Amazon RedShift er en skydatavarehustjeneste som gir høyytelses analytisk prosessering basert på en massivt parallell prosessering (MPP) arkitektur. Å bygge og vedlikeholde datapipelines er en felles utfordring for alle virksomheter. Å administrere SQL-filene, integrere arbeid på tvers av team, innlemme alle programvaretekniske prinsipper og importere eksterne verktøy kan være en tidkrevende oppgave som krever kompleks design og mye forberedelse.
DBT (DataBuildTool) tilbyr denne mekanismen ved å introdusere et godt strukturert rammeverk for dataanalyse, transformasjon og orkestrering. Den bruker også generelle programvaretekniske prinsipper som integrering med git-repositories, oppsett TØRKER kode, legge til funksjonelle testtilfeller og inkludere eksterne biblioteker. Denne mekanismen lar utviklere fokusere på å klargjøre SQL-filene i henhold til forretningslogikken, og resten tar dbt seg av.
I dette innlegget ser vi på en optimal og kostnadseffektiv måte å innlemme dbt i Amazon Redshift. Vi bruker Amazon Elastic Beholderregister (Amazon ECR) for å lagre våre dbt Docker-bilder og AWS Fargate som en Amazon Elastic Container Service (Amazon ECS) oppgave for å kjøre jobben.
Hvordan fungerer dbt-rammeverket med Amazon Redshift?
dbt har en Amazon Redshift-adaptermodul kalt dbt-rødforskyvning som gjør det mulig å koble til og jobbe med Amazon Redshift. Alle tilkoblingsprofilene er konfigurert i dbt profiles.yml fil. I et optimalt miljø lagrer vi legitimasjonen i AWS Secrets Manager og hente dem.
Følgende kode viser innholdet i profile.yml:
Følgende diagram illustrerer nøkkelkomponentene i dbt-rammeverket:
