Nu data-engineering steeds complexer wordt, zijn organisaties op zoek naar nieuwe manieren om hun dataverwerkingsworkflows te stroomlijnen. Veel data-ingenieurs gebruiken tegenwoordig Apache Airflow om hun datapijplijnen te bouwen, plannen en monitoren.
Naarmate de hoeveelheid gegevens groeit, kan het beheren en opschalen van deze pijplijnen echter een lastige taak worden. Door Amazon beheerde workflows voor Apache Airflow (Amazon MWAA) kan het proces van het bouwen, uitvoeren en beheren van datapijplijnen helpen vereenvoudigen. Door Apache Airflow aan te bieden als een volledig beheerd platform, stelt Amazon MWAA data-ingenieurs in staat zich te concentreren op het bouwen van dataworkflows in plaats van zich zorgen te maken over de infrastructuur.
Tegenwoordig hebben bedrijven en organisaties kosteneffectieve en efficiënte manieren nodig om grote hoeveelheden gegevens te verwerken. Amazon EMR Serverloos is een kosteneffectieve en schaalbare oplossing voor de verwerking van big data die grote hoeveelheden gegevens kan verwerken. De Amazon-provider in Apache Airflow wordt geleverd met EMR Serverless-operators en is al opgenomen in Amazon MWAA, waardoor het voor data-ingenieurs gemakkelijk is om schaalbare en betrouwbare dataverwerkingspijplijnen te bouwen. U kunt EMR Serverless gebruiken om Spark-taken op de gegevens uit te voeren, en Amazon MWAA gebruiken om de werkstromen en afhankelijkheden tussen deze taken te beheren. Deze integratie kan ook helpen de kosten te verlagen door automatisch de bronnen te schalen die nodig zijn om gegevens te verwerken.
Amazon Athena is een serverloze, interactieve analyseservice die is gebouwd op open-sourceframeworks en ondersteuning biedt voor open-tabel- en bestandsformaten. U kunt standaard SQL gebruiken om met gegevens te communiceren. Athena, een serverloze en interactieve analyseservice, maakt dit mogelijk zonder de noodzaak om een complexe infrastructuur te beheren.
In dit bericht gebruiken we Amazon MWAA, EMR Serverless en Athena om een complete end-to-end dataverwerkingspijplijn op te bouwen.
Overzicht oplossingen
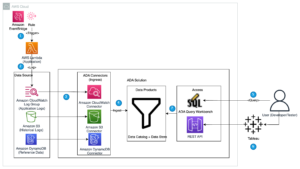
Het volgende diagram illustreert de oplossingsarchitectuur.
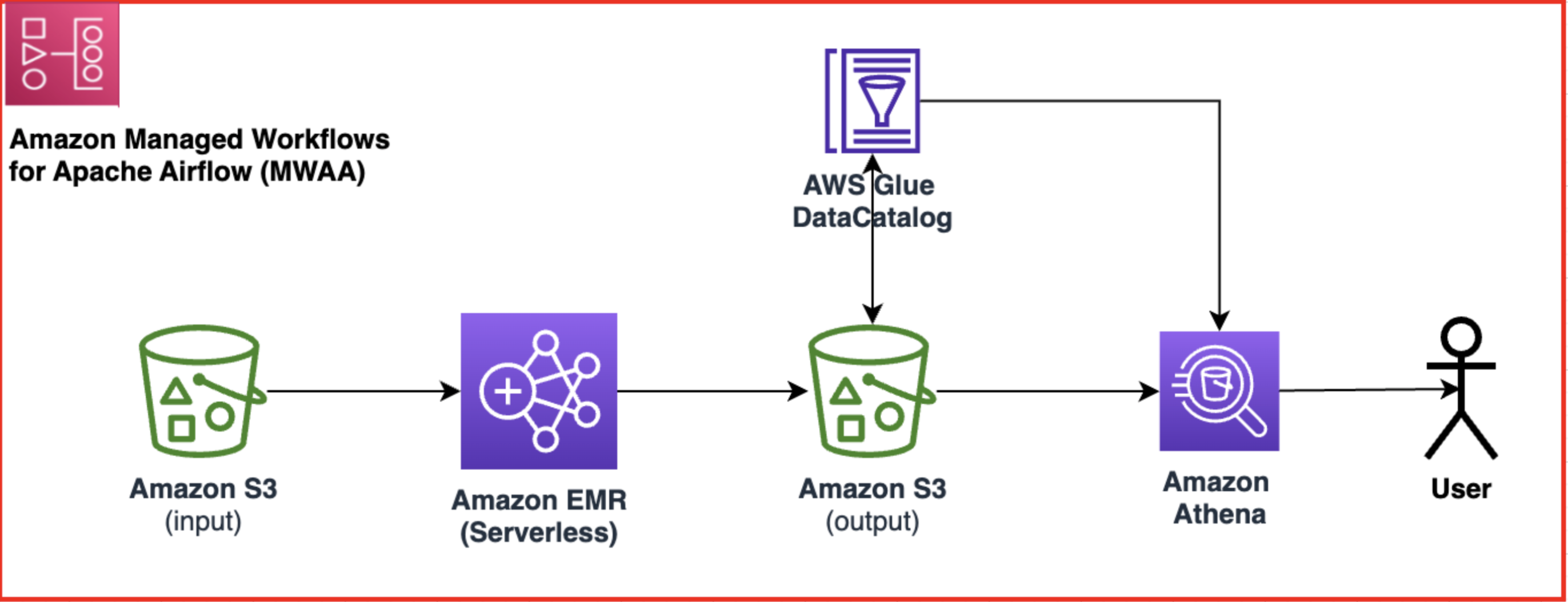
De workflow omvat de volgende stappen:
- Creëer een Amazon MWAA-workflow die gegevens uit uw invoer haalt Amazon eenvoudige opslagservice (Amazon S3) emmer.
- Gebruik EMR Serverless om de gegevens te verwerken die zijn opgeslagen in Amazon S3. EMR Serverless schaalt automatisch omhoog of omlaag op basis van de werklast, zodat u zich geen zorgen hoeft te maken over het inrichten of beheren van welke infrastructuur dan ook.
- Gebruik EMR Serverless om de gegevens te transformeren met behulp van PySpark-code en sla de getransformeerde gegevens vervolgens weer op in uw S3-bucket.
- Gebruik Athena om een externe tabel te maken op basis van de S3-gegevensset en voer query's uit om de getransformeerde gegevens te analyseren. Athene gebruikt de AWS lijm Data Catalog om de tabelmetagegevens op te slaan.
Voorwaarden
U moet de volgende vereisten hebben:
Data voorbereiding
Om het gebruik van EMR Serverless-taken met Apache Spark via Amazon MWAA en gegevensvalidatie met Athena te illustreren, gebruiken we de openbaar beschikbare NYC-taxidataset. Download de volgende gegevenssets naar uw lokale computer:
- Groene taxi- en gele taxiritgegevens – Ritgegevens voor gele en groene taxi's, die informatie bevatten zoals ophaal- en afleverdata en -tijden, locaties, ritafstanden en betalingswijzen. In ons voorbeeld gebruiken we de nieuwste Parquet-bestanden voor 2022.
