Layanan Pencarian Terbuka Amazon adalah layanan terkelola yang memudahkan untuk mengamankan, menerapkan, dan mengoperasikan OpenSearch dan klaster Elasticsearch lama dalam skala besar di AWS Cloud. Amazon OpenSearch Service menyediakan semua sumber daya untuk klaster Anda, meluncurkannya, dan secara otomatis mendeteksi dan mengganti node yang gagal, mengurangi overhead infrastruktur yang dikelola sendiri. Layanan ini memudahkan Anda untuk melakukan analitik log interaktif, pemantauan aplikasi waktu nyata, pencarian situs web, dan lainnya dengan menawarkan versi OpenSearch terbaru, dukungan untuk 19 versi Elasticsearch (versi 1.5 hingga 7.10), dan kemampuan visualisasi yang didukung oleh Dasbor OpenSearch dan Kibana (versi 1.5 hingga 7.10).
Dalam rilis perangkat lunak layanan terbaru, kami telah memperbarui logika alokasi shard agar peka terhadap beban sehingga ketika shard didistribusikan kembali jika terjadi kegagalan node, layanan tidak mengizinkan node yang bertahan untuk kelebihan beban oleh shard yang sebelumnya dihosting di node yang gagal. Hal ini sangat penting bagi domain Multi-AZ untuk memberikan performa klaster yang konsisten dan dapat diprediksi.
Jika Anda ingin lebih banyak latar belakang tentang logika alokasi shard secara umum, silakan lihat Demystifikasi alokasi shard Elasticsearch.
Tantangan
Domain Amazon OpenSearch Service dikatakan "seimbang" ketika jumlah node didistribusikan secara merata di seluruh Availability Zone yang dikonfigurasi, dan jumlah total shard didistribusikan secara merata di semua node yang tersedia tanpa pemusatan shard dari salah satu indeks pada salah satu simpul. Selain itu, OpenSearch memiliki properti yang disebut “Zone Awareness” yang, jika diaktifkan, memastikan bahwa shard utama dan replikanya dialokasikan di Availability Zone yang berbeda. Jika Anda memiliki lebih dari satu salinan data, memiliki beberapa Availability Zone memberikan toleransi kesalahan dan ketersediaan yang lebih baik. Jika domain diskalakan atau diskalakan di atau selama kegagalan node, OpenSearch secara otomatis mendistribusikan kembali pecahan di antara node yang tersedia sambil mematuhi aturan alokasi berdasarkan kesadaran zona.
Meskipun proses penyeimbangan shard memastikan bahwa shard didistribusikan secara merata di seluruh Availability Zone, dalam beberapa kasus, jika terjadi kegagalan tak terduga dalam satu zona, shard akan dialokasikan kembali ke node yang bertahan. Ini mungkin mengakibatkan node yang bertahan menjadi kewalahan, yang berdampak pada stabilitas cluster.
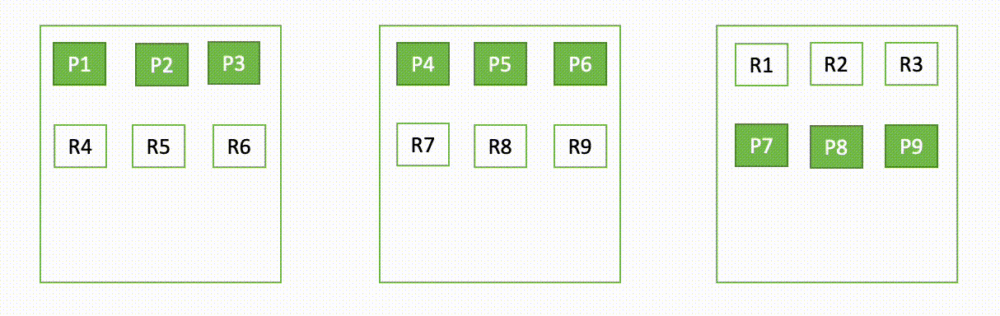
Misalnya, jika satu node dalam cluster tiga node turun, OpenSearch mendistribusikan kembali pecahan yang belum ditetapkan, seperti yang ditunjukkan pada diagram berikut. Di sini "P" mewakili salinan pecahan utama, sedangkan "R" mewakili salinan pecahan replika.