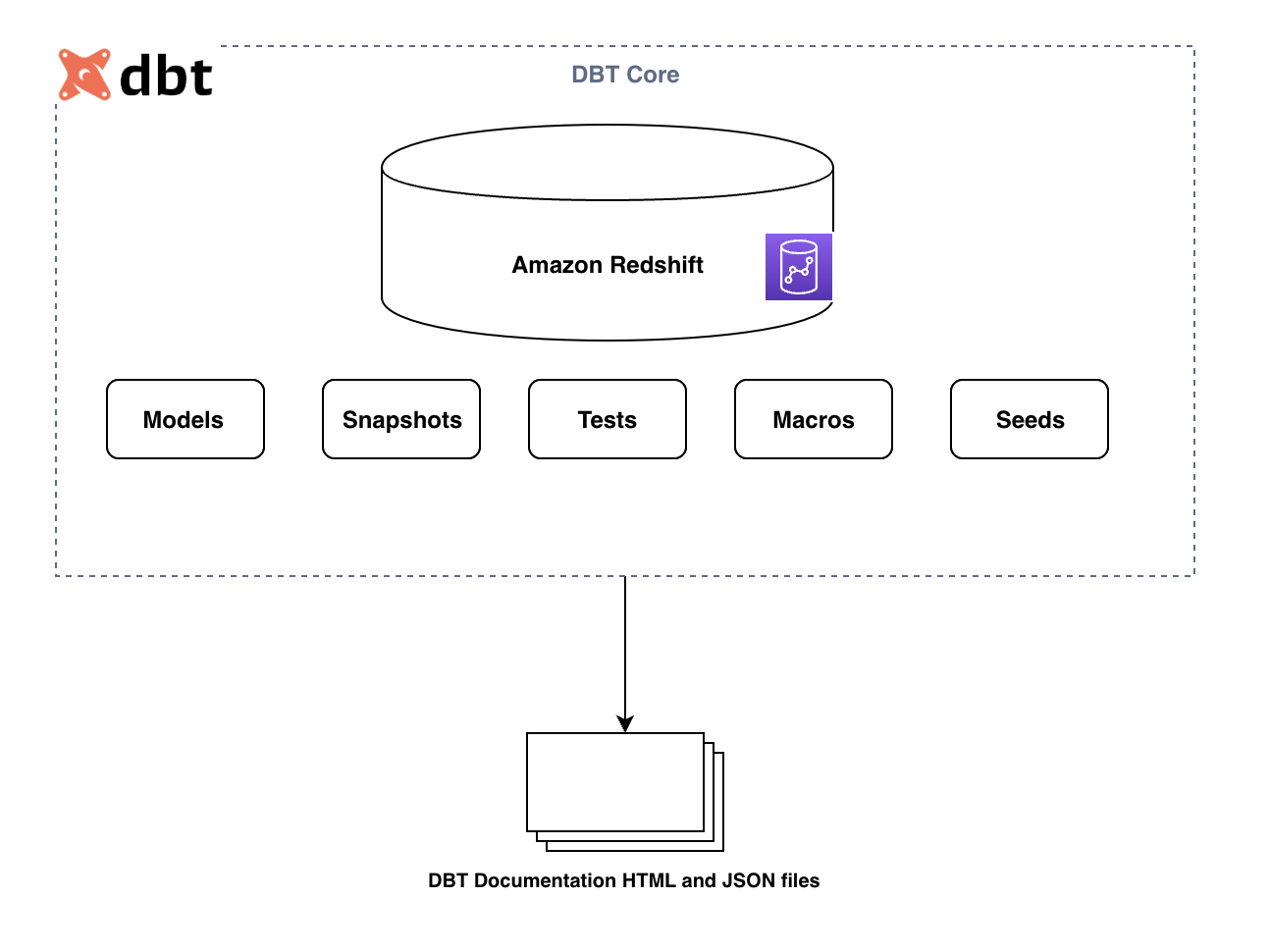
De primære komponentene er som følger:
- Modeller – Disse skrives som en SELECT-setning og lagres som en .sql-fil. Alle transformasjonsspørringene kan skrives her som kan materialiseres som en tabell eller visning. Tabelloppdateringen kan være full eller inkrementell basert på konfigurasjonen. For mer informasjon, se SQL-modeller.
- snapshots – Disse redskapene type-2 sakte skiftende dimensjoner (SCD-er) over mutbare kildetabeller. Disse SCD-ene identifiserer hvordan en rad i en tabell endres over tid.
- Frø – Dette er CSV-filer i dbt-prosjektet ditt (vanligvis i frøkatalogen din), som dbt kan laste inn i datalager bruker
dbt seedkommando. - Tester – Dette er påstander du kommer med om modellene dine og andre ressurser i dbt-prosjektet ditt (som kilder, frø og øyeblikksbilder). Når du løper
dbt test, vil dbt fortelle deg om hver test i prosjektet ditt består eller mislykkes. - Makroer – Dette er kodebiter som kan gjenbrukes flere ganger. De er analoge med "funksjoner" i andre programmeringsspråk, og er ekstremt nyttige hvis du finner deg selv å gjenta kode på tvers av flere modeller.
Disse komponentene lagres som .sql-filer og kjøres av dbt CLI-kommandoer. Under løpeturen lager dbt en Regissert asyklisk graf (DAG) basert på den interne referansen mellom dbt-komponentene. Den bruker DAG til å orkestrere løpesekvensen deretter.
Flere profiler kan opprettes i profiles.yml-filen, som dbt kan bruke til å målrette mot forskjellige Redshift-miljøer mens du kjører. For mer informasjon, se Redshift-oppsett.
Løsningsoversikt
Følgende diagram illustrerer løsningsarkitekturen.