- Gegevensset voor het opzoeken van taxizones – Een dataset die locatie-ID's en bijbehorende zonedetails voor taxi's levert.
In latere stappen uploaden we deze datasets naar Amazon S3.
Oplossingsbronnen maken
In deze sectie worden de stappen beschreven voor het instellen van gegevensverwerking en -transformatie.
Maak een EMR-serverloze applicatie
U kunt een of meer serverloze EMR-toepassingen maken die gebruikmaken van open source-analyseframeworks zoals Apache Spark of Apache Hive. In tegenstelling tot EMR op EC2 hoeft u EMR Serverless-applicaties niet te verwijderen of te beëindigen. EMR Serverloze applicatie is slechts een definitie en kan, eenmaal gemaakt, zo lang als nodig worden hergebruikt. Dit maakt de MWAA-pijplijn eenvoudiger, omdat u nu alleen nog maar taken hoeft in te dienen bij een vooraf gemaakte EMR Serverless-applicatie.
StandaardDe EMR Serverless-applicatie start standaard automatisch bij het indienen van opdrachten en stopt automatisch wanneer deze gedurende 15 minuten inactief is om kostenefficiëntie te garanderen. U kunt de hoeveelheid inactieve tijd wijzigen of ervoor kiezen om de functie uit te schakelen.
Om een applicatie te maken met behulp van de EMR Serverless console, volgt u de instructies in “Maak een EMR-serverloze applicatie'. Noteer de applicatie-ID, aangezien we deze in de volgende stappen zullen gebruiken.
![]()
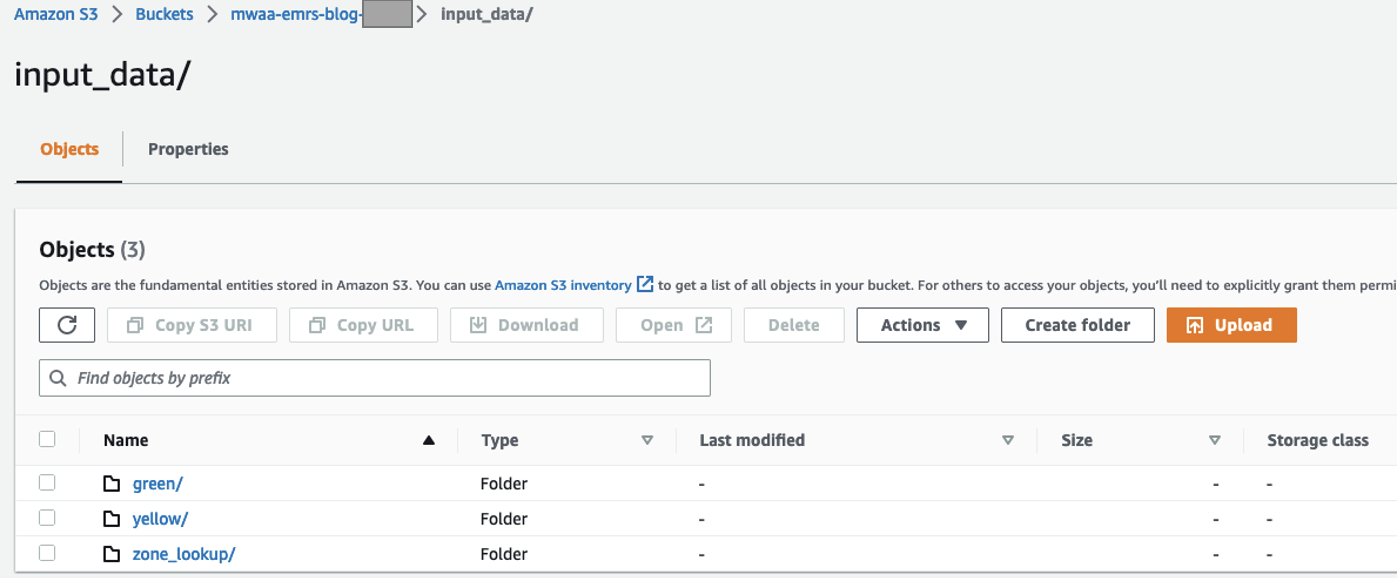
Een S3-bucket en -mappen maken
Voer de volgende stappen uit om uw S3-bucket en -mappen in te stellen:
- Op de Amazon S3-console, maak een S3-bucket om de dataset op te slaan.
- Noteer de naam van de S3-bucket die u in latere stappen wilt gebruiken.
- Maak een
input_datamap voor het opslaan van invoergegevens. - Maak binnen die map drie afzonderlijke mappen, één voor elke gegevensset:
green,yellowenzone_lookup.
U kunt de nieuwste beschikbare datasets downloaden en ermee werken. Voor onze tests gebruiken we de volgende bestanden:
- De
green/map bevat het bestandgreen_tripdata_2022-06.parquet - De
yellow/map bevat het bestandyellow_tripdata_2022-06.parquet - De
zone_lookup/map bevat het bestandtaxi_zone_lookup.csv
Stel de Amazon MWAA DAG-scripts in
Voer de volgende stappen uit om uw DAG-scripts in te stellen:
- Download de volgende scripts naar uw lokale computer:
- requirements.txt – Een Python-afhankelijkheid is elk pakket of elke distributie die niet is opgenomen in de Apache Airflow-basisinstallatie voor uw Apache Airflow-versie in uw Amazon MWAA-omgeving. Voor dit bericht gebruiken we Boto3
version >=1.23.9. - blog_dag_mwaa_emrs_ny_taxi.py – Dit script is onderdeel van de Amazon MWAA DAG en bestaat uit de volgende taken:
yellow_taxi_zone_lookup,green_taxi_zone_lookupenny_taxi_summary,. Deze taken omvatten het uitvoeren van Spark-taken om taxizones op te zoeken en een gegevenssamenvatting te genereren. - groene_zone.py – Dit PySpark-script leest gegevensbestanden voor groene taxiritten en het opzoeken van zones, voert een join-operatie uit om ze te combineren en genereert een uitvoerbestand met groene taxiritten met zone-informatie. Het maakt gebruik van tijdelijke weergaven voor de
df_greenendf_zonedataframes, voert op kolommen gebaseerde joins uit en verzamelt gegevens zoals het aantal passagiers, de reisafstand en het tariefbedrag. Ten slotte creëert het deoutput_datamap in de opgegeven S3-bucket om het resulterende dataframe te schrijven,df_green_zone, als Parquet-bestanden. - geel_zone.py – Dit PySpark-script verwerkt gegevensbestanden voor gele taxiritten en zones door ze samen te voegen om een uitvoerbestand te genereren met gele taxiritten met zone-informatie. Het script accepteert een door de gebruiker opgegeven S3-bucketnaam en initieert een Spark-sessie met de toepassingsnaam
yellow_zone. Het leest de gele taxibestanden en het zone-opzoekbestand uit de opgegeven S3-bucket, creëert tijdelijke weergaven, voert een join uit op basis van locatie-ID en berekent statistieken zoals het aantal passagiers, de reisafstand en het tariefbedrag. Ten slotte creëert het deoutput_datamap in de opgegeven S3-bucket om het resulterende dataframe te schrijven,df_yellow_zone, als Parquet-bestanden. - ny_taxi_summary.py – Dit PySpark-script verwerkt de
green_zoneenyellow_zonebestanden om statistieken over taxiritten te verzamelen, waarbij gegevens worden gegroepeerd op servicezones en locatie-ID's. Het vereist een S3-bucketnaam als opdrachtregelargument en maakt een SparkSession met de naamny_taxi_summary, leest de bestanden van S3, voert een join uit en genereert een nieuw dataframe met de naamny_taxi_summary. Er wordt een map output_data gemaakt in de opgegeven S3-bucket om het resulterende dataframe naar nieuwe Parquet-bestanden te schrijven.
