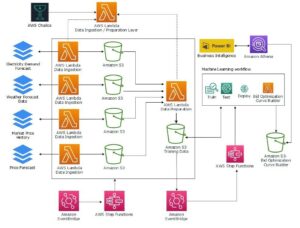
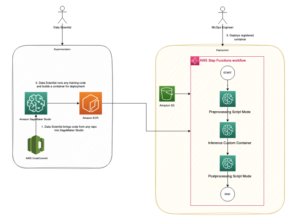
A beágyazások kulcsszerepet játszanak a természetes nyelvi feldolgozásban (NLP) és a gépi tanulásban (ML). Szöveg beágyazása A szöveg a nagydimenziós vektortérben található numerikus reprezentációkká alakításának folyamatára utal. Ezt a technikát ML algoritmusok használatával érik el, amelyek lehetővé teszik az adatok jelentésének és kontextusának megértését (szemantikai kapcsolatok), valamint az adatokon belüli összetett kapcsolatok és minták megtanulását (szintaktikai kapcsolatok). Az eredményül kapott vektoros ábrázolásokat számos alkalmazáshoz használhatja, például információ-visszakereséshez, szövegosztályozáshoz, természetes nyelvi feldolgozáshoz és sok máshoz.
Amazon Titan szövegbeágyazások egy olyan szövegbeágyazási modell, amely a természetes nyelvű szöveget – amely egyedi szavakból, kifejezésekből vagy akár nagyméretű dokumentumokból áll – numerikus reprezentációkká alakítja, amelyek felhasználhatók olyan használati esetekre, mint a keresés, a személyre szabás és a szemantikai hasonlóságon alapuló klaszterezés.
Ebben a bejegyzésben az Amazon Titan Text Embeddings modelljét, annak jellemzőit és használati eseteit tárgyaljuk.
Néhány kulcsfogalom a következőket tartalmazza:
- A szöveg numerikus ábrázolása (vektorok) a szemantikát és a szavak közötti kapcsolatokat rögzíti
- A gazdag beágyazások felhasználhatók a szöveg hasonlóságának összehasonlítására
- A többnyelvű szövegbeágyazás képes azonosítani a jelentést különböző nyelveken
Hogyan alakítható át egy szövegrész vektorrá?
Számos technika létezik a mondatok vektorrá alakítására. Az egyik népszerű módszer a szóbeágyazási algoritmusok, például a Word2Vec, a GloVe vagy a FastText használata, majd a szóbeágyazások összesítése mondatszintű vektoros reprezentáció létrehozásához.
Egy másik elterjedt megközelítés a nagy nyelvi modellek (LLM) használata, mint például a BERT vagy a GPT, amelyek kontextus szerinti beágyazást biztosíthatnak egész mondatokhoz. Ezek a modellek olyan mély tanulási architektúrákon alapulnak, mint például a Transformers, amelyek hatékonyabban képesek rögzíteni a szövegkörnyezeti információkat és a szavak közötti kapcsolatokat egy mondatban.
Miért van szükségünk beágyazási modellre?
A vektorbeágyazások alapvető fontosságúak az LLM-ek számára a nyelv szemantikai fokának megértéséhez, és lehetővé teszik az LLM-ek számára, hogy jól teljesítsenek az olyan downstream NLP-feladatokban, mint a hangulatelemzés, az elnevezett entitás felismerés és a szövegosztályozás.
A szemantikus keresés mellett a beágyazásokat is használhatja, hogy pontosabb eredményeket érjen el a Retrieval Augmented Generation (RAG) segítségével – de használatukhoz vektoros képességekkel rendelkező adatbázisban kell tárolnia őket.
