AWS Lijm Studio is nu geïntegreerd met AWS lijm DataBrew. AWS Glue Studio is een grafische interface die het gemakkelijk maakt om ETL-taken (extraheren, transformeren en laden) te maken, uit te voeren en te controleren in AWS lijm. DataBrew is een hulpmiddel voor visuele gegevensvoorbereiding waarmee u gegevens kunt opschonen en normaliseren zonder code te hoeven schrijven. De meer dan 200 transformaties die het biedt, zijn nu beschikbaar voor gebruik in een visuele taak van AWS Glue Studio.
In DataBrew, een recept is een reeks gegevenstransformatiestappen die u interactief kunt schrijven in de intuïtieve visuele interface. In dit bericht zie je hoe je een recept bouwt in DataBrew en het vervolgens toepast als onderdeel van een visuele ETL-taak van AWS Glue Studio.
Bestaande DataBrew-gebruikers zullen ook profiteren van deze integratie: u kunt nu uw recepten uitvoeren als onderdeel van een grotere visuele workflow met alle andere componenten die AWS Glue Studio biedt, naast het gebruik van geavanceerde taakconfiguratie en de nieuwste versie van de AWS Glue-engine .
Deze integratie biedt duidelijke voordelen voor de bestaande gebruikers van beide tools:
- Je hebt een gecentraliseerd beeld in AWS Glue Studio van het algehele ETL-diagram, end-to-end
- U kunt interactief een recept definiëren, waarden, statistieken en distributie bekijken op de DataBrew-console, en vervolgens die geteste en geversieerde verwerkingslogica hergebruiken in visuele taken van AWS Glue Studio
- U kunt meerdere DataBrew-recepten orkestreren in een AWS Glue ETL-taak of zelfs meerdere taken met behulp van AWS Glue-workflows
- DataBrew-recepten kunnen nu AWS Glue-taakfuncties gebruiken, zoals bladwijzers voor incrementele gegevensverwerking, automatisch opnieuw proberen, automatisch schalen of het groeperen van kleine bestanden voor meer efficiëntie
Overzicht oplossingen
In onze fictieve use-case is de vereiste het opschonen van een synthetische dataset voor medische claims die voor dit bericht is gemaakt en waarin met opzet enkele problemen met de gegevenskwaliteit zijn geïntroduceerd om de DataBrew-mogelijkheden voor gegevensvoorbereiding te demonstreren. Vervolgens worden de claimgegevens opgenomen in de catalogus (zodat deze zichtbaar is voor analisten), nadat deze is verrijkt met enkele relevante details over de overeenkomstige medische zorgverleners die uit een aparte bron komen.
De oplossing bestaat uit een visuele taak van AWS Glue Studio die twee CSV-bestanden leest met respectievelijk claims en providers. De taak past een recept van de eerste toe om de kwaliteitsproblemen aan te pakken, selecteert kolommen uit de tweede, voegt beide datasets samen en slaat ten slotte het resultaat op Amazon eenvoudige opslagservice (Amazon S3), een tabel in de catalogus maken zodat de uitvoergegevens kunnen worden gebruikt door andere tools zoals Amazone Athene.
Maak een DataBrew-recept
Begin met het registreren van het gegevensarchief voor het claimbestand. Hierdoor kunt u het recept in de interactieve editor bouwen met behulp van de daadwerkelijke gegevens, zodat u het resultaat van de transformaties kunt evalueren terwijl u ze definieert.
- Download het CSV-bestand met claims via de volgende link: alabama_claims_data_jun2023.csv.
- Kies op de DataBrew-console datasets in het navigatievenster en kies vervolgens Nieuwe dataset verbinden.
- Kies de optie Bestand upload.
- Voor Naam dataset, ga naar binnen
Alabama claims. - Voor Selecteer een bestand om te uploaden, kies het bestand dat u zojuist op uw computer hebt gedownload.
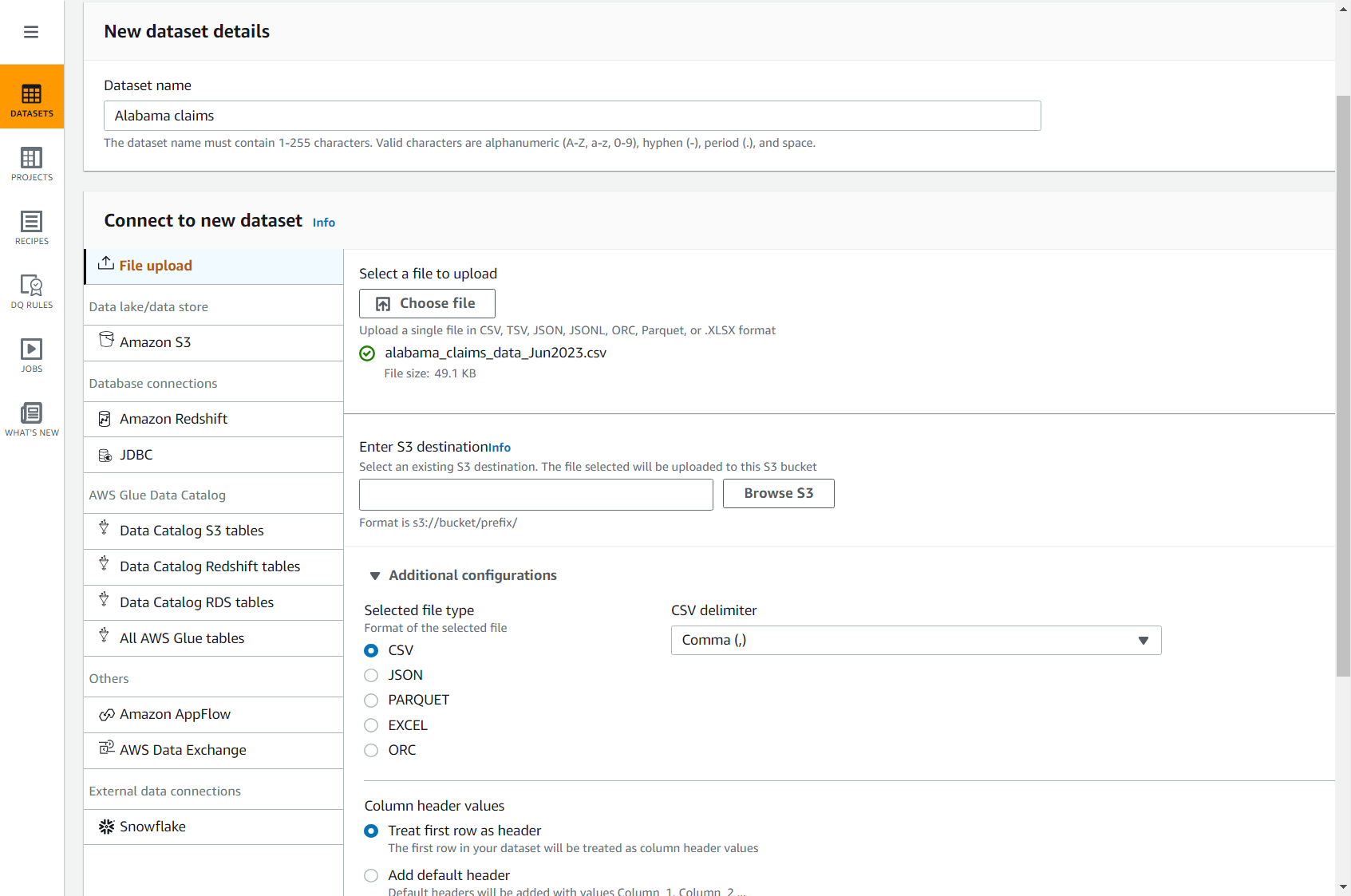
- Voor Voer S3-bestemming in, typ of blader naar een bucket in uw account en regio.
- Laat de rest van de opties standaard staan (CSV gescheiden door komma's en met koptekst) en voltooi het maken van de dataset.
- Kies Project in het navigatievenster en kies vervolgens Maak een project aan.
- Voor Naam van het project, Noem maar op
ClaimsCleanup. - Onder Recept detailsvoor Bijgevoegd recept, kiezen Nieuw recept maken, Noem maar op
ClaimsCleanup-recipeen kies hetAlabama claimsgegevensset die u zojuist hebt gemaakt.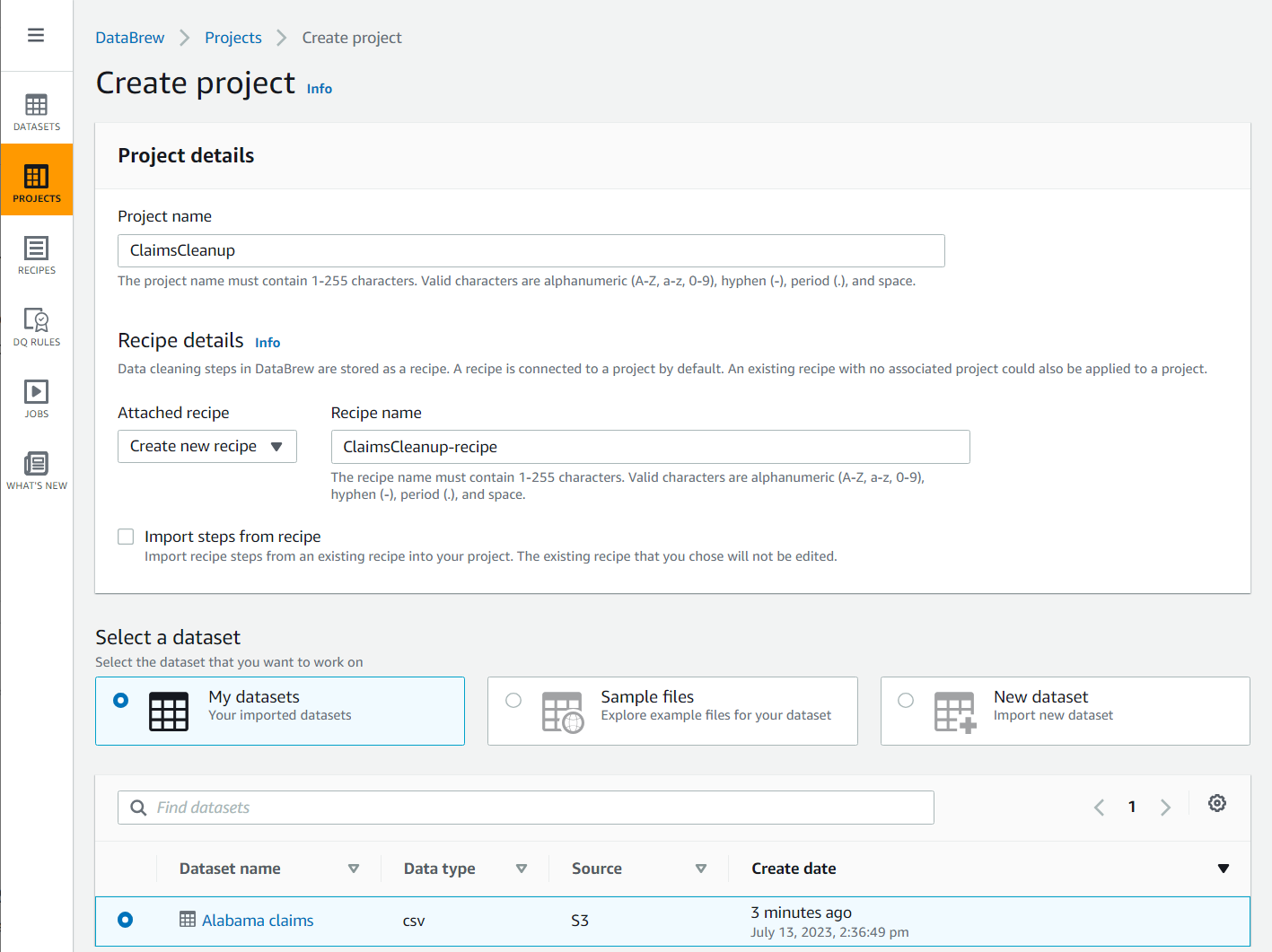
- Selecteer een rol geschikt voor DataBrew of maak een nieuwe aan en voltooi de creatie van het project.
