Zoals vrijwel alle klanten wilt u zo min mogelijk uitgeven en toch de best mogelijke prestaties behalen. Dit betekent dat u op de prijs-prestatieverhouding moet letten. Met Amazon roodverschuiving, je kunt je taart hebben en hem ook opeten! Amazon Redshift levert tot 4.9 keer lagere kosten per gebruiker en tot 7.9 keer betere prijs-kwaliteitverhouding dan andere clouddatawarehouses op real-world workloads met behulp van geavanceerde technieken zoals concurrency-schaling om honderden gelijktijdige gebruikers te ondersteunen, verbeterde string-codering voor snellere queryprestaties , En Amazon Redshift Serverloos prestatieverbeteringen. Lees verder om te begrijpen waarom prijs-prestaties belangrijk zijn en hoe de prijs-prestaties van Amazon Redshift een maatstaf zijn voor hoeveel het kost om een bepaald niveau van werklastprestaties te bereiken, namelijk prestatie-ROI (return on investment).
Omdat zowel prijs als prestatie een rol spelen in de prijs-prestatieberekening, zijn er twee manieren om over prijs-prestatie na te denken. De eerste manier is om de prijs constant te houden: als u €1 te besteden heeft, hoeveel prestatie haalt u dan uit uw datawarehouse? Een database met een betere prijs-kwaliteitverhouding levert betere prestaties voor elke bestede euro. Als u de prijs constant houdt bij het vergelijken van twee datawarehouses die hetzelfde kosten, zal de database met betere prijs-prestaties uw zoekopdrachten sneller uitvoeren. De tweede manier om naar de prijs-prestatieverhouding te kijken, is door de prestaties constant te houden: als uw werklast binnen 10 minuten moet worden voltooid, wat gaat dat dan kosten? Een database met een betere prijs-prestatieverhouding voert uw werklast in 10 minuten uit tegen lagere kosten. Wanneer de prestaties constant worden gehouden bij het vergelijken van twee datawarehouses die dezelfde afmetingen hebben om dezelfde prestaties te leveren, zal de database met de betere prijs-prestatieverhouding dus minder kosten en u geld besparen.
Ten slotte is een ander belangrijk aspect van prijs-prestatie voorspelbaarheid. Weten hoeveel uw datawarehouse gaat kosten naarmate het aantal datawarehouse-gebruikers groeit, is cruciaal voor de planning. Het moet niet alleen vandaag de dag de beste prijs-prestatieverhouding leveren, maar ook voorspelbaar schalen en de beste prijs-prestatieverhouding leveren naarmate er meer gebruikers en workloads worden toegevoegd. Een ideaal datawarehouse zou dat moeten hebben lineaire schaal– het schalen van uw datawarehouse om tweemaal de querydoorvoer te leveren zou idealiter twee keer zoveel (of minder) moeten kosten.
In dit bericht delen we prestatieresultaten om te illustreren hoe Amazon Redshift aanzienlijk betere prijs-prestaties levert in vergelijking met toonaangevende alternatieve clouddatawarehouses. Dit betekent dat als u hetzelfde bedrag uitgeeft aan Amazon Redshift als aan een van deze andere datawarehouses, u betere prestaties krijgt met Amazon Redshift. Als u uw Redshift-cluster echter zodanig indeelt dat deze dezelfde prestaties levert, zult u lagere kosten zien in vergelijking met deze alternatieven.
Prijs-prestatieverhouding voor echte workloads
Je kunt Amazon Redshift gebruiken om een zeer grote diversiteit aan werklasten aan te sturen, van batchverwerking van complexe op extractie, transformatie en laad (ETL) gebaseerde rapporten, en realtime streaming-analyses tot business intelligence (BI)-dashboards met lage latentie die moeten honderden of zelfs duizenden gebruikers tegelijkertijd bedienen met responstijden van minder dan een seconde, en alles daartussenin. Een van de manieren waarop we de prijsprestaties voor onze klanten voortdurend verbeteren, is door voortdurend de software- en hardwareprestatietelemetrie van de Redshift-vloot te beoordelen, op zoek naar kansen en gebruiksscenario's van klanten waarin we de prestaties van Amazon Redshift verder kunnen verbeteren.
Enkele recente voorbeelden van prestatie-optimalisaties aangestuurd door vloottelemetrie zijn:
- Optimalisaties van stringquery's – Door te analyseren hoe Amazon Redshift verschillende gegevenstypen in de Redshift-vloot verwerkte, ontdekten we dat het optimaliseren van string-heavy queries aanzienlijke voordelen zou opleveren voor de werklast van onze klanten. (We bespreken dit later in dit bericht in meer detail.)
- Geautomatiseerde gematerialiseerde weergaven – We ontdekten dat Amazon Redshift-klanten vaak veel zoekopdrachten uitvoeren met gemeenschappelijke subquerypatronen. Verschillende query's kunnen bijvoorbeeld aan dezelfde drie tabellen worden gekoppeld met dezelfde samenvoegvoorwaarde. Amazon Redshift kan nu automatisch gematerialiseerde views creëren en onderhouden en vervolgens op transparante wijze queries herschrijven om de gematerialiseerde views te gebruiken met behulp van de door de machine geleerde geautomatiseerde gematerialiseerde weergave autonomiefunctie in Amazon Redshift. Indien ingeschakeld kunnen geautomatiseerde gematerialiseerde weergaven op transparante wijze de queryprestaties voor repetitieve query's verbeteren zonder tussenkomst van de gebruiker. (Merk op dat geautomatiseerde gematerialiseerde weergaven niet zijn gebruikt in de benchmarkresultaten die in dit bericht worden besproken).
