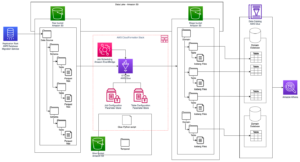
Amazon EMR tilbyr en administrert tjeneste for enkelt å kjøre analyseapplikasjoner ved å bruke åpen kildekode-rammeverk som Apache Spark, Hive, Presto, Trino, HBase og Flink. Amazon EMR kjøretid for Spark og Presto inkluderer optimaliseringer som gir over dobbelt så høy ytelsesforbedringer sammenlignet med åpen kildekode Apache Spark og Presto.
Med Amazon EMR utgivelse 6.7 kan du nå bruke Amazon Elastic Compute Cloud (Amazon EC2) C7g-forekomster, som bruker AWS Graviton3 prosessorer. Disse forekomstene forbedrer prisytelsen for å kjøre Spark-arbeidsbelastninger på Amazon EMR med 7.93–13.35 % sammenlignet med tidligere generasjonsforekomster, avhengig av forekomststørrelsen. I dette innlegget beskriver vi hvordan vi estimerte pris-ytelsesfordelen.
Amazon EMR kjøretid med EC2 C7g-forekomster
Vi kjørte TPC-DS 3 TB benchmark-spørringer på Amazon EMR 6.9 ved å bruke Amazon EMR-runtime for Apache Spark (kompatibel med Apache Spark 3.3) med C7g-forekomster. Data ble lagret i Amazon enkel lagringstjeneste (Amazon S3), og resultatene ble sammenlignet med tilsvarende C6g-klynger fra forrige generasjons instansfamilie. Vi målte ytelsesforbedringer ved å bruke den totale spørringens kjøretid og det geometriske gjennomsnittet av spørringens kjøretid på tvers av TPC-DS 3 TB benchmark-spørringer.
Resultatene våre viste 13.65–18.73 % forbedring i total søkekjøringsytelse og 16.98–20.28 % forbedring i geometrisk gjennomsnitt på EMR-klynger med C7g sammenlignet med tilsvarende EMR-klynger med C6g-forekomster, avhengig av forekomststørrelsen. Ved å sammenligne kostnader observerte vi 7.93–13.35 % reduksjon i kostnad på EMR-klyngen med C7g sammenlignet med tilsvarende med C6g, avhengig av instansstørrelsen. Vi referanseindekserte ikke C6g xlarge-forekomsten fordi den ikke hadde nok minne til å kjøre spørringene.
Tabellen nedenfor viser resultatene fra å kjøre TPC-DS 3 TB benchmark-spørringer med Amazon EMR 6.9 sammenlignet med tilsvarende C7g- og C6g-forekomst-EMR-klynger.
| Forekomststørrelse | 16 XL | 12 XL | 8 XL | 4 XL | 2 XL |
| Total størrelse på klyngen (1 leder + 5 kjernenoder) | 6 | 6 | 6 | 6 | 6 |
| Total spørringstid på C6g (sekunder) | 2774.86205 | 2752.84429 | 3173.08086 | 5108.45489 | 8697.08117 |
| Total spørringstid på C7g (sekunder) | 2396.22799 | 2336.28224 | 2698.72928 | 4151.85869 | 7249.58148 |
| Total forbedring av spørringskjøringen med C7g | 13.65% | 15.13% | 14.95% | 18.73% | 16.64% |
| Geometrisk gjennomsnittlig spørring kjøretid C6g (sekunder) | 22.2113 | 21.75459 | 23.38081 | 31.97192 | 45.41656 |
| Geometrisk gjennomsnittlig spørring kjøretid C7g (sekunder) | 18.43905 | 17.65898 | 19.01684 | 25.48695 | 37.43737 |
| Forbedring av geometrisk gjennomsnittlig spørringstid med C7g | 16.98% | 18.83% | 18.66% | 20.28% | 17.57% |
| EC2 C6g-forekomstpris ($ per time) | $2.1760 | $1.6320 | $1.0880 | $0.5440 | $0.2720 |
| EMR C6g-forekomstpris ($ per time) | $0.5440 | $0.4080 | $0.2720 | $0.1360 | $0.0680 |
| (EC2 + EMR) forekomstpris ($ per time) | $2.7200 | $2.0400 | $1.3600 | $0.6800 | $0.3400 |
| Kostnad for å kjøre på C6g ($ per forekomst) | $2.09656 | $1.55995 | $1.19872 | $0.96493 | $0.82139 |
| EC2 C7g-forekomstpris ($ per time) | $2.3200 | $1.7400 | $1.1600 | $0.5800 | $0.2900 |
| EMR C7g-pris ($ per time per forekomst) | $0.5800 | $0.4350 | $0.2900 | $0.1450 | $0.0725 |
| (EC2 + EMR) C7g-forekomstpris ($ per time) | $2.9000 | $2.1750 | $1.4500 | $0.7250 | $0.3625 |
| Kostnad for å kjøre på C7g ($ per forekomst) | $1.930290 | $1.411500 | $1.086990 | $0.836140 | $0.729990 |
| Total kostnadsreduksjon med C7g inkludert ytelsesforbedring | -7.93% | -9.52% | -9.32% | -13.35% | -11.13% |
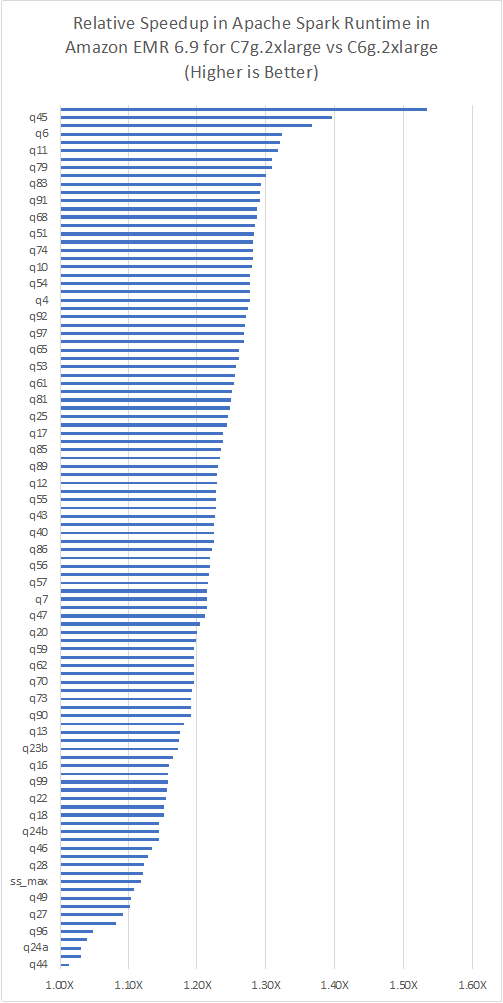
Følgende graf viser forbedringer per forespørsel observert på C7g 2xlarge forekomster sammenlignet med tilsvarende C6g-generasjoner.