Perilaku domain ini dapat dijelaskan dalam dua bagian – selama kegagalan dan selama pemulihan.
Selama kegagalan
Domain yang diterapkan di beberapa Availability Zone dapat mengalami berbagai jenis kegagalan selama siklus hidupnya.
Kegagalan zona lengkap
Sebuah klaster dapat kehilangan satu Availability Zone karena berbagai alasan dan juga semua node di zona tersebut. Hari ini, layanan mencoba untuk menempatkan node yang hilang di Availability Zones sehat yang tersisa. Layanan juga mencoba membuat kembali pecahan yang hilang di node yang tersisa sambil tetap mengikuti aturan alokasi. Ini dapat mengakibatkan beberapa konsekuensi yang tidak diinginkan.
- Ketika pecahan dari zona yang terkena dampak dialokasikan kembali ke zona sehat, mereka memicu pemulihan pecahan yang dapat meningkatkan latensi karena menghabiskan siklus CPU tambahan dan bandwidth jaringan.
- Untuk penyiapan n-AZ, n-copy, (n>1), Availability Zone n-1 yang bertahan dialokasikan dengan salinan shard ke-n, yang dapat menjadi tidak diinginkan karena dapat menyebabkan kecondongan dalam distribusi shard, yang juga dapat mengakibatkan lalu lintas yang tidak seimbang di seluruh node. Node ini bisa kelebihan beban, menyebabkan kegagalan lebih lanjut.
Kegagalan sebagian zona
Jika terjadi kegagalan sebagian zona atau saat domain hanya kehilangan sebagian node di Availability Zone, Amazon OpenSearch Service mencoba mengganti node yang gagal secepat mungkin. Namun, jika terlalu lama untuk mengganti node, OpenSearch mencoba mengalokasikan pecahan yang belum ditetapkan dari zona tersebut ke dalam node yang bertahan di Availability Zone. Jika layanan tidak dapat mengganti node di Availability Zone yang terkena dampak, layanan dapat mengalokasikannya di Availability Zone lain yang dikonfigurasi, yang selanjutnya dapat mendistorsi distribusi shard baik di seluruh maupun di dalam zona. Ini lagi memiliki konsekuensi yang tidak diinginkan.
- Jika node pada domain tidak memiliki ruang penyimpanan yang cukup untuk mengakomodasi shard tambahan, domain dapat diblokir secara tulis, yang memengaruhi operasi pengindeksan.
- Karena distribusi shard yang miring, domain juga dapat mengalami lalu lintas yang miring di seluruh node, yang selanjutnya dapat meningkatkan latensi atau waktu tunggu untuk operasi baca dan tulis.
Recovery
Saat ini, untuk mempertahankan jumlah node domain yang diinginkan, Amazon OpenSearch Service meluncurkan node data di Availability Zone sehat yang tersisa, serupa dengan skenario yang dijelaskan di bagian kegagalan di atas. Untuk memastikan distribusi node yang tepat di semua Availability Zone setelah kejadian seperti itu, AWS memerlukan intervensi manual.
Apa yang berubah
Untuk meningkatkan keseluruhan penanganan kegagalan dan meminimalkan dampak kegagalan pada kesehatan dan kinerja domain, Amazon OpenSearch Service melakukan perubahan berikut:
- Kesadaran Zona Paksa: OpenSearch memiliki konfigurasi penyeimbangan shard yang sudah ada sebelumnya yang disebut kesadaran paksa yang digunakan untuk menyetel Availability Zone tempat shard perlu dialokasikan. Misalnya, jika Anda memiliki atribut kesadaran yang disebut zona dan mengonfigurasi node di
zone1danzone2, Anda dapat menggunakan kesadaran paksa untuk mencegah OpenSearch mengalokasikan replika jika hanya satu zona yang tersedia:
Dengan contoh konfigurasi ini, jika Anda memulai dua node dengan node.attr.zone mulai zone1 dan membuat indeks dengan lima pecahan dan satu replika, OpenSearch membuat indeks dan mengalokasikan lima pecahan utama tetapi tanpa replika. Replika hanya dialokasikan sekali node dengan node.attr.zone mulai zone2 tersedia.