- Werklasten met hoge gelijktijdigheid – Een groeiend gebruiksscenario dat we zien is het gebruik van Amazon Redshift om dashboardachtige werklasten te bedienen. Deze werklasten worden gekenmerkt door gewenste responstijden voor zoekopdrachten van enkele seconden of minder, waarbij tientallen of honderden gelijktijdige gebruikers tegelijkertijd zoekopdrachten uitvoeren met een piekerig en vaak onvoorspelbaar gebruikspatroon. Het prototypische voorbeeld hiervan is een door Amazon Redshift ondersteund BI-dashboard dat op maandagochtend een piek in het verkeer kent, wanneer een groot aantal gebruikers hun week begint.
Vooral workloads met hoge gelijktijdigheid hebben een zeer brede toepasbaarheid: de meeste datawarehouse-workloads werken met gelijktijdigheid, en het is niet ongebruikelijk dat honderden of zelfs duizenden gebruikers tegelijkertijd query's uitvoeren op Amazon Redshift. Amazon Redshift is ontworpen om de reactietijden van vragen voorspelbaar en snel te houden. Redshift Serverless doet dit automatisch voor u door indien nodig rekenkracht toe te voegen en te verwijderen om de reactietijden van zoekopdrachten snel en voorspelbaar te houden. Dit betekent dat een door Redshift Serverless ondersteund dashboard dat snel laadt wanneer het door een of twee gebruikers wordt geopend, snel blijft laden, zelfs wanneer veel gebruikers het tegelijkertijd laden.
Om dit soort werklast te simuleren, hebben we een benchmark gebruikt die is afgeleid van TPC-DS met een dataset van 100 GB. TPC-DS is een industriestandaard benchmark die een verscheidenheid aan typische datawarehouse-query's omvat. Op deze relatief kleine schaal van 100 GB worden queries in deze benchmark op Redshift Serverless in gemiddeld enkele seconden uitgevoerd, wat representatief is voor wat gebruikers die een interactief BI-dashboard laden zouden verwachten. We hebben tussen de 1 en 200 gelijktijdige tests van deze benchmark uitgevoerd, waarbij we tussen de 1 en 200 gebruikers simuleerden die tegelijkertijd een dashboard probeerden te laden. We hebben de test ook herhaald met verschillende populaire alternatieve clouddatawarehouses die ook automatisch uitschalen ondersteunen (als je bekend bent met het bericht Amazon Redshift zet zijn leiderschap op het gebied van prijs-prestatie voort, we hebben concurrent A niet opgenomen omdat deze geen automatische opschaling ondersteunt). We hebben de gemiddelde reactietijd van zoekopdrachten gemeten, wat betekent hoe lang een gebruiker zou wachten totdat zijn zoekopdrachten waren voltooid (of hun dashboard was geladen). De resultaten worden weergegeven in de volgende grafiek.
