Dit bericht is geschreven in samenwerking met Preshen Goobiah en Johan Olivier van Capitec.
Apache Spark is een veelgebruikt open source gedistribueerd verwerkingssysteem dat bekend staat om het verwerken van grootschalige dataworkloads. Het wordt veelvuldig toegepast onder Spark-ontwikkelaars die ermee werken Amazon EMR, Amazon Sage Maker, AWS lijm en aangepaste Spark-applicaties.
Amazon roodverschuiving biedt naadloze integratie met Apache Spark, waardoor u eenvoudig toegang heeft tot uw Redshift-gegevens op zowel door Amazon Redshift ingerichte clusters als Amazon Redshift Serverloos. Deze integratie breidt de mogelijkheden voor AWS-analyse- en machine learning (ML)-oplossingen uit, waardoor het datawarehouse toegankelijk wordt voor een breder scala aan toepassingen.
Met de Amazon Redshift-integratie voor Apache Spark, kunt u snel aan de slag en moeiteloos Spark-applicaties ontwikkelen met behulp van populaire talen zoals Java, Scala, Python, SQL en R. Uw applicaties kunnen naadloos lezen van en schrijven naar uw Amazon Redshift-datawarehouse met behoud van optimale prestaties en transactionele consistentie. Bovendien profiteert u van prestatieverbeteringen door middel van pushdown-optimalisaties, waardoor de efficiëntie van uw activiteiten verder wordt verbeterd.
Capitec, de grootste retailbank van Zuid-Afrika met meer dan 21 miljoen retailbankklanten, streeft ernaar eenvoudige, betaalbare en toegankelijke financiële diensten aan te bieden om Zuid-Afrikanen te helpen beter te bankieren, zodat ze beter kunnen leven. In dit bericht bespreken we de succesvolle integratie van de open source Amazon Redshift-connector door het Feature Platform-team van Capitec voor gedeelde services. Als gevolg van het gebruik van de Amazon Redshift-integratie voor Apache Spark steeg de productiviteit van ontwikkelaars met een factor 10, werden pijplijnen voor het genereren van functies gestroomlijnd en werd gegevensduplicatie tot nul teruggebracht.
De zakelijke mogelijkheid
Er zijn 19 voorspellende modellen beschikbaar voor het gebruik van 93 functies die zijn gebouwd met AWS Glue in de Retail Credit-divisies van Capitec. Functierecords worden verrijkt met feiten en dimensies die zijn opgeslagen in Amazon Redshift. Apache PySpark werd geselecteerd om functies te creëren omdat het een snel, gedecentraliseerd en schaalbaar mechanisme biedt om gegevens uit verschillende bronnen te verzamelen.
Deze productiefuncties spelen een cruciale rol bij het mogelijk maken van realtime leningaanvragen met een vaste looptijd, creditcardaanvragen, batchmonitoring van maandelijks kredietgedrag en batchidentificatie van dagelijkse salarissen binnen het bedrijf.
Het datasourcingprobleem
Om de betrouwbaarheid van PySpark-gegevenspijplijnen te garanderen, is het essentieel om consistente gegevens op recordniveau te hebben van zowel dimensionale als feitentabellen die zijn opgeslagen in het Enterprise Data Warehouse (EDW). Deze tabellen worden vervolgens tijdens runtime samengevoegd met tabellen uit het Enterprise Data Lake (EDL).
Tijdens de ontwikkeling van functies hebben data-ingenieurs een naadloze interface met de EDW nodig. Dankzij deze interface hebben ze toegang tot de benodigde gegevens van de EDW en kunnen ze deze integreren in de datapijplijnen, waardoor efficiënte ontwikkeling en testen van functies mogelijk wordt.
Vorig oplossingsproces
In de vorige oplossing waren de data-ingenieurs van het productteam 30 minuten per run bezig met het handmatig beschikbaar stellen van Redshift-gegevens aan Spark. De stappen omvatten het volgende:
- Construeer een voorspelde query in Python.
- Stuur een LOSSEN vraag via de Amazon Redshift-gegevens-API.
- Catalogiseer gegevens in de AWS Glue Data Catalog via de AWS SDK voor Panda's met behulp van steekproeven.
Deze aanpak leverde problemen op voor grote datasets, vereiste terugkerend onderhoud van het platformteam en was complex om te automatiseren.
