În era digitală de astăzi, datele se află în centrul succesului fiecărei organizații. Unul dintre cele mai frecvent utilizate formate pentru schimbul de date este XML. Analiza fișierelor XML este crucială din mai multe motive. În primul rând, fișierele XML sunt utilizate în multe industrii, inclusiv în finanțe, asistență medicală și guvern. Analiza fișierelor XML poate ajuta organizațiile să obțină informații despre datele lor, permițându-le să ia decizii mai bune și să-și îmbunătățească operațiunile. Analiza fișierelor XML poate ajuta și la integrarea datelor, deoarece multe aplicații și sisteme folosesc XML ca format standard de date. Prin analizarea fișierelor XML, organizațiile pot integra cu ușurință date din diferite surse și pot asigura coerența în sistemele lor. Cu toate acestea, fișierele XML conțin date semi-structurate, foarte imbricate, ceea ce face dificilă accesarea și analizarea informațiilor, mai ales dacă fișierul este mare și are schemă complexă, foarte imbricată.
Fișierele XML sunt potrivite pentru aplicații, dar este posibil să nu fie optime pentru motoarele de analiză. Pentru a îmbunătăți performanța interogărilor și a permite accesul ușor în motoarele de analiză din aval, cum ar fi Amazon Atena, este esențial să preprocesați fișierele XML într-un format de coloană precum Parquet. Această transformare permite o eficiență și o utilizare îmbunătățită în fluxurile de lucru de analiză. În această postare, arătăm cum să procesăm datele XML folosind AWS Adeziv și Atena.
Prezentare generală a soluțiilor
Explorăm două tehnici distincte care vă pot simplifica fluxul de lucru de procesare a fișierelor XML:
- Tehnica 1: Utilizați un crawler AWS Glue și editorul vizual AWS Glue – Puteți utiliza interfața de utilizator AWS Glue împreună cu un crawler pentru a defini structura tabelului pentru fișierele dvs. XML. Această abordare oferă o interfață ușor de utilizat și este potrivită în special pentru persoanele care preferă o abordare grafică pentru gestionarea datelor.
- Tehnica 2: Utilizați AWS Glue DynamicFrames cu scheme deduse și fixe – Crawler-ul are o limitare când vine vorba de procesarea unui singur rând în fișiere XML mai mari decât 1 MB. Pentru a depăși această restricție, folosim un notebook AWS Glue pentru a construi AWS Glue
DynamicFrames, utilizând atât scheme deduse, cât și scheme fixe. Această metodă asigură gestionarea eficientă a fișierelor XML cu rânduri care depășesc 1 MB în dimensiune.
În ambele abordări, scopul nostru final este de a converti fișierele XML în format Apache Parquet, făcându-le ușor disponibile pentru interogare folosind Athena. Cu aceste tehnici, puteți îmbunătăți viteza de procesare și accesibilitatea datelor dvs. XML, permițându-vă să obțineți informații valoroase cu ușurință.
Cerințe preliminare
Înainte de a începe acest tutorial, completați următoarele cerințe preliminare (acestea se aplică ambelor tehnici):
- Descărcați fișierele XML tehnica1.xml și tehnica2.xml.
- Încărcați fișierele într-un Serviciul Amazon de stocare simplă (Amazon S3) găleată. Le puteți încărca în același bucket S3 în foldere diferite sau în diferite compartimente S3.
- Creați o Gestionarea identității și accesului AWS (IAM) pentru jobul sau blocnotesul dvs. ETL, conform instrucțiunilor din Configurați permisiunile IAM pentru AWS Glue Studio.
- Adăugați o politică integrată rolului dvs. cu deja: PassRole acțiune:
- Adăugați o politică de permisiuni la rolul cu acces la compartimentul dvs. S3.
Acum că am terminat cu cerințele preliminare, să trecem la implementarea primei tehnici.
Tehnica 1: utilizați un crawler AWS Glue și editorul vizual
Următoarea diagramă ilustrează arhitectura simplă pe care o puteți utiliza pentru a implementa soluția.
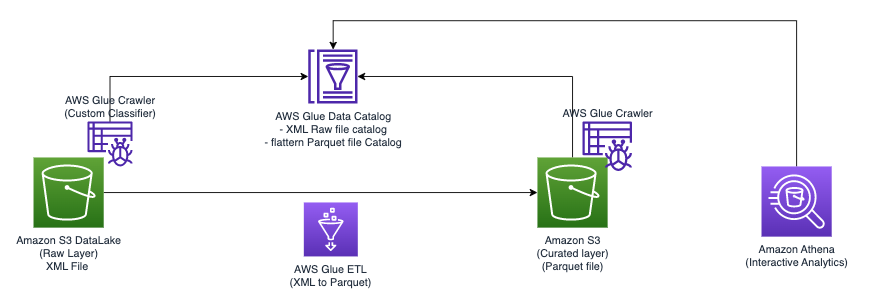
Pentru a analiza fișierele XML stocate în Amazon S3 folosind AWS Glue și Athena, parcurgem următorii pași de nivel înalt:
- Creați un crawler AWS Glue pentru a extrage metadatele XML și creați un tabel în Catalogul de date AWS Glue.
- Procesați și transformați datele XML într-un format (cum ar fi Parquet) potrivit pentru Athena utilizând o lucrare de extragere, transformare și încărcare (ETL) AWS Glue.
- Configurați și rulați o lucrare AWS Glue prin consola AWS Glue sau prin intermediul Interfața liniei de comandă AWS (CLI AWS).
- Utilizați datele procesate (în format Parquet) cu tabelele Athena, permițând interogări SQL.
- Utilizați interfața ușor de utilizat din Athena pentru a analiza datele XML cu interogări SQL pe datele dvs. stocate în Amazon S3.
Această arhitectură este o soluție scalabilă și rentabilă pentru analiza datelor XML pe Amazon S3 folosind AWS Glue și Athena. Puteți analiza seturi mari de date fără gestionarea complexă a infrastructurii.
Folosim crawler-ul AWS Glue pentru a extrage metadatele fișierului XML. Puteți alege clasificatorul AWS Glue implicit pentru clasificarea XML de uz general. Detectează automat structura și schema de date XML, ceea ce este util pentru formatele comune.
De asemenea, folosim un clasificator XML personalizat în această soluție. Este conceput pentru anumite scheme sau formate XML, permițând extragerea precisă a metadatelor. Acesta este ideal pentru formatele XML non-standard sau atunci când aveți nevoie de un control detaliat asupra clasificării. Un clasificator personalizat asigură extragerea doar a metadatelor necesare, simplificând procesarea în aval și sarcinile de analiză. Această abordare optimizează utilizarea fișierelor XML.
