작성자 별 이미지
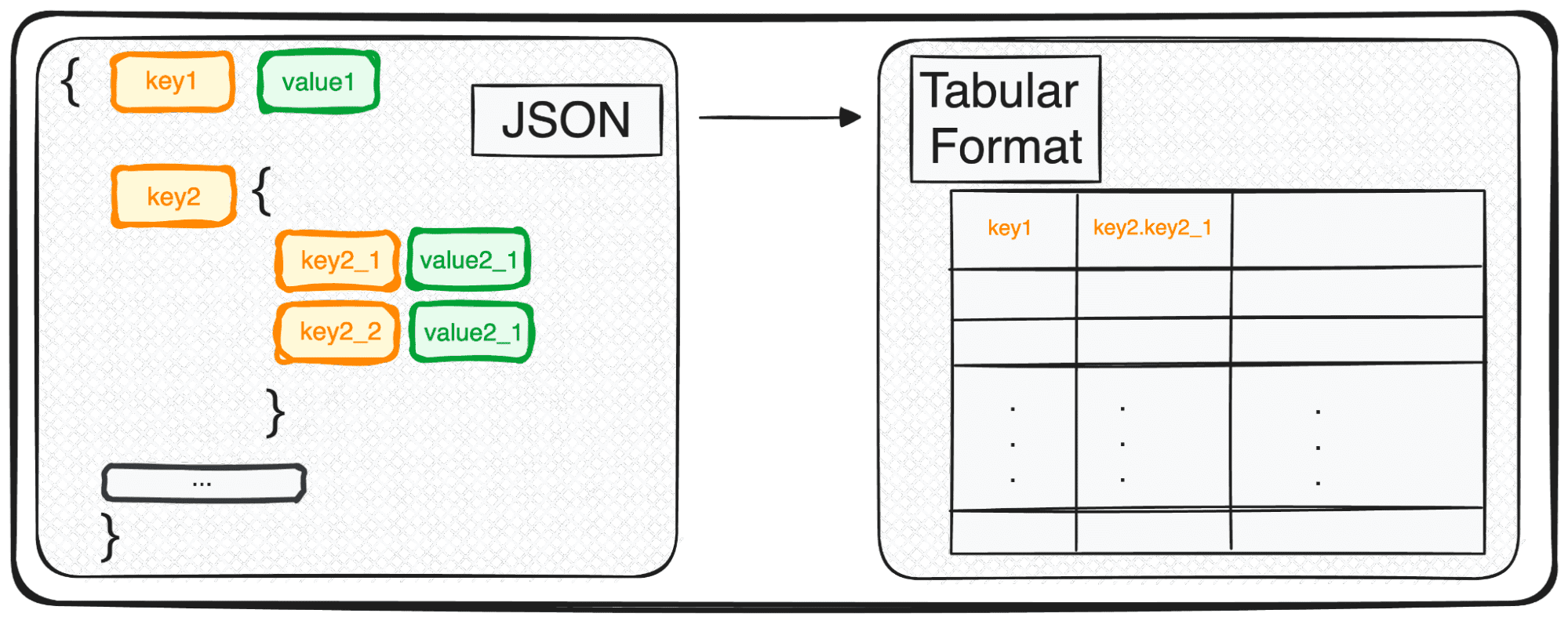
데이터 과학 및 기계 학습의 세계에 뛰어들면서 접하게 될 기본 기술 중 하나는 데이터를 읽는 기술입니다. 이미 경험이 있다면 데이터 저장 및 교환에 널리 사용되는 형식인 JSON(JavaScript Object Notation)에 익숙할 것입니다.
MongoDB와 같은 NoSQL 데이터베이스가 JSON에 데이터를 저장하는 것을 좋아하는지, REST API가 종종 동일한 형식으로 응답하는지 생각해 보세요.
그러나 JSON은 저장 및 교환에 적합하지만 원시 형식의 심층 분석에는 아직 준비가 되어 있지 않습니다. 여기에서 이를 좀 더 분석적으로 친숙한 표 형식으로 변환합니다.
