Med lanseringen av den nevrale søkefunksjonen for Amazon OpenSearch-tjeneste i OpenSearch 2.9 er det nå enkelt å integrere med AI/ML-modeller for å drive semantisk søk og andre brukstilfeller. OpenSearch Service har støttet både leksikalsk og vektorsøk siden introduksjonen av funksjonen k-nearest neighbor (k-NN) i 2020; konfigurering av semantisk søk krevde imidlertid å bygge et rammeverk for å integrere maskinlæringsmodeller (ML) for å innta og søke. Den nevrale søkefunksjonen letter tekst-til-vektor-transformasjon under inntak og søk. Når du bruker en nevrale spørring under søk, blir spørringen oversatt til en vektorinnbygging og k-NN brukes til å returnere de nærmeste vektorinnbyggingene fra korpuset.
For å bruke nevrale søk må du sette opp en ML-modell. Vi anbefaler å konfigurere AI/ML-koblinger til AWS AI- og ML-tjenester (som f.eks Amazon SageMaker or Amazonas grunnfjell) eller tredjepartsalternativer. Fra og med versjon 2.9 på OpenSearch Service, integreres AI/ML-koblinger med nevralt søk for å forenkle og operasjonalisere oversettelsen av datakorpus og spørringer til vektorinnbygginger, og dermed fjerne mye av kompleksiteten til vektorhydrering og søk.
