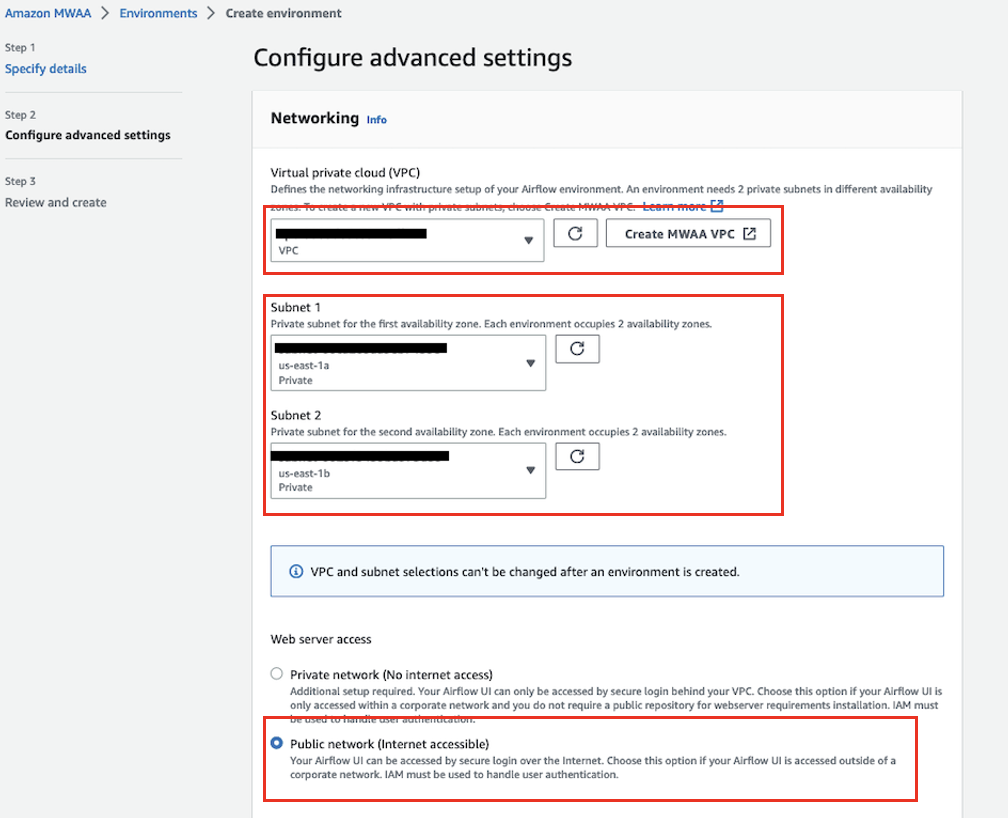
- Pentru Cloud privat virtual (VPC), alegeți un VPC care are cel puțin două subrețele private.
Aceasta va popula două dintre subrețelele private din VPC-ul dvs.
- În Acces la server web, Selectați Retea publica.
Acest lucru permite ca interfața de utilizare Apache Airflow să fie accesată prin internet de către utilizatorii cărora li s-a acordat acces la Politica IAM pentru mediul dumneavoastră.
- Pentru Grupuri de securitate, Selectați Creați un nou grup de securitate.
- Pentru Clasa de mediu, Selectați mw1.mic.