Huidig oplossingsoverzicht
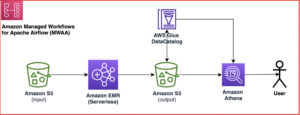
Capitec kon deze problemen oplossen met de Amazon Redshift-integratie voor Apache Spark binnen pijplijnen voor het genereren van functies. De architectuur wordt gedefinieerd in het volgende diagram.

De workflow omvat de volgende stappen:
- Interne bibliotheken worden in de AWS Glue PySpark-taak geïnstalleerd via AWS-codeartefact.
- Een AWS Glue-taak haalt Redshift-clusterreferenties op van AWS-geheimenmanager en stelt de Amazon Redshift-verbinding in (injecteert clusterreferenties, ontlaadlocaties, bestandsformaten) via de gedeelde interne bibliotheek. De Amazon Redshift-integratie voor Apache Spark ondersteunt ook het gebruik AWS Identiteits- en toegangsbeheer (IAM) aan haal inloggegevens op en maak verbinding met Amazon Redshift.
- De Spark-query wordt vertaald naar een voor Amazon Redshift geoptimaliseerde query en ingediend bij de EDW. Dit wordt bereikt door de Amazon Redshift-integratie voor Apache Spark.
- De EDW-gegevensset wordt in een tijdelijk voorvoegsel in een Amazon eenvoudige opslagservice (Amazon S3) emmer.
- De EDW-dataset uit de S3-bucket wordt in Spark-uitvoerders geladen via de Amazon Redshift-integratie voor Apache Spark.
- De EDL-dataset wordt via de AWS Glue Data Catalog in Spark-uitvoerders geladen.
Deze componenten werken samen om ervoor te zorgen dat data-ingenieurs en productiedatapijplijnen over de nodige tools beschikken om de Amazon Redshift-integratie voor Apache Spark te implementeren, queries uit te voeren en het overbrengen van gegevens van Amazon Redshift naar de EDL te vergemakkelijken.
Gebruik van de Amazon Redshift-integratie voor Apache Spark in AWS Glue 4.0
In deze sectie demonstreren we het nut van de Amazon Redshift-integratie voor Apache Spark door een tabel met leningaanvragen in het S3-datameer te verrijken met klantinformatie uit het Redshift-datawarehouse in PySpark.
De dimclient tabel in Amazon Redshift bevat de volgende kolommen:
- Clientsleutel –INT8
- KlantAltKey – VARCHAR50
- Partijidentificatienummer – VARCHAR20
- KlantCreateDate - DATUM
- Gaat niet door –INT2
- RijIsCurrent –INT2
De loanapplication tabel in de AWS Glue Data Catalog bevat de volgende kolommen:
- RecordID – BIGINT
- LogDatum – TIJDSTEMPEL
- Partijidentificatienummer - SNAAR
De Redshift-tabel wordt gelezen via de Amazon Redshift-integratie voor Apache Spark en in de cache opgeslagen. Zie de volgende code:
De registraties van leningaanvragen worden uit het S3-datameer ingelezen en verrijkt met de dimclient tabel met Amazon Redshift-informatie:
Als gevolg hiervan wordt het dossier van de leningaanvraag (uit het S3-datameer) verrijkt met de ClientCreateDate kolom (van Amazon Redshift).

Hoe de Amazon Redshift-integratie voor Apache Spark het datasourcingprobleem oplost
De Amazon Redshift-integratie voor Apache Spark pakt het datasourcingprobleem effectief aan via de volgende mechanismen:
- Just-in-time lezen – De Amazon Redshift-integratie voor Apache Spark-connector leest Redshift-tabellen op een just-in-time manier, waardoor de consistentie van gegevens en schema wordt gegarandeerd. Dit is bijzonder waardevol voor Type 2 langzaam veranderende dimensie (SCD) en tijdspanne die momentopname-feiten verzamelt. Door deze Redshift-tabellen te combineren met de bronsysteem AWS Glue Data Catalog-tabellen van de EDL binnen productie-PySpark-pijplijnen, maakt de connector een naadloze integratie van gegevens uit meerdere bronnen mogelijk met behoud van de gegevensintegriteit.
