SmugMug driver to veldig store online fotoplattformer, SmugMug og Flickr, som gjør det mulig for mer enn 100 millioner kunder å trygt lagre, søke, dele og selge titalls milliarder bilder. Kunder som lastet opp og søkte gjennom flere tiår med bilder bidro til å gjøre søk til kritisk infrastruktur, og har vokst jevnt siden SmugMug først ble brukt Amazon CloudSearch i 2012, etterfulgt av Amazon OpenSearch-tjeneste siden 2018, etter å ha nådd milliarder av dokumenter og terabyte med søkelagring.
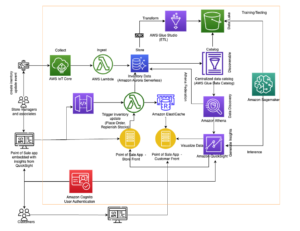
Her deler Lee Shepherd, SmugMug Staff Engineer, SmugMugs søkearkitektur som brukes til å publisere, fylle ut og speile live trafikk til flere klynger. SmugMug bruker disse rørledningene til å benchmarke, validere og migrere til nye konfigurasjoner, inkludert Graviton-baserte r6gd.2xlarge-forekomster fra i3.2xlarge, sammen med testing Amazon OpenSearch Serverless. Vi dekker tre rørledninger som brukes til publisering, utfylling og spørring uten å introdusere piggete urealistiske trafikkmønstre, og uten noen innvirkning på produksjonstjenester.
Det er to hovedarkitektoniske deler som er kritiske for prosessen:
- En varig kilde til sannhet for indeksdata. Det er beste praksis og en del av vår backup-strategi for å ha en holdbar butikk utover OpenSearch-indeksen, og Amazon DynamoDB gir skalerbarhet og integrasjon med AWS Lambda som forenkler mye av prosessen. Vi bruker DynamoDB for andre ikke-søketjenester, så dette passet naturlig.
- En Lambda-funksjon for å publisere data fra sannhetens kilde til OpenSearch. Ved hjelp av funksjonsaliaser hjelper til med å kjøre flere konfigurasjoner av samme Lambda-funksjon samtidig og er nøkkelen til å holde data synkronisert.
Publisering
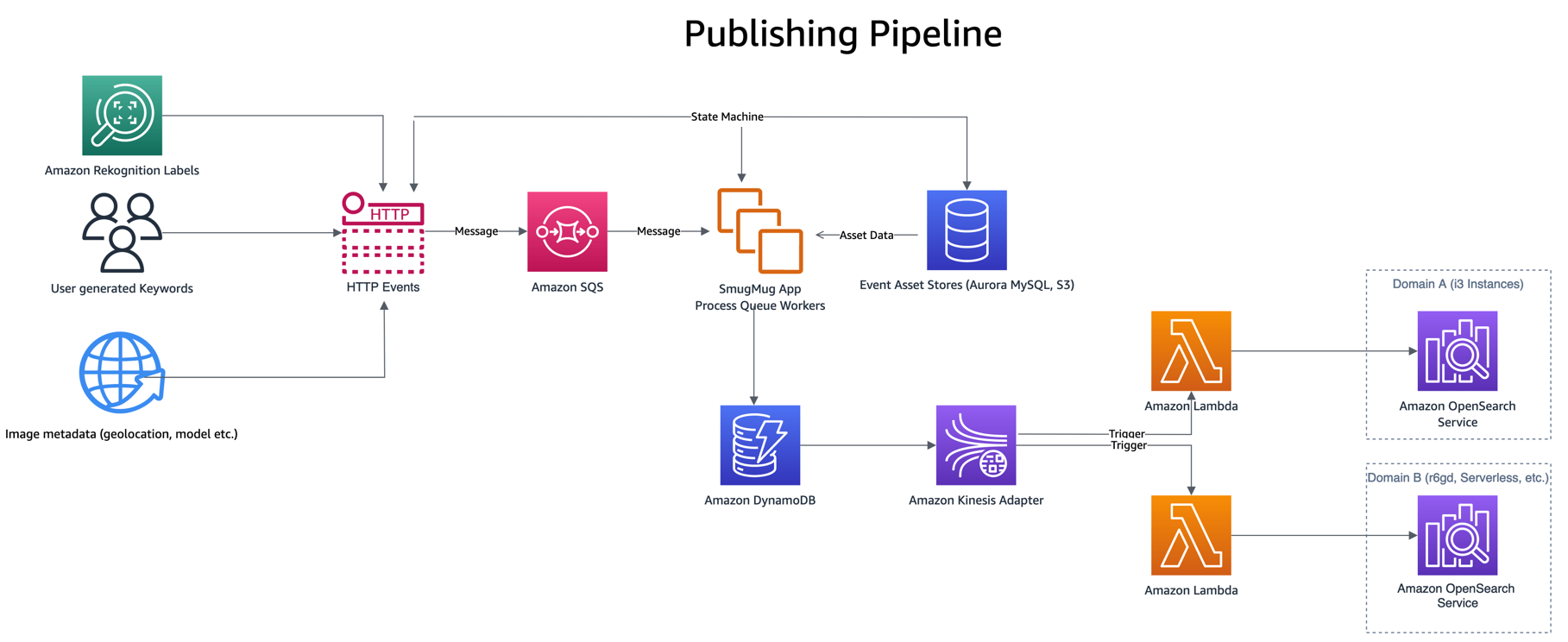
