AWS Lim Studio er nå integrert med AWS Lim DataBrew. AWS Glue Studio er et grafisk grensesnitt som gjør det enkelt å lage, kjøre og overvåke ekstrahere, transformere og laste (ETL) jobber i AWS Lim. DataBrew er et visuelt dataforberedelsesverktøy som lar deg rense og normalisere data uten å skrive noen kode. De over 200 transformasjonene den gir, er nå tilgjengelig for bruk i en visuell jobb i AWS Glue Studio.
I DataBrew, en . er et sett med datatransformasjonstrinn som du kan skrive interaktivt i det intuitive visuelle grensesnittet. I dette innlegget vil du se hvordan du bruker å bygge en oppskrift i DataBrew og deretter bruke den som en del av en AWS Glue Studio visuell ETL-jobb.
Eksisterende DataBrew-brukere vil også dra nytte av denne integrasjonen – du kan nå kjøre oppskriftene dine som en del av en større visuell arbeidsflyt med alle de andre komponentene AWS Glue Studio tilbyr, i tillegg til å kunne bruke avansert jobbkonfigurasjon og den nyeste versjonen av AWS Glue Engine .
Denne integrasjonen gir distinkte fordeler for eksisterende brukere av begge verktøyene:
- Du har en sentralisert visning i AWS Glue Studio av det overordnede ETL-diagrammet, ende til ende
- Du kan interaktivt definere en oppskrift, se verdier, statistikk og distribusjon på DataBrew-konsollen, og deretter gjenbruke den testede og versjonerte prosesseringslogikken i AWS Glue Studio visuelle jobber
- Du kan orkestrere flere DataBrew-oppskrifter i en AWS Glue ETL-jobb eller til og med flere jobber ved å bruke AWS Glue-arbeidsflyter
- DataBrew-oppskrifter kan nå bruke AWS-limjobbfunksjoner som bokmerker for inkrementell databehandling, automatiske forsøk på nytt, automatisk skalering eller gruppering av små filer for større effektivitet
Løsningsoversikt
I vårt fiktive brukstilfelle er kravet å rydde opp i et syntetisk medisinsk påstandsdatasett opprettet for dette innlegget, som har noen datakvalitetsproblemer introdusert med vilje for å demonstrere DataBrew-funksjonene for dataforberedelse. Deretter tas påstandsdataene inn i katalogen (slik at den er synlig for analytikere), etter å ha beriket den med noen relevante detaljer om de tilsvarende medisinske leverandørene som kommer fra en egen kilde.
Løsningen består av en AWS Glue Studio visuell jobb som leser to CSV-filer med henholdsvis krav og leverandører. Jobben bruker en oppskrift av den første for å løse kvalitetsproblemene, velge kolonner fra den andre, slå sammen begge datasettene og til slutt lagre resultatet på Amazon enkel lagringstjeneste (Amazon S3), lage en tabell i katalogen slik at utdataene kan brukes av andre verktøy som Amazonas Athena.
Lag en DataBrew-oppskrift
Start med å registrere datalageret for skadefilen. Dette vil tillate deg å bygge oppskriften i dens interaktive editor ved å bruke de faktiske dataene, slik at du kan evaluere resultatet av transformasjonene slik du definerer dem.
- Last ned CSV-filen for krav ved å bruke følgende lenke: alabama_claims_data_Jun2023.csv.
- Velg på DataBrew-konsollen datasett i navigasjonsruten, og velg deretter Koble til nytt datasett.
- Velg alternativet Filopplasting.
- Til Datasettnavn, Tast inn
Alabama claims. - Til Velg en fil du vil laste opp, velg filen du nettopp lastet ned på datamaskinen.
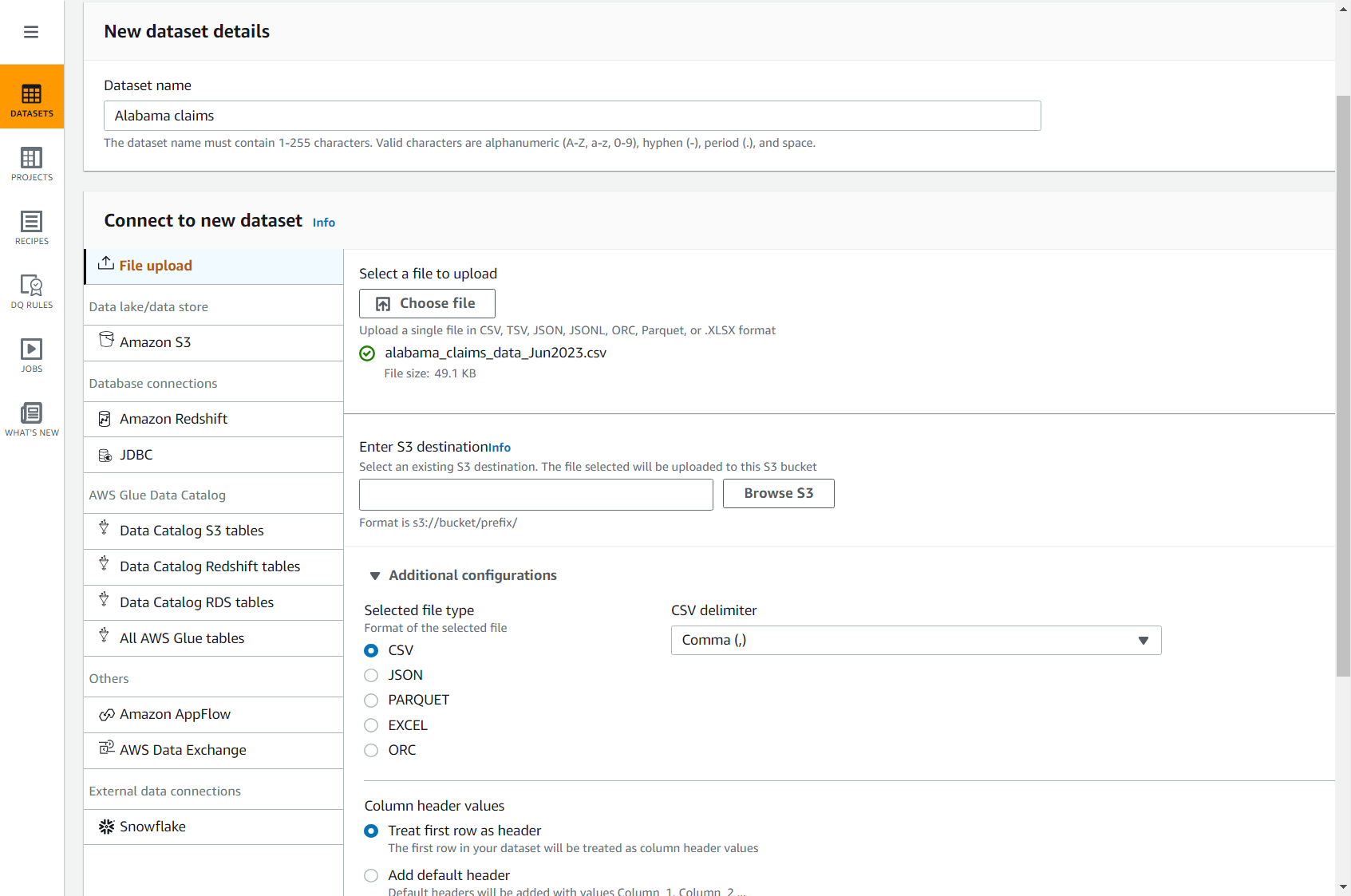
- Til Angi S3-destinasjon, skriv inn eller bla gjennom en bøtte i kontoen din og regionen.
- La resten av alternativene være som standard (CSV atskilt med komma og med overskrift) og fullfør datasettopprettelsen.
- Velg Prosjekt i navigasjonsruten, og velg deretter Opprett prosjekt.
- Til Prosjektnavn, navngi det
ClaimsCleanup. - Under OppskriftsdetaljerFor Vedlagt oppskrift, velg Lag ny oppskrift, navngi det
ClaimsCleanup-recipe, og velgAlabama claimsdatasettet du nettopp opprettet.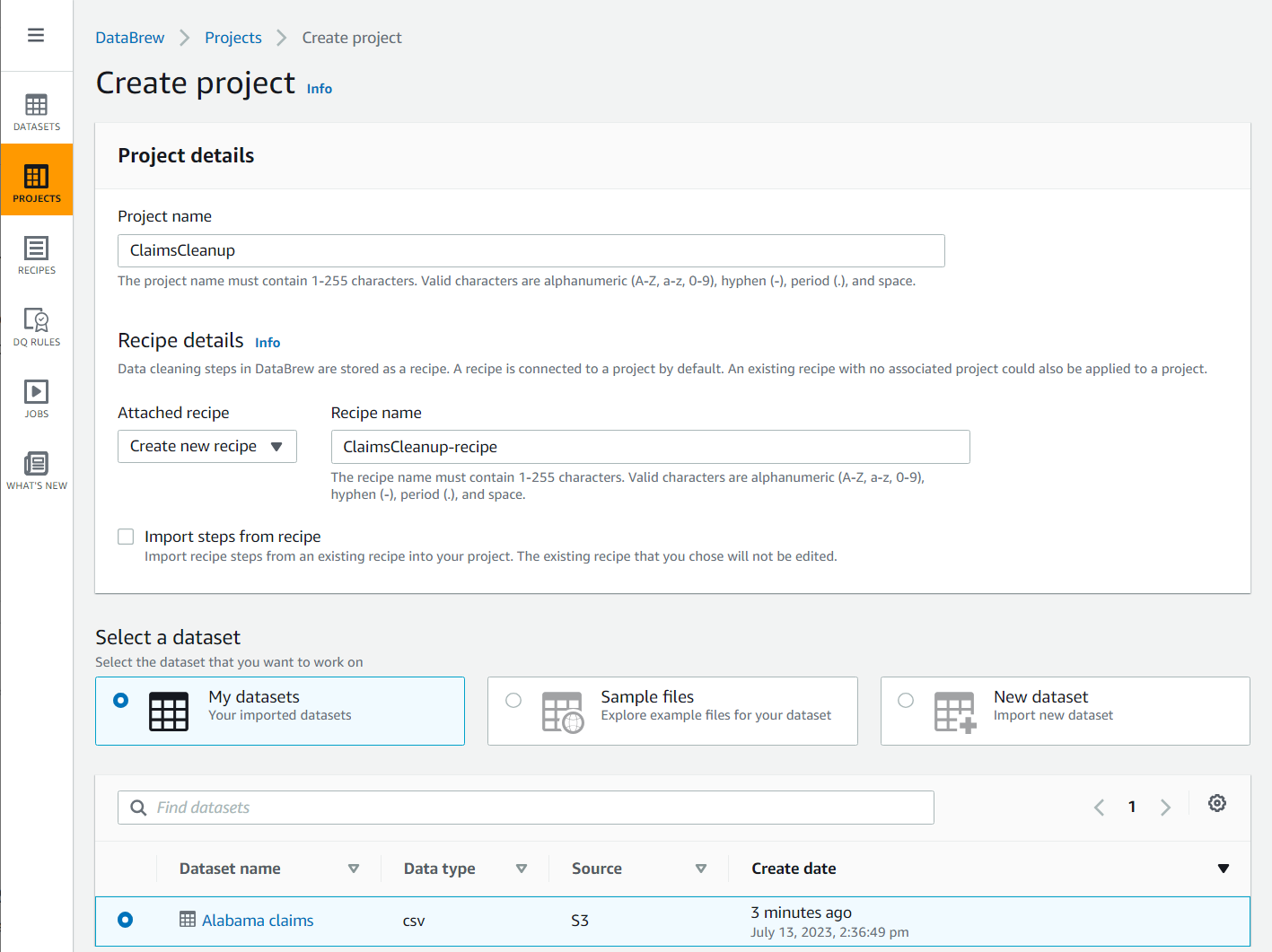
- Velg en rolle egnet for DataBrew eller opprett en ny, og fullfør prosjektopprettingen.
