Roblox が過去 16 年以上にわたって成長するにつれて、何百万もの没入型 3D 共同体験をサポートする技術インフラストラクチャの規模と複雑さも増大しました。 当社がサポートするマシンの数は過去 36,000 年間で 30 倍以上に増加し、2021 年 145,000 月 1,000 日時点で約 XNUMX 台から、現在では約 XNUMX 台となっています。 世界中の人々にこれらの常時接続エクスペリエンスをサポートするには、XNUMX を超える内部サービスが必要です。 コストとネットワーク遅延を制御できるように、当社ではこれらのマシンを、主にオンプレミスで実行されるカスタム構築されたハイブリッド プライベート クラウド インフラストラクチャの一部として展開および管理しています。
当社のインフラストラクチャは現在、Roblox に依存しているクリエイターを含む、世界中で 70 万人を超える毎日のアクティブ ユーザーをサポートしています。 経済 彼らのビジネスのために。 これら何百万人もの人々は皆、非常に高いレベルの信頼性を期待しています。 私たちの体験の没入型の性質を考えると、遅延はもちろん、停止はもちろんのこと、遅延や遅延に対する許容度も非常に低くなります。 Roblox は、没入型 3D 体験で人々が集まる、コミュニケーションとつながりのためのプラットフォームです。 人々が没入型空間で自分のアバターとしてコミュニケーションをとっている場合、わずかな遅延や不具合であっても、テキスト スレッドや電話会議よりも目立ちます。
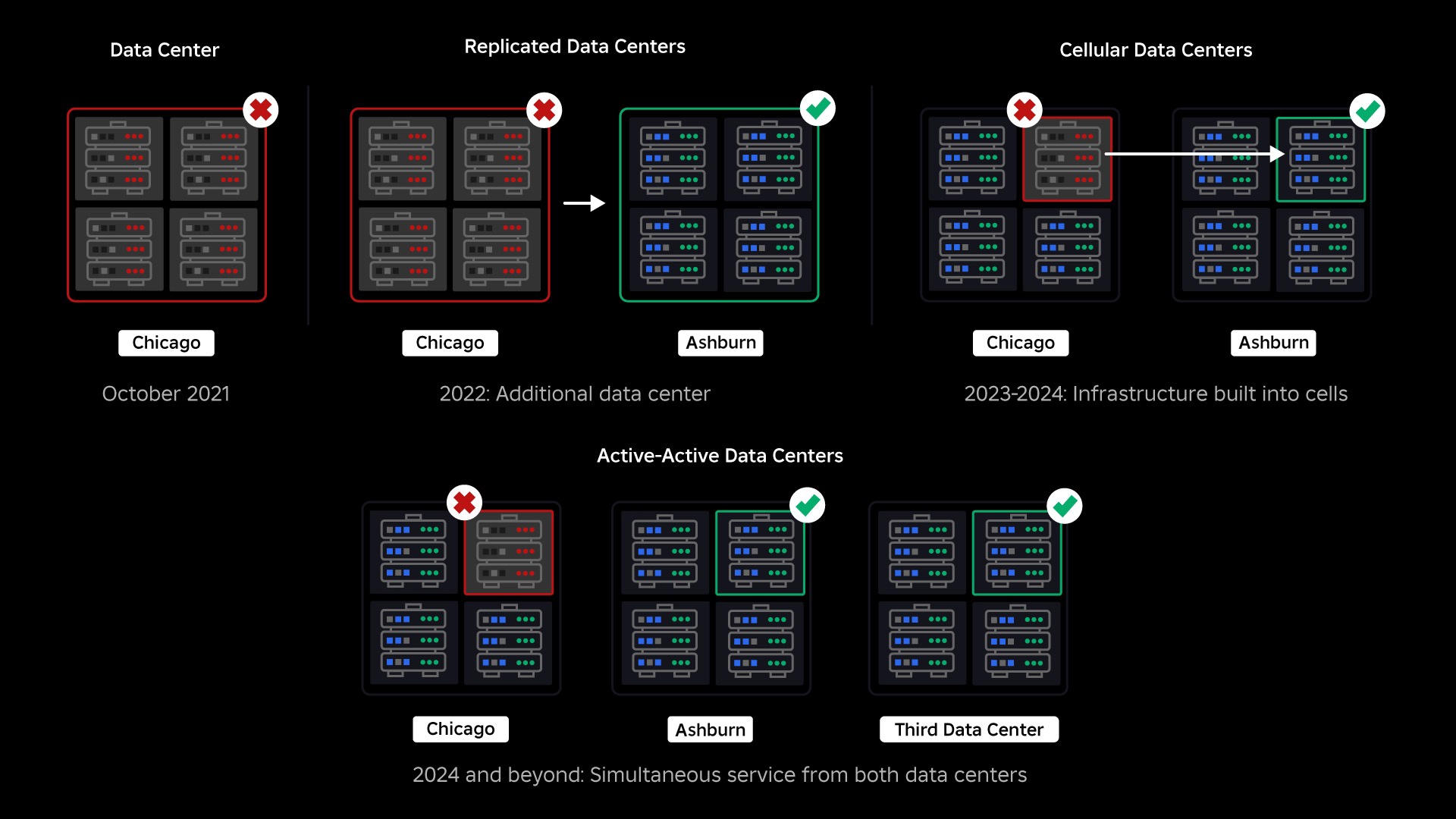
2021 年 73 月にシステム全体の停止が発生しました。 始まりは小規模で、XNUMX つのデータセンターの XNUMX つのコンポーネントに問題が発生しました。 しかし、私たちが調査している間に感染は急速に広がり、最終的には XNUMX 時間の停止につながりました。 当時は両方を共有していました 何が起こったのかについての詳細 この問題から得た初期の教訓のいくつか。 それ以来、私たちはこれらの教訓を研究し、極端なトラフィックの急増、天候、ハードウェア障害、ソフトウェアのバグなどの要因によってすべての大規模システムで発生する種類の障害に対するインフラストラクチャの回復力を高めることに取り組んできました。人間は間違いを犯します。 このような障害が発生した場合、単一のコンポーネントまたはコンポーネントのグループの問題がシステム全体に広がらないようにするにはどうすればよいでしょうか? この問題は過去 2023 年間私たちが焦点を当ててきたもので、作業は進行中ですが、これまでの取り組みはすでに成果を上げています。 たとえば、125 年上半期では、2022 年上半期と比較して、月間 XNUMX 億 XNUMX 万時間のエンゲージメント時間を節約できました。今日、私たちはこれまでに行った作業と、構築に関する長期的なビジョンを共有します。より復元力の高いインフラストラクチャ システム。
バックストップの構築