Hiermee wordt een sessie gemaakt met behulp van een configureerbare subset van de gegevens. Nadat de sessie is geïnitialiseerd, kunt u zien dat sommige cellen ongeldige of ontbrekende waarden hebben.
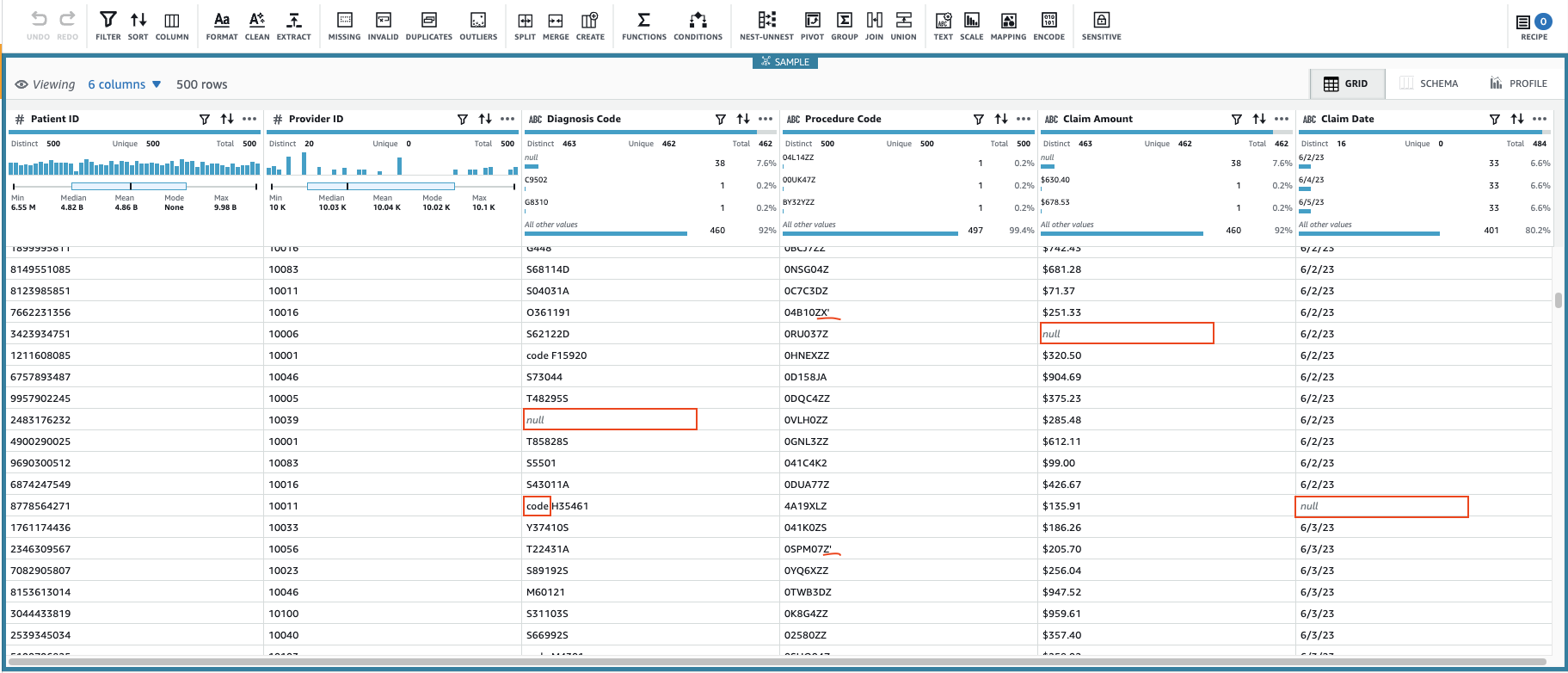
Naast de ontbrekende waarden in de kolommen Diagnosecode, Bedrag opeisen en Datum claimen, hebben sommige waarden in de gegevens enkele extra tekens: Diagnosecode waarden worden soms voorafgegaan door "code" (inclusief spatie), en Procedurecode waarden worden soms gevolgd door enkele aanhalingstekens.
Bedrag opeisen waarden zullen waarschijnlijk worden gebruikt voor sommige berekeningen, dus converteer naar getal, en Gegevens claimen moet worden geconverteerd naar datumtype.
Nu we de problemen met de gegevenskwaliteit hebben geïdentificeerd die moeten worden aangepakt, moeten we beslissen hoe we met elk geval moeten omgaan.
Er zijn meerdere manieren waarop u receptstappen kunt toevoegen, waaronder het contextmenu van de kolom, de werkbalk bovenaan of vanuit het receptoverzicht. Met behulp van de laatste methode kunt u zoeken naar het aangegeven staptype om het recept dat in dit bericht is gemaakt, te repliceren.
Bedrag opeisen is essentieel voor deze use case, en de beslissing is om dergelijke rijen te verwijderen.
- Voeg de stap toe Verwijder ontbrekende waarden.
- Voor Bron kolom, kiezen Bedrag opeisen.
- Laat de standaardactie staan Verwijder rijen met ontbrekende waarden En kies Solliciteer om het op te slaan.
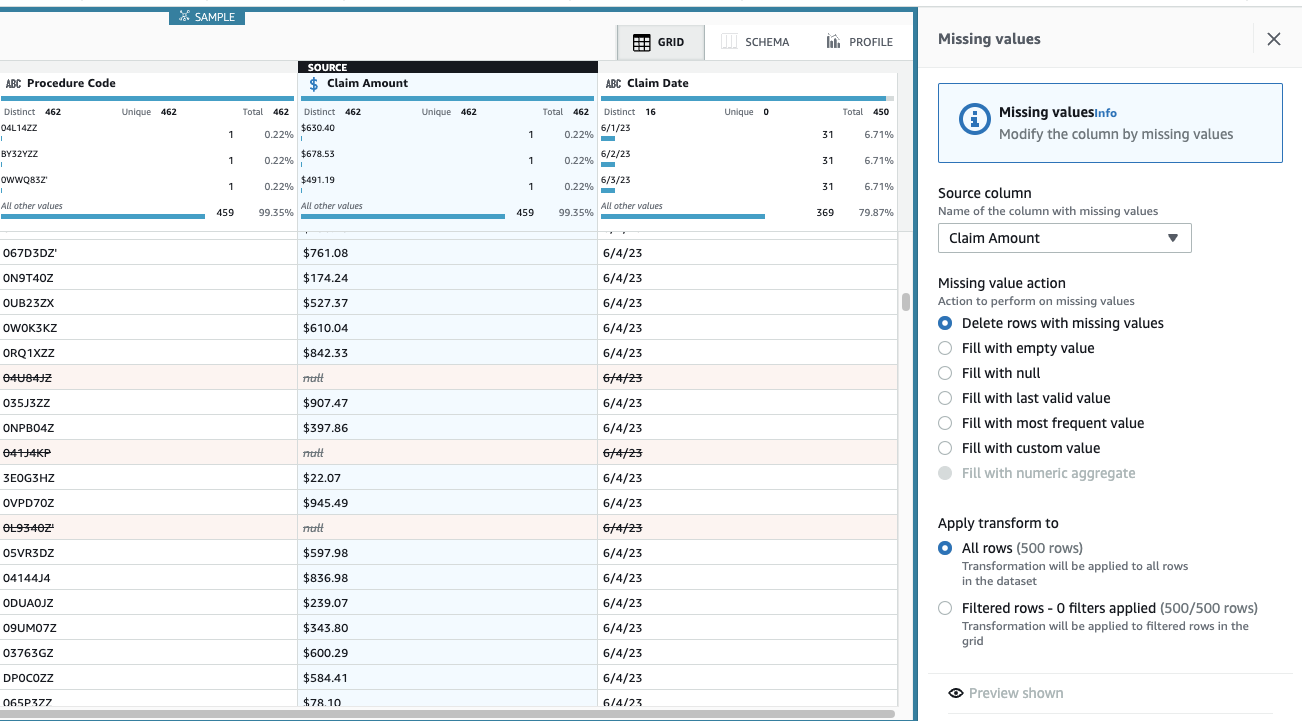
De weergave is nu bijgewerkt om de stappentoepassing weer te geven en de rijen met ontbrekende bedragen zijn er niet meer.
Diagnosecode kan leeg zijn, dus dit wordt geaccepteerd, maar in het geval van Datum claimen, willen we een redelijke schatting hebben. De rijen in de gegevens worden in chronologische volgorde gesorteerd, zodat u ontbrekende datums kunt toeschrijven met behulp van de geldige voorbeeldwaarde van de voorgaande rijen. Ervan uitgaande dat elke dag claims heeft, zou de grootste fout zijn om deze toe te wijzen aan de preview-dag als het de eerste claim die dag zou zijn zonder de datum; laten we ter illustratie die potentiële fout als acceptabel beschouwen.