Dette vil opprette en økt med et konfigurerbart delsett av dataene. Etter at den har initialisert økten, kan du legge merke til at noen av cellene har ugyldige eller manglende verdier.
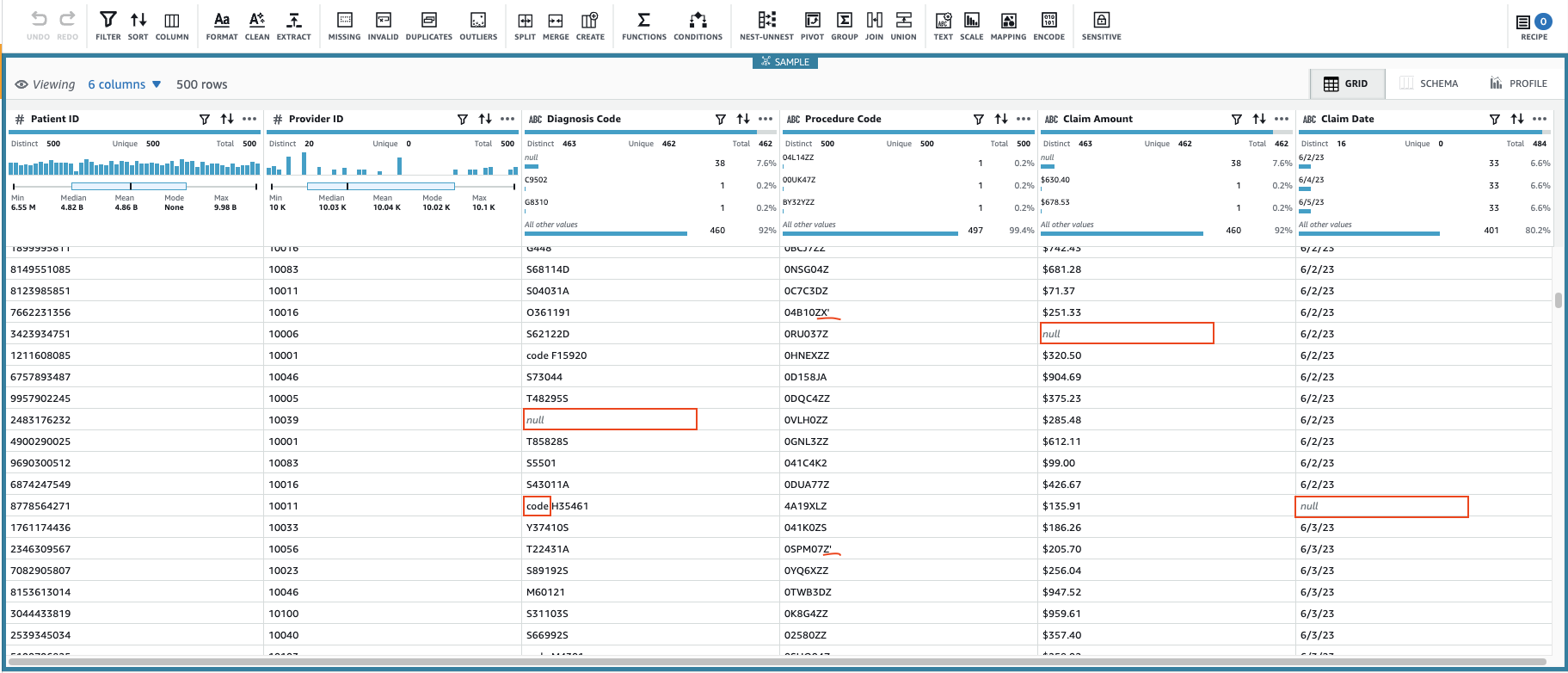
I tillegg til de manglende verdiene i kolonnene Diagnosekode, Kravsbeløpog Kravdato, noen verdier i dataene har noen ekstra tegn: Diagnosekode verdier er noen ganger prefikset med "kode" (mellomrom inkludert), og Prosedyrekode verdier blir noen ganger fulgt av enkle anførselstegn.
Kravsbeløp verdier vil sannsynligvis bli brukt for noen beregninger, så konverter til tall, og Krev data skal konverteres til datotype.
Nå som vi har identifisert datakvalitetsproblemene som skal løses, må vi bestemme hvordan vi skal håndtere hvert enkelt tilfelle.
Det er flere måter du kan legge til oppskriftstrinn, inkludert å bruke kolonnekontekstmenyen, verktøylinjen øverst eller fra oppskriftssammendraget. Ved å bruke den siste metoden kan du søke etter den angitte trinntypen for å replikere oppskriften som ble opprettet i dette innlegget.
Kravsbeløp er avgjørende for denne brukssaken, og beslutningen er å fjerne slike rader.
- Legg til trinnet Fjern manglende verdier.
- Til Kildekolonne, velg Kravsbeløp.
- Forlat standardhandlingen Slett rader med manglende verdier Og velg Påfør å lagre det.
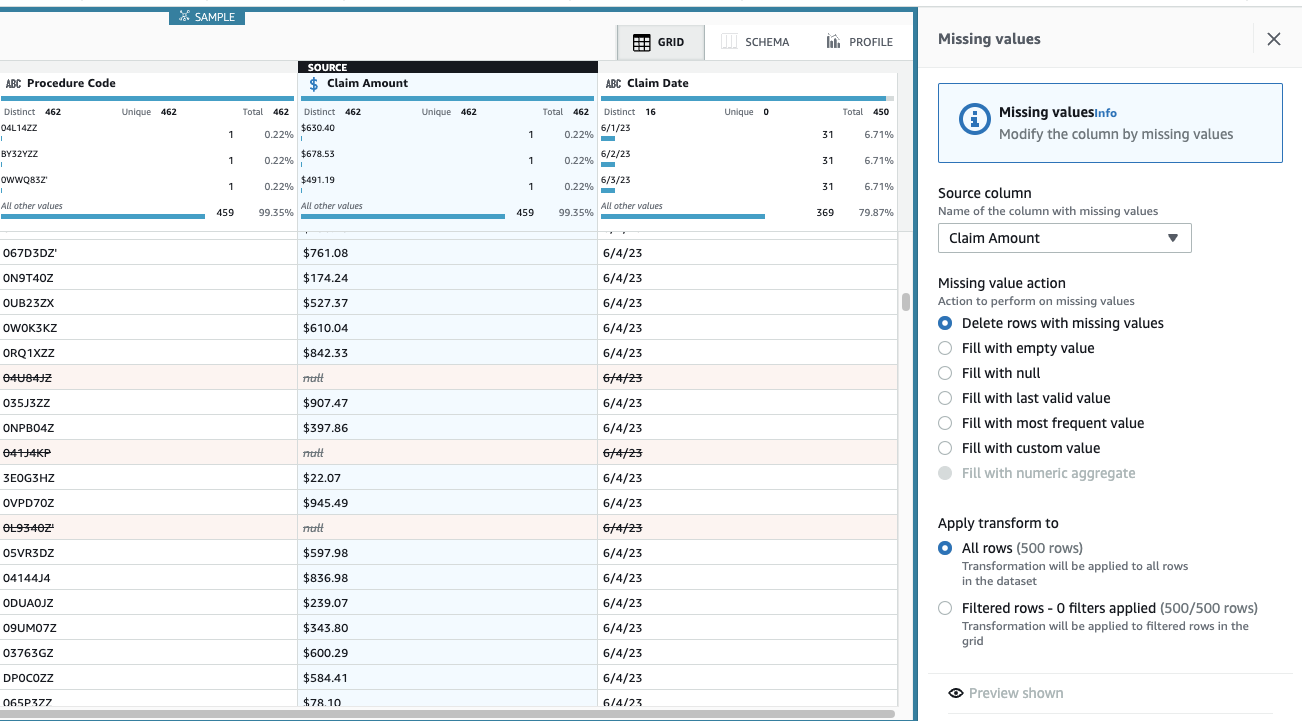
Visningen er nå oppdatert for å gjenspeile trinnapplikasjonen, og radene med manglende beløp er ikke lenger der.
Diagnosekode kan være tom så dette aksepteres, men i tilfelle Kravdato, ønsker vi å ha et rimelig estimat. Radene i dataene er sortert i kronologisk rekkefølge, slik at du kan beregne manglende datoer ved å bruke forhåndsvisningens gyldige verdi fra de foregående radene. Forutsatt at hver dag har krav, ville den største feilen være å tilordne den til forhåndsvisningsdagen hvis det var det første kravet den dagen som mangler datoen; for illustrasjonsformål, la oss vurdere den potensielle feilen som akseptabel.