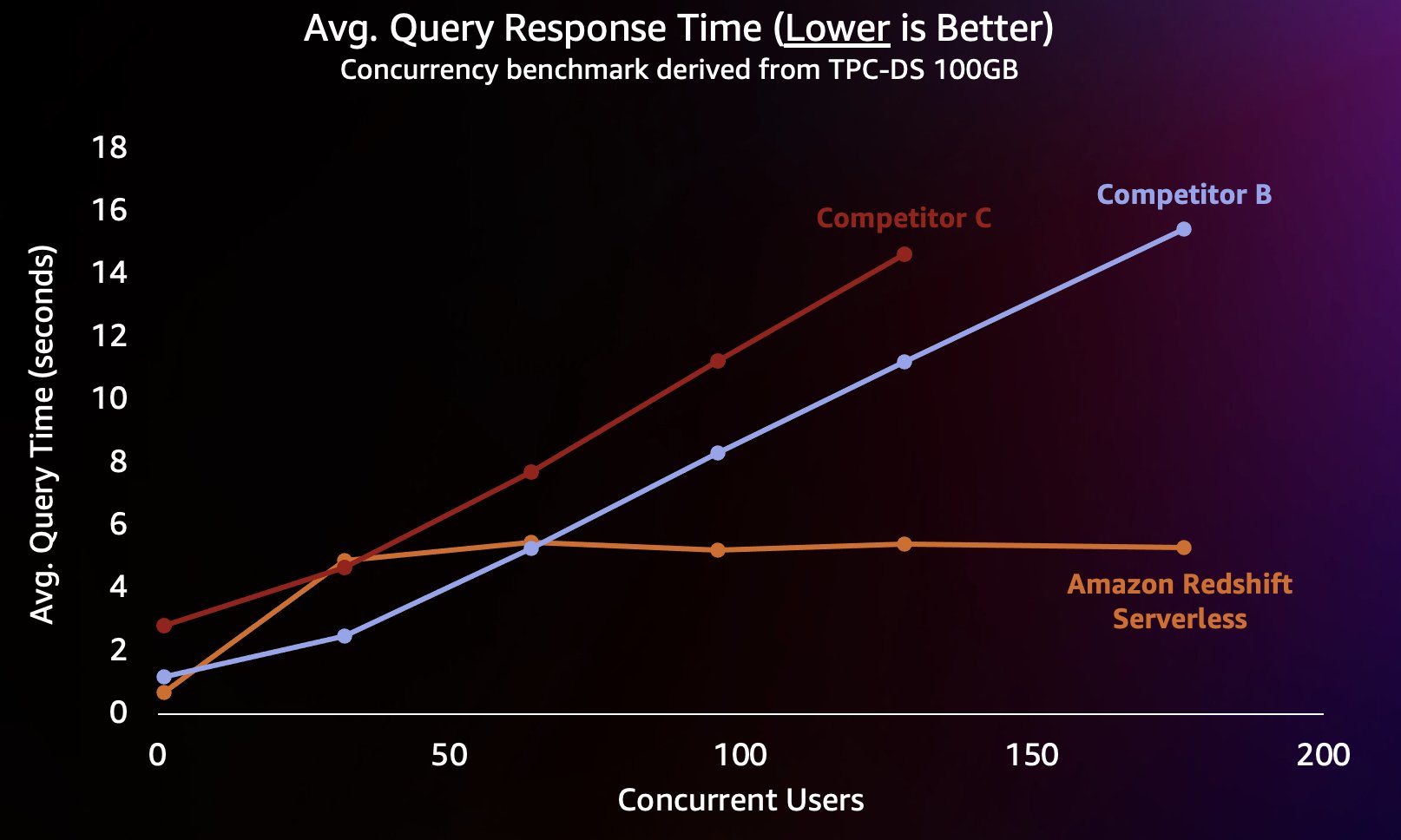
Concurrent B schaalt goed op tot ongeveer 64 gelijktijdige query's. Op dat moment is het niet meer in staat om aanvullende rekenkracht te bieden en worden query's in de wachtrij geplaatst, wat leidt tot langere responstijden voor query's. Hoewel concurrent C automatisch kan schalen, wordt de doorvoer van query's lager dan zowel Amazon Redshift als concurrent B, en kan hij de runtimes van query's niet laag houden. Bovendien ondersteunt het geen wachtrijquery's wanneer de rekenkracht opraakt, waardoor het niet verder kan schalen dan ongeveer 128 gelijktijdige gebruikers. Het indienen van aanvullende vragen die verder gaan, wordt door het systeem afgewezen.
Hier kan Redshift Serverless de reactietijd van zoekopdrachten relatief consistent houden op ongeveer 5 seconden, zelfs wanneer honderden gebruikers tegelijkertijd zoekopdrachten uitvoeren. De gemiddelde reactietijden op vragen voor concurrenten B en C nemen gestaag toe naarmate de belasting van de magazijnen toeneemt, wat ertoe leidt dat gebruikers langer moeten wachten (tot 16 seconden) voordat hun vragen terugkeren wanneer het datawarehouse bezet is. Dit betekent dat als een gebruiker een dashboard probeert te vernieuwen (dat zelfs meerdere gelijktijdige zoekopdrachten kan indienen wanneer het opnieuw wordt geladen), Amazon Redshift de laadtijden van het dashboard veel consistenter kan houden, zelfs als het dashboard door tientallen of honderden andere wordt geladen. gebruikers tegelijkertijd.
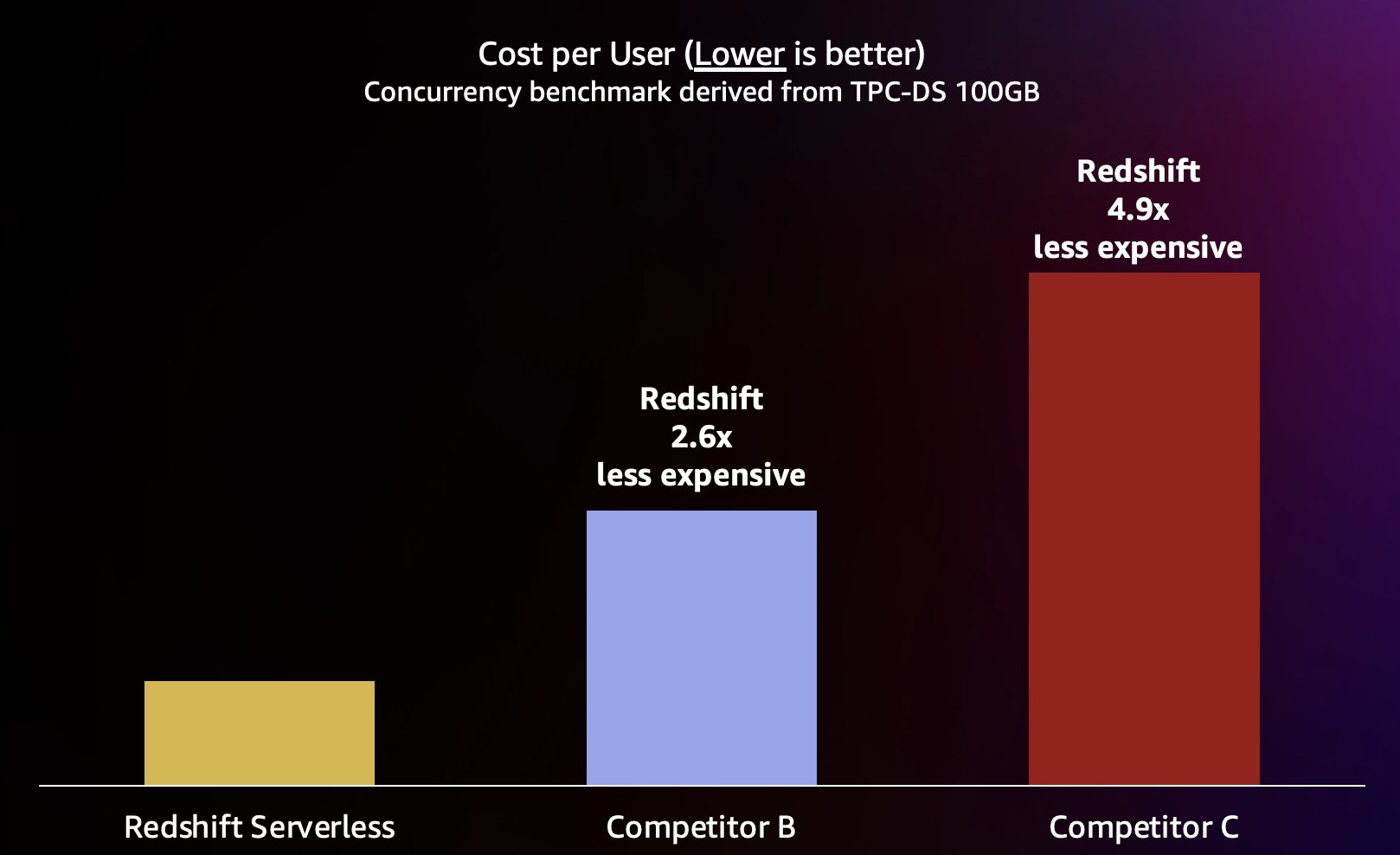
Omdat Amazon Redshift een zeer hoge doorvoercapaciteit voor korte zoekopdrachten kan leveren (zoals we hierover schreven in Amazon Redshift zet zijn leiderschap op het gebied van prijs-prestatie voort), is het ook in staat om met deze hogere gelijktijdigheid om te gaan bij het efficiënter opschalen en dus tegen aanzienlijk lagere kosten. Om dit te kwantificeren, kijken we naar de prijs-prestatieverhouding met gepubliceerde gegevens prijzen op aanvraag voor elk van de magazijnen in de voorgaande test, weergegeven in het volgende diagram. Het is vermeldenswaard dat het gebruik van Gereserveerde exemplaren (RI's), vooral RI's met een looptijd van 3 jaar die zijn gekocht met de optie voor volledige vooruitbetaling, hebben de laagste kosten om Amazon Redshift op ingerichte clusters uit te voeren, wat resulteert in de beste relatieve prijs-prestatieverhouding vergeleken met on-demand of andere RI-opties.