I dette innlegget viser vi hvordan du konfigurerer AI/ML-koblinger til eksterne modeller gjennom OpenSearch Service-konsollen.
Løsningsoversikt
Nærmere bestemt leder dette innlegget deg gjennom å koble til en modell i SageMaker. Deretter veileder vi deg gjennom å bruke koblingen til å konfigurere semantisk søk på OpenSearch Service som et eksempel på en brukssak som støttes gjennom tilkobling til en ML-modell. Amazon Bedrock og SageMaker-integrasjoner støttes for tiden på OpenSearch Service-konsollens brukergrensesnitt, og listen over brukergrensesnittstøttede første- og tredjepartsintegrasjoner vil fortsette å vokse.
For modeller som ikke støttes gjennom brukergrensesnittet, kan du i stedet sette dem opp ved å bruke de tilgjengelige APIene og ML tegninger. For mer informasjon, se Introduksjon til OpenSearch-modeller. Du kan finne tegninger for hver kobling i ML Commons GitHub-depot.
Forutsetninger
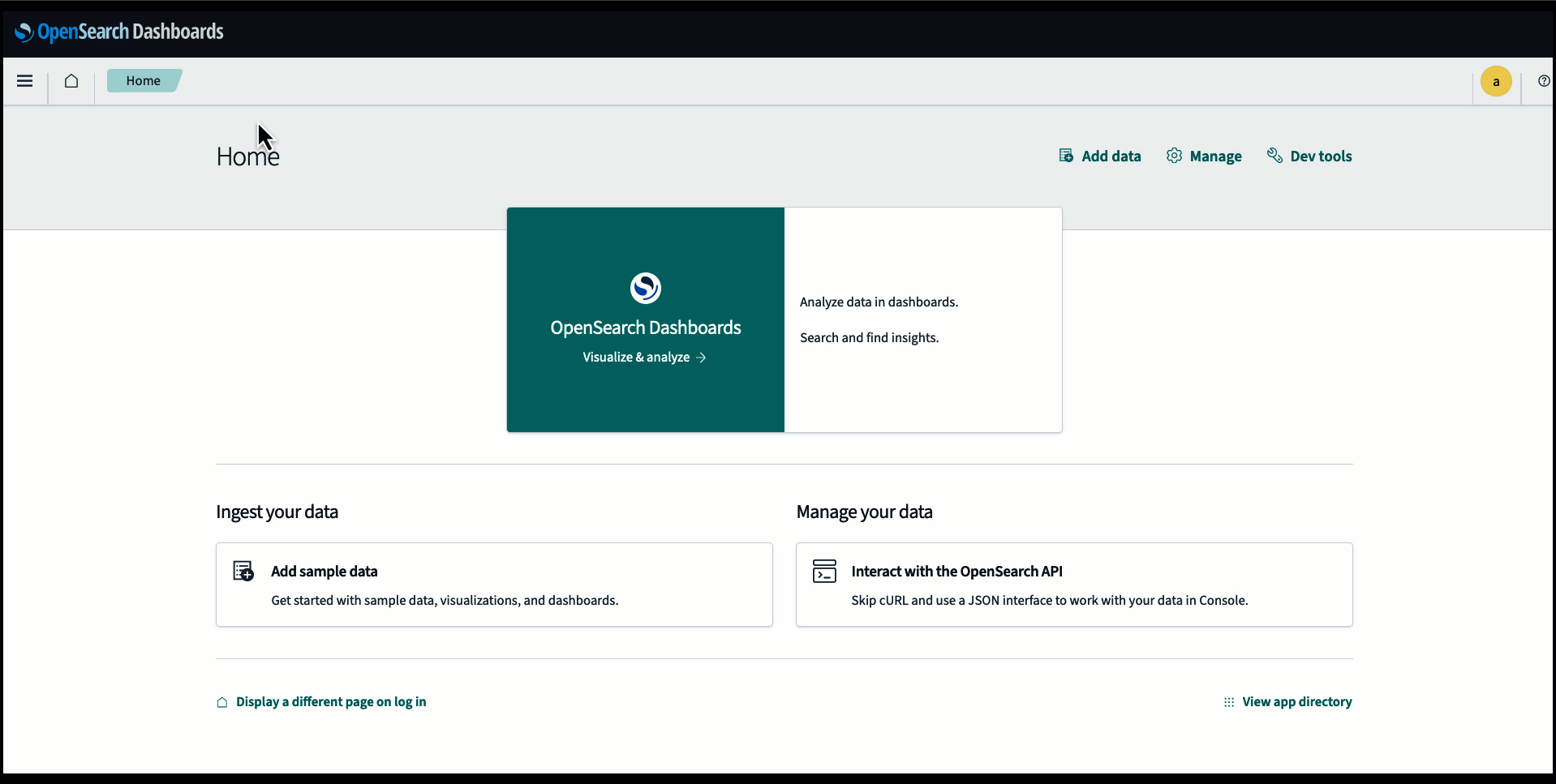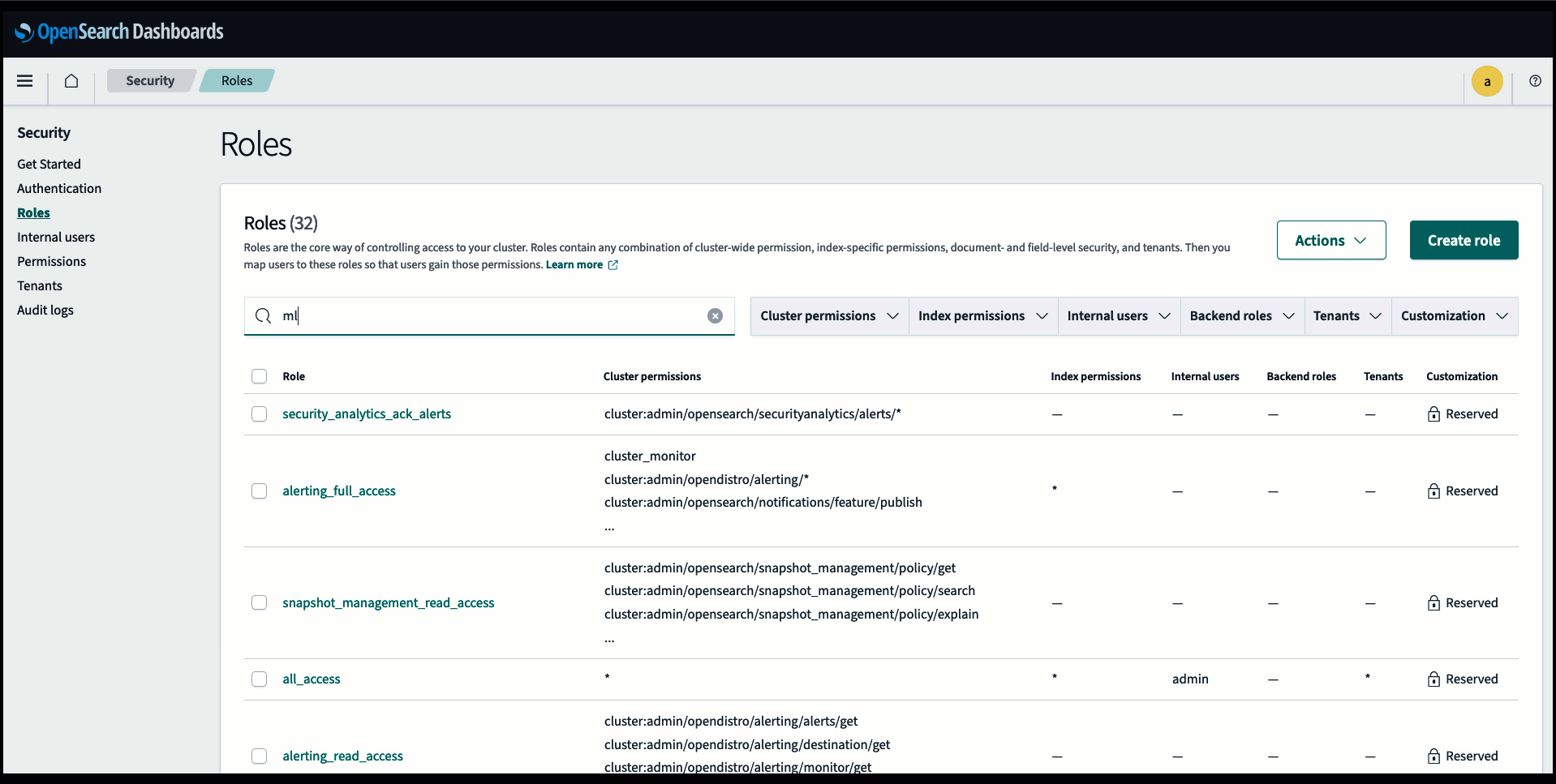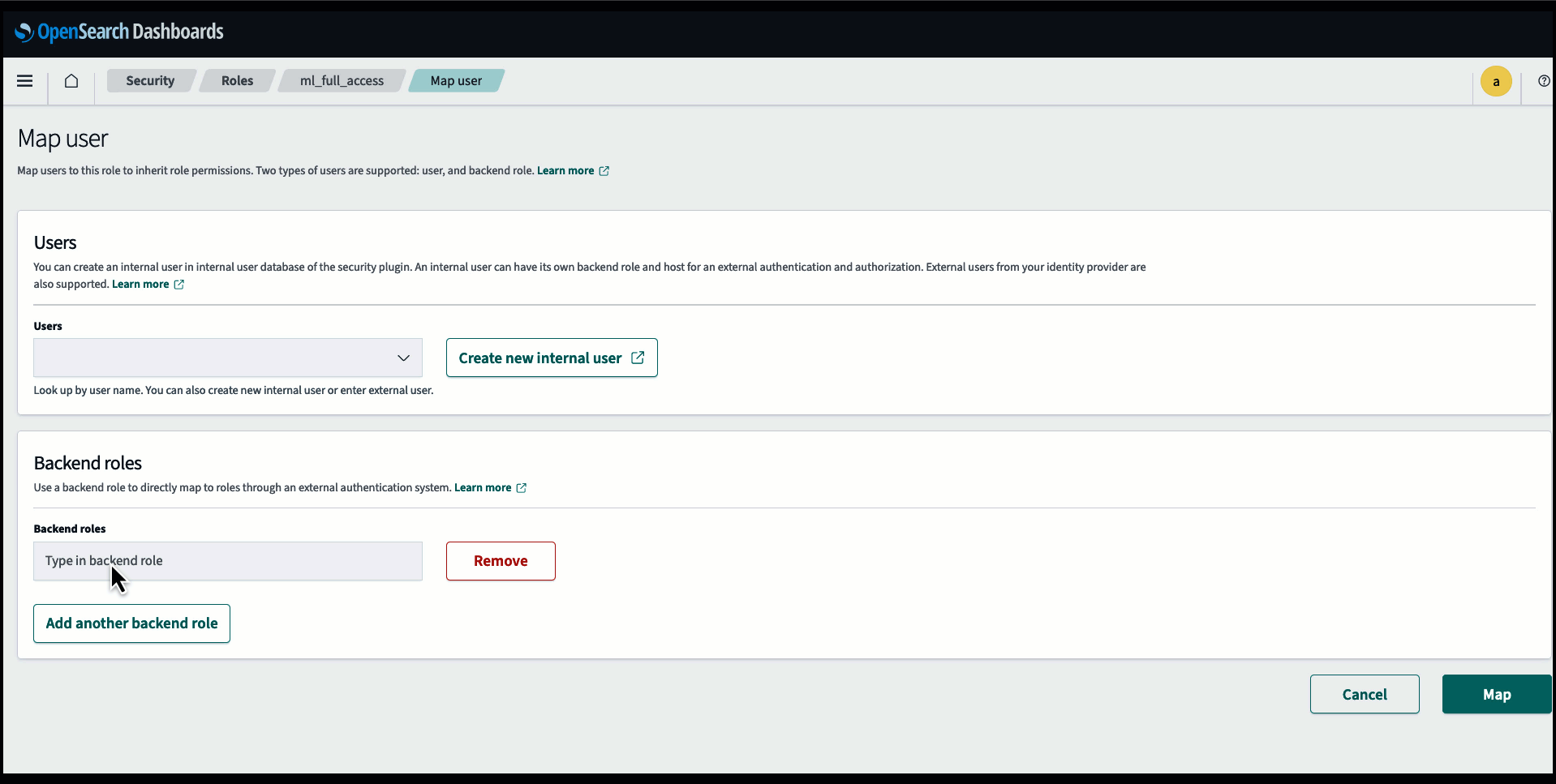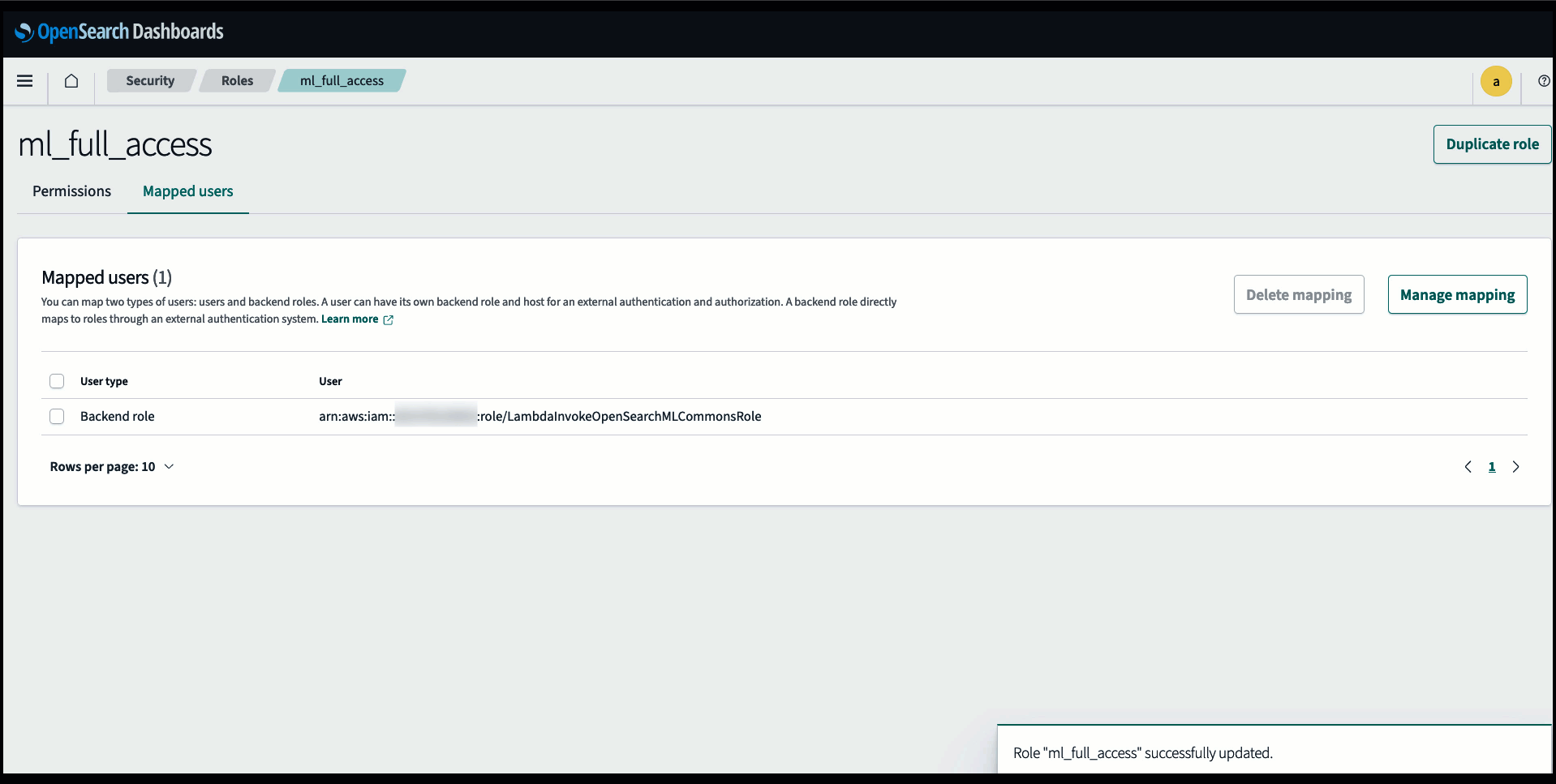