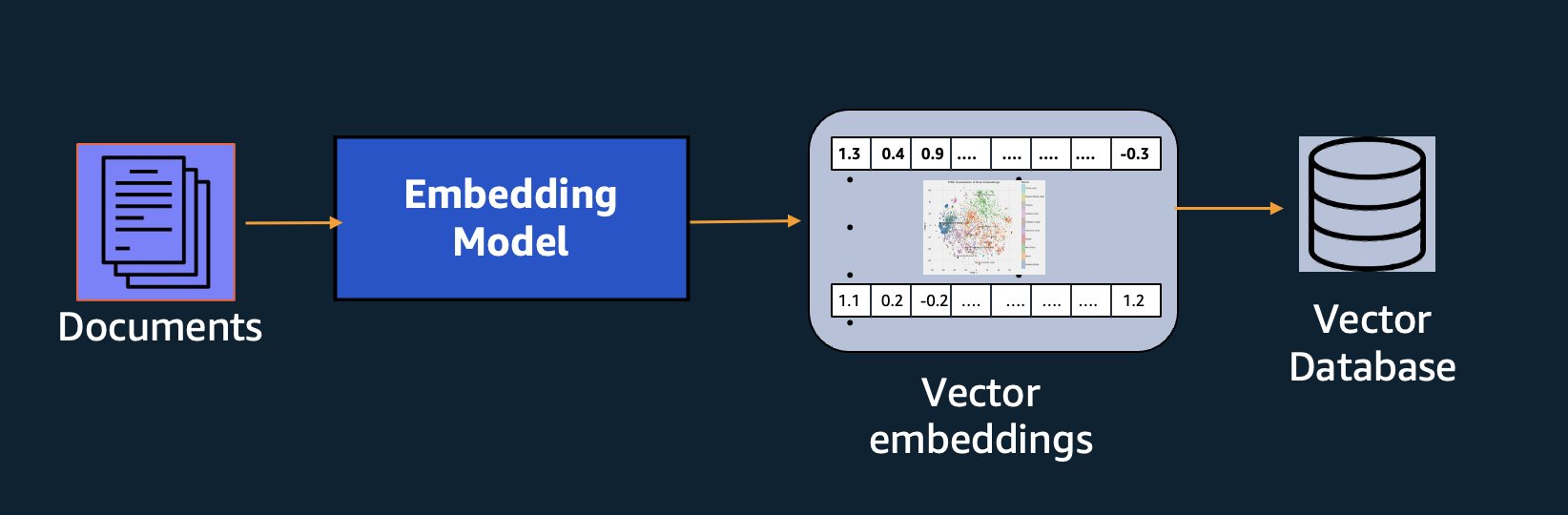
Az Amazon Titan Text Embeddings modell szöveg-visszakeresésre van optimalizálva, hogy lehetővé tegye a RAG felhasználási eseteket. Lehetővé teszi, hogy először a szöveges adatokat numerikus ábrázolásokká vagy vektorokká alakítsa, majd ezeket a vektorokat használja a releváns szövegrészek pontos megkeresésére egy vektor-adatbázisból, lehetővé téve, hogy a legtöbbet hozza ki védett adataiból más alapmodellekkel kombinálva.
Mivel az Amazon Titan Text Embeddings egy felügyelt modell Amazon alapkőzet, teljesen szerver nélküli élményként kínáljuk. Használhatja az Amazon Bedrock REST-en keresztül API vagy az AWS SDK. A szükséges paraméterek az a szöveg, amelynek a beágyazásait generálni szeretné, és a modelID paraméter, amely az Amazon Titan Text Embeddings modell nevét jelenti. A következő kód egy példa az AWS SDK for Python (Boto3) használatára:
A kimenet a következőképpen fog kinézni:
Hivatkozni Amazon Bedrock boto3 beállítása A szükséges csomagok telepítésével kapcsolatos további részletekért csatlakozzon az Amazon Bedrockhoz, és hívja meg a modelleket.