Amazon Redshift kan dus niet alleen betere prestaties leveren bij hogere gelijktijdigheid, maar ook tegen aanzienlijk lagere kosten. Elk gegevenspunt in het prijs-prestatiediagram is gelijk aan de kosten om de benchmark met de opgegeven gelijktijdigheid uit te voeren. Omdat de prijs-prestatieverhouding lineair is, kunnen we de kosten voor het uitvoeren van de benchmark bij elke gelijktijdigheid delen door de gelijktijdigheid (aantal gelijktijdige gebruikers in dit diagram) om ons te vertellen hoeveel het toevoegen van elke nieuwe gebruiker kost voor deze specifieke benchmark.
De voorgaande resultaten zijn eenvoudig te repliceren. Alle zoekopdrachten die in de benchmark worden gebruikt, zijn beschikbaar in onze GitHub-repository en de prestaties worden gemeten door een datawarehouse te lanceren, Concurrency Scaling op Amazon Redshift (of de overeenkomstige automatische schalingsfunctie op andere magazijnen) in te schakelen, de gegevens kant-en-klaar te laden (geen handmatige afstemming of database-specifieke instellingen) en vervolgens een gelijktijdige stroom van query's op gelijktijdigheden van 1-200 in stappen van 32 op elk datawarehouse. Dezelfde GitHub-repository verwijst naar vooraf gegenereerde (en ongewijzigde) TPC-DS-gegevens in Amazon eenvoudige opslagservice (Amazon S3) op verschillende schalen met behulp van de officiële TPC-DS datageneratiekit.
Optimaliseren van string-zware workloads
Zoals eerder vermeld, is het Amazon Redshift-team voortdurend op zoek naar nieuwe mogelijkheden om onze klanten nog betere prijs-prestaties te bieden. Een verbetering die we onlangs hebben geïntroduceerd en die de prestaties aanzienlijk heeft verbeterd, is een optimalisatie die de prestaties van query's op stringgegevens versnelt. U wilt bijvoorbeeld de totale omzet vinden die is gegenereerd door winkels in New York City met een zoekopdracht als SELECT sum(price) FROM sales WHERE city = ‘New York’. Deze query past een predikaat toe op tekenreeksgegevens (city = ‘New York’). Zoals u zich kunt voorstellen, is de verwerking van stringgegevens alomtegenwoordig in datawarehouse-toepassingen.