大規模なインフラ システムでは、小規模な障害が XNUMX 日に何度も発生します。 XNUMX 台のマシンに問題が発生し、サービスを停止する必要がある場合でも、ほとんどの企業はバックエンド サービスの複数のインスタンスを維持しているため、対処可能です。 したがって、XNUMX つのインスタンスに障害が発生すると、他のインスタンスがワークロードを引き継ぎます。 これらの頻繁な失敗に対処するために、リクエストは通常、エラーが発生した場合に自動的に再試行するように設定されています。
システムまたはユーザーがあまりにも積極的に再試行すると、これが困難になり、小規模な障害がインフラストラクチャ全体で他のサービスやシステムに伝播する可能性があります。 ネットワークまたはユーザーが何度も再試行を続けると、最終的にはそのサービスのすべてのインスタンス、および場合によっては他のシステムもグローバルに過負荷になります。 2021 年のシステム停止は、大規模システムではよくある現象の結果でした。障害は小さく始まり、システム全体に伝播し、すぐに大きくなり、すべてがダウンする前に解決するのが困難です。
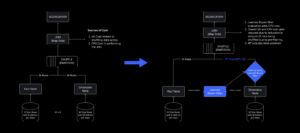
障害が発生した時点では、アクティブなデータ センターが XNUMX つありました (その中のコンポーネントがバックアップとして機能していました)。 問題により既存のデータセンターがダウンした場合に、新しいデータセンターに手動でフェイルオーバーできる機能が必要でした。 私たちの最優先事項は、Roblox のバックアップ展開を確保することでした。そのため、地理的に異なる地域にある新しいデータセンターにバックアップを構築しました。 これにより、データセンター内の十分なコンポーネントに停止が広がり、完全に動作不能になるという最悪のシナリオに対する保護が追加されました。 現在、ワークロードを処理する XNUMX つのデータセンター (アクティブ) と、バックアップとして機能するスタンバイ (パッシブ) のデータセンターが XNUMX つあります。 私たちの長期的な目標は、このアクティブ/パッシブ構成から、両方のデータ センターがワークロードを処理し、ロード バランサーがレイテンシ、容量、健全性に基づいてそれらの間でリクエストを分散するアクティブ/アクティブ構成に移行することです。 これが導入されれば、Roblox 全体の信頼性がさらに高まり、数時間かかるのではなく、ほぼ瞬時にフェイルオーバーできるようになることが期待されます。 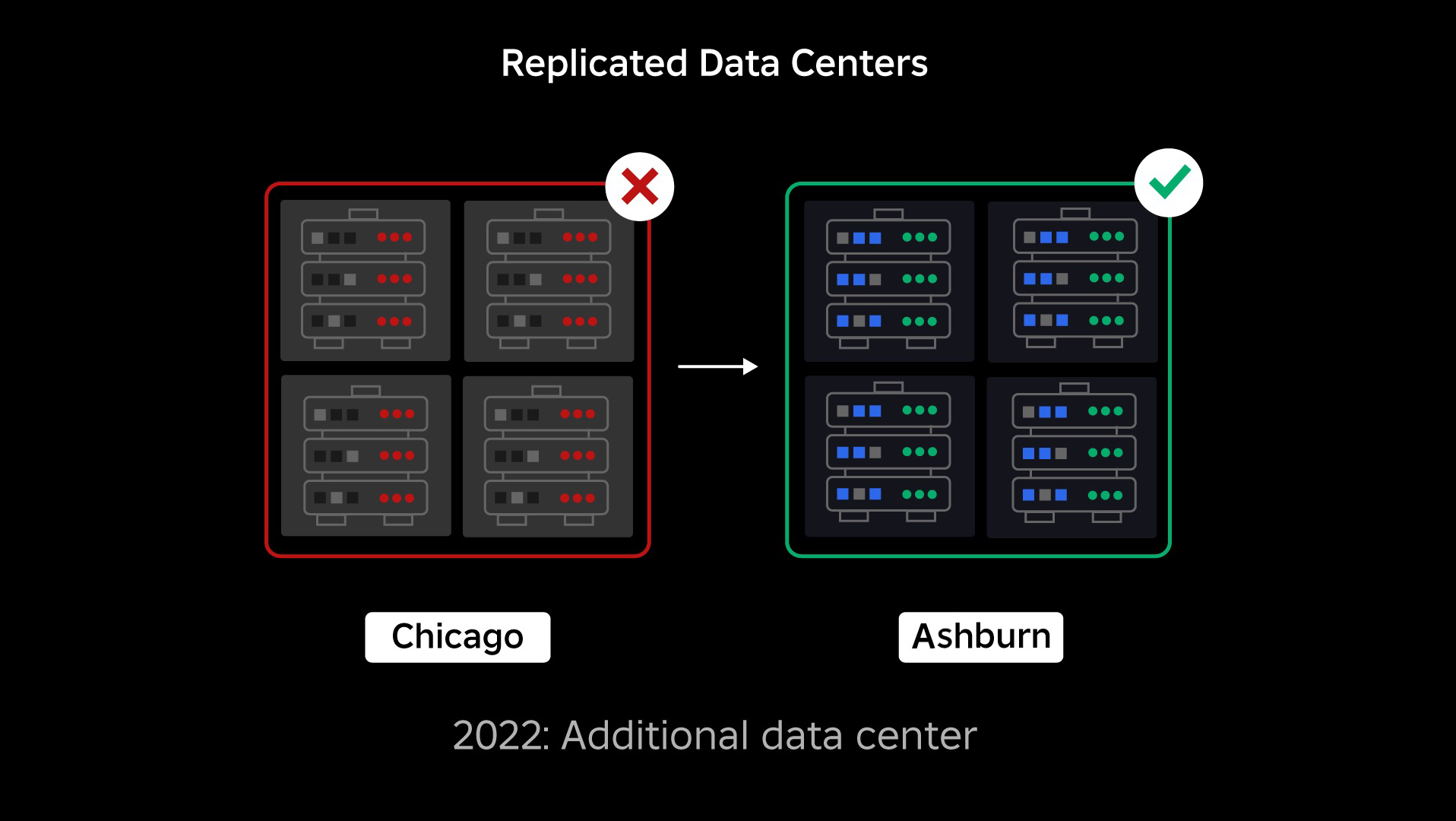
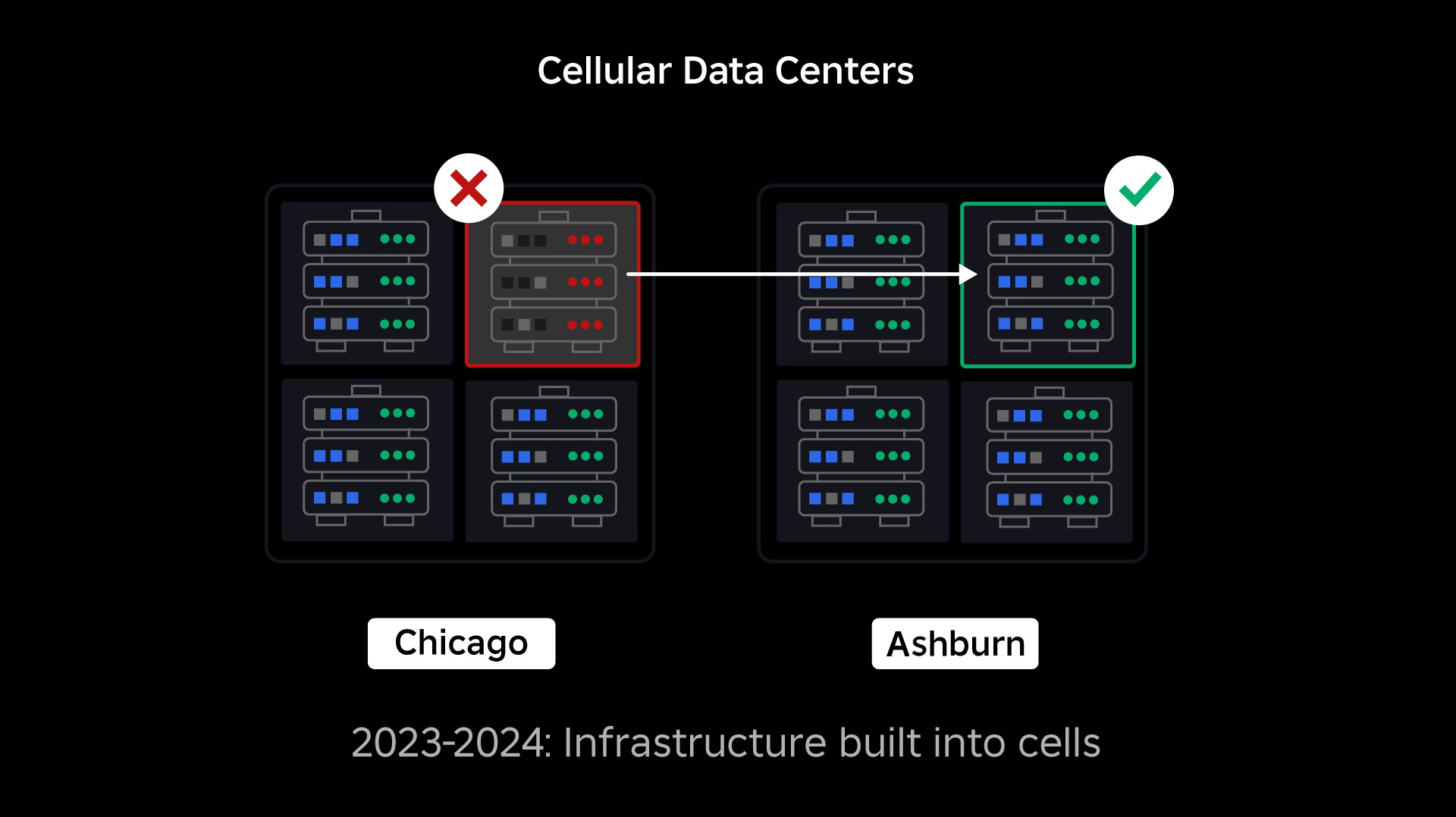
セルラーインフラへの移行
私たちの次の優先事項は、データセンター全体が故障する可能性を減らすために、各データセンター内に強力な爆破壁を構築することでした。 セル (一部の企業はクラスターと呼んでいます) は本質的に機械のセットであり、私たちがこれらの壁を作成する方法です。 冗長性を高めるために、セル内とセル間の両方でサービスを複製します。 最終的には、Roblox のすべてのサービスがセル内で実行され、強力なブラスト ウォールと冗長性の両方のメリットが得られるようにしたいと考えています。 セルが機能しなくなった場合は、安全に非アクティブ化できます。 セル間のレプリケーションにより、セルが修復されている間もサービスを実行し続けることができます。 場合によっては、セルの修復はセルの完全な再プロビジョニングを意味する場合があります。 業界全体で、個々のマシンまたは小規模なマシン セットをワイプして再プロビジョニングすることはかなり一般的ですが、約 1,400 台のマシンが含まれるセル全体に対してこれを行うことは一般的ではありません。