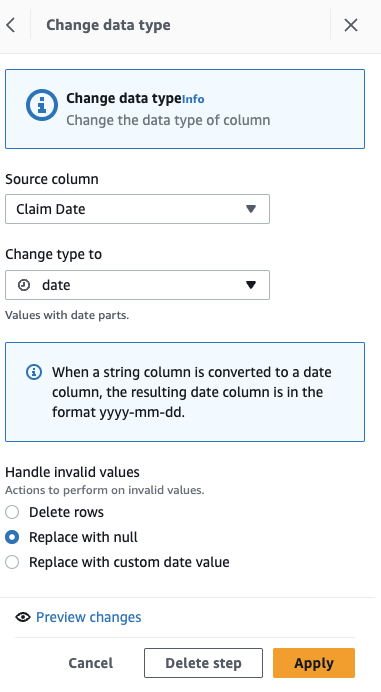
Converteer eerst de kolom van tekenreeks naar datumtype.
- Voeg de stap toe Van type veranderen.
- Kies Datum claimen als de kolom en gegevens als het type, kies dan Solliciteer.
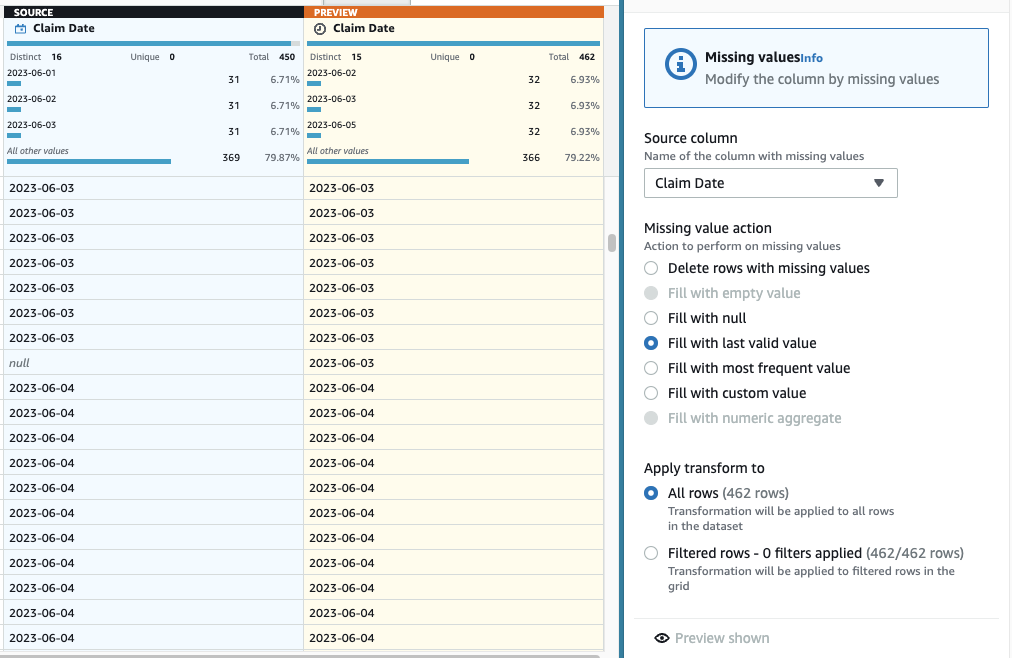
- Voeg nu de stap toe om de imputatie van ontbrekende datums uit te voeren Ontbrekende waarden aanvullen of toerekenen.
- Selecteer Vullen met laatste geldige waarde als actie en kies Datum claimen als de bron.
- Kies Voorbeeld van wijzigingen om het te valideren, kies dan Solliciteer om de stap op te slaan.
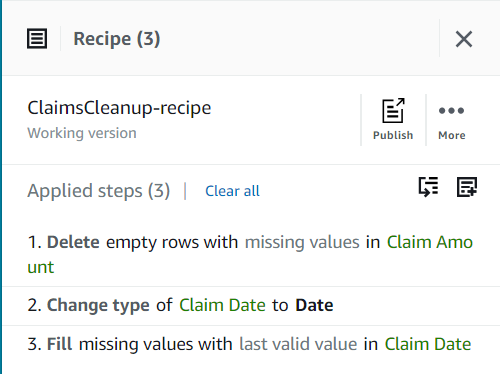
Tot nu toe zou je recept uit drie stappen moeten bestaan, zoals te zien is in de volgende schermafbeelding.
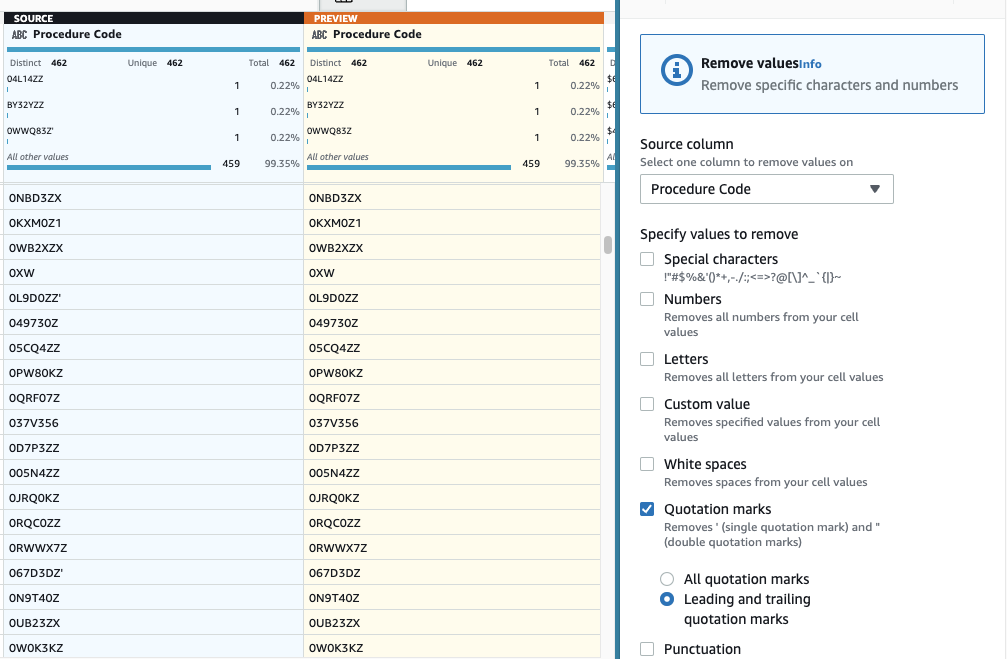
- Voeg vervolgens de stap toe Verwijder aanhalingstekens.
- Kies de Procedurecode kolom en selecteer Voorloop- en volgaanhalingstekens.
- Bekijk een voorbeeld om te controleren of het het gewenste effect heeft en pas de nieuwe stap toe.
- Voeg de stap toe Speciale tekens verwijderen.
- Kies de Bedrag opeisen kolom en selecteer om specifieker te zijn Aangepaste speciale tekens en ga naar binnen
$For Voer aangepaste speciale tekens in.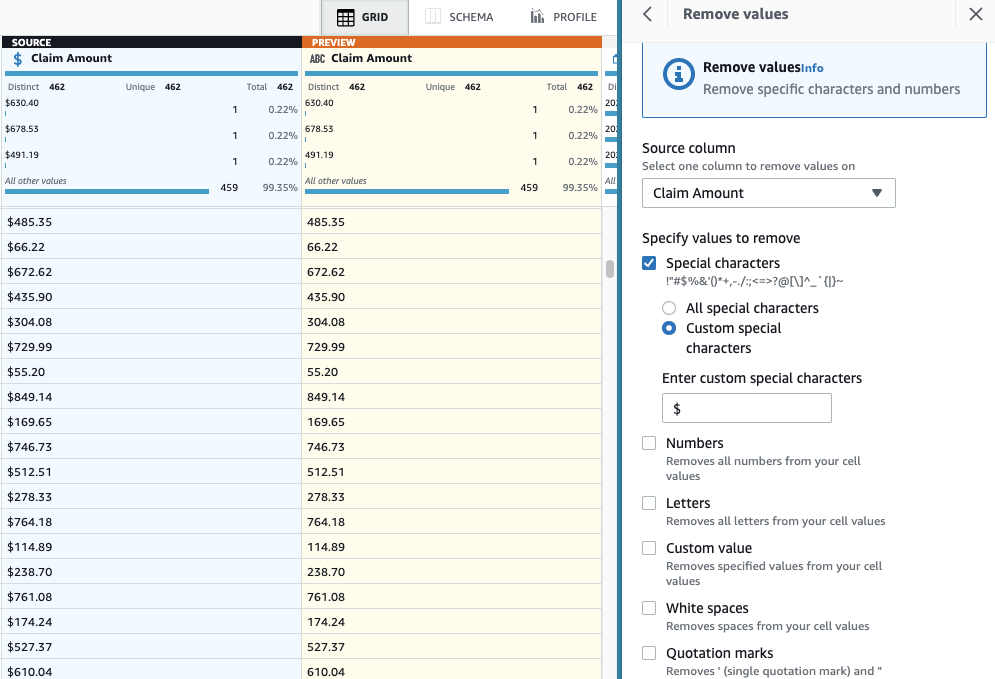
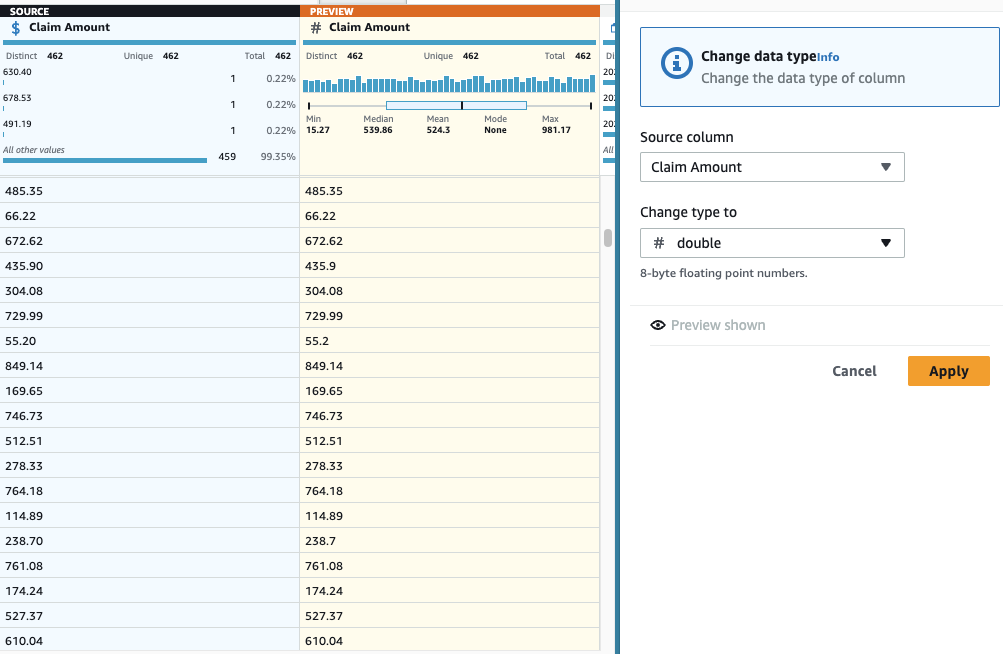
- Voeg een Van type veranderen stap op de kolom Bedrag opeisen En kies verdubbelen als de soort.