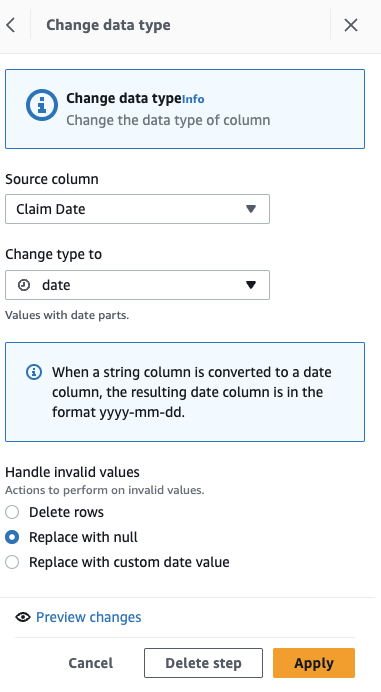
Konverter først kolonnen fra streng til datotype.
- Legg til trinnet Endre type.
- Velg Kravdato som kolonnen og data som type, velg deretter Påfør.
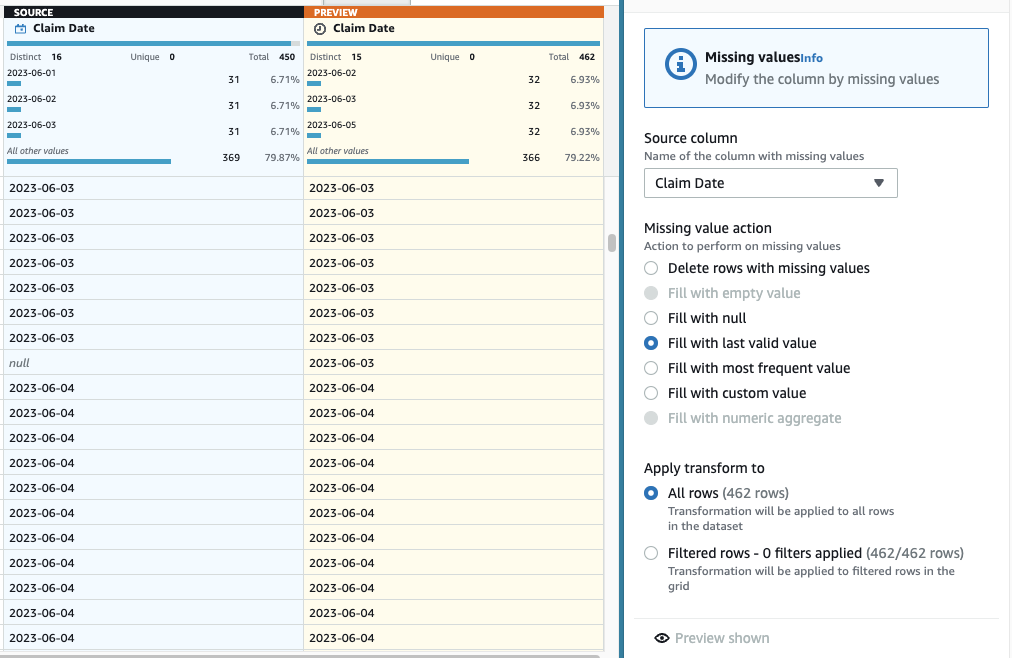
- Legg til trinnet for å beregne manglende datoer Fyll ut eller tilskriv manglende verdier.
- Velg Fyll med siste gyldige verdi som handling og velg Kravdato som kilde.
- Velg Forhåndsvisning av endringer for å validere det, velg deretter Påfør for å redde trinnet.
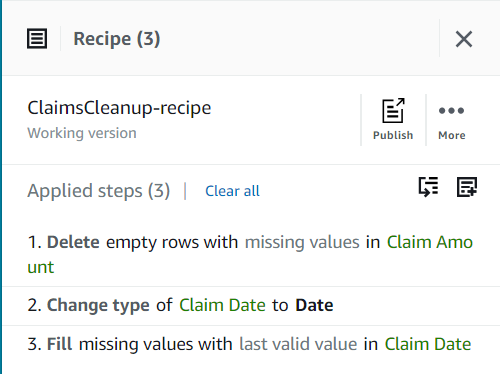
Så langt skal oppskriften din ha tre trinn, som vist i følgende skjermbilde.
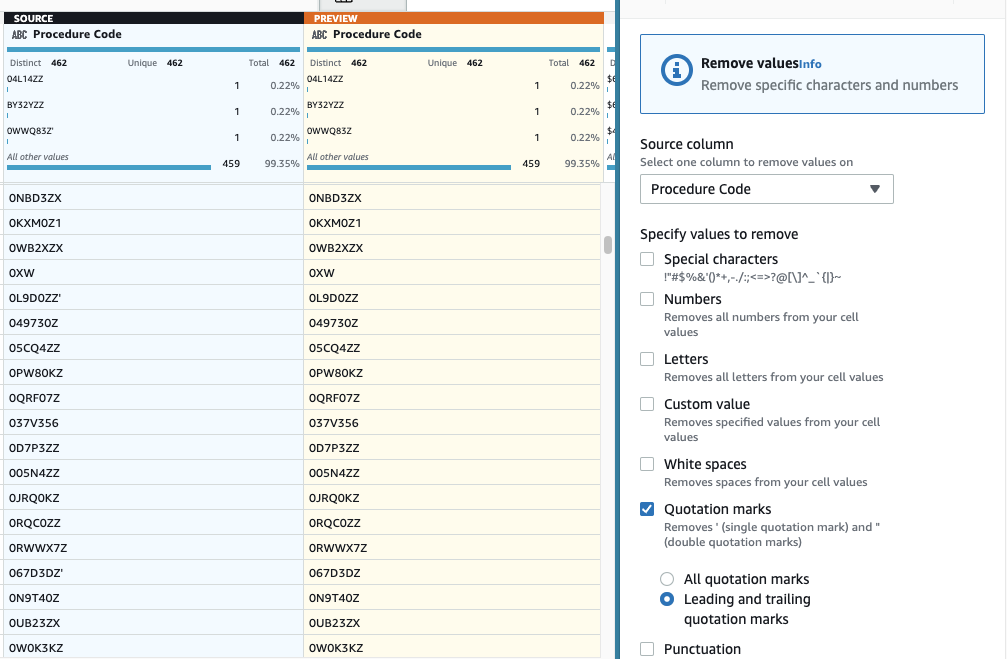
- Deretter legger du til trinnet Fjern anførselstegn.
- Velg Prosedyrekode kolonne og velg Ledende og etterfølgende anførselstegn.
- Forhåndsvis for å bekrefte at den har ønsket effekt og bruk det nye trinnet.
- Legg til trinnet Fjern spesialtegn.
- Velg Kravsbeløp kolonne og for å være mer spesifikk, velg Egendefinerte spesialtegn og skriv inn
$forum Skriv inn egendefinerte spesialtegn.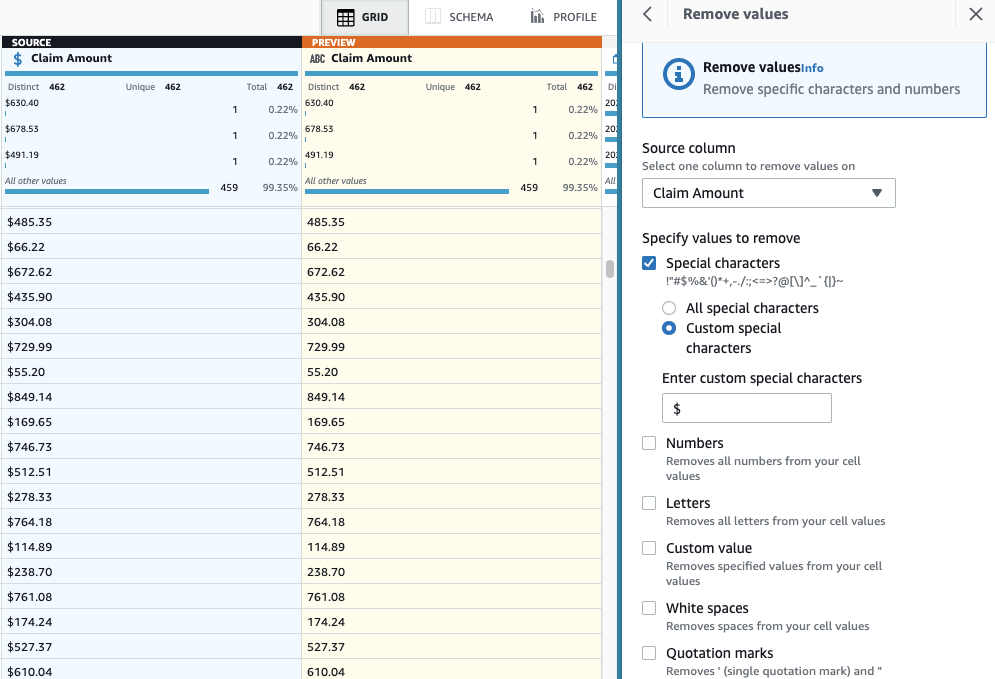
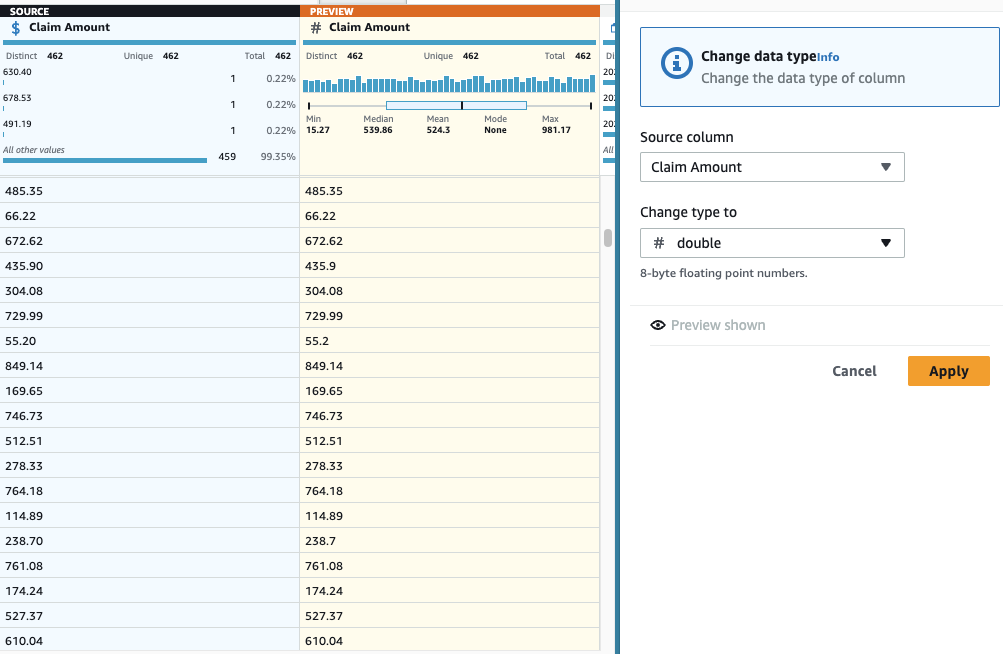
- legge en Endre type gå på søylen Kravsbeløp Og velg dobbelt som typen.