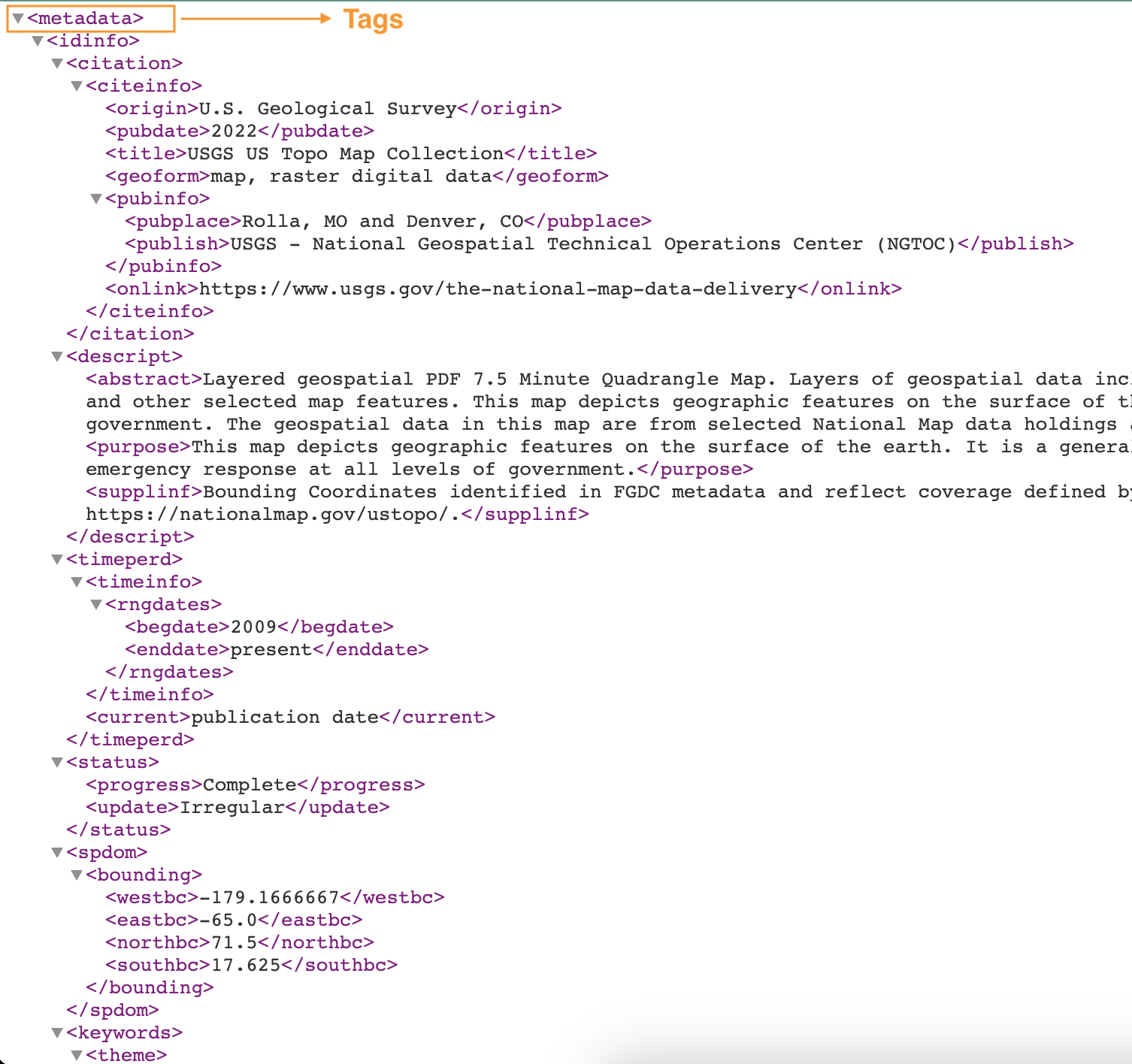
Următoarea captură de ecran arată un exemplu de fișier XML cu etichete.
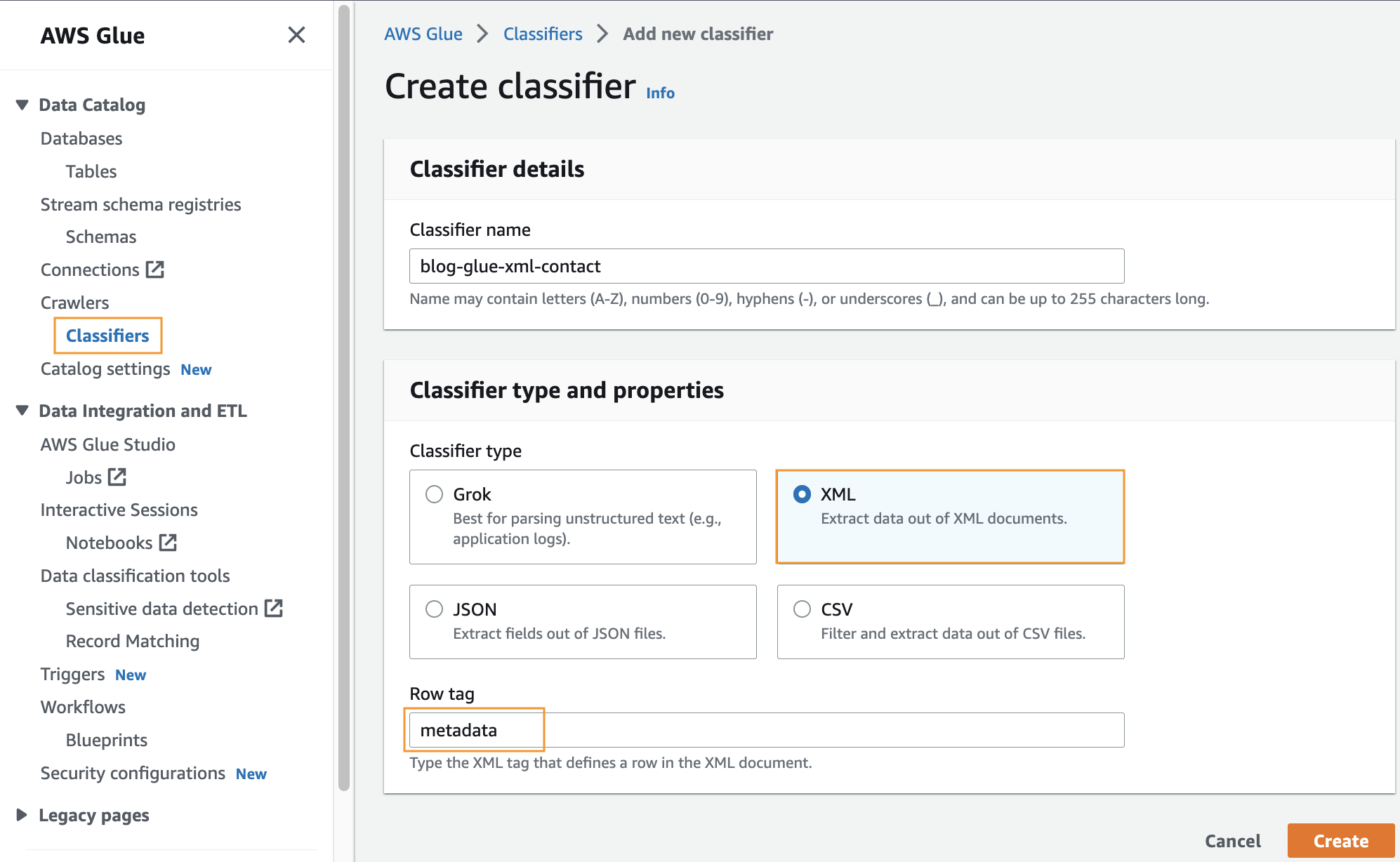
Creați un clasificator personalizat
În acest pas, creați un clasificator AWS Glue personalizat pentru a extrage metadate dintr-un fișier XML. Parcurgeți următorii pași:
- Pe consola AWS Glue, sub crawlere în panoul de navigare, alegeți Clasificatoare.
- Alege Adăugați clasificator.
- Selectați XML ca tip de clasificator.
- Introduceți un nume pentru clasificator, cum ar fi
blog-glue-xml-contact. - Pentru Etichetă de rând, introduceți numele etichetei rădăcină care conține metadatele (de exemplu,
metadata). - Alege Crea.
Creați un crawler AWS Glue pentru a accesa cu crawlere fișierul xml
În această secțiune, creăm un Glue Crawler pentru a extrage metadatele din fișierul XML folosind clasificatorul de clienți creat la pasul anterior.
Creați o bază de date
- Du-te la Consola AWS Glue, alege Baze de date în panoul de navigare.
- Faceţi clic pe Adăugați baza de date.
- Furnizați un nume precum
blog_glue_xml - Alege Crea Baza de date
Creați un crawler
Parcurgeți următorii pași pentru a vă crea primul crawler:
- Pe consola AWS Glue, alegeți crawlere în panoul de navigare.
- Alege Creați un crawler.
- Pe Setați proprietățile crawlerului pagina, furnizați un nume pentru noul crawler (cum ar fi
blog-glue-parquet), atunci alege Pagina Următoare →. - Pe Alegeți surse de date și clasificatoare pagina, selectați Nu inca în Configurarea sursei de date.
- Alege Adăugați un depozit de date.
- Pentru Calea S3, navigați la
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Asigurați-vă că alegeți folderul XML și nu fișierul din interiorul folderului.
- Lăsați restul opțiunilor ca implicite și alegeți Adăugați o sursă de date S3.
