Lacurile de date alimentate de AWS, susținute de disponibilitatea de neegalat a Serviciul Amazon de stocare simplă (Amazon S3), poate gestiona amploarea, agilitatea și flexibilitatea necesare pentru a combina diferite abordări de date și analize. Pe măsură ce lacurile de date au crescut în dimensiune și s-au maturizat în utilizare, se poate depune o cantitate semnificativă de efort pentru a menține datele în concordanță cu evenimentele de afaceri. Pentru a se asigura că fișierele sunt actualizate într-o manieră coerentă din punct de vedere tranzacțional, un număr tot mai mare de clienți utilizează formate de tabel tranzacționale open-source, cum ar fi Apache Iceberg, Apache Hudi, și Fundația Linux Delta Lake care vă ajută să stocați date cu rate de compresie ridicate, să interacționați nativ cu aplicațiile și cadrele dvs. și să simplificați procesarea incrementală a datelor în lacurile de date construite pe Amazon S3. Aceste formate permit tranzacțiile ACID (atomicitate, consistență, izolare, durabilitate), supărări și ștergeri, precum și funcții avansate, cum ar fi călătoria în timp și instantanee, care anterior erau disponibile numai în depozitele de date. Fiecare format de stocare implementează această funcționalitate în moduri ușor diferite; pentru o comparație, consultați Alegerea unui format de tabel deschis pentru lacul dvs. de date tranzacționale pe AWS.
În 2023, AWS a anunțat disponibilitatea generală pentru Apache Iceberg, Apache Hudi și Linux Foundation Delta Lake în Amazon Athena pentru Apache Spark, care elimină necesitatea instalării unui conector separat sau a dependențelor asociate și gestionarea versiunilor și simplifică pașii de configurare necesari pentru a utiliza aceste cadre.
În această postare, vă arătăm cum să utilizați Spark SQL în Amazon Atena caiete și lucrați cu formatele de tabel Iceberg, Hudi și Delta Lake. Demonstrăm operațiuni obișnuite, cum ar fi crearea de baze de date și tabele, inserarea datelor în tabele, interogarea datelor și examinarea instantaneelor tabelelor în Amazon S3 folosind Spark SQL în Athena.
Cerințe preliminare
Completați următoarele cerințe preliminare:
Descărcați și importați exemple de notebook-uri de pe Amazon S3
Pentru a urma, descărcați caietele discutate în această postare din următoarele locații:
După ce descărcați blocnotesurile, importați-le în mediul dvs. Athena Spark urmând Pentru a importa un caiet secțiune în Gestionarea fișierelor notebook.
Navigați la secțiunea specifică Open Table Format
Dacă sunteți interesat de formatul tabelului Iceberg, navigați la Lucrul cu tabelele Apache Iceberg secţiune.
Dacă sunteți interesat de formatul tabelului Hudi, navigați la Lucrul cu tabele Apache Hudi secţiune.
Dacă sunteți interesat de formatul tabelului Delta Lake, navigați la Lucrul cu tabelele Delta Lake ale fundației Linux secţiune.
Lucrul cu tabelele Apache Iceberg
Când utilizați notebook-uri Spark în Athena, puteți rula interogări SQL direct, fără a fi nevoie să utilizați PySpark. Facem acest lucru folosind magia celulară, care sunt anteturi speciale într-o celulă de notebook care schimbă comportamentul celulei. Pentru SQL, putem adăuga %%sql magic, care va interpreta întregul conținut al celulei ca o instrucțiune SQL care va fi rulată pe Athena.
În această secțiune, arătăm cum puteți utiliza SQL pe Apache Spark pentru Athena pentru a crea, analiza și gestiona tabele Apache Iceberg.
Configurați o sesiune de notebook
Pentru a utiliza Apache Iceberg în Athena, în timp ce creați sau editați o sesiune, selectați Apache Iceberg opțiunea prin extinderea Proprietăți Apache Spark secțiune. Acesta va completa proprietățile, așa cum se arată în următoarea captură de ecran.