Før du kobler til modellen via OpenSearch Service-konsollen, må du opprette et OpenSearch Service-domene. Kartlegg en AWS identitets- og tilgangsadministrasjon (IAM) rolle ved navn LambdaInvokeOpenSearchMLCommonsRole som backend-rolle på ml_full_access rolle ved å bruke sikkerhetspluginen på OpenSearch Dashboards, som vist i følgende video. Arbeidsflyten for OpenSearch Service-integrering er forhåndsutfylt for å bruke LambdaInvokeOpenSearchMLCommonsRole IAM-rolle som standard for å opprette koblingen mellom OpenSearch Service-domenet og modellen som er distribuert på SageMaker. Hvis du bruker en tilpasset IAM-rolle på OpenSearch Service-konsollintegreringene, må du sørge for at den tilpassede rollen er tilordnet som backend-rollen med ml_full_access tillatelser før du distribuerer malen.
Distribuer modellen ved hjelp av AWS CloudFormation
Følgende video demonstrerer trinnene for å bruke OpenSearch Service-konsollen til å distribuere en modell i løpet av minutter på Amazon SageMaker og generere modell-ID-en via AI-koblingene. Det første trinnet er å velge integrasjoner i navigasjonsruten på OpenSearch Service AWS-konsollen, som ruter til en liste over tilgjengelige integrasjoner. Integrasjonen er satt opp gjennom et brukergrensesnitt, som vil be deg om de nødvendige inngangene.