- Extinde Clasificatoare personalizate – opționale, alege blog-glue-xml-contact, apoi alege Pagina Următoare → și păstrați restul opțiunilor ca implicite.
- Alegeți rolul dvs. IAM sau alegeți Creați un nou rol IAM, adăugați sufixul
glue-xml-contact(de exemplu,AWSGlueServiceNotebookRoleBlog), și alegeți Pagina Următoare →. - Pe Setați ieșirea și programarea pagina, sub Configurare ieșire, alege
blog_glue_xmlpentru Baza de date țintă. - Intrați
console_ca prefix adăugat la tabele (opțional) și mai jos Programul crawlerului, păstrați frecvența setată la La cerere. - Alege Pagina Următoare →.
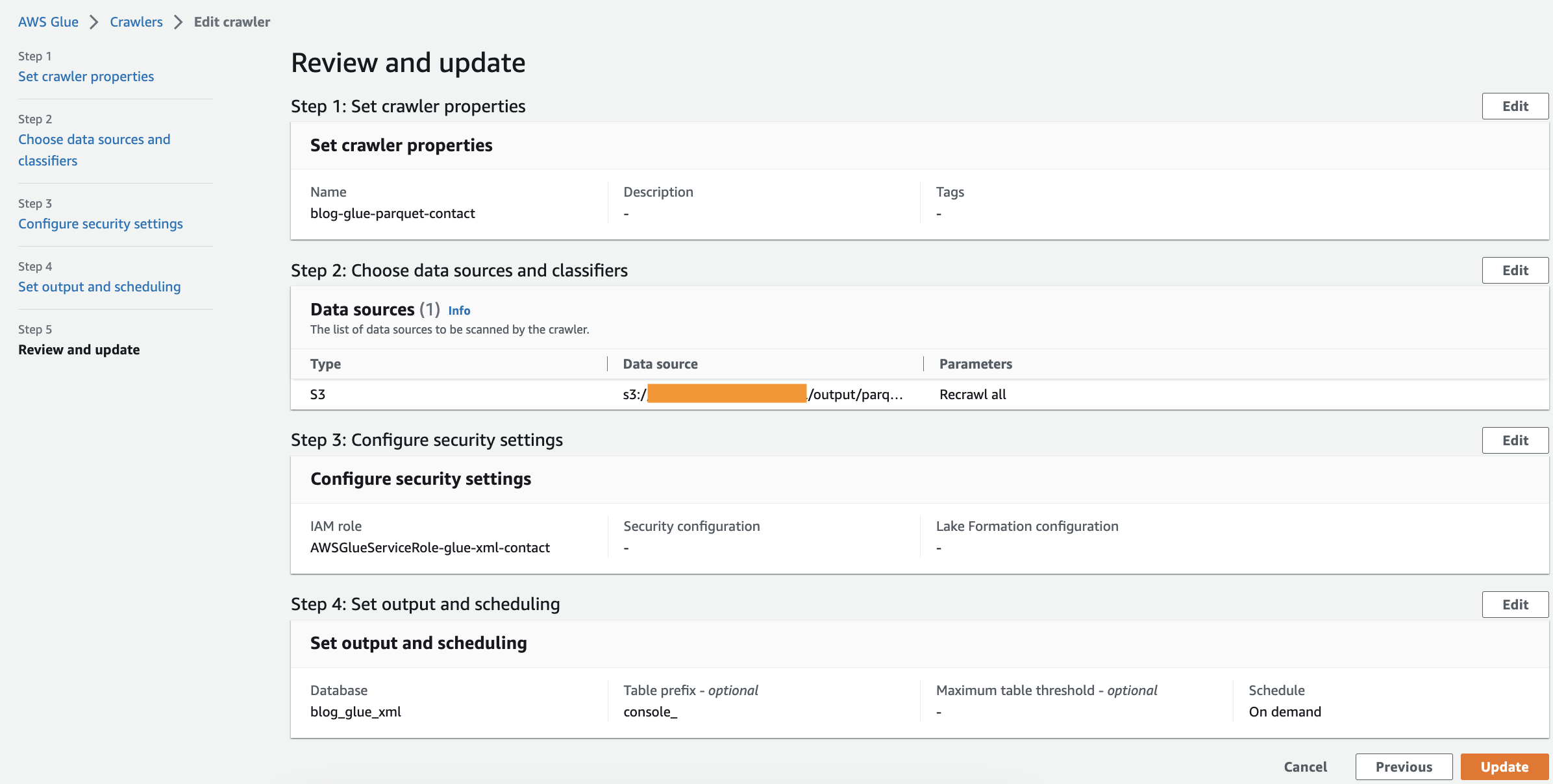
- Examinați toți parametrii și alegeți Creați un crawler.
Rulați Crawlerul
După ce creați crawler-ul, parcurgeți următorii pași pentru a-l rula:
- Pe consola AWS Glue, alegeți crawlere în panoul de navigare.
- Deschide crawler-ul pe care l-ai creat și alege Alerga.
Funcționarea crawler-ului va dura 1-2 minute.
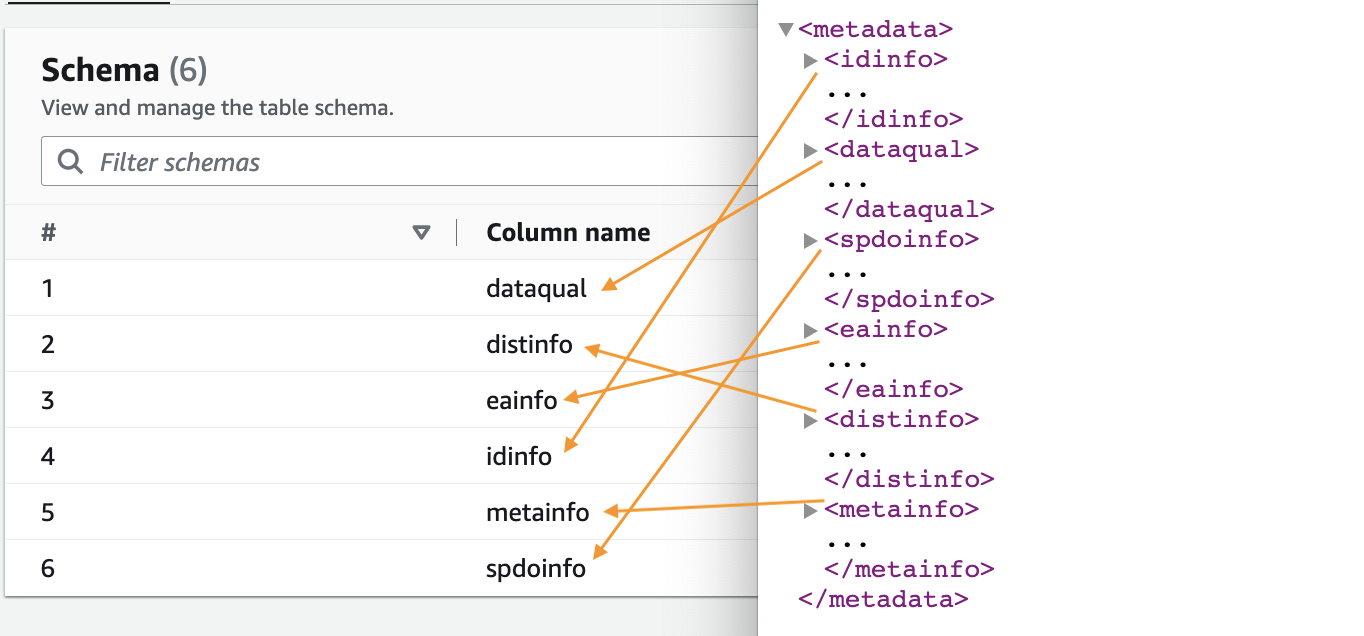
- Când crawler-ul este complet, alegeți Baze de date în panoul de navigare.
- Alegeți baza de date pe care ați creat-o și alegeți numele tabelului pentru a vedea schema extrasă de crawler.
Creați o lucrare AWS Glue pentru a converti XML în formatul Parquet
În acest pas, creați o lucrare AWS Glue Studio pentru a converti fișierul XML într-un fișier Parquet. Parcurgeți următorii pași:
- Pe consola AWS Glue, alegeți Locuri de munca în panoul de navigare.