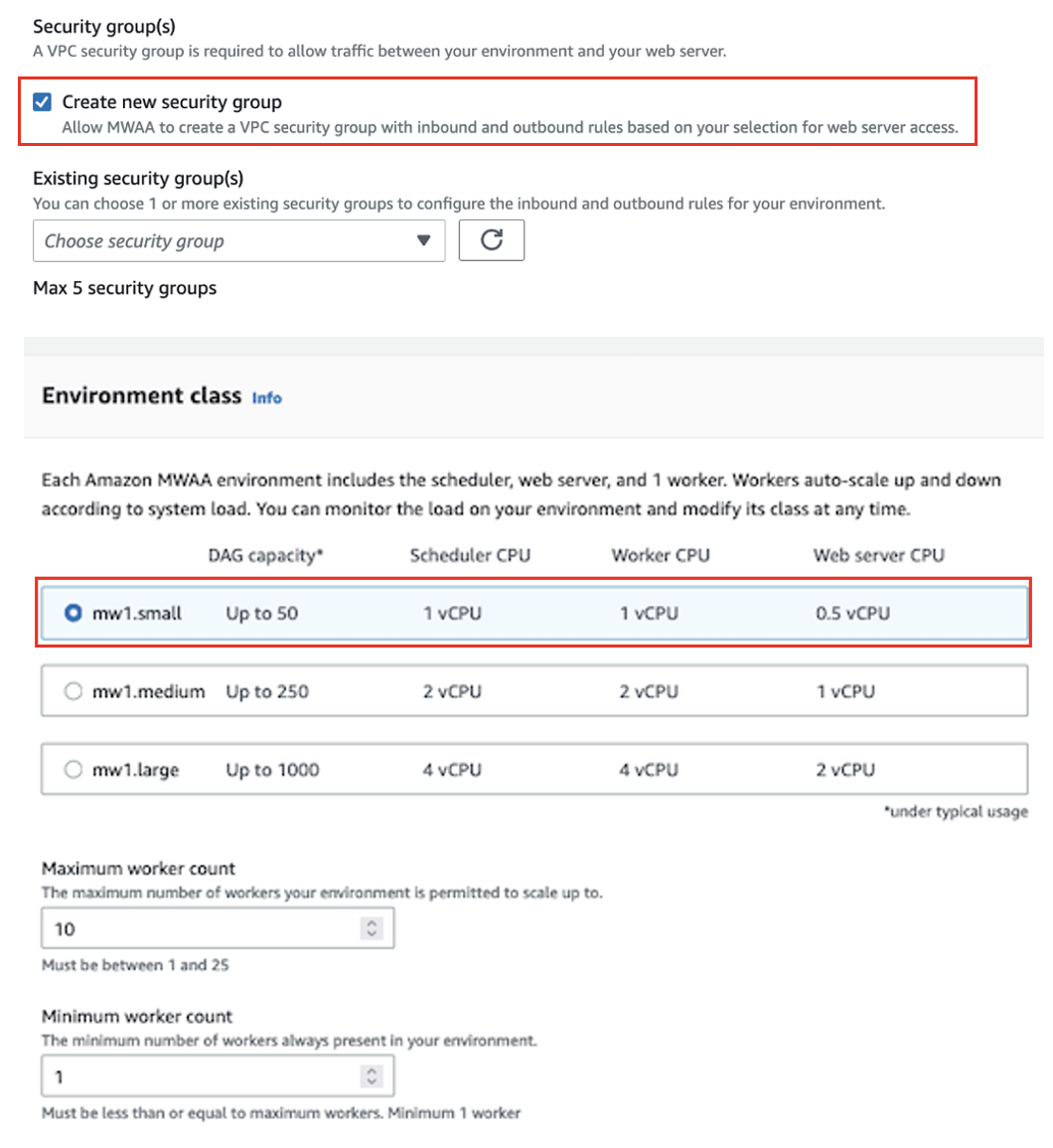
- Pentru Rolul de execuție, alege Creați un nou rol.
- Pentru Nume rol, introduceți un nume.
- Lăsați celelalte configurații ca implicite și alegeți Pagina Următoare →.

- Pe pagina următoare, alegeți Crea mediu inconjurator.
Crearea mediului Amazon MWAA poate dura aproximativ 20-30 de minute.
- Când starea mediului Amazon MWAA se schimbă în Disponibil, navigați la consola IAM și actualizați rolul de execuție a clusterului pentru a adăuga transmite privilegii de rol la
emr_serverless_execution_role.
Declanșați Amazon MWAA DAG
Pentru a declanșa DAG, parcurgeți următorii pași:
- Pe consola Amazon MWAA, alegeți medii în panoul de navigare.
- Deschide-ți mediul și alege Deschideți interfața de utilizare a fluxului de aer.