Az Amazon Titan szövegbeágyazás jellemzői
Az Amazon Titan Text Embeddings segítségével akár 8,000 tokent is beírhat, így az Ön használati esete alapján kiválóan alkalmas arra, hogy egyes szavakkal, kifejezésekkel vagy teljes dokumentumokkal dolgozzon. Az Amazon Titan 1536-os dimenziójú kimeneti vektorokat ad vissza, nagyfokú pontosságot biztosítva, miközben alacsony késleltetésű, költséghatékony eredményekre optimalizál.
Az Amazon Titan Text Embeddings több mint 25 különböző nyelven támogatja a szöveg beágyazásainak létrehozását és lekérdezését. Ez azt jelenti, hogy alkalmazhatja a modellt a használati eseteire anélkül, hogy külön modelleket kellene létrehoznia és karbantartania minden egyes támogatni kívánt nyelvhez.
Ha egyetlen beágyazási modellt több nyelven tanítanak meg, az a következő fő előnyökkel jár:
- Szélesebb hatókör – Több mint 25 nyelv azonnali támogatásával számos nemzetközi piacon kiterjesztheti alkalmazásai elérését a felhasználókra és a tartalmakra.
- Következetes teljesítmény – A több nyelvet lefedő egységes modellel konzisztens eredményeket érhet el a különböző nyelveken, ahelyett, hogy nyelvenként külön optimalizálna. A modellt holisztikusan képezték ki, így Ön a nyelvek közötti előnyöket élvezheti.
- Többnyelvű lekérdezés támogatása – Az Amazon Titan Text Embeddings lehetővé teszi a szövegbeágyazások lekérdezését bármely támogatott nyelven. Ez rugalmasságot biztosít a szemantikailag hasonló tartalom lekéréséhez több nyelven anélkül, hogy egyetlen nyelvre korlátozódna. Létrehozhat olyan alkalmazásokat, amelyek többnyelvű adatokat kérdeznek le és elemeznek ugyanazon egyesített beágyazási tér használatával.
A cikk írása óta a következő nyelvek támogatottak:
- arab
- Egyszerűsített kínai)
- Kínai (hagyományos)
- cseh
- Holland
- Angol
- francia
- Német
- héber
- hindi
- olasz
- japán
- kannada
- koreai
- Malayalam
- marathi
- lengyel
- portugál
- orosz
- spanyol
- svéd
- filippínó tagalog
- tamil
- telugu
- török
Amazon Titan szövegbeágyazások használata a LangChain segítségével
LangChain egy népszerű nyílt forráskódú keretrendszer a generatív mesterséges intelligencia modellekkel és a támogató technológiákkal való munkavégzéshez. Ez magában foglalja a BedrockEmbeddings kliens amely kényelmesen beburkolja a Boto3 SDK-t egy absztrakciós réteggel. A BedrockEmbeddings kliens lehetővé teszi, hogy közvetlenül dolgozzon szöveggel és beágyazásokkal, anélkül, hogy ismerné a JSON-kérés részleteit vagy a válaszstruktúrákat. A következő egy egyszerű példa:
Használhatja a LangChain-t is BedrockEmbeddings klienst az Amazon Bedrock LLM kliens mellé, hogy leegyszerűsítsék a RAG, a szemantikus keresés és más beágyazással kapcsolatos minták megvalósítását.
Használjon eseteket a beágyazáshoz
Bár jelenleg a RAG a legnépszerűbb felhasználási eset a beágyazásokkal való munkavégzéshez, sok más felhasználási eset is alkalmazható a beágyazások alkalmazására. Az alábbiakban felsorolunk néhány további forgatókönyvet, ahol a beágyazásokat használhatja konkrét problémák megoldására, akár önmagában, akár egy LLM-mel együttműködve:
- Kérdés és válasz – A beágyazások segíthetnek a kérdés-válasz felületek támogatásában a RAG mintán keresztül. A vektoros adatbázissal párosított beágyazásgenerálás lehetővé teszi, hogy szoros egyezéseket találjon a kérdések és a tartalom között egy tudástárban.