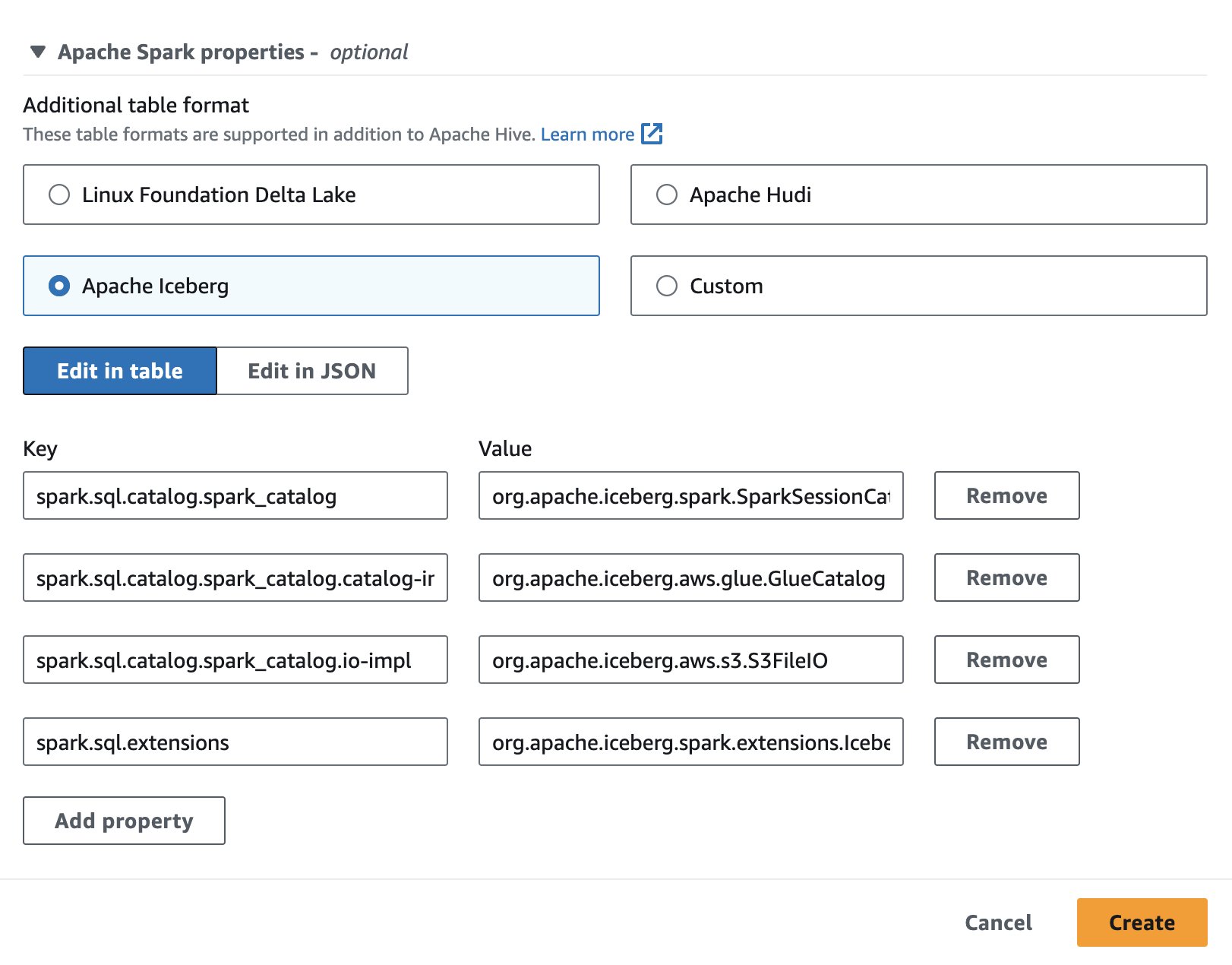
Pentru pași, vezi Editarea detaliilor sesiunii or Crearea propriului caiet.
Codul folosit în această secțiune este disponibil în SparkSQL_iceberg.ipynb fișier de urmat.
Creați o bază de date și un tabel Iceberg
Mai întâi, creăm o bază de date în AWS Glue Data Catalog. Cu următorul SQL, putem crea o bază de date numită icebergdb:
Apoi, în baza de date icebergdb, creăm un tabel Iceberg numit noaa_iceberg indicând către o locație din Amazon S3 unde vom încărca datele. Rulați următoarea instrucțiune și înlocuiți locația s3://<your-S3-bucket>/<prefix>/ cu găleata și prefixul S3:
Introduceți datele în tabel
Pentru a popula noaa_iceberg Tabelul Iceberg, inserăm date din tabelul Parquet sparkblogdb.noaa_pq care a fost creat ca parte a cerințelor prealabile. Puteți face acest lucru folosind un INTRODU IN declarație în Spark:
Alternativ, puteți utiliza CREATE TABLE AS SELECT cu clauza USING iceberg pentru a crea un tabel Iceberg și a insera date dintr-un tabel sursă într-un singur pas:
Interogați tabelul Iceberg
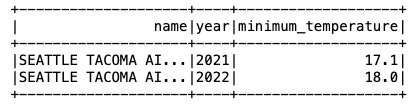
Acum că datele sunt introduse în tabelul Iceberg, putem începe să le analizăm. Să rulăm un Spark SQL pentru a găsi temperatura minimă înregistrată pe an pentru 'SEATTLE TACOMA AIRPORT, WA US' Locul de amplasare:
Obținem următoarea ieșire.
