Så du har sett alle veiledningene. Du forstår nå hvordan et nevralt nettverk fungerer. Du har bygget en katt- og hundklassifiser. Du prøvde deg på et halvt anstendig RNN på karakternivå. Du er bare en pip install tensorflow unna å bygge terminatoren, ikke sant? Feil.

En svært viktig del av dyp læring er å finne de riktige hyperparametrene. Dette er tall som modellen kan ikke lære.
I denne artikkelen vil jeg lede deg gjennom noen av de vanligste (og viktige) hyperparametrene du vil møte på veien til #1-plassen på Kaggle-poengtavlene. I tillegg vil jeg også vise deg noen kraftige algoritmer som kan hjelpe deg med å velge hyperparametrene dine med omhu.
Hyperparametere i dyp læring
Hyperparametere kan betraktes som tuning-knottene til modellen din.
Et fancy 7.1 Dolby Atmos hjemmekinosystem med en subwoofer som produserer bass utenfor det menneskelige ørets hørbare rekkevidde er ubrukelig hvis du setter AV-receiveren på stereo.

På samme måte vil en inception_v3 med en billion parametere ikke engang få deg forbi MNIST hvis hyperparametrene dine er av.
Så nå, la oss ta en titt på knottene for å stille inn før vi kommer inn på hvordan du ringer inn de riktige innstillingene.
Læringsgrad
Uten tvil den viktigste hyperparameteren, læringshastigheten, kontrollerer grovt sett hvor raskt det nevrale nettet ditt "lærer".
Så hvorfor forsterker vi ikke dette og lever livet på hurtigbanen?

Ikke så enkelt. Husk at i dyp læring er målet vårt å minimere en tapsfunksjon. Hvis læringsraten er for høy, vil tapet vårt begynne å hoppe over alt og aldri konvergere.

Og hvis læringsraten er for liten, vil modellen ta altfor lang tid å konvergere, som illustrert ovenfor.
Momentum
Siden denne artikkelen fokuserer på hyperparameteroptimalisering, skal jeg ikke forklare hele konseptet momentum. Men kort fortalt kan momentumkonstanten betraktes som massen til en ball som ruller nedover overflaten til tapsfunksjonen.
Jo tyngre ballen, jo raskere faller den. Men hvis den er for tung, kan den sette seg fast eller overskride målet.

dropout
Hvis du føler et tema her, skal jeg nå henvise deg til Amar Budhirajasin artikkel om frafall.

Men som en rask oppfriskning er dropout en regulariseringsteknikk foreslått av Geoff Hinton som tilfeldig setter aktiveringer i et nevralt nettverk til 0 med en sannsynlighet på (p). Dette bidrar til å forhindre at nevrale nett overpasser (memorerer) dataene i motsetning til å lære dem.
(p) er en hyperparameter.
Arkitektur — antall lag, nevroner per lag, etc.
En annen (ganske fersk) idé er å gjøre selve arkitekturen til det nevrale nettverket til en hyperparameter.
Selv om vi vanligvis ikke får maskiner til å finne ut arkitekturen til modellene våre (ellers ville AI-forskere mistet jobben), noen nye teknikker som f.eks. Nevral arkitektur søk har blitt implementert denne ideen med ulik grad av suksess.
Hvis du har hørt om AutoML, dette er i utgangspunktet hvordan Google gjør det: gjør alt til en hyperparameter og deretter kaste en milliard TPUer på problemet og la det løse seg selv.
Men for de aller fleste av oss som bare ønsker å klassifisere katter og hunder med en budsjettmaskin brosteinsbelagt etter et Black Friday-salg, er det på tide at vi finner ut hvordan vi kan få disse dyplæringsmodellene til å fungere.
Hyperparameteroptimaliseringsalgoritmer
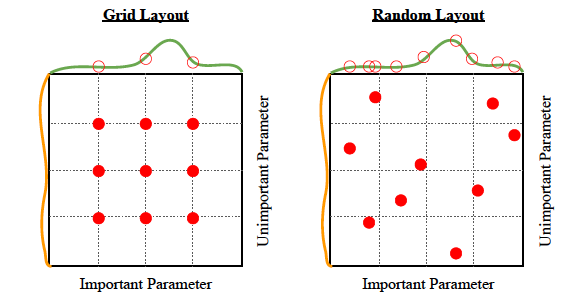
Rutenett søk
Dette er den enkleste måten å få gode hyperparametre på. Det er bokstavelig talt bare brute force.
Algoritmen: Prøv ut en haug med hyperparametre fra et gitt sett med hyperparametre, og se hva som fungerer best.
Pros: Det er enkelt nok for en femteklassing å implementere. Kan lett parallelliseres.
Ulemper: Som du sikkert har gjettet, er det vanvittig beregningsmessig dyrt (som alle brute force-metoder er).
Bør jeg bruke det: Sannsynligvis ikke. Rutenettsøk er fryktelig ineffektivt. Selv om du ønsker å holde det enkelt, er det bedre å bruke tilfeldig søk.
Tilfeldig søk
Alt ligger i navnet – tilfeldige søk. Tilfeldig.
Algoritmen: Prøv ut en haug med tilfeldige hyperparametre fra en enhetlig fordeling over et hyperparameterrom, og se hva som fungerer best.
Pros: Kan lett parallelliseres. Like enkelt som rutenettsøk, men litt bedre ytelse, som illustrert nedenfor:

