Zdjęcie autora
Dostępnych jest wiele kursów i zasobów na temat uczenia maszynowego i nauki o danych, ale bardzo niewiele na temat inżynierii danych. Rodzi to pewne pytania. Czy to trudna dziedzina? Czy oferuje niskie wynagrodzenie? Czy nie jest to uważane za równie ekscytujące, jak inne role w branży technologicznej? Rzeczywistość jest jednak taka, że wiele firm aktywnie poszukuje talentów w dziedzinie inżynierii danych i oferuje wysokie wynagrodzenia, czasami przekraczające 200,000 XNUMX USD. Inżynierowie danych odgrywają kluczową rolę jako architekci platform danych, projektując i budując podstawowe systemy, które umożliwiają badaczom danych i ekspertom w zakresie uczenia maszynowego efektywne działanie.
Wypełniając tę lukę branżową, DataTalkClub wprowadził transformacyjny i bezpłatny bootcamp „Inżynieria danych Zoomcamp„. Celem tego kursu jest wyposażenie początkujących lub profesjonalistów pragnących zmienić karierę w niezbędne umiejętności i praktyczne doświadczenie w inżynierii danych.
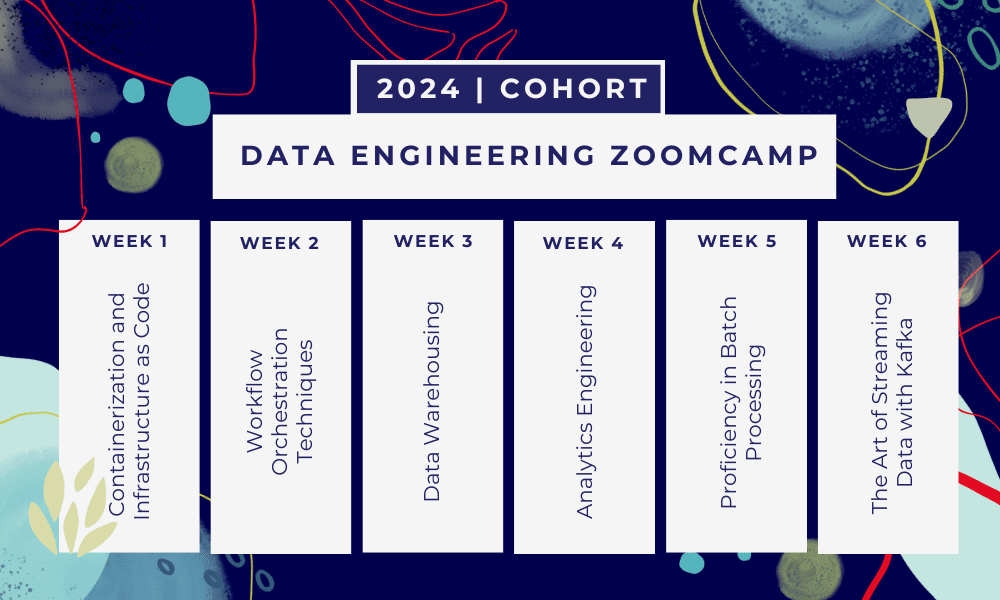
To jest 6-tygodniowy bootcamp gdzie będziesz uczyć się poprzez wiele kursów, materiałów do czytania, warsztatów i projektów. Na koniec każdego modułu otrzymasz pracę domową, dzięki której możesz przećwiczyć zdobytą wiedzę.
- Tydzień 1: Wprowadzenie do GCP, Dockera, Postgres, Terraform i konfiguracji środowiska.
- Tydzień 2: Orkiestracja przepływu pracy za pomocą Mage.
- Tydzień 3: Hurtownia danych z BigQuery i uczenie maszynowe z BigQuery.
- Tydzień 4: Inżynier analityczny z dbt, Google Data Studio i Metabase.
- Tydzień 5: Przetwarzanie wsadowe za pomocą platformy Spark.
- Tydzień 6: Streaming z Kafką.