- Selectați
blog_dag_mwaa_emr_ny_taxi, alege pictograma de redare și alege Declanșează DAG.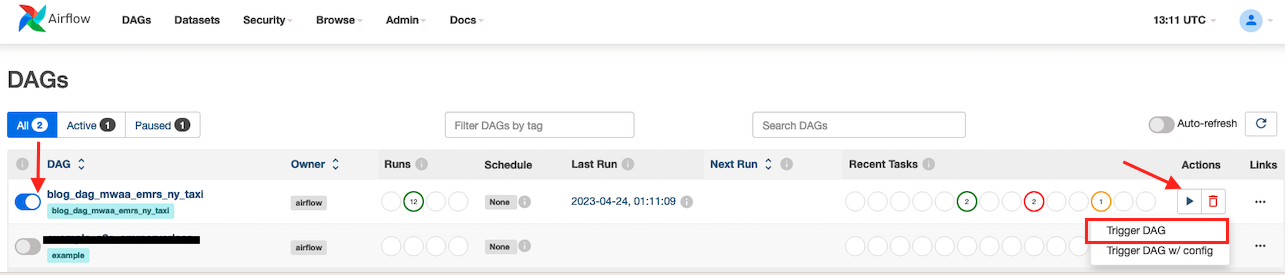
- Când DAG rulează, alegeți DAG
blog_dag_mwaa_emrs_ny_taxiȘi alegeți Grafic pentru a localiza fluxul de lucru al rulării DAG.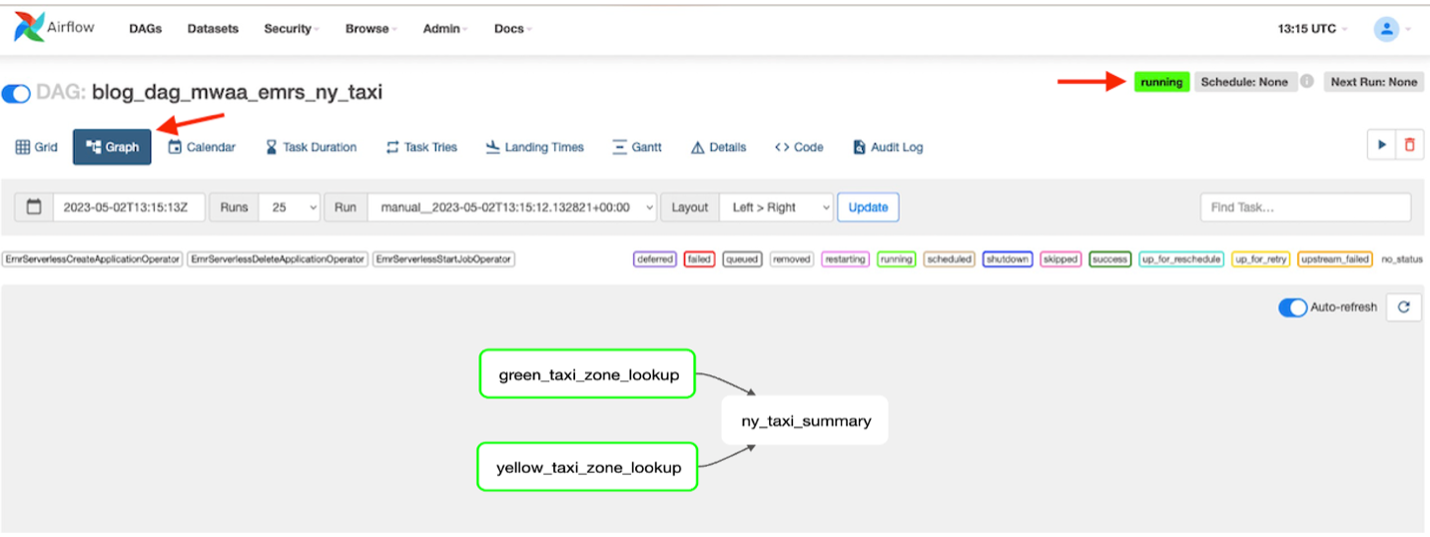
DAG va dura aproximativ 4-6 minute pentru a rula toate scripturile. Veți vedea toate sarcinile complete și starea generală a DAG se va afișa ca succes.