Publiseringspipelinen er drevet fra hendelser som en bruker som skriver inn søkeord eller bildetekster, nye opplastinger eller etikettgjenkjenning gjennom Amazon-anerkjennelse. Disse hendelsene behandles, og kombinerer data fra noen få andre aktivabutikker som Amazon Aurora MySQL-kompatibel utgave og Amazon Simple Storage Service (Amazon S3), før du skriver et enkelt element inn i DynamoDB.
Å skrive til DynamoDB påkaller en Lambda-publiseringsfunksjon, gjennom DynamoDB Streams Kinesis Adapter, som tar et parti med oppdaterte elementer fra DynamoDB og indekserer dem i OpenSearch. Det er andre fordeler med å bruke DynamoDB Streams Kinesis Adapter som å redusere antall samtidige lambdaer som kreves.
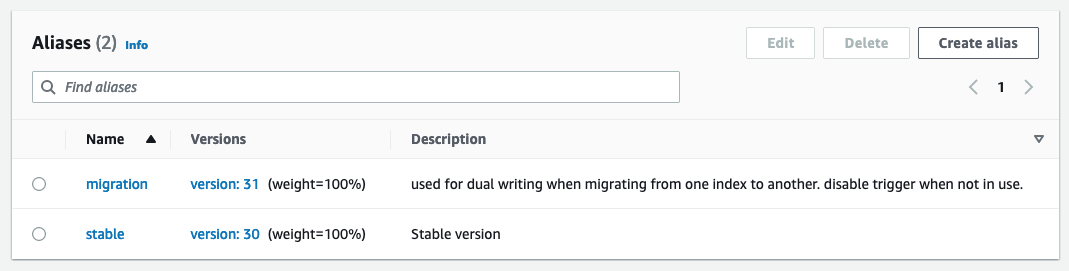
Den publiserende Lambda-funksjonen bruker miljøvariabler for å bestemme hvilket OpenSearch-domene og hvilket indeks som skal publiseres til. Et produksjonsalias er konfigurert til å skrive til produksjons OpenSearch-domenet, utenfor DynamoDB-tabellen eller Kinesis Stream
Når du tester nye konfigurasjoner eller migrerer, konfigureres et migreringsalias til å skrive til det nye OpenSearch-domenet, men bruke samme utløser som produksjonsaliaset. Dette muliggjør dobbel indeksering av data til begge OpenSearch Service-domenene samtidig.
Her er et eksempel på DynamoDB-tabellskjemaet:
'LastUpdated'-verdien brukes som dokumentversjon ved indeksering, slik at OpenSearch kan avvise eventuelle oppdateringer som ikke er i orden.
Fylling på nytt
Nå som endringer publiseres på begge domenene, må det nye domenet (indeksen) fylles ut med historiske data. For å fylle ut en nyopprettet indeks, en kombinasjon av Amazon Simple Queue Service (Amazon SQS) og DynamoDB brukes. Et skript fyller ut en SQS-kø med meldinger som inneholder instruksjoner for parallell skanning et segment av DynamoDB-tabellen.