- În Creați loc de muncă, Selectați Vizual cu o pânză goală.
- Alege Crea.
- Redenumiți jobul în
blog_glue_xml_job.
Acum aveți un editor de lucrări vizuale AWS Glue Studio necompletat. În partea de sus a editorului sunt filele pentru diferite vizualizări.
- Alege Scenariu pentru a vedea un shell gol al scriptului AWS Glue ETL.
Pe măsură ce adăugăm pași noi în editorul vizual, scriptul va fi actualizat automat.
- Alege Detaliile postului pentru a vedea toate configurațiile jobului.
- Pentru Rolul IAM, alege
AWSGlueServiceNotebookRoleBlog. - Pentru Varianta cu lipici, alege Glue 4.0 – Suport Spark 3.3, Scala 2, Python 3.
- set Numărul de muncitori solicitat la 2.
- set Numărul de reîncercări la 0.
- Alege Vizual pentru a reveni la editorul vizual.
- Pe Sursă meniul derulant, alegeți Catalogul de date AWS Glue.
- Pe Proprietățile sursei de date – Catalog de date fila, furnizați următoarele informații:
- Pentru Baza de date, alege
blog_glue_xml. - Pentru Tabel, alegeți tabelul care începe cu numele console_ pe care l-a creat crawler-ul (de exemplu,
console_geologicalsurvey).
- Pentru Baza de date, alege
- Pe Proprietățile nodului fila, furnizați următoarele informații:
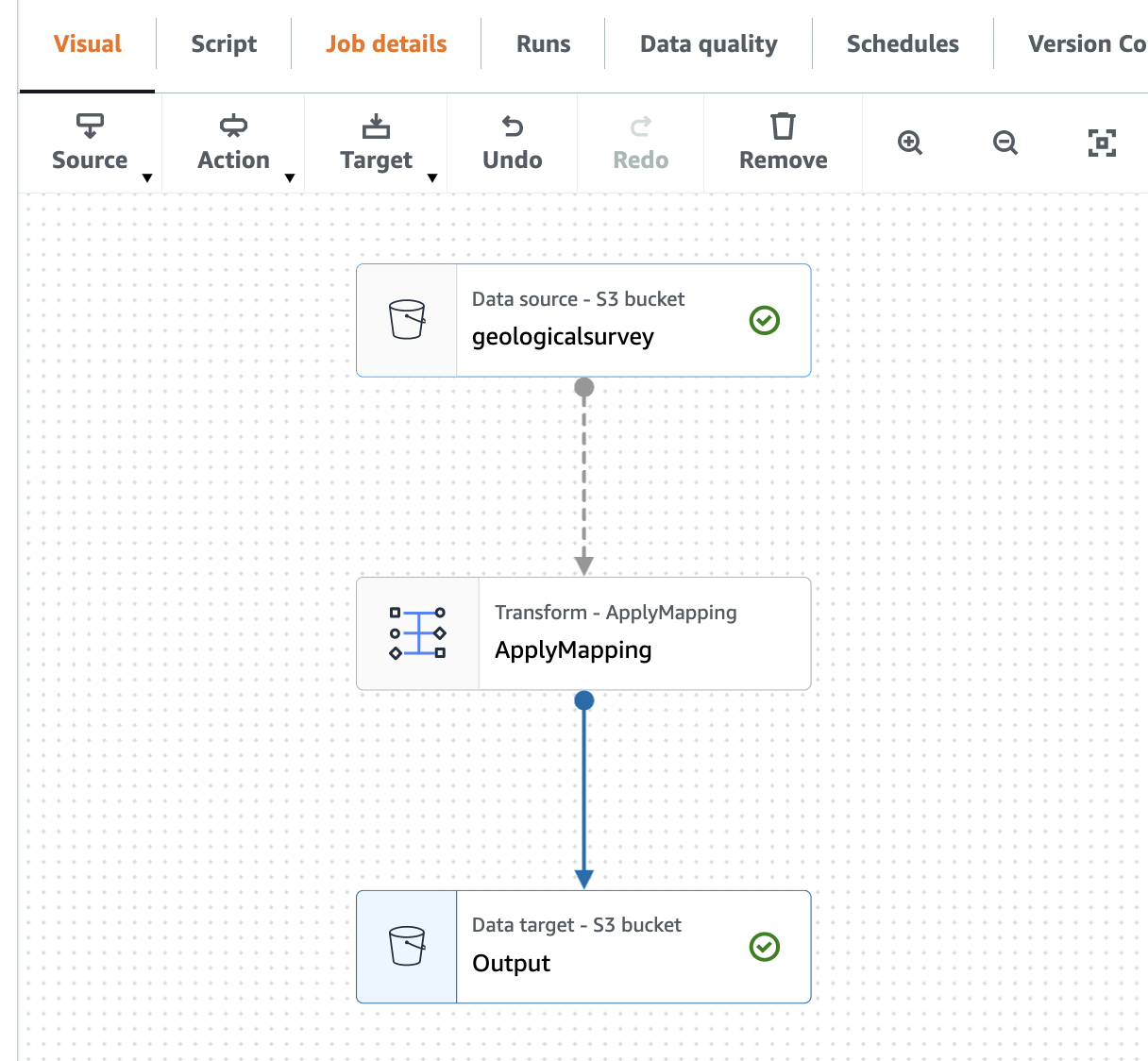
- Schimba Nume si Prenume la
geologicalsurveyset de date. - Alege Acțiune si transformarea Schimbați schema (Aplicați maparea).
- Alege Proprietățile nodului și schimbați numele transformării din Schimbare Schema (Aplicare mapare) în
ApplyMapping. - Pe Ţintă meniu, alegeți S3.
- Schimba Nume si Prenume la
- Pe Proprietățile sursei de date - S3 fila, furnizați următoarele informații:
- Pentru Format, Selectați parchet.
- Pentru Tip de compresie, Selectați Necomprimat.
- Pentru tip sursă S3, Selectați Locația S3.
- Pentru URL S3, introduce
s3://${BUCKET_NAME}/output/parquet/. - Alege Proprietățile nodului și schimbați numele în
Output.
- Alege Economisiți pentru a salva locul de muncă.
- Alege Alerga pentru a rula treaba.
Următoarea captură de ecran arată lucrarea în editorul vizual.
Creați un crawler AWS Gue pentru a accesa cu crawlere fișierul Parquet
În acest pas, creați un crawler AWS Glue pentru a extrage metadate din fișierul Parquet pe care l-ați creat folosind o lucrare AWS Glue Studio. De data aceasta, utilizați clasificatorul implicit. Parcurgeți următorii pași:
- Pe consola AWS Glue, alegeți crawlere în panoul de navigare.
- Alege Creați un crawler.
- Pe Setați proprietățile crawlerului pagina, furnizați un nume pentru noul crawler, cum ar fi blog-glue-parquet-contact, apoi alegeți Pagina Următoare →.
- Pe Alegeți surse de date și clasificatoare pagina, selectați Nu inca pentru Configurarea sursei de date.
- Alege Adăugați un depozit de date.
- Pentru Calea S3, navigați la
s3://${BUCKET_NAME}/output/parquet/.
Asigurați-vă că alegeți parquet folder, mai degrabă decât fișierul din interiorul folderului.
- Alegeți rolul dvs. IAM creat în secțiunea de cerințe preliminare sau alegeți Creați un nou rol IAM (de exemplu,
AWSGlueServiceNotebookRoleBlog), și alegeți Pagina Următoare →. - Pe Setați ieșirea și programarea pagina, sub Configurare ieșire, alege
blog_glue_xmlpentru Baza de date. - Intrați
parquet_ca prefix adăugat la tabele (opțional) și mai jos Programul crawlerului, păstrați frecvența setată la La cerere. - Alege Pagina Următoare →.
- Examinați toți parametrii și alegeți Creați un crawler.
Acum puteți rula crawler-ul, care durează 1-2 minute.

Puteți previzualiza schema nou creată pentru fișierul Parquet în AWS Glue Data Catalog, care este similară cu schema fișierului XML.