Ulemper: Selv om det gir bedre ytelse enn rutenettsøk, er det fortsatt like beregningsintensivt.
Bør jeg bruke det: Hvis triviell parallellisering og enkelhet er av største betydning, gå for det. Men hvis du kan spare tid og krefter, vil du bli belønnet stort ved å bruke Bayesian Optimization.
Bayesian Optimalisering
I motsetning til de andre metodene vi har sett så langt, bruker Bayesiansk optimalisering kunnskap om tidligere iterasjoner av algoritmen. Med rutenettsøk og tilfeldig søk er hver hyperparametergjetning uavhengig. Men med Bayesianske metoder, hver gang vi velger og prøver ut forskjellige hyperparametre, tommer mot perfeksjon.

Ideene bak Bayesiansk hyperparameterinnstilling er lange og detaljrike. Så for å unngå for mange kaninhull, skal jeg gi deg kjernen her. Men husk å lese deg opp Gaussiske prosesser og Bayesiansk optimalisering generelt, hvis det er den typen ting du er interessert i.
Husk at grunnen til at vi bruker disse hyperparameterjusteringsalgoritmene er at det er umulig å faktisk evaluere flere hyperparametervalg individuelt. La oss for eksempel si at vi ønsket å finne en god læringsrate manuelt. Dette vil innebære å sette en læringsrate, trene modellen din, evaluere den, velge en annen læringshastighet, trene modellen fra bunnen av igjen, revurdere den, og syklusen fortsetter.
Problemet er at det kan ta opptil dager (avhengig av kompleksiteten til problemet) å fullføre «å trene modellen din». Så du vil bare være i stand til å prøve noen få læringshastigheter når fristen for innlevering av papirer for konferansen går ut. Og hva vet du, du har ikke engang begynt å leke med farten. Oops.

Algoritmen: Bayesianske metoder prøver å bygge en funksjon (mer nøyaktig, en sannsynlighetsfordeling over mulig funksjon) som estimerer hvor god modellen din kunne være for et bestemt valg av hyperparametere. Ved å bruke denne omtrentlige funksjonen (kalt en surrogatfunksjon i litteraturen), trenger du ikke å gå gjennom settet, trene, evaluere loopen for mye tid, siden du bare kan optimere hyperparametrene til surrogatfunksjonen.
Som et eksempel, si at vi ønsker å minimere denne funksjonen (tenk på det som en proxy for modellens tapsfunksjon):