Amazon OpenSearch Service akan menggunakan konfigurasi kesadaran paksa pada domain Multi-AZ untuk memastikan bahwa shard hanya dialokasikan sesuai aturan kesadaran zona. Ini akan mencegah peningkatan beban secara tiba-tiba pada node Availability Zone yang sehat.
- Alokasi Shard Sadar Beban: Amazon OpenSearch Service akan mempertimbangkan faktor-faktor seperti kapasitas yang disediakan, kapasitas sebenarnya, dan total salinan shard untuk menghitung jika ada node yang kelebihan muatan dengan lebih banyak shard berdasarkan rata-rata shard yang diharapkan per node. Itu akan mencegah penugasan shard ketika ada node yang mengalokasikan jumlah shard yang melampaui batas ini.
Note bahwa setiap unassigned primer salinan masih akan diizinkan pada node yang kelebihan beban untuk mencegah cluster dari kehilangan data yang akan segera terjadi.
Demikian pula, untuk mengatasi masalah pemulihan manual (seperti yang dijelaskan di bagian Pemulihan di atas), Amazon OpenSearch Service juga melakukan perubahan pada komponen penskalaan internalnya. Dengan diterapkannya perubahan yang lebih baru, Amazon OpenSearch Service tidak akan meluncurkan node di Availability Zone yang tersisa bahkan saat melalui skenario kegagalan yang telah dijelaskan sebelumnya.
Memvisualisasikan perilaku saat ini dan baru
Misalnya, domain Amazon OpenSearch Service dikonfigurasikan dengan 3-AZ, 6 node data, 12 shard utama, dan 24 shard replika. Domain disediakan di AZ-1, AZ-2, dan AZ-3, dengan dua node di setiap zona.
Alokasi pecahan saat ini:
Jumlah total pecahan: 12 Utama + 24 Replika = 36 pecahan
Jumlah Zona Ketersediaan: 3
Jumlah pecahan per zona (kewaspadaan zona benar): 36/3 = 12
Jumlah node per Availability Zone: 2
Jumlah pecahan per node: 12/2 = 6
Diagram berikut menyediakan representasi visual dari penyiapan domain. Lingkaran menunjukkan jumlah pecahan yang dialokasikan ke node. Amazon OpenSearch Service akan mengalokasikan enam shard per node.

Selama kegagalan zona parsial, di mana satu node di AZ-3 gagal, node yang gagal ditugaskan ke zona yang tersisa, dan shard di zona tersebut didistribusikan kembali berdasarkan node yang tersedia. Setelah perubahan yang dijelaskan di atas, cluster tidak akan membuat node baru atau mendistribusikan kembali pecahan setelah kegagalan node.

Pada diagram di atas, dengan hilangnya satu node di AZ-3, Amazon OpenSearch Service akan mencoba meluncurkan kapasitas pengganti di zona yang sama. Namun, karena beberapa pemadaman, zona tersebut mungkin mengalami gangguan dan gagal meluncurkan penggantian. Dalam kejadian seperti itu, layanan mencoba meluncurkan kapasitas defisit di zona sehat lainnya, yang dapat menyebabkan ketidakseimbangan zona di seluruh Availability Zone. Pecahan di zona yang terkena dampak dimasukkan ke node yang bertahan di zona yang sama. Namun, dengan perilaku baru, layanan akan mencoba meluncurkan kapasitas di zona yang sama tetapi akan menghindari meluncurkan kapasitas defisit di zona lain untuk menghindari ketidakseimbangan. Pengalokasi pecahan juga akan memastikan bahwa node yang bertahan tidak kelebihan beban.