- Személyre szabott ajánlások – Hasonlóan a kérdés-felelethez, a beágyazások segítségével a felhasználó által megadott kritériumok alapján kereshet nyaralási célpontokat, főiskolákat, járműveket vagy egyéb termékeket. Ez történhet egy egyszerű találati lista formájában, vagy használhat egy LLM-et az egyes ajánlások feldolgozásához, és elmagyarázhatja, hogy az hogyan felel meg a felhasználó kritériumainak. Ezt a megközelítést arra is használhatja, hogy egyéni „10 legjobb” cikket hozzon létre a felhasználók számára az egyedi igényei alapján.
- Adatkezelés – Ha vannak olyan adatforrásai, amelyek nincsenek tisztán egymáshoz leképezve, de rendelkezik az adatrekordot leíró szöveges tartalommal, akkor beágyazásokkal azonosíthatja a lehetséges ismétlődő rekordokat. Használhatja például a beágyazásokat az ismétlődő jelöltek azonosítására, amelyek eltérő formázást, rövidítéseket használhatnak, vagy akár lefordított nevük is lehet.
- Alkalmazási portfólió racionalizálása – Amikor az alkalmazásportfóliókat az anyavállalat és az akvizíció között kívánja összehangolni, nem mindig egyértelmű, hol kezdje el a lehetséges átfedéseket. A konfigurációkezelési adatok minősége korlátozó tényező lehet, és nehéz lehet a csapatok közötti koordináció az alkalmazási környezet megértéséhez. A beágyazásokkal való szemantikai egyeztetés használatával gyors elemzést végezhetünk az alkalmazásportfóliók között, hogy azonosítsuk a nagy potenciállal jelölt alkalmazásokat a racionalizálásra.
- Tartalmi csoportosítás – A beágyazásokkal megkönnyítheti a hasonló tartalmak olyan kategóriákba való csoportosítását, amelyeket esetleg nem tud előre. Tegyük fel például, hogy gyűjtötte vevői e-maileket vagy online termékértékeléseket. Létrehozhat beágyazásokat minden egyes elemhez, majd futtathatja a beágyazásokat k-klaszterezést jelent a vevői aggodalmak, termékdicséretek vagy -panaszok vagy egyéb témák logikus csoportosításának azonosítása. Ezután koncentrált összefoglalókat hozhat létre a csoportok tartalmából egy LLM segítségével.
Szemantikus keresési példa
A mi példa a GitHubon, bemutatunk egy egyszerű beágyazáskereső alkalmazást az Amazon Titan Text Embeddings, a LangChain és a Streamlit segítségével.
A példa a felhasználó lekérdezését egy memórián belüli vektoradatbázis legközelebbi bejegyzéseivel egyezteti. Az egyezéseket ezután közvetlenül a felhasználói felületen jelenítjük meg. Ez akkor lehet hasznos, ha egy RAG-alkalmazással szeretne hibaelhárítást végezni, vagy közvetlenül szeretne kiértékelni egy beágyazási modellt.
Az egyszerűség kedvéért az in-memory-t használjuk FAISS adatbázis a beágyazási vektorok tárolására és keresésére. Valós méretű forgatókönyv esetén valószínűleg olyan állandó adattárat szeretne használni, mint a vektoros motor az Amazon OpenSearch Serverless számára vagy a pgvector kiterjesztés a PostgreSQL-hez.
Próbáljon ki néhány utasítást a webalkalmazásból különböző nyelveken, például a következőket:
- Hogyan tudom nyomon követni a használatomat?
- Hogyan szabhatom testre a modelleket?
- Milyen programozási nyelveket használhatok?
- Hozzászólás mes données sont-elles sécurisées ?
- 私のデータはどのように保護されていますか?
- Quais fornecedores de modelos estão disponíveis por meio do Bedrock?
- A welchen régióban az Amazon Bedrock verfügbar?
- 有哪些级别的支持?
Vegye figyelembe, hogy bár a forrásanyag angol nyelvű volt, a más nyelvű lekérdezéseket a megfelelő bejegyzésekkel egyeztették.