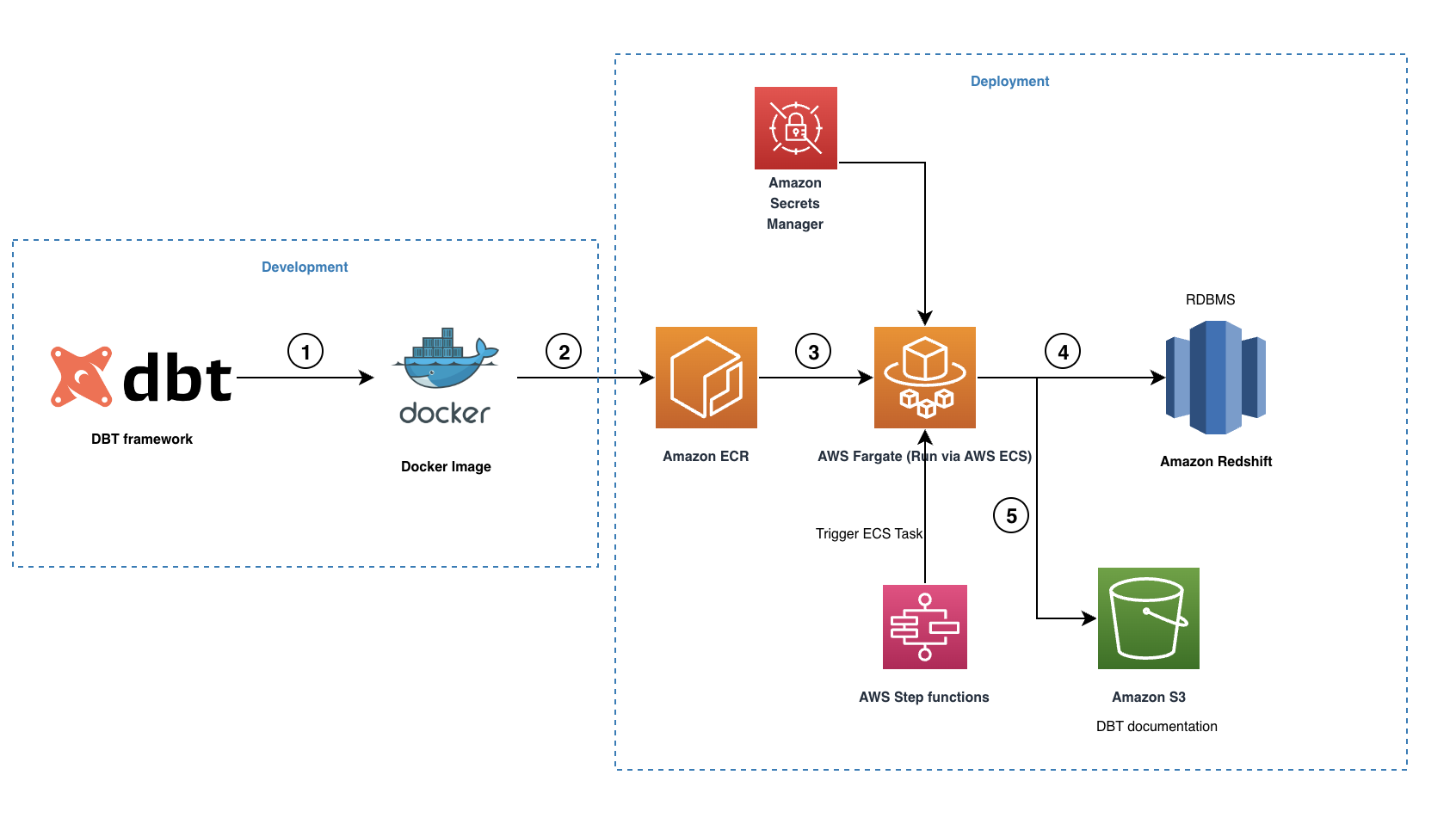
Arbeidsflyten inneholder følgende trinn:
- Open source dbt-redshift-koblingen brukes til å lage dbt-prosjektet vårt, inkludert alle nødvendige modeller, øyeblikksbilder, tester, makroer og profiler.
- Et Docker-bilde opprettes og skyves til ECR-depotet.
- Docker-bildet kjøres av Fargate som en ECS-oppgave utløst via AWS trinnfunksjoner. All Amazon Redshift-legitimasjonen er lagret i Secrets Manager, som deretter brukes av ECS-oppgaven for å koble til Amazon Redshift.
- Under kjøringen konverterer dbt alle modellene, øyeblikksbilder, tester og makroer til Amazon Redshift-kompatible SQL-setninger, og den orkestrerer kjøringen basert på den interne datalinjegraf opprettholdt. Disse SQL-kommandoene kjøres direkte på Redshift-klyngen, og derfor blir arbeidsbelastningen sendt direkte til Amazon Redshift.
- Når kjøringen er fullført, vil dbt opprette et sett med HTML- og JSON-filer for å være vert for DBT-dokumentasjon, som beskriver datakatalogen, kompilerte SQL-setninger, datalinjediagram og mer.
Forutsetninger
Du bør ha følgende forutsetninger:
- En god forståelse av dbt-prinsippene og implementeringstrinn.
- En AWS-konto med brukerrolletillatelse for å få tilgang til AWS-tjenestene som brukes i denne løsningen.