Demikian pula, jika semua node di AZ-3 hilang, atau AZ-3 terganggu, Amazon OpenSearch Service menampilkan node yang hilang di Availability Zone yang tersisa dan juga mendistribusikan kembali pecahan pada node. Namun, setelah perubahan baru, Amazon OpenSearch Service tidak akan mengalokasikan node ke zona yang tersisa atau akan mencoba mengalokasikan ulang pecahan yang hilang ke zona yang tersisa. Amazon OpenSearch Service akan menunggu Pemulihan terjadi dan domain kembali ke konfigurasi awal setelah pemulihan.
Jika domain Anda tidak disediakan dengan kapasitas yang cukup untuk menahan hilangnya Availability Zone, Anda mungkin mengalami penurunan throughput untuk domain Anda. Oleh karena itu, sangat disarankan untuk mengikuti praktik terbaik saat mengukur domain Anda, yang berarti menyediakan sumber daya yang cukup untuk menahan hilangnya satu kegagalan Availability Zone.

Saat ini, setelah domain pulih, layanan memerlukan intervensi manual untuk menyeimbangkan kapasitas di seluruh Availability Zone, yang juga melibatkan pergerakan shard. Namun, dengan perilaku baru, tidak diperlukan intervensi selama proses pemulihan karena kapasitas kembali di zona yang terkena dampak dan shard juga secara otomatis dialokasikan ke node yang dipulihkan. Ini memastikan bahwa tidak ada prioritas yang bersaing pada sumber daya yang tersisa.
Apa yang dapat Anda harapkan
Setelah Anda memperbarui domain Amazon OpenSearch Service ke rilis perangkat lunak layanan terbaru, domain yang telah dikonfigurasi dengan praktik terbaik akan memiliki kinerja yang lebih dapat diprediksi bahkan setelah kehilangan satu atau banyak node data di Availability Zone. Akan ada pengurangan kasus shard overallocation dalam sebuah node. Merupakan praktik yang baik untuk menyediakan kapasitas yang cukup agar dapat mentolerir kegagalan zona tunggal
Terkadang Anda mungkin melihat domain berubah menjadi kuning selama kegagalan tak terduga tersebut karena kami tidak akan menetapkan pecahan replika ke node yang kelebihan muatan. Namun, ini tidak berarti bahwa akan ada kehilangan data di domain yang terkonfigurasi dengan baik. Kami masih akan memastikan bahwa semua pemilihan pendahuluan ditetapkan selama pemadaman. Ada pemulihan otomatis di tempat, yang akan menjaga keseimbangan node dalam domain dan memastikan bahwa replika ditetapkan setelah kegagalan pulih.
Perbarui perangkat lunak layanan domain Amazon OpenSearch Service Anda agar perubahan baru ini diterapkan ke domain Anda. Rincian lebih lanjut tentang proses pembaruan perangkat lunak layanan ada di Dokumentasi Layanan Amazon OpenSearch.
Kesimpulan
Dalam postingan ini kami melihat bagaimana Amazon OpenSearch Service baru-baru ini meningkatkan logika untuk mendistribusikan node dan pecahan di seluruh Availability Zone selama pemadaman zona.
Perubahan ini akan membantu layanan untuk memastikan performa yang lebih konsisten dan dapat diprediksi selama kegagalan node atau zona. Domain tidak akan melihat peningkatan latensi atau blok tulis selama pemrosesan tulis dan baca, yang biasanya muncul lebih awal karena alokasi shard yang berlebihan pada node.
Tentang penulis
 Bukhtawar Khan adalah Insinyur Perangkat Lunak Senior yang bekerja di Amazon OpenSearch Service. Dia tertarik pada sistem terdistribusi dan otonom. Dia adalah kontributor aktif untuk OpenSearch.
Bukhtawar Khan adalah Insinyur Perangkat Lunak Senior yang bekerja di Amazon OpenSearch Service. Dia tertarik pada sistem terdistribusi dan otonom. Dia adalah kontributor aktif untuk OpenSearch.