Pentru a rula din nou DAG, eliminați s3://<<your_s3_bucket here >>/output_data/.
Opțional, pentru a înțelege cum rulează Amazon MWAA aceste sarcini, alegeți sarcina pe care doriți să o inspectați.

Alege Alerga pentru a vedea detaliile executării sarcinii.
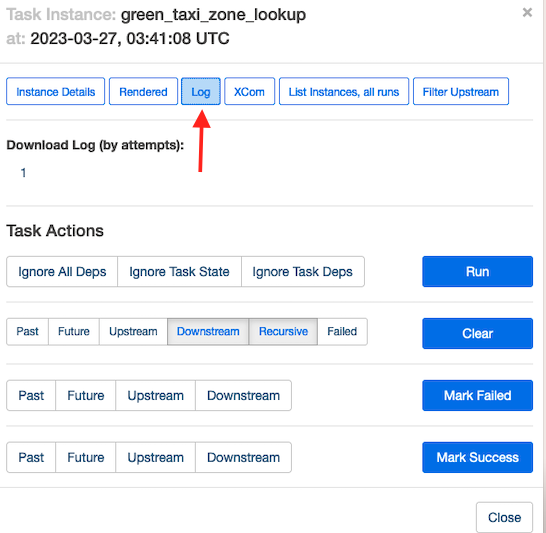
Următoarea captură de ecran arată un exemplu de jurnalele de activități.
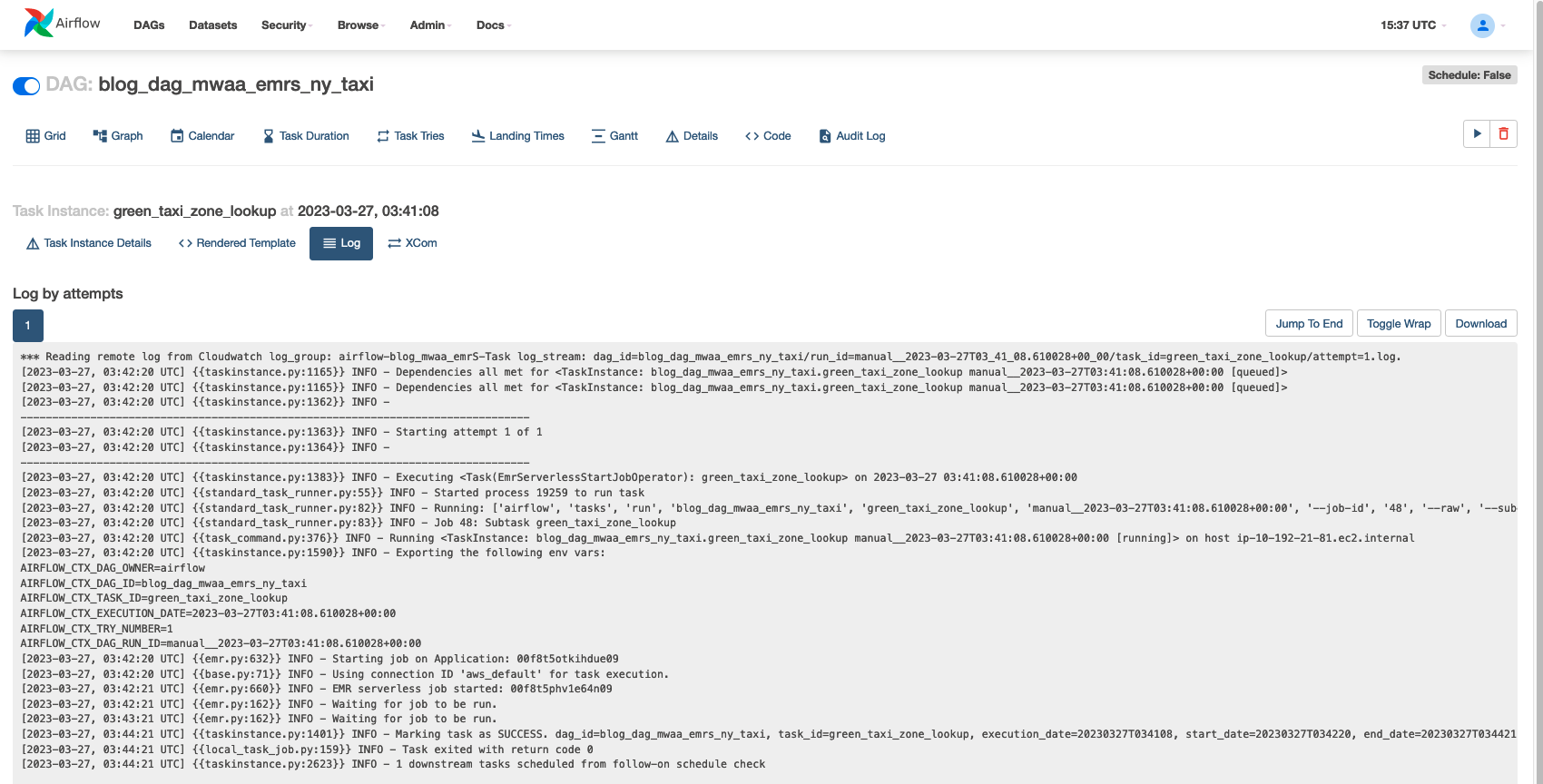
Dacă doriți să vă aprofundați în jurnalele de execuție, atunci pe consola EMR Serverless, navigați la „Aplicații”. Jurnalele driverului Apache Spark vor indica inițierea lucrării dvs. împreună cu detaliile pentru executanți, etapele și sarcinile care au fost create de EMR Serverless. Aceste jurnale pot fi utile pentru a vă monitoriza progresul lucrării și pentru a remedia erorile.
În mod implicit, EMR Serverless va stoca jurnalele aplicațiilor în siguranță în stocarea gestionată Amazon EMR pentru o perioadă de 30 de zile. Cu toate acestea, puteți specifica și Amazon S3 sau Amazon CloudWatch ca opțiunile dvs. de livrare a jurnalului în timpul trimiterii jobului.