これが機能するには、これらのセルがほぼ均一である必要があり、ワークロードをあるセルから別のセルに迅速かつ効率的に移動できます。 サービスがセル内で実行される前に満たす必要がある特定の要件を設定しました。 たとえば、サービスはコンテナ化する必要があるため、サービスの移植性が大幅に向上し、OS レベルで構成を変更できなくなります。 私たちは、セルに対してコードとしてのインフラストラクチャの哲学を採用しています。ソース コード リポジトリには、セル内のすべての定義が含まれているため、自動ツールを使用してセルを最初から迅速に再構築できます。
現在、すべてのサービスがこれらの要件を満たしているわけではないため、サービス所有者が可能な限り要件を満たせるよう支援し、準備ができたらサービスをセルに簡単に移行できるようにする新しいツールを構築しました。 たとえば、新しいデプロイメント ツールは、サービス デプロイメントをセル間で自動的に「ストライプ化」するため、サービス所有者はレプリケーション戦略について考える必要がありません。 このレベルの厳格さにより、移行プロセスはより困難で時間がかかりますが、長期的な見返りは次のようなシステムになります。
- 障害を封じ込め、他のセルへの波及を防ぐ方がはるかに簡単です。
- 当社のインフラストラクチャ エンジニアはより効率的に、より迅速に行動できるようになります。 そして
- 最終的にセルにデプロイされる製品レベルのサービスを構築するエンジニアは、サービスがどのセルで実行されているかを知る必要も、心配する必要もありません。
より大きな課題を解決する
炎を封じ込めるために防火扉が使用されるのと同様に、セルはインフラ内で強力な防風壁として機能し、単一のセル内で障害を引き起こすあらゆる問題を封じ込めるのに役立ちます。 最終的には、Roblox を構成するすべてのサービスがセル内およびセル間で冗長的に展開されることになります。 この作業が完了しても、問題がセル全体を動作不能にするほど広範囲に伝播する可能性はありますが、問題がそのセルを超えて伝播することは非常に困難になります。 そして、細胞を交換可能にすることに成功すれば、回復は大幅に速くなるでしょう。 なぜなら、別のセルにフェイルオーバーして、問題がエンドユーザーに影響を与えないようにすることができるからです。
これが難しいのは、パフォーマンスと機能を維持しながら、エラーが伝播する機会を減らすためにこれらのセルを十分に分離することです。 複雑なインフラストラクチャ システムでは、サービスはクエリ、情報、ワークロードなどを共有するために相互に通信する必要があります。これらのサービスをセルに複製するとき、相互通信をどのように管理するかを考慮する必要があります。 理想的な世界では、トラフィックを XNUMX つの異常なセルから他の正常なセルにリダイレクトします。 しかし、私たちは「死の問い」にどのように対処すればよいのでしょうか。 原因 細胞が不健康になるのか? そのクエリを別のセルにリダイレクトすると、私たちが回避しようとしているとおりに、そのセルが異常になる可能性があります。 私たちは、セルを不健全にする原因となっているトラフィックを検出して抑制しながら、「良好な」トラフィックを不健全なセルから移動させるメカニズムを見つける必要があります。