따라서 단일 JSON 개체를 처리하든, 그 개체의 멋진 배열을 처리하든, Python의 관점에서 보면 기본적으로 사전 또는 사전 목록을 처리하게 됩니다.
이러한 변환이 어떻게 전개되어 데이터를 분석하기에 적합하게 만드는지 함께 살펴보겠습니다.
오늘은 JSON을 몇 초 만에 표 형식으로 쉽게 구문 분석할 수 있는 마법의 명령에 대해 설명하겠습니다.
그리고 그것은… pd.json_normalize()
그럼 다양한 유형의 JSON에서 어떻게 작동하는지 살펴보겠습니다.
우리가 사용할 수 있는 첫 번째 JSON 유형은 몇 가지 키와 값이 있는 단일 수준 JSON입니다. 첫 번째 간단한 JSON을 다음과 같이 정의합니다.
작성자 별 코드
이제 이러한 JSON을 사용하여 작업해야 하는 필요성을 시뮬레이션해 보겠습니다. 우리 모두는 JSON 형식으로 할 수 있는 일이 많지 않다는 것을 알고 있습니다. 우리는 이러한 JSON을 읽기 쉽고 수정 가능한 형식으로 변환해야 합니다. 이는 Pandas DataFrames를 의미합니다!
1.1 간단한 JSON 구조 다루기
먼저 pandas 라이브러리를 가져와야 하며 다음과 같이 pd.json_normalize() 명령을 사용할 수 있습니다.
import pandas as pd
pd.json_normalize(json_string)
단일 레코드가 있는 JSON에 이 명령을 적용하면 가장 기본적인 테이블을 얻을 수 있습니다. 그러나 데이터가 조금 더 복잡하고 JSON 목록을 제공하는 경우 더 이상 복잡하지 않게 동일한 명령을 사용할 수 있으며 출력은 여러 레코드가 있는 테이블에 해당합니다.

작성자 별 이미지
쉬워요… 그렇죠?
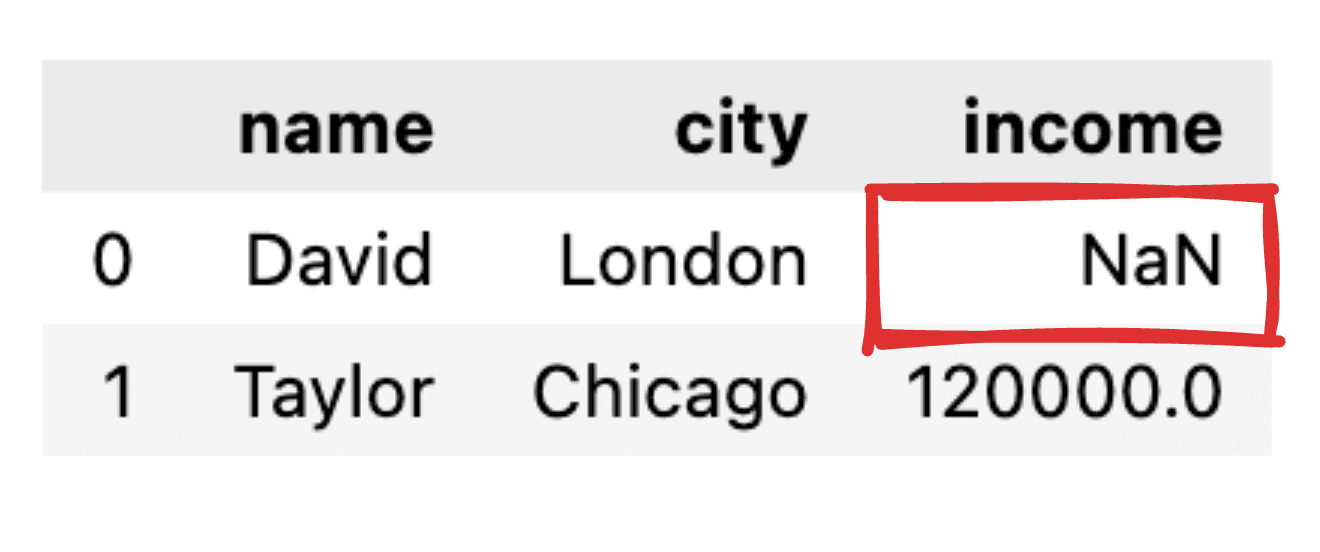
다음 자연스러운 질문은 일부 값이 누락되면 어떻게 되는지입니다.