- Som det siste trinnet, for å fjerne det overflødige "kode"-prefikset, legg til en Erstatt verdi eller mønster skritt.
- Velg kolonnen Diagnosekode, Og for Angi egendefinert verdi, Tast inn
code(med et mellomrom på slutten).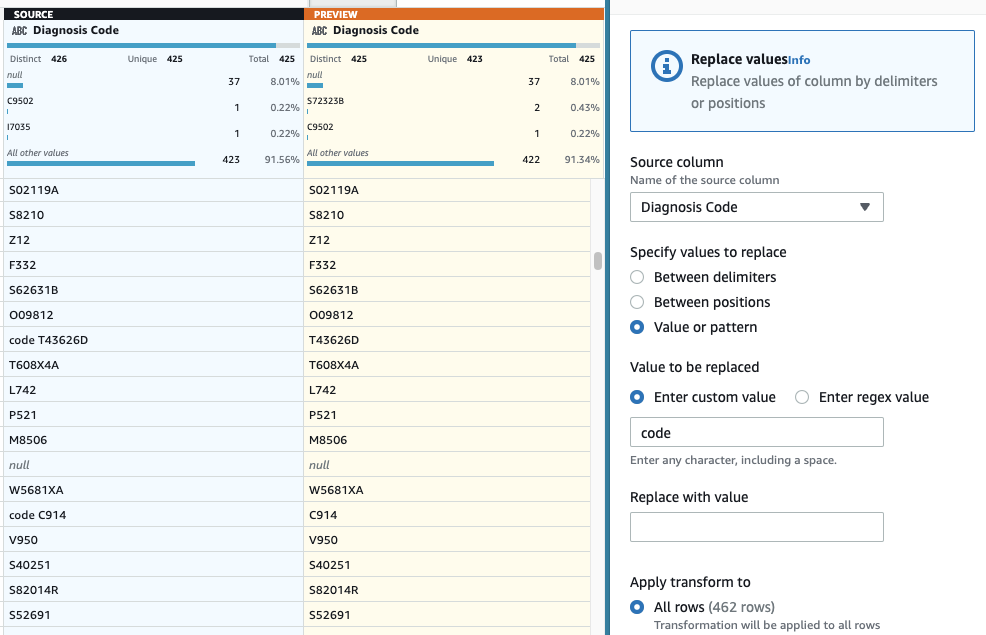
Nå som du har løst alle datakvalitetsproblemer identifisert på prøven, publiser prosjektet som en oppskrift.
- Velg Publiser i Oppskrift skriv inn en valgfri beskrivelse og fullfør publikasjonen.
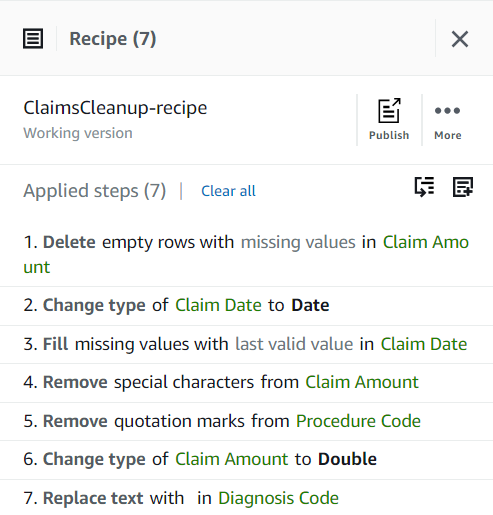
Hver gang du publiserer, vil det lage en annen versjon av oppskriften. Senere vil du kunne velge hvilken versjon av oppskriften du skal bruke.
Lag en visuell ETL-jobb i AWS Glue Studio
Deretter oppretter du jobben som bruker oppskriften. Fullfør følgende trinn:
- På AWS Glue Studio-konsollen velger du Visuell ETL i navigasjonsruten.
- Velg Visuelt med et tomt lerret og skape den visuelle jobben.
- Øverst i jobben erstatter du "Untitled job" med et navn du ønsker.
- På jobbdetaljer fanen, spesifiser en rolle som jobben skal bruke.
Dette må være en AWS identitets- og tilgangsadministrasjon (JEG ER) rolle egnet for AWS Glue med tillatelser til Amazon S3 og AWS Glue Data Catalog. Merk at rollen som tidligere ble brukt for DataBrew ikke er brukbar for kjørejobber, så den vil ikke bli oppført på IAM-rolle rullegardinmenyen her.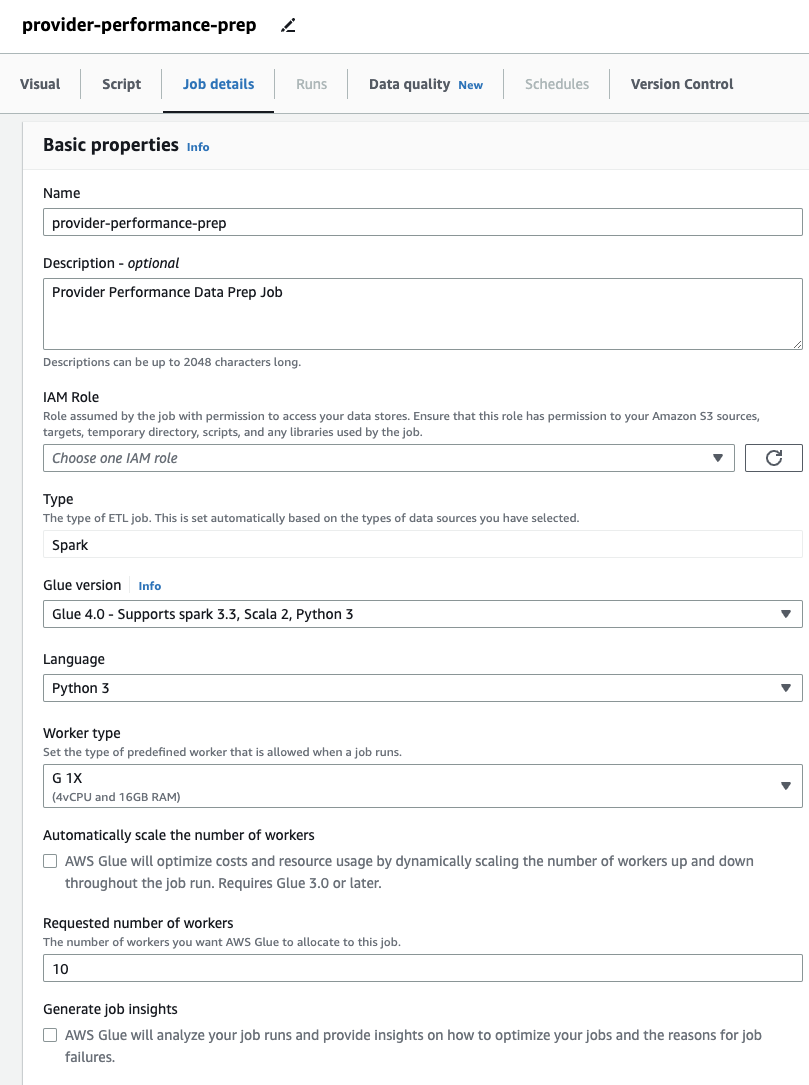
Hvis du bare brukte DataBrew-jobber før, legg merke til at i AWS Glue Studio kan du velge ytelses- og kostnadsinnstillinger, inkludert arbeiderstørrelse, automatisk skalering og Fleksibel utførelse, samt bruke den nyeste AWS Glue 4.0-kjøretiden og dra nytte av de betydelige ytelsesforbedringene den gir. For denne jobben kan du bruke standardinnstillingene, men redusere det forespurte antallet arbeidere av hensyn til nøysomhet. For dette eksemplet vil to arbeidere gjøre. - På Visual fanen, legg til en S3-kilde og navngi den
Providers. - Til S3 URL, Tast inn
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.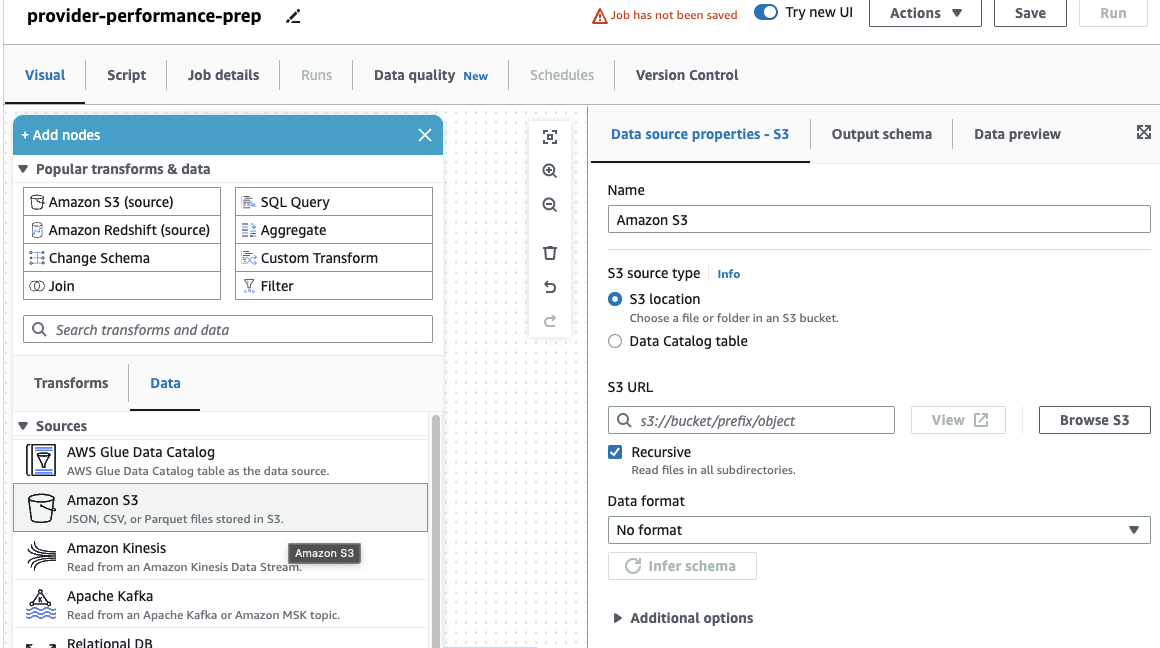
- Velg formatet som CSV Og velg Utlede skjema.