Obraz z DataTalksClub/data-inżynieria-zoomcamp
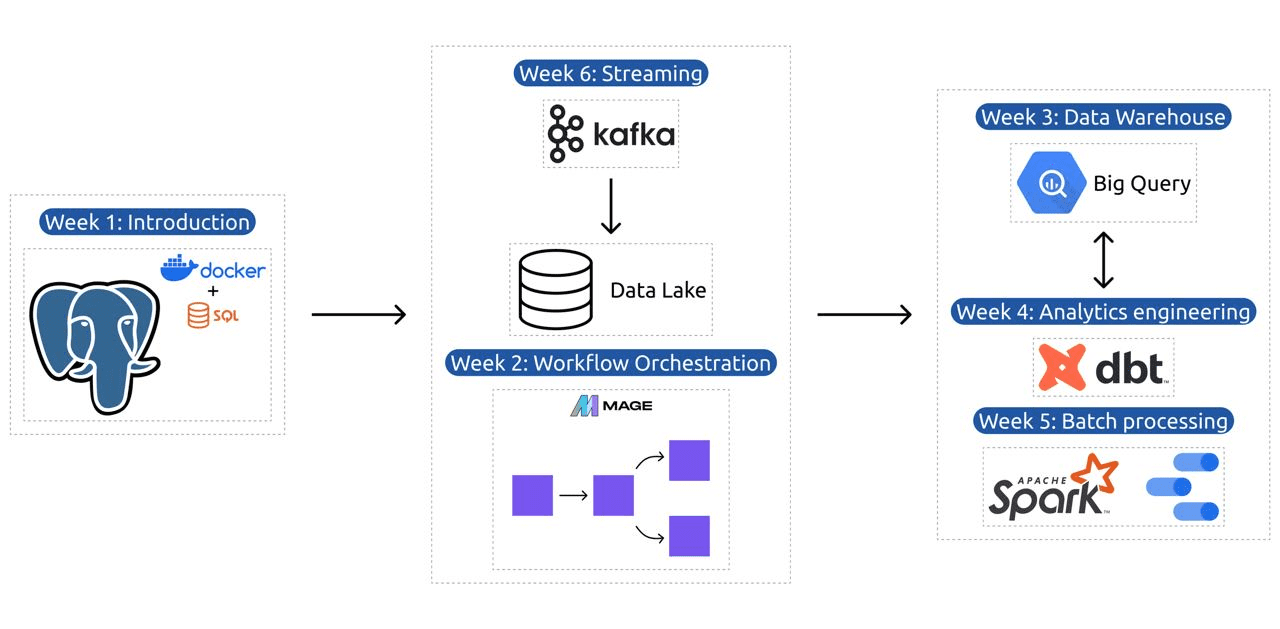
Program nauczania obejmuje 6 modułów, 2 warsztaty i projekt obejmujący wszystko, co potrzebne, aby zostać profesjonalnym inżynierem danych.
Moduł 1: Opanowanie konteneryzacji i infrastruktury jako kodu
W tym module dowiesz się o Dockerze i Postgresie, zaczynając od podstaw, a kończąc na szczegółowych samouczkach na temat tworzenia potoków danych, uruchamiania Postgres z Dockerem i nie tylko.
Moduł obejmuje także podstawowe narzędzia, takie jak pgAdmin, Docker-compose i tematy odświeżania SQL, z opcjonalną treścią na temat sieci Docker i specjalnym przewodnikiem dla użytkowników Linuksa z podsystemem Windows. Na koniec kurs wprowadza Cię w GCP i Terraform, zapewniając całościowe zrozumienie konteneryzacji i infrastruktury jako kodu, niezbędnego w nowoczesnych środowiskach opartych na chmurze.
Moduł 2: Techniki orkiestracji przepływu pracy
Moduł oferuje dogłębną eksplorację Mage, innowacyjnej hybrydowej platformy open source do transformacji i integracji danych. Moduł ten rozpoczyna się od podstaw orkiestracji przepływu pracy, przechodząc do praktycznych ćwiczeń z Mage, w tym konfigurowania go za pomocą Dockera i budowania potoków ETL z API do Postgres i Google Cloud Storage (GCS), a następnie do BigQuery.
Mieszanka filmów, zasobów i praktycznych zadań modułu zapewnia wszechstronną naukę, wyposażając uczniów w umiejętności zarządzania skomplikowanymi przepływami danych za pomocą Mage.