1.2 널 값 다루기
예를 들어 David의 소득 기록이 누락된 경우와 같이 일부 값에 정보가 제공되지 않는다고 가정해 보겠습니다. JSON을 간단한 pandas 데이터 프레임으로 변환하면 해당 값이 NaN으로 표시됩니다.
작성자 별 이미지
그리고 일부 필드만 가져오려면 어떻게 해야 합니까?
1.3 관심 있는 컬럼만 선택
일부 특정 필드를 테이블 형식의 pandas DataFrame으로 변환하려는 경우 json_normalize() 명령을 사용하면 변환할 필드를 선택할 수 없습니다.
따라서 관심 있는 열만 필터링하는 JSON의 작은 전처리를 수행해야 합니다.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
이제 좀 더 발전된 JSON 구조로 넘어가 보겠습니다.
다중 레벨 JSON을 처리할 때 다양한 레벨 내에 중첩된 JSON이 있다는 것을 알게 됩니다. 절차는 이전과 동일하지만 이 경우 변환할 레벨 수를 선택할 수 있습니다. 기본적으로 이 명령은 항상 모든 수준을 확장하고 모든 중첩 수준의 연결된 이름을 포함하는 새 열을 생성합니다.
따라서 다음 JSON을 정규화하면.
작성자 별 코드
필드 기술 아래에 3개의 열이 있는 다음 표를 얻을 수 있습니다.
- 기술.파이썬
- 기술.SQL
- 기술.GCP
필드 역할 아래에 4개의 열이 있습니다.
- 역할.프로젝트 관리자
- 역할.데이터 엔지니어
- 역할.데이터 과학자
- 역할.데이터 분석가

작성자 별 이미지
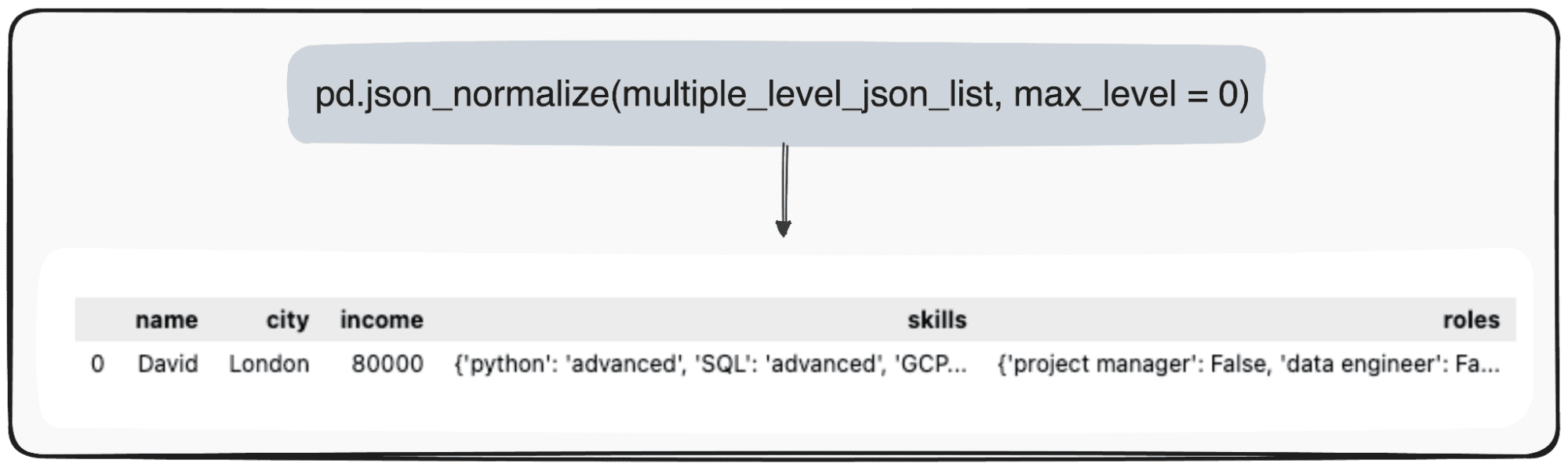
그러나 우리가 단지 최상위 수준을 변화시키고 싶다고 상상해 보십시오. max_level 매개변수를 0(확장하려는 max_level)으로 구체적으로 정의하여 그렇게 할 수 있습니다.