Om te kwantificeren hoe vaak de werklasten van klanten toegang krijgen tot strings, hebben we een gedetailleerde analyse uitgevoerd van het gebruik van stringdatatypes met behulp van vloottelemetrie van tienduizenden klantenclusters beheerd door Amazon Redshift. Uit onze analyse blijkt dat in 90% van de clusters stringkolommen minstens 30% van alle kolommen uitmaken, en dat in 50% van de clusters stringkolommen minstens 50% van alle kolommen uitmaken. Bovendien heeft een meerderheid van alle zoekopdrachten die op het Amazon Redshift clouddatawarehouse-platform worden uitgevoerd, toegang tot ten minste één stringkolom. Een andere belangrijke factor is dat tekenreeksgegevens vaak een lage kardinaliteit hebben, wat betekent dat de kolommen een relatief kleine set unieke waarden bevatten. Hoewel bijvoorbeeld een orders tabel die verkoopgegevens vertegenwoordigt, kan miljarden rijen bevatten order_status kolom binnen die tabel bevat mogelijk slechts een paar unieke waarden in die miljarden rijen, zoals pending, in process en completed.
Op het moment van schrijven zijn de meeste tekenreekskolommen in Amazon Redshift gecomprimeerd met LZO or ZSTD algoritmen. Dit zijn goede compressie-algoritmen voor algemene doeleinden, maar ze zijn niet ontworpen om te profiteren van stringgegevens met een lage kardinaliteit. In het bijzonder vereisen ze dat gegevens worden gedecomprimeerd voordat ze worden gebruikt, en zijn ze minder efficiënt in het gebruik van hardwaregeheugenbandbreedte. Voor gegevens met een lage kardinaliteit is er een ander type codering dat optimaler kan zijn: BYTEDICT. Deze codering maakt gebruik van een woordenboekcoderingsschema waarmee de database-engine rechtstreeks op gecomprimeerde gegevens kan werken zonder deze eerst te hoeven decomprimeren.
Om de prijs-prestaties voor string-zware workloads verder te verbeteren, introduceert Amazon Redshift nu aanvullende prestatieverbeteringen die scans en predikaatevaluaties versnellen, ten opzichte van stringkolommen met lage kardinaliteit die zijn gecodeerd als BYTEDICT, tussen 5-63 keer sneller (zie resultaten in de volgende sectie) vergeleken met alternatieve compressiecoderingen zoals LZO of ZSTD. Amazon Redshift bereikt deze prestatieverbetering door scans te vectoriseren over lichtgewicht, CPU-efficiënte, BYTEDICT-gecodeerde stringkolommen met lage kardinaliteit. Deze optimalisaties voor stringverwerking maken effectief gebruik van de geheugenbandbreedte die wordt geboden door moderne hardware, waardoor realtime analyse van stringgegevens mogelijk wordt. Deze nieuw geïntroduceerde prestatiemogelijkheden zijn optimaal voor tekenreekskolommen met een lage kardinaliteit (tot een paar honderd unieke tekenreekswaarden).
U kunt automatisch profiteren van deze nieuwe hoogwaardige tekenreeksverbetering door in te schakelen automatische tafeloptimalisatie in uw Amazon Redshift-datawarehouse. Als u automatische tafeloptimalisatie niet heeft ingeschakeld voor uw tafels, kunt u aanbevelingen ontvangen van de Amazon Redshift-adviseur in de Amazon Redshift-console over de geschiktheid van een stringkolom voor BYTEDICT-codering. U kunt ook nieuwe tabellen definiëren die tekenreekskolommen met een lage kardinaliteit hebben met BYTEDICT-codering. Stringverbeteringen in Amazon Redshift zijn nu beschikbaar in alle AWS-regio's waar Amazon Redshift is beschikbaar.
Prestatie resultaten
Om de prestatie-impact van onze stringverbeteringen te meten, hebben we een dataset van 10 TB (Tera Byte) gegenereerd die bestond uit stringgegevens met een lage kardinaliteit. We hebben drie versies van de gegevens gegenereerd met behulp van korte, middellange en lange reeksen, die overeenkomen met het 25e, 50e en 75e percentiel van de reekslengtes uit Amazon Redshift-vloottelemetrie. We hebben deze gegevens twee keer in Amazon Redshift geladen, waarbij we deze in één geval hebben gecodeerd met behulp van LZO-compressie en in een ander geval met BYTEDICT-compressie. Ten slotte hebben we de prestaties gemeten van zoekopdrachten die veel scannen en die veel rijen (90% van de tabel), een gemiddeld aantal rijen (50% van de tabel) en enkele rijen (1% van de tabel) retourneren boven deze lage waarden. -kardinaliteitsreeksgegevenssets. De prestatieresultaten zijn samengevat in het volgende diagram.

Zoekopdrachten met predikaten die overeenkomen met een hoog percentage rijen zagen verbeteringen van 5 tot 30 keer met de nieuwe gevectoriseerde BYTEDICT-codering vergeleken met LZO, terwijl zoekopdrachten met predikaten die overeenkomen met een laag percentage rijen verbeteringen van 10 tot 63 keer zagen in deze interne benchmark.