Nå er skjemaet oppført på Utdataskjema fanen ved hjelp av filoverskriften.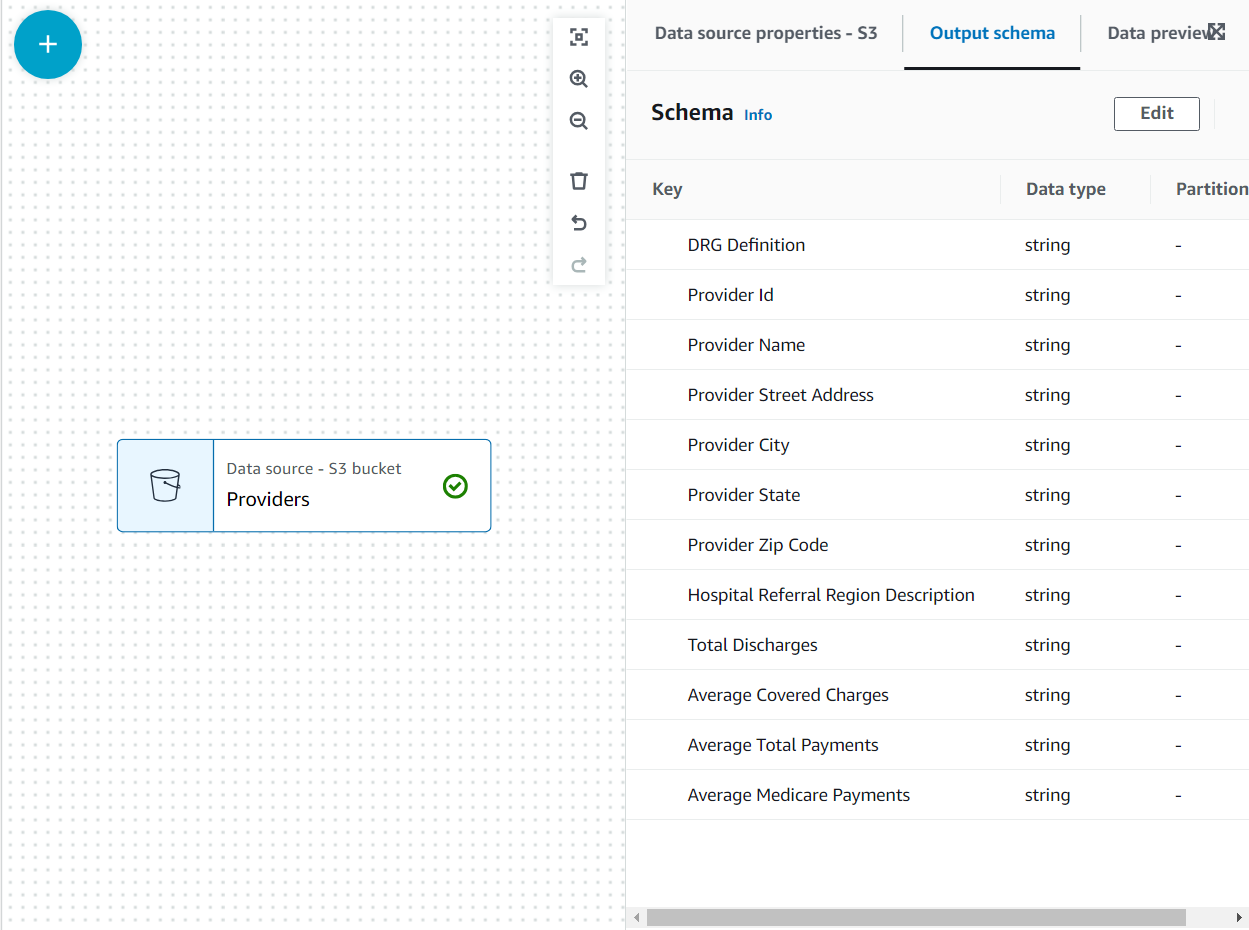
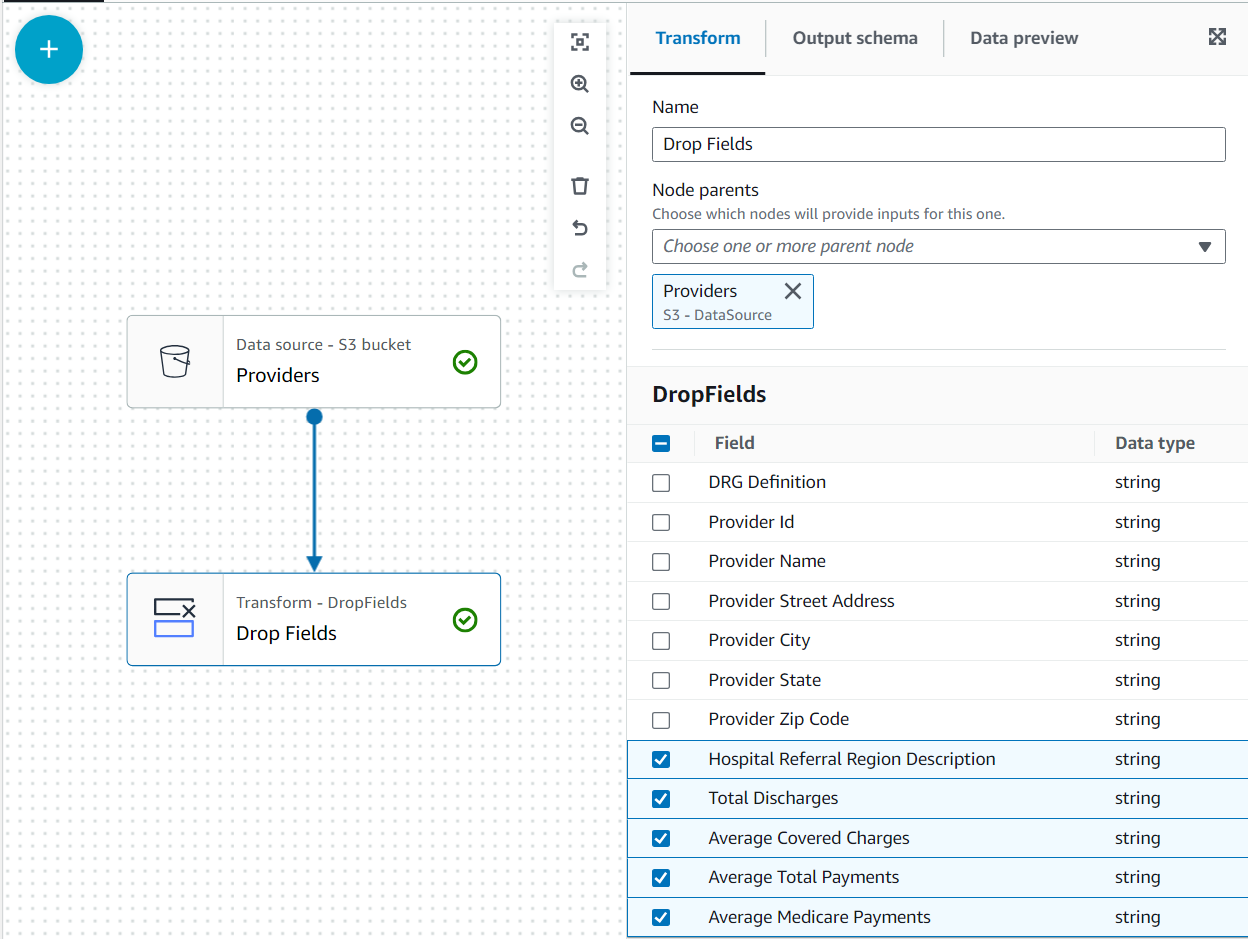
I denne brukssaken er beslutningen at ikke alle kolonnene i leverandørens datasett er nødvendige, så vi kan forkaste resten.
- Med tilbydere node valgt, legg til en Slipp felt transformere (hvis du ikke valgte den overordnede noden, vil den ikke ha en; i så fall tilordner du den overordnede noden manuelt).
- Velg alle feltene etter Leverandørens postnummer.
Senere vil disse dataene bli forent av kravene for staten Alabama ved å bruke leverandøren; det andre datasettet har imidlertid ikke den angitte tilstanden. Vi kan bruke kunnskap om dataene til å optimalisere sammenføyningen ved å filtrere dataene vi virkelig trenger.
- legge en filtre forvandle seg som et barn av Slipp felt.