- Sikkerhetsgrupper for Fargate for å få tilgang til Redshift-klyngen og Secrets Manager fra Amazon ECS.
- En rødforskyvningsklynge. For opprettelsesinstruksjoner, se Lag en klynge.
- Et ECR-lager: For instruksjoner, se Opprette et privat depot
- En Secrets Manager hemmelighet som inneholder all legitimasjon for å koble til Amazon Redshift. Dette inkluderer verten, porten, databasenavnet, brukernavnet og passordet. For mer informasjon, se Opprett en AWS Secrets Manager-databasehemmelighet.
- An Amazon enkel lagring (Amazon S3) bøtte for å være vert for dokumentasjonsfiler.
Lag et dbt-prosjekt
Vi bruker dbt CLI så alle kommandoer kjøres på kommandolinjen. Installer derfor pip hvis det ikke allerede er installert. Referere til installasjon for mer informasjon.
For å opprette et dbt-prosjekt, fullfør følgende trinn:
- Installer avhengige dbt-pakker:
pip install dbt-redshift - Initialiser et dbt-prosjekt ved å bruke
dbt init <project_name>kommando, som oppretter alle malmappene automatisk. - Legg til alle nødvendige DBT-artefakter.
Referere til dbt-redshift-etlpattern repo som inkluderer et referansedbt-prosjekt. For mer informasjon om byggeprosjekter, se Om dbt-prosjekter.
I referanseprosjektet har vi implementert følgende funksjoner:
- SCD type 1 ved bruk av inkrementelle modeller
- SCD type 2 ved hjelp av øyeblikksbilder
- Seed-oppslagsfiler
- Makroer for å legge til gjenbrukbar kode i prosjektet
- Tester for å analysere inngående data
Python-skriptet er forberedt for å hente legitimasjonen som kreves fra Secrets Manager for å få tilgang til Amazon Redshift. Referere til export_redshift_connection.py filen.
- Forbered
run_dbt.shskript for å kjøre dbt-rørledningen sekvensielt. Dette skriptet er plassert i rotmappen til dbt-prosjektet som vist i eksempelrepo.
- Opprett en Docker-fil i den overordnede katalogen til dbt-prosjektmappen. Dette trinnet bygger bildet av dbt-prosjektet som skal skyves til ECR-depotet.
Last opp bildet til Amazon ECR og kjør det som en ECS-oppgave
For å skyve bildet til ECR-depotet, fullfør følgende trinn:
- Hent et autentiseringstoken og autentiser Docker-klienten til registeret ditt:
- Bygg Docker-bildet ditt ved å bruke følgende kommando:
- Etter at byggingen er fullført, merk bildet ditt slik at du kan skyve det til depotet:
- Kjør følgende kommando for å skyve bildet til ditt nyopprettede AWS-lager:
- På Amazon ECS-konsollen oppretter du en klynge med Fargate som et infrastrukturalternativ.
- Oppgi din VPC og subnett etter behov.
- Etter at du har opprettet klyngen, oppretter du en ECS-oppgave og tilordner det opprettede dbt-bildet som oppgavedefinisjonsfamilien.
- I nettverksdelen velger du VPC, undernett og sikkerhetsgruppe for å koble til Amazon Redshift, Amazon S3 og Secrets Manager.
Denne oppgaven vil utløse run_dbt.sh pipeline script og kjør alle dbt-kommandoene sekvensielt. Når skriptet er fullført, kan vi se resultatene i Amazon Redshift og dokumentasjonsfilene sendt til Amazon S3.
- Du kan være vert for dokumentasjonen via Amazon S3 statisk nettstedsvert. For mer informasjon, se Å være vert for et statisk nettsted ved hjelp av Amazon S3.
- Til slutt kan du kjøre denne oppgaven i Step Functions som en ECS-oppgave for å planlegge jobbene etter behov. For mer informasjon, se Administrer Amazon ECS- eller Fargate-oppgaver med trinnfunksjoner.
De dbt-redshift-etlpattern repo har nå alle kodeeksemplene som kreves.
Kostnader for å utføre dbt-jobber i AWS Fargate som en Amazon ECS-oppgave med minimale driftskrav vil ta rundt $1.5 (kostnadslink) per måned.
Rydd opp
Fullfør følgende trinn for å rydde opp i ressursene dine:
- Slett ECS-klyngen du opprettet.