Redshift Serverloze prijs-prestatieverhouding
Naast de prestatieresultaten met hoge gelijktijdigheid die in dit bericht worden gepresenteerd, hebben we ook de van TPC-DS afgeleide Cloud Data Warehouse-benchmark gebruikt om de prijs-prestaties van Redshift Serverless te vergelijken met andere datawarehouses die een grotere dataset van 3 TB gebruiken. We kozen voor datawarehouses met een vergelijkbare prijs, in dit geval binnen 10% van $32 per uur, waarbij gebruik werd gemaakt van openbaar beschikbare on-demand prijzen. Deze resultaten laten zien dat Redshift Serverless, net als Amazon Redshift RA3-instances, betere prijs-prestaties levert in vergelijking met andere toonaangevende clouddatawarehouses. Zoals altijd kunnen deze resultaten worden gerepliceerd met behulp van onze SQL-scripts in onze GitHub-repository.

We moedigen je aan om Amazon Redshift te proberen met je eigen versie proof of concept voor workloads als de beste manier om te zien hoe Amazon Redshift aan uw behoeften op het gebied van data-analyse kan voldoen.
Vind de beste prijs-prestatieverhouding voor uw workloads
De benchmarks die in dit bericht worden gebruikt, zijn afgeleid van de industriestandaard TPC-DS-benchmark en hebben de volgende kenmerken:
- Het schema en de gegevens worden ongewijzigd gebruikt vanuit TPC-DS.
- De query's worden gegenereerd met behulp van de officiële TPC-DS-kit, waarbij queryparameters worden gegenereerd met behulp van de standaard willekeurige kiem van de TPC-DS-kit. Door TPC goedgekeurde queryvarianten worden gebruikt voor een magazijn als het magazijn het SQL-dialect van de standaard TPC-DS-query niet ondersteunt.
- De test omvat de 99 TPC-DS SELECT-query's. Het omvat geen stappen voor onderhoud en doorvoer.
- Voor de gelijktijdigheidstest van 3 TB zijn drie stroomruns uitgevoerd, en voor elk datawarehouse is de beste run genomen.
- De prijs-prestatieverhouding voor de TPC-DS-query's wordt berekend als de kosten per uur (USD) maal de benchmarkruntime in uren, wat gelijk is aan de kosten voor het uitvoeren van de benchmark. De laatst gepubliceerde prijzen op aanvraag worden gebruikt voor alle datawarehouses en niet voor de prijzen voor gereserveerde exemplaren, zoals eerder vermeld.
We noemen dit de Cloud Data Warehouse-benchmark en u kunt de voorgaande benchmarkresultaten eenvoudig reproduceren met behulp van de scripts, queries en gegevens die beschikbaar zijn in onze GitHub-repository. Het is afgeleid van de TPC-DS-benchmarks zoals beschreven in dit bericht en is als zodanig niet vergelijkbaar met gepubliceerde TPC-DS-resultaten, omdat de resultaten van onze tests niet voldoen aan de officiële specificatie.
Conclusie
Amazon Redshift streeft ernaar de beste prijs-kwaliteitverhouding in de branche te leveren voor de breedste verscheidenheid aan werklasten. Redshift Serverless schaalt lineair met de beste (laagste) prijs-prestatieverhouding en ondersteunt honderden gelijktijdige gebruikers met behoud van consistente responstijden voor vragen. Op basis van de testresultaten die in dit bericht worden besproken, heeft Amazon Redshift tot 2.6 keer betere prijs-prestaties bij hetzelfde niveau van gelijktijdigheid vergeleken met de dichtstbijzijnde concurrent (concurrent B). Zoals eerder vermeld, geeft het gebruik van Reserved Instances met de 3-jarige all-upfront-optie u de laagste kosten voor het uitvoeren van Amazon Redshift, wat resulteert in een nog betere relatieve prijs-prestatieverhouding vergeleken met de on-demand instance-prijzen die we in dit bericht hebben gebruikt. Onze benadering van continue prestatieverbetering omvat een unieke combinatie van de obsessie van klanten om gebruiksscenario's van klanten en de bijbehorende knelpunten in de schaalbaarheid te begrijpen, gekoppeld aan continue analyse van wagenparkgegevens om kansen te identificeren om aanzienlijke prestatie-optimalisaties door te voeren.
Elke werklast heeft unieke kenmerken, dus als u net begint: a proof of concept voor is de beste manier om te begrijpen hoe Amazon Redshift uw kosten kan verlagen en tegelijkertijd betere prestaties kan leveren. Wanneer u uw eigen proof of concept uitvoert, is het belangrijk om u te concentreren op de juiste statistieken: querydoorvoer (aantal query's per uur), responstijd en prijs-prestatieverhouding. U kunt een datagestuurde beslissing nemen door zelf een proof of concept uit te voeren met assistentie van AWS of een systeemintegratie- en adviespartner.
Volg de om op de hoogte te blijven van de laatste ontwikkelingen in Amazon Redshift Wat is er nieuw in Amazon Redshift voeden.
Over de auteurs
 Stefan Gromoll is een Senior Performance Engineer bij het Amazon Redshift-team, waar hij verantwoordelijk is voor het meten en verbeteren van de Redshift-prestaties. In zijn vrije tijd houdt hij van koken, spelen met zijn drie jongens en brandhout hakken.
Stefan Gromoll is een Senior Performance Engineer bij het Amazon Redshift-team, waar hij verantwoordelijk is voor het meten en verbeteren van de Redshift-prestaties. In zijn vrije tijd houdt hij van koken, spelen met zijn drie jongens en brandhout hakken.
