Obraz autorstwa redaktora
Na wynos
- Test t jest testem statystycznym, którego można użyć do określenia, czy istnieje istotna różnica między średnimi z dwóch niezależnych próbek danych.
- Zilustrujemy, w jaki sposób można zastosować test t za pomocą zestawu danych tęczówki i biblioteki Scipy Pythona.
Test t jest testem statystycznym, którego można użyć do określenia, czy istnieje istotna różnica między średnimi z dwóch niezależnych próbek danych. W tym samouczku zilustrujemy najbardziej podstawową wersję testu t, dla której założymy, że dwie próbki mają równe wariancje. Inne zaawansowane wersje testu t obejmują test t Welcha, który jest adaptacją testu t i jest bardziej niezawodny, gdy dwie próbki mają nierówne wariancje i prawdopodobnie nierówne rozmiary próbek.
Statystykę t lub wartość t oblicza się w następujący sposób:
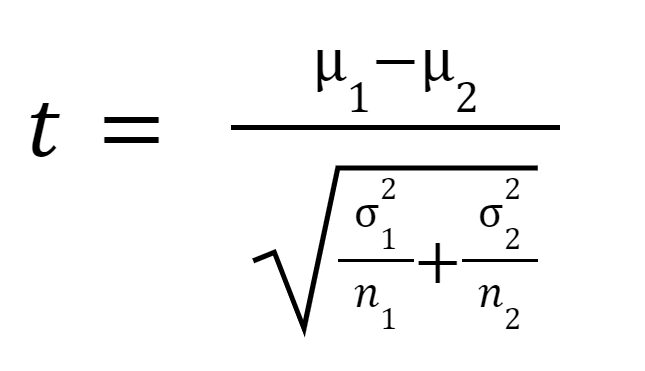
gdzie
jest średnią z próbki 1,
jest średnią z próbki 2,
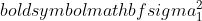 jest wariancją próbki 1,
jest wariancją próbki 1, 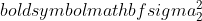 jest wariancją próbki 2,
jest wariancją próbki 2, 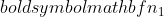 jest wielkością próbki próbki 1, oraz
jest wielkością próbki próbki 1, oraz 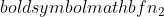 jest wielkością próby 2.
jest wielkością próby 2.
Aby zilustrować użycie testu t, pokażemy prosty przykład wykorzystujący zestaw danych tęczówki. Załóżmy, że obserwujemy dwie niezależne próbki, np. długości działek kwiatowych, i zastanawiamy się, czy dwie próbki zostały pobrane z tej samej populacji (np. tego samego gatunku kwiatu lub dwóch gatunków o podobnych cechach działek), czy też z dwóch różnych populacji.
Test t określa ilościowo różnicę między średnimi arytmetycznymi dwóch próbek. Wartość p określa ilościowo prawdopodobieństwo uzyskania obserwowanych wyników, przy założeniu, że hipoteza zerowa (że próbki pochodzą z populacji o tych samych średnich populacyjnych) jest prawdziwa. Wartość p większa niż wybrany próg (np. 5% lub 0.05) wskazuje, że nasza obserwacja nie jest tak nieprawdopodobna, aby wydarzyła się przypadkowo. Dlatego akceptujemy hipotezę zerową równych średnich populacji. Jeśli wartość p jest mniejsza niż nasz próg, mamy dowody przeciwko hipotezie zerowej równych średnich populacji.
Wejście testu T
Dane wejściowe lub parametry niezbędne do wykonania testu t to:
- Dwie tablice a i b zawierające dane dla próbki 1 i próbki 2
Wyjścia testu T
Test t zwraca:
- Obliczone statystyki t
- Wartość p
Zaimportuj niezbędne biblioteki
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Załaduj zestaw danych tęczówki
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Oblicz średnie próby i wariancje próby
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Zaimplementuj test t
stats.ttest_ind(a_1, b_1, equal_var = False)
Wydajność
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
Wydajność
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
Wydajność
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Komentarze
Zauważamy, że użycie „true” lub „false” dla parametru „equal-var” nie zmienia tak bardzo wyników testu t. Zauważamy również, że zamiana kolejności tablic próbek a_1 i b_1 daje ujemną wartość testu t, ale nie zmienia wielkości wartości testu t, zgodnie z oczekiwaniami. Ponieważ obliczona wartość p jest znacznie większa niż wartość progowa 0.05, możemy odrzucić hipotezę zerową, że różnica między średnimi z próby 1 i próby 2 jest znacząca. To pokazuje, że długości działek dla próbki 1 i próbki 2 zostały pobrane z tych samych danych populacji.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Oblicz średnie próby i wariancje próby
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Zaimplementuj test t
stats.ttest_ind(a_1, b_1, equal_var = False)
Wydajność
stats.ttest_ind(a_1, b_1, equal_var = False)Komentarze
Zauważamy, że użycie próbek o nierównej wielkości nie zmienia istotnie statystyki t i wartości p.