- Slett ECR-depotet du opprettet for lagring av bildefilene.
- Slett Redshift-klyngen du opprettet.
- Slett Redshift Secrets lagret i Secrets Manager.
konklusjonen
Dette innlegget dekket den grunnleggende implementeringen av å bruke dbt med Amazon Redshift på en kostnadseffektiv måte ved å bruke Fargate i Amazon ECS. Vi beskrev nøkkelinfrastrukturen og konfigurasjonsoppsettet med et eksempelprosjekt. Denne arkitekturen kan hjelpe deg å dra nytte av fordelene ved å ha et dbt-rammeverk for å administrere datavarehusplattformen din i Amazon Redshift.
For mer informasjon om dbt-makroer og modeller for Amazon Redshift intern drift og vedlikehold, se følgende GitHub repo. I det påfølgende innlegget vil vi utforske de tradisjonelle mønstrene for ekstraksjon, transformasjon og belastning (ETL) som du kan implementere ved å bruke dbt-rammeverket i Amazon Redshift. Test denne løsningen i kontoen din og gi tilbakemelding eller forslag i kommentarene.
Om forfatterne
 Seshadri Senthamaraikannan er en dataarkitekt med AWS profesjonelle serviceteam basert i London, Storbritannia. Han er godt erfaren og spesialisert innen Data Analytics og jobber med kunder med fokus på å bygge innovative og skalerbare løsninger i AWS Cloud for å møte deres forretningsmål. På fritiden liker han å tilbringe tid med familien og drive med sport.
Seshadri Senthamaraikannan er en dataarkitekt med AWS profesjonelle serviceteam basert i London, Storbritannia. Han er godt erfaren og spesialisert innen Data Analytics og jobber med kunder med fokus på å bygge innovative og skalerbare løsninger i AWS Cloud for å møte deres forretningsmål. På fritiden liker han å tilbringe tid med familien og drive med sport.
 Mohamed hamdy er en senior Big Data Architect med AWS Professional Services basert i London, Storbritannia. Han har over 15 års erfaring med å bygge, lede og bygge datavarehus og store dataplattformer. Han hjelper kunder med å utvikle store data- og analyseløsninger for å akselerere forretningsresultatene gjennom deres skyadopsjonsreise. Utenom jobben liker Mohamed å reise, løpe, svømme og spille squash.
Mohamed hamdy er en senior Big Data Architect med AWS Professional Services basert i London, Storbritannia. Han har over 15 års erfaring med å bygge, lede og bygge datavarehus og store dataplattformer. Han hjelper kunder med å utvikle store data- og analyseløsninger for å akselerere forretningsresultatene gjennom deres skyadopsjonsreise. Utenom jobben liker Mohamed å reise, løpe, svømme og spille squash.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/implement-data-warehousing-solution-using-dbt-on-amazon-redshift/
- : har
- :er
- :ikke
- $OPP
- 1
- 10
- 11
- 15 år
- 15%
- 7
- 8
- 90
- 970
- a
- Om oss
- akselerere
- adgang
- Tilgang
- Logg inn
- tvers
- legge til
- legge
- Adopsjon
- Fordel
- Alle
- tillater
- allerede
- også
- Amazon
- Amazon Web Services
- an
- analyse
- Analytisk
- analytics
- analyserer
- og
- gjelder
- arkitektur
- ER
- rundt
- AS
- godkjenne
- Autentisering
- automatisk
- AWS
- AWS profesjonelle tjenester
- basert
- grunnleggende
- BE
- Fordeler
- mellom
- Stor
- Store data
- bygge
- Bygning
- bygger
- virksomhet
- by
- CAN
- hvilken
- saker
- katalog
- utfordre
- Endringer
- endring
- Velg
- ren
- kunde
- Cloud
- skyadopsjon
- Cluster
- kode
- kommentarer
- Felles
- kompilert
- fullføre
- komplekse
- kompatibel
- komponenter
- Konfigurasjon
- konfigurert
- Koble
- Tilkobling
- tilkobling
- Konsoll
- Container
- inneholder
- innhold
- kostnadseffektiv
- dekket
- skape
- opprettet
- skaper
- skaperverket
- Credentials
- skikk
- Kunder
- DAG
- dato
- dataanalyse
- Data Analytics
- datalager
- datavarehus
- Database
- Misligholde
- definisjon
- avhengig
- beskrevet
- utforming
- dev
- utvikle
- utviklere
- forskjellig
- direkte
- Docker
- dokumentasjon
- gjør
- under
- hver enkelt
- muliggjør
- Ingeniørarbeid
- bedrifter
- Miljø
- miljøer
- Eter (ETH)
- utførende
- erfaring
- erfaren
- utforske
- utvendig
- trekke ut
- ekstremt
- mislykkes
- familie
- Egenskaper
- tilbakemelding
- filet
- Filer
- Finn
- Fokus
- fokusering
- etter
- følger
- Til
- Rammeverk
- fra
- fullt
- funksjonelle
- funksjoner
- general
- generere
- gå
- Mål
- god
- graf
- Gruppe
- Gruppens
- Ha
- å ha
- he
- hjelpe
- hjelper
- her.