Validați setul de rezultate final cu Athena
Să validăm datele încărcate de proces folosind interogări Athena SQL.
- Pe consola Athena, alegeți Editor de interogări în panoul de navigare.
- Dacă utilizați Athena pentru prima dată, sub Setări cont, alege Administrare și introduceți locația compartimentului S3 pe care ați creat-o mai devreme (
<S3_BUCKET_NAME>/athena), atunci alege Economisiți.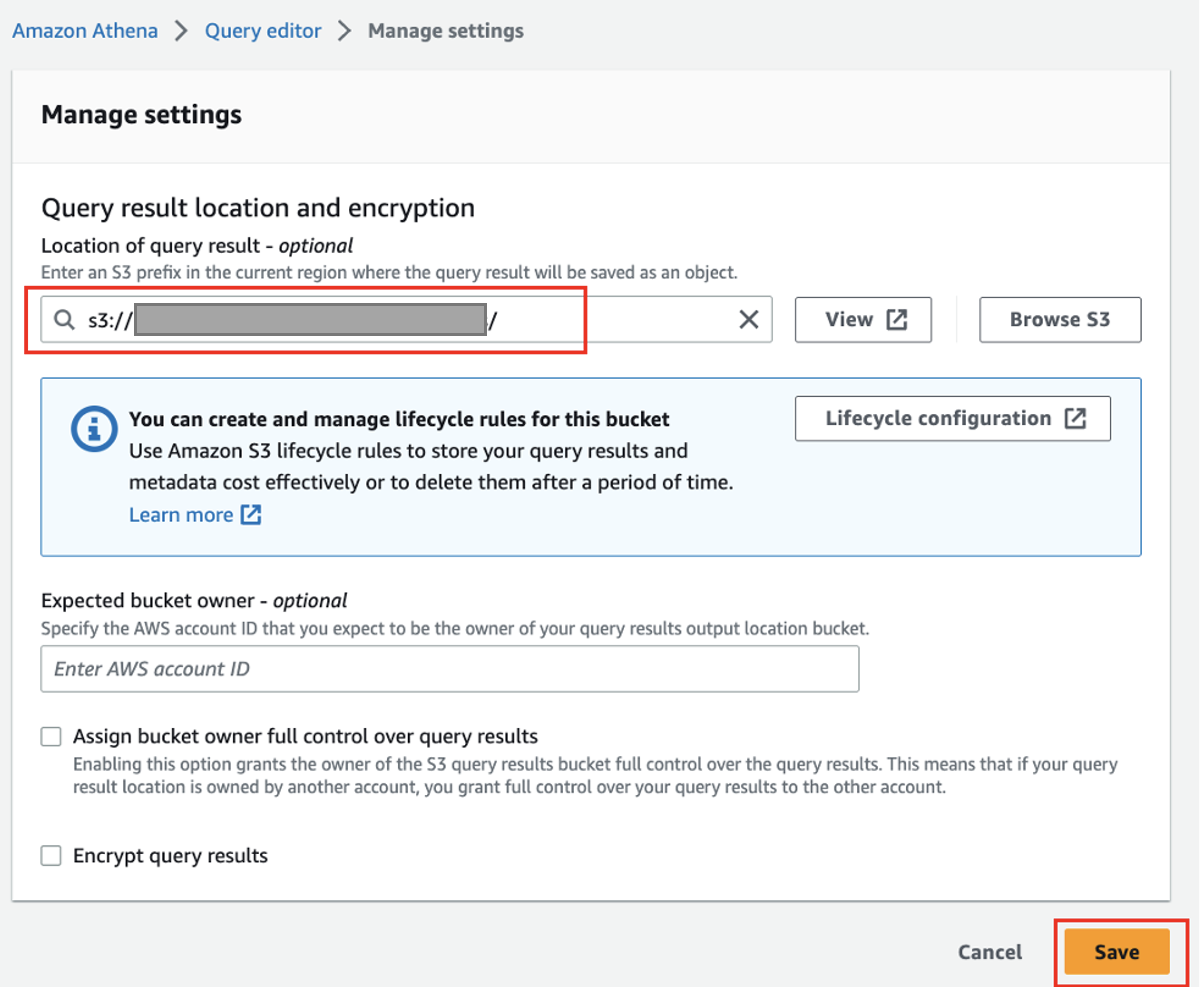
- În editorul de interogări, introduceți următoarea interogare pentru a crea un tabel extern:

Rulați următoarea interogare pe cel recent creat ny_taxi_summary tabel pentru a prelua primele 10 rânduri pentru a valida datele:

A curăța
Pentru a preveni taxele viitoare, parcurgeți următorii pași:
- Pe consola Amazon S3, ștergeți compartimentul S3 pe care l-ați creat pentru a stoca Amazon MWAA DAG, scripturile și jurnalele.
- Pe consola Athena, plasați tabelul pe care l-ați creat:
- Pe consola Amazon MWAA, navigați la mediul pe care l-ați creat și alegeți Șterge.

- Pe consola EMR Studio, ștergeți aplicația.
Pentru a șterge aplicația, navigați la Listează aplicațiile pagină. Selectați aplicația pe care ați creat-o și alegeți Acțiuni → Opriți pentru a opri aplicația. După ce aplicația este în starea OPRIT, selectați aceeași aplicație și alegeți Acțiuni → Șterge.

Concluzie
Ingineria datelor este o componentă critică a multor organizații și, pe măsură ce volumele de date continuă să crească, este esențial să găsim modalități de eficientizare a fluxurilor de lucru de procesare a datelor. Combinația dintre Amazon MWAA, EMR Serverless și Athena oferă o soluție puternică pentru a construi, rula și gestiona eficient conductele de date. Cu această conductă de procesare a datelor end-to-end, inginerii de date pot procesa și analiza cu ușurință cantități mari de date rapid și rentabil, fără a fi nevoie să gestioneze infrastructura complexă. Integrarea acestor servicii AWS oferă o soluție robustă și scalabilă pentru procesarea datelor, ajutând organizațiile să ia decizii în cunoștință de cauză pe baza informațiilor lor despre date.
