Modelele de limbaj mari (LLM) devin din ce în ce mai populare, noi cazuri de utilizare fiind explorate în mod constant. În general, puteți construi aplicații bazate pe LLM-uri prin încorporarea ingineriei prompte în cod. Cu toate acestea, există cazuri în care solicitarea unui LLM existent este insuficientă. Aici poate ajuta reglarea fină a modelului. Ingineria promptă se referă la ghidarea rezultatelor modelului prin crearea de solicitări de intrare, în timp ce reglarea fină înseamnă antrenarea modelului pe seturi de date personalizate pentru a-l face mai potrivit pentru anumite sarcini sau domenii.
Înainte de a putea regla fin un model, trebuie să găsiți un set de date specific unei sarcini. Un set de date care este utilizat în mod obișnuit este Set de date Common Crawl. Corpusul Common Crawl conține petaocteți de date, colectați în mod regulat din 2008 și conține date brute ale paginilor web, extrase de metadate și extrase de text. Pe lângă determinarea setului de date care trebuie utilizat, este necesară curățarea și procesarea datelor în funcție de nevoia specifică a reglajului fin.
Am lucrat recent cu un client care dorea să preproceseze un subset al celui mai recent set de date Common Crawl și apoi să își ajusteze LLM cu date curățate. Clientul căuta cum ar putea realiza acest lucru în cel mai rentabil mod pe AWS. După ce am discutat despre cerințe, am recomandat utilizarea Amazon EMR fără server ca platformă pentru preprocesarea datelor. EMR Serverless este potrivit pentru prelucrarea datelor la scară largă și elimină necesitatea întreținerii infrastructurii. În ceea ce privește costul, se percepe doar în funcție de resursele și durata utilizată pentru fiecare job. Clientul a putut să preproceseze sute de TB de date într-o săptămână folosind EMR Serverless. După ce au preprocesat datele, au folosit Amazon SageMaker pentru a ajusta LLM.
În această postare, vă prezentăm cazul de utilizare al clientului și arhitectura utilizată.
În secțiunile următoare, introducem mai întâi setul de date Common Crawl și cum să explorem și să filtram datele de care avem nevoie. Amazon Atena taxează doar pentru dimensiunea datelor pe care le scanează și este folosit pentru a explora și filtra datele rapid, fiind în același timp rentabil. EMR Serverless oferă o opțiune rentabilă și fără întreținere pentru procesarea datelor Spark și este utilizată pentru a procesa datele filtrate. În continuare, folosim Amazon SageMaker JumpStart pentru a regla fin Model Llama 2 cu setul de date preprocesat. SageMaker JumpStart oferă un set de soluții pentru cele mai comune cazuri de utilizare care pot fi implementate cu doar câteva clicuri. Nu trebuie să scrieți niciun cod pentru a regla fin un LLM, cum ar fi Llama 2. În cele din urmă, implementăm modelul ajustat folosind Amazon SageMaker și comparați diferențele de text pentru aceeași întrebare între modelele Llama 2 original și reglate fin.
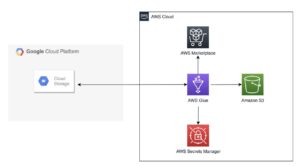
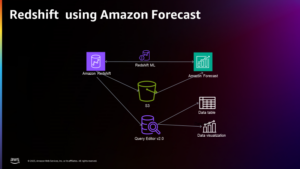
Următoarea diagramă ilustrează arhitectura acestei soluții.
Înainte de a vă aprofunda detaliile soluției, parcurgeți următorii pași prealabil:
Common Crawl este un set de date corpus deschis, obținut prin accesarea cu crawlere a peste 50 de miliarde de pagini web. Include cantități masive de date nestructurate în mai multe limbi, începând din 2008 și atingând nivelul petabyte. Este actualizat continuu.
În antrenamentul GPT-3, setul de date Common Crawl reprezintă 60% din datele sale de antrenament, așa cum se arată în următoarea diagramă (sursa: Modelele lingvistice sunt studenți puțini).
Un alt set de date important care merită menționat este Setul de date C4. C4, prescurtare pentru Colossal Clean Crawled Corpus, este un set de date derivat din postprocesarea setului de date Common Crawl. În lucrarea LLaMA a lui Meta, ei au subliniat seturile de date utilizate, Common Crawl reprezentând 67% (folosind 3.3 TB de date) și C4 pentru 15% (folosind 783 GB de date). Lucrarea subliniază importanța încorporării datelor preprocesate diferit pentru îmbunătățirea performanței modelului. În ciuda faptului că datele originale C4 fac parte din Common Crawl, Meta a optat pentru versiunea reprocesată a acestor date.
În această secțiune, acoperim modalități comune de a interacționa, filtra și procesa setul de date Common Crawl.
Setul de date brute Common Crawl include trei tipuri de fișiere de date: date brute ale paginii web (WARC), metadate (WAT) și extragerea textului (WET).