Következtetés
Az alapmodellek szöveggenerálási képességei nagyon izgalmasak, de nem szabad elfelejteni, hogy a szöveg megértése, a releváns tartalom megtalálása a tudásanyagból, valamint a szövegrészek közötti kapcsolatok kialakítása elengedhetetlen a generatív mesterséges intelligencia teljes értékének eléréséhez. A következő években továbbra is látni fogjuk a beágyazások új és érdekes felhasználási módjait, ahogy ezek a modellek folyamatosan javulnak.
A következő lépések
További példákat találhat jegyzetfüzetként vagy bemutatóalkalmazásként történő beágyazásra a következő műhelyekben:
A szerzőkről
 Jason Stehle Senior Solutions Architect az AWS-nél, székhelye New England területén található. Együttműködik az ügyfelekkel, hogy az AWS képességeit a legnagyobb üzleti kihívásokhoz igazítsa. A munkán kívül építkezéssel és képregényfilmek nézésével tölti idejét családjával.
Jason Stehle Senior Solutions Architect az AWS-nél, székhelye New England területén található. Együttműködik az ügyfelekkel, hogy az AWS képességeit a legnagyobb üzleti kihívásokhoz igazítsa. A munkán kívül építkezéssel és képregényfilmek nézésével tölti idejét családjával.
 Nitin Eusebius Sr. Enterprise Solutions Architect az AWS-nél, tapasztalattal rendelkezik a szoftverfejlesztés, a vállalati architektúra és az AI/ML területén. Mélyen lelkesedik a generatív mesterséges intelligencia lehetőségeinek feltárásáért. Együttműködik az ügyfelekkel, hogy segítsen nekik jól megtervezett alkalmazásokat építeni az AWS platformon, és elkötelezett a technológiai kihívások megoldása és a felhőalapú utazásuk segítése iránt.
Nitin Eusebius Sr. Enterprise Solutions Architect az AWS-nél, tapasztalattal rendelkezik a szoftverfejlesztés, a vállalati architektúra és az AI/ML területén. Mélyen lelkesedik a generatív mesterséges intelligencia lehetőségeinek feltárásáért. Együttműködik az ügyfelekkel, hogy segítsen nekik jól megtervezett alkalmazásokat építeni az AWS platformon, és elkötelezett a technológiai kihívások megoldása és a felhőalapú utazásuk segítése iránt.
 Raj Pathak a Fortune 50 listán szereplő nagyvállalatok és közepes méretű pénzügyi szolgáltató intézmények (FSI) fő megoldási építésze és műszaki tanácsadója Kanadában és az Egyesült Államokban. Olyan gépi tanulási alkalmazásokra specializálódott, mint a generatív AI, a természetes nyelvi feldolgozás, az intelligens dokumentumfeldolgozás és az MLOps.
Raj Pathak a Fortune 50 listán szereplő nagyvállalatok és közepes méretű pénzügyi szolgáltató intézmények (FSI) fő megoldási építésze és műszaki tanácsadója Kanadában és az Egyesült Államokban. Olyan gépi tanulási alkalmazásokra specializálódott, mint a generatív AI, a természetes nyelvi feldolgozás, az intelligens dokumentumfeldolgozás és az MLOps.
 Mani Khanuja Technikai vezető – Generatív mesterségesintelligencia-specialisták, az Alkalmazott gépi tanulás és nagy teljesítményű számítástechnika az AWS-en című könyv szerzője, valamint a Nők a Gyáriparos Oktatásban Alapítvány igazgatótanácsának tagja. Gépi tanulási (ML) projekteket vezet különböző területeken, mint például a számítógépes látás, a természetes nyelvi feldolgozás és a generatív mesterséges intelligencia. Segít ügyfeleinek nagyméretű gépi tanulási modellek létrehozásában, betanításában és üzembe helyezésében. Felszólal belső és külső konferenciákon, mint például a Re:Invent, a Women in Manufacturing West, a YouTube webináriumokon és a GHC 23-ban. Szabadidejében szeret hosszasan futni a tengerparton.