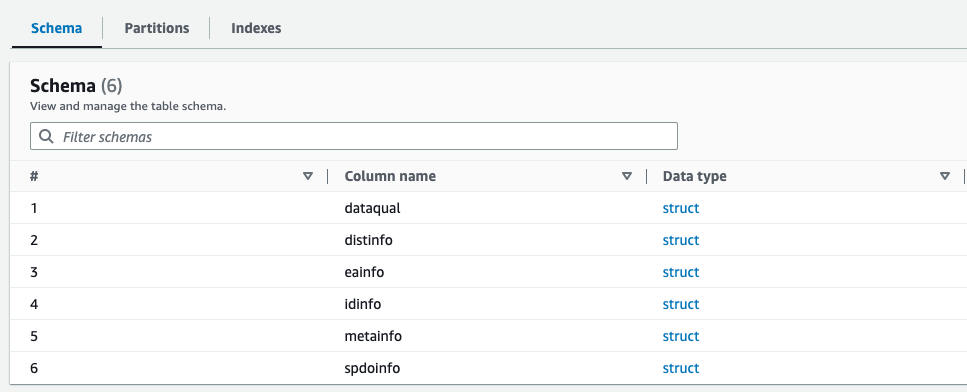
Acum deținem date care sunt potrivite pentru utilizare cu Athena. În secțiunea următoare, efectuăm interogări de date folosind Athena.
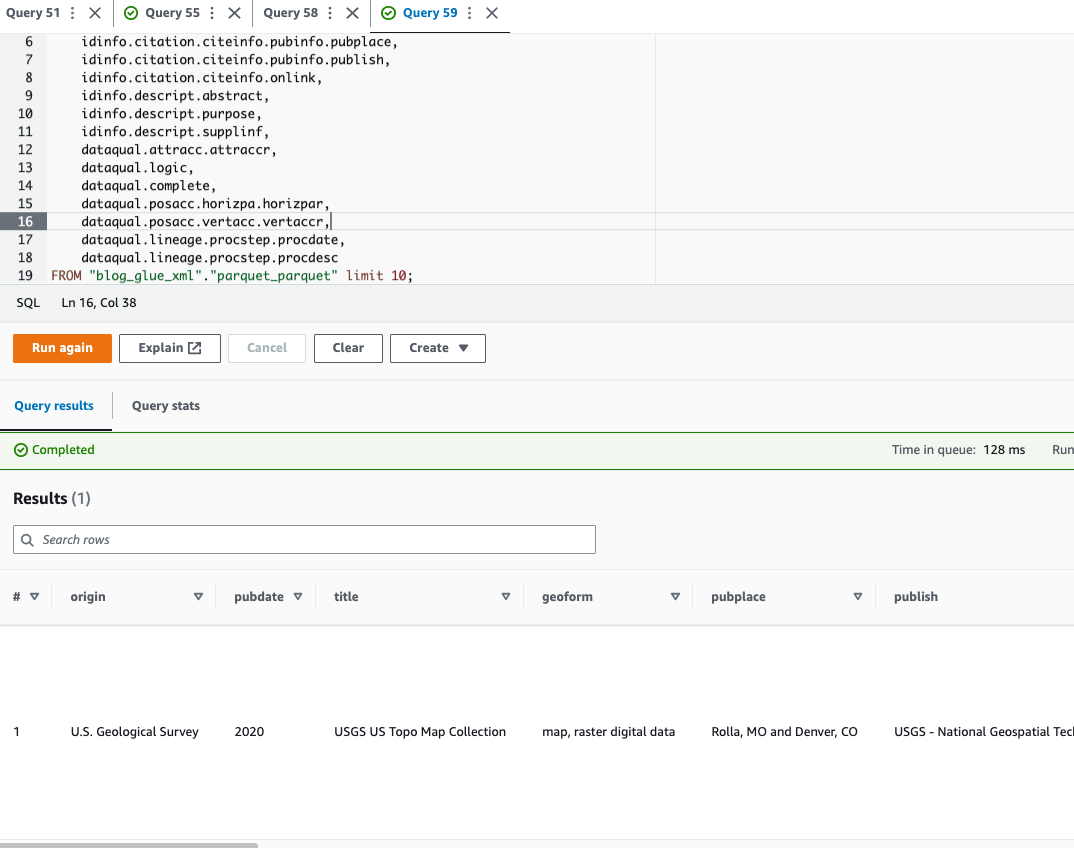
Interogați fișierul Parquet folosind Athena
Athena nu acceptă interogarea Format de fișier XML, motiv pentru care ați convertit fișierul XML în Parquet pentru interogare și utilizare mai eficientă a datelor notație cu puncte pentru a interoga tipuri complexe și structuri imbricate.
Următorul exemplu de cod folosește notația cu puncte pentru a interoga datele imbricate:
Acum că am terminat tehnica 1, să trecem la tehnica 2.
Tehnica 2: Utilizați AWS Glue DynamicFrames cu scheme deduse și fixe
În secțiunea anterioară, am acoperit procesul de manipulare a unui fișier XML mic folosind un crawler AWS Glue pentru a genera un tabel, un job AWS Glue pentru a converti fișierul în format Parquet și Athena pentru a accesa datele Parquet. Cu toate acestea, crawler-ul întâmpină limitări atunci când vine vorba de procesarea fișierelor XML care depășesc Dimensiune 1 MB. În această secțiune, vom aborda subiectul procesării în lot a fișierelor XML mai mari, necesitând o analiză suplimentară pentru a extrage evenimente individuale și a efectua analize folosind Athena.
Abordarea noastră implică citirea fișierelor XML prin AWS Glue DynamicFrames, utilizând atât scheme deduse, cât și scheme fixe. Apoi extragem evenimentele individuale în format Parquet folosind relaționați transformare, permițându-ne să le interogăm și să le analizăm fără probleme folosind Athena.
Pentru a implementa această soluție, parcurgeți următorii pași de nivel înalt:
- Creați un blocnotes AWS Glue pentru a citi și analiza fișierul XML.
- Utilizare
DynamicFramescuInferSchemapentru a citi fișierul XML. - Utilizați funcția de relaționare pentru a anula orice matrice.
- Convertiți datele în format Parquet.
- Interogați datele Parquet folosind Athena.
- Repetați pașii anteriori, dar de data aceasta transmiteți o schemă
DynamicFramesîn loc de a folosiInferSchema.
Fișierul XML de date privind populația vehiculului electric are un response eticheta la nivelul rădăcină. Această etichetă conține o serie de row etichete, care sunt imbricate în el. Eticheta de rând este o matrice care conține un set de alte etichete de rând, care oferă informații despre un vehicul, inclusiv marca, modelul și alte detalii relevante. Următoarea captură de ecran arată un exemplu.

Creați un blocnotes AWS Glue
Pentru a crea un blocnotes AWS Glue, parcurgeți următorii pași:
- Deschideți AWS Glue Studio consola, alege Locuri de munca în panoul de navigare.
- Selectați Jupiter Notebook Și alegeți Crea.