Surrogatfunksjonen kommer fra noe som kalles en Gauss-prosess (merk: det er andre måter å modellere surrogatfunksjonen på, men jeg bruker en Gauss-prosess). Som jeg nevnte, jeg kommer ikke til å gjøre noen matematiske avledninger, men her er hva alt det snakket om bayesianere og gaussere koker ned til:
$$ mathbb{P} (F_n(X)|X_n) = frac{e^{-frac12 F_n^T Sigma_n^{-1} F_n}}{sqrt{(2pi)^n |Sigma_n|}} $$
Noe som riktignok er en munnfull. Men la oss prøve å bryte det ned.
Venstre side forteller deg at en sannsynlighetsfordeling er involvert (gitt tilstedeværelsen av den fancy looken ( mathbb{P} ) ). Ser vi innenfor parentesene, kan vi se at det er en sannsynlighetsfordeling på ( F_n(X) ), som er en eller annen vilkårlig funksjon. Hvorfor? For husk, vi definerer en sannsynlighetsfordeling over alle mulige funksjoner, ikke bare en bestemt. I hovedsak sier venstre side at sannsynligheten for at den sanne funksjonen som kartlegger hyperparametre til modellens beregninger (som valideringsnøyaktighet, logg sannsynlighet, testfeilrate, etc.) er ( F_n(X) ), gitt noen eksempeldata (X_n) er lik det som er på høyre side.
Nå som vi har funksjonen for å optimalisere, optimaliserer vi den.
Her er hvordan den Gaussiske prosessen vil se ut før vi starter optimaliseringsprosessen:

Bruk favorittoptimalisatoren du velger (proffene liker å maksimere forventet forbedring), men på en eller annen måte, følg bare skiltene (eller gradientene) og før du vet ordet av det, vil du ende opp på ditt lokale minimum.
Etter noen iterasjoner blir den gaussiske prosessen bedre til å tilnærme målfunksjonen:

Uavhengig av metoden du brukte, har du nå funnet `argmin` av surrogatfunksjonen. Ans overraskelse, overraskelse, de argumentene som minimerer surrogatfunksjonen er (et estimat av) de optimale hyperparametrene! Jippi.
Det endelige resultatet skal se slik ut:

Bruk disse "optimale" hyperparametrene for å kjøre et treningsløp på nevrale nettet ditt, og du bør se en viss forbedring. Men du kan også bruke denne nye informasjonen til å gjøre om hele den Bayesianske optimaliseringsprosessen, igjen, og igjen, og igjen. Kjør gjerne Bayesian-sløyfen hvor mange ganger du vil, men vær forsiktig. Du regner faktisk ting. Disse AWS-kredittene kommer ikke gratis, vet du. Eller gjør de...
Pros: Bayesiansk optimalisering gir bedre resultater enn både rutenettsøk og tilfeldig søk.
Ulemper: Det er ikke like lett å parallellisere.
Bør jeg bruke det: I de fleste tilfeller, ja! De eneste unntakene vil være hvis
- Du er en dyp læringsekspert, og du trenger ikke hjelp av en mektig tilnærmingsalgoritme.
- Du har tilgang til enorme beregningsressurser og kan massivt parallellisere rutenettsøk og tilfeldig søk.
- Hvis du er en frekventist/anti-bayesiansk statistikknerd.
En alternativ tilnærming til å finne en god læringsrate
I alle metodene vi har sett så langt, er det ett underliggende tema: automatiser jobben til maskinlæringsingeniøren. Som er flott og alt; til sjefen din får vite om dette og bestemmer seg for å erstatte deg med 4 RTX Titan-kort. Hu h. Tror du burde ha holdt deg til manuelt søk.