- Navngi det
Alabama providersog legg til et vilkår som staten må matcheAL.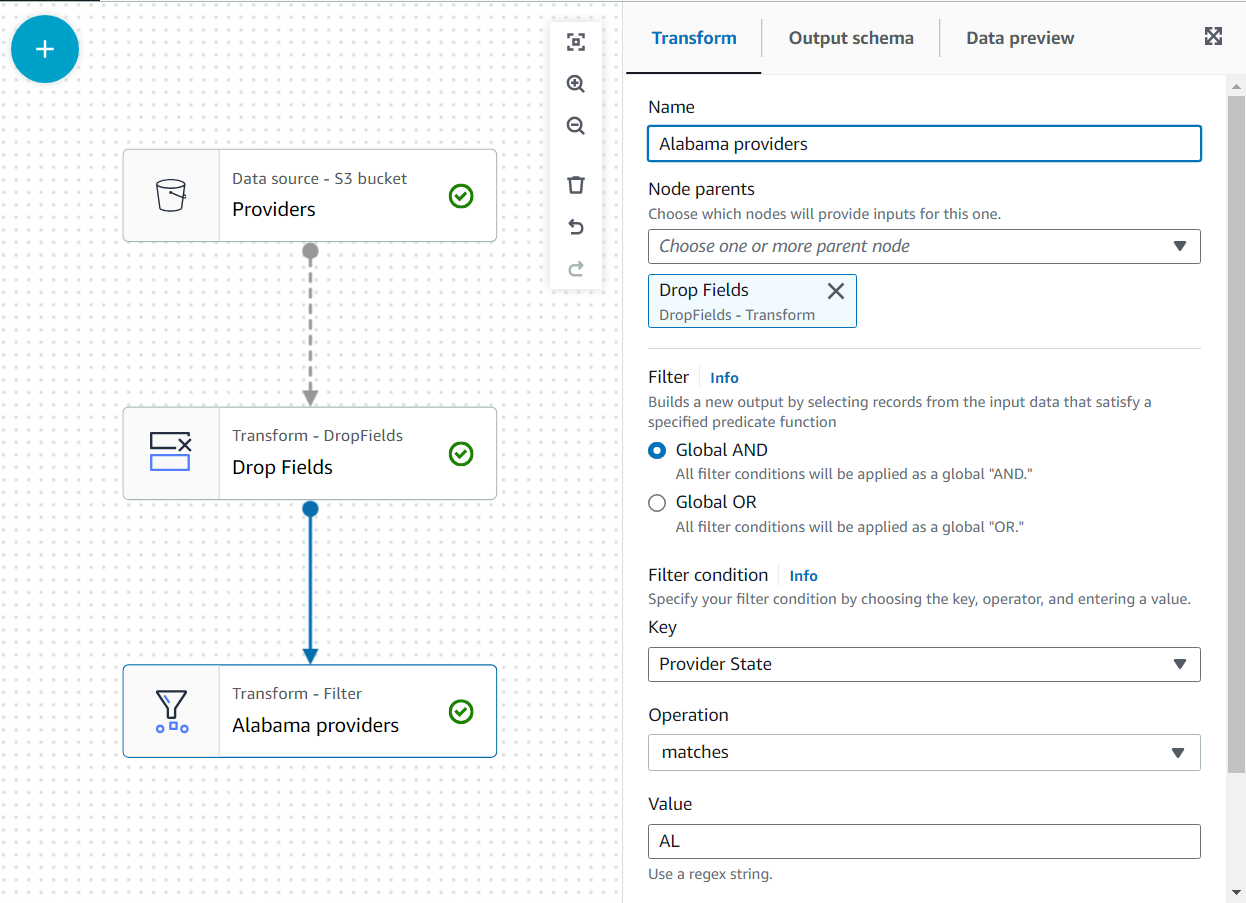
- Legg til den andre kilden (en ny S3-kilde) og gi den et navn
Alabama claims. - For å gå inn i S3 URL, åpne DataBrew i en egen nettleserfane, velg Datasett i navigasjonsruten, og kopier plasseringen som vises i tabellen for Alabama hevder (kopier teksten som starter med s3://, ikke http-lenken tilknyttet). Så tilbake på den visuelle jobben, lim den inn som S3 URL; hvis det er riktig, vil du se i Utdataskjema kategorien datafeltene som er oppført.
- Velg CSV-format og utlede skjemaet som du gjorde med den andre kilden.
- Som barn av denne kilden, søk i Legg til noder meny for
recipeOg velg Dataforberedelsesoppskrift.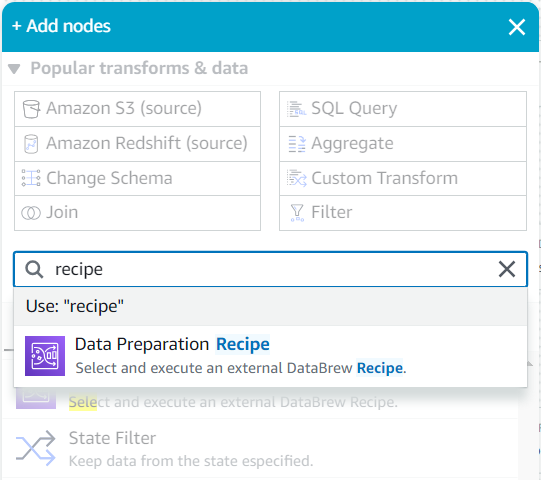
- I egenskapene til denne nye noden, gi den navnet
Claim cleanup recipeog velg oppskriften og versjonen du publiserte før. - Du kan se gjennom oppskriftstrinnene her og bruke lenken til DataBrew for å gjøre endringer om nødvendig.
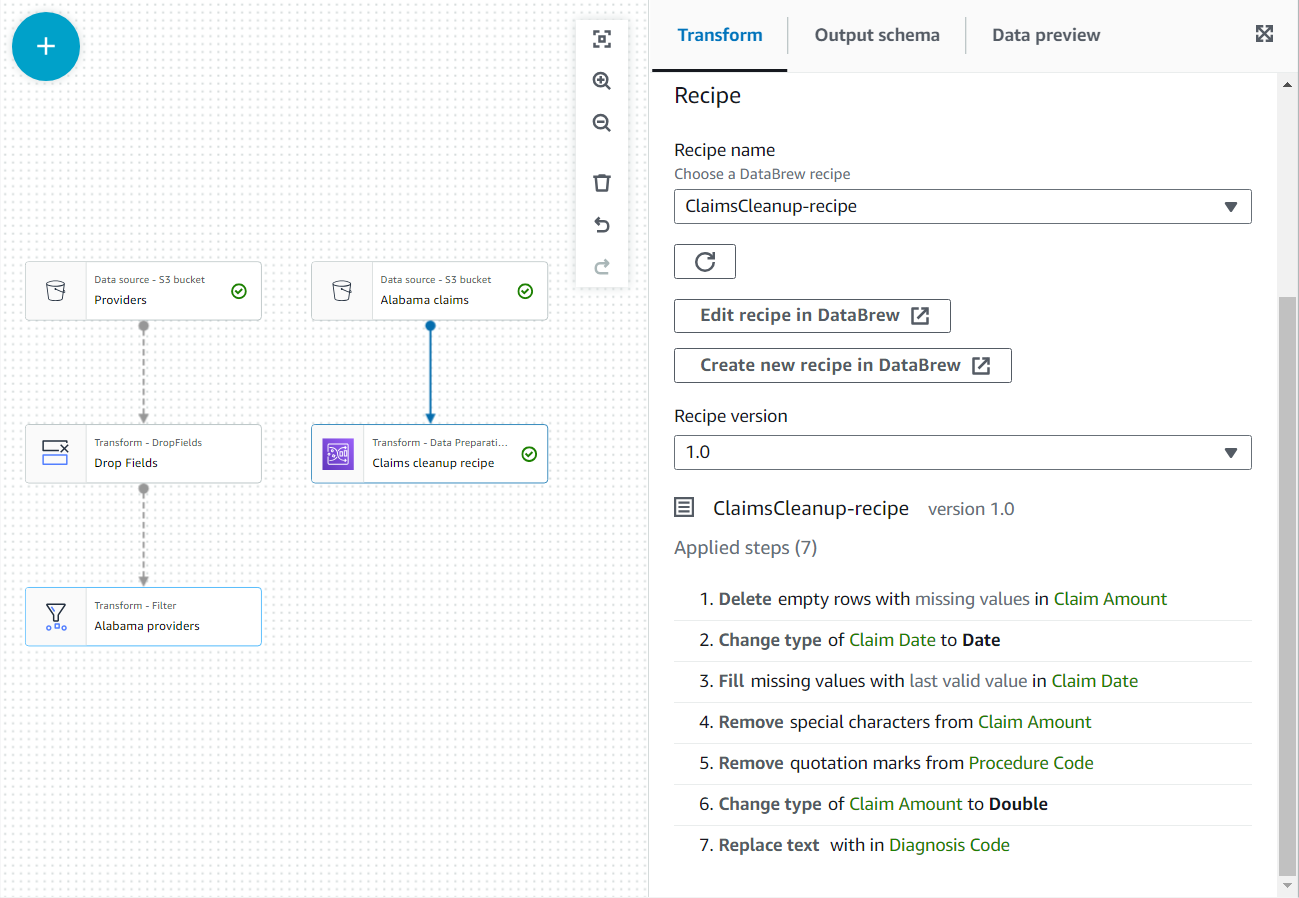
- legge en Bli med node og velg begge Alabama-leverandører og Gjør krav på oppryddingsoppskrifter som forelder.
- Legg til en sammenføyningsbetingelse som tilsvarer leverandør-ID-en fra begge kildene.
- Som siste trinn legger du til en S3-node som et mål (merk at den første som er oppført når du søker er kilden; sørg for at du velger versjonen som er oppført som målet).
- I nodekonfigurasjonen, la standardformatet JSON og angi en S3 URL som jobbrollen har tillatelse til å skrive på.
I tillegg gjør du datautgangen tilgjengelig som en tabell i katalogen.
- på Alternativer for oppdatering av datakatalog seksjon, velg det andre alternativet Opprett en tabell i datakatalogen og ved påfølgende kjøringer, oppdater skjemaet og legg til nye partisjoner, velg deretter en database som du har tillatelse til å lage tabeller på.