Datele colectate după 2013 sunt stocate în format WARC și includ metadatele corespunzătoare (WAT) și datele de extragere a textului (WET). Setul de date se află în Amazon S3, este actualizat lunar și poate fi accesat direct prin intermediul Piața AWS.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzSetul de date Common Crawl oferă, de asemenea, un tabel index pentru filtrarea datelor, care se numește cc-index-table.
cc-index-table este un index al datelor existente, oferind un index bazat pe tabel al fișierelor WARC. Permite o căutare ușoară a informațiilor, cum ar fi fișierul WARC care corespunde unei anumite adrese URL.
De exemplu, puteți crea un tabel Athena pentru a mapa datele cc-index cu următorul cod:
Instrucțiunile SQL precedente demonstrează cum să creați un tabel Athena, să adăugați partiții și să rulați o interogare.
Filtrați datele din setul de date Common Crawl
După cum puteți vedea din instrucțiunea SQL create table, există mai multe câmpuri care pot ajuta la filtrarea datelor. De exemplu, dacă doriți să obțineți numărul documentelor chinezești într-o anumită perioadă, atunci instrucțiunea SQL ar putea fi după cum urmează:
Dacă doriți să faceți o procesare ulterioară, puteți salva rezultatele într-un alt bucket S3.
Analizați datele filtrate
Depozitul GitHub de acces cu crawlere comun oferă mai multe exemple PySpark pentru procesarea datelor brute.
Să ne uităm la un exemplu de alergare server_count.py (exemplu de script furnizat de depozitul GitHub Common Crawl) privind datele aflate în s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
În primul rând, aveți nevoie de un mediu Spark, cum ar fi EMR Spark. De exemplu, puteți lansa un Amazon EMR pe cluster EC2 în us-east-1 (deoarece setul de date este în us-east-1). Utilizarea unui EMR pe cluster EC2 vă poate ajuta să efectuați teste înainte de a trimite lucrări în mediul de producție.
După lansarea unui EMR pe cluster EC2, trebuie să faceți o conectare SSH la nodul principal al clusterului. Apoi, împachetați mediul Python și trimiteți scriptul (consultați documentatie Conda pentru a instala Miniconda):
Procesarea tuturor referințelor din warc.path poate dura timp. În scopuri demonstrative, puteți îmbunătăți timpul de procesare cu următoarele strategii:
- Descărcați fișierul
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzpe mașina dvs. locală, dezarhivați-l și apoi încărcați-l pe HDFS sau Amazon S3. Acest lucru se datorează faptului că fișierul .gzip nu poate fi divizat. Trebuie să-l dezarhivați pentru a procesa acest fișier în paralel. - Modificați
warc.pathfișier, ștergeți majoritatea liniilor sale și păstrați doar două rânduri pentru ca lucrarea să ruleze mult mai rapid.
După finalizarea lucrării, puteți vedea rezultatul în s3://xxxx-common-crawl/output/, în format parchet.
Implementați o logică personalizată a posesiei
Repozitorul GitHub Common Crawl oferă o abordare comună pentru procesarea fișierelor WARC. În general, puteți extinde CCSparkJob pentru a suprascrie o singură metodă (process_record), ceea ce este suficient pentru multe cazuri.
Să ne uităm la un exemplu pentru a obține recenziile IMDB ale filmelor recente. Mai întâi, trebuie să filtrați fișierele de pe site-ul IMDB:
Apoi puteți obține liste de fișiere WARC care conțin date de revizuire IMDB și puteți salva numele fișierelor WARC ca listă într-un fișier text.
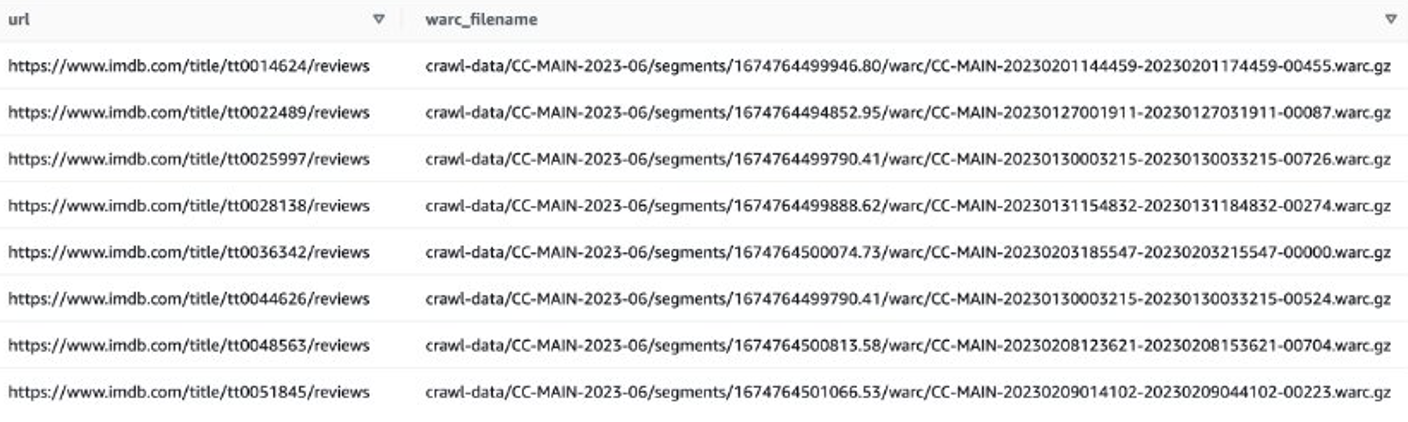
Alternativ, puteți utiliza EMR Spark pentru a obține lista de fișiere WARC și a o stoca în Amazon S3. De exemplu:
Fișierul de ieșire ar trebui să arate similar cu s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
Următorul pas este extragerea recenziilor utilizatorilor din aceste fișiere WARC. Puteți extinde CCSparkJob pentru a trece peste process_record() metodă:
Puteți salva scriptul precedent ca imdb_extractor.py, pe care îl veți folosi în următorii pași. După ce ați pregătit datele și scripturile, puteți utiliza EMR Serverless pentru a procesa datele filtrate.