Men fortvil ikke, det forskes aktivt på feltet om å få forskere til å gjøre mindre og samtidig få mer betalt. Og en av ideene som har fungert ekstremt bra er læringshastighetstesten, som så vidt jeg vet først dukket opp i en papir av Leslie Smith.
Oppgaven handler faktisk om en metode for å planlegge (endre) læringsraten over tid. LR (læringshastighet) rekkeviddestesten var en gullklump som forfatteren bare tilfeldig falt på siden.
Når du bruker en læringshastighetsplan som varierer læringshastigheten fra en minimums- til maksimumsverdi, for eksempel sykliske læringsrater or stokastisk gradientnedstigning med varme omstarter, foreslår forfatteren å lineært øke læringsraten etter hver iterasjon fra en liten til en stor verdi (si, 1e-7 til 1e-1), evaluer tapet ved hver iterasjon, og plott tapet (eller testfeil eller nøyaktighet) mot læringsraten på en loggskala. Plottet ditt skal se omtrent slik ut:

Som markert på plottet, bruker du deretter sette læringsfrekvensplanen din til å sprette mellom minimum og maksimum læringshastighet, som du finner ved å se på plottet og prøve å se området med den bratteste gradienten.
Her er et eksempel på LR-områdetestplott (DenseNet trent på CIFAR10) fra vår Colab bærbare:

Som en tommelfingerregel, hvis du ikke gjør noen fancy læringshastighetsplaner, setter du bare den konstante læringshastigheten til en størrelsesorden lavere enn minimumsverdien på plottet. I dette tilfellet vil det være omtrentlig 1e-2.
Den kuleste delen med denne metoden, bortsett fra at den fungerer veldig bra og sparer deg for tid, mental innsats og beregning som kreves for å finne gode hyperparametre med andre algoritmer, er at den praktisk talt ikke koster noen ekstra beregning.
Mens de andre algoritmene, nemlig rutenettsøk, tilfeldig søk og Bayesian Optimalisering, krever at du kjører et helt prosjekt som tangerer målet ditt om å trene et godt nevralt nett, LR-rekkeviddestesten utfører bare en enkel, vanlig treningsløkke og holder styr på noen få variabler underveis.
Her er typen konvergenshastighet du kan forvente når du bruker en optimal læringshastighet (fra eksempelet i bærbare):

LR rekkeviddestesten er implementert av teamet kl fort.ai, og du bør definitivt ta en titt på biblioteket deres for å implementere LR range-testen (de kaller det læringsratefinner) så vel som mange andre algoritmer med letthet.
For den mer sofistikerte dyplæringsutøveren
Hvis du er interessert, er det også en notatbok skrevet i ren pytorch som implementerer ovennevnte. Dette kan gi deg en bedre forståelse av opplæringsprosessen bak kulissene. Sjekk det ut her..
Spar deg selv innsatsen

Selvfølgelig fungerer ikke alle disse algoritmene, like gode som de er, i praksis. Det er mange flere faktorer å vurdere når du trener nevrale nett, for eksempel hvordan du skal forhåndsbehandle dataene dine, definere modellen din og faktisk få en datamaskin som er kraftig nok til å kjøre den jævla greia.
Nanonetter gir enkel å bruke APIer til trene og implementere tilpasset dyplæring modeller. Den tar seg av alle de tunge løftene, inkludert dataforsterkning, overføringslæring og ja, hyperparameteroptimalisering!
Nanonetter bruker Bayesiansk søk på deres enorme GPU-klynger for å finne det riktige settet med hyperparametre uten at du trenger å bekymre deg for å blåse penger på det nyeste grafikkortet og out of bounds for axis 0.
Når den finner den beste modellen, Nanonetter serverer den på nettskyen deres slik at du kan teste modellen ved hjelp av deres nettgrensesnitt eller integrere den i programmet ved hjelp av 2 linjer med kode.
Si farvel til mindre enn perfekte modeller.
konklusjonen
I denne artikkelen har vi snakket om hyperparametre og noen få metoder for å optimalisere dem. Men hva betyr det hele?
Etter hvert som vi prøver hardere og hardere å demokratisere AI-teknologi, er automatisert hyperparameterinnstilling sannsynligvis et skritt i riktig retning. Det lar vanlige folk som deg og meg bygge fantastiske dyplæringsapplikasjoner uten en matte-ph.d.
Mens du kan argumentere for at det å gjøre modeller sultne på datakraft overlater de aller beste modellene i hendene på de som har råd til denne datakraften, hjelper skytjenester som AWS og Nanonets med å demokratisere tilgangen til kraftige maskiner, noe som gjør dyp læring langt mer tilgjengelig.
Men mer fundamentalt, hva vi er faktisk gjør her ved å bruke matematikk for å løse mer matematikk. Noe som er interessant ikke bare på grunn av hvordan meta det høres ut, men også på grunn av hvor lett det kan mistolkes.