- Tildele
alabama_claimssom navn og velg Kravdato som partisjonsnøkkel (dette er for illustrasjonsformål; en liten tabell som denne trenger egentlig ikke partisjoner hvis ytterligere data ikke vil bli lagt til senere).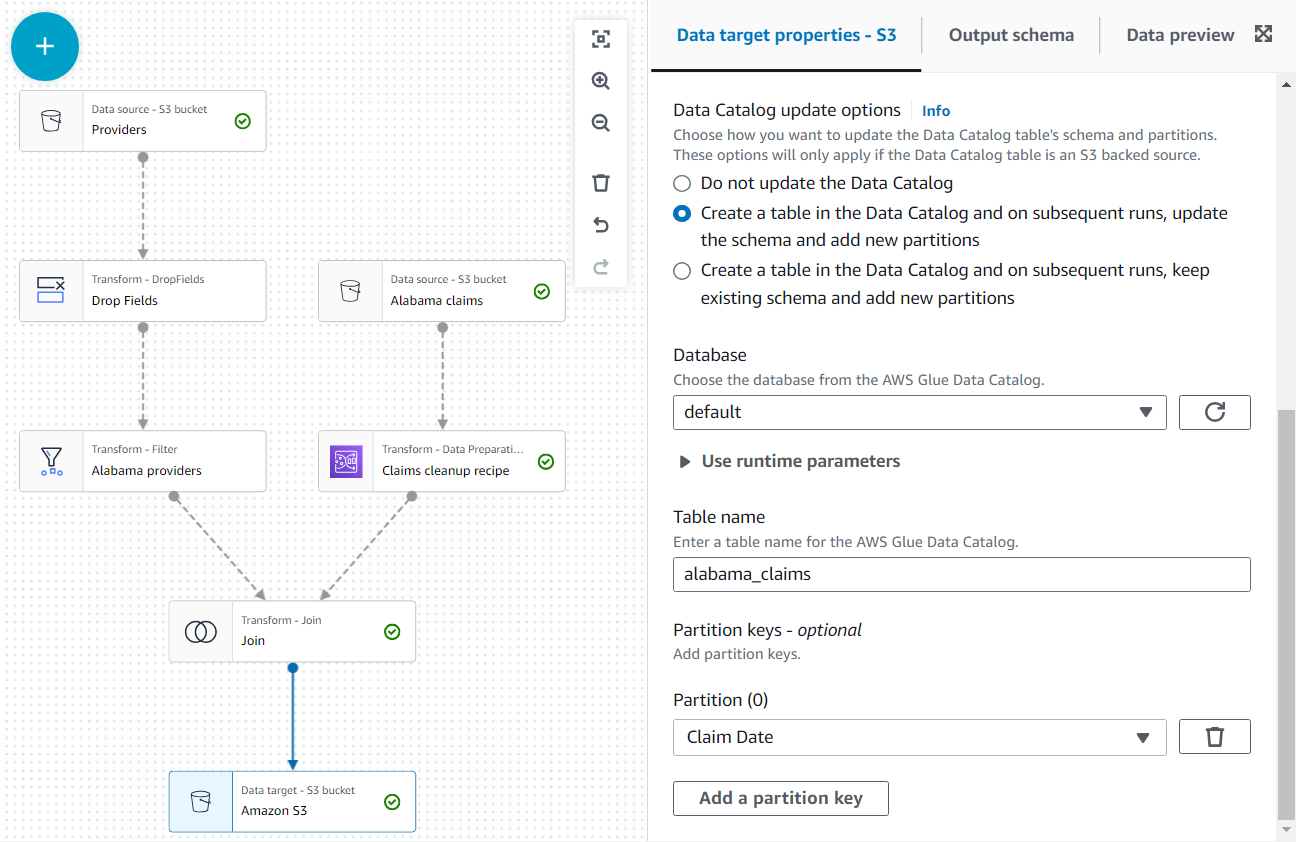
- Nå kan du lagre og kjøre jobben.
- På Kjører fanen, kan du holde styr på prosessen og se detaljerte jobbberegninger ved å bruke jobb-ID-lenken.
Jobben bør ta noen minutter å fullføre.
- Når jobben er fullført, naviger til Athena-konsollen.
- Søk etter tabellen
alabama_claimsi databasen du valgte, og bruk kontekstmenyen til å velge Forhåndsvisningstabell, som vil kjøre en enkel SELECT * SQL-setning på bordet.
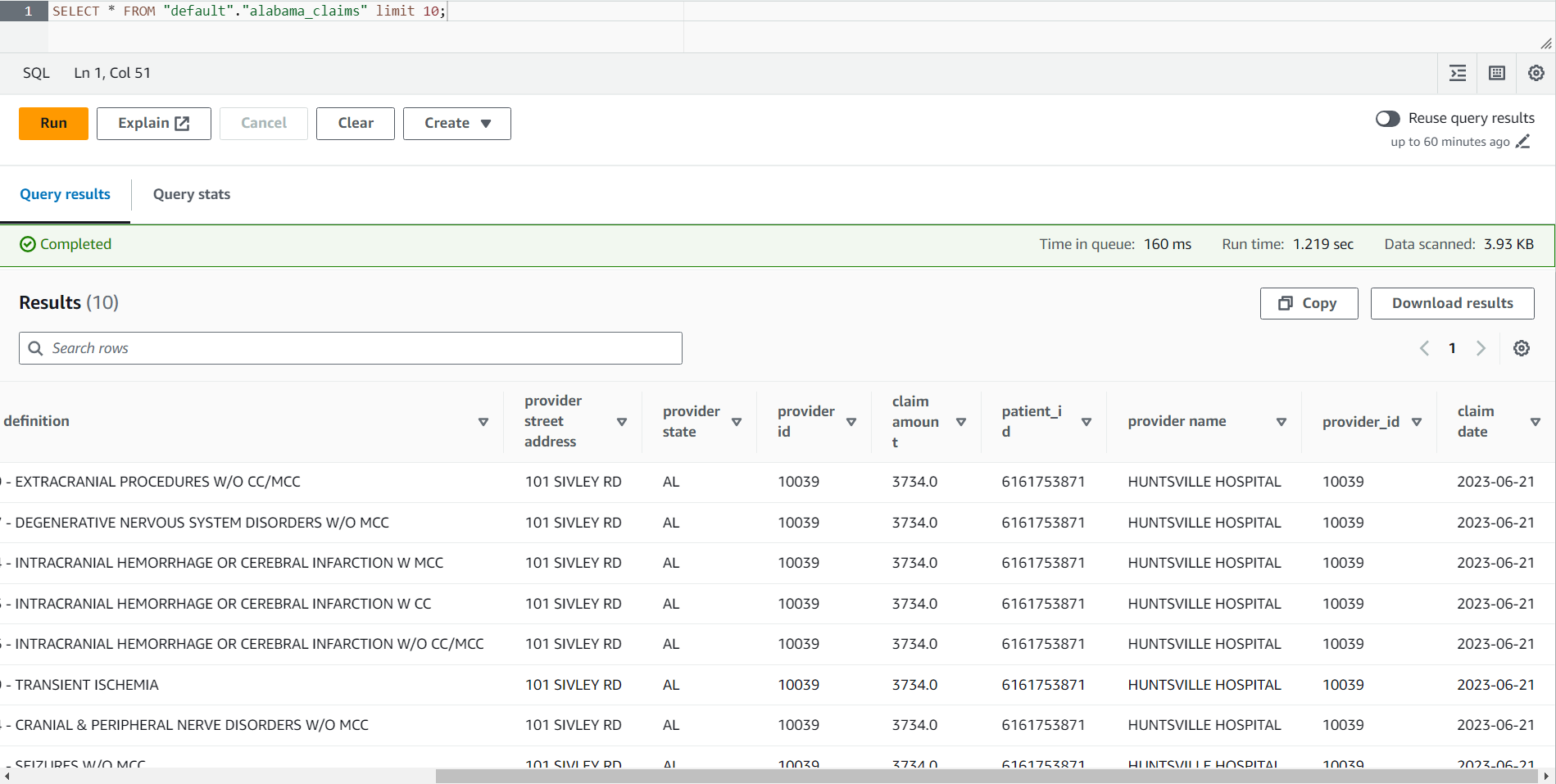
Du kan se i resultatet av jobben at dataene ble renset av DataBrew-oppskriften og beriket av AWS Glue Studio-tilknytningen.
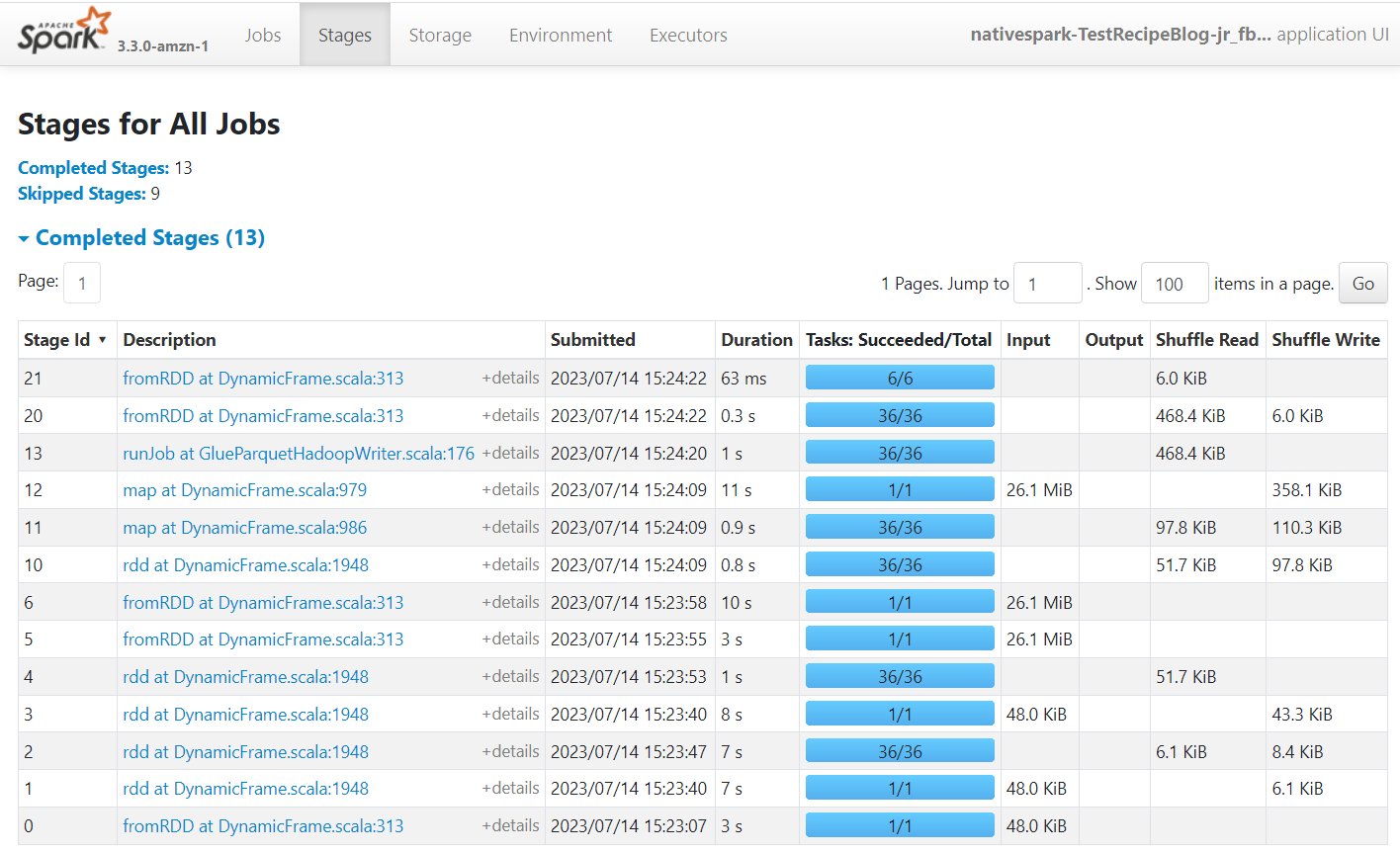
Apache Spark er motoren som kjører jobbene som er opprettet på AWS Glue Studio. Ved å bruke Spark-grensesnittet på hendelsesloggene den produserer, kan du se innsikt om jobbplanen og kjøringen, noe som kan hjelpe deg å forstå hvordan jobben din utfører og potensielle flaskehalser i ytelsen. For denne jobben på et stort datasett kan du for eksempel bruke den til å sammenligne virkningen av å filtrere eksplisitt leverandørtilstanden før du gjør sammenføyningen, eller identifisere om du kan dra nytte av å legge til en Autobalanse-transformasjon for å forbedre parallelliteten.
