Ma örömmel jelentjük be, hogy elérhető a Llama 2 következtetési és finomhangolási támogatása AWS Trainium és a AWS Inferentia példányok be Amazon SageMaker JumpStart. Az AWS Trainium és Inferentia alapú példányok SageMakeren keresztüli használatával a felhasználók akár 50%-kal csökkenthetik a finomhangolási költségeket, és 4.7-szeresére csökkenthetik a telepítési költségeket, miközben csökkentik a tokenenkénti késleltetést. A Llama 2 egy automatikusan regresszív generatív szövegnyelvi modell, amely optimalizált transzformátor architektúrát használ. Nyilvánosan elérhető modellként a Llama 2-t számos NLP-feladatra tervezték, mint például a szövegosztályozás, a hangulatelemzés, a nyelvi fordítás, a nyelvi modellezés, a szöveggenerálás és a párbeszédrendszerek. Az LLM-ek finomhangolása és telepítése, mint például a Llama 2, költségessé vagy kihívást jelenthet a valós idejű teljesítmény elérése érdekében, hogy jó ügyfélélményt biztosítsanak. A Trainium és AWS Inferentia által engedélyezett AWS Neuron szoftverfejlesztő készlet (SDK), nagy teljesítményű és költséghatékony lehetőséget kínál a Llama 2 modellek betanítására és következtetéseire.
Ebben a bejegyzésben bemutatjuk, hogyan telepíthető és finomhangolható a Llama 2 Trainium és AWS Inferentia példányokon a SageMaker JumpStartban.
Megoldás áttekintése
Ebben a blogban a következő forgatókönyveket fogjuk végigjárni:
- Telepítse a Llama 2-t az AWS Inferentia példányokon mindkét esetben Amazon SageMaker Studio UI, egy kattintásos üzembe helyezési tapasztalattal és a SageMaker Python SDK-val.
- Finomhangolja a Llama 2-t a Trainium példányokon a SageMaker Studio felhasználói felületén és a SageMaker Python SDK-ban egyaránt.
- Hasonlítsa össze a finomhangolt Llama 2 modell teljesítményét az előre betanított modellével, hogy megmutassa a finomhangolás hatékonyságát.
A kézhezvételhez lásd a GitHub példajegyzetfüzet.
Telepítse a Llama 2-t AWS Inferentia példányokon a SageMaker Studio UI és a Python SDK használatával
Ebben a részben bemutatjuk, hogyan telepítheti a Llama 2-t AWS Inferentia-példányokon a SageMaker Studio felhasználói felületével az egykattintásos telepítéshez és a Python SDK-val.
Fedezze fel a Llama 2 modellt a SageMaker Studio felhasználói felületén
A SageMaker JumpStart hozzáférést biztosít mind a nyilvánosan, mind a szabadalmaztatottakhoz alapozó modellek. Az alapítványi modelleket külső és védett szolgáltatók építik be és tartják karban. Mint ilyenek, a modellforrás által megjelölt különböző licencek alatt kerülnek kiadásra. Feltétlenül tekintse át minden használt alapmodell licencét. Ön felelős azért, hogy a tartalom letöltése vagy használata előtt átnézzen és betartsa a vonatkozó licencfeltételeket, és megbizonyosodjon arról, hogy azok az Ön használati esetére elfogadhatók.
A Llama 2 alapozó modelleket a SageMaker JumpStart segítségével érheti el a SageMaker Studio UI-ban és a SageMaker Python SDK-ban. Ebben a részben áttekintjük, hogyan fedezheti fel a modelleket a SageMaker Stúdióban.
A SageMaker Studio egy integrált fejlesztői környezet (IDE), amely egyetlen web-alapú vizuális felületet biztosít, ahol hozzáférhet a célra épített eszközökhöz a gépi tanulás (ML) fejlesztési lépéseinek végrehajtásához, az adatok előkészítésétől az ML felépítéséig, betanításáig és telepítéséig. modellek. A SageMaker Studio megkezdésével és beállításával kapcsolatos további részletekért lásd: Amazon SageMaker Studio.
A SageMaker Studio használata után elérheti a SageMaker JumpStart alkalmazást, amely előre betanított modelleket, notebookokat és előre elkészített megoldásokat tartalmaz. Előre elkészített és automatizált megoldások. A védett modellek elérésével kapcsolatos részletesebb információkért lásd: Használja az Amazon SageMaker JumpStart szabadalmaztatott alapozómodelljeit az Amazon SageMaker Studio alkalmazásban.
A SageMaker JumpStart nyitóoldalán megoldások, modellek, notebookok és egyéb források között böngészhet.
Ha nem látja a Llama 2 modelleket, frissítse a SageMaker Studio verzióját úgy, hogy leállítja és újraindítja. A verziófrissítésekkel kapcsolatos további információkért lásd: Zárja le és frissítse a Studio Classic alkalmazásokat.

Választással más modellváltozatokat is találhat Fedezze fel az összes szöveggenerációs modellt vagy keres llama or neuron a keresőmezőben. Ezen az oldalon megtekintheti a Llama 2 Neuron modelleket.