SQS-køen lanserer en Lambda-funksjon som leser meldingsinstruksjonene, henter en gruppe varer fra det tilsvarende segmentet i DynamoDB-tabellen og skriver dem inn i en OpenSearch-indeks. Nye meldinger skrives til SQS-køen for å holde oversikt over fremdriften gjennom segmentet. Etter at segmentet er fullført, blir det ikke skrevet flere meldinger til SQS-køen, og prosessen stopper seg selv.
Samtidighet bestemmes av antall segmenter, med tilleggskontroller levert av Lambdas samtidighetsskalering. SmugMug er i stand til å indeksere mer enn 1 milliard dokumenter i timen på deres OpenSearch-konfigurasjon, samtidig som det ikke har noen innvirkning på produksjonsdomenet.
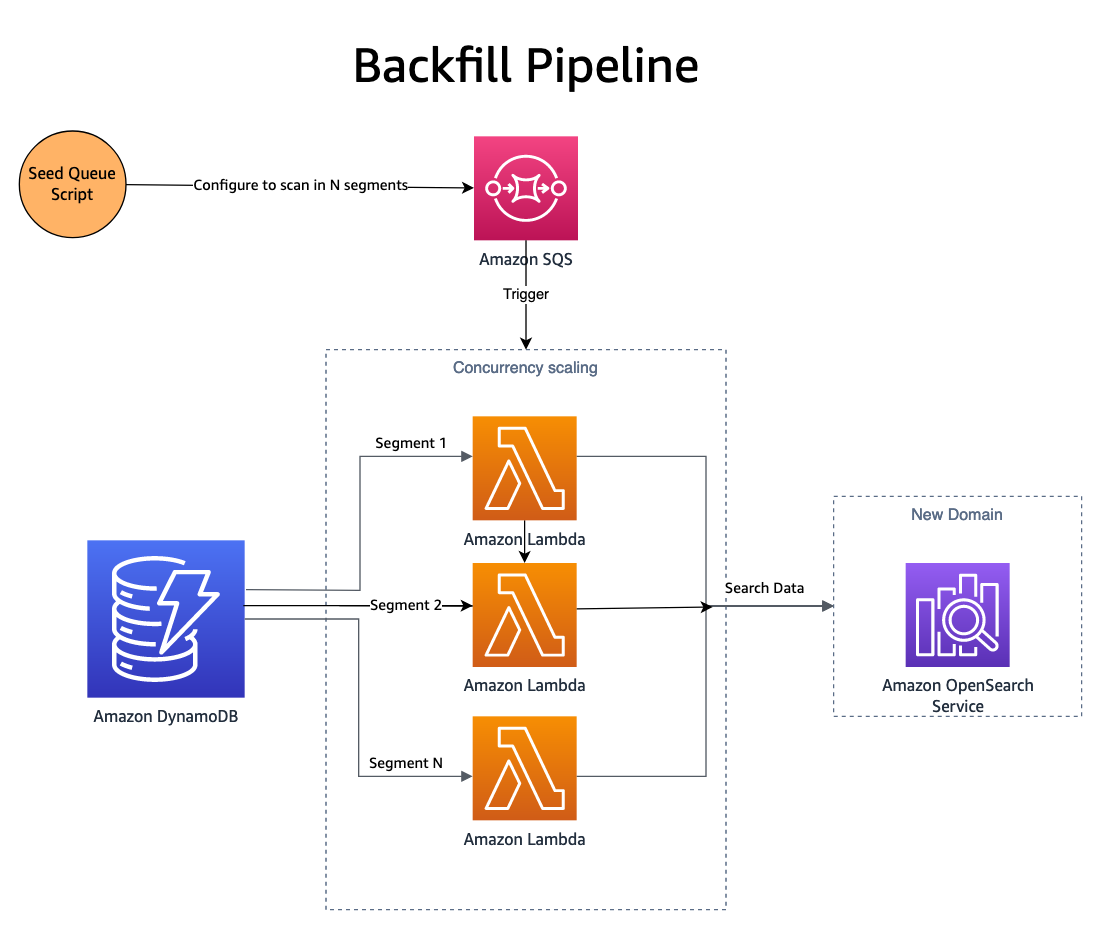
Et NodeJS AWS-SDK-basert skript brukes til å seede SQS-køen. Her er et utdrag av SQS-konfigurasjonsskriptets alternativer:
Sammen med formatet til den resulterende SQS-meldingen:
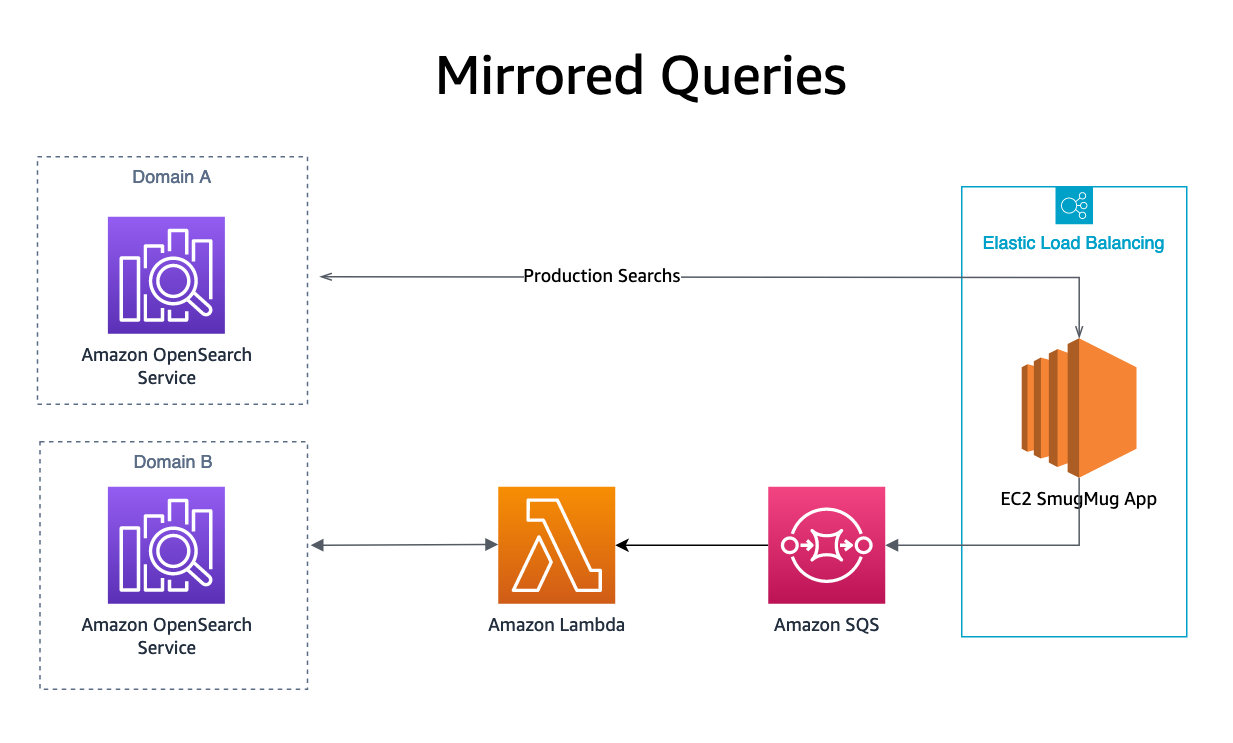
Speiling
Sist, vår speilet søk resultater kjøres ved å sende en OpenSearch-spørring til en SQS-kø, i tillegg til produksjonsdomenet vårt. SQS-køen lanserer en Lambda-funksjon som spiller av spørringen på nytt til replikadomenet. Søkeresultatene fra disse forespørslene sendes ikke til noen brukere, men tillater replikering av produksjonsbelastning på OpenSearch-tjenesten som testes uten innvirkning på produksjonssystemer eller kunder.