- Geoptimaliseerde Redshift-query's – De Amazon Redshift-integratie voor Apache Spark speelt een cruciale rol bij het omzetten van het Spark-queryplan naar een geoptimaliseerde Redshift-query. Dit conversieproces vereenvoudigt de ontwikkelingservaring voor het productteam door vast te houden aan het datalokaliteitsprincipe. De geoptimaliseerde queries maken gebruik van de mogelijkheden en prestatie-optimalisaties van Amazon Redshift, waardoor het efficiënt ophalen en verwerken van gegevens vanuit Amazon Redshift voor de PySpark-pijplijnen wordt gegarandeerd. Dit helpt het ontwikkelingsproces te stroomlijnen en tegelijkertijd de algehele prestaties van de datasourcingactiviteiten te verbeteren.
Het behalen van de beste prestaties
De Amazon Redshift-integratie voor Apache Spark past automatisch predicaat- en query-pushdown toe om de prestaties te optimaliseren. U kunt prestatieverbeteringen verkrijgen door de standaard Parquet-indeling te gebruiken die wordt gebruikt voor het verwijderen van deze integratie.
Voor aanvullende details en codevoorbeelden raadpleegt u Nieuw – Amazon Redshift-integratie met Apache Spark.
Voordelen van de oplossing:
De adoptie van de integratie leverde een aantal belangrijke voordelen op voor het team:
- Verbeterde productiviteit van ontwikkelaars – De PySpark-interface van de integratie verhoogde de productiviteit van ontwikkelaars met een factor 10, waardoor een soepelere interactie met Amazon Redshift mogelijk werd.
- Eliminatie van gegevensduplicatie – Dubbele en door AWS Glue gecatalogiseerde Redshift-tabellen in het datameer zijn geëlimineerd, wat resulteert in een meer gestroomlijnde dataomgeving.
- Verminderde EDW-belasting – De integratie vergemakkelijkte het selectief ontladen van gegevens, waardoor de belasting van de EDW werd geminimaliseerd door alleen de noodzakelijke gegevens te extraheren.
Door de Amazon Redshift-integratie voor Apache Spark te gebruiken, heeft Capitec de weg vrijgemaakt voor verbeterde gegevensverwerking, verhoogde productiviteit en een efficiënter ecosysteem voor feature-engineering.
Conclusie
In dit bericht hebben we besproken hoe het Capitec-team met succes de Apache Spark Amazon Redshift-integratie voor Apache Spark heeft geïmplementeerd om hun workflows voor functieberekening te vereenvoudigen. Ze benadrukten het belang van het gebruik van gedecentraliseerde en modulaire PySpark-datapijplijnen voor het creëren van voorspellende modelfuncties.
Momenteel wordt de Amazon Redshift-integratie voor Apache Spark gebruikt door zeven productiedatapijplijnen en twintig ontwikkelingspijplijnen, wat de effectiviteit ervan binnen de omgeving van Capitec aantoont.
In de toekomst is het Feature Platform-team voor gedeelde services bij Capitec van plan om de adoptie van de Amazon Redshift-integratie voor Apache Spark in verschillende bedrijfsgebieden uit te breiden, met als doel de gegevensverwerkingsmogelijkheden verder te verbeteren en efficiënte feature-engineeringpraktijken te bevorderen.
Raadpleeg de volgende bronnen voor aanvullende informatie over het gebruik van de Amazon Redshift-integratie voor Apache Spark:
Over de auteurs
 Preshen Goobiah is de Lead Machine Learning Engineer voor het Feature Platform bij Capitec. Hij richt zich op het ontwerpen en bouwen van Feature Store-componenten voor zakelijk gebruik. In zijn vrije tijd houdt hij van lezen en reizen.
Preshen Goobiah is de Lead Machine Learning Engineer voor het Feature Platform bij Capitec. Hij richt zich op het ontwerpen en bouwen van Feature Store-componenten voor zakelijk gebruik. In zijn vrije tijd houdt hij van lezen en reizen.
 Johan Olivier is een Senior Machine Learning Engineer voor het Model Platform van Capitec. Hij is een ondernemer en een liefhebber van probleemoplossing. In zijn vrije tijd houdt hij van muziek en gezelligheid.
Johan Olivier is een Senior Machine Learning Engineer voor het Model Platform van Capitec. Hij is een ondernemer en een liefhebber van probleemoplossing. In zijn vrije tijd houdt hij van muziek en gezelligheid.
 Sudipta Bagchi is een Senior Specialist Solutions Architect bij Amazon Web Services. Hij heeft meer dan 12 jaar ervaring in data en analytics en helpt klanten bij het ontwerpen en bouwen van schaalbare en krachtige analytics-oplossingen. Buiten zijn werk houdt hij van hardlopen, reizen en cricket spelen. Maak verbinding met hem LinkedIn.