短期的には、コンピューティング サービスのコピーを各コンピューティング セルに展開し、データ センターへのほとんどのリクエストを単一のセルで処理できるようにしました。 また、セル間のトラフィックの負荷分散も行っています。 さらに将来に目を向けると、私たちはサービス メッシュを活用する次世代のサービス ディスカバリ プロセスの構築に着手しており、2024 年に完成することを目指しています。これにより、セル間の通信を許可する高度なポリシーを実装できるようになります。フェイルオーバー セルに悪影響を与えることはありません。 また、2024 年には、依存するリクエストを同じセル内のサービス バージョンに送信する方法が導入される予定です。これにより、セル間のトラフィックが最小限に抑えられ、セル間で障害が伝播するリスクが軽減されます。
ピーク時には、バックエンド サービス トラフィックの 70% 以上がセルから提供されており、セルの作成方法については多くのことを学びましたが、2024 年までサービスの移行を続ける中で、さらに多くの研究とテストが行われることが予想されます。超えて。 進行するにつれて、これらの爆風壁はますます強力になります。
常時接続インフラストラクチャの移行
Roblox は世界中のユーザーをサポートするグローバル プラットフォームであるため、オフピークまたは「ダウンタイム」中にサービスを移動することはできません。そのため、すべてのマシンをセルに移行し、それらのセルでサービスを実行するプロセスがさらに複雑になります。 。 私たちは、それらを実行するマシンやそれらをサポートするサービスを移動する場合でも、引き続きサポートする必要がある常時稼働のエクスペリエンスを何百万も抱えています。 このプロセスを開始したとき、これらのワークロードの移行に使用できる未使用のマシンが何万台も放置されているわけではありませんでした。
ただし、将来の成長を見込んで追加購入したマシンが少数ありました。 まず、これらのマシンを使用して新しいセルを構築し、ワークロードをそれらのマシンに移行しました。 私たちは効率だけでなく信頼性も重視しているため、「予備」のマシンがなくなったら追加のマシンを購入するのではなく、移行元のマシンをワイプして再プロビジョニングすることで、より多くのセルを構築しました。 次に、それらの再プロビジョニングされたマシンにワークロードを移行し、プロセスを最初からやり直しました。 このプロセスは複雑です。マシンが置き換えられ、セルに組み込まれるために解放されるとき、それらは理想的かつ秩序立った方法で解放されません。 これらはデータ ホール全体で物理的に断片化されているため、断片的な方法でプロビジョニングする必要があります。これには、ハードウェアの場所を大規模な物理障害ドメインに合わせて維持するためのハードウェア レベルの最適化プロセスが必要です。