EMR fără server
EMR Serverless este o opțiune de implementare fără server pentru a rula aplicații de analiză a datelor mari folosind cadre open source precum Apache Spark și Hive, fără a configura, gestiona și scala clustere sau servere.
Cu EMR Serverless, puteți rula sarcini de lucru de analiză la orice scară, cu scalare automată care redimensionează resursele în câteva secunde pentru a satisface volumele de date în schimbare și cerințele de procesare. EMR Serverless scalează automat resursele în sus și în jos pentru a oferi capacitatea potrivită pentru aplicația dvs. și plătiți doar pentru ceea ce utilizați.
Procesarea setului de date Common Crawl este, în general, o sarcină de procesare unică, ceea ce îl face potrivit pentru încărcăturile de lucru fără server EMR.
Creați o aplicație EMR Serverless
Puteți crea o aplicație EMR Serverless pe consola EMR Studio. Parcurgeți următorii pași:
- Pe consola EMR Studio, alegeți aplicatii în serverless în panoul de navigare.
- Alege Creați aplicația.

- Furnizați un nume pentru aplicație și alegeți o versiune Amazon EMR.

- Dacă este necesar accesul la resursele VPC, adăugați o setare de rețea personalizată.

- Alege Creați aplicația.
Mediul dumneavoastră fără server Spark va fi apoi gata.
Înainte de a putea trimite o lucrare la EMR Spark Serverless, mai trebuie să creați un rol de execuție. A se referi la Noțiuni introductive cu Amazon EMR Serverless pentru mai multe detalii.
Procesați datele Common Crawl cu EMR Serverless
După ce aplicația dvs. EMR Spark Serverless este gata, parcurgeți următorii pași pentru a procesa datele:
- Pregătiți un mediu Conda și încărcați-l pe Amazon S3, care va fi folosit ca mediu în EMR Spark Serverless.
- Încărcați scripturile care urmează să fie rulate într-un bucket S3. În exemplul următor, există două scripturi:
- imbd_extractor.py – Logica personalizată pentru extragerea conținutului din setul de date. Conținutul poate fi găsit mai devreme în această postare.
- cc-pyspark/sparkcc.py – Exemplul de cadru PySpark din Common Crawl Repo GitHub, care este necesar să fie inclus.
- Trimiteți jobul PySpark la EMR Serverless Spark. Definiți următorii parametri pentru a rula acest exemplu în mediul dvs.:
- ID-ul aplicației – ID-ul aplicației dvs. EMR Serverless.
- executie-rol-arn – Rolul dvs. de execuție EMR Serverless. Pentru a-l crea, consultați Creați un rol de rulare a jobului.
- Locația fișierului WARC – Locația fișierelor dvs. WARC.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtconține lista de fișiere WARC filtrată, pe care ați obținut-o mai devreme în această postare. - spark.sql.warehouse.dir – Locația implicită a depozitului (utilizați directorul S3).
- scânteie.arhive – Locația S3 a mediului Conda pregătit.
- spark.submit.pyFiles – Scriptul PySpark pregătit sparkcc.py.
Consultați următorul cod:
După finalizarea lucrării, recenziile extrase sunt stocate în Amazon S3. Pentru a verifica conținutul, puteți utiliza Amazon S3 Select, așa cum se arată în următoarea captură de ecran.