 Anshu Agarwal adalah Insinyur Perangkat Lunak Senior yang mengerjakan AWS OpenSearch di Amazon Web Services. Dia bersemangat memecahkan masalah yang terkait dengan membangun sistem yang dapat diskalakan dan sangat andal.
Anshu Agarwal adalah Insinyur Perangkat Lunak Senior yang mengerjakan AWS OpenSearch di Amazon Web Services. Dia bersemangat memecahkan masalah yang terkait dengan membangun sistem yang dapat diskalakan dan sangat andal.
 Shourya Dutta Biswas adalah Insinyur Perangkat Lunak yang mengerjakan AWS OpenSearch di Amazon Web Services. Dia bersemangat membangun sistem terdistribusi yang sangat tangguh.
Shourya Dutta Biswas adalah Insinyur Perangkat Lunak yang mengerjakan AWS OpenSearch di Amazon Web Services. Dia bersemangat membangun sistem terdistribusi yang sangat tangguh.
 Rishab Nahata adalah Insinyur Perangkat Lunak yang mengerjakan OpenSearch di Amazon Web Services. Dia terpesona tentang pemecahan masalah dalam sistem terdistribusi. Dia adalah kontributor aktif untuk OpenSearch.
Rishab Nahata adalah Insinyur Perangkat Lunak yang mengerjakan OpenSearch di Amazon Web Services. Dia terpesona tentang pemecahan masalah dalam sistem terdistribusi. Dia adalah kontributor aktif untuk OpenSearch.
 Ranjith Ramachandra adalah Manajer Teknik yang bekerja di Amazon OpenSearch Service di Amazon Web Services.
Ranjith Ramachandra adalah Manajer Teknik yang bekerja di Amazon OpenSearch Service di Amazon Web Services.
 Jon Pengendali adalah Senior Principal Solutions Architect, yang berspesialisasi dalam teknologi pencarian AWS – Amazon CloudSearch, dan Amazon OpenSearch Service. Berbasis di Palo Alto, dia membantu berbagai pelanggan mendapatkan beban kerja pencarian dan analitik log mereka diterapkan dengan benar dan berfungsi dengan baik.
Jon Pengendali adalah Senior Principal Solutions Architect, yang berspesialisasi dalam teknologi pencarian AWS – Amazon CloudSearch, dan Amazon OpenSearch Service. Berbasis di Palo Alto, dia membantu berbagai pelanggan mendapatkan beban kerja pencarian dan analitik log mereka diterapkan dengan benar dan berfungsi dengan baik.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/impact-of-infrastructure-failures-on-shard-in-amazon-opensearch-service/
- 1
- 10
- 100
- 7
- 9
- a
- Sanggup
- Tentang Kami
- atas
- menampung
- Menurut
- di seluruh
- aktif
- Tambahan
- alamat
- Setelah
- Semua
- dialokasikan
- mengalokasikan
- alokasi
- Amazon
- Amazon Web Services
- analisis
- dan
- Lain
- Aplikasi
- terapan
- ditugaskan
- atribut
- Otomatis
- secara otomatis
- otonom
- tersedianya
- tersedia
- rata-rata
- kesadaran
- AWS
- latar belakang
- Saldo
- Bandwidth
- berdasarkan
- karena
- menjadi
- TERBAIK
- Praktik Terbaik
- Lebih baik
- antara
- Luar
- Blok
- Membawa
- luas
- Bangunan
- bernama
- Bisa Dapatkan
- tidak bisa
- kemampuan
- Kapasitas
- yang
- kasus
- kasus
- Menyebabkan
- perubahan
- Perubahan
- lingkaran
- awan
- Kelompok
- bersaing
- komponen
- konsentrasi
- konfigurasi
- Konsekuensi
- pertimbangan
- konsisten
- penyumbang
- Sesuai
- membuat