 Ravi Animi is een Senior Product Management-leider in het Amazon Redshift-team en beheert verschillende functionele gebieden van de Amazon Redshift-clouddatawarehouse-service, waaronder prestaties, ruimtelijke analyses, streaming-opname en migratiestrategieën. Hij heeft ervaring met relationele databases, multidimensionale databases, IoT-technologieën, opslag- en computerinfrastructuurdiensten en meer recentelijk als oprichter van een startup met behulp van AI/deep learning, computervisie en robotica.
Ravi Animi is een Senior Product Management-leider in het Amazon Redshift-team en beheert verschillende functionele gebieden van de Amazon Redshift-clouddatawarehouse-service, waaronder prestaties, ruimtelijke analyses, streaming-opname en migratiestrategieën. Hij heeft ervaring met relationele databases, multidimensionale databases, IoT-technologieën, opslag- en computerinfrastructuurdiensten en meer recentelijk als oprichter van een startup met behulp van AI/deep learning, computervisie en robotica.
 Aamer Sjah is een Senior Engineer in het Amazon Redshift Service-team.
Aamer Sjah is een Senior Engineer in het Amazon Redshift Service-team.
 Sanket Hase is een Software Development Manager in het Amazon Redshift Service-team.
Sanket Hase is een Software Development Manager in het Amazon Redshift Service-team.
 Orestis Polychroniou is een hoofdingenieur in het Amazon Redshift Service-team.
Orestis Polychroniou is een hoofdingenieur in het Amazon Redshift Service-team.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- : heeft
- :is
- :niet
- :waar
- $UP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- in staat
- Over
- versnelt
- toegang
- geraadpleegde
- Bereikt
- over
- toegevoegd
- toe te voegen
- toevoeging
- Extra
- vergevorderd
- Voordeel
- veroorloofd
- tegen
- algoritmen
- Alles
- toestaat
- ook
- alternatief
- alternatieven
- Hoewel
- altijd
- Amazone
- Amazon Web Services
- bedragen
- an
- analyse
- analytics
- het analyseren van
- en
- Nog een
- elke
- toepassingen
- Het toepassen van
- nadering
- ZIJN
- gebieden
- rond
- AS
- verschijning
- geassocieerd
- At
- aandacht
- auto
- geautomatiseerde
- Automatisch
- webmaster.
- Beschikbaar
- gemiddelde
- AWS
- b
- bandbreedte
- gebaseerde
- BE
- omdat
- vaardigheden
- beginnen
- wezen
- criterium
- benchmarks
- voordeel
- BEST
- Betere
- tussen
- Verder
- miljarden
- zowel
- knelpunten
- Box camera's
- brengen
- breed
- bedrijfsdeskundigen
- business intelligence
- druk
- maar
- by
- CAKE
- berekend
- berekening
- Bellen
- CAN
- mogelijkheden
- geval
- gevallen
- kenmerken
- gekarakteriseerde
- tabel
- hakken
- koos
- Plaats
- Cloud
- TROS
- Kolom
- columns
- combinatie van
- toegewijd
- Gemeen
- vergelijkbaar
- vergelijken
- vergeleken
- vergelijken
- concurrent
- concurrenten
- complex
- voldoen
- Berekenen
- computer
- Computer visie
- concept
- gelijktijdig
- voorwaarde
- uitgevoerd
- consequent
- troosten
- constante
- permanent
- vormen
- consulting
- bevatten
- permanent
- voortzetten
- blijft
- doorlopend
- doorlopend
- koken
- Overeenkomend
- Kosten
- Kosten
- gepaard
- en je merk te creëren
- cruciaal
- klant
- Klanten
- dashboards
- dashboards
- gegevens
- gegevensanalyse
- gegevens Analytics
- gegevensverwerking
- gegevensset
- datawarehouse
- data warehouses
- Gegevensgestuurde
- Database
- databanken
- datasets
- Datum
- beslissing
- Standaard
- bepalen
- leveren
- het leveren van
- levert
- Afgeleid
- beschreven
- ontworpen
- gewenste
- detail
- gedetailleerd
- Ontwikkeling
- ontwikkelingen
- anders
- direct
- bespreken
- besproken
- Verscheidenheid
- verdelen
- do
- doet
- Nee
- Dont
- gedreven
- elk
- Vroeger
- gemakkelijk
- eten
- effectief
- doeltreffend
- efficiënt
- ingeschakeld
- waardoor
- aanmoedigen
- Motor
- ingenieur
- verbeterde
- enhancement
- uitbreidingen
- Enter
- Gelijkwaardig
- vooral
- Ether (ETH)
- evaluaties
- Zelfs
- alles
- voorbeeld
- voorbeelden
- verwachten
- ervaring
- extract
- factor
- vertrouwd
- ver
- SNELLE
- sneller
- Kenmerk
- weinig
- Tot slot
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- afmaken
- Voornaam*
- VLOOT
- Focus
- volgen
- volgend
- Voor
- gevonden
- oprichter
- oppompen van
- functioneel
- verder
- voor algemeen gebruik
- gegenereerde
- generatie
- krijgen
- het krijgen van
- GitHub
- geeft
- gaan
- goed
- Groeiend
- Groeit
- handvat
- Hardware
- Hebben
- met
- he
- Hoge
- hoger
- zijn
- houden
- bezit
- uur
- HOURS
- Hoe
- HTML
- http
- HTTPS
- honderd
- Honderden
- ideaal
- ideaal
- identificeren
- if
- illustreren
- beeld
- Impact
- belangrijk
- belangrijk aspect
- verbeteren
- verbeterd
- verbetering
- verbeteringen
- het verbeteren van
- in
- omvatten
- omvat
- Inclusief
- Laat uw omzet
- meer
- Verhoogt
- geeft aan
- industrie
- Infrastructuur
- instantie
- gevallen
- integratie
- Intelligentie
- interactieve
- intern
- tussenkomst
- in
- geïntroduceerd
- de invoering
- investering
- gaat
- iot
- IT
- HAAR
- mee
- jpg
- voor slechts
- Houden
- uitrusting
- Weten
- Groot
- groter
- later
- laatste
- laatste ontwikkelingen
- gelanceerd
- lancering
- leider
- leidend
- leren
- minst
- minder
- Niveau
- lichtgewicht
- als
- Elke kleine stap levert grote resultaten op!