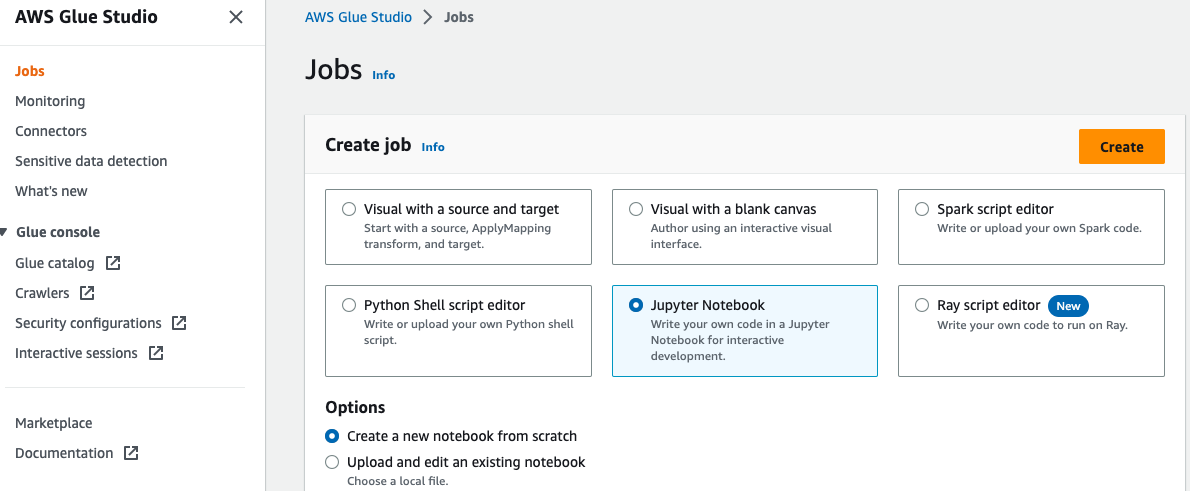
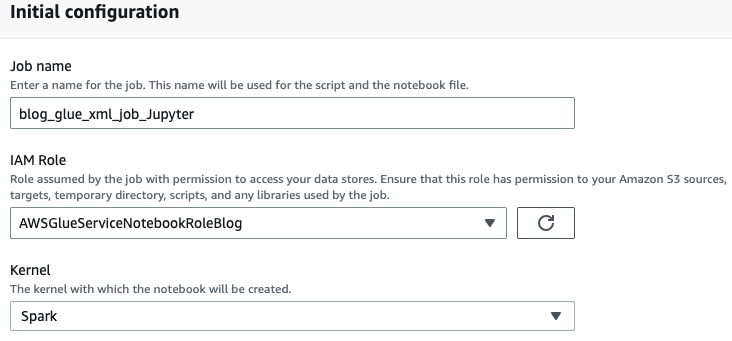
- Introduceți un nume pentru jobul dvs. AWS Glue, cum ar fi
blog_glue_xml_job_Jupyter. - Alegeți rolul pe care l-ați creat în condițiile preliminare (
AWSGlueServiceNotebookRoleBlog).
Blocnotesul AWS Glue vine cu un exemplu preexistent care demonstrează cum să interogați o bază de date și să scrieți rezultatul pe Amazon S3.
- Ajustați timpul de expirare (în minute) așa cum se arată în următoarea captură de ecran și rulați celula pentru a crea sesiunea interactivă AWS Glue.
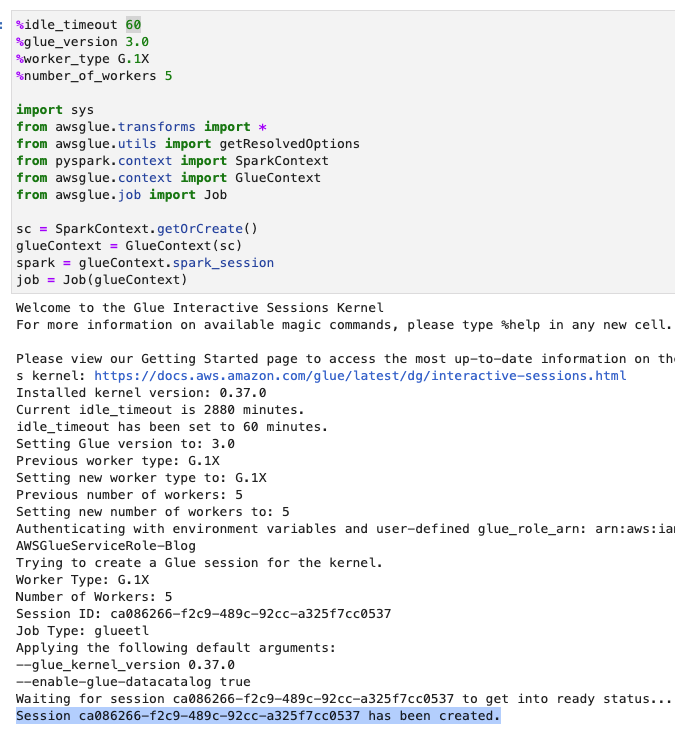
Creați variabile de bază
După ce creați sesiunea interactivă, la sfârșitul blocnotesului, creați o nouă celulă cu următoarele variabile (furnizați propriul nume de grup):
Citiți fișierul XML care deduce schema
Dacă nu treceți o schemă către DynamicFrame, va deduce schema fișierelor. Pentru a citi datele folosind un cadru dinamic, puteți folosi următoarea comandă:
Tipăriți schema DynamicFrame
Tipăriți schema cu următorul cod:
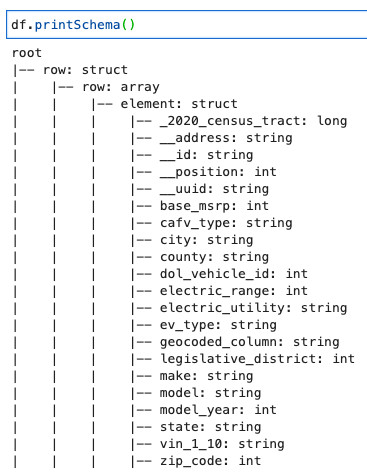
Schema arată o structură imbricată cu a row matrice care contine mai multe elemente. Pentru a anula această structură în linii, puteți utiliza AWS Glue relaționați transformare:
Suntem interesați doar de informațiile conținute în matricea de rânduri și putem vizualiza schema utilizând următoarea comandă:
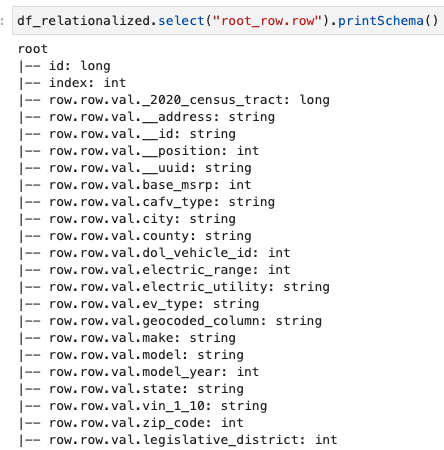
Numele coloanelor conțin row.row, care corespund structurii matricei și coloanei matricei din setul de date. Nu redenumim coloanele din această postare; pentru instrucțiuni pentru a face acest lucru, consultați Automatizați maparea dinamică și redenumirea numelor de coloane din fișierele de date folosind AWS Glue: Partea 1. Apoi puteți converti datele în format Parquet și puteți crea tabelul AWS Glue folosind următoarea comandă:
AWS Adeziv DynamicFrame oferă caracteristici pe care le puteți utiliza în scriptul dvs. ETL pentru a crea și actualiza o schemă în Catalogul de date. Noi folosim updateBehavior parametru pentru a crea tabelul direct în Catalogul de date. Cu această abordare, nu este nevoie să rulăm un crawler AWS Glue după ce sarcina AWS Glue este finalizată.

Citiți fișierul XML setând o schemă
O modalitate alternativă de a citi fișierul este prin predefinirea unei scheme. Pentru a face acest lucru, parcurgeți următorii pași:
- Importați tipurile de date AWS Glue:
- Creați o schemă pentru fișierul XML:
- Transmiteți schema când citiți fișierul XML:
- Anulați setul de date ca înainte:
- Convertiți setul de date în Parquet și creați tabelul AWS Glue:
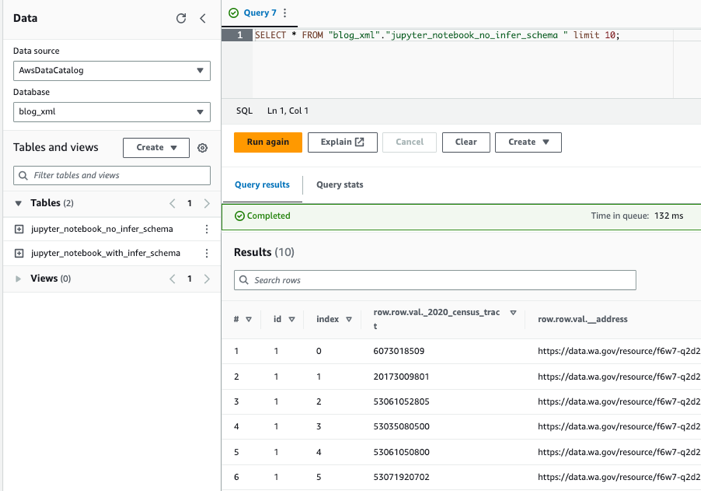
Interogați tabelele folosind Athena
Acum că am creat ambele tabele, putem interoga tabelele folosind Athena. De exemplu, putem folosi următoarea interogare:
Clean Up
În această postare, am creat un rol IAM, un notebook AWS Glue Jupyter și două tabele în Catalogul de date AWS Glue. De asemenea, am încărcat câteva fișiere într-o găleată S3. Pentru a curăța aceste obiecte, parcurgeți următorii pași:
- Pe consola IAM, ștergeți rolul pe care l-ați creat.