pd.json_normalize(mutliple_level_json_list, max_level = 0)
보류 중인 값은 Pandas DataFrame 내의 JSON 내에 유지됩니다.
작성자 별 이미지
우리가 찾을 수 있는 마지막 사례는 JSON 필드 내에 중첩된 목록이 있는 경우입니다. 따라서 먼저 사용할 JSON을 정의합니다.
작성자 별 코드
Python의 Pandas를 사용하여 이 데이터를 효과적으로 관리할 수 있습니다. pd.json_normalize() 함수는 이러한 맥락에서 특히 유용합니다. 중첩 목록을 포함한 JSON 데이터를 분석에 적합한 구조화된 형식으로 평면화할 수 있습니다. 이 함수가 JSON 데이터에 적용되면 중첩 목록을 해당 필드의 일부로 통합하는 정규화된 테이블이 생성됩니다.
게다가 Pandas는 이 프로세스를 더욱 개선할 수 있는 기능을 제공합니다. pd.json_normalize()의 Record_path 매개변수를 활용하면 함수가 중첩 목록을 구체적으로 정규화하도록 지시할 수 있습니다.
이 작업을 수행하면 목록 콘텐츠 전용 테이블이 생성됩니다. 기본적으로 이 프로세스는 목록 내의 요소만 펼칩니다. 그러나 각 레코드에 연결된 ID를 유지하는 등 추가 컨텍스트로 이 테이블을 강화하려면 메타 매개변수를 사용할 수 있습니다.

작성자 별 이미지
요약하면, Python의 Pandas 라이브러리를 사용하여 JSON 데이터를 CSV 파일로 변환하는 것은 쉽고 효과적입니다.
JSON은 현대 데이터 저장 및 교환, 특히 NoSQL 데이터베이스 및 REST API에서 여전히 가장 일반적인 형식입니다. 그러나 원시 형식의 데이터를 처리할 때 몇 가지 중요한 분석 과제가 있습니다.
Pandas의 pd.json_normalize()의 중추적인 역할은 이러한 형식을 처리하고 데이터를 pandas DataFrame으로 변환하는 훌륭한 방법으로 나타납니다.
이 가이드가 도움이 되었기를 바랍니다. 다음에 JSON을 다룰 때 더 효과적인 방법으로 사용할 수 있습니다.
다음에서 해당 Jupyter Notebook을 확인할 수 있습니다. GitHub 레포를 따릅니다.
조셉 페레르 바르셀로나 출신의 분석 엔지니어입니다. 물리공학과를 졸업하고 현재 인간의 이동성을 응용한 데이터 사이언스 분야에서 일하고 있다. 그는 데이터 과학 및 기술에 중점을 둔 파트 타임 콘텐츠 제작자입니다. 당신은 그에게 연락 할 수 있습니다 링크드인, 트위터 or 중급.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :이다
- :아니
- :어디
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- 소개
- 동작
- 추가
- 많은
- All
- 수
- 수
- 이미
- 항상
- an
- 분석
- 분석자
- 분석
- 분석
- 및
- 어떤
- API
- 표시
- 적용된
- 적용
- 있군요
- 배열
- 미술
- AS
- 관련
- 바르셀로나
- 기본
- BE
- 전에
- 비트
- 두
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- CAN
- 능력
- 케이스
- 과제
- 검사
- 왼쪽 메뉴에서
- City
- 열
- 공통의
- 복잡한
- 합병증
- CONTACT
- 함유량
- 내용
- 문맥
- 변하게 하다
- 변환
- 해당
- 동
- 창조자
- 현재
- 데이터
- 데이터 분석가
- 데이터 엔지니어
- 데이터 과학
- 데이터 과학자
- 데이터 저장
- 데이터베이스
- 데이비드
- 취급
- 전용
- 태만
- 밝히다
- 정의
- 매우 기쁜
- DICT
- 다른
- 곧장
- do
- 하지
- 마다
- 용이하게
- 쉽게
- 유효한
- 효과적으로
- 요소
- 나온다.