- Als laatste stap, om het overbodige "code"-voorvoegsel te verwijderen, voegt u een toe Vervang waarde of patroon stap.
- Kies de kolom DiagnosecodeEn voor Voer aangepaste waarde in, ga naar binnen
code(met een spatie aan het eind).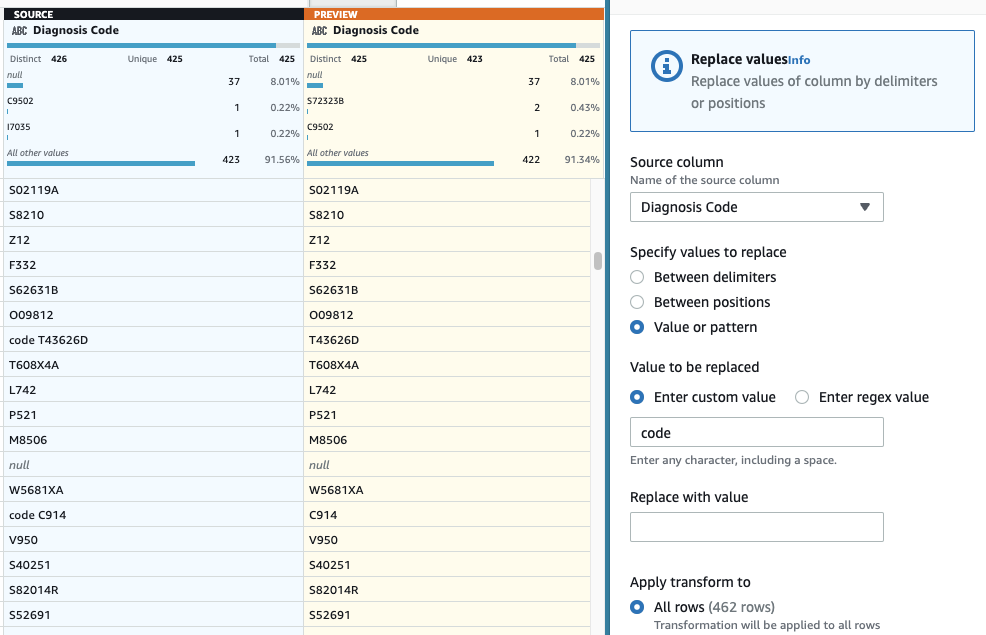
Nu u alle problemen met de gegevenskwaliteit die in het voorbeeld zijn geïdentificeerd, hebt opgelost, publiceert u het project als een recept.
- Kies Publiceer in de Recept deelvenster, voer een optionele beschrijving in en voltooi de publicatie.
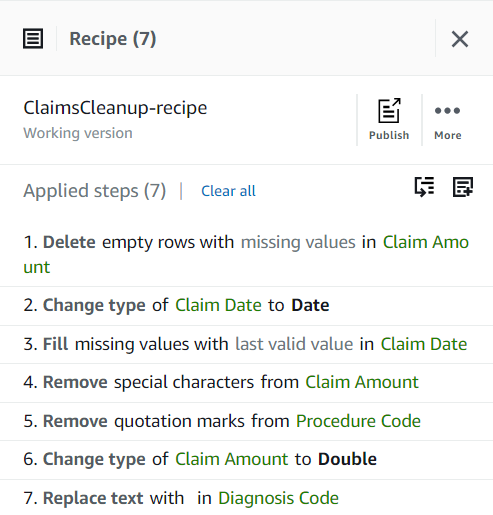
Elke keer dat u publiceert, wordt er een andere versie van het recept gemaakt. Later kunt u kiezen welke versie van het recept u wilt gebruiken.
Maak een visuele ETL-taak in AWS Glue Studio
Vervolgens maakt u de taak aan die het recept gebruikt. Voer de volgende stappen uit:
- Kies op de AWS Glue Studio-console: Visuele ETL in het navigatievenster.
- Kies Visueel met een leeg canvas en maak de visuele taak.
- Vervang bovenaan de vacature 'Naamloze vacature' door een naam naar keuze.
- Op de Job Details geeft u op het tabblad een rol op die de taak zal gebruiken.
Dit moet een AWS Identiteits- en toegangsbeheer (IAM) rol geschikt voor AWS Glue met machtigingen voor Amazon S3 en de AWS Glue Data Catalog. Houd er rekening mee dat de eerder gebruikte rol voor DataBrew niet bruikbaar is voor run jobs, dus zal niet worden vermeld op de IAM-rol vervolgkeuzemenu hier.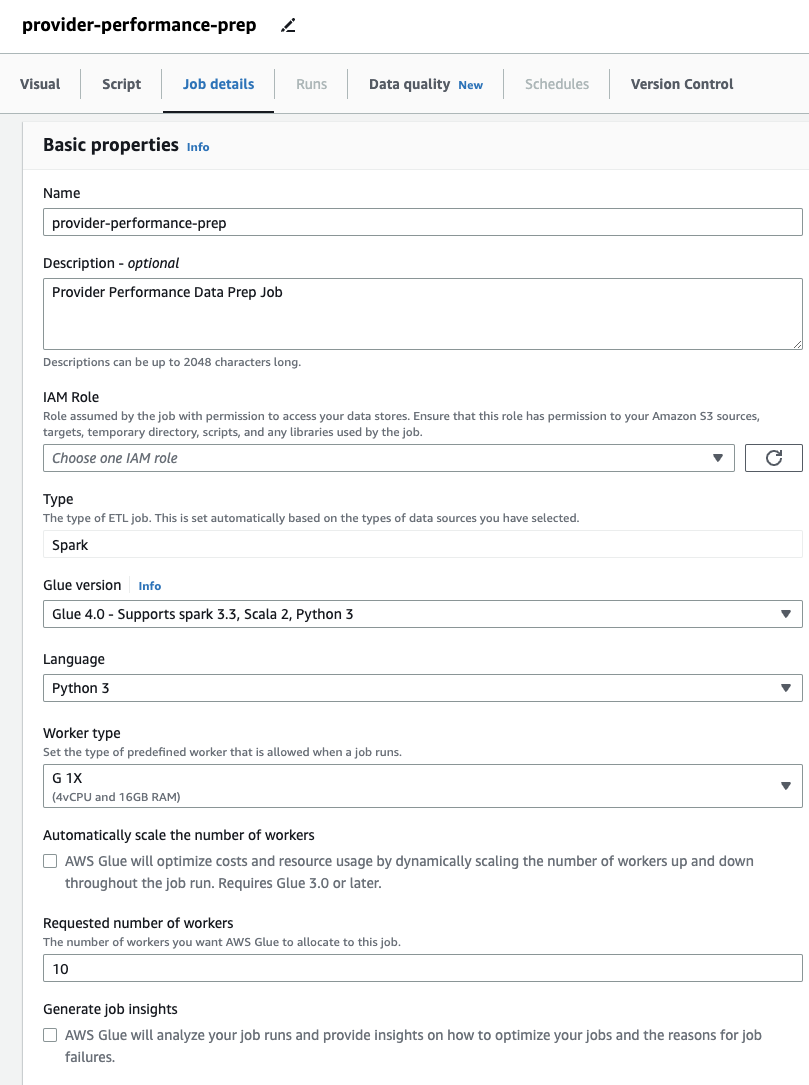
Als u voorheen alleen DataBrew-taken gebruikte, merk dan op dat u in AWS Glue Studio prestatie- en kosteninstellingen kunt kiezen, waaronder de grootte van de werknemer, automatisch schalen en Flexibele uitvoering, en gebruik de nieuwste AWS Glue 4.0-runtime en profiteer van de aanzienlijke prestatieverbeteringen die dit met zich meebrengt. Voor deze taak kunt u de standaardinstellingen gebruiken, maar het gevraagde aantal werknemers verminderen in het belang van zuinigheid. Voor dit voorbeeld zijn twee werknemers voldoende. - Op de Visual tabblad, voeg een S3-bron toe en geef deze een naam
Providers. - Voor S3-URL, ga naar binnen
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.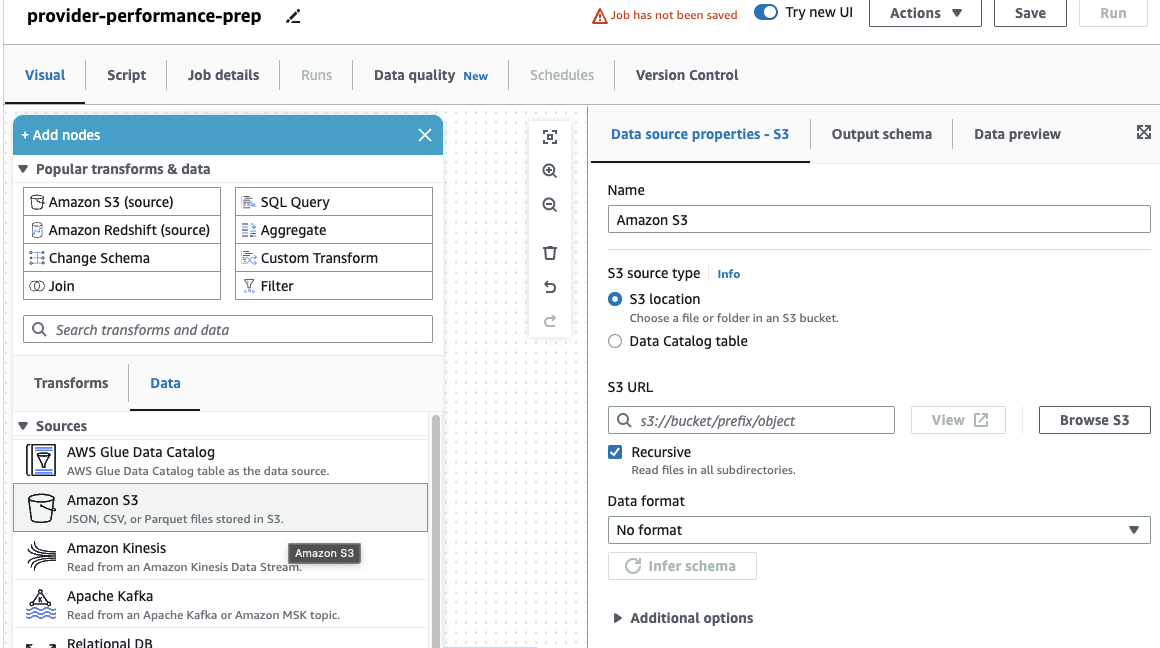
- Selecteer het formaat als CSV En kies Schema afleiden.