- Pe consola AWS Glue Studio, ștergeți clasificatorul personalizat, crawler-ul, joburile ETL și blocnotesul Jupyter.
- Navigați la AWS Glue Data Catalog și ștergeți tabelele pe care le-ați creat.
- Pe consola Amazon S3, navigați la găleata pe care ați creat-o și ștergeți folderele numite
temp,infer_schema, șino_infer_schema.
Intrebari cu cheie
În AWS Glue, există o funcție numită InferSchema în AWS Glue DynamicFrames. Acesta descoperă automat structura unui cadru de date pe baza datelor pe care le conține. În schimb, definirea unei scheme înseamnă a preciza în mod explicit cum ar trebui să fie structura cadrului de date înainte de a încărca datele.
XML, fiind un format bazat pe text, nu restricționează tipurile de date ale coloanelor sale. Acest lucru poate cauza probleme cu funcția InferSchema. De exemplu, la prima rulare, un fișier cu coloana A având o valoare de 2 are ca rezultat un fișier Parquet cu coloana A ca număr întreg. În a doua rulare, un fișier nou are coloana A cu valoarea C, ceea ce duce la un fișier Parquet cu coloana A ca șir. Acum există două fișiere pe S3, fiecare cu o coloană A de diferite tipuri de date, care pot crea probleme în aval.
Același lucru se întâmplă cu tipurile de date complexe, cum ar fi structuri imbricate sau matrice. De exemplu, dacă un fișier are o intrare de etichetă numită transaction, este dedus ca struct. Dar dacă un alt fișier are aceeași etichetă, este dedus ca o matrice
În ciuda acestor probleme de tip de date, InferSchema este util atunci când nu cunoașteți schema sau definirea manuală a uneia este impracticabilă. Cu toate acestea, nu este ideal pentru seturi de date mari sau în continuă schimbare. Definirea unei scheme este mai precisă, în special cu tipurile de date complexe, dar are propriile probleme, cum ar fi necesitatea unui efort manual și inflexibilitatea la modificările datelor.
InferSchema are limitări, cum ar fi inferența incorectă a tipului de date și probleme cu gestionarea valorilor nule. Definirea unei scheme are, de asemenea, limitări, cum ar fi efortul manual și erori potențiale.
Alegerea între deducerea și definirea unei scheme depinde de nevoile proiectului. InferSchema este excelent pentru explorarea rapidă a seturilor de date mici, în timp ce definirea unei scheme este mai bună pentru seturi de date mai mari și complexe care necesită acuratețe și consecvență. Luați în considerare compromisurile și constrângerile fiecărei metode pentru a alege ceea ce se potrivește cel mai bine proiectului dvs.
Concluzie
În această postare, am explorat două tehnici de gestionare a datelor XML folosind AWS Glue, fiecare adaptată pentru a răspunde nevoilor și provocărilor specifice pe care le puteți întâlni.
Tehnica 1 oferă o cale ușor de utilizat pentru cei care preferă o interfață grafică. Puteți utiliza un crawler AWS Glue și editorul vizual pentru a defini fără efort structura tabelului pentru fișierele dvs. XML. Această abordare simplifică procesul de gestionare a datelor și este deosebit de atrăgătoare pentru cei care caută o modalitate simplă de a-și gestiona datele.
Cu toate acestea, recunoaștem că crawler-ul are limitări, în special atunci când se ocupă de fișiere XML cu rânduri mai mari de 1 MB. Aici tehnica 2 vine în ajutor. Prin valorificarea AWS Glue DynamicFrames cu scheme atât deduse, cât și fixe și utilizând un notebook AWS Glue, puteți gestiona eficient fișierele XML de orice dimensiune. Această metodă oferă o soluție robustă care asigură o procesare fără întreruperi chiar și pentru fișierele XML cu rânduri care depășesc limita de 1 MB.
Pe măsură ce navigați în lumea managementului datelor, având aceste tehnici în setul dvs. de instrumente, vă împuterniciți să luați decizii informate pe baza cerințelor specifice ale proiectului dumneavoastră. Indiferent dacă preferați simplitatea tehnicii 1 sau scalabilitatea tehnicii 2, AWS Glue oferă flexibilitatea de care aveți nevoie pentru a gestiona datele XML în mod eficient.
Despre Autori
 Navnit Shuklaservește ca arhitect de soluții de specialitate AWS, cu accent pe Analytics. El posedă un entuziasm puternic pentru a ajuta clienții să descopere informații valoroase din datele lor. Prin expertiza sa, el construiește soluții inovatoare care permit companiilor să ajungă la alegeri informate, bazate pe date. În special, Navnit Shukla este autorul desăvârșit al cărții intitulate „Data Wrangling on AWS.
Navnit Shuklaservește ca arhitect de soluții de specialitate AWS, cu accent pe Analytics. El posedă un entuziasm puternic pentru a ajuta clienții să descopere informații valoroase din datele lor. Prin expertiza sa, el construiește soluții inovatoare care permit companiilor să ajungă la alegeri informate, bazate pe date. În special, Navnit Shukla este autorul desăvârșit al cărții intitulate „Data Wrangling on AWS.
 Patrick Muller lucrează ca arhitect senior de laborator de date la AWS. Principala lui responsabilitate este de a ajuta clienții să-și transforme ideile într-un produs de date pregătit pentru producție. În timpul liber, lui Patrick îi place să joace fotbal, să se uite la filme și să călătorească.
Patrick Muller lucrează ca arhitect senior de laborator de date la AWS. Principala lui responsabilitate este de a ajuta clienții să-și transforme ideile într-un produs de date pregătit pentru producție. În timpul liber, lui Patrick îi place să joace fotbal, să se uite la filme și să călătorească.
 Amogh Gaikwad este dezvoltator senior de soluții la Amazon Web Services. El ajută clienții globali să construiască și să implementeze soluții AI/ML pe AWS. Munca lui se concentrează în principal pe viziunea computerizată și pe procesarea limbajului natural și pe sprijinirea clienților să-și optimizeze sarcinile de lucru AI/ML pentru durabilitate. Amogh și-a primit masterul în Informatică, specializat în Machine Learning.
Amogh Gaikwad este dezvoltator senior de soluții la Amazon Web Services. El ajută clienții globali să construiască și să implementeze soluții AI/ML pe AWS. Munca lui se concentrează în principal pe viziunea computerizată și pe procesarea limbajului natural și pe sprijinirea clienților să-și optimizeze sarcinile de lucru AI/ML pentru durabilitate. Amogh și-a primit masterul în Informatică, specializat în Machine Learning.
 Sheela Sonone este arhitect rezident senior la AWS. Ea îi ajută pe clienții AWS să facă alegeri în cunoștință de cauză și să facă compromisuri cu privire la accelerarea sarcinilor și implementărilor de date, analiză și AI/ML. În timpul liber, îi place să petreacă timpul cu familia ei – de obicei pe terenurile de tenis.