- requirements.txt – Een Python-afhankelijkheid is elk pakket of elke distributie die niet is opgenomen in de Apache Airflow-basisinstallatie voor uw Apache Airflow-versie in uw Amazon MWAA-omgeving. Voor dit bericht gebruiken we Boto3
- Update op uw lokale computer het
blog_dag_mwaa_emrs_ny_taxi.pyscript met de volgende informatie:- Update uw S3-bucketnaam in de volgende twee regels:
- Update uw rolnaam ARN:
- Update EMR serverloze applicatie-ID. Gebruik de eerder gemaakte applicatie-ID.
- Upload de
requirements.txtbestand naar de eerder gemaakte S3-bucket
- Maak in de S3-bucket een map met de naam
dagsen upload de bijgewerkteblog_dag_mwaa_emrs_ny_taxi.pybestand vanaf uw lokale computer.
- Maak op de Amazon S3-console een nieuwe map met de naam
scriptsin de S3-bucket en upload de scripts vanaf uw lokale computer naar deze map.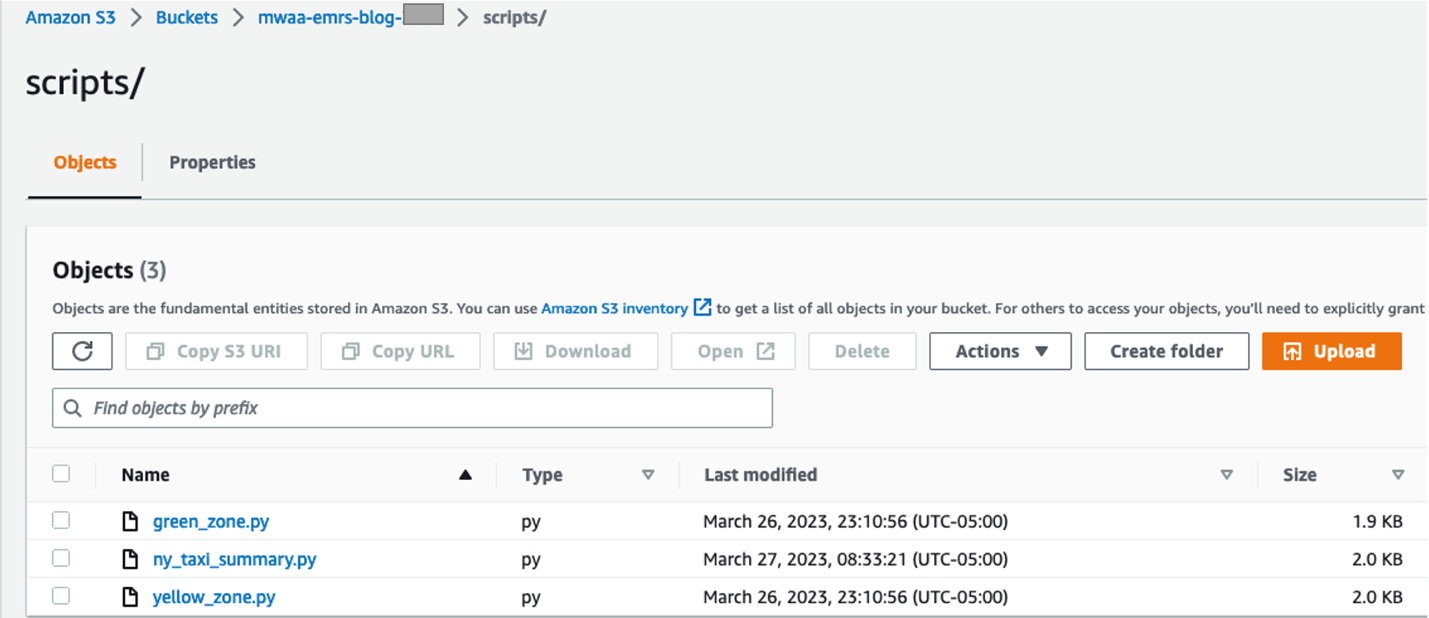
Creëer een Amazon MWAA-omgeving
Om een Airflow-omgeving te creëren, voert u de volgende stappen uit:
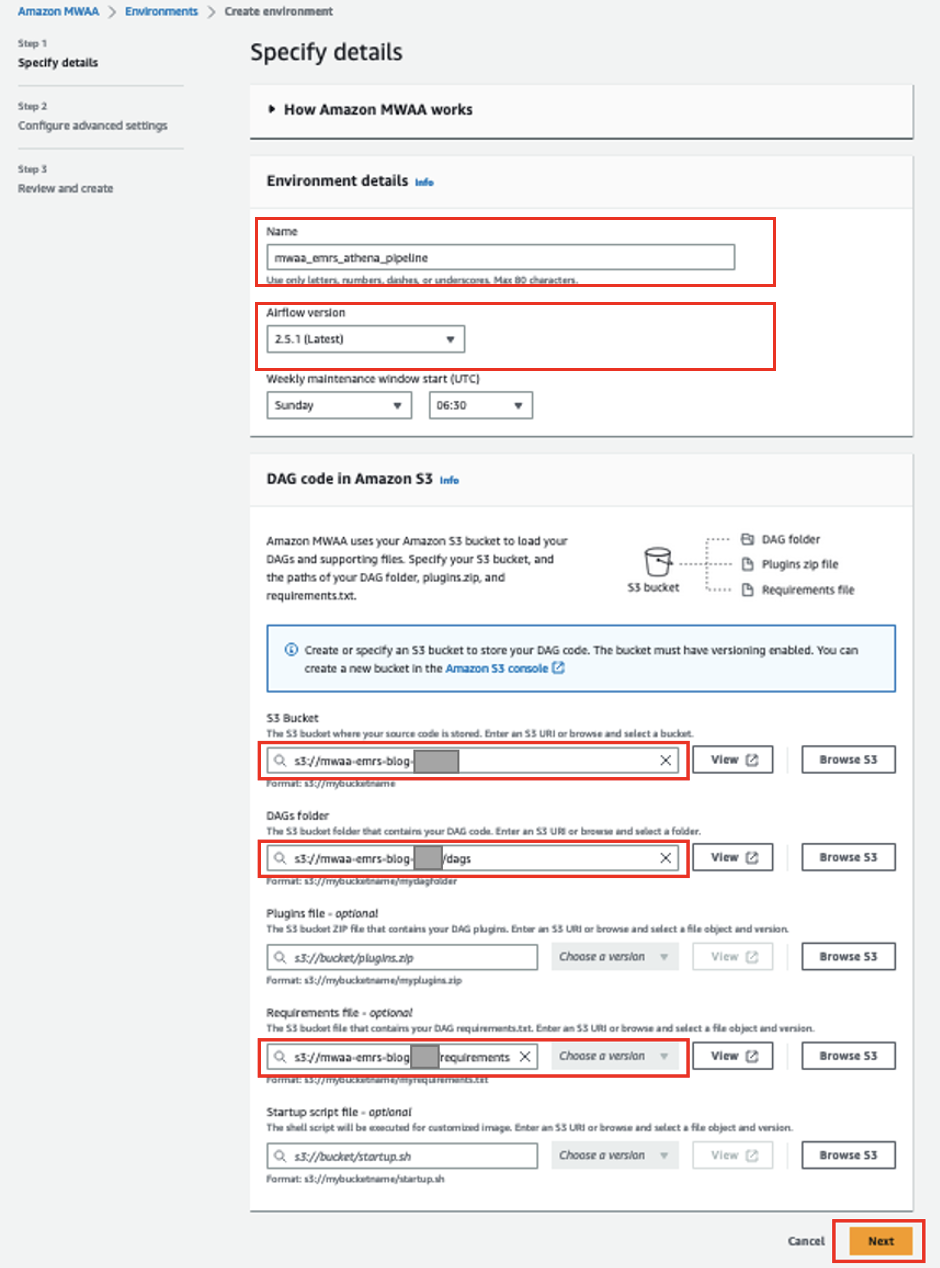
- Kies op de Amazon MWAA-console: Creëer omgeving.