Warsztat 1: Strategie pozyskiwania danych
Podczas pierwszego warsztatu opanujesz budowę wydajnych potoków pozyskiwania danych. Warsztaty skupiają się na podstawowych umiejętnościach, takich jak wyodrębnianie danych z interfejsów API i plików, normalizowanie i ładowanie danych oraz techniki ładowania przyrostowego. Po ukończeniu tego warsztatu będziesz w stanie tworzyć wydajne potoki danych niczym starszy inżynier danych.
Moduł 3: Hurtownia danych
Moduł obejmuje dogłębną eksplorację przechowywania i analizy danych, ze szczególnym uwzględnieniem hurtowni danych przy użyciu BigQuery. Omawia kluczowe pojęcia, takie jak partycjonowanie i grupowanie, a także omawia najlepsze praktyki BigQuery. Moduł przechodzi do zaawansowanych tematów, w szczególności integracji uczenia maszynowego (ML) z BigQuery, podkreślając wykorzystanie SQL do ML i udostępniając zasoby dotyczące dostrajania hiperparametrów, wstępnego przetwarzania funkcji i wdrażania modeli.
Moduł 4: Inżynieria analityczna
Moduł inżynierii analitycznej koncentruje się na budowaniu projektu przy użyciu dbt (narzędzie do budowania danych) z istniejącą hurtownią danych, BigQuery lub PostgreSQL.
Moduł obejmuje konfigurację dbt zarówno w środowisku chmurowym, jak i lokalnym, wprowadzenie koncepcji inżynierii analitycznej, ETL vs ELT oraz modelowanie danych. Obejmuje również zaawansowane funkcje dbt, takie jak modele przyrostowe, znaczniki, haki i migawki.
Na koniec moduł wprowadza techniki wizualizacji przekształconych danych za pomocą narzędzi takich jak Google Data Studio i Metabase, a także zapewnia zasoby do rozwiązywania problemów i wydajnego ładowania danych.
Moduł 5: Biegłość w przetwarzaniu wsadowym
Moduł ten obejmuje przetwarzanie wsadowe przy użyciu Apache Spark, zaczynając od wprowadzenia do przetwarzania wsadowego i platformy Spark, wraz z instrukcjami instalacji dla systemów Windows, Linux i MacOS.
Obejmuje eksplorację Spark SQL i DataFrames, przygotowywanie danych, wykonywanie operacji SQL i zrozumienie wewnętrznych elementów Spark. Na koniec uruchamiamy Sparka w chmurze i integrujemy Sparka z BigQuery.
Moduł 6: Sztuka przesyłania strumieniowego danych za pomocą Kafki
Moduł rozpoczyna się wprowadzeniem do koncepcji przetwarzania strumieniowego, po którym następuje dogłębna eksploracja Kafki, w tym jej podstaw, integracja z Confluent Cloud oraz praktyczne zastosowania z udziałem producentów i konsumentów.
Moduł obejmuje również konfigurację i strumienie Kafki, omawiając takie tematy, jak łączenie strumieni, testowanie, otwieranie okien i korzystanie z Kafka ksqldb & Connect. Dodatkowo koncentruje się na środowiskach Python i JVM, włączając Faust do przetwarzania strumieni w Pythonie, Pyspark – Structured Streaming i przykłady Scala dla strumieni Kafka.
Warsztat 2: Przetwarzanie strumieniowe za pomocą SQL
Dowiesz się, jak przetwarzać dane przesyłane strumieniowo i zarządzać nimi za pomocą RisingWave, które zapewnia ekonomiczne rozwiązanie z doświadczeniem w stylu PostgreSQL, zwiększające możliwości aplikacji przetwarzających strumienie.
Projekt: Aplikacja do inżynierii danych w świecie rzeczywistym
Celem tego projektu jest wdrożenie wszystkich koncepcji, których nauczyliśmy się podczas tego kursu, w celu zbudowania kompleksowego potoku danych. Będziesz tworzyć dashboard składający się z dwóch kafelków, wybierając zbiór danych, budując potok do przetwarzania danych i przechowywania ich w jeziorze danych, budując potok do przesyłania przetworzonych danych z jeziora danych do hurtowni danych, przekształcając danych w hurtowni danych i przygotowanie ich do dashboardu, a na koniec zbudowanie dashboardu umożliwiającego wizualną prezentację danych.