konklusjonen
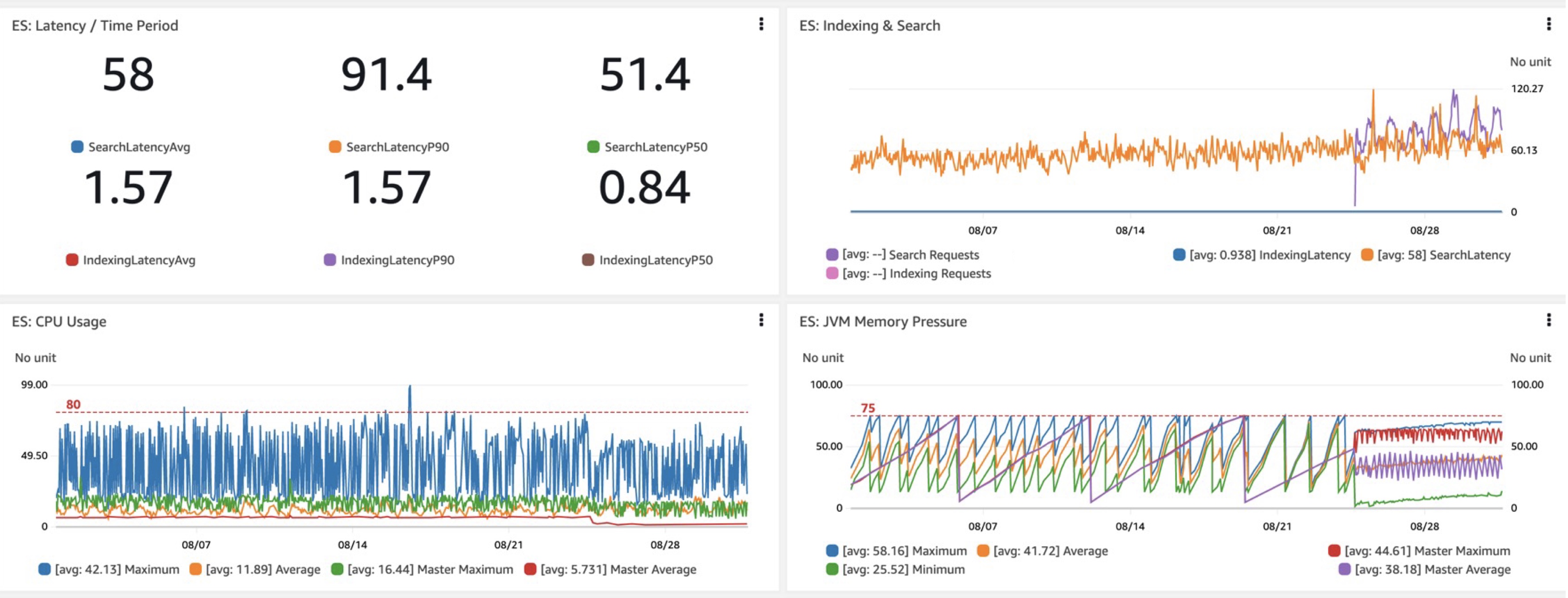
Når vi evaluerer et nytt OpenSearch-domene eller -konfigurasjon, er de viktigste beregningene vi er interessert i ytelse for spørringsforsinkelser, nemlig forsinkelser som har tatt (latenser per gang), og viktigst av alt forsinkelser for søk. I vår overgang til Graviton R6gd så vi omtrent 40 prosent lavere P50-P99-forsinkelser, sammen med lignende gevinster i CPU-bruk sammenlignet med i3-er (ignorerer Gravitons lavere kostnader). En annen velkommen fordel var det mer forutsigbare og overvåkerbare JVM-minnetrykket med søppeloppsamlingsendringene fra tillegget av G1GC på R6gd og andre nye forekomster.
Ved å bruke denne pipelinen tester vi også OpenSearch Serverless og finner de beste bruksområdene. Vi er begeistret for den tjenesten og har fullt ut til hensikt å ha en helt serverløs arkitektur i tide. Følg med for resultater.