- høy ytelse
- hans
- vert
- Hosting
- Hvordan
- HTML
- HTTPS
- identifisere
- if
- illustrerer
- bilde
- bilder
- iverksette
- gjennomføring
- implementert
- importere
- importere
- in
- I andre
- inkluderer
- Inkludert
- innlemme
- inkrementell
- informasjon
- Infrastruktur
- innovative
- installere
- instruksjoner
- Integrering
- intern
- inn
- innføre
- IT
- Jobb
- Jobb
- reise
- JSON
- nøkkel
- språk
- siste
- ledende
- bibliotekene
- i likhet med
- liker
- linje
- laste
- logikk
- Logg inn
- London
- Se
- masse
- makroer
- opprettholde
- vedlikehold
- gjøre
- administrer
- leder
- administrerende
- massivt
- mekanisme
- Møt
- minimal
- modell
- modeller
- moduler
- Mohamed
- Måned
- mer
- flere
- navn
- oppkalt
- nødvendig
- nettverk
- nylig
- nå
- of
- Tilbud
- on
- åpen
- åpen kildekode
- drift
- operasjonell
- optimal
- Alternativ
- or
- orkestre
- Annen
- vår
- utfall
- utganger
- utenfor
- enn
- oversikt
- pakker
- Parallel
- passerer
- Passord
- mønstre
- for
- tillatelse
- stykker
- rørledning
- plasseres
- plattform
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Spille
- spiller
- Post
- forberedelse
- forberedt
- forbereder
- forutsetninger
- primære
- prinsipper
- privat
- prosessering
- profesjonell
- Profil
- Profiler
- Programmering
- programmerings språk
- prosjekt
- prosjekter
- gi
- gir
- Skyv
- presset
- Python
- spørsmål
- referere
- referanse
- registret
- Repository
- krever
- påkrevd
- Krav
- Krever
- Ressurser
- REST
- Resultater
- gjenbruk
- Rolle
- root
- RAD
- Kjør
- rennende
- lagret
- skalerbar
- planlegge
- script
- sekunder
- hemmeligheter
- Seksjon
- sikkerhet
- se
- seed
- frø
- senior
- Sequence
- tjeneste
- Tjenester
- sett
- innstilling
- bør
- vist
- Viser
- Enkelt
- Sakte
- Snapshot
- So
- Software
- software engineering
- løsning
- Solutions
- kilde
- Kilder
- spesialisert
- utgifter
- Sports
- SQL
- Uttalelse
- uttalelser
- Trinn
- Steps
- oppbevare
- lagret
- subnett
- senere
- slik
- svømming
- bord
- TAG
- Ta
- tatt
- Target
- Oppgave
- oppgaver
- lag
- fortelle
- mal
- test
- tester
- Det
- De
- deres
- Dem
- deretter
- derfor
- Disse
- de
- denne
- Gjennom
- tid
- tidkrevende
- ganger
- til
- token
- tradisjonelle
- Transform
- Transformation
- utløse
- utløst
- typen
- typisk
- Uk
- forståelse
- bruke
- brukt
- Bruker
- bruker
- ved hjelp av
- verktøy
- av
- Se
- Warehouse
- lager
- Vei..
- we
- web
- webtjenester
- Nettsted
- VI VIL
- når
- hvilken
- mens
- Wikipedia
- vil
- med
- innenfor
- Arbeid
- arbeidsflyt
- virker
- ville
- skrevet
- år
- du
- Din
- deg selv
- zephyrnet