- Voor Naam, ga naar binnen
mwaa_emrs_athena_pipeline. - Voor Luchtstroomversie, kies de nieuwste versie (voor dit bericht, 2.5.1).
- Voor S3-emmer, voer het pad naar uw S3-bucket in.
- Voor DAG's map, voer het pad in naar uw
dagsmap. - Voor Vereistenbestand, voer het pad in naar de
requirements.txtbestand. - Kies Volgende.
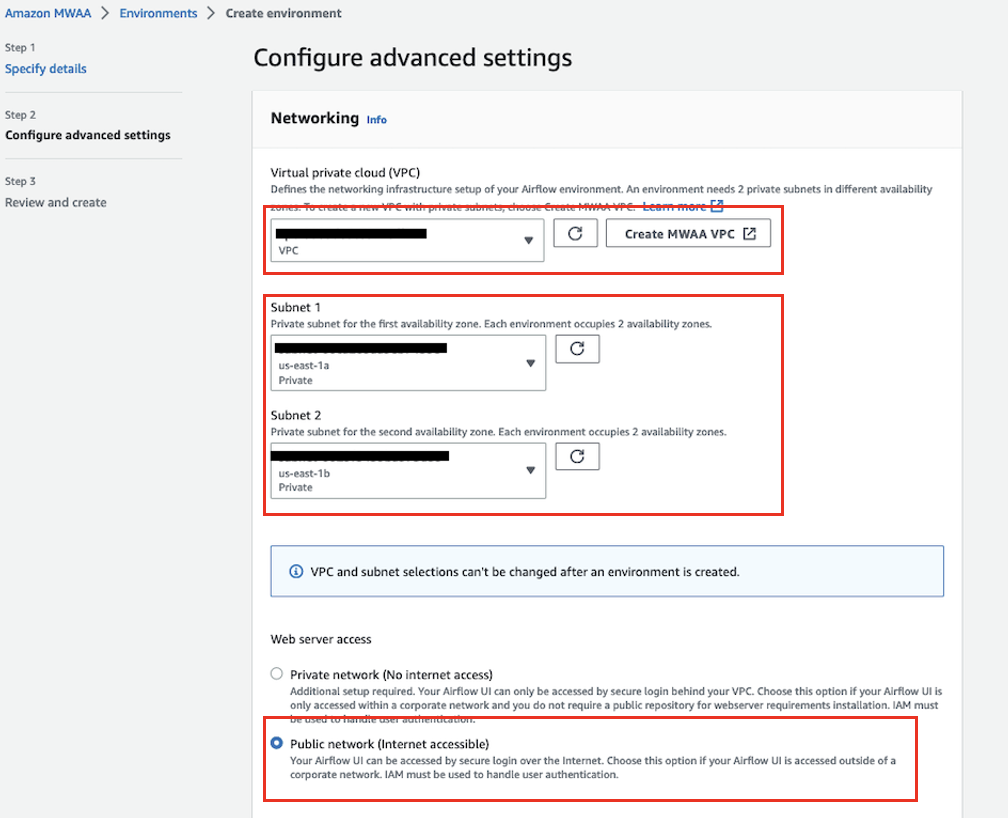
- Voor Virtuele privécloud (VPC)kiest u een VPC met minimaal twee privé-subnetten.
Hierdoor worden twee van de privé-subnetten in uw VPC gevuld.
- Onder Toegang tot webserverselecteer Openbaar netwerk.
Hierdoor is de gebruikersinterface van Apache Airflow via internet toegankelijk voor gebruikers die toegang hebben gekregen tot de IAM-beleid voor uw omgeving.
- Voor Beveiligingsgroep (en)selecteer Maak een nieuwe beveiligingsgroep.
- Voor Omgeving klasseselecteer mw1.klein.