Nu staat het schema op de Uitvoerschema tabblad met behulp van de bestandskop.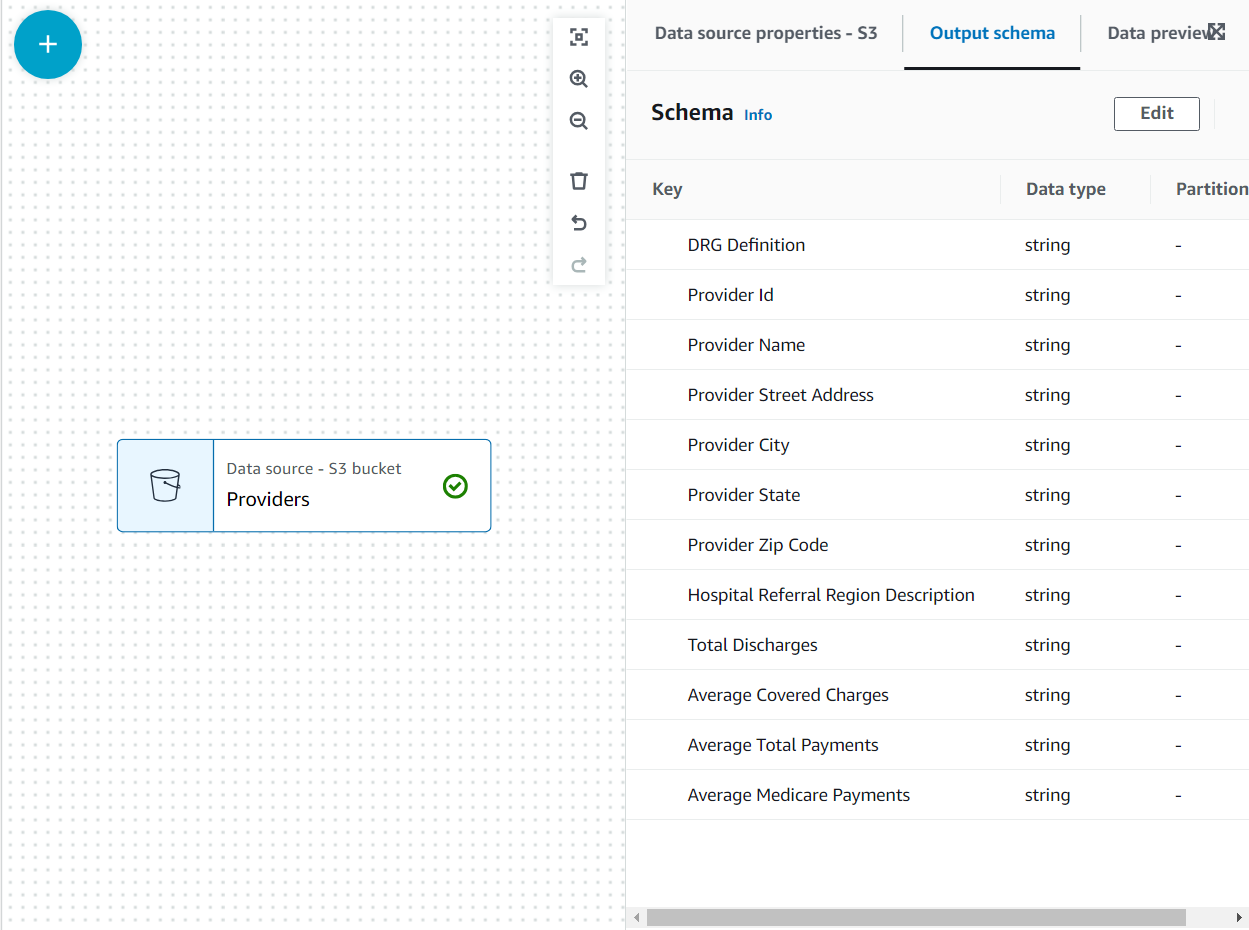
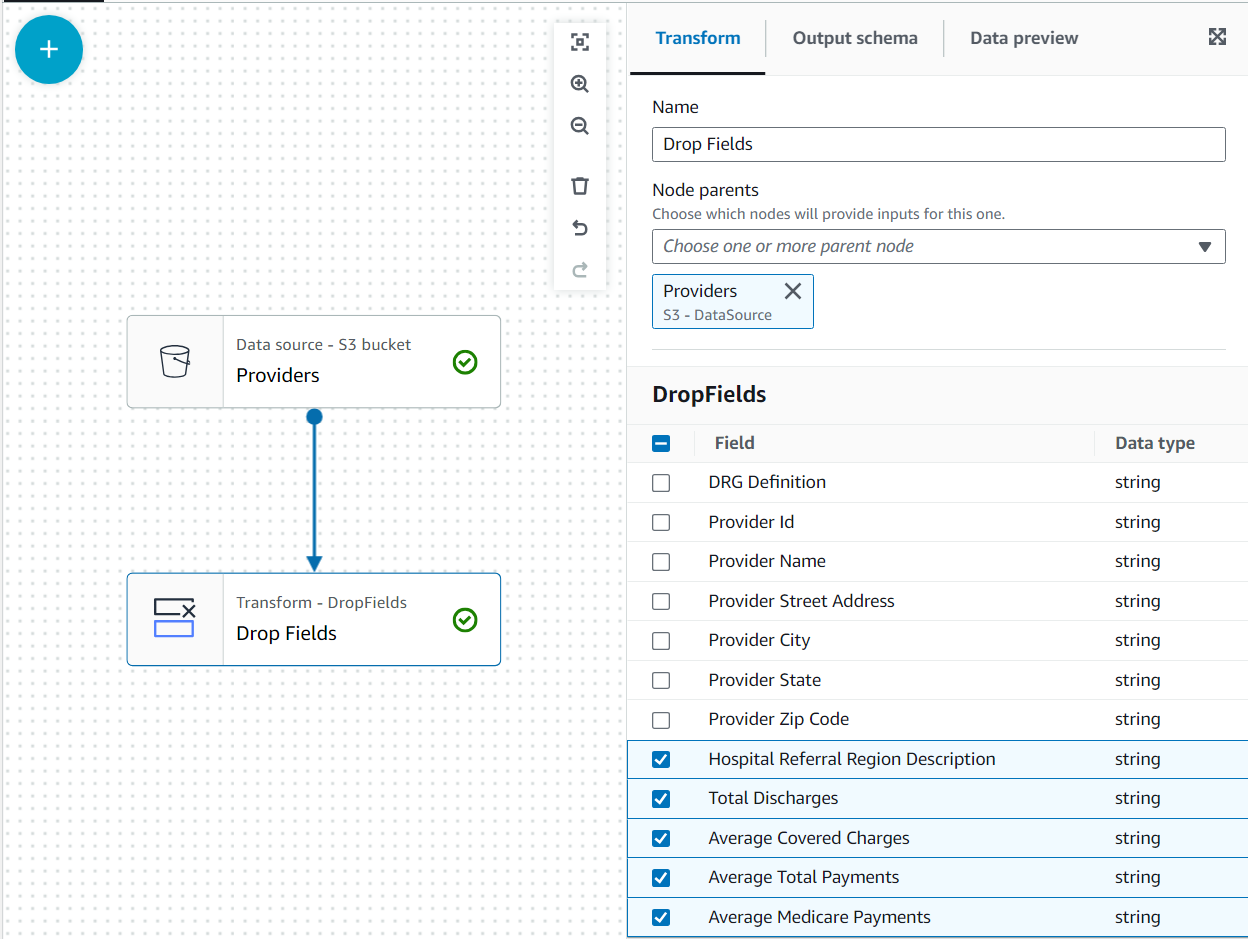
In deze use case is de beslissing dat niet alle kolommen in de dataset van de provider nodig zijn, dus kunnen we de rest weggooien.
- Met de Providers knooppunt geselecteerd, voeg een toe Velden laten vallen transformeren (als u het bovenliggende knooppunt niet hebt geselecteerd, heeft het er geen; wijs in dat geval het bovenliggende knooppunt handmatig toe).
- Selecteer daarna alle velden Postcode provider.
Later zullen deze gegevens worden vergezeld door de claims voor de staat Alabama met behulp van de provider; die tweede dataset heeft echter niet de opgegeven status. We kunnen kennis van de data gebruiken om de join te optimaliseren door de data te filteren die we echt nodig hebben.
- Voeg een FILTER transformeren als een kind van Velden laten vallen.