Sheela Sonone este arhitect rezident senior la AWS. Ea îi ajută pe clienții AWS să facă alegeri în cunoștință de cauză și să facă compromisuri cu privire la accelerarea sarcinilor și implementărilor de date, analiză și AI/ML. În timpul liber, îi place să petreacă timpul cu familia ei – de obicei pe terenurile de tenis.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- Despre Noi
- REZUMAT
- accelerarea
- acces
- accesibilitate
- realizat
- precizie
- peste
- Acțiune
- adăuga
- adăugat
- Suplimentar
- adresa
- După
- vârstă
- AI / ML
- TOATE
- permite
- Permiterea
- permite
- de asemenea
- alternativă
- Amazon
- Amazon Atena
- Amazon Web Services
- an
- analiză
- Google Analytics
- analiza
- analiza
- și
- O alta
- Orice
- Apache
- interesant
- aplicatii
- Aplică
- abordare
- abordari
- arhitectură
- SUNT
- Mulțime
- AS
- ajuta
- asistarea
- At
- autor
- în mod automat
- disponibil
- AWS
- AWS Adeziv
- înapoi
- bazat
- de bază
- BE
- deoarece
- înainte
- începe
- fiind
- CEL MAI BUN
- Mai bine
- între
- necompletat
- carte
- atât
- construi
- întreprinderi
- dar
- by
- denumit
- CAN
- catalog
- Provoca
- celulă
- provocări
- Schimbare
- Modificări
- schimbarea
- alegeri
- Alege
- Oraș
- clasificare
- clientii
- cod
- Coloană
- Coloane
- COM
- vine
- Comun
- în mod obișnuit
- Completă
- Terminat
- complex
- calculator
- Informatică
- Computer Vision
- condiție
- Conduce
- conjuncție
- Lua în considerare
- Consoleze
- mereu
- constrângeri
- construi
- conţine
- conținute
- conține
- contrast
- Control
- converti
- convertit
- cost-eficiente
- soluție rentabilă
- județ
- Instanțe
- acoperit
- tractor pe şenile
- crea
- a creat
- Crearea
- crucial
- personalizat
- client
- clienţii care
- de date
- integrarea datelor
- management de date
- Pe bază de date
- Baza de date
- seturi de date
- abuzive
- Deciziile
- Mod implicit
- defini
- definire
- se îngropa
- demonstrează
- depinde de
- implementa
- proiectat
- detaliat
- detalii
- Dezvoltator
- diferit
- dificil
- digital
- era digitala
- direct
- descoperirea
- distinct
- do
- Nu
- făcut
- Dont
- DOT
- în timpul
- dinamic
- fiecare
- uşura
- cu ușurință
- uşor
- editor
- efect
- în mod eficient
- eficiență
- eficient
- eficient
- efort
- efort
- electric
- vehicul electric
- element
- angajarea
- împuternici
- imputerniceste
- gol
- permite
- permițând
- întâlni
- capăt
- Motoare
- spori
- asigura
- asigură
- Intrați
- entuziasm
- intrare
- Erori
- mai ales
- Eter (ETH)
- Chiar
- evenimente
- Fiecare
- exemplu
- depăși
- schimbând
- expertiză
- explorare
- explora
- explorat
- extrage
- extracţie
- familie
- Caracteristică
- DESCRIERE
- cifre
- Fișier
- Fişiere
- finanţa
- First
- fixată
- Flexibilitate
- Concentra
- concentrat
- următor
- Pentru
- format
- FRAME
- Gratuit
- Frecvență
- din
- funcţie
- Câştig
- scop general
- genera
- Caritate
- Go
- scop
- Guvern
- mare
- manipula
- Manipularea
- se întâmplă
- Cablaje
- Avea
- având în
- he
- de asistență medicală
- inimă
- ajutor
- ajutor
- ajută
- ei
- la nivel înalt
- extrem de
- lui
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- IAM
- ideal
- idei
- Identitate
- if
- ilustrează
- punerea în aplicare a
- implementările
- Punere în aplicare a
- import
- îmbunătăţi
- îmbunătățit
- in
- Inclusiv
- individ
- persoane fizice
- industrii
- informații
- informat
- Infrastructură
- inovatoare
- în interiorul
- perspective
- in schimb
- instrucțiuni
- integra
- integrare
- interactiv
- interesat
- interfaţă
- în
- implică
- probleme de
- IT
- ESTE
- Loc de munca
- Locuri de munca
- jpg
- JSON
- Jupiter Notebook
- A pastra
- Cunoaște
- de laborator
- limbă
- mare
- mai mare
- conducere
- AFLAȚI
- învăţare
- Nivel
- ca
- LIMITĂ
- limitare
- limitări
- Linie
- linii
- încărca
- încărcare
- logică
- cautati
- maşină
- masina de învățare
- Principal
- mai ales
- face
- Efectuarea
- administrare
- de conducere
- manual
- manual
- multe
- cartografiere
- studii de masterat
- Mai..
- mijloace
- Meniu
- Metadata
- metodă
- minute
- model
- mai mult
- mai eficient
- cele mai multe
- muta
- Filme
- multiplu
- nume
- Numit
- nume
- Natural
- Limbajul natural
- Procesarea limbajului natural
- Navigaţi
- Navigare
- necesar
- Nevoie
- nevoilor
- Nou
- recent
- următor
- în special
- caiet
- acum
- număr
- obiecte
- of
- promoții
- on
- ONE
- afară
- Operațiuni
- optimă
- Optimizați
- Optimizează
- Opţiuni
- or
- comandă
- organizații
- Origine
- Altele
- al nostru
- afară
- producție
- peste
- Învinge
- propriu
- pagină
- pâine
- parametru
- parametrii
- parte
- în special
- trece
- cale
- patrick
- efectua
- performanță
- permisiuni
- alege
- Plato
- Informații despre date Platon
- PlatoData
- joc
- Politica
- populație
- poseda
- Post
- potenţial
- precis
- a prefera
- premise
- Anunţ
- precedent
- probleme
- proces
- prelucrate
- prelucrare
- Produs
- proiect
- Proiecte
- proprietăţi
- furniza
- furnizează
- publica
- scop
- Piton
- interogări
- Rapid
- mai degraba
- Citeste
- uşor
- Citind
- motive
- primit
- recunoaște
- trimite
- Cerinţe
- salvare
- resursă
- răspuns
- responsabilitate
- REST
- restrânge
- restricţie
- REZULTATE
- robust
- Rol
- rădăcină
- RÂND
- Alerga
- acelaşi
- Economisiți
- Scala
- scalabilitate
- scalabil
- Ştiinţă
- scenariu
- fără sudură
- perfect
- Al doilea
- Secțiune
- vedea
- senior
- Servicii
- sesiune
- set
- instalare
- câteva
- ea
- Coajă
- să
- Arăta
- indicat
- Emisiuni
- asemănător
- simplu
- simplitate
- simplificarea
- singur
- Mărimea
- mic
- So
- Fotbal
- soluţie
- soluţii
- unele
- Sursă
- Surse
- Scânteie
- specialist
- specializata
- specific
- specific
- viteză
- Cheltuire
- SQL
- standard
- începe
- Stat
- Declarație
- precizând
- Pas
- paşi
- depozitare
- stocate
- simplu
- simplifica
- Şir
- puternic
- structura
- structurile
- studio
- succes
- astfel de
- potrivit
- a sustine
- sigur
- Durabilitate
- sisteme
- tabel
- TAG
- adaptate
- Lua
- ia
- sarcini
- tehnici de
- tenis
- decât
- acea
- informațiile
- lumea
- lor
- Lor
- apoi
- Acolo.
- Acestea
- ei
- acest
- aceste
- Prin
- timp
- Titlu
- cu denumirea
- la
- azi
- Toolkit
- top
- subiect
- Transforma
- Transformare
- Traveling
- Cotitură
- tutorial
- Două
- tip
- Tipuri
- final
- în
- Actualizează
- actualizat
- încărcat
- us
- uzabilitate
- utilizare
- utilizat
- Utilizator
- User Interface
- ușor de utilizat
- utilizări
- folosind
- obișnuit
- Utilizand
- Valoros
- valoare
- Valori
- vehicul
- versiune
- de
- Vizualizare
- vizualizari
- viziune
- vizionarea
- Cale..
- we
- web
- servicii web
- Ce
- cand
- întrucât
- dacă
- care
- OMS
- de ce
- voi
- cu
- în
- fără
- Apartamente
- flux de lucru
- fluxuri de lucru
- fabrică
- lume
- scrie
- XML
- tu
- Ta
- zephyrnet