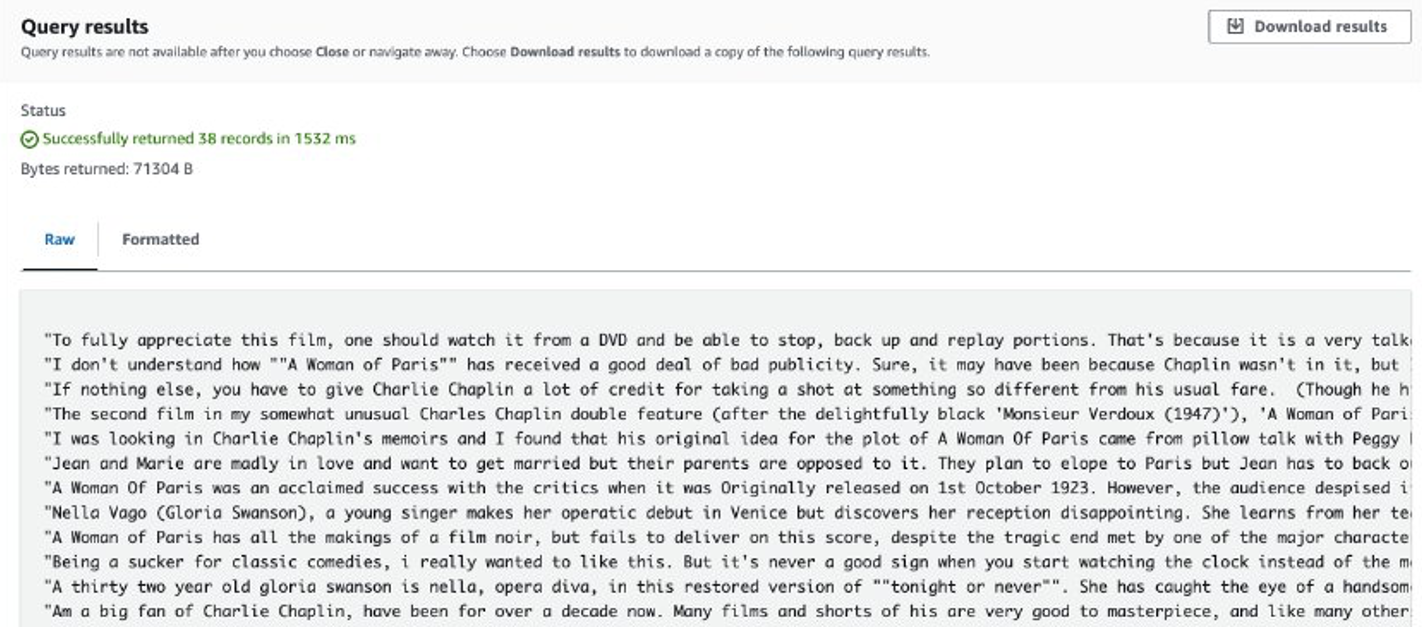
Considerații
Următoarele sunt punctele de luat în considerare atunci când aveți de-a face cu cantități masive de date cu cod personalizat:
- Este posibil ca unele biblioteci Python terțe să nu fie disponibile în Conda. În astfel de cazuri, puteți trece la un mediu virtual Python pentru a construi mediul de rulare PySpark.
- Dacă există o cantitate masivă de date de procesat, încercați să creați și să utilizați mai multe aplicații EMR Serverless Spark pentru a le paraleliza. Fiecare aplicație se ocupă cu un subset de liste de fișiere.
- Este posibil să întâmpinați o problemă de încetinire cu Amazon S3 la filtrarea sau procesarea datelor Common Crawl. Acest lucru se datorează faptului că compartimentul S3 care stochează datele este accesibil public, iar alți utilizatori pot accesa datele în același timp. Pentru a atenua această problemă, puteți adăuga un mecanism de reîncercare sau puteți sincroniza anumite date din compartimentul Common Crawl S3 în propriul compartiment.
Reglați fin Llama 2 cu SageMaker
După ce datele sunt pregătite, puteți ajusta cu ele un model Llama 2. Puteți face acest lucru folosind SageMaker JumpStart, fără a scrie niciun cod. Pentru mai multe informații, consultați Reglați fin Llama 2 pentru generarea de text pe Amazon SageMaker JumpStart.
În acest scenariu, efectuați o reglare fină a adaptării domeniului. Cu acest set de date, intrarea constă dintr-un fișier CSV, JSON sau TXT. Trebuie să puneți toate datele de revizuire într-un fișier TXT. Pentru a face acest lucru, puteți trimite o lucrare Spark simplă către EMR Spark Serverless. Vedeți următorul fragment de cod exemplu:
După ce pregătiți datele de antrenament, introduceți locația datelor pentru Set de date de antrenament, Apoi alegeți Tren.