Actualizați datele din tabelul Iceberg
Să vedem cum să actualizăm datele din tabelul nostru. Vrem să actualizăm numele stației 'SEATTLE TACOMA AIRPORT, WA US' la 'Sea-Tac'. Folosind Spark SQL, putem rula un UPDATE declarație împotriva tabelului Iceberg:
Putem rula apoi interogarea SELECT anterioară pentru a găsi temperatura minimă înregistrată pentru 'Sea-Tac' Locul de amplasare:
Obținem următoarea ieșire.

Fișiere de date compacte
Formatele de tabel deschise, cum ar fi Iceberg, funcționează prin crearea de modificări delta în stocarea fișierelor și urmărirea versiunilor de rânduri prin fișierele manifest. Mai multe fișiere de date duc la mai multe metadate stocate în fișierele manifest, iar fișierele de date mici cauzează adesea o cantitate inutilă de metadate, rezultând interogări mai puțin eficiente și costuri mai mari de acces Amazon S3. Conducerea lui Iceberg rewrite_data_files procedura din Spark pentru Athena va compacta fișierele de date, combinând multe fișiere mici de modificare delta într-un set mai mic de fișiere Parquet optimizate pentru citire. Compactarea fișierelor accelerează operația de citire atunci când sunt interogate. Pentru a rula compactarea pe tabelul nostru, rulați următorul Spark SQL:
rewrite_data_files oferă opțiuni pentru a specifica strategia de sortare, care poate ajuta la reorganizarea și compactarea datelor.
Listați instantanee de tabel
Fiecare operațiune de scriere, actualizare, ștergere, suprapunere și compactare pe un tabel Iceberg creează un nou instantaneu al unui tabel, păstrând în același timp datele și metadatele vechi pentru izolarea instantaneelor și călătoria în timp. Pentru a lista instantaneele unui tabel Iceberg, rulați următoarea instrucțiune Spark SQL:
Expiră instantaneele vechi
Instantaneele care expiră în mod regulat sunt recomandate pentru a șterge fișierele de date care nu mai sunt necesare și pentru a menține dimensiunea mică a metadatelor din tabel. Nu va elimina niciodată fișierele care sunt încă solicitate de un instantaneu care nu a expirat. În Spark pentru Athena, rulați următorul SQL pentru a expira instantaneele pentru tabel icebergdb.noaa_iceberg care sunt mai vechi decât un anumit marcaj de timp:
Rețineți că valoarea marcajului de timp este specificată ca șir în format yyyy-MM-dd HH:mm:ss.fff. Ieșirea va oferi o contorizare a numărului de fișiere de date și metadate șterse.
Aruncă tabelul și baza de date
Puteți rula următorul Spark SQL pentru a curăța tabelele Iceberg și datele asociate din Amazon S3 din acest exercițiu:
Rulați următorul Spark SQL pentru a elimina baza de date icebergdb:
Pentru a afla mai multe despre toate operațiunile pe care le puteți efectua pe mesele Iceberg folosind Spark pentru Athena, consultați Spark Interogări și Proceduri Spark în documentația Iceberg.
Lucrul cu tabele Apache Hudi
În continuare, vă arătăm cum puteți utiliza SQL pe Spark pentru Athena pentru a crea, analiza și gestiona tabele Apache Hudi.
Configurați o sesiune de notebook
Pentru a utiliza Apache Hudi în Athena, în timp ce creați sau editați o sesiune, selectați Apache Hudi opțiunea prin extinderea Proprietăți Apache Spark secţiune.