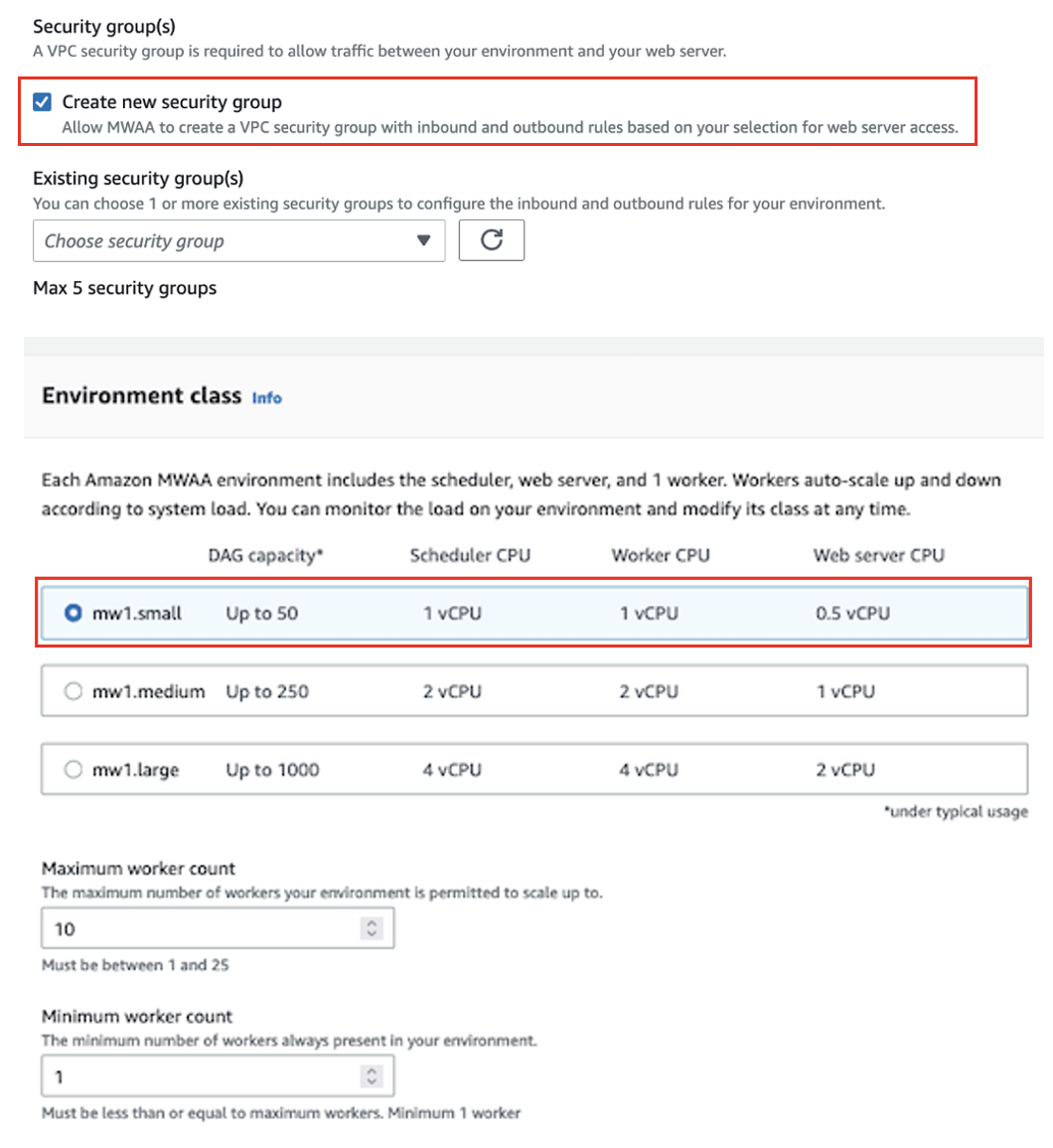
- Voor Uitvoeringsrol, kiezen Maak een nieuwe rol.
- Voor Rol naam, voer een naam in.
- Laat de overige configuraties standaard staan en kies Volgende.

- Kies op de volgende pagina creëren milieu.
Het kan ongeveer 20 tot 30 minuten duren om uw Amazon MWAA-omgeving te maken.
- Wanneer de Amazon MWAA-omgevingsstatus verandert in Beschikbaar, navigeer naar de IAM-console en update de clusteruitvoeringsrol om toe te voegen rolrechten doorgeven naar
emr_serverless_execution_role.
Activeer de Amazon MWAA DAG
Voer de volgende stappen uit om de DAG te activeren:
- Kies op de Amazon MWAA-console: omgevingen in het navigatievenster.
- Open uw omgeving en kies Open de luchtstroom-UI.
- kies
blog_dag_mwaa_emr_ny_taxi, kies het afspeelpictogram en kies Activeer DAG.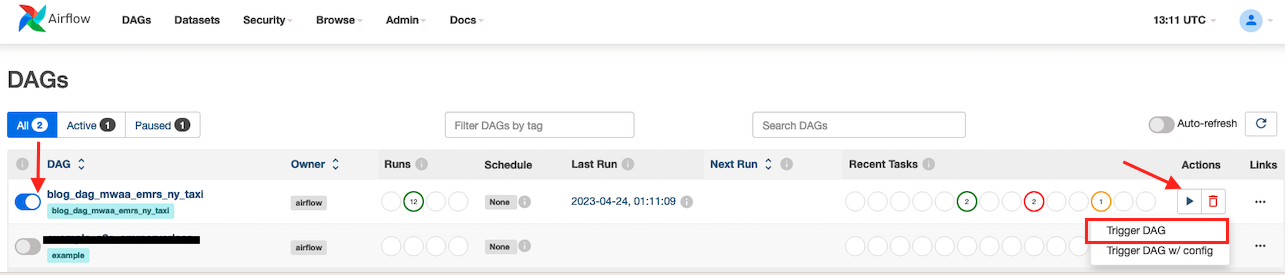
- Wanneer de DAG actief is, kiest u de DAG
blog_dag_mwaa_emrs_ny_taxiEn kies Diagram om uw DAG-runworkflow te vinden.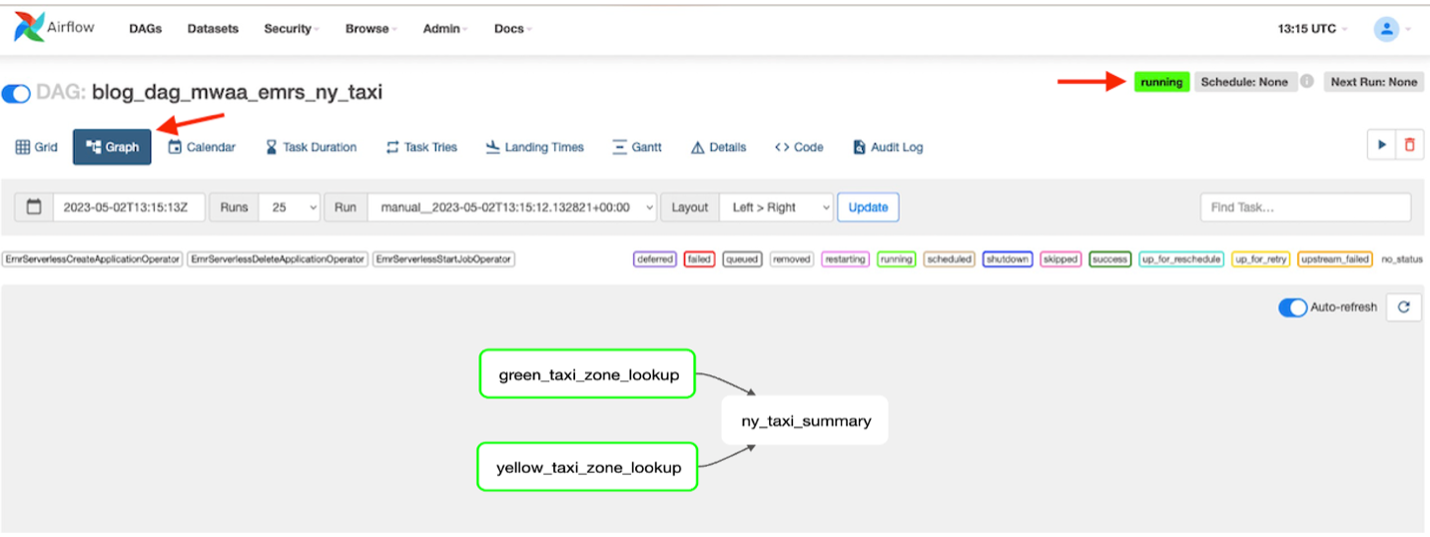
Het duurt ongeveer 4 tot 6 minuten voordat de DAG alle scripts uitvoert. Je ziet alle volledige taken en de algemene status van de DAG wordt weergegeven als succes.