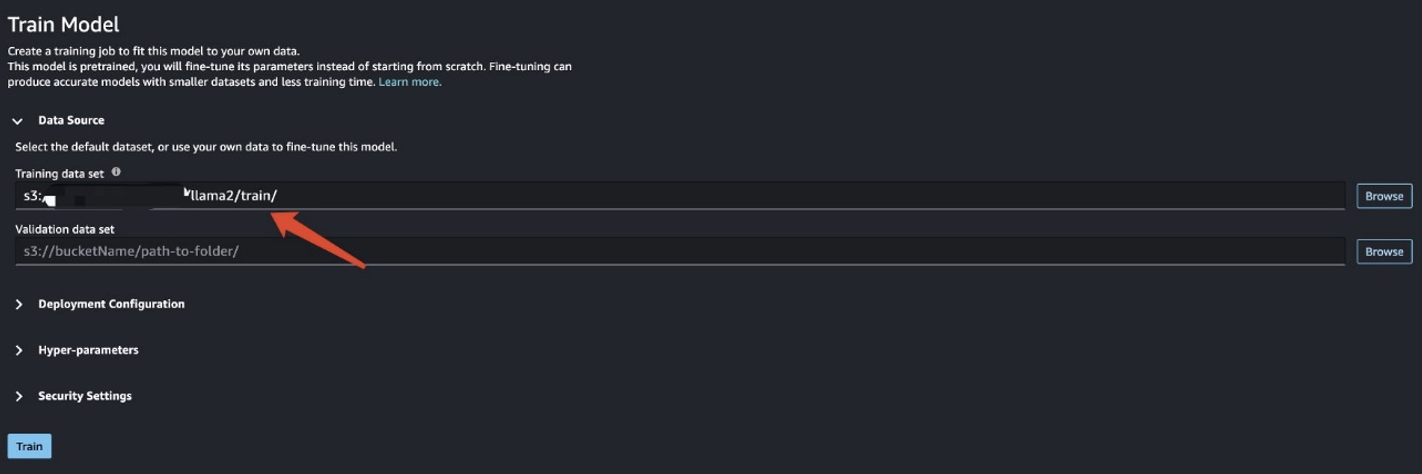
Puteți urmări starea jobului de formare.
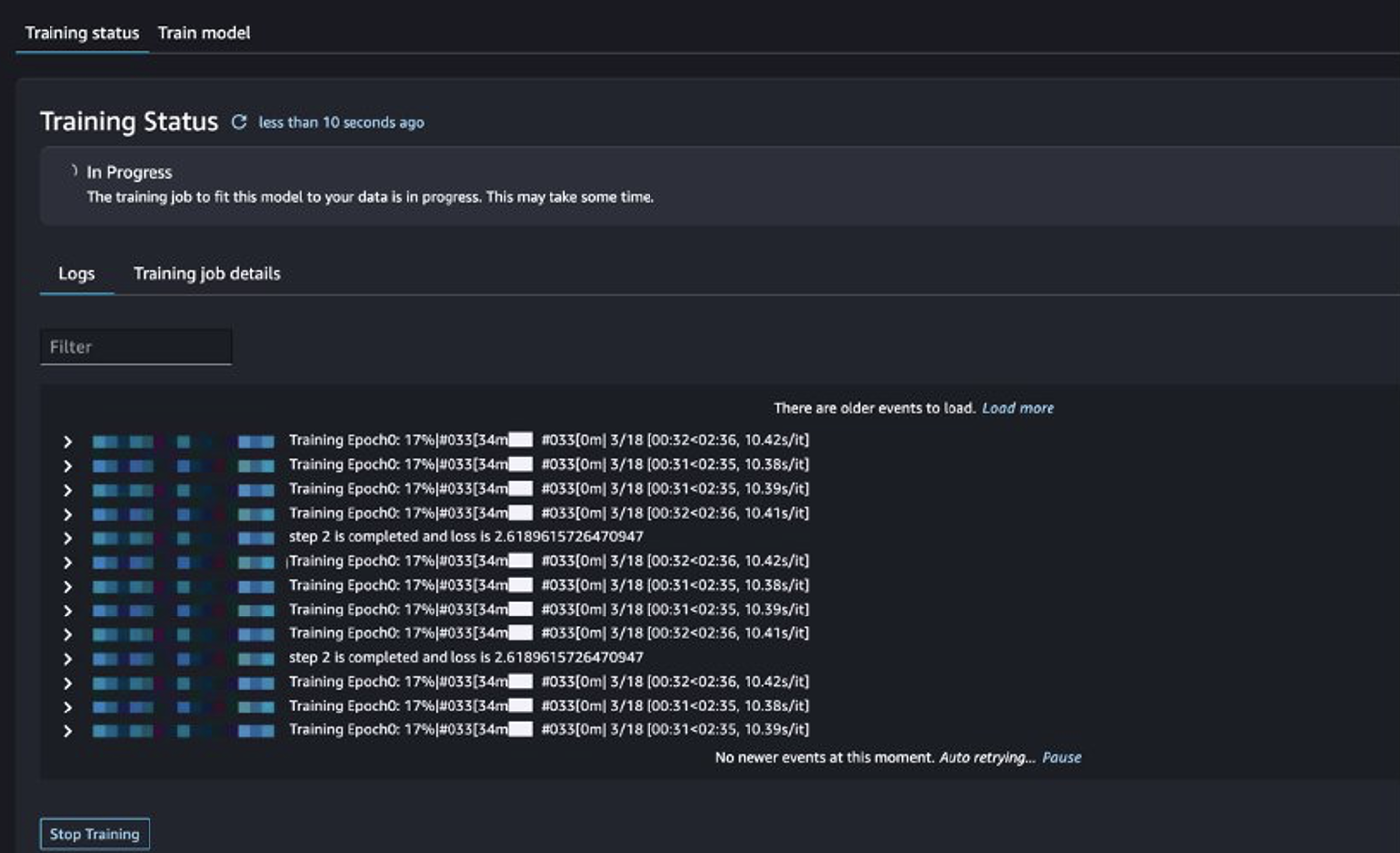
Evaluați modelul reglat fin
După terminarea antrenamentului, alegeți Lansa în SageMaker JumpStart pentru a vă implementa modelul reglat fin.