Om forfatterne
Lee Shepherd er en SmugMug Staff Software Engineer
Aydn Bekirov er en Amazon Web Services Principal Technical Account Manager
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/smugmugs-durable-search-pipelines-for-amazon-opensearch-service/
- :er
- :ikke
- 1
- 100
- 12
- 14
- 20
- 2012
- 2018
- 40
- 7
- 9
- a
- I stand
- Om oss
- Logg inn
- la til
- tillegg
- Ytterligere
- Etter
- tillate
- tillate
- langs
- også
- Amazon
- Amazon Web Services
- an
- og
- En annen
- noen
- arkitektonisk
- arkitektur
- ER
- AS
- eiendel
- At
- Aurora
- AWS
- Backup
- basert
- BE
- før du
- være
- benchmark
- nytte
- Fordeler
- BEST
- Beyond
- Milliarder
- milliarder
- både
- men
- by
- teksting
- Endringer
- samling
- kombinasjon
- kombinere
- sammenlignet
- kompatibel
- Fullfører
- samtidig
- Konfigurasjon
- konfigurert
- inneholde
- kontroller
- Tilsvarende
- Kostnader
- dekke
- prosessor
- opprettet
- kritisk
- Kritisk infrastruktur
- Kunder
- dato
- tiår
- Gjenkjenning
- Bestem
- bestemmes
- dokument
- dokumenter
- domene
- domener
- drevet
- hver enkelt
- muliggjør
- muliggjør
- Endpoint
- ingeniør
- går inn
- fullstendig
- Miljø
- Eter (ETH)
- evaluere
- hendelser
- eksempel
- opphisset
- Noen få
- Felt
- finne
- Først
- passer
- fulgt
- Til
- format
- fra
- fullt
- funksjon
- inntjening
- Økende
- Ha
- høyde
- hjulpet
- hjelper
- historisk
- time
- HTML
- http
- HTTPS
- i
- i3
- ID
- Påvirkning
- viktigere
- in
- Inkludert
- indeks
- indekser
- Infrastruktur
- forekomster
- instruksjoner
- integrering
- hensikt
- interessert
- inn
- innføre
- påkaller
- varer
- køyring
- DET ER
- selv
- jpg
- Hold
- holde
- nøkkel
- nøkkelord
- Etiketten
- stor
- Ventetid
- lanseringer
- Lee
- i likhet med
- leve
- laste
- Lot
- lavere
- Hoved
- Minne
- melding
- meldinger
- Metrics
- migrere
- Migrere
- migrasjon
- millioner
- millioner kunder
- speil
- mer
- mest
- flytte
- flere
- MySQL
- navn
- nemlig
- Naturlig
- behov
- Ny
- nylig
- neste
- Nei.
- Antall
- of
- off
- on
- på nett
- opererer
- alternativer
- opts
- or
- Annen
- vår
- Parallel
- del
- mønstre
- for
- prosent
- ytelse
- bilde
- Bilder
- stykker
- rørledning
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Forutsigbar
- press
- forrige
- Principal
- prosess
- behandlet
- Produksjon
- Progress
- forutsatt
- gir
- publisere
- publisert
- Publisering
- nå
- redusere
- svare
- forespørsler
- påkrevd
- resulterende
- Resultater
- Kjør
- trygt
- samme
- så
- skalerbarhet
- skalering
- script
- Søk
- søker
- seed
- segmentet
- segmenter
- selger
- sending
- sendt
- server~~POS=TRUNC
- tjeneste
- Tjenester
- Del
- Aksjer
- lignende
- Enkelt
- samtidig
- siden
- enkelt
- tekstutdrag
- So
- Software
- kilde
- Staff
- opphold
- stadig
- Stopper
- lagring
- oppbevare
- butikker
- Strategi
- bekker
- slik
- Systemer
- bord
- tar
- Teknisk
- titus
- test
- Testing
- enn
- Det
- De
- Kilden
- deres
- Dem
- Der.
- Disse
- denne
- tre
- Gjennom
- tid
- til
- tok
- spor
- trafikk
- utløse
- Sannhet
- SVING
- to
- etter
- oppdatert
- oppdateringer
- Opplasting
- URL
- bruk
- bruke
- bruk-tilfeller
- brukt
- Bruker
- bruker
- ved hjelp av
- VALIDERE
- verdi
- versjon
- veldig
- var
- we
- web
- webtjenester
- velkommen
- Hva
- når
- mens
- med
- uten
- skrive
- skriving
- skrevet
- zephyrnet
- null