Acum că ați văzut cum să trimiteți joburi Spark pe EMR Serverless prin Amazon MWAA, vă încurajăm să utilizați Amazon MWAA pentru a crea un flux de lucru care va rula joburi PySpark prin EMR Serverless.
Așteptăm feedback-ul și întrebările dvs. Vă rugăm să nu ezitați să ne contactați dacă aveți întrebări sau comentarii.
Despre autori
 Rahul Sonawane este arhitect principal de soluții de analiză la AWS, având ca domeniu de specialitate AI/ML și Analytics.
Rahul Sonawane este arhitect principal de soluții de analiză la AWS, având ca domeniu de specialitate AI/ML și Analytics.
 Gaurav Parekh este un arhitect de soluții care ajută clienții AWS să construiască arhitectură modernă la scară largă. El este specializat în analiza datelor și rețele. În afara serviciului, lui Gaurav îi place să joace cricket, fotbal și volei.
Gaurav Parekh este un arhitect de soluții care ajută clienții AWS să construiască arhitectură modernă la scară largă. El este specializat în analiza datelor și rețele. În afara serviciului, lui Gaurav îi place să joace cricket, fotbal și volei.
Istoricul auditului
Decembrie 2023: Această postare a fost revizuită pentru acuratețea tehnică de către Santosh Gantaram, managerul tehnic senior de cont.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/orchestrate-amazon-emr-serverless-spark-jobs-with-amazon-mwaa-and-data-validation-using-amazon-athena/
- :are
- :este
- :nu
- $UP
- 1
- 10
- 100
- 118
- 15%
- 16
- 2022
- 2023
- 23
- 25
- 30
- 300
- 7
- 700
- 8
- 9
- 990
- a
- Despre Noi
- acceptă
- acces
- accesate
- Cont
- precizie
- adăuga
- După
- agregat
- AI / ML
- TOATE
- permite
- de-a lungul
- deja
- de asemenea
- Amazon
- Amazon Atena
- Amazon EMR
- Amazon Web Services
- sumă
- Sume
- an
- Google Analytics
- analiza
- și
- Orice
- Apache
- Apache Spark
- aplicație
- aplicatii
- aproximativ
- arhitectură
- SUNT
- ZONĂ
- argument
- AS
- At
- în mod automat
- disponibil
- AWS
- înapoi
- de bază
- bazat
- BE
- deveni
- devine
- între
- Mare
- Datele mari
- construi
- Clădire
- construit
- întreprinderi
- by
- calculează
- CAN
- catalog
- Schimbare
- Modificări
- taxe
- Alege
- clasificare
- Cloud
- Grup
- cod
- combinaţie
- combina
- vine
- comentarii
- Completă
- complex
- component
- constă
- Consoleze
- continua
- Corespunzător
- A costat
- cost-eficiente
- Cheltuieli
- crea
- a creat
- creează
- crichet
- critic
- clienţii care
- DAG
- de date
- Analiza datelor
- de prelucrare a datelor
- seturi de date
- Date
- Zi
- Deciziile
- adânc
- Mod implicit
- definiție
- livrare
- dependențe
- Dependenţă
- detalii
- distanţă
- distribuire
- scufunda
- do
- Dont
- dubla
- jos
- Descarca
- şofer
- Picătură
- în timpul
- e
- fiecare
- Mai devreme
- cu ușurință
- uşor
- editor
- eficiență
- eficient
- eficient
- încuraja
- un capăt la altul
- Inginerie
- inginerii
- asigura
- Intrați
- Mediu inconjurator
- esenţial
- Eter (ETH)
- exemplu
- execuție
- extern
- suplimentar
- eşecuri
- Caracteristică
- feedback-ul
- simţi
- Fișier
- Fişiere
- final
- Găsi
- First
- prima dată
- Concentra
- urma
- următor
- Pentru
- format
- FRAME
- cadre
- Gratuit
- din
- complet
- viitor
- genera
- generează
- generator
- acordate
- Verde
- Crește
- creste
- Hadoop
- manipula
- Avea
- he
- ajutor
- util
- ajutor
- aici
- lui
- Stup
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- Idle
- ID-uri
- if
- ilustra
- ilustrează
- in
- include
- inclus
- include
- tot mai mult
- indica
- informații
- informat
- Infrastructură
- Initiaza
- inițiere
- intrare
- Cereri
- în interiorul
- perspective
- instala
- in schimb
- instrucțiuni
- integrare
- interacţiona
- interactiv
- Internet
- implica
- IT
- Loc de munca
- Locuri de munca
- alătura
- aderarea
- Se alătură
- jpg
- doar
- mare
- în cele din urmă
- mai tarziu
- Ultimele
- ca
- LIMITĂ
- Linie
- linii
- local
- locaţie
- Locații
- log
- Lung
- cautati
- căutare
- maşină
- face
- FACE
- Efectuarea
- administra
- gestionate
- manager
- de conducere
- multe
- Mai..