当社のインフラストラクチャ エンジニアリング チームの一部は、既存のワークロードをレガシー環境、つまり「セル以前」の環境からセルに移行することに重点を置いています。 この作業は、数千の異なるインフラストラクチャ サービスと数千のバックエンド サービスを新しく構築されたセルに移行するまで続きます。 いくつかの複雑な要因により、これには来年いっぱいかかり、おそらく 2025 年までかかると予想されます。 まず、この作業には堅牢なツールを構築する必要があります。 たとえば、新しいセルを展開するときに、ユーザーに影響を与えることなく、多数のサービスのバランスを自動的に再調整するツールが必要です。 また、インフラストラクチャを前提として構築されたサービスも見られました。 これらのサービスは、セルに移行する際に将来変更される可能性のあるものに依存しないように修正する必要があります。 また、セルラー アーキテクチャではうまく機能しない既知の設計パターンを検索する方法と、移行される各サービスの系統的なテスト プロセスの両方を実装しました。 これらのプロセスは、セルと互換性のないサービスによって引き起こされるユーザーが直面する問題を回避するのに役立ちます。
現在、30,000 台近くのマシンがセルによって管理されています。 これはフリート全体のほんの一部に過ぎませんが、これまでのところプレイヤーにマイナスの影響を与えることなく非常にスムーズに移行できています。 私たちの最終目標は、システムが毎月 99.99 パーセントのユーザー稼働時間を達成することです。これは、エンゲージメント時間の 0.01 パーセント以下を中断することを意味します。 業界全体でダウンタイムを完全になくすことはできませんが、私たちの目標は、Roblox のダウンタイムをほとんど目立たない程度まで減らすことです。
規模を拡大しても将来を見据えた対応
私たちの初期の取り組みは成功を収めていますが、細胞に関する研究はまだ終わっていません。 Roblox が拡大を続ける中、私たちはこのテクノロジーや他のテクノロジーを通じてシステムの効率と回復力を向上させるよう努力し続けます。 進むにつれて、プラットフォームは問題に対する回復力をますます高め、発生する問題は徐々に目立たなくなり、プラットフォーム上の人々にとって混乱をもたらすものになるはずです。
要約すると、これまでのところ次のとおりです。
- XNUMX番目のデータセンターを構築し、アクティブ/パッシブ状態を実現しました。
- アクティブ データ センターとパッシブ データ センターにセルを作成し、バックエンド サービス トラフィックの 70% 以上をこれらのセルに移行することに成功しました。
- 残りのインフラストラクチャの移行を継続する際に、すべてのセルを均一に保つために従う必要がある要件とベスト プラクティスを設定します。
- セル間により強力な「爆発壁」を構築する継続的なプロセスが開始されました。
これらのセルの交換可能性が高まると、セル間のクロストークが少なくなります。 これにより、監視、トラブルシューティング、さらにはワークロードの自動シフトに関する自動化を強化するという点で、非常に興味深い機会が得られます。