For å sette opp integrasjonen trenger du bare å oppgi OpenSearch Service-domeneendepunktet og oppgi et modellnavn for å identifisere modellforbindelsen unikt. Som standard implementerer malen Hugging Face-setningstransformatormodellen, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
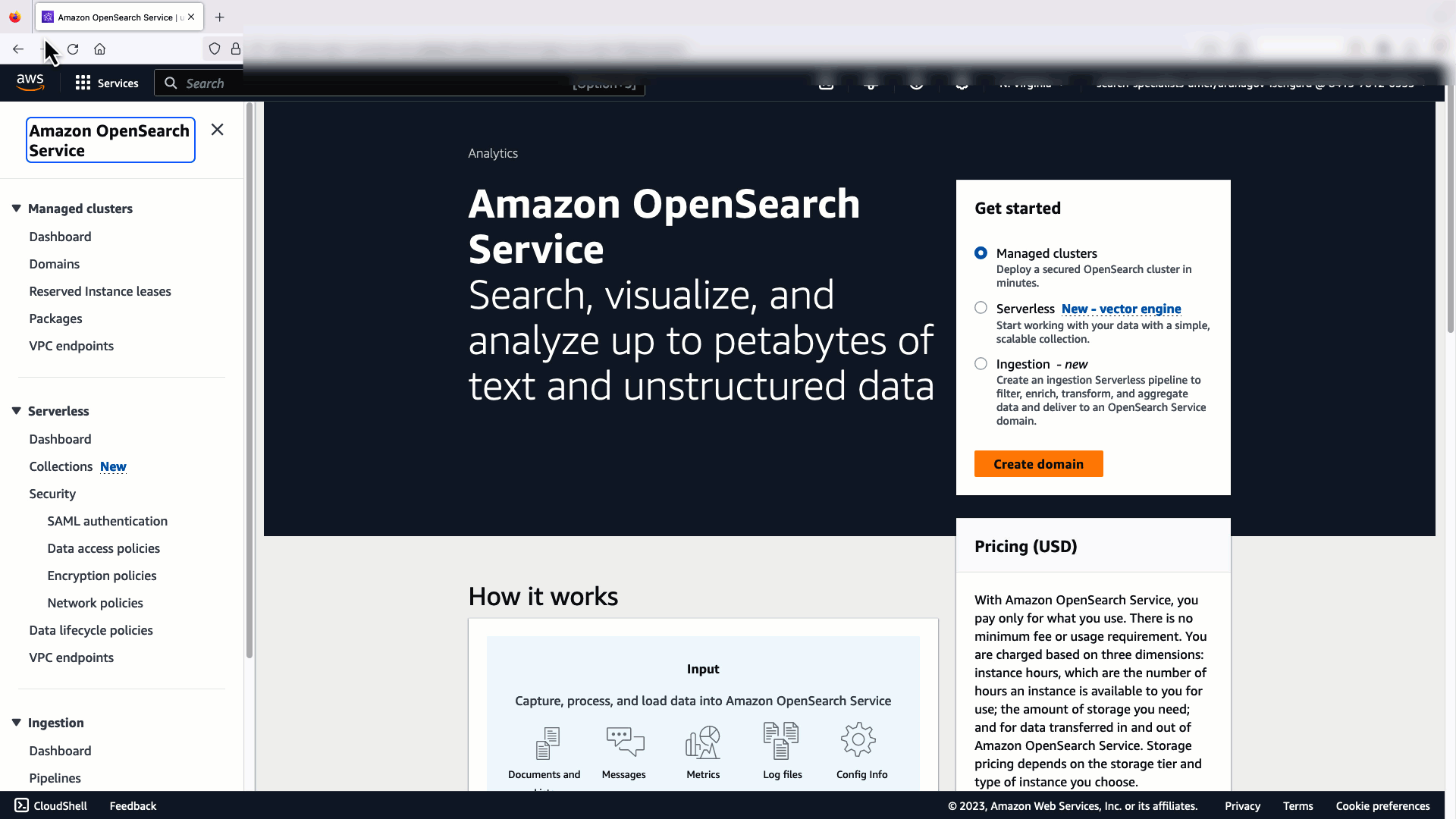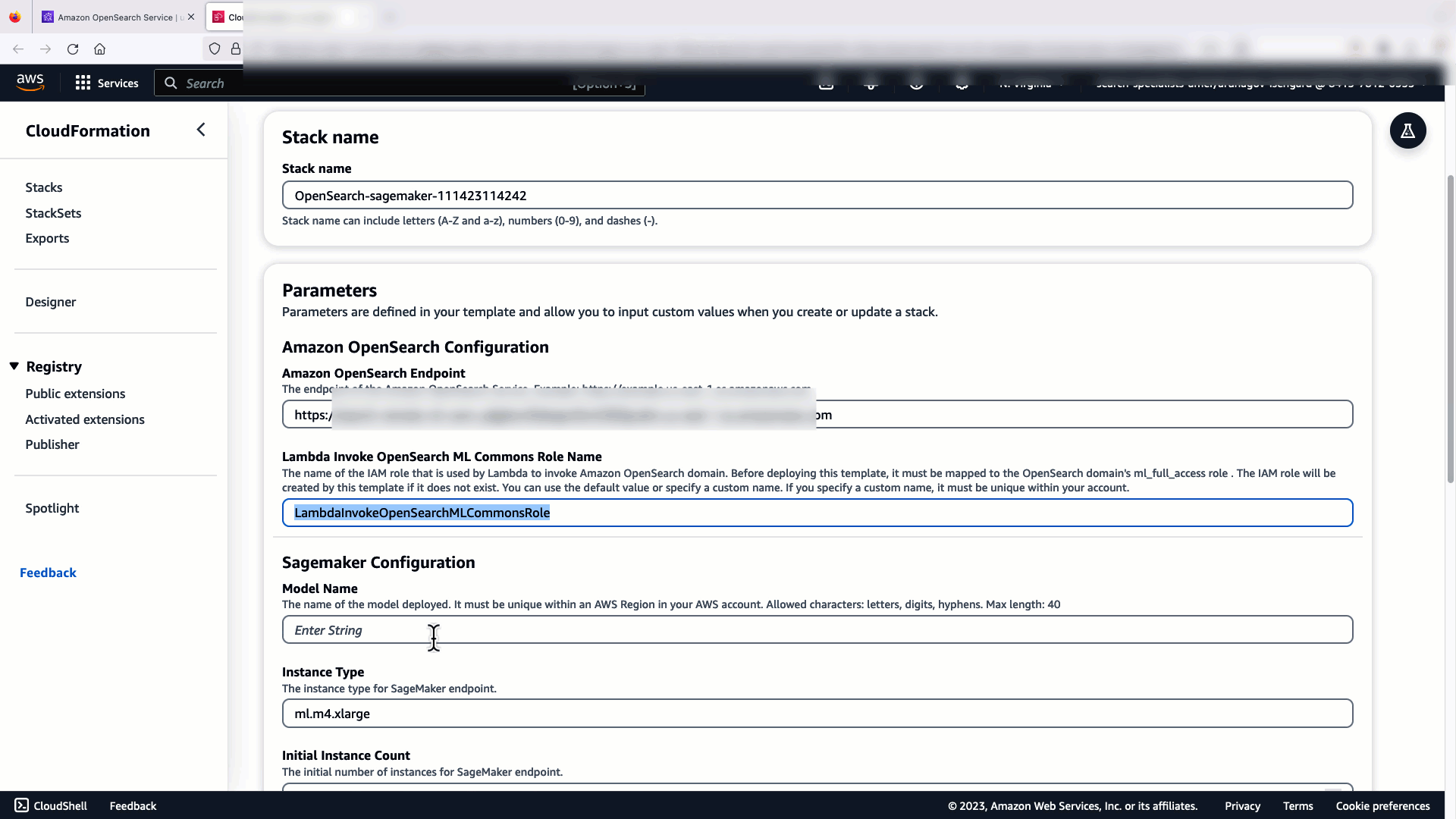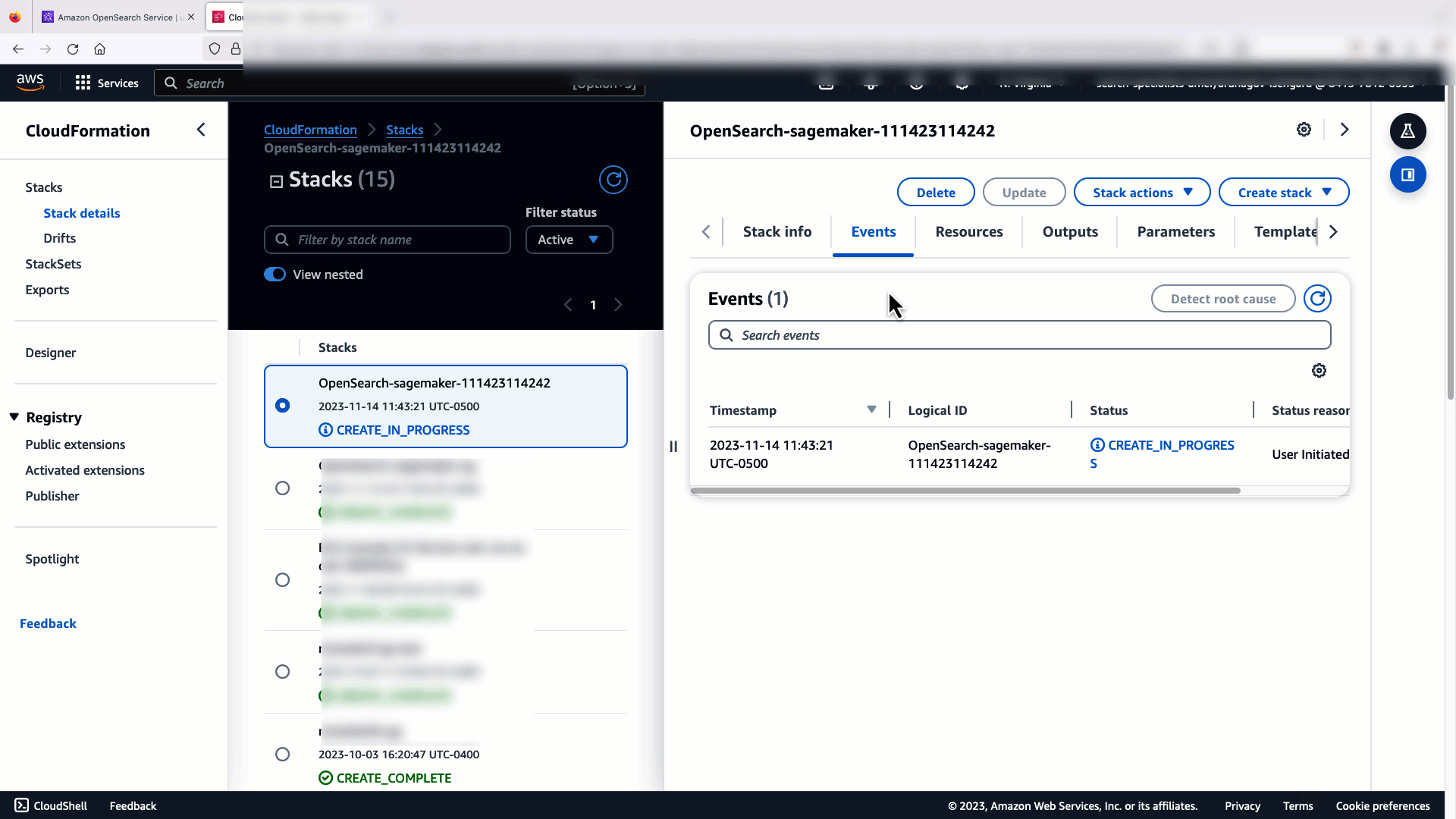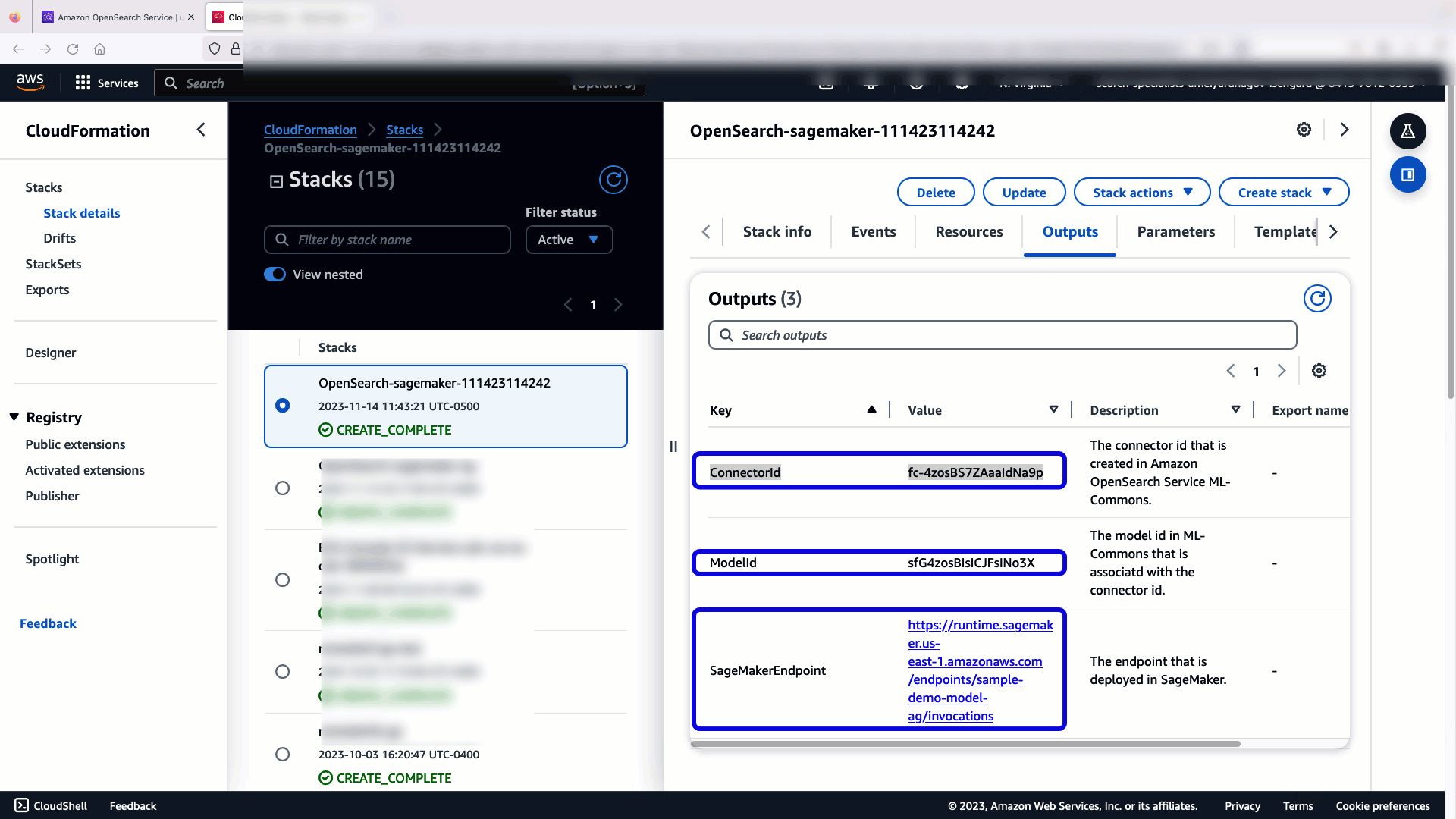
Når du velger Lag stabel, blir du dirigert til AWS skyformasjon konsoll. CloudFormation-malen distribuerer arkitekturen som er beskrevet i følgende diagram.

CloudFormation-stakken oppretter en AWS Lambda applikasjon som distribuerer en modell fra Amazon enkel lagringstjeneste (Amazon S3), oppretter kontakten og genererer modell-ID-en i utgangen. Du kan deretter bruke denne modell-ID-en til å lage en semantisk indeks.