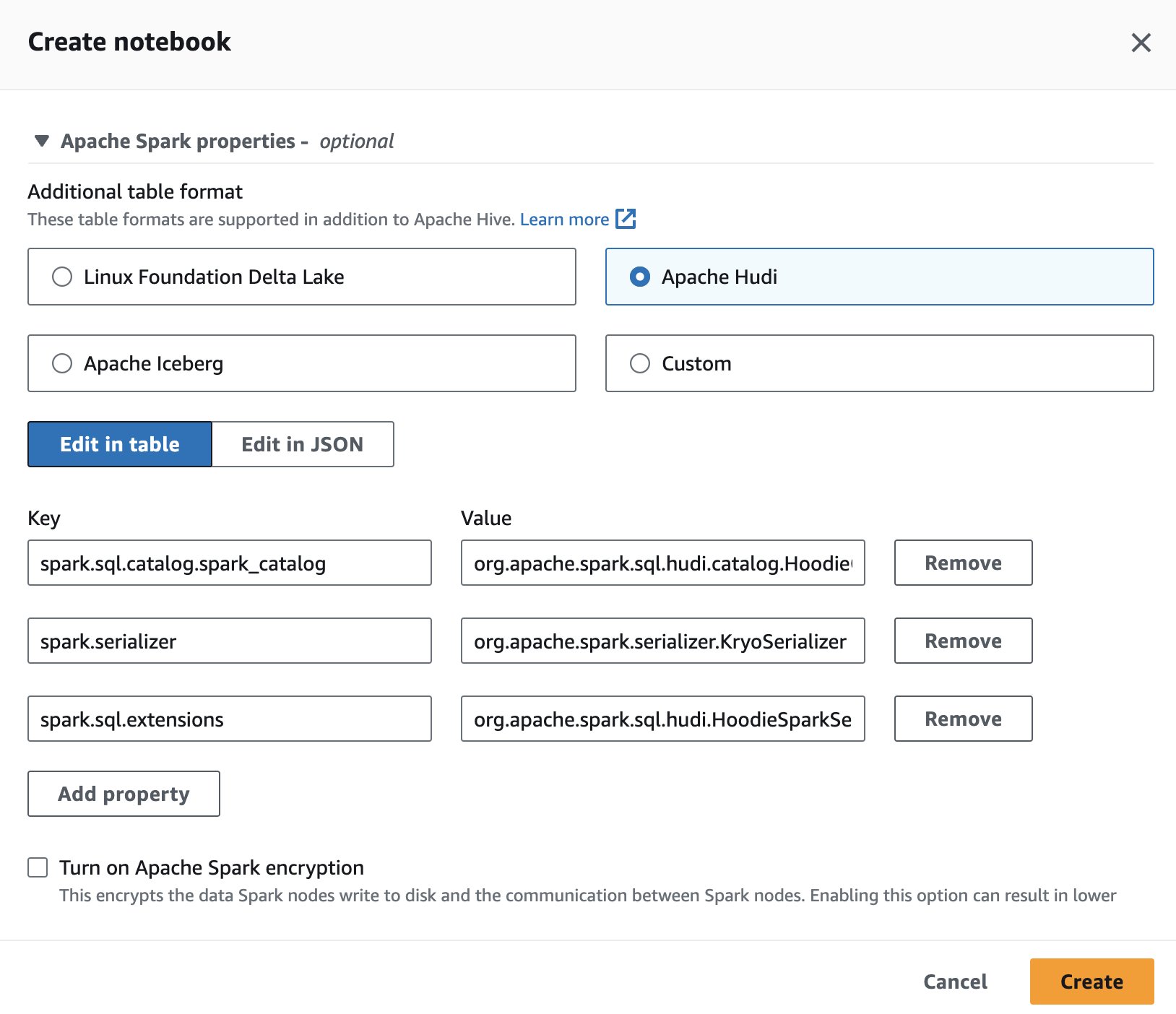
Pentru pași, vezi Editarea detaliilor sesiunii or Crearea propriului caiet.
Codul folosit în această secțiune ar trebui să fie disponibil în SparkSQL_hudi.ipynb fișier de urmat.