- Noem maar op
Alabama providersen voeg een voorwaarde toe waaraan de status moet voldoenAL.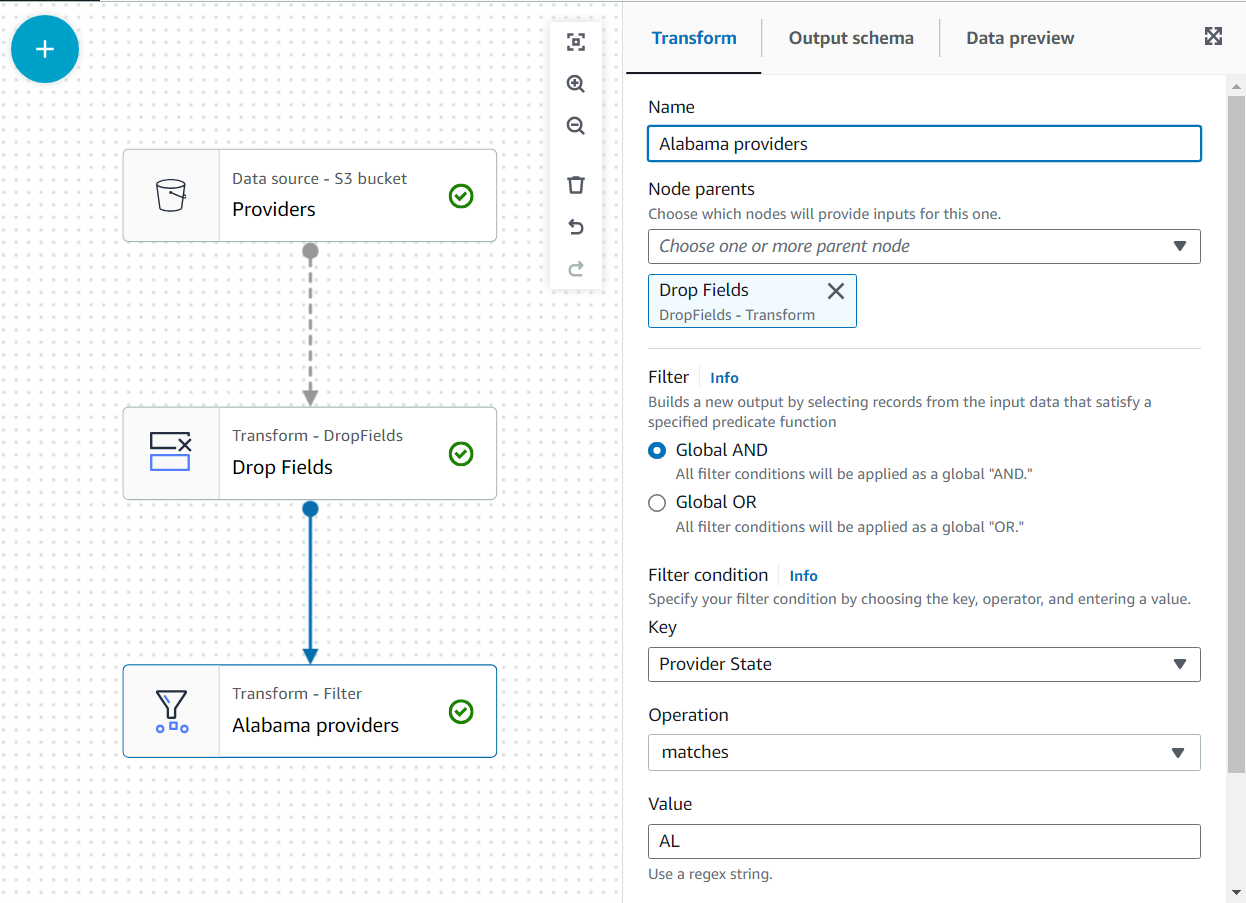
- Voeg de tweede bron toe (een nieuwe S3-bron) en geef deze een naam
Alabama claims. - Om de S3-URL, open DataBrew op een apart browsertabblad, kies Datasets in het navigatievenster en kopieer op de tabel de locatie die op de tabel wordt weergegeven voor Alabama beweert (kopieer de tekst die begint met s3://, niet de bijbehorende http-link). Ga vervolgens terug naar de visuele taak en plak deze als S3-URL; als het correct is, ziet u in de Uitvoerschema tab de vermelde gegevensvelden.
- Selecteer CSV-indeling en leid het schema af zoals u deed met de andere bron.
- Zoek als kind van deze bron in de Knooppunten toevoegen menu voor
recipeEn kies Recept voor gegevensvoorbereiding.
- Geef het de naam in de eigenschappen van dit nieuwe knooppunt
Claim cleanup recipeen kies het recept en de versie die je eerder hebt gepubliceerd. - U kunt hier de receptstappen bekijken en de link naar DataBrew gebruiken om indien nodig wijzigingen aan te brengen.
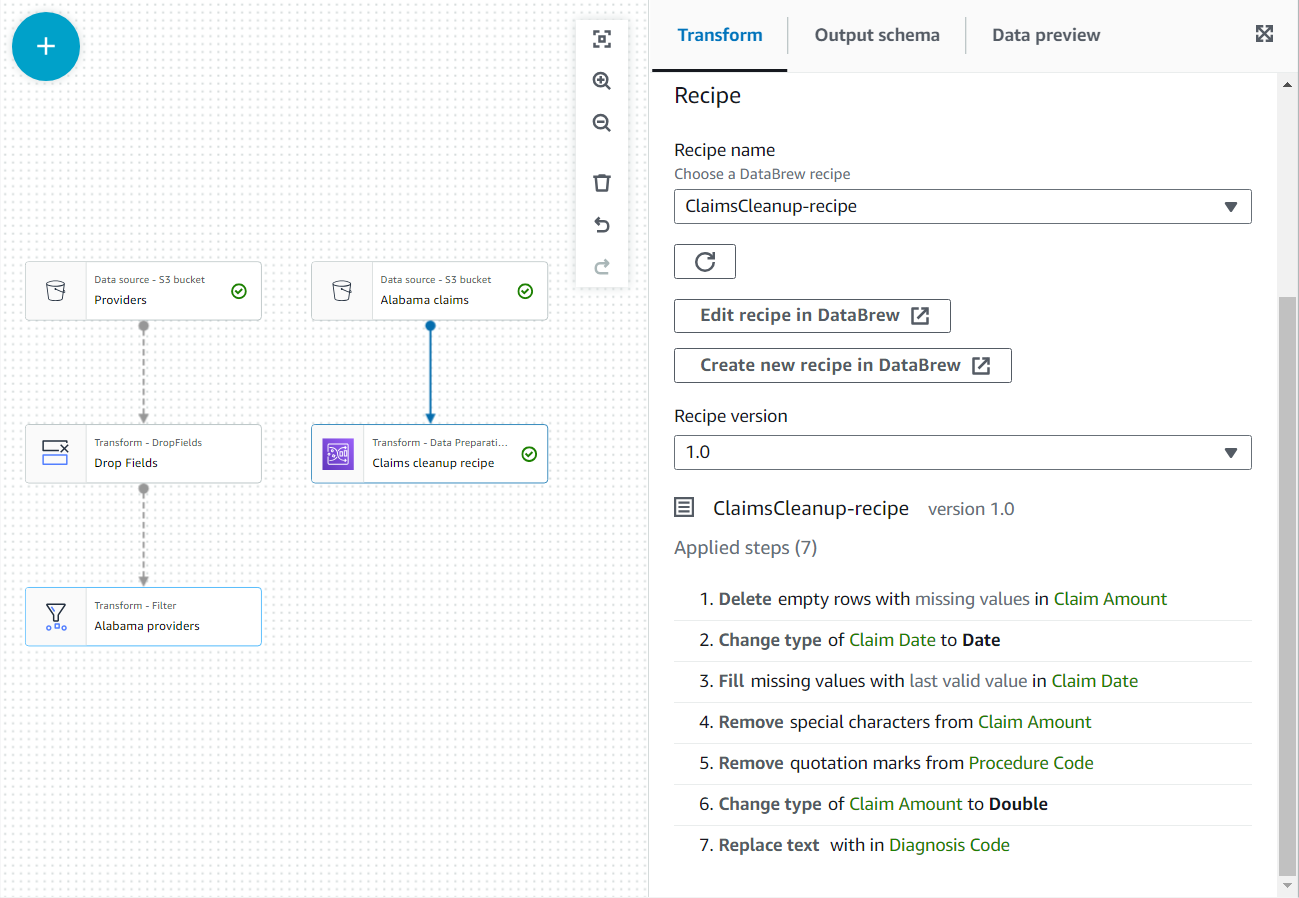
- Voeg een Aanmelden knoop en selecteer beide Alabama-aanbieders en Claim opruimrecepten als de ouder.
- Voeg een join-voorwaarde toe die gelijk is aan de provider-ID van beide bronnen.
- Voeg als laatste stap een S3-node toe als doel (let op: de eerste die wordt vermeld wanneer u zoekt, is de bron; zorg ervoor dat u de versie selecteert die wordt vermeld als doel).
- Laat in de knooppuntconfiguratie de standaardindeling JSON staan en voer een S3-URL in waarop de taakrol mag schrijven.
Stel de data-output daarnaast als tabel beschikbaar in de catalogus.
- In het Update-opties voor gegevenscatalogus sectie, selecteert u de tweede optie Maak een tabel in de gegevenscatalogus en werk bij volgende uitvoeringen het schema bij en voeg nieuwe partities toe, selecteer vervolgens een database waarvoor u toestemming hebt om tabellen te maken.