- 교전
- 기사
- 엔지니어링
- 높이다
- 본질적으로
- 교환
- 교환
- 독점적으로
- 펼치기
- 경험
- 설명
- 탐험
- 익숙한
- 를
- 들
- Fields
- 파일
- 필터링
- Find
- 먼저,
- 집중
- 수행원
- 다음
- 럭셔리
- 형태
- 체재
- 친절한
- 에
- 기능
- 기본적인
- 추가
- GCP
- 생성
- 얻을
- GitHub의
- Go
- 큰
- 안내
- 핸들
- 처리
- 발생
- 있다
- 데
- he
- 그를
- 기대
- 방법
- 그러나
- HTTPS
- 사람의
- i
- 악
- ID
- if
- 그림
- import
- 중대한
- in
- 심도
- 포함
- 포함
- 수입
- 통합
- 정보
- 예
- 관심
- 으로
- Isn
- IT
- 그
- 자바 스크립트
- JSON
- 주피터 수첩
- 다만
- 너 겟츠
- 키
- 키
- 알아
- 성
- 배우기
- 레벨
- 레벨
- 도서관
- 처럼
- 링크드인
- 명부
- 작은
- ll
- 애정
- 기계
- 기계 학습
- 마법
- 유지
- 유튜브 영상을 만드는 것은
- 관리
- 매니저
- .
- 방법
- 메타
- 누락
- 유동성
- 현대
- MongoDB의
- 배우기
- 가장
- 움직임
- 많은
- 여러
- name
- 자연의
- 필요
- 중첩
- 신제품
- 다음 것
- 아니
- 특히
- 수첩
- 대상
- 획득
- of
- 제공
- 자주
- on
- ONE
- 만
- or
- 우리의
- 우리 스스로
- 출력
- 팬더
- 매개 변수
- 부품
- 특별히
- 대기
- 완전한
- 수행
- 물리학
- 추축의
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 인기 문서
- 선물
- 아마
- 순서
- 방법
- 생산하다
- 프로젝트
- Python
- 문제
- 아주
- 살갗이 벗어 진
- RE
- 읽기
- 준비
- 기록
- 기록
- 수정하다
- 응답
- REST
- 결과
- 유지
- 연락해주세요
- 직위별
- s
- 같은
- 과학
- 과학 기술
- 과학자
- 초
- 참조
- 선택
- 영상을
- 단순, 간단, 편리
- 시뮬레이션하다
- 단일
- 기술
- 작은
- So
- 일부
- 무언가
- 구체적인
- 구체적으로
- SQL
- 아직도
- 저장
- 저장
- 구조
- 구조화
- 이러한
- 적당한
- 개요
- T
- 테이블
- Technology
- 조건
- 그
- XNUMXD덴탈의
- 세계
- 그들의
- 그들
- 그때
- Bowman의
- 이
- 그
- 시간
- 에
- 함께
- 상단
- 변환
- 변환
- 변화
- 유형
- 유형
- 아래에
- us
- 사용
- 유용
- 사용
- 활용
- 가치
- 마케팅은:
- 필요
- 였다
- 방법..
- we
- 뭐
- 언제
- 여부
- 어느
- 동안
- 의지
- 과
- 이내
- 작업
- 일하는
- 일
- 세계
- 겠지
- 당신
- 제퍼 넷