Creați o bază de date și un tabel Hudi
Mai întâi, creăm o bază de date numită hudidb care va fi stocat în Catalogul de date AWS Glue, urmat de crearea tabelului Hudi:
Creăm un tabel Hudi care indică o locație din Amazon S3 unde vom încărca datele. Rețineți că tabelul este de Copie pe scriere tip. Este definit de type= 'cow' în tabelul DDL. Am definit stația și data ca chei primare multiple și preCombinedField ca an. De asemenea, tabelul este împărțit pe an. Rulați următoarea instrucțiune și înlocuiți locația s3://<your-S3-bucket>/<prefix>/ cu găleata și prefixul S3:
Introduceți datele în tabel
Ca și în cazul Iceberg, folosim INTRODU IN declarație pentru a completa tabelul citind date din sparkblogdb.noaa_pq tabel creat în postarea anterioară:
Interogați tabelul Hudi
Acum că tabelul este creat, să rulăm o interogare pentru a găsi temperatura maximă înregistrată pentru 'SEATTLE TACOMA AIRPORT, WA US' Locul de amplasare:
Actualizați datele din tabelul Hudi
Să schimbăm numele stației 'SEATTLE TACOMA AIRPORT, WA US' la 'Sea–Tac'. Putem rula o declarație UPDATE pe Spark pentru Athena actualizare înregistrările de la noaa_hudi masa:
Executăm interogarea anterioară SELECT pentru a găsi temperatura maximă înregistrată pentru 'Sea-Tac' Locul de amplasare:
Rulați interogări de călătorie în timp
Putem folosi interogări de călătorie în timp în SQL pe Athena pentru a analiza instantanee de date din trecut. De exemplu:
Această interogare verifică datele de temperatură a aeroportului din Seattle la o anumită perioadă din trecut. Clauza de marcaj temporal ne permite să călătorim înapoi fără a modifica datele curente. Rețineți că valoarea marcajului de timp este specificată ca șir în format yyyy-MM-dd HH:mm:ss.fff.
Optimizați viteza interogărilor cu clustering
Pentru a îmbunătăți performanța interogărilor, puteți efectua clustering pe tabele Hudi folosind SQL în Spark pentru Athena:
Mese compacte
Compactarea este un serviciu de tabele folosit de Hudi în mod specific în tabelele Merge On Read (MOR) pentru a îmbina actualizările din fișierele jurnal bazate pe rânduri cu fișierul de bază pe coloană corespunzător periodic pentru a produce o nouă versiune a fișierului de bază. Compactarea nu este aplicabilă tabelelor Copy On Write (COW) și se aplică numai tabelelor MOR. Puteți rula următoarea interogare în Spark pentru ca Athena să efectueze compactarea pe tabelele MOR:
Aruncă tabelul și baza de date
Rulați următorul Spark SQL pentru a elimina tabelul Hudi pe care l-ați creat și datele asociate din locația Amazon S3:
Rulați următorul Spark SQL pentru a elimina baza de date hudidb:
Pentru a afla despre toate operațiunile pe care le puteți efectua pe mesele Hudi folosind Spark pentru Athena, consultați SQL DDL și Proceduri în documentația Hudi.
Lucrul cu tabelele Delta Lake ale fundației Linux
În continuare, vă arătăm cum puteți utiliza SQL pe Spark pentru Athena pentru a crea, analiza și gestiona tabele Delta Lake.
Configurați o sesiune de notebook
Pentru a utiliza Delta Lake în Spark pentru Athena, în timp ce creați sau editați o sesiune, selectați Fundația Linux Delta Lake prin extinderea Proprietăți Apache Spark secţiune.
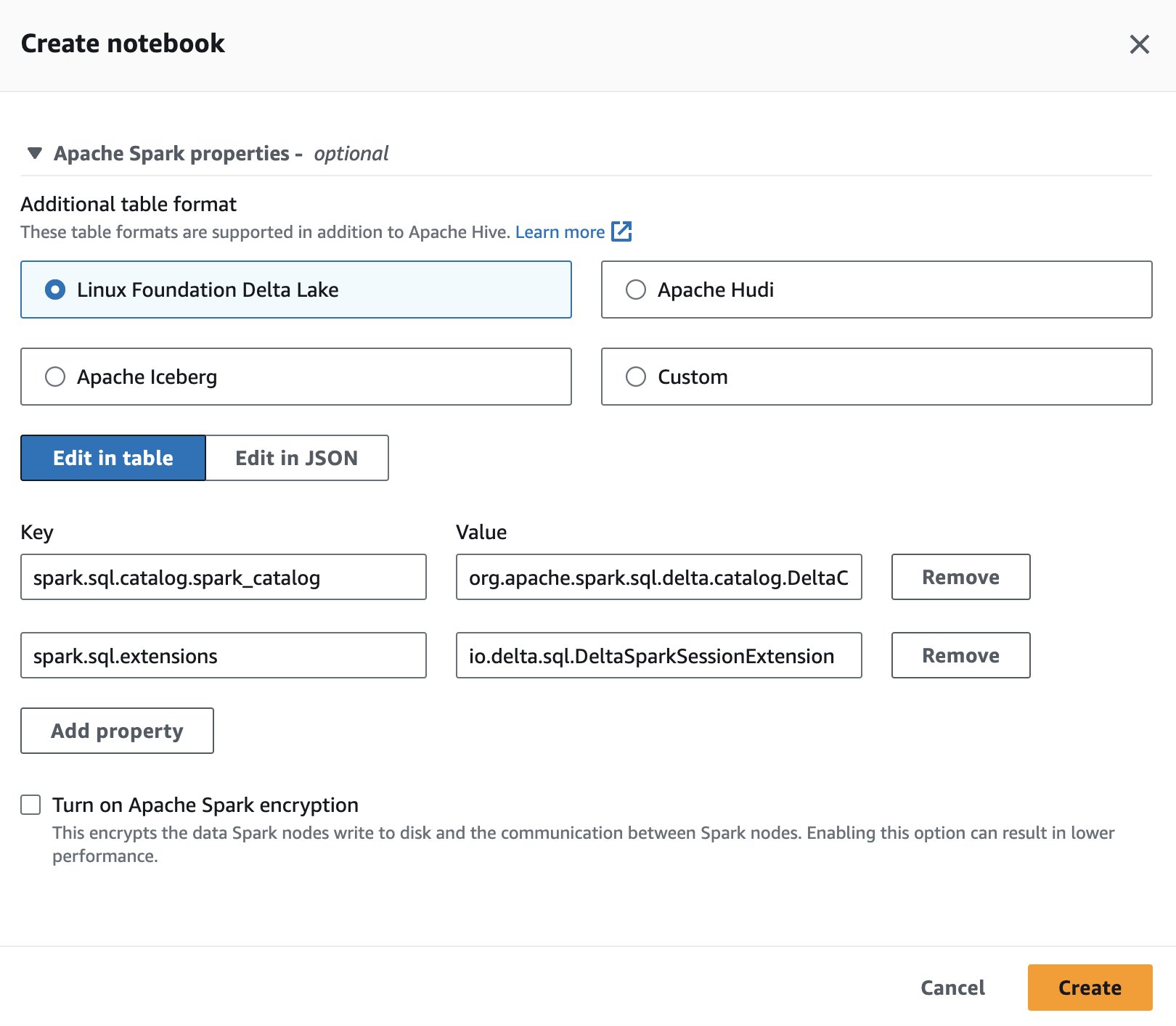
Pentru pași, vezi Editarea detaliilor sesiunii or Crearea propriului caiet.
Codul folosit în această secțiune ar trebui să fie disponibil în SparkSQL_delta.ipynb fișier de urmat.
Creați o bază de date și un tabel Delta Lake
În această secțiune, creăm o bază de date în AWS Glue Data Catalog. Folosind următorul SQL, putem crea o bază de date numită deltalakedb:
Apoi, în baza de date deltalakedb, creăm un tabel Delta Lake numit noaa_delta indicând către o locație din Amazon S3 unde vom încărca datele. Rulați următoarea instrucțiune și înlocuiți locația s3://<your-S3-bucket>/<prefix>/ cu găleata și prefixul S3:
Introduceți datele în tabel
Folosim un INTRODU IN declarație pentru a completa tabelul citind date din sparkblogdb.noaa_pq tabel creat în postarea anterioară:
De asemenea, puteți utiliza CREATE TABLE AS SELECT pentru a crea un tabel Delta Lake și pentru a insera date dintr-un tabel sursă într-o singură interogare.
Interogați tabelul Delta Lake
Acum că datele sunt introduse în tabelul Delta Lake, putem începe să le analizăm. Să rulăm un Spark SQL pentru a găsi temperatura minimă înregistrată pentru 'SEATTLE TACOMA AIRPORT, WA US' Locul de amplasare:
Actualizați datele din tabelul lacului Delta
Să schimbăm numele stației 'SEATTLE TACOMA AIRPORT, WA US' la 'Sea–Tac'. Putem rula un UPDATE declarație privind Spark pentru ca Athena să actualizeze înregistrările noaa_delta masa:
Putem rula interogarea anterioară SELECT pentru a găsi temperatura minimă înregistrată pentru 'Sea-Tac' locație, iar rezultatul ar trebui să fie același ca mai devreme:
Fișiere de date compacte
În Spark pentru Athena, puteți rula OPTIMIZE pe tabelul Delta Lake, care va compacta fișierele mici în fișiere mai mari, astfel încât interogările să nu fie împovărate de supraîncărcarea fișierelor mici. Pentru a efectua operația de compactare, rulați următoarea interogare:
A se referi la Optimizări în documentația Delta Lake pentru diferite opțiuni disponibile în timpul rulării OPTIMIZE.