După ce modelul este implementat cu succes, alegeți Deschide Notebook, care vă redirecționează către un caiet Jupyter pregătit unde puteți rula codul dvs. Python.

Puteți utiliza imaginea Data Science 2.0 și kernel-ul Python 3 pentru notebook.
Apoi, puteți evalua modelul reglat fin și modelul original în acest notebook.
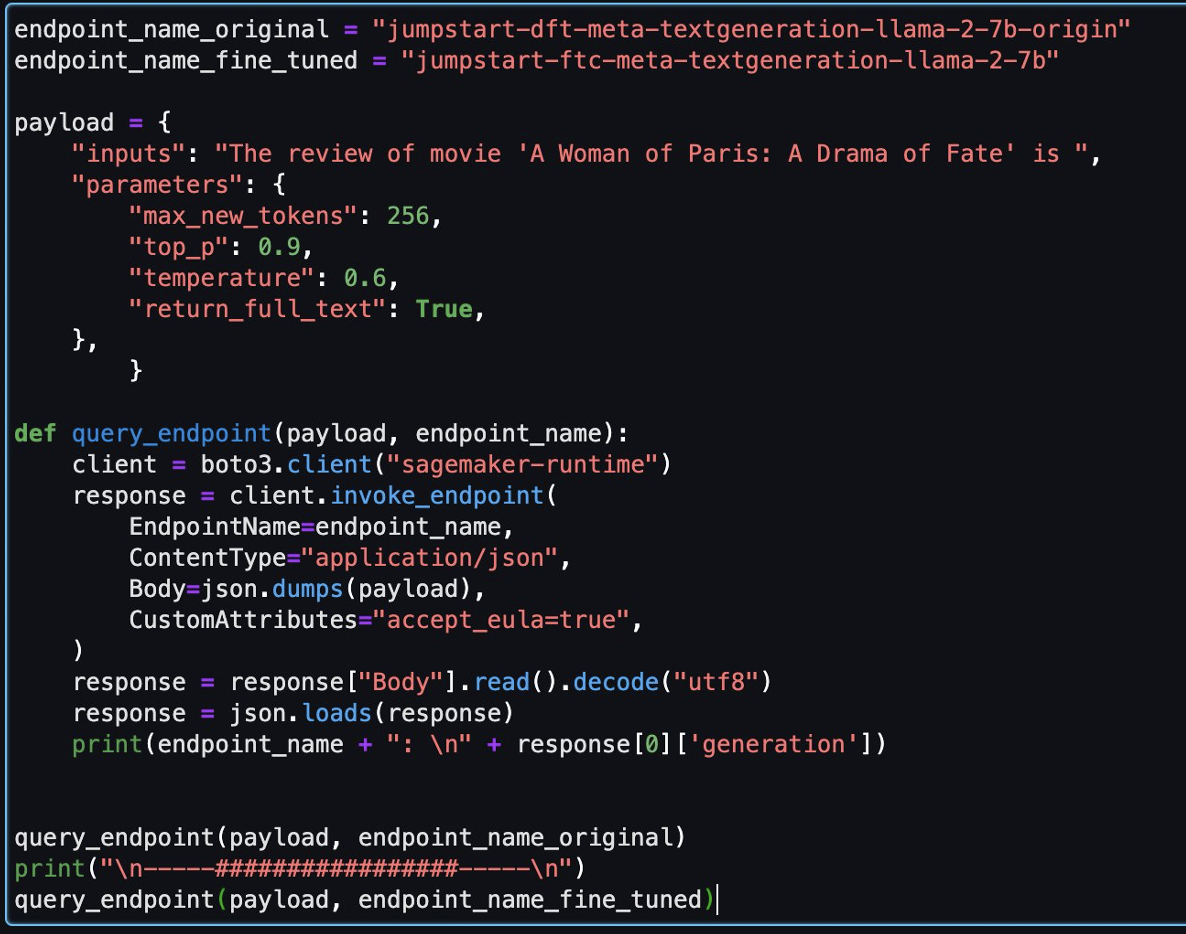
Următoarele sunt două răspunsuri returnate de modelul original și modelul ajustat pentru aceeași întrebare.