Mani Khanuja Technikai vezető – Generatív mesterségesintelligencia-specialisták, az Alkalmazott gépi tanulás és nagy teljesítményű számítástechnika az AWS-en című könyv szerzője, valamint a Nők a Gyáriparos Oktatásban Alapítvány igazgatótanácsának tagja. Gépi tanulási (ML) projekteket vezet különböző területeken, mint például a számítógépes látás, a természetes nyelvi feldolgozás és a generatív mesterséges intelligencia. Segít ügyfeleinek nagyméretű gépi tanulási modellek létrehozásában, betanításában és üzembe helyezésében. Felszólal belső és külső konferenciákon, mint például a Re:Invent, a Women in Manufacturing West, a YouTube webináriumokon és a GHC 23-ban. Szabadidejében szeret hosszasan futni a tengerparton.
 Mark Roy az AWS fő gépi tanulási építésze, aki segít az ügyfeleknek AI/ML megoldások tervezésében és kivitelezésében. Mark munkája az ML felhasználási esetek széles skáláját fedi le, elsősorban a számítógépes látás, a mély tanulás és az ML méretezése a vállalaton belül. Számos iparágban segített cégeknek, beleértve a biztosítást, a pénzügyi szolgáltatásokat, a médiát és a szórakoztatást, az egészségügyet, a közműveket és a gyártást. Mark hat AWS-tanúsítvánnyal rendelkezik, köztük az ML Specialty Certification-vel. Mielőtt csatlakozott az AWS-hez, Mark több mint 25 éven át építész, fejlesztő és technológiai vezető volt, ebből 19 évig pénzügyi szolgáltatásokkal foglalkozott.
Mark Roy az AWS fő gépi tanulási építésze, aki segít az ügyfeleknek AI/ML megoldások tervezésében és kivitelezésében. Mark munkája az ML felhasználási esetek széles skáláját fedi le, elsősorban a számítógépes látás, a mély tanulás és az ML méretezése a vállalaton belül. Számos iparágban segített cégeknek, beleértve a biztosítást, a pénzügyi szolgáltatásokat, a médiát és a szórakoztatást, az egészségügyet, a közműveket és a gyártást. Mark hat AWS-tanúsítvánnyal rendelkezik, köztük az ML Specialty Certification-vel. Mielőtt csatlakozott az AWS-hez, Mark több mint 25 éven át építész, fejlesztő és technológiai vezető volt, ebből 19 évig pénzügyi szolgáltatásokkal foglalkozott.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :van
- :is
- :nem
- :ahol
- $ UP
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- Rólunk
- absztrakció
- Elfogad!