Szczegóły kohorty na rok 2024
- Rejestracja: Zapisać się
- Data rozpoczęcia: 15 stycznia 2024 r. o godzinie 17:00 CET
- Samodzielna nauka z przewodnikiem
- Folder kohorty z zadaniami domowymi i terminami
- Interaktywny Slack Społeczność do wzajemnego uczenia się
Wymagania wstępne
- Podstawowe umiejętności kodowania i wiersza poleceń
- Podstawa w SQL
- Python: korzystny, ale nie obowiązkowy
Doświadczeni instruktorzy poprowadzą Twoją podróż
- Ankush Khanna
- Wiktoria Perez Mola
- Aleksiej Grigoriew
- Matta Palmera
- Luisa Oliveiry
- Michał Szewc
Dołącz do naszej kohorty na rok 2024 i rozpocznij naukę w niesamowitej społeczności zajmującej się inżynierią danych. Dzięki szkoleniom prowadzonym przez ekspertów, praktycznemu doświadczeniu i programowi nauczania dostosowanemu do potrzeb branży, ten bootcamp nie tylko wyposaży Cię w niezbędne umiejętności, ale także zapewni Ci pozycję na czele lukratywnej i poszukiwanej ścieżki kariery. Zapisz się już dziś i zamień swoje aspiracje w rzeczywistość!
Abid Ali Awan (@ 1abidaliawan) jest certyfikowanym specjalistą ds. analityków danych, który uwielbia tworzyć modele uczenia maszynowego. Obecnie koncentruje się na tworzeniu treści i pisaniu blogów technicznych na temat technologii uczenia maszynowego i data science. Abid posiada tytuł magistra zarządzania technologią oraz tytuł licencjata inżynierii telekomunikacyjnej. Jego wizją jest zbudowanie produktu AI z wykorzystaniem grafowej sieci neuronowej dla studentów zmagających się z chorobami psychicznymi.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 000
- 1
- 15%
- 17
- 2024
- a
- Zdolny
- O nas
- aktywnie
- do tego
- adresowanie
- zaawansowany
- postęp
- Po
- AI
- Wszystkie kategorie
- wzdłuż
- również
- zdumiewający
- an
- analiza
- Analityczny
- analityka
- i
- i infrastruktura
- Apache
- Apache Spark
- api
- Pszczoła
- aplikacje
- architekci
- SĄ
- Sztuka
- AS
- At
- dostępny
- Podstawy
- BE
- stają się
- staje
- początkujących
- korzystny
- BEST
- Najlepsze praktyki
- bigQuery
- Mieszanka
- blogi
- obie
- budować
- Budowanie
- ale
- by
- Kariera
- kariery
- Dyplomowani
- Chmura
- przechowywanie w chmurze
- klastrowanie
- kod
- Kodowanie
- Kohorta
- społeczność
- Firmy
- wypełniając
- wszechstronny
- Koncepcje
- konkluduje
- systemu
- Dopływ
- Skontaktuj się
- za
- Składający się
- skonstruować
- Konsumenci
- zawiera
- zawartość
- Tworzenie treści
- kurs
- kursy
- obejmuje
- Stwórz
- Tworzenie
- tworzenie
- istotny
- Obecnie
- Curriculum
- tablica rozdzielcza
- dane
- inżynier danych
- Jezioro danych
- nauka danych
- naukowiec danych
- przechowywanie danych
- hurtownia danych
- Data
- Stopień
- Wdrożenie
- zaprojektowany
- projektowanie
- szczegółowe
- trudny
- Doker
- każdy
- faktycznie
- wydajny
- bądź
- upoważniać
- umożliwiać
- zakończenia
- koniec końców
- inżynier
- Inżynieria
- Inżynierowie
- zapisać
- zapewnia
- Środowisko
- środowiska
- niezbędny
- Eter (ETH)
- wszystko
- przykłady
- ekscytujący
- Przede wszystkim system został opracowany
- doświadczenie