XNUMX 月には、データセンター全体でアクティブ/アクティブ実験の実行も開始しました。 これは、信頼性を向上させ、フェイルオーバー時間を最小限に抑えるためにテスト中のもう XNUMX つのメカニズムです。 これらの実験は、主にデータ アクセスに関する多数のシステム設計パターンを特定するのに役立ちました。これらは、完全なアクティブ/アクティブ化に向けて再検討する必要があります。 全体として、実験は十分に成功し、限られた数のユーザーからのトラフィックに対して実行を続けることができました。
私たちは、プラットフォームの効率性と回復力をさらに高めるために、この取り組みを推進し続けることに興奮しています。 セルとアクティブ/アクティブ インフラストラクチャに関するこの取り組みと、その他の取り組みにより、当社は数百万人にとって信頼性が高くパフォーマンスの高いユーティリティに成長し、XNUMX 億人を実際に接続するために取り組みながら規模を拡大し続けることが可能になります。時間。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- :持っている
- :は
- :not
- :どこ
- $UP
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- 能力
- できる
- 私たちについて
- アクセス
- 達成する
- 達成
- 越えて
- 行為
- 演技
- アクティブ
- 追加されました
- NEW
- 住所
- 採択
- 再び
- 積極的に
- 整列した
- すべて
- 許す
- 一人で
- 沿って
- 既に
- また
- an
- および
- 別の
- 予想する
- 期待
- どれか
- 誰も
- 約
- 建築
- です
- 周りに
- AS
- 前提条件
- At
- 自動化
- 自動的に
- オートメーション
- 利用できます
- アバター
- 避ける
- バックエンド
- バックアップ
- スイング
- バランシング
- ベース
- BE
- なぜなら
- になる
- になる
- になる
- き
- 始め
- さ
- 恩恵
- BEST
- ベストプラクティス
- の間に
- 越えて
- ビッグ
- より大きい
- 10億
- ブログ
- 両言語で
- 持って来る
- た
- バグ
- ビルド
- 建物
- 内蔵
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- 買収
- by
- コール
- 缶
- 容量
- 例
- 原因となる
- 生じました
- 原因
- セル
- 細胞
- 細胞の
- センター
- センター
- 一定
- 挑戦
- 変化する
- 変更
- 閉じる
- クラウド
- クラウドインフラ
- コード
- 来ます
- 到来
- コマンドと
- 伝える
- 通信中
- コミュニケーション
- 企業
- 比べ
- コンプリート
- 完全に
- 複雑な
- 複雑さ
- コンポーネント
- コンポーネント
- 計算
- コンピューティング
- 講演
- お問合せ
- 接続
- 含む
- 含まれています
- 続ける
- 続ける
- 連続的な
- コントロール
- コピー
- コスト
- 可能性
- 作ります
- 作成
- クリエイター
- 現在
- 特注の
- daily
- データ
- データアクセス
- データセンター
- データセンター
- 日付
- 中
- 定義
- 度
- 遅延