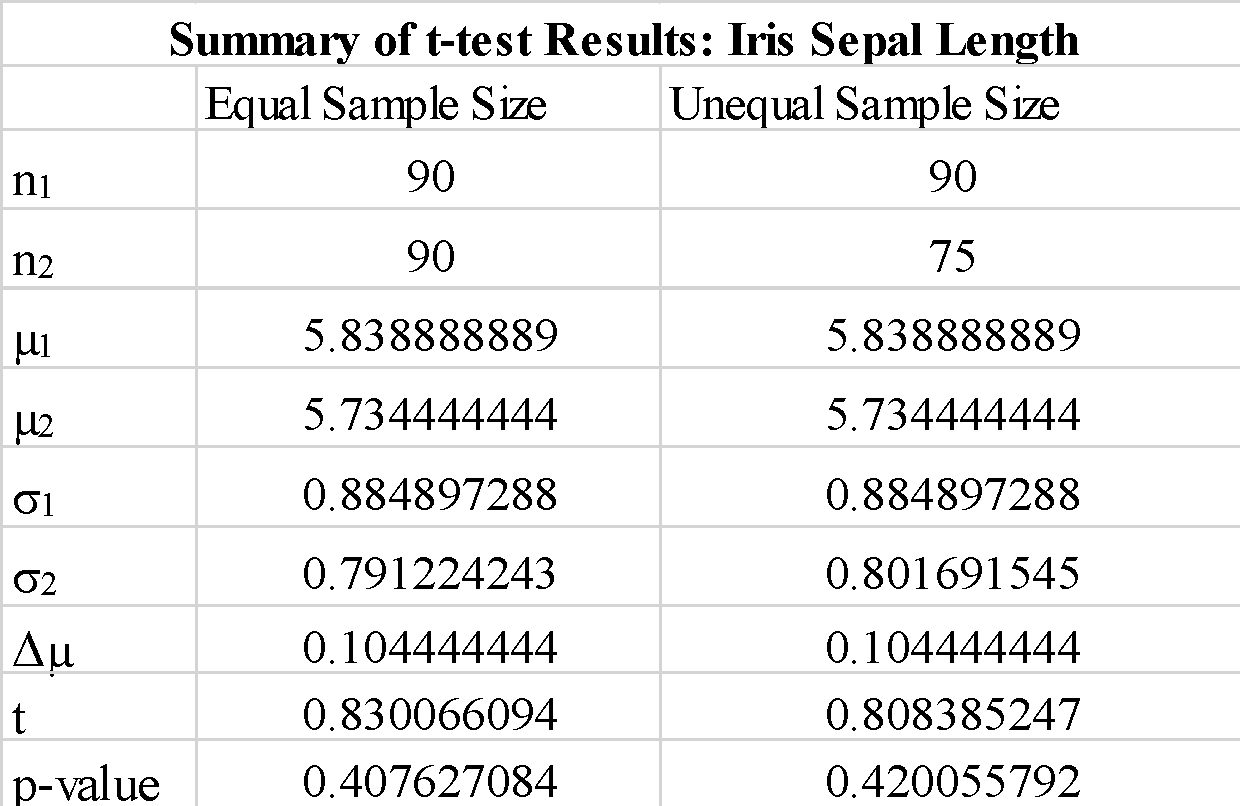
Podsumowując, pokazaliśmy, jak można zaimplementować prosty test t przy użyciu biblioteki scipy w Pythonie.
Benjamin O. Tajo jest fizykiem, nauczycielem nauki o danych i pisarzem, a także właścicielem DataScienceHub. Wcześniej Benjamin wykładał inżynierię i fizykę na U. of Central Oklahoma, Grand Canyon U. i Pittsburgh State U.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- Akceptuj
- zaawansowany
- przed
- i
- stosowany
- podstawowy
- Beniaminek
- pomiędzy
- obliczony
- centralny
- szansa
- zmiana
- Charakterystyka
- wybrany
- wobec
- mógłby
- dane
- nauka danych
- zbiory danych
- Ustalać
- różnica
- różne
- sporządzony
- Inżynieria
- dowód
- przykład
- spodziewany
- kwiat
- następujący
- następujący sposób
- od
- W jaki sposób
- HTTPS
- realizowane
- importować
- in
- zawierać
- niezależny
- wskazuje
- Knuggety
- większe
- Biblioteka
- matplotlib
- znaczy
- jeszcze
- większość
- niezbędny
- ujemny
- tępy
- obserwować
- uzyskiwanie
- miejsce
- Oklahoma
- zamówienie
- Inne
- właściciel
- parametr
- parametry
- wykonywania
- Fizyka
- pittsburgh
- plato
- Analiza danych Platona
- PlatoDane
- populacja
- populacje
- poprzednio
- prawdopodobieństwo
- Python
- rzetelny
- Efekt
- powraca
- taki sam
- nauka
- pokazać
- pokazane
- Targi
- znaczący
- znacznie
- podobny
- Prosty
- ponieważ
- Rozmiar
- rozmiary
- mniejszy
- So
- Stan
- statystyczny
- statystyki
- PODSUMOWANIE
- Nauczanie
- test
- Połączenia
- w związku z tym
- próg
- do
- prawdziwy
- Tutorial
- posługiwać się
- wartość
- wersja
- czy
- który
- będzie
- pisarz
- plony
- zefirnet