- Toewijzen
alabama_claimsals de naam en kies Datum claimen als de partitiesleutel (dit is ter illustratie; een kleine tabel als deze heeft niet echt partities nodig als er later geen verdere gegevens worden toegevoegd).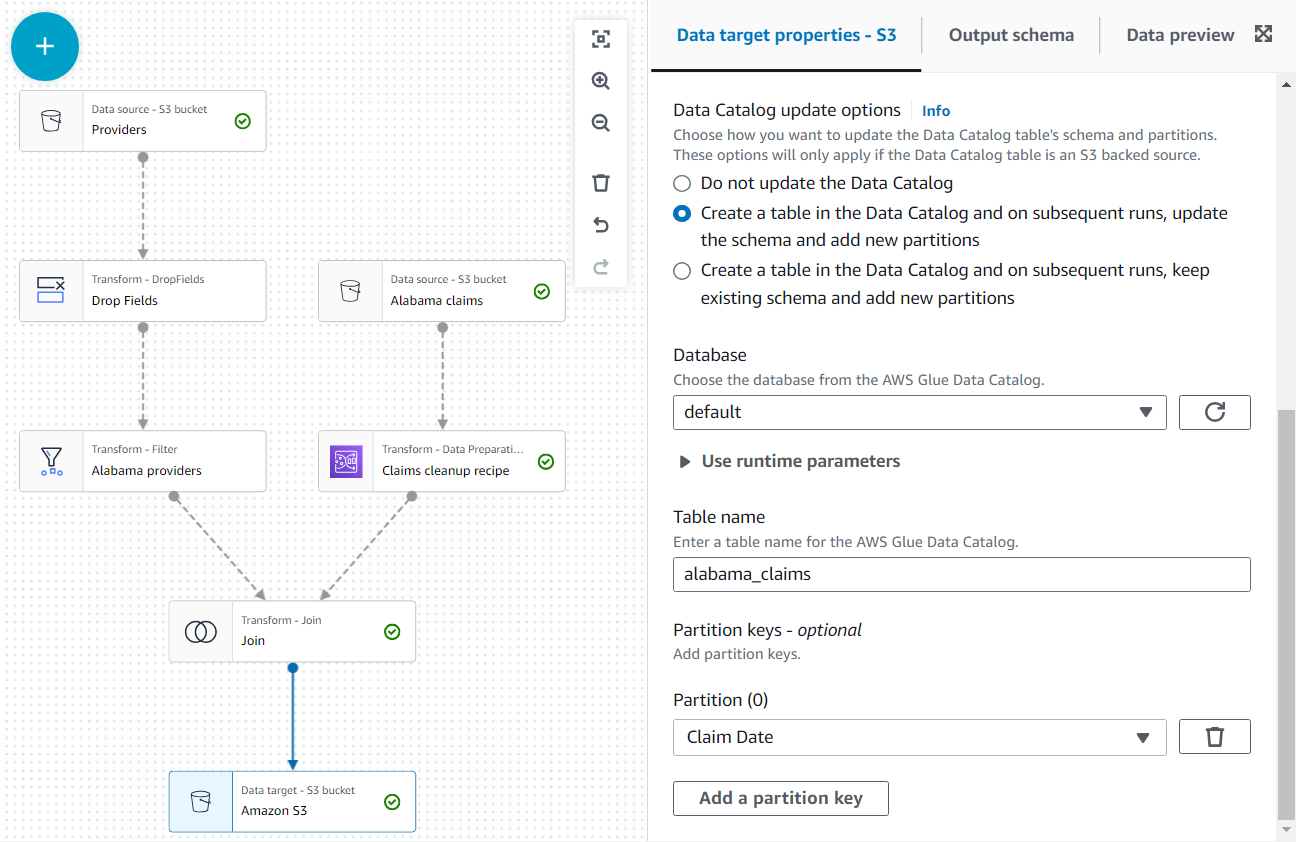
- Nu kunt u de taak opslaan en uitvoeren.
- Op de Runs tabblad kunt u het proces volgen en gedetailleerde taakstatistieken bekijken met behulp van de taak-ID-link.
De taak duurt een paar minuten om te voltooien.
- Wanneer de taak is voltooid, navigeert u naar de Athena-console.
- Zoek de tafel
alabama_claimsin de database die u hebt geselecteerd en kies met behulp van het contextmenu Voorbeeldtabel, waarmee een eenvoudige SELECT * SQL-instructie op de tafel wordt uitgevoerd.
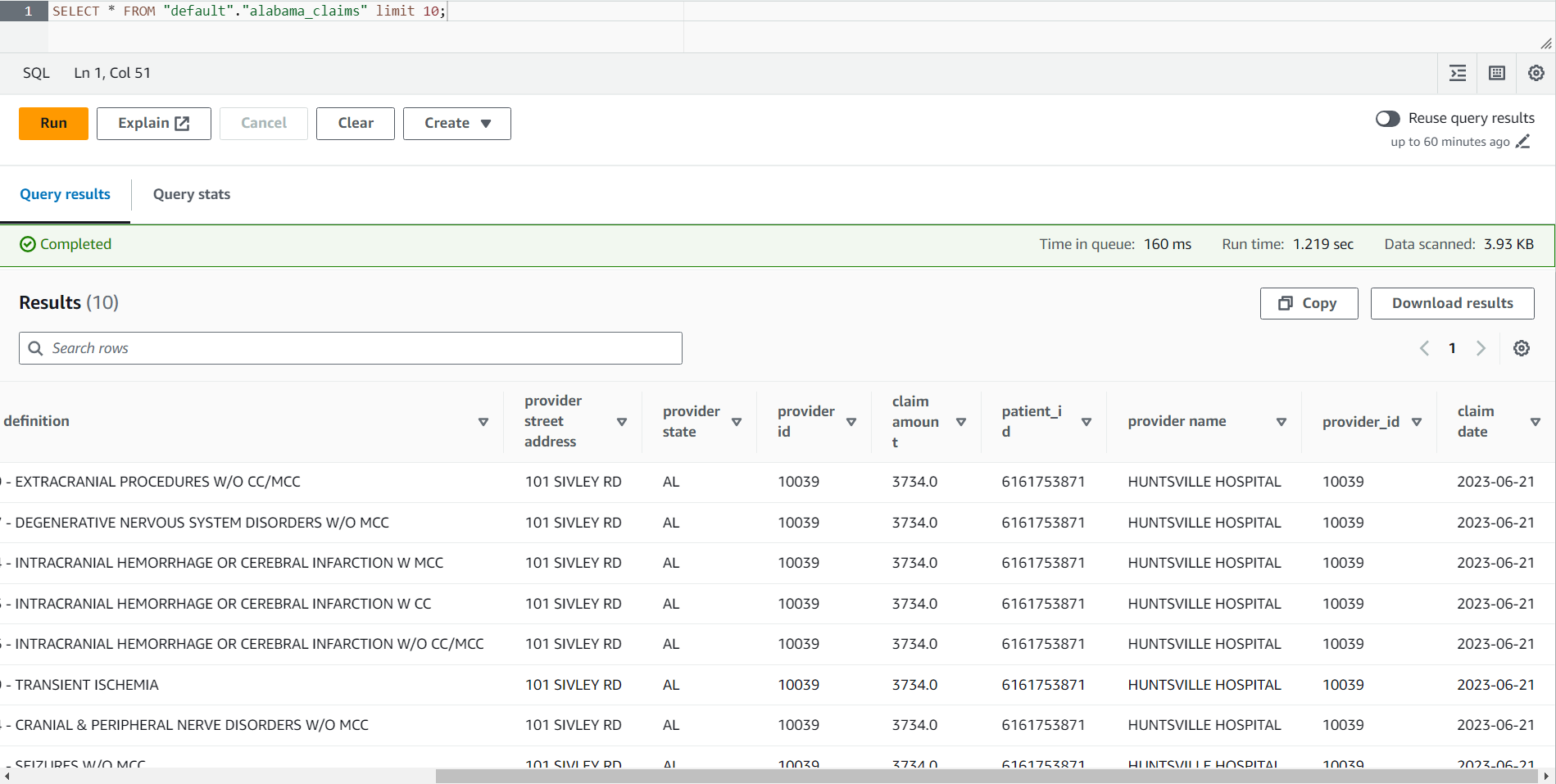
U kunt in het resultaat van de taak zien dat de gegevens zijn opgeschoond door het DataBrew-recept en verrijkt door de AWS Glue Studio-join.
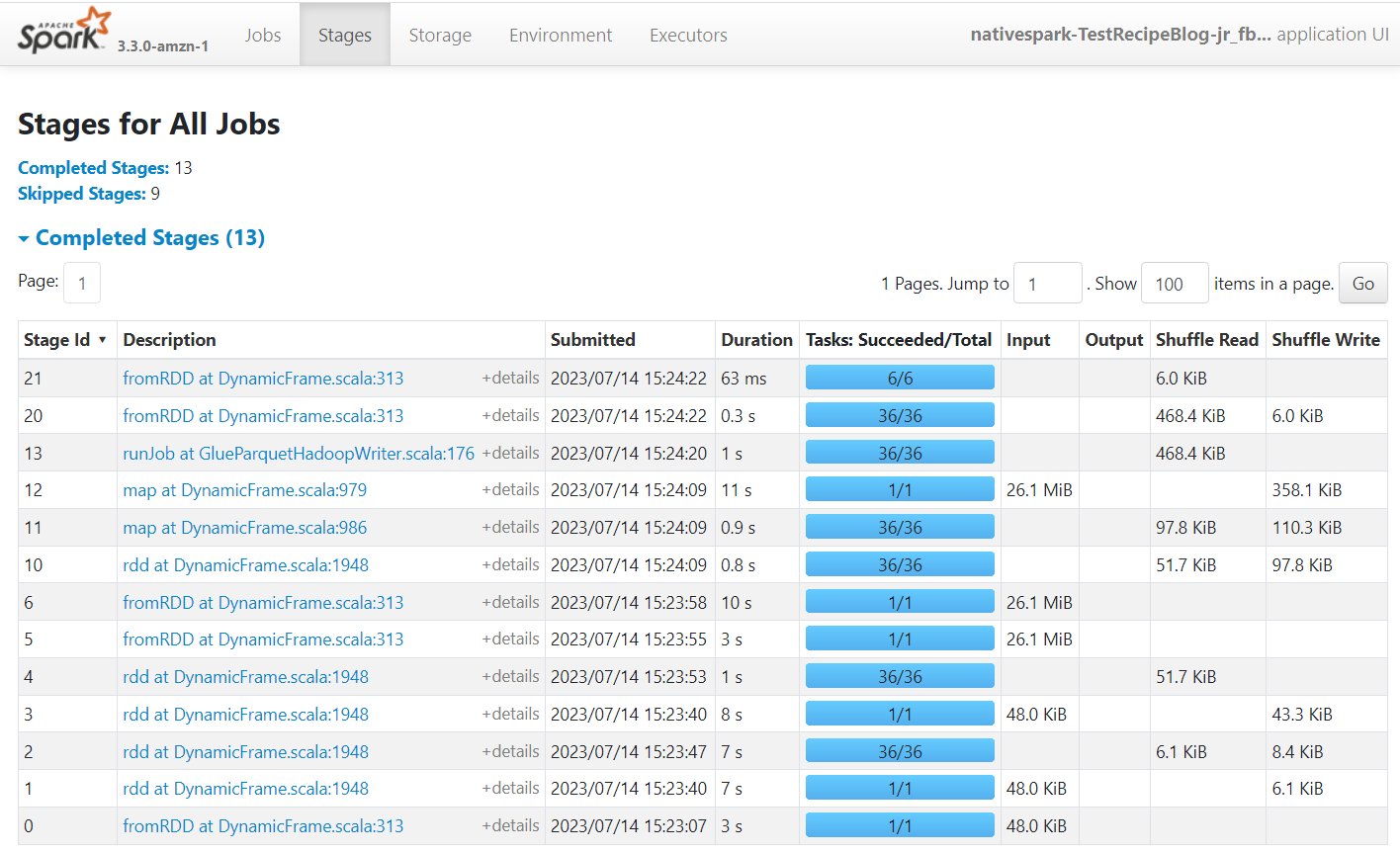
Apache Spark is de engine die de taken uitvoert die in AWS Glue Studio zijn gemaakt. Met behulp van de Spark-gebruikersinterface in de gebeurtenislogboeken die het produceert, kunt u inzichten bekijken over het taakplan en de uitvoering, wat u kan helpen begrijpen hoe uw taak presteert en mogelijke prestatieknelpunten. Voor deze taak op een grote gegevensset kunt u deze bijvoorbeeld gebruiken om de impact te vergelijken van het expliciet filteren van de providerstatus voordat u lid wordt, of om te bepalen of u baat kunt hebben bij het toevoegen van een Autobalance-transformatie om parallellisme te verbeteren.