- 決まる
- 依存
- 展開します
- 展開
- 展開
- 設計
- デザインパターン
- DID
- 異なります
- 難しい
- 演出
- 発見
- 混乱する
- 破壊的な
- 配布する
- do
- ありません
- すること
- ドメイン
- 行われ
- ドント
- ドア
- ダウン
- ダウンタイム
- 運転
- 原因
- 間に
- 各
- 早い
- 容易
- 簡単に
- 効率
- 効率的な
- 効率良く
- 努力
- 除去された
- 可能
- end
- 婚約
- エンジニアリング
- エンジニア
- 十分な
- 確保
- 全体
- 完全に
- 環境
- エラー
- エラー
- 本質的に
- 等
- さらに
- 最終的に
- あらゆる
- すべてのもの
- 例
- 興奮した
- 既存の
- 期待する
- 経験豊かな
- エクスペリエンス
- 実験
- 実験
- 極端な
- 非常に
- 要因
- フェイル
- 失敗
- 失敗
- 不良解析
- 障害
- かなり
- 遠く
- ファッション
- 速いです
- もう完成させ、ワークスペースに掲示しましたか?
- 火災
- 名
- 艦隊
- フォーカス
- 焦点を当て
- フォワード
- 分数
- 断片化して
- 無料版
- 頻繁な
- から
- フル
- 完全に
- 機能的な
- さらに
- 未来
- 将来の成長
- 一般に
- 地理的
- 取得する
- 受け
- 与えられた
- グローバル
- グローバルに
- Go
- 目標
- ゴエス
- 行く
- 大きい
- グループ
- 成長する
- 成長した
- 成長性
- 持っていました
- 半分
- ハンドル
- ハンドリング
- 起こる
- ハード
- Hardware
- 持ってる
- 健康
- 健康
- 助けます
- 助けました
- ハイ
- より高い
- 希望
- HOURS
- 認定条件
- How To
- しかしながら
- HTTPS
- 人間
- ハイブリッド
- 理想
- 識別する
- if
- 没入できる
- 影響
- 影響を与える
- 実装する
- 実装
- 改善します
- in
- include
- 含めて
- 互換性がない
- 増える
- の増加
- ますます
- 個人
- 産業を変えます
- 情報
- インフラ
- 内部
- インスタンス
- 瞬時に
- 興味深い
- 内部
- に
- 問題
- 問題
- IT
- 六月
- ただ
- キープ
- 保管
- 知っている
- 既知の
- 大
- 大規模
- 主として
- レイテンシ
- 学んだ
- コメントを残す
- 残す
- Legacy
- less
- う
- レベル
- レバレッジ
- ような
- 限定的
- 負荷
- 位置して
- 場所
- 長期的
- より長いです
- 探して
- たくさん
- ロー
- 機械
- マシン
- 維持する
- make
- 作る
- 作成
- 管理します
- マネージド
- 手動で
- 多くの
- 最大幅
- 意味する
- 意味
- メカニズム
- メカニズム
- 大会
- メッシュ
- 方法
- 整然とした
- かもしれない
- 移動します
- 移行
- 移行中
- 移行
- 百万
- 何百万
- 最小限に抑えます
- マイナー
- ミス
- モニタリング
- 月
- 他には?