Eliminați fișierele care nu mai fac referire de un tabel Delta Lake
Puteți elimina fișierele stocate în Amazon S3 care nu mai sunt referite de un tabel Delta Lake și care sunt mai vechi decât pragul de retenție, rulând comanda VACCUM pe tabel folosind Spark pentru Athena:
A se referi la Eliminați fișierele care nu mai fac referire de un tabel Delta în documentația Delta Lake pentru opțiunile disponibile cu VACUUM.
Aruncă tabelul și baza de date
Rulați următorul Spark SQL pentru a elimina tabelul Delta Lake pe care l-ați creat:
Rulați următorul Spark SQL pentru a elimina baza de date deltalakedb:
Rularea DROP TABLE DDL pe tabelul și baza de date Delta Lake șterge metadatele pentru aceste obiecte, dar nu șterge automat fișierele de date din Amazon S3. Puteți rula următorul cod Python în celula notebook-ului pentru a șterge datele din locația S3:
Pentru a afla mai multe despre instrucțiunile SQL pe care le puteți rula pe un tabel Delta Lake folosind Spark pentru Athena, consultați QuickStart în documentația Delta Lake.
Concluzie
Această postare a demonstrat cum să utilizați Spark SQL în notebook-urile Athena pentru a crea baze de date și tabele, pentru a insera și a interoga date și pentru a efectua operațiuni comune, cum ar fi actualizări, compactări și călătorii în timp pe tabelele Hudi, Delta Lake și Iceberg. Formatele de tabel deschise adaugă tranzacții ACID, upsers și ștergeri la lacurile de date, depășind limitările stocării obiectelor brute. Prin eliminarea necesității de a instala conectori separati, integrarea încorporată a Spark on Athena reduce pașii de configurare și cheltuielile generale de gestionare atunci când se utilizează aceste cadre populare pentru construirea de lacuri de date fiabile pe Amazon S3. Pentru a afla mai multe despre selectarea unui format de tabel deschis pentru sarcinile de lucru ale lacului de date, consultați Alegerea unui format de tabel deschis pentru lacul dvs. de date tranzacționale pe AWS.
Despre Autori
![]() Pathik Shah este un arhitect senior Analytics pe Amazon Athena. Sa alăturat AWS în 2015 și de atunci s-a concentrat pe spațiul de analiză a datelor mari, ajutând clienții să construiască soluții scalabile și robuste folosind serviciile de analiză AWS.
Pathik Shah este un arhitect senior Analytics pe Amazon Athena. Sa alăturat AWS în 2015 și de atunci s-a concentrat pe spațiul de analiză a datelor mari, ajutând clienții să construiască soluții scalabile și robuste folosind serviciile de analiză AWS.
![]() Raj Devnath este manager de produs la AWS pe Amazon Athena. El este pasionat de a construi produse pe care clienții le plac și de a-i ajuta pe clienți să extragă valoare din datele lor. Experiența sa este în furnizarea de soluții pentru mai multe piețe finale, cum ar fi finanțe, retail, clădiri inteligente, automatizare a locuințelor și sisteme de comunicare de date.
Raj Devnath este manager de produs la AWS pe Amazon Athena. El este pasionat de a construi produse pe care clienții le plac și de a-i ajuta pe clienți să extragă valoare din datele lor. Experiența sa este în furnizarea de soluții pentru mai multe piețe finale, cum ar fi finanțe, retail, clădiri inteligente, automatizare a locuințelor și sisteme de comunicare de date.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- :are
- :este
- :nu
- :Unde
- $UP
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- Despre Noi
- acces
- adăuga
- avansat
- împotriva
- aeroport
- TOATE
- de-a lungul
- de asemenea
- Amazon
- Amazon Atena
- Amazon Web Services
- sumă
- an
- Google Analytics
- analiza
- analiza
- și
- a anunțat
- Apache
- Apache Spark
- aplicabil
- aplicatii
- se aplică
- abordari
- SUNT
- în jurul
- AS
- asociate
- At
- în mod automat
- Automatizare
- disponibilitate
- disponibil
- AWS
- AWS Adeziv
- înapoi
- fundal
- de bază
- BE
- fost
- comportament