Om de DAG opnieuw uit te voeren, verwijdert u deze s3://<<your_s3_bucket here >>/output_data/.
Om te begrijpen hoe Amazon MWAA deze taken uitvoert, kiest u eventueel de taak die u wilt inspecteren.

Kies lopen om de details van de taakuitvoering te bekijken.
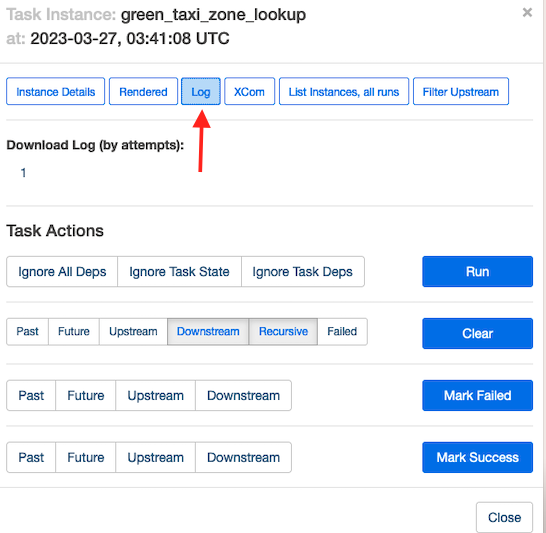
De volgende schermafbeelding toont een voorbeeld van de taaklogboeken.
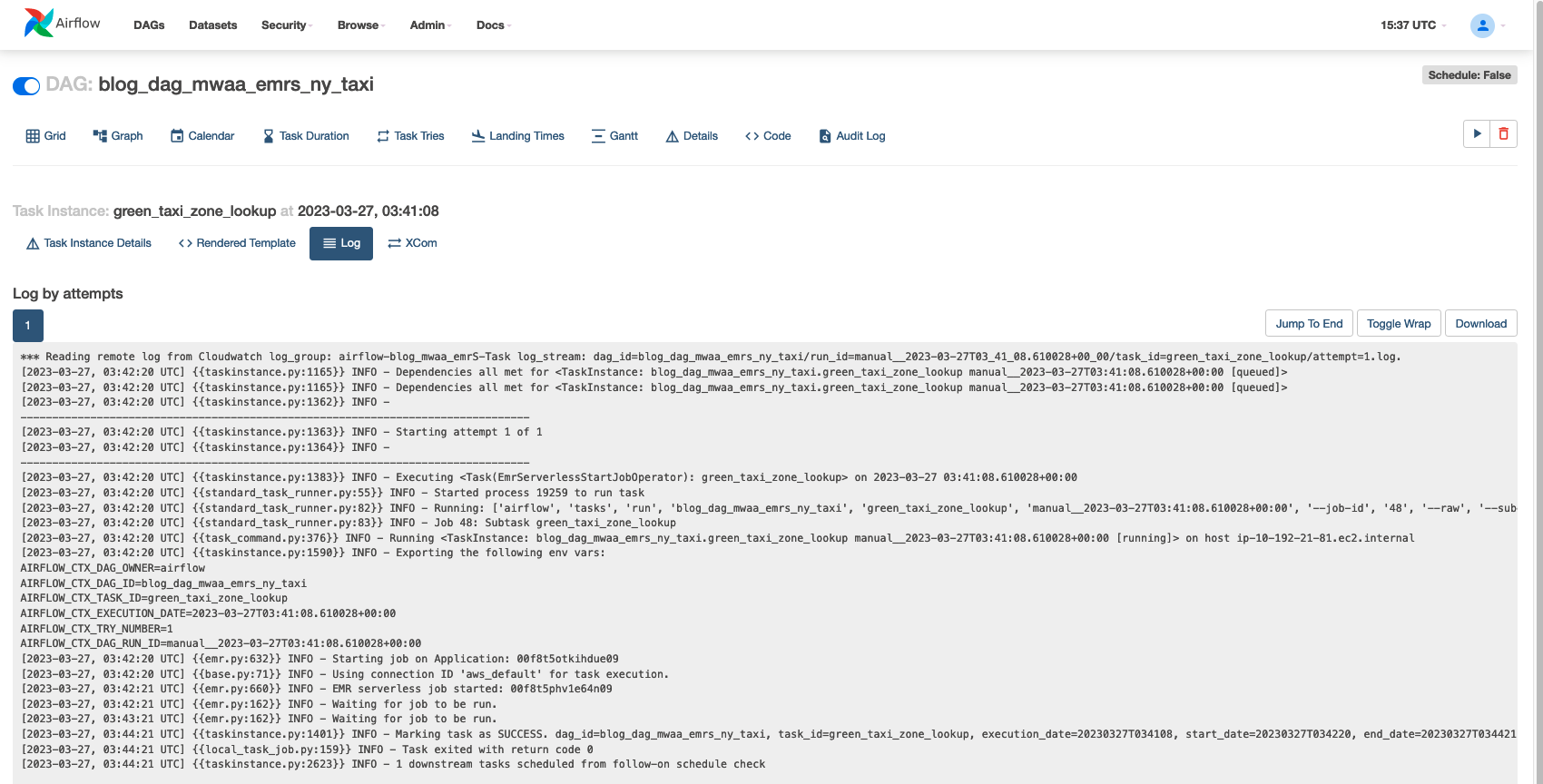
Als u graag diep in de uitvoeringslogboeken duikt, navigeert u op de EMR Serverless-console naar "Toepassingen". De Apache Spark-stuurprogrammalogboeken geven de start van uw taak aan, samen met de details voor uitvoerders, fasen en taken die zijn gemaakt door EMR Serverless. Deze logboeken kunnen nuttig zijn om de voortgang van uw taak te controleren en fouten op te lossen.
Standaard bewaart EMR Serverless applicatielogboeken veilig in de door Amazon EMR beheerde opslag gedurende een periode van 30 dagen. U kunt echter ook specificeren Amazon S3 of Amazon CloudWatch als uw opties voor het leveren van logboeken tijdens het indienen van opdrachten.

Valideer de eindresultaatset met Athena
Laten we de gegevens valideren die door het proces zijn geladen met behulp van Athena SQL-query's.
- Kies op de Athena-console Query-editor in het navigatievenster.