- pontosság
- pontos
- pontosan
- elért
- elérése
- beszerzés
- át
- mellett
- További
- Előny
- tanácsadó
- előre
- AI
- AI modellek
- AI / ML
- algoritmusok
- összehangolása
- Minden termék
- lehetővé
- lehetővé téve
- lehetővé teszi, hogy
- mentén
- mellett
- Is
- mindig
- amazon
- Az Amazon Web Services
- an
- elemzés
- elemez
- és a
- válasz
- bármilyen
- Alkalmazás
- alkalmazások
- alkalmazott
- alkalmaz
- megközelítés
- építészet
- architektúrák
- VANNAK
- TERÜLET
- cikkek
- AS
- segítő
- At
- fokozza
- bővített
- szerző
- elérhető
- AWS
- alapján
- BE
- strand
- hogy
- Előnyök
- között
- bizottság
- Igazgatóság
- test
- könyv
- Doboz
- épít
- Épület
- üzleti
- de
- by
- TUD
- Kanada
- jelölt
- jelöltek
- képességek
- elfog
- fogások
- eset
- esetek
- kategóriák
- Tanúsítvány
- tanúsítványok
- kihívások
- besorolás
- vásárló
- közel
- felhő
- csoportosítás
- kód
- gyűjtemény
- Főiskolák
- kombináció
- Közös
- Companies
- vállalat
- összehasonlítani
- panaszok
- bonyolult
- számítógép
- Számítógépes látás
- számítástechnika
- fogalmak
- aggodalmak
- konferenciák
- Configuration
- Csatlakozás
- kapcsolat
- kapcsolatok
- következetes
- tartalom
- kontextus
- szövegre vonatkozó
- folytatódik
- kényelmesen
- megtérít
- átalakított
- együttműködés
- koordinációs
- költséghatékony
- tudott
- fedő
- burkolatok
- teremt
- létrehozása
- kritériumok
- kritikus
- Jelenleg
- szokás
- vevő
- Ügyfelek
- testre
- dátum
- adatbázis
- de
- elszánt
- mély
- mély tanulás
- mélyen
- meghatározott
- Fok
- Demó
- bizonyítani
- telepíteni
- körülír
- Design
- úticél
- részletek
- Fejlesztő
- különböző
- nehéz
- Dimenzió
- közvetlenül
- igazgatók
- megvitatni
- kijelző
- do
- dokumentum
- dokumentumok
- domainek
- ne
- minden
- Oktatás
- hatékonyan
- bármelyik
- e-mailek
- beágyazás
- felmerül
- lehetővé
- lehetővé teszi
- Motor
- Mérnöki
- Anglia
- Angol
- Vállalkozás
- Vállalati megoldások
- Szórakozás
- Egész
- teljesen
- egység
- Eter (ETH)
- értékelni
- Még
- példa
- példák
- izgalmas
- Bontsa
- tapasztalat
- tapasztalt
- Magyarázza
- Feltárása
- kiterjesztés
- külső
- megkönnyítése
- tényező
- család
- Jellemzők
- kevés
- pénzügyi
- pénzügyi szolgáltatások
- Találjon
- megtalálása
- vezetéknév
- Rugalmasság
- összpontosított
- következő
- A
- forma
- Szerencse
- Alapítvány
- Keretrendszer
- Ingyenes
- ból ből
- Tele
- alapvető
- generál
- generáció
- nemző
- Generatív AI
- kap
- szerzés
- Giving
- kesztyű
- Go
- legnagyobb
- kellett
- Legyen
- he
- egészségügyi
- segít
- segített
- segít
- segít
- neki
- Magas
- Nagy teljesítményű számítástechnika
- övé
- tart
- Hogyan
- How To
- HTML
- HTTPS
- i
- azonosítani
- if
- végrehajtási
- importál
- fontos
- javul
- in
- Más
- tartalmaz
- magában foglalja a
- Beleértve
- iparágak
- információ
- bemenet
- telepíteni
- helyette
- intézmények
- biztosítás
- Intelligens
- Intelligens dokumentumfeldolgozás
- kamat
- érdekes
- Felület
- interfészek
- belső
- Nemzetközi
- bele
- IT
- ITS
- csatlakozott
- utazás
- jpg
- json
- Kulcs
- Ismer
- Ismerve
- tudás
- táj
- nyelv
- Nyelvek
- nagy
- réteg
- vezet
- vezető
- vezetékek
- tanulás
- hadd
- mint
- Valószínű
- Kedvencek
- korlátozó
- Lista
- llm
- logikus
- Hosszú