Am oferit ambelor modele aceeași propoziție: „Recenzia filmului „A Woman of Paris: A Drama of Fate” este” și le-am lăsat să completeze propoziția.
Modelul original produce propoziții fără sens:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
În schimb, ieșirile modelului reglat fin sunt mai degrabă ca o recenzie de film:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Evident, modelul reglat fin funcționează mai bine în acest scenariu specific.
A curăța
După ce terminați acest exercițiu, parcurgeți următorii pași pentru a vă curăța resursele:
- Ștergeți găleata S3 care stochează setul de date curățat.
- Opriți mediul EMR Serverless.
- Ștergeți punctul final SageMaker care găzduiește modelul LLM.
- Ștergeți domeniul SageMaker care rulează caietele tale.
Aplicația pe care ați creat-o ar trebui să se oprească automat după 15 minute de inactivitate în mod implicit.
În general, nu trebuie să curățați mediul Athena, deoarece nu există taxe atunci când nu îl utilizați.
Concluzie
În această postare, am prezentat setul de date Common Crawl și cum să folosiți EMR Serverless pentru a procesa datele pentru reglarea fină a LLM. Apoi am demonstrat cum să folosiți SageMaker JumpStart pentru a regla fin LLM și a-l implementa fără niciun cod. Pentru mai multe cazuri de utilizare a EMR Serverless, consultați Amazon EMR fără server. Pentru mai multe informații despre găzduirea și reglarea fină a modelelor pe Amazon SageMaker JumpStart, consultați Documentația Sagemaker JumpStart.
Despre Autori
 Shijian Tang este arhitect de soluții specializat în analize la Amazon Web Services.
Shijian Tang este arhitect de soluții specializat în analize la Amazon Web Services.
 Matthew Liem este Senior Solution Architecture Manager la Amazon Web Services.
Matthew Liem este Senior Solution Architecture Manager la Amazon Web Services.
 Dalei Xu este arhitect de soluții specializat în analize la Amazon Web Services.
Dalei Xu este arhitect de soluții specializat în analize la Amazon Web Services.
 Yuanjun Xiao este arhitect senior de soluții la Amazon Web Services.
Yuanjun Xiao este arhitect senior de soluții la Amazon Web Services.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :este
- :nu
- :Unde
- $UP
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- Capabil
- Despre Noi
- acces
- accesate
- accesibil
- Contabilitate
- Conturi
- Obține
- activa
- adăuga
- plus
- Africa
- După
- TOATE
- permite
- de asemenea
- uimitor
- Amazon
- Amazon EMR
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- sumă
- Sume
- an
- Google Analytics
- și
- O alta
- Orice
- Apache
- Apache Spark
- aplicație
- aplicatii
- abordare
- arhitectură
- SUNT
- AS
- At
- australian
- Automat
- în mod automat
- disponibil
- AWS
- fundal
- bazat
- bază
- BE
- frumos
- deoarece
- devenire
- înainte
- începe
- fiind
- Mai bine
- între
- Mare
- Datele mari
- Miliard
- corp
- atât
- construi
- by
- denumit
- CAN
- Poate obține
- Capacitate
- transporta
- caz
- cazuri
- schimbarea
- caracter
- taxe
- verifica
- chinez
- Alege
- clasă
- curat
- client
- Grup
- cod
- COM
- Comun
- în mod obișnuit
- comparaţie
- Completă
- configurarea
- Lua în considerare
- constă
- Consoleze
- mereu
- conţine
- conține
- conținut
- continuu
- contrast
- Corespunzător
- corespunde
- A costat
- cost-eficiente
- ar putea
- conta
- acoperi
- crea
- a creat
- personalizat
- client
- personalizate
- de date
- Analiza datelor
- de prelucrare a datelor
- știința datelor
- seturi de date
- Davis
- abuzive
- Oferte
- adânc
- Mod implicit
- defini
- Demo
- demonstra
- demonstrat
- implementa
- dislocate
- desfășurarea
- Derivat
- În ciuda
- detalii
- determinarea
- diagramă
- diferenţele
- diferit
- dirijat
- direct
- discutarea
- scufunda
- do
- documente
- domeniu
- domenii
- Donald
- Dont
- jos
- Dramă
- şofer
- durată
- în timpul
- fiecare
- Mai devreme
- uşor
- elimină
- subliniază
- întâlni
- Inginerie
- consolidarea
- Intrați
- Mediu inconjurator
- Eter (ETH)
- evalua
- exemplu
- exemple
- execuție
- Exercita
- existent
- există
- explora
- explorat
- extinde
- extern
- extrage
- extracţie
- extracte
- Falls
- fals
- mai repede
- soartă
- Recomandate
- puțini
- Domenii
- Fișier
- Fişiere
- filtru
- filtrare
- În cele din urmă
- Găsi
- termina
- First
- următor
- urmează
- Pentru
- format
- găsit
- Cadru
- cadre
- din
- mai mult
- General
- în general
- generator
- generaţie
- obține
- merge
- GitHub
- călăuzitor
- Avea
- ajutor
- Stup
- găzduire
- Gazdele
- Cum
- Cum Pentru a
- Totuși
- HTML
- HTTPS
- sute
- i
- IAM
- ID
- if
- ilustrează
- imagine
- import
- important
- îmbunătăţi
- in
- inclus
- include
- care încorporează
- crescând
- index
- informații
- Infrastructură
- intrare
- intrări
- instala
- interacţiona
- în
- introduce
- introdus
- problema
- IT
- ESTE
- jack
- Loc de munca
- Locuri de munca
- JSON
- Jupiter Notebook
- doar
- A pastra
- Cheie
- limbă
- Limbă
- pe scară largă
- Ultimele
- lansa
- lansare
- conduce
- lăsa
- Nivel
- biblioteci
- ca
- LIMITĂ
- linii
- Listă
- liste
- Lamă
- LLM
- local
- situat
- locaţie
- logică
- Logare
- Uite
- cautati
- căutare
- maşină
- întreținere
- face
- Efectuarea
- manager
- de conducere
- multe
- Hartă
- masiv
- Mai..