- menciptakan
- terbaru
- pelanggan
- siklus
- data
- kehilangan data
- DEFISIT
- menyebarkan
- dikerahkan
- dijelaskan
- rincian
- berbeda
- mendistribusikan
- didistribusikan
- sistem terdistribusi
- distribusi
- domain
- domain
- Dont
- turun
- Menjatuhkan
- selama
- setiap
- Terdahulu
- insinyur
- Teknik
- cukup
- memastikan
- Memastikan
- memastikan
- sama
- terutama
- Eter (ETH)
- Bahkan
- Acara
- contoh
- diharapkan
- pengalaman
- menjelaskan
- faktor
- GAGAL
- Gagal
- gagal
- Kegagalan
- mengikuti
- berikut
- kekuatan
- dari
- berfungsi
- lebih lanjut
- Umum
- mendapatkan
- mendapatkan
- gif
- Pergi
- baik
- Penanganan
- terjadi
- memiliki
- Kesehatan
- sehat
- membantu
- membantu
- di sini
- sangat
- host
- Seterpercayaapakah Olymp Trade? Kesimpulan
- Namun
- HTML
- HTTPS
- ketidakseimbangan
- Dampak
- dampak
- penting
- memperbaiki
- ditingkatkan
- in
- Di lain
- insiden
- Meningkatkan
- Pada meningkat
- indeks
- Infrastruktur
- infrastruktur
- contoh
- interaktif
- tertarik
- intern
- intervensi
- isu
- IT
- Terbaru
- jalankan
- meluncurkan
- peluncuran
- memimpin
- terkemuka
- Warisan
- MEMBATASI
- memuat
- Panjang
- kehilangan
- Kerugian
- kehilangan
- lepas
- memelihara
- membuat
- MEMBUAT
- Membuat
- berhasil
- manajer
- panduan
- banyak
- cara
- mungkin
- meminimalkan
- pemantauan
- lebih
- gerak-gerik
- beberapa
- Perlu
- juga tidak
- jaringan
- New
- simpul
- Distribusi Node
- node
- jumlah
- menawarkan
- ONE
- beroperasi
- operasi
- Operasi
- urutan
- asli
- Lainnya
- outage
- Padam
- secara keseluruhan
- kewalahan
- Palo Alto
- bagian
- bergairah
- melakukan
- prestasi
- melakukan
- Tempat
- plato
- Kecerdasan Data Plato
- Data Plato
- silahkan
- mungkin
- Pos
- didukung
- praktek
- praktek
- Bisa ditebak
- mencegah
- sebelumnya
- primer
- Utama
- masalah
- proses
- pengolahan
- tepat
- milik
- memberikan
- menyediakan
- ketentuan
- segera
- jarak
- Baca
- real-time
- alasan
- baru-baru ini
- direkomendasikan
- Sembuh
- pemulihan
- mengurangi
- mengurangi
- terkait
- melepaskan
- dapat diandalkan
- yang tersisa
- menggantikan
- menjawab
- perwakilan
- merupakan
- membutuhkan
- tabah
- Sumber
- mengakibatkan
- kembali
- Pengembalian
- aturan
- Tersebut
- sama
- terukur
- Skala
- skala
- skenario
- Pencarian
- Bagian
- aman
- layanan
- Layanan
- set
- penyiapan
- ditunjukkan
- mirip
- sejak
- tunggal
- ENAM
- condong
- So
- Perangkat lunak
- Software Engineer
- Solusi
- Memecahkan
- beberapa
- Space
- mengkhususkan diri
- Stabilitas
- awal
- Masih
- penyimpanan
- sangat
- seperti itu
- tiba-tiba
- cukup
- mendukung
- Permukaan
- sistem
- Mengambil
- Dibutuhkan
- Teknologi
- Grafik
- mereka
- karena itu
- Melalui
- keluaran
- kali
- untuk
- hari ini
- toleransi
- terlalu
- Total
- lalu lintas
- memicu
- benar
- Putar
- jenis
- Tiba-tiba
- Memperbarui
- diperbarui
- menggunakan
- Nilai - Nilai
- variasi
- visualisasi
- menunggu
- jaringan
- layanan web
- Situs Web
- yang
- sementara
- akan
- dalam
- tanpa
- kerja
- akan
- menulis
- Anda
- zephyrnet.dll
- zona