Hvis standard all-MiniLM-L6-v2-modellen ikke tjener formålet ditt, kan du distribuere hvilken som helst tekstinnbyggingsmodell etter eget valg på den valgte modellverten (SageMaker eller Amazon Bedrock) ved å tilby modellartefakter som et tilgjengelig S3-objekt. Alternativt kan du velge ett av følgende forhåndstrente språkmodeller og distribuer den til SageMaker. For instruksjoner for å sette opp endepunkt og modeller, se Tilgjengelige Amazon SageMaker-bilder.
SageMaker er en fullstendig administrert tjeneste som samler et bredt sett med verktøy for å muliggjøre høyytelses, rimelig ML for alle brukstilfeller, og gir nøkkelfordeler som modellovervåking, serverløs hosting og arbeidsflytautomatisering for kontinuerlig opplæring og distribusjon. SageMaker lar deg være vert for og administrere livssyklusen til tekstinnbyggingsmodeller, og bruke dem til å drive semantiske søk i OpenSearch Service. Når tilkoblet, er SageMaker vert for modellene dine, og OpenSearch Service brukes til å spørre basert på slutningsresultater fra SageMaker.
Se den distribuerte modellen gjennom OpenSearch Dashboards
For å bekrefte at CloudFormation-malen har implementert modellen på OpenSearch Service-domenet og få modell-ID-en, kan du bruke ML Commons REST GET API gjennom OpenSearch Dashboards Dev Tools.
GET _plugins REST API gir nå flere APIer for også å se modellstatusen. Følgende kommando lar deg se statusen til en ekstern modell:
Som vist i følgende skjermbilde, a DEPLOYED status i svaret indikerer at modellen er vellykket distribuert på OpenSearch Service-klyngen.

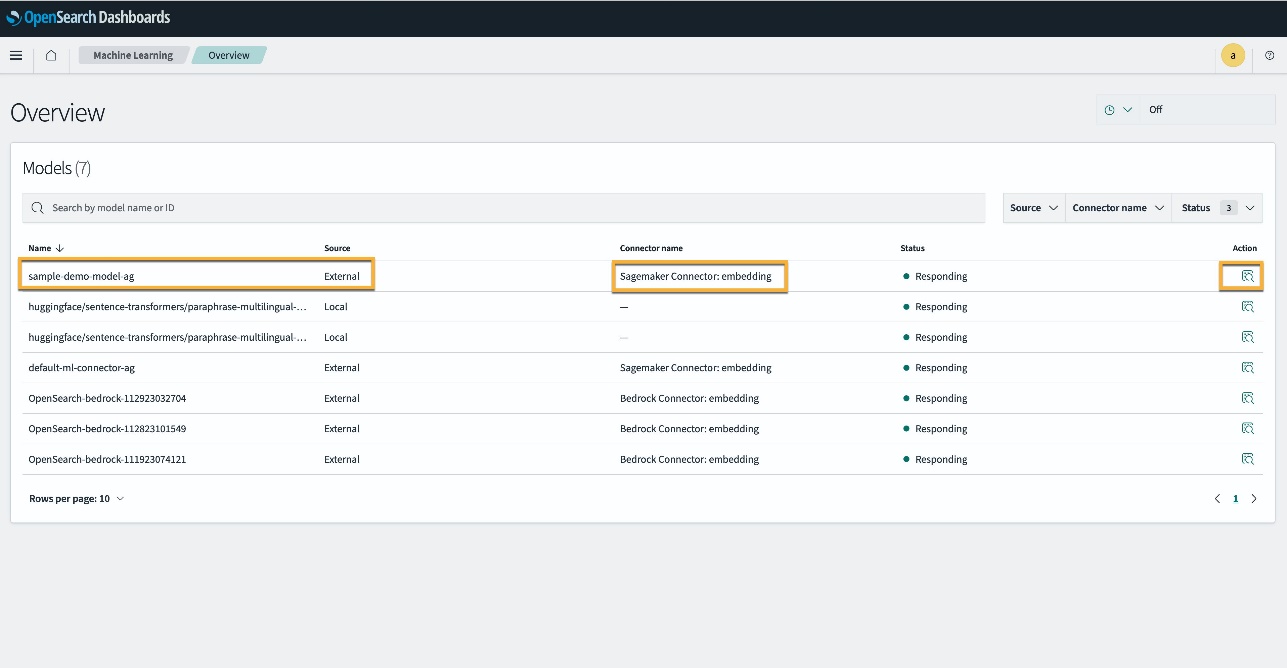
Alternativt kan du se modellen som er distribuert på OpenSearch Service-domenet ditt ved å bruke Maskinlæring siden til OpenSearch Dashboards.

Denne siden viser modellinformasjonen og statusene til alle modellene som er distribuert.

Lag den nevrale rørledningen ved å bruke modell-ID
Når statusen til modellen vises som enten DEPLOYED i Dev Tools eller grønn og svare i OpenSearch Dashboards kan du bruke modell-ID-en til å bygge nevrale inntakspipeline. Følgende inntakspipeline kjøres i domenets OpenSearch Dashboards Dev Tools. Sørg for at du erstatter modell-ID-en med den unike ID-en som er generert for modellen som er distribuert på domenet ditt.

Opprett den semantiske søkeindeksen ved å bruke den nevrale rørledningen som standardrørledningen
Du kan nå definere indekskartleggingen med standardrørledningen konfigurert til å bruke den nye nevrale rørledningen du opprettet i forrige trinn. Sørg for at vektorfeltene er deklarert som knn_vector og dimensjonene er passende for modellen som er distribuert på SageMaker. Hvis du har beholdt standardkonfigurasjonen for å distribuere all-MiniLM-L6-v2-modellen på SageMaker, beholder du følgende innstillinger som de er og kjør kommandoen i Dev Tools.

Ta inn eksempeldokumenter for å generere vektorer
For denne demoen kan du innta prøve detaljdemostore produktkatalog til det nye semantic_demostore indeks. Erstatt brukernavnet, passordet og domeneendepunktet med domeneinformasjonen din og legg inn rådata i OpenSearch Service:

Valider den nye semantiske_demostore-indeksen
Nå som du har lagt inn datasettet til OpenSearch Service-domenet, valider om de nødvendige vektorene genereres ved å bruke et enkelt søk for å hente alle feltene. Bekreft om feltene er definert som knn_vectors har de nødvendige vektorene.

Sammenlign leksikalsk søk og semantisk søk drevet av nevrale søk ved å bruke verktøyet Sammenlign søkeresultater
De Sammenlign søkeresultatverktøy på OpenSearch Dashboards er tilgjengelig for produksjonsarbeidsmengder. Du kan navigere til Sammenlign søkeresultater side og sammenligne søkeresultater mellom leksikalsk søk og nevralt søk konfigurert til å bruke modell-IDen generert tidligere.