- mecanism
- Întâlni
- se intalneste
- menționând
- meta
- Metadata
- metodă
- minute
- diminua
- model
- Modele
- lunar
- mai mult
- cele mai multe
- film
- Filme
- mult
- multiplu
- nume
- nume
- Navigare
- necesar
- Nevoie
- reţea
- Nou
- următor
- Nu.
- nod
- caiet
- notebook-uri
- obținut
- octombrie
- of
- on
- ONE
- afară
- deschide
- open-source
- Opțiune
- or
- original
- Altele
- afară
- a subliniat
- producție
- iesiri
- peste
- trece peste
- propriu
- Ambalaj
- pachet
- pâine
- Hârtie
- Paralel
- parametrii
- Paris
- parte
- cale
- căi
- Plătește
- oameni
- performanță
- spectacole
- efectuează
- perioadă
- petabyte
- Peter
- fotograf
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- intrigă
- puncte
- Popular
- Post
- alimentat
- pre
- precedent
- Pregăti
- pregătit
- primar
- proces
- prelucrate
- prelucrare
- producere
- solicitări
- furniza
- prevăzut
- furnizează
- furnizarea
- public
- scopuri
- pune
- Piton
- întrebare
- întrebare
- repede
- Crud
- date neprelucrate
- ajungând
- Citeste
- gata
- recent
- recent
- recomandat
- record
- trimite
- referințe
- regulat
- relaţie
- eliberat
- repara
- înlocui
- cereri de
- necesar
- Cerinţe
- Resurse
- răspuns
- răspunsuri
- rezultat
- REZULTATE
- revizuiască
- Recenzii
- dreapta
- Rol
- rory
- Alerga
- funcţionare
- ruleaza
- sagemaker
- acelaşi
- Economisiți
- Scară
- cântare
- scalare
- scanări
- scenariu
- Ştiinţă
- scenariu
- script-uri
- secunde
- Secțiune
- secțiuni
- vedea
- segment
- selecta
- SELF
- senior
- propoziție
- serverless
- servere
- Servicii
- set
- instalare
- câteva
- ea
- Pantaloni scurți
- să
- indicat
- semnificație
- asemănător
- întrucât
- singur
- teren
- Mărimea
- Incetineste
- fragment
- So
- soluţie
- soluţii
- supă
- Sursă
- Scânteie
- specialist
- specific
- SQL
- ssh
- început
- Pornire
- Declarație
- Declarații
- Stare
- Pas
- paşi
- Încă
- Stop
- stoca
- stocate
- magazine
- Poveste
- simplu
- strategii
- Şir
- studio
- prezenta
- depunere
- Reușit
- astfel de
- suficient
- potrivit
- Intrerupator
- sincronizare
- tabel
- Lua
- Ţintă
- Sarcină
- sarcini
- tensorflow
- termeni
- teste
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- generarea textului
- acea
- lor
- Lor
- apoi
- Acolo.
- Acestea
- ei
- terț
- acest
- trei
- Prin
- timp
- timestamp-ul
- la
- urmări
- Pregătire
- CĂLĂTORII
- adevărat
- încerca
- Două
- Tipuri
- în
- nestructurat
- actualizat
- URL-ul
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- comentarii utilizator
- utilizatorii
- folosind
- Utilizand
- versiune
- Virtual
- volume
- umbla
- vrea
- dorit
- Depozit
- a fost
- Cale..
- modalități de
- we
- web
- servicii web
- săptămână
- BINE
- Ce
- cand
- întrucât
- care
- în timp ce
- OMS
- Wildlife
- voi
- william
- cu
- în
- fără
- femeie
- a lucrat
- valoare
- scrie
- scris
- Randament
- tu
- Ta
- zephyrnet