- Mare
- Datele mari
- construi
- Clădire
- construit
- construit-in
- afaceri
- dar
- by
- apel
- denumit
- CAN
- catalog
- Provoca
- celulă
- Schimbare
- Modificări
- Verificări
- curat
- cod
- combina
- combinând
- Comun
- Comunicare
- sisteme de comunicare
- compact
- comparație
- Configuraţie
- consistent
- conținut
- Corespunzător
- Cheltuieli
- conta
- crea
- a creat
- creează
- Crearea
- creaţie
- Curent
- clienţii care
- de date
- Analiza datelor
- Lacul de date
- de prelucrare a datelor
- depozite de date
- Baza de date
- baze de date
- Data
- definit
- livrarea
- Deltă
- demonstra
- demonstrat
- dependențe
- diferit
- direct
- discutat
- do
- documentaţie
- Nu
- Descarca
- Picătură
- durabilitate
- fiecare
- Mai devreme
- editare
- eficient
- efort
- angajat
- permite
- capăt
- asigura
- Întreg
- Mediu inconjurator
- Eter (ETH)
- evenimente
- exemplu
- Exercita
- extinderea
- extrage
- DESCRIERE
- Fișier
- Fişiere
- finanţa
- Găsi
- First
- Flexibilitate
- concentrându-se
- urma
- a urmat
- următor
- Pentru
- format
- Fundație
- cadre
- din
- funcționalitate
- General
- obține
- Da
- grup
- În creştere
- crescut
- manipula
- Avea
- având în
- he
- anteturile
- ajutor
- ajutor
- hh
- Înalt
- superior
- lui
- Acasă
- Automatizare acasă
- Cum
- Cum Pentru a
- HTML
- http
- HTTPS
- imagine
- ustensile
- import
- îmbunătăţi
- in
- incrementală
- instala
- integrare
- interesat
- interfaţă
- în
- izolare
- IT
- alăturat
- jpg
- A pastra
- păstrare
- chei
- lac
- lacuri
- mai mare
- latitudine
- Conduce
- AFLAȚI
- mai puțin
- Permite
- ca
- limitări
- linux
- fundația linux
- Listă
- încărca
- locaţie
- Locații
- log
- mai lung
- Uite
- cautati
- dragoste
- magie
- administra
- administrare
- manager
- manieră
- multe
- pieţe
- max
- maxim
- Îmbina
- Metadata
- minute
- minim
- mai mult
- multiplu
- nume
- nativ
- Navigaţi
- Nevoie
- necesar
- nu
- Nou
- Nu.
- nota
- caiet
- notebook-uri
- număr
- obiect
- Depozitarea obiectelor
- obiecte
- of
- promoții
- de multe ori
- Vechi
- mai în vârstă
- on
- ONE
- afară
- OP
- deschide
- open-source
- operaţie
- Operațiuni
- Optimizați
- Opțiune
- Opţiuni
- or
- comandă
- al nostru
- producție
- depășirea
- propriu
- parte
- pasionat
- trecut
- efectua
- performanță
- Plato
- Informații despre date Platon
- PlatoData
- Popular
- Post
- premise
- precedent
- în prealabil
- primar
- procedură
- prelucrare
- produce
- Produs
- manager de produs
- Produse
- proprietăţi
- Piton
- interogări
- tarife
- Crud
- Citeste
- Citind
- recomandat
- inregistrata
- înregistrări
- reduce
- trimite
- referință
- de încredere
- scoate
- Îndepărtează
- eliminarea
- înlocui
- necesar
- rezultat
- rezultând
- cu amănuntul
- retenţie
- robust
- Alerga
- funcţionare
- acelaşi
- scalabil
- Scară
- Seattle
- Al doilea
- Secțiune
- vedea
- selecta
- selectarea
- distinct
- serviciu
- Servicii
- sesiune
- set
- să
- Arăta
- indicat
- Emisiuni
- semnificativ
- simplu
- Simplifică
- simplifica
- întrucât
- Mărimea
- ușor diferite
- SLP
- mic
- mai mici
- inteligent
- Instantaneu
- So
- soluţii
- Sursă
- Spaţiu
- Scânteie
- special
- specific
- specific
- specificată
- viteză
- viteze
- uzat
- SQL
- Începe
- Declarație
- Declarații
- staţie
- Pas
- paşi
- Încă
- depozitare
- stoca
- stocate
- Strategie
- Şir
- astfel de
- Suportat
- sistem
- sisteme
- tabel
- Tacoma
- decât
- acea
- lor
- Lor
- apoi
- Acestea
- acest
- prag
- Prin
- timp
- timp de călătorie
- timestamp-ul
- la
- Urmărire
- tranzacțional
- Tranzacții
- călătorie
- tip
- fără egal
- Actualizează
- actualizat
- actualizări
- us
- Folosire
- utilizare
- utilizat
- folosind
- Vid
- valoare
- versiune
- Versiunile
- vrea
- a fost
- modalități de
- we
- web
- servicii web
- au fost
- cand
- care
- în timp ce
- voi
- cu
- fără
- Apartamente
- scrie
- an
- tu
- Ta
- zephyrnet