- Als je Athena voor het eerst gebruikt, onder Instellingen, kiezen Beheren en voer de S3-bucketlocatie in die u eerder hebt gemaakt (
<S3_BUCKET_NAME>/athena), kies dan Bespaar.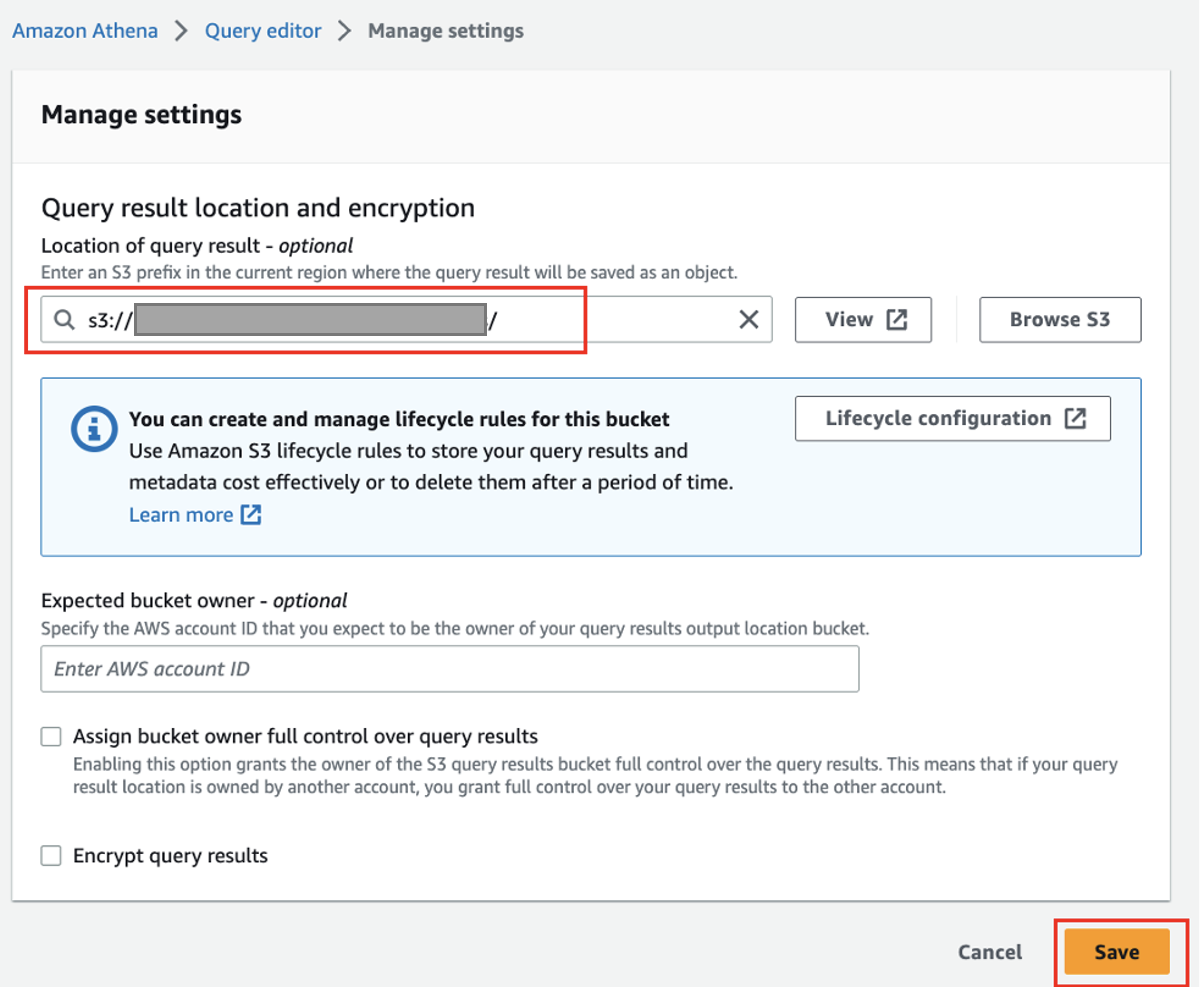
- Voer in de query-editor de volgende query in om een externe tabel te maken:

Voer de volgende query uit op het onlangs gemaakte ny_taxi_summary tabel om de eerste 10 rijen op te halen om de gegevens te valideren:

Opruimen
Voer de volgende stappen uit om toekomstige kosten te voorkomen:
- Verwijder op de Amazon S3-console de S3-bucket die u hebt gemaakt om de Amazon MWAA DAG, scripts en logboeken op te slaan.
- Plaats de tabel die u hebt gemaakt op de Athena-console:
- Navigeer op de Amazon MWAA-console naar de omgeving die u hebt gemaakt en kies Verwijder.

- Verwijder de applicatie op de EMR Studio-console.
Om de applicatie te verwijderen, navigeert u naar de Lijst toepassingen bladzijde. Selecteer de applicatie die u hebt gemaakt en kies Acties → Stoppen om de toepassing te stoppen. Nadat de applicatie de status GESTOPT heeft, selecteert u dezelfde applicatie en kiest u Acties → Verwijderen.

Conclusie
Data-engineering is een cruciaal onderdeel van veel organisaties, en omdat de datavolumes blijven groeien, is het essentieel om manieren te vinden om de dataverwerkingsworkflows te stroomlijnen. De combinatie van Amazon MWAA, EMR Serverless en Athena biedt een krachtige oplossing om datapijplijnen efficiënt te bouwen, uit te voeren en te beheren. Met deze end-to-end pijplijn voor gegevensverwerking kunnen data-ingenieurs grote hoeveelheden gegevens eenvoudig, snel en kosteneffectief verwerken en analyseren zonder de noodzaak om een complexe infrastructuur te beheren. De integratie van deze AWS-diensten biedt een robuuste en schaalbare oplossing voor dataverwerking, waardoor organisaties weloverwogen beslissingen kunnen nemen op basis van hun data-inzichten.
Nu je hebt gezien hoe je Spark-taken kunt indienen op EMR Serverless via Amazon MWAA, raden we je aan om Amazon MWAA te gebruiken om een workflow te creëren die PySpark-taken uitvoert via EMR Serverless.
Wij zijn blij met uw feedback en vragen. Neem gerust contact met ons op als u vragen of opmerkingen heeft.
Over de auteurs
 Rahul Sonawane is een Principal Analytics Solutions Architect bij AWS met AI/ML en Analytics als zijn specialiteit.
Rahul Sonawane is een Principal Analytics Solutions Architect bij AWS met AI/ML en Analytics als zijn specialiteit.
 Gaurav Parekh is een Solutions Architect die AWS-klanten helpt bij het bouwen van grootschalige moderne architectuur. Hij is gespecialiseerd in data-analyse en netwerken. Buiten zijn werk speelt Gaurav graag cricket, voetbal en volleybal.
Gaurav Parekh is een Solutions Architect die AWS-klanten helpt bij het bouwen van grootschalige moderne architectuur. Hij is gespecialiseerd in data-analyse en netwerken. Buiten zijn werk speelt Gaurav graag cricket, voetbal en volleybal.