- もっと効率的
- 最も
- ずっと
- の試合に
- しなければなりません
- 自然
- ほぼ
- 必要
- 必要とされる
- 負
- マイナスに
- ネットワーク
- 新作
- 新しく
- 次の
- 次世代
- いいえ
- 今
- 数
- 番号
- 発生する
- 10月
- of
- オフ
- on
- かつて
- ONE
- 継続
- の
- 機会
- 機会
- or
- OS
- その他
- その他
- 私たちの
- でる
- 機能停止
- 停電
- が
- 全体
- 所有者
- 部
- パッシブ
- 過去
- パターン
- 支払い
- ピーク
- のワークプ
- 以下のために
- パーセント
- 実行
- しつこく
- 人
- 哲学
- 物理的な
- 物理的に
- 選ぶ
- 場所
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プレイヤー
- ポリシー
- ポータブル
- 部分
- 可能性
- 可能
- おそらく
- :
- プラクティス
- 防ぐ
- を防止
- 主に
- 優先順位
- プライベート
- プロセス
- ラボレーション
- 進捗
- 徐々に
- 伝播
- 保護
- 判明
- 準備
- 購入した
- プッシュ
- クエリ
- 質問
- すぐに
- むしろ
- 準備
- リアル
- への
- リバランス
- 回復
- リダイレクト
- 減らします
- 地域
- 信頼性
- 信頼性のある
- 頼る
- 修理
- 置き換え
- レプリケーション
- 倉庫
- リクエスト
- 要件
- 必要
- 研究
- 回復力
- 弾力性のあります
- 解決する
- REST
- 結果
- 得られました
- 修正します
- リスク
- ROBLOX
- 堅牢な
- ラン
- ランニング
- runs
- 安全に
- 同じ
- 保存されました
- 規模
- シナリオ
- スクラッチ
- を検索
- 二番
- 見て
- 切り離す
- 9月
- サービスを提供
- サービス
- サービス
- サービング
- セッションに
- いくつかの
- シェアする
- shared
- シェアリング
- シフト
- シフト
- ショート
- すべき
- 著しく
- から
- 座っている
- 小さい
- スムーズ
- So
- これまでのところ
- ソフトウェア
- 一部
- 何か
- 洗練された
- ソース
- ソースコード
- スペース
- スパイク
- 広がる
- 広がる
- start
- 開始
- 開始
- Status:
- まだ
- 戦略
- 強い
- 強い
- 勉強
- 成功する
- 成功した
- 首尾よく
- 概要
- サポート
- サポート
- 支援する
- サポート
- システム
- 取る
- 撮影
- チーム
- 技術的
- テクノロジー
- 十
- 期間
- 条件
- テスト
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- より
- それ
- 未来
- 世界
- アプリ環境に合わせて
- それら
- その後
- そこ。
- それによって
- ボーマン
- 彼ら
- 物事
- 考える
- この
- それらの
- 数千
- 介して
- 全体
- 時間
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- 今日
- 一緒に
- 公差
- あまりに
- ツール
- 豊富なツール群
- トータル
- に向かって
- トラフィック
- 遷移
- トリガー
- しよう
- 2
- 究極の
- 最終的に
- ロック解除
- まで
- 未使用
- に
- uptime
- us
- 中古
- ユーザー
- users
- ユーティリティ
- 値
- バージョン
- 非常に
- 目に見える
- ビジョン
- 欲しいです
- ました
- 仕方..
- we
- 天気
- WELL
- した
- この試験は
- どのような
- いつ
- which
- while
- 誰
- ワイド
- 意志
- ワイピング
- 以内
- 仕事
- 働いていました
- ワーキング
- 世界
- 不安
- でしょう
- 年
- 年
- ゼファーネット