- Metadata
- minim
- minute
- Modern
- modifica
- monitor
- mai mult
- nume
- Numit
- Navigaţi
- Navigare
- Nevoie
- necesar
- rețele
- Nou
- următor
- Nici unul
- acum
- NYC
- of
- de pe
- on
- dată
- ONE
- afară
- deschide
- open-source
- operaţie
- Operatorii
- Opţiuni
- or
- organizații
- Altele
- al nostru
- afară
- contururi
- producție
- exterior
- peste
- global
- pachet
- pagină
- pâine
- parte
- cale
- plată
- efectuează
- perioadă
- conducte
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- Joaca
- joc
- "vă rog"
- Politica
- posibil
- Post
- puternic
- premise
- împiedica
- Principal
- privat
- proces
- procese
- prelucrare
- Progres
- furnizorul
- furnizează
- furnizarea
- public
- Piton
- interogări
- Întrebări
- repede
- ajunge
- recent
- înregistrări
- reduce
- de încredere
- scoate
- necesita
- Necesită
- Resurse
- rezultat
- rezultând
- revizuite
- Călări
- plimbari
- robust
- Rol
- RÂND
- Alerga
- funcţionare
- ruleaza
- s
- acelaşi
- scalabil
- Scară
- cântare
- scalare
- programa
- scenariu
- script-uri
- Secțiune
- în siguranță,
- securitate
- vedea
- văzut
- selecta
- distinct
- serverul
- serverless
- serviciu
- Servicii
- sesiune
- set
- instalare
- să
- Arăta
- Emisiuni
- simplu
- simplifica
- So
- Fotbal
- soluţie
- soluţii
- Sursă
- Scânteie
- specializată
- Specialitate
- specificată
- SQL
- Stadiile
- standard
- Stat
- statistică
- Stare
- paşi
- Stop
- oprit
- depozitare
- stoca
- stocate
- simplifica
- Şir
- studio
- supunere
- prezenta
- subrețele
- astfel de
- REZUMAT
- De sprijin
- tabel
- Lua
- Sarcină
- sarcini
- Tehnic
- temporar
- Testarea
- acea
- lor
- Lor
- apoi
- Acestea
- acest
- trei
- timp
- ori
- la
- astăzi
- Transforma
- Transformare
- transformat
- declanşa
- excursie
- ÎNTORCĂ
- Două
- Tipuri
- ui
- în
- înţelege
- spre deosebire de
- Actualizează
- actualizat
- us
- utilizare
- utilizatorii
- utilizări
- folosind
- utilizează
- VALIDA
- validare
- versiune
- de
- Vizualizare
- vizualizari
- volum
- volume
- vrea
- a fost
- modalități de
- we
- web
- servicii web
- bun venit
- au fost
- cand
- care
- voi
- cu
- fără
- Apartamente
- flux de lucru
- fluxuri de lucru
- face griji
- îngrijorător
- scrie
- galben
- tu
- Ta
- zephyrnet
- zone