- laden
- het laden
- ladingen
- gelegen
- lang
- langer
- Kijk
- op zoek
- Laag
- te verlagen
- laagste
- onderhouden
- behoud van
- onderhoud
- Meerderheid
- maken
- beheerd
- management
- manager
- beheert
- handboek
- veel
- Match
- Zaken
- Mei..
- betekenis
- middel
- maatregel
- afgemeten
- het meten van
- Medium
- Maak kennis met
- Geheugen
- vermeld
- macht
- migratie
- minuten
- Modern
- maandag
- geld
- meer
- Bovendien
- meest
- veel
- namelijk
- Noodzaak
- nodig
- behoeften
- New
- New York
- new york city
- onlangs
- volgende
- geen
- nota
- bekend
- opmerkend
- nu
- aantal
- of
- officieel
- vaak
- on
- On-Demand
- EEN
- Slechts
- besturen
- bediend
- Kansen
- optimale
- optimalisatie
- optimaliseren
- Keuze
- Opties
- or
- Overige
- onze
- uit
- over
- het te bezitten.
- parameters
- bijzonder
- Patronen
- patronen
- Betaal
- betaling
- voor
- percentage
- prestatie
- planning
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- spelen
- punt
- Populair
- mogelijk
- Post
- energie
- Voorspelbaar
- gepresenteerd
- voorkomt
- prijs
- prijsstelling
- Principal
- verwerkt
- verwerking
- Product
- product management
- bewijs
- proof of concept voor
- zorgen voor
- in het openbaar
- gepubliceerde
- gekocht
- queries
- snel
- willekeurige
- Lees
- echte wereld
- real-time
- ontvangen
- recent
- onlangs
- aanbevelingen
- referenties
- regio
- Afgekeurd..
- relatief
- relatief
- het verwijderen van
- herhaald
- herhalende
- gerepliceerd
- Rapporten
- vertegenwoordiger
- vertegenwoordigen
- vereisen
- gereserveerd
- antwoord
- verantwoordelijk
- verkregen
- Resultaten
- <HR>Retail
- terugkeer
- inkomsten
- beoordelen
- rechts
- robotica
- ROI
- lopen
- lopend
- loopt
- verkoop
- dezelfde
- Bespaar
- zagen
- Schaalbaarheid
- Scale
- balans
- scaling
- scant
- schema
- scripts
- Tweede
- seconden
- sectie
- zien
- zaad
- senior
- dienen
- Serverless
- service
- Diensten
- reeks
- setup
- verscheidene
- Delen
- Bermuda's
- moet
- tonen
- getoond
- aanzienlijke
- aanzienlijk
- evenzo
- Eenvoudig
- gelijktijdig
- single
- Maat
- sized
- Klein
- So
- Software
- software development
- ruimtelijke
- specificatie
- gespecificeerd
- snelheid
- besteden
- besteed
- aar
- SQL
- begin
- gestart
- startup
- blijven
- gestaag
- Stappen
- mediaopslag
- winkels
- eenvoudig
- strategieën
- stream
- streaming
- Draad
- voorleggen
- dergelijk
- geschiktheid
- ondersteuning
- Ondersteuning
- system
- tafel
- Nemen
- ingenomen
- team
- technieken
- Technologies
- vertellen
- tienen
- proef
- testen
- neem contact
- dat
- De
- hun
- harte
- Er.
- daarom
- Deze
- ze
- denken
- dit
- die
- duizenden kosten
- drie
- doorvoer
- niet de tijd of
- keer
- naar
- vandaag
- Totaal
- verkeer
- Transformeren
- transparant
- proberen
- proberen
- Twee keer
- twee
- type dan:
- types
- typisch
- alomtegenwoordig
- niet in staat
- Uncommon
- begrijpen
- unieke
- onvoorspelbaar
- tot
- us
- Gebruik
- USD
- .
- use case
- gebruikt
- Gebruiker
- gebruikers
- toepassingen
- gebruik
- Values
- variëteit
- divers
- zeer
- .
- virtueel
- visie
- wachten
- willen
- Magazijn
- was
- Manier..
- manieren
- we
- web
- webservices
- week
- GOED
- waren
- Wat
- wanneer
- terwijl
- welke
- en
- Waarom
- breed
- wil
- Met
- binnen
- zonder
- waard
- zou
- het schrijven van
- schreef
- york
- u
- Your
- zephyrnet