- néz
- keres
- gép
- gépi tanulás
- fenntartása
- csinál
- Gyártás
- sikerült
- vezetés
- gyártási
- sok
- térkép
- jel
- Marké
- piacok
- párosított
- gyufa
- egyező
- anyag
- me
- jelenti
- eszközök
- Média
- tag
- módszer
- esetleg
- ML
- ML algoritmusok
- MLOps
- modell
- modellek
- monitor
- több
- a legtöbb
- Legnepszerubb
- Filmek
- többszörös
- my
- név
- Nevezett
- nevek
- Természetes
- Természetes nyelv
- Természetes nyelvi feldolgozás
- Szükség
- igénylő
- igények
- Új
- következő
- NLP
- laptopok
- Nyilvánvaló
- of
- felajánlott
- on
- ONE
- online
- nyitva
- nyílt forráskódú
- optimalizált
- optimalizálása
- or
- érdekében
- Más
- Egyéb
- mi
- ki
- teljesítmény
- kívül
- felett
- saját
- csomagok
- párosított
- paraméter
- paraméterek
- anyavállalat
- szakaszok
- szenvedélyes
- Mintás
- minták
- mert
- teljesít
- teljesítmény
- Testreszabás
- kifejezés
- darab
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- játszani
- kérem
- Népszerű
- BY
- portfolió
- portfóliók
- lehetőségek
- állás
- postgresql
- potenciális
- hatalom
- elsődleges
- Fő
- Előzetes
- problémák
- folyamat
- feldolgozás
- Termékek
- termék vélemények
- Termékek
- Programozás
- programozási nyelvek
- projektek
- utasításokat
- szabadalmazott
- ad
- feltéve,
- biztosít
- Piton
- világítás
- lekérdezések
- kérdés
- kérdés
- Kérdések
- Quick
- rongy
- hatótávolság
- RE
- el
- való Világ
- elismerés
- Ajánlást
- ajánlások
- rekord
- nyilvántartások
- kifejezés
- Kapcsolatok
- eszébe jut
- raktár
- képviselet
- jelentése
- kérni
- kötelező
- válasz
- REST
- korlátozott
- kapott
- Eredmények
- visszakeresés
- Visszatér
- Vélemények
- Szerep
- futás
- fut
- s
- azonos
- azt mondják
- Skála
- skálázás
- forgatókönyv
- forgatókönyvek
- sdk
- Keresés
- lát
- szemantikus
- szemantika
- idősebb
- mondat
- érzés
- különálló
- vagy szerver
- Szolgáltatások
- ő
- hasonló
- Egyszerű
- egyszerűség
- egyszerűsített
- egyszerűsítése
- egyetlen
- SIX
- So
- szoftver
- szoftverfejlesztés
- Megoldások
- SOLVE
- Megoldása
- néhány
- valami
- forrás
- Források
- Hely
- beszél
- szakemberek
- specializálódott
- Különlegesség
- különleges
- kezdet
- kezdődött
- Államok
- tárolni
- struktúrák
- ilyen
- támogatás
- Támogatott
- Támogató
- Támogatja
- Vesz
- feladatok
- csapat
- tech
- Műszaki
- technika
- technikák
- Technologies
- Technológia
- mondd
- szöveg
- Szöveg osztályozása
- szöveggenerálás
- hogy
- A
- The Source
- azok
- Őket
- témák
- akkor
- Ott.
- Ezek
- dolgok
- ezt
- azok
- bár?
- Keresztül
- idő
- titán-
- nak nek
- tokenek
- hagyományos
- Vonat
- kiképzett
- transzformerek
- transzformáló
- megért
- megértés
- egységes
- Egyesült
- Egyesült Államok
- Használat
- használ
- használati eset
- használt
- hasznos
- használó
- felhasználói felület
- Felhasználók
- segítségével
- segédprogramok
- vakáció
- érték
- különféle
- Járművek
- nagyon
- keresztül
- látomás
- akar
- volt
- őrzés
- we
- háló
- webalkalmazás
- webes szolgáltatások
- Webinárium
- JÓL
- voltak
- Nyugati
- amikor
- ami
- míg
- széles
- Széleskörű
- lesz
- val vel
- belül
- nélkül
- Női
- szó
- szavak
- Munka
- dolgozó
- művek
- Műhelyek
- lenne
- ír
- írás
- év
- te
- A te
- youtube
- zephyrnet