Sudipta Bagchi is een Senior Specialist Solutions Architect bij Amazon Web Services. Hij heeft meer dan 12 jaar ervaring in data en analytics en helpt klanten bij het ontwerpen en bouwen van schaalbare en krachtige analytics-oplossingen. Buiten zijn werk houdt hij van hardlopen, reizen en cricket spelen. Maak verbinding met hem LinkedIn.
 Syed Humair is een Senior Analytics Specialist Solutions Architect bij Amazon Web Services (AWS). Hij heeft meer dan 17 jaar ervaring in enterprise-architectuur met de nadruk op data en AI/ML, waarmee hij AWS-klanten wereldwijd helpt om aan hun zakelijke en technische vereisten te voldoen. U kunt verbinding met hem maken via LinkedIn.
Syed Humair is een Senior Analytics Specialist Solutions Architect bij Amazon Web Services (AWS). Hij heeft meer dan 17 jaar ervaring in enterprise-architectuur met de nadruk op data en AI/ML, waarmee hij AWS-klanten wereldwijd helpt om aan hun zakelijke en technische vereisten te voldoen. U kunt verbinding met hem maken via LinkedIn.
 Vuyisa Maswana is een Senior Solutions Architect bij AWS, gevestigd in Kaapstad. Vuyisa heeft een sterke focus op het helpen van klanten bij het bouwen van technische oplossingen om zakelijke problemen op te lossen. Sinds 2019 ondersteunt hij Capitec in hun AWS-reis.
Vuyisa Maswana is een Senior Solutions Architect bij AWS, gevestigd in Kaapstad. Vuyisa heeft een sterke focus op het helpen van klanten bij het bouwen van technische oplossingen om zakelijke problemen op te lossen. Sinds 2019 ondersteunt hij Capitec in hun AWS-reis.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/simplifying-data-processing-at-capitec-with-amazon-redshift-integration-for-apache-spark/
- : heeft
- :is
- $UP
- 06
- 1
- 10
- 100
- 12
- 16
- 17
- 19
- 20
- 2019
- 30
- 7
- a
- in staat
- toegang
- beschikbaar
- volbracht
- over
- Extra
- Extra informatie
- Daarnaast
- adres
- adressen
- zich eraan houden
- Adoptie
- betaalbaar
- AI / ML
- het richten
- wil
- Het toestaan
- toestaat
- ook
- Amazone
- Amazon Web Services
- Amazon Web Services (AWS)
- onder
- an
- analytics
- en
- apache
- Apache Spark
- Aanvraag
- toepassingen
- geldt
- nadering
- architectuur
- ZIJN
- gebieden
- AS
- At
- automatiseren
- webmaster.
- AWS
- AWS lijm
- Bank
- Bankieren
- gebaseerde
- omdat
- gedrag
- voordeel
- betekent
- BEST
- Betere
- tussen
- Grootste
- Boosted
- zowel
- bredere
- bouw
- Gebouw
- bebouwd
- bedrijfsdeskundigen
- by
- CAN
- mogelijkheden
- kaap
- kaart
- catalogus
- veranderende
- klant
- klanten
- TROS
- CO
- code
- Kolom
- columns
- combineren
- complex
- componenten
- berekening
- Verbinden
- versterken
- consequent
- bevat
- verband
- Camper ombouw
- het omzetten van
- en je merk te creëren
- Wij creëren
- Geloofsbrieven
- Credits
- creditkaart
- krekel
- cruciaal
- gewoonte
- Klanten
- dagelijks
- gegevens
- Datameer
- gegevensverwerking
- datawarehouse
- datasets
- gedecentraliseerde
- Standaard
- gedefinieerd
- tonen
- Design
- ontwerpen
- gegevens
- ontwikkelen
- Ontwikkelaar
- ontwikkelaars
- Ontwikkeling
- anders
- Afmeting
- Afmeting
- bespreken
- besproken
- verdeeld
- diversen
- gemakkelijk
- ecosysteem
- effectief
- effectiviteit
- doeltreffendheid
- doeltreffend
- moeiteloos
- geëlimineerd
- benadrukte
- maakt
- waardoor