Som standard vil jobben lagre Apache Spark-hendelsesloggene under banen s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. For å se jobbene må du installere en historikkserver med en av metodene som er tilgjengelige.
Rydd opp
Hvis du ikke lenger trenger denne løsningen, kan du slette filene generert på Amazon S3, tabellen opprettet av jobben, DataBrew-oppskriften og AWS Glue-jobben.
konklusjonen
I dette innlegget viste vi hvordan du kan bruke AWS DataBrew til å bygge en oppskrift ved å bruke den medfølgende interaktive editoren og deretter bruke den publiserte oppskriften som en del av en AWS Glue Studio visuell ETL-jobb. Vi inkluderte noen eksempler på vanlige oppgaver som kreves når du gjør dataforberedelse og inntak av data i AWS Glue Catalog-tabeller.
Dette eksemplet brukte en enkelt oppskrift i den visuelle jobben, men det er mulig å bruke flere oppskrifter på forskjellige deler av ETL-prosessen, i tillegg til å gjenbruke den samme oppskriften på flere jobber.
Disse AWS Glue-løsningene lar deg effektivt lage avanserte ETL-rørledninger som er enkle å bygge og vedlikeholde, alt uten å skrive noen kode. Du kan begynne å lage løsninger som kombinerer begge verktøyene i dag.
Om forfatterne
 Mikhail Smirnov er Sr. Software Dev Engineer i AWS Glue-teamet og en del av AWS Glue DataBrew-utviklingsteamet. Utenom jobben inkluderer hans interesser å lære å spille gitar og reise med familien.
Mikhail Smirnov er Sr. Software Dev Engineer i AWS Glue-teamet og en del av AWS Glue DataBrew-utviklingsteamet. Utenom jobben inkluderer hans interesser å lære å spille gitar og reise med familien.
 Gonzalo Herreros er Sr. Big Data Architect i AWS Glue-teamet. Basert på Dublin, Irland, hjelper han kunder med å lykkes med big data-løsninger basert på AWS Glue. På fritiden liker han brettspill og sykling.
Gonzalo Herreros er Sr. Big Data Architect i AWS Glue-teamet. Basert på Dublin, Irland, hjelper han kunder med å lykkes med big data-løsninger basert på AWS Glue. På fritiden liker han brettspill og sykling.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Bil / elbiler, Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- BlockOffsets. Modernisering av eierskap for miljøkompensasjon. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- : har
- :er
- :ikke
- $OPP
- 10
- 100
- 12
- 15%
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- I stand
- Om oss
- akseptabelt
- akseptert
- adgang
- Logg inn
- Handling
- faktiske
- legge til
- la til
- legge
- tillegg
- adresse
- avansert
- Etter
- Alabama
- Alle
- tillate
- også
- Amazon
- Amazon Web Services
- beløp
- an
- analytikere
- og
- noen
- Apache
- Apache Spark
- Søknad
- Påfør
- ER
- AS
- assosiert
- At
- forfatter
- auto
- Automatisk
- tilgjengelig
- AWS
- AWS Lim
- tilbake
- basert
- BE
- før du
- være
- nytte
- Fordeler
- Stor
- Store data
- blank
- borde
- Board Games
- bokmerker
- både
- Bringer
- nett~~POS=TRUNC leseren~~POS=HEADCOMP
- bygge
- men
- by
- CAN
- evner
- saken
- katalog
- Celler
- sentralisert
- endring
- Endringer
- tegn
- barn
- valg
- Velg
- hevder
- krav
- kode
- Kolonne
- kolonner
- kombinere
- kommer
- Felles
- sammenligne
- fullføre
- komponenter
- datamaskin
- tilstand
- Konfigurasjon
- Vurder
- består
- Konsoll
- kontekst
- konvertere
- konvertert
- korrigere
- Tilsvarende
- Kostnad
- kunne
- skape
- opprettet
- Opprette
- skaperverket
- skikk
- Kunder
- dato
- Dataklargjøring
- databehandling
- datakvalitet
- Database
- datasett
- Dato
- datoer
- dag
- avtale
- bestemme
- avgjørelse
- Misligholde
- demonstrere
- beskrivelse
- ønsket
- detaljert
- detaljer
- dev
- Utvikling
- utviklingsteam
- gJORDE
- forskjellig
- distinkt
- distribusjon
- do
- ikke
- gjør
- Dollar
- dobbelt
- Drop
- dublin
- hver enkelt
- lett
- redaktør
- effekt
- effektivt
- muliggjør
- slutt
- Motor
- ingeniør
- anriket
- berikende
- Enter
- feil
- avgjørende
- Eter (ETH)
- evaluere
- Selv
- Event
- Hver
- hver dag
- eksempel
- eksempler
- eksisterende
- ekstra
- trekke ut
- familie
- langt
- Egenskaper
- Noen få
- Felt
- filet
- Filer
- fyll
- filtrere
- filtrering
- Endelig
- Først
- fulgt
- etter
- Til
- format
- fra
- videre
- Games
- generert
- Gi
- større
- Ha
- he
- hjelpe
- hjelper
- her.
- hans
- historie
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- IAM
- ID
- identifisert
- identifisere
- Identitet
- if
- Påvirkning
- forbedre
- forbedringer
- in
- inkludere
- inkludert
- Inkludert
- indikert
- inngang
- innsikt
- installere
- f.eks
- integrert
- integrering
- interaktiv
- interesse
- interesser
- Interface
- inn
- introdusert
- intuitiv
- Irland
- saker
- IT
- DET ER
- Jobb
- Jobb
- bli medlem
- ble med
- jpg
- JSON
- bare
- Hold
- nøkkel
- kunnskap
- stor
- større
- største
- Siste
- seinere
- siste
- læring
- Permisjon
- i likhet med
- Sannsynlig
- LINK
- oppført
- laste
- plassering
- logikk
- lenger
- vedlikeholde
- gjøre
- GJØR AT
- manuelt
- Match
- medisinsk
- Meny
- metode
- metoder
- Metrics
- minutter
- mangler
- Overvåke
- mer
- flere
- må
- navn
- Naviger
- Navigasjon
- Trenger
- nødvendig
- behov
- Ny
- Nei.
- node
- Legge merke til..
- nå
- Antall
- of
- on
- ONE
- bare
- åpen
- Optimalisere
- Alternativ
- alternativer
- or
- rekkefølge
- Annen
- vår
- produksjon
- utenfor
- enn
- samlet
- brød
- del
- deler
- banen
- ytelse
- utfører
- tillatelse
- tillatelser
- fly
- plato
- Platon Data Intelligence
- PlatonData
- Spille
- mulig
- Post
- potensiell
- forberedelse
- Forhåndsvisning
- Forhåndsvisninger
- prosess
- prosessering
- produserer
- prosjekt
- egenskaper
- forutsatt
- leverandør
- tilbydere
- gir
- Utgivelse
- publisere
- publisert
- formål
- formål
- kvalitet
- sitater
- virkelig
- rimelig
- .
- oppskrifter
- redusere
- reflektere
- region
- registrering
- relevant
- fjerne
- erstatte
- Forespurt
- påkrevd
- behov
- henholdsvis
- REST
- resultere
- Resultater
- gjenbruk
- anmeldelse
- Rolle
- Kjør
- går
- samme
- Spar
- Skala
- skalering
- Søk
- Sekund
- Seksjon
- se
- se
- valgt
- separat
- Tjenester
- Session
- sett
- innstillinger
- bør
- viste
- vist
- undertegne
- signifikant
- Enkelt
- enkelt
- Størrelse
- liten
- So
- så langt
- Software
- løsning
- Solutions
- noen
- kilde
- Kilder
- Rom
- Spark
- spesiell
- spesifikk
- spesifisert
- SQL
- Begynn
- Start
- Tilstand
- Uttalelse
- statistikk
- Trinn
- Steps
- lagring
- oppbevare
- rett fram
- String
- studio
- senere
- lykkes
- slik
- egnet
- SAMMENDRAG
- sikker
- syntetisk
- bord
- Ta
- Target
- oppgaver
- lag
- testet
- Det
- De
- Kilden
- Staten
- Dem
- deretter
- Der.
- denne
- tre
- tid
- til
- i dag
- verktøy
- verktøy
- topp
- spor
- Transform
- Transformation
- transformasjoner
- Traveling
- to
- typen
- ui
- etter
- forstå
- Oppdater
- oppdatert
- URL
- bruk
- bruke
- bruk sak
- brukt
- Brukere
- bruker
- ved hjelp av
- VALIDERE
- verdi
- Verdier
- verifisere
- versjon
- Se
- synlig
- ønsker
- var
- måter
- we
- web
- webtjenester
- VI VIL
- var
- når
- hvilken
- vil
- med
- uten
- Arbeid
- arbeidstaker
- arbeidere
- arbeidsflyt
- ville
- skrive
- skriving
- du
- Din
- zephyrnet
- Zip