Standaard slaat de taak de Apache Spark-gebeurtenislogboeken op onder het pad s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. Om de vacatures te bekijken, moet u een History-server installeren met behulp van een van de beschikbare methoden.
Opruimen
Als u deze oplossing niet langer nodig heeft, kunt u de bestanden verwijderen die zijn gegenereerd op Amazon S3, de tabel die door de taak is gemaakt, het DataBrew-recept en de AWS Glue-taak.
Conclusie
In dit bericht hebben we laten zien hoe je AWS DataBrew kunt gebruiken om een recept te bouwen met behulp van de meegeleverde interactieve editor en vervolgens het gepubliceerde recept kunt gebruiken als onderdeel van een visuele ETL-taak van AWS Glue Studio. We hebben enkele voorbeelden toegevoegd van veelvoorkomende taken die nodig zijn bij het voorbereiden van gegevens en het opnemen van gegevens in AWS Glue Catalog-tabellen.
In dit voorbeeld werd een enkel recept gebruikt in de visuele job, maar het is mogelijk om meerdere recepten te gebruiken in verschillende delen van het ETL-proces, en hetzelfde recept te hergebruiken voor meerdere jobs.
Met deze AWS Glue-oplossingen kunt u effectief geavanceerde ETL-pijplijnen maken die eenvoudig te bouwen en te onderhouden zijn, en dat allemaal zonder code te schrijven. U kunt vandaag al beginnen met het creëren van oplossingen die beide tools combineren.
Over de auteurs
 Michail Smirnov is een Sr. Software Dev Engineer in het AWS Glue-team en maakt deel uit van het AWS Glue DataBrew-ontwikkelingsteam. Buiten zijn werk zijn zijn interesses onder meer gitaar leren spelen en reizen met zijn gezin.
Michail Smirnov is een Sr. Software Dev Engineer in het AWS Glue-team en maakt deel uit van het AWS Glue DataBrew-ontwikkelingsteam. Buiten zijn werk zijn zijn interesses onder meer gitaar leren spelen en reizen met zijn gezin.
 Gonzalo herreros is Sr. Big Data Architect in het AWS Glue-team. Hij is gevestigd in Dublin, Ierland en helpt klanten slagen met big data-oplossingen op basis van AWS Glue. In zijn vrije tijd houdt hij van bordspellen en fietsen.
Gonzalo herreros is Sr. Big Data Architect in het AWS Glue-team. Hij is gevestigd in Dublin, Ierland en helpt klanten slagen met big data-oplossingen op basis van AWS Glue. In zijn vrije tijd houdt hij van bordspellen en fietsen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- : heeft
- :is
- :niet
- $UP
- 10
- 100
- 12
- 15%
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- in staat
- Over
- aanvaardbaar
- aanvaard
- toegang
- Account
- Actie
- daadwerkelijk
- toevoegen
- toegevoegd
- toe te voegen
- toevoeging
- adres
- vergevorderd
- Na
- Alabama
- Alles
- toelaten
- ook
- Amazone
- Amazon Web Services
- hoeveelheden
- an
- analisten
- en
- elke
- apache
- Apache Spark
- Aanvraag
- Solliciteer
- ZIJN
- AS
- geassocieerd
- At
- auteur
- auto
- Automatisch
- Beschikbaar
- AWS
- AWS lijm
- terug
- gebaseerde
- BE
- vaardigheden
- wezen
- voordeel
- betekent
- Groot
- Big data
- blanco
- boord
- Gezelschapsspelletjes
- bladwijzers
- zowel
- Brengt
- browser
- bouw
- maar
- by
- CAN
- mogelijkheden
- geval
- catalogus
- Cellen
- gecentraliseerde
- verandering
- Wijzigingen
- tekens
- kind
- keuze
- Kies
- aanspraak maken op
- vorderingen
- code
- Kolom
- columns
- combineren
- komst
- Gemeen
- vergelijken
- compleet
- componenten
- computer
- voorwaarde
- Configuratie
- Overwegen
- bestaat uit
- troosten
- verband
- converteren
- geconverteerd
- te corrigeren
- Overeenkomend
- Kosten
- kon
- en je merk te creëren
- aangemaakt
- Wij creëren
- het aanmaken
- gewoonte
- Klanten
- gegevens
- Data voorbereiding
- gegevensverwerking
- data kwaliteit
- Database
- datasets
- Datum
- Data
- dag
- transactie
- beslissen
- beslissing
- Standaard
- tonen
- beschrijving
- gewenste
- gedetailleerd
- gegevens
- Dev
- Ontwikkeling
- ontwikkelingsteam
- DEED
- anders
- onderscheiden
- distributie
- do
- Nee
- doen
- Dollar
- verdubbelen
- Val
- dublin
- elk
- En het is heel gemakkelijk
- editor
- effect
- effectief
- maakt
- einde
- Motor
- ingenieur
- verrijkt
- verrijkende
- Enter
- fout
- essentieel
- Ether (ETH)
- schatten
- Zelfs
- Event
- Alle
- elke dag
- voorbeeld
- voorbeelden
- bestaand
- extra
- extract
- familie
- ver
- Voordelen
- weinig
- Velden
- Dien in
- Bestanden
- vullen
- filter
- filtering
- Tot slot
- Voornaam*
- gevolgd
- volgend
- Voor
- formaat
- oppompen van
- verder
- Spellen
- gegenereerde
- Geven
- meer
- Hebben
- he
- hulp
- helpt
- hier
- zijn
- geschiedenis
- Hoe
- How To
- Echter
- HTML
- http
- HTTPS
- IAM
- ID
- geïdentificeerd
- identificeren
- Identiteit
- if
- Impact
- verbeteren
- verbeteringen
- in
- omvatten
- inclusief
- Inclusief
- aangegeven
- invoer
- inzichten
- installeren
- instantie
- geïntegreerde
- integratie
- interactieve
- belang
- belangen
- Interface
- in
- geïntroduceerd
- intuïtief
- Ierland
- problemen
- IT
- HAAR
- Jobomschrijving:
- Vacatures
- mee
- toegetreden
- jpg
- json
- voor slechts
- Houden
- sleutel
- kennis
- Groot
- groter
- grootste
- Achternaam*
- later
- laatste
- leren
- Verlof
- als
- Waarschijnlijk
- LINK
- opgesomd
- laden
- plaats
- logica
- langer
- onderhouden
- maken
- MERKEN
- handmatig
- Match
- medisch
- Menu
- methode
- methoden
- Metriek
- minuten
- vermist
- monitor
- meer
- meervoudig
- Dan moet je
- naam
- OP DEZE WEBSITE VIND JE
- Navigatie
- Noodzaak
- nodig
- behoeften
- New
- geen
- knooppunt
- Merk op..
- nu
- aantal
- of
- on
- EEN
- Slechts
- open
- Optimaliseer
- Keuze
- Opties
- or
- bestellen
- Overige
- onze
- uitgang
- buiten
- over
- totaal
- brood
- deel
- onderdelen
- pad
- prestatie
- uitvoerend
- toestemming
- permissies
- plan
- Plato
- Plato gegevensintelligentie
- PlatoData
- Spelen
- mogelijk
- Post
- potentieel
- voorbereiding
- Voorbeschouwing
- Previews
- verwerking
- produceert
- project
- vastgoed
- mits
- leverancier
- providers
- biedt
- Publicatie
- publiceren
- gepubliceerde
- doel
- doeleinden
- kwaliteit
- citaten
- werkelijk
- redelijk
- recept
- Recepten
- verminderen
- reflecteren
- regio
- registreren
- relevante
- verwijderen
- vervangen
- aangevraagd
- nodig
- vereiste
- respectievelijk
- REST
- resultaat
- Resultaten
- hergebruiken
- beoordelen
- Rol
- lopen
- loopt
- dezelfde
- Bespaar
- Scale
- scaling
- Ontdek
- Tweede
- sectie
- zien
- te zien
- gekozen
- apart
- Diensten
- Sessie
- reeks
- settings
- moet
- vertoonde
- getoond
- teken
- aanzienlijke
- Eenvoudig
- single
- Maat
- Klein
- So
- dusver
- Software
- oplossing
- Oplossingen
- sommige
- bron
- bronnen
- Tussenruimte
- Vonk
- special
- specifiek
- gespecificeerd
- SQL
- begin
- Start
- Land
- Statement
- statistiek
- Stap voor
- Stappen
- mediaopslag
- shop
- eenvoudig
- Draad
- studio
- volgend
- slagen
- dergelijk
- geschikt
- OVERZICHT
- zeker
- synthetisch
- tafel
- Nemen
- doelwit
- taken
- team
- getest
- dat
- De
- De Bron
- De Staat
- Ze
- harte
- Er.
- dit
- drie
- niet de tijd of
- naar
- vandaag
- tools
- tools
- top
- spoor
- Transformeren
- Transformatie
- transformaties
- Reizend
- twee
- type dan:
- ui
- voor
- begrijpen
- bijwerken
- bijgewerkt
- URL
- bruikbaar
- .
- use case
- gebruikt
- gebruikers
- toepassingen
- gebruik
- BEVESTIG
- waarde
- Values
- controleren
- versie
- Bekijk
- zichtbaar
- willen
- was
- manieren
- we
- web
- webservices
- GOED
- waren
- wanneer
- welke
- wil
- Met
- zonder
- Mijn werk
- werker
- werknemers
- workflow
- zou
- schrijven
- het schrijven van
- u
- Your
- zephyrnet
- Postcode