- ingenieur
- Engineering
- Ingenieurs
- verhogen
- verbeteren
- verrijkt
- verrijkende
- verzekeren
- zorgen
- Enterprise
- enthousiast
- Ondernemer
- Milieu
- essentieel
- Ether (ETH)
- bestaand
- Uitvouwen
- breidt uit
- ervaring
- vergemakkelijken
- vergemakkelijkt
- feit
- factor
- feiten
- SNELLE
- Kenmerk
- Voordelen
- Dien in
- financieel
- financiële diensten
- vondsten
- Focus
- gericht
- gericht
- volgend
- Voor
- formaat
- Naar voren
- veelvuldig
- oppompen van
- functies
- verder
- Krijgen
- generatie
- krijgen
- GitHub
- Wereldwijd
- Behandeling
- Hebben
- he
- hulp
- het helpen van
- helpt
- hem
- zijn
- Hoe
- HTML
- http
- HTTPS
- IAM
- Identificatie
- Identiteit
- uitvoeren
- geïmplementeerd
- importeren
- belang
- verbeterd
- verbeteringen
- in
- inclusief
- omvat
- meer
- informatie
- integreren
- integratie
- integriteit
- wisselwerking
- Interface
- intern
- in
- problemen
- IT
- HAAR
- Java
- Jobomschrijving:
- mee
- toegetreden
- meer
- Talen
- Groot
- grootschalig
- leiden
- leren
- links
- bibliotheken
- Bibliotheek
- als
- leven
- laden
- lening
- locaties
- houdt
- machine
- machine learning
- behoud van
- onderhoud
- maken
- manier
- handmatig
- mechanisme
- mechanismen
- miljoen
- minimaliseren
- minuten
- ML
- model
- modellen
- modulaire
- Grensverkeer
- maandelijks
- meer
- efficiënter
- meervoudig
- Muziek
- noodzakelijk
- of
- Aanbod
- Olivier
- on
- Slechts
- open
- open source
- Operations
- optimale
- Optimaliseer
- geoptimaliseerde
- bestellen
- buiten
- over
- totaal
- panda's
- vooral
- Wachtwoord
- voor
- prestatie
- plan
- plannen
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- Spelen
- spelen
- speelt
- Populair
- gesteld
- mogelijkheden
- Post
- praktijken
- voorspellend
- vorig
- principe
- probleem
- probleemoplossing
- problemen
- verwerking
- Product
- productie
- produktiviteit
- promoten
- zorgen voor
- mits
- Python
- queries
- snel
- R
- reeks
- Lees
- lezing
- real-time
- record
- archief
- terugkerend
- Gereduceerd
- verwijzen
- betrouwbaarheid
- Vermaard
- vereisen
- nodig
- Voorwaarden
- oplossen
- Resources
- resultaat
- verkregen
- <HR>Retail
- Retailbanking
- Rol
- lopen
- lopend
- salaris
- SC
- Scala
- schaalbare
- omvang
- sdk
- naadloos
- naadloos
- geheimen
- sectie
- zien
- gekozen
- selecteren
- selectief
- senior
- Diensten
- Sets
- verscheidene
- gedeeld
- presentatie
- aanzienlijke
- Eenvoudig
- vereenvoudigen
- vereenvoudigen
- sinds
- Langzaam
- gladder
- Momentopname
- So
- socialiseren
- oplossing
- Oplossingen
- OPLOSSEN
- Lost op
- bron
- bronnen
- Sourcing XNUMX
- Zuiden
- Vonk
- specialist
- besteed
- SQL
- gestart
- Stappen
- mediaopslag
- opgeslagen
- gestroomlijnd
- gestroomlijnd
- Draad
- sterke
- ingediend
- geslaagd
- Met goed gevolg
- ondersteunde
- steunen
- system
- tafel
- team
- Technisch
- tijdelijk
- Testen
- dat
- De
- De Bron
- hun
- Ze
- harte
- Deze
- ze
- dit
- Door
- niet de tijd of
- naar
- samen
- tools
- stad
- transactionele
- Reizend
- URL
- .
- gebruikt
- gebruik
- utility
- gebruikt
- Gebruik makend
- waardevol
- via
- Magazijn
- was
- Manier..
- we
- web
- webservices
- waren
- en
- Met
- binnen
- Mijn werk
- samenwerken
- workflow
- workflows
- werkzaam
- schrijven
- jaar
- opgeleverd
- u
- Your
- zephyrnet
- nul