Rydd opp
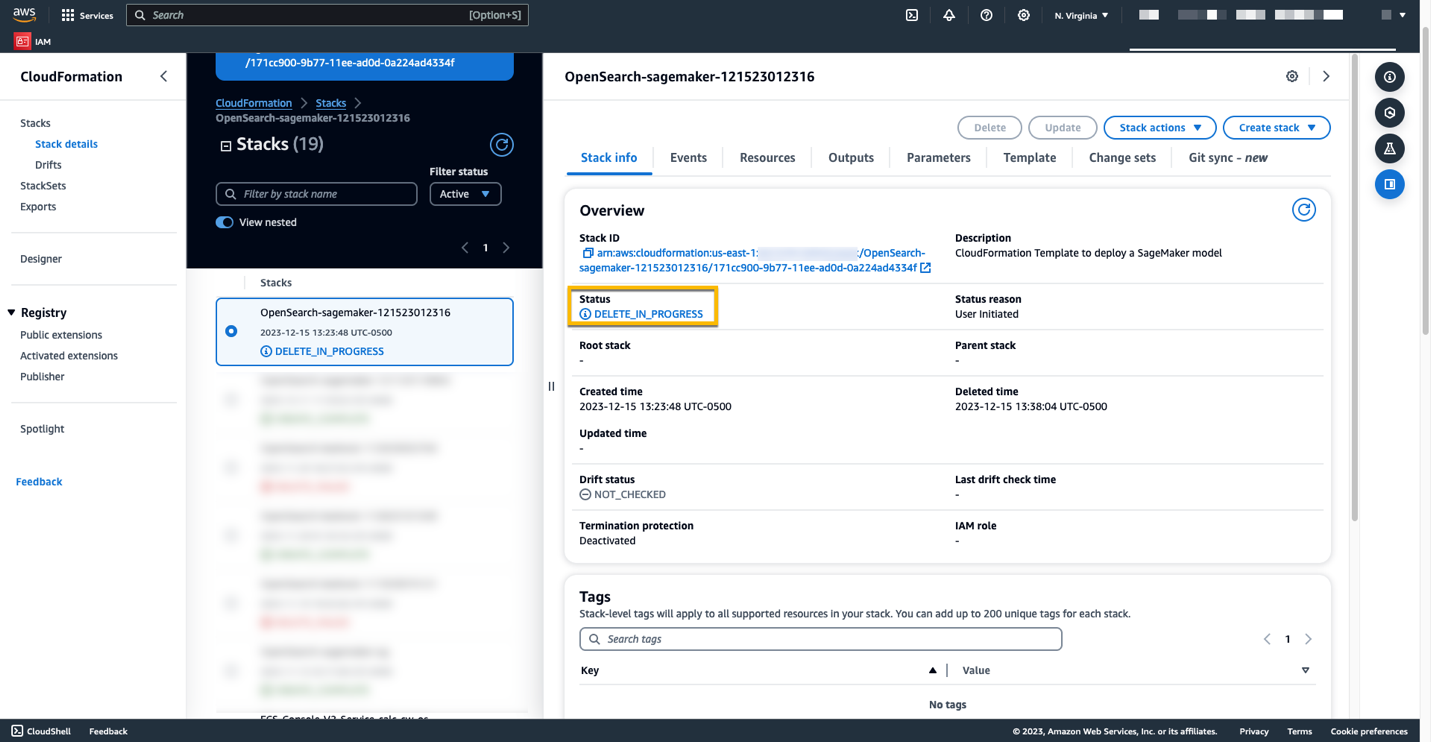
Du kan slette ressursene du opprettet ved å følge instruksjonene i dette innlegget ved å slette CloudFormation-stakken. Dette vil slette Lambda-ressursene og S3-bøtten som inneholder modellen som ble distribuert til SageMaker. Fullfør følgende trinn:
- På AWS CloudFormation-konsollen, naviger til siden med stabeldetaljer.
- Velg Delete.

- Velg Delete å bekrefte.

Du kan overvåke fremdriften for sletting av stabelen på AWS CloudFormation-konsollen.
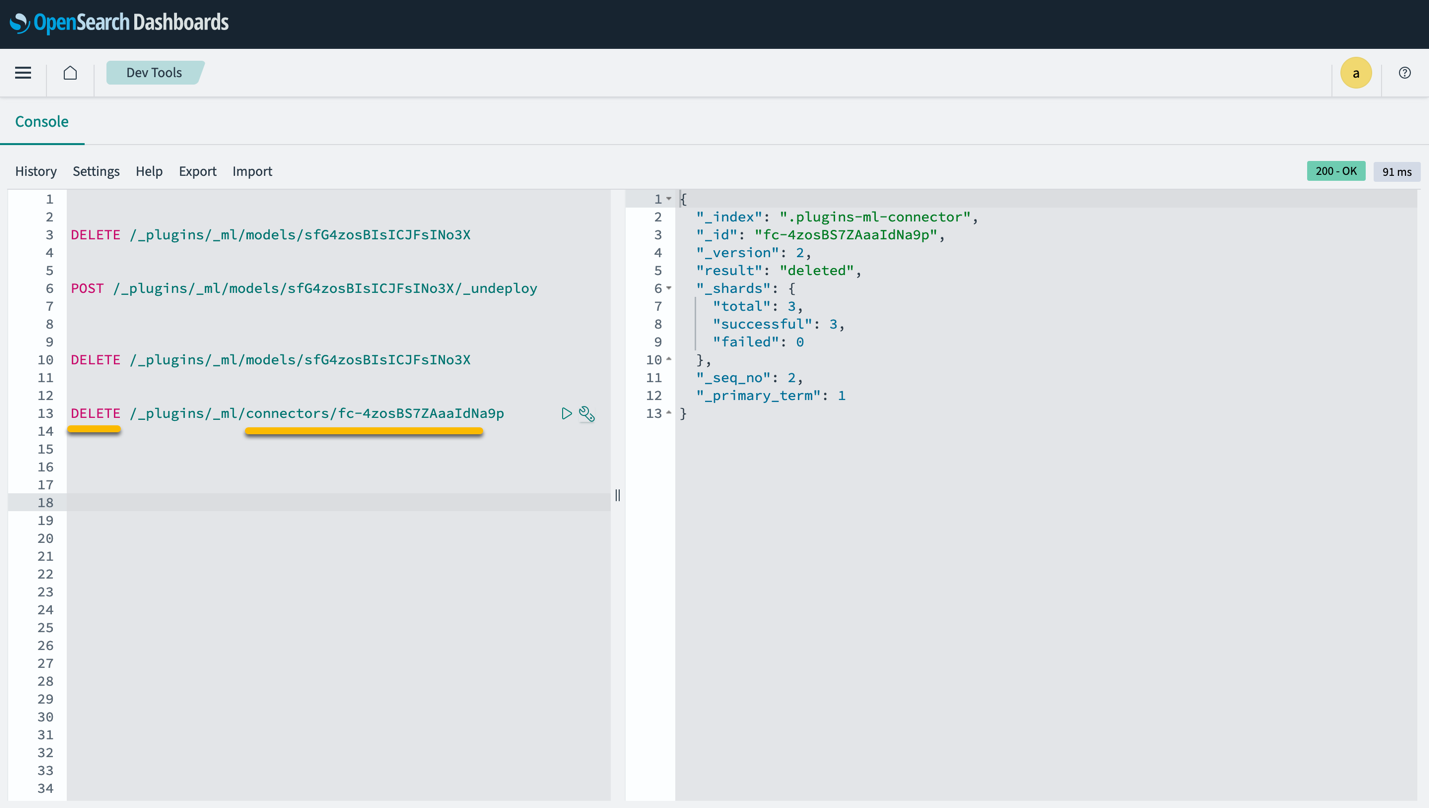
Merk at sletting av CloudFormation-stakken sletter ikke modellen som er distribuert på SageMaker-domenet og AI/ML-koblingen som er opprettet. Dette er fordi disse modellene og koblingen kan assosieres med flere indekser innenfor domenet. For å spesifikt slette en modell og dens tilknyttede kobling, bruk modell-API-ene som vist i følgende skjermbilder.