- eksperci
- eksploracja
- Exploring
- rozciąga się
- Cecha
- Korzyści
- Wyposażony w
- kilka
- pole
- Akta
- W końcu
- i terminów, a
- Skupiać
- koncentruje
- skupienie
- następnie
- W razie zamówieenia projektu
- czoło
- Podstawowy
- Framework
- Darmowy
- od
- funkcjonować
- Podstawy
- szczelina
- GCP
- dany
- Google Cloud
- wykres
- Wykres sieci neuronowej
- prowadzony
- hands-on
- Have
- he
- podświetlanie
- jego
- posiada
- holistyczne
- Praca domowa
- Haczyki
- Jednak
- HTTPS
- Hybrydowy
- Dostrajanie hiperparametrów
- choroba
- wdrożenia
- in
- informacje
- obejmuje
- Włącznie z
- przyrostowe
- przemysł
- Infrastruktura
- Innowacyjny
- instalacja
- instrukcje
- Integracja
- integracja
- najnowszych
- wprowadzono
- Przedstawia
- wprowadzenie
- Wprowadzenie
- wstępy
- z udziałem
- IT
- JEGO
- styczeń
- Łączy
- kafka
- Knuggety
- Klawisz
- jezioro
- prowadzący
- UCZYĆ SIĘ
- dowiedziałem
- uczniowie
- nauka
- lubić
- Linia
- linux
- załadunek
- miejscowy
- poszukuje
- kocha
- niski
- lukratywny
- maszyna
- uczenie maszynowe
- MacOS
- zarządzanie
- i konserwacjami
- obowiązkowe
- wiele
- mistrz
- Mastering
- materiały
- psychika
- Choroba umysłowa
- ML
- model
- modelowanie
- modele
- Nowoczesne technologie
- moduł
- Moduły
- jeszcze
- wielokrotność
- niezbędny
- Potrzebować
- potrzebne
- wymagania
- sieć
- sieci
- Nerwowy
- sieci neuronowe
- cel
- of
- oferuje
- Oferty
- on
- tylko
- open source
- operacje
- or
- orkiestracja
- Inne
- ludzkiej,
- Pielgrzym z ziemi świętej
- szczególnie
- ścieżka
- Zapłacić
- par
- wykonywania
- rurociąg
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- Pozycje
- postgresql
- Praktyczny
- Praktyczne zastosowania
- praktyka
- praktyki
- przygotowanie
- teraźniejszość
- wygląda tak
- obrobiony
- przetwarzanie
- Producenci
- Produkt
- profesjonalny
- specjalistów
- postępuje
- projekt
- projektowanie
- zapewnia
- że
- Python
- pytania
- podnosi
- Czytający
- Prawdziwy świat
- Rzeczywistość
- Zasoby
- Rola
- role
- bieganie
- s
- pensje
- Scala
- nauka
- Naukowiec
- Naukowcy
- poszukuje
- wybierając
- senior
- ustawienie
- ustawienie
- umiejętności
- luźny
- rozwiązanie
- kilka
- czasami
- wyrafinowany
- Iskra
- specjalny
- SQL
- początek
- Startowy
- przechowywanie
- strumień
- Streaming
- Strumienie
- zbudowany
- Walka
- Studenci
- studio
- znaczny
- taki
- wsparcie
- Przełącznik
- systemy
- dostosowane
- Talent
- zadania
- tech
- Techniczny
- Techniki
- Technologies
- Technologia
- telekomunikacja
- Terraform
- Testowanie
- że
- Połączenia
- Podstawy
- następnie
- to
- Przez
- do
- już dziś
- narzędzie
- narzędzia
- tematy
- Trening
- Przesyłanie
- Przekształcać
- Transformacja
- transformacyjny
- przekształcony
- transformatorowy
- tutoriale
- drugiej
- zrozumienie
- USD
- posługiwać się
- Użytkownicy
- za pomocą
- Ve
- początku.
- przez
- Filmy
- wizja
- naocznie
- vs
- Magazyn
- Magazynowanie
- we
- Co
- który
- KIM
- będzie
- okna
- w
- workflow
- przepływów pracy
- warsztat
- warsztaty
- pisanie
- ty
- Twój
- zefirnet