Vi har absolutt kommet langt fra epoken med hullkort og sporingstabeller til en alder hvor vi optimerer funksjoner som optimerer funksjoner som optimerer funksjoner. Men vi er ikke i nærheten av å bygge maskiner som kan "tenke" på egenhånd.
Og det er ikke nedslående, ikke i det minste, for hvis menneskeheten kan gjøre så mye med så lite, forestill deg hva fremtiden bringer, når visjonene våre blir noe vi faktisk kan se.
Og så sitter vi, på en polstret nettingstol og stirrer på en tom terminalskjerm, og hvert tastetrykk gir oss en sudo superkraft som kan tørke disken ren.
Og så sitter vi, vi sitter der hele dagen, for det neste store gjennombruddet er kanskje bare ett pip install borte.
Lat til å kode? Vil du ikke bruke på dataressurser? Gå over til Nanonetter og Begynn å bygge en modell nå!
Du kan være interessert i de siste innleggene våre på:
Kilde: https://nanonets.com/blog/hyperparameter-optimization/
- 7
- 9
- adgang
- aktiv
- AI
- algoritme
- algoritmer
- Alle
- amp
- APIer
- søknader
- arkitektur
- argumenter
- Artikkel
- Audible
- Automatisert
- AV
- AWS
- BEST
- Milliarder
- Bit
- Svart
- Black Friday
- bygge
- Bygning
- Bunch
- ring
- hvilken
- saker
- Kontanter
- Katter
- Cloud
- skytjenester
- kode
- Felles
- Beregn
- databehandling
- databehandlingskraft
- Konferanse
- fortsetter
- Kostnader
- studiepoeng
- dato
- dag
- dyp læring
- hunder
- droppet
- ingeniør
- estimater
- etc
- FAST
- Figur
- funn
- Først
- passer
- følge
- Gratis
- Fredag
- FS
- funksjon
- framtid
- gif
- GitHub
- Giving
- Gull
- god
- GPU
- flott
- Grid
- hode
- her.
- Høy
- Hjemprodukt
- Hvordan
- Hvordan
- HTTPS
- Sulten
- Tanken
- inches
- Inkludert
- informasjon
- involvert
- IT
- Jobb
- Jobb
- holde
- kunnskap
- stor
- siste
- LÆRE
- læring
- Bibliotek
- litteratur
- lokal
- logo
- Lang
- maskinlæring
- maskiner
- Flertall
- Making
- Kart
- math
- Media
- medium
- meme
- Meta
- Metrics
- modell
- Momentum
- nemlig
- nett
- nettverk
- neural
- nevrale nettverket
- tall
- rekkefølge
- Annen
- Papir
- ytelse
- innlegg
- makt
- program
- prosjekt
- proxy
- punsj
- område
- priser
- RE
- forskning
- Ressurser
- Resultater
- Kjør
- salg
- Skala
- Skjerm
- Søk
- Tjenester
- sett
- innstilling
- Kort
- Skilt
- Enkelt
- liten
- So
- LØSE
- Rom
- fart
- bruke
- Spot
- Begynn
- startet
- statistikk
- suksess
- overflaten
- overraskelse
- system
- Target
- Teknologi
- test
- Fremtiden
- teater
- tema
- tid
- spor
- Kurs
- tutorials
- Unsplash
- us
- verktøyet
- verdi
- Se
- web
- HVEM
- vind
- Arbeid
- virker
- X







{kind=link}
{kind=link}
{kind=link}