Først undeploy modellen fra OpenSearch Service-domeneminnet:

Deretter kan du slette modellen fra modellindeksen:

Til slutt sletter du koblingen fra koblingsindeksen:
konklusjonen
I dette innlegget lærte du hvordan du distribuerer en modell i SageMaker, oppretter AI/ML-koblingen ved hjelp av OpenSearch Service-konsollen og bygger den nevrale søkeindeksen. Muligheten til å konfigurere AI/ML-koblinger i OpenSearch Service forenkler vektorhydreringsprosessen ved å gjøre integrasjonene til eksterne modeller native. Du kan lage en nevral søkeindeks på minutter ved å bruke rørledningen for nevrale inntak og det nevrale søket som bruker modell-ID-en til å generere vektorinnbyggingen i farten under inntak og søk.
For å lære mer om disse AI/ML-kontaktene, se Amazon OpenSearch Service AI-koblinger for AWS-tjenester, AWS CloudFormation malintegrasjoner for semantisk søkog Opprette koblinger for tredjeparts ML-plattformer.
Om forfatterne
 Aruna Govindaraju er en Amazon OpenSearch Specialist Solutions Architect og har jobbet med mange kommersielle søkemotorer og åpen kildekode. Hun brenner for søk, relevans og brukeropplevelse. Hennes ekspertise med å korrelere sluttbrukersignaler med søkemotoratferd har hjulpet mange kunder med å forbedre søkeopplevelsen.
Aruna Govindaraju er en Amazon OpenSearch Specialist Solutions Architect og har jobbet med mange kommersielle søkemotorer og åpen kildekode. Hun brenner for søk, relevans og brukeropplevelse. Hennes ekspertise med å korrelere sluttbrukersignaler med søkemotoratferd har hjulpet mange kunder med å forbedre søkeopplevelsen.
 Dagney Braun er hovedproduktsjef hos AWS med fokus på OpenSearch.
Dagney Braun er hovedproduktsjef hos AWS med fokus på OpenSearch.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- : har
- :er
- :ikke
- $OPP
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- evne
- Om oss
- adgang
- tilgjengelig
- Ytterligere
- AI
- AI / ML
- Alle
- tillater
- også
- alternativer
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- og
- noen
- api
- APIer
- Søknad
- hensiktsmessig
- arkitektur
- ER
- AS
- assosiert
- At
- Automatisering
- tilgjengelig
- AWS
- AWS skyformasjon
- Backend
- basert
- BE
- fordi
- atferd
- Fordeler
- mellom
- både
- Bringer
- bred
- bygge
- Bygning
- by
- CAN
- saken
- saker
- katalog
- valg
- Velg
- valgt ut
- Cluster
- kommersiell
- Commons
- sammenligne
- fullføre
- kompleksitet
- Konfigurasjon
- konfigurert
- konfigurering
- Bekrefte
- tilkoblet
- Tilkobling
- tilkobling
- Konsoll
- inneholde
- fortsette
- kontinuerlig
- korrelerer
- skape
- opprettet
- skaper
- I dag
- skikk
- Kunder
- oversikter
- dato
- Misligholde
- definere
- definert
- levere
- Demo
- demonstrere
- demonstrerer
- utplassere
- utplassert
- utplasserings
- distribusjon
- Distribueres
- beskrivelse
- detaljert
- detaljer
- dev
- Dimensjon
- dimensjoner
- dokumenter
- ikke
- domene
- under
- hver enkelt
- Tidligere
- uanstrengt
- enten
- embedding
- muliggjøre
- Endpoint
- Motor
- Motorer
- sikre
- Eter (ETH)
- eksempel
- erfaring
- ekspertise
- utvendig
- Face
- forenkler
- Trekk
- Felt
- Finn
- Først
- fokuserte
- etter
- Til
- Rammeverk
- fra
- fullt
- generere
- generert
- genererer
- få
- gif
- GitHub
- Grønn
- Grow
- veilede
- Ha
- hjulpet
- her
- høy ytelse
- vert
- Hosting
- Vertskapet
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- Klem ansikt
- hydrering
- IAM
- ID
- identifisere
- Identitet
- if
- forbedre
- in
- indeks
- indekser
- indikerer
- informasjon
- innganger
- i stedet
- instruksjoner
- integrere
- integrering
- integrasjoner
- inn
- Introduksjon
- IT
- DET ER
- jpg
- JSON
- Hold
- nøkkel
- Språk
- lansere
- LÆRE
- lært
- læring
- Livssyklus
- Liste
- lister
- lave kostnader
- maskin
- maskinlæring
- gjøre
- Making
- administrer
- fikk til
- leder
- mange
- kart
- kartlegging
- Minne
- metode
- minutter
- ML
- modell
- modeller
- Overvåke
- overvåking
- mer
- mye
- flere
- må
- navn
- innfødt
- Naviger
- Navigasjon
- nødvendig
- Trenger
- neural
- Ny
- nå
- objekt
- of
- on
- ONE
- bare
- åpen
- åpen kildekode
- or
- Annen
- produksjon
- side
- brød
- lidenskapelig
- Passord
- tillatelser
- rørledning
- plato
- Platon Data Intelligence
- PlatonData
- plugg inn
- Post
- makt
- powered
- forrige
- Principal
- Før
- prosess
- prosessorer
- Produkt
- Produktsjef
- Produksjon
- Progress
- egenskaper
- gi
- gir
- gi
- formål
- spørsmål
- Raw
- rådata
- anbefaler
- referere
- fjernkontroll
- fjerne
- erstatte
- påkrevd
- Ressurser
- svar
- REST
- Resultater
- detaljhandel
- beholdes
- retur
- Rolle
- ruter
- Kjør
- sagemaker
- skjermbilder
- Søk
- søkemotor
- Søkemotorer
- sikkerhet
- se
- velg
- betjene
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- innstillinger
- hun
- vist
- Viser
- signaler
- Enkelt
- forenkler
- forenkle
- siden
- Solutions
- kilde
- spesialist
- spesielt
- stable
- Start
- status
- Trinn
- Steps
- lagring
- vellykket
- slik
- Støttes
- sikker
- mal
- tekst
- Det
- De
- deres
- Dem
- deretter
- derved
- Disse
- tredjeparts
- denne
- Gjennom
- til
- sammen
- verktøy
- Kurs
- Transformation
- Oversettelse
- sant
- typen
- ui
- unik
- unikt
- bruke
- bruk sak
- brukt
- Bruker
- Brukererfaring
- ved hjelp av
- VALIDERE
- verifisere
- versjon
- av
- video
- Se
- vandringer
- var
- we
- web
- webtjenester
- når
- hvilken
- vil
- med
- innenfor
- arbeidet
- arbeidsflyt
- arbeidsflytautomatisering
- du
- Din
- zephyrnet