Benchmarking metodikk
Referansen som brukes i dette innlegget er avledet fra industristandarden TPC-DS-referansen, og bruker spørringer fra Spark SQL-ytelsestester GitHub-repo med følgende reparasjoner anvendt.
Vi beregnet TCO ved å multiplisere kostnad per time med antall forekomster i klyngen og tiden det tok å kjøre spørringene i klyngen. Vi brukte etterspørselspriser i USA øst (N. Virginia)-regionen i alle tilfeller.
konklusjonen
I dette innlegget beskrev vi hvordan vi estimerte kostnads-ytelsesfordelen ved å bruke Amazon EMR med C7g-forekomster sammenlignet med å bruke tilsvarende tidligere generasjonsforekomster. Bruk av disse nye forekomstene med Amazon EMR forbedrer kostnadsytelsen med ytterligere 7–13 %.
Om forfatterne
 Al MS er produktsjef for Amazon EMR hos Amazon Web Services.
Al MS er produktsjef for Amazon EMR hos Amazon Web Services.
 Kyeonghyun Ryoo er en programvareutviklingsingeniør for EMR hos Amazon Web Services. Han jobber primært med å designe og bygge automasjonsverktøy for interne team og kunder for å maksimere produktiviteten deres. Utenom jobben er han en pensjonert verdensmester i profesjonell spilling som fortsatt liker å spille videospill.
Kyeonghyun Ryoo er en programvareutviklingsingeniør for EMR hos Amazon Web Services. Han jobber primært med å designe og bygge automasjonsverktøy for interne team og kunder for å maksimere produktiviteten deres. Utenom jobben er han en pensjonert verdensmester i profesjonell spilling som fortsatt liker å spille videospill.
 Yuzhou Sun er en programvareutviklingsingeniør for EMR hos Amazon Web Services.
Yuzhou Sun er en programvareutviklingsingeniør for EMR hos Amazon Web Services.
 Steve Koonce er ingeniørsjef for EMR hos Amazon Web Services.
Steve Koonce er ingeniørsjef for EMR hos Amazon Web Services.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/amazon-emr-launches-support-for-amazon-ec2-c7g-graviton3-instances-to-improve-cost-performance-for-spark-workloads-by-7-13/
- 1
- 100
- 35%
- 7
- 9
- a
- tvers
- Ytterligere
- AI
- Alle
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- analytics
- og
- Apache
- Apache Spark
- søknader
- anvendt
- Automatisering
- fordi
- benchmark
- nytte
- Bygning
- beregnet
- Champion
- Cluster
- sammenlignet
- sammenligne
- kompatibel
- Beregn
- Kjerne
- Kostnad
- kostnadsreduksjon
- Kostnader
- Kunder
- dato
- avhengig
- Avledet
- beskrive
- beskrevet
- utforme
- Utvikling
- gJORDE
- lett
- øst
- ingeniør
- Ingeniørarbeid
- nyte
- Tilsvarende
- anslått
- Eter (ETH)
- familie
- etter
- rammer
- fra
- Games
- gaming
- generasjonen
- generasjoner
- GitHub
- graf
- Hive
- Hvordan
- HTTPS
- forbedre
- forbedring
- forbedringer
- forbedrer
- in
- inkluderer
- Inkludert
- f.eks
- intern
- IT
- lanseringer
- leder
- fikk til
- leder
- Maksimer
- Minne
- MS
- multiplisere
- Ny
- noder
- Antall
- åpen kildekode
- utenfor
- ytelse
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- Post
- forrige
- pris
- prising
- primært
- prosessorer
- Produkt
- Produktsjef
- produktivitet
- profesjonell
- gi
- gir
- region
- slipp
- Resultater
- Kjør
- rennende
- sekunder
- tjeneste
- Tjenester
- Viser
- Enkelt
- Størrelse
- Software
- programvareutvikling
- Spark
- SQL
- Still
- lagring
- lagret
- slik
- tilstrekkelig
- støtte
- bord
- lag
- tester
- De
- deres
- tid
- til
- verktøy
- Totalt
- us
- bruke
- video
- videospill
- Virginia
- web
- webtjenester
- hvilken
- HVEM
- Arbeid
- virker
- verden
- zephyrnet