Auditgeschiedenis
December 2023: Dit bericht is beoordeeld op technische nauwkeurigheid door Santosh Gantaram, Sr. Technical Account Manager.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/orchestrate-amazon-emr-serverless-spark-jobs-with-amazon-mwaa-and-data-validation-using-amazon-athena/
- : heeft
- :is
- :niet
- $UP
- 1
- 10
- 100
- 118
- 15%
- 16
- 2022
- 2023
- 23
- 25
- 30
- 300
- 7
- 700
- 8
- 9
- 990
- a
- Over
- Accepteert
- toegang
- geraadpleegde
- Account
- nauwkeurigheid
- toevoegen
- Na
- aggregaat
- AI / ML
- Alles
- toestaat
- langs
- al
- ook
- Amazone
- Amazone Athene
- Amazon EMR
- Amazon Web Services
- bedragen
- hoeveelheden
- an
- analytics
- analyseren
- en
- elke
- apache
- Apache Spark
- Aanvraag
- toepassingen
- ongeveer
- architectuur
- ZIJN
- GEBIED
- argument
- AS
- At
- webmaster.
- Beschikbaar
- AWS
- terug
- baseren
- gebaseerde
- BE
- worden
- wordt
- tussen
- Groot
- Big data
- bouw
- Gebouw
- bebouwd
- ondernemingen
- by
- berekent
- CAN
- catalogus
- verandering
- Wijzigingen
- lasten
- Kies
- classificatie
- Cloud
- TROS
- code
- combinatie van
- combineren
- komt
- opmerkingen
- compleet
- complex
- bestanddeel
- bestaat uit
- troosten
- voortzetten
- Overeenkomend
- Kosten
- kostenefficient
- Kosten
- en je merk te creëren
- aangemaakt
- creëert
- krekel
- kritisch
- Klanten
- DAG
- gegevens
- gegevens Analytics
- gegevensverwerking
- datasets
- Data
- dagen
- beslissingen
- deep
- Standaard
- definitie
- levering
- afhankelijkheden
- Afhankelijkheid
- gegevens
- afstand
- distributie
- duiken
- do
- Dont
- verdubbelen
- beneden
- Download
- bestuurder
- Val
- gedurende
- e
- elk
- Vroeger
- gemakkelijk
- En het is heel gemakkelijk
- editor
- doeltreffendheid
- doeltreffend
- efficiënt
- aanmoedigen
- eind tot eind
- Engineering
- Ingenieurs
- verzekeren
- Enter
- Milieu
- essentieel
- Ether (ETH)
- voorbeeld
- uitvoering
- extern
- extra
- mislukkingen
- Kenmerk
- feedback
- voelen
- Dien in
- Bestanden
- finale
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- eerste keer
- Focus
- volgen
- volgend
- Voor
- formaat
- FRAME
- frameworks
- Gratis
- oppompen van
- geheel
- toekomst
- voortbrengen
- genereert
- het genereren van
- verleend
- Groen
- Groeien
- Groeit
- Hadoop
- handvat
- Hebben
- he
- hulp
- nuttig
- het helpen van
- hier
- zijn
- Bijenkorf
- Hoe
- How To
- Echter
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- Idle
- ids
- if
- illustreren
- illustreert
- in
- omvatten
- inclusief
- omvat
- in toenemende mate
- aangeven
- informatie
- op de hoogte
- Infrastructuur
- ingewijden
- inwijding
- invoer
- vragen
- binnen
- inzichten
- installeren
- verkrijgen in plaats daarvan
- instructies
- integratie
- interactie
- interactieve
- Internet
- betrekken
- IT
- Jobomschrijving:
- Vacatures
- mee
- aansluiting
- Sluit zich aan bij
- jpg
- voor slechts
- Groot
- tot slot
- later
- laatste
- als
- LIMIT
- Lijn
- lijnen
- lokaal
- plaats
- locaties
- inloggen
- lang
- op zoek
- lookup
- machine
- maken
- MERKEN
- maken
- beheer
- beheerd
- manager
- beheren
- veel
- Mei..
- Metadata
- minimum
- minuten
- Modern
- wijzigen
- monitor
- meer
- naam
- Genoemd
- OP DEZE WEBSITE VIND JE
- Navigatie
- Noodzaak
- nodig
- netwerken
- New
- volgende
- Geen
- nu
- NYC
- of
- korting
- on
- eens
- EEN
- Slechts
- open
- open source
- operatie
- exploitanten
- Opties
- or
- organisaties
- Overige
- onze
- uit
- outlines
- uitgang
- buiten
- over
- totaal
- pakket
- pagina
- brood
- deel
- pad
- betaling
- presteert
- periode
- pijpleiding
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- Spelen
- spelen
- dan
- beleidsmaatregelen
- mogelijk
- Post
- krachtige
- vereisten
- voorkomen
- Principal
- privaat
- processen
- verwerking
- Voortgang
- leverancier
- biedt
- het verstrekken van
- in het openbaar
- Python
- queries
- Contact
- snel
- bereiken
- onlangs
- archief
- verminderen
- betrouwbaar
- verwijderen
- vereisen
- vereist
- Resources
- resultaat
- verkregen
- beoordeeld
- Rijden
- ritten
- robuust
- Rol
- RIJ
- lopen
- lopend
- loopt
- s
- dezelfde
- schaalbare
- Scale
- balans
- scaling
- rooster
- script
- scripts
- sectie
- vast
- veiligheid
- zien
- gezien
- kiezen
- apart
- server
- Serverless
- service
- Diensten
- Sessie
- reeks
- het instellen van
- moet
- tonen
- Shows
- Eenvoudig
- vereenvoudigen
- So
- Voetbal
- oplossing
- Oplossingen
- bron
- Vonk
- specialiseert
- Specialiteit
- gespecificeerd
- SQL
- stadia
- standaard
- Land
- statistiek
- Status
- Stappen
- stop
- gestopt
- mediaopslag
- shop
- opgeslagen
- gestroomlijnd
- Draad
- studio
- voorlegging
- voorleggen
- subnetten
- dergelijk
- OVERZICHT
- Ondersteuning
- tafel
- Nemen
- Taak
- taken
- Technisch
- tijdelijk
- Testen
- dat
- De
- hun
- Ze
- harte
- Deze
- dit
- drie
- niet de tijd of
- keer
- naar
- vandaag
- Transformeren
- Transformatie
- getransformeerd
- leiden
- reis
- BEURT
- twee
- types
- ui
- voor
- begrijpen
- anders
- bijwerken
- bijgewerkt
- us
- .
- gebruikers
- toepassingen
- gebruik
- maakt gebruik van
- BEVESTIG
- bevestiging
- versie
- via
- Bekijk
- .
- volume
- volumes
- willen
- was
- manieren
- we
- web
- webservices
- welkom
- waren
- wanneer
- welke
- wil
- Met
- zonder
- Mijn werk
- workflow
- workflows
- zorgen
- zorgen te maken
- schrijven
- geel
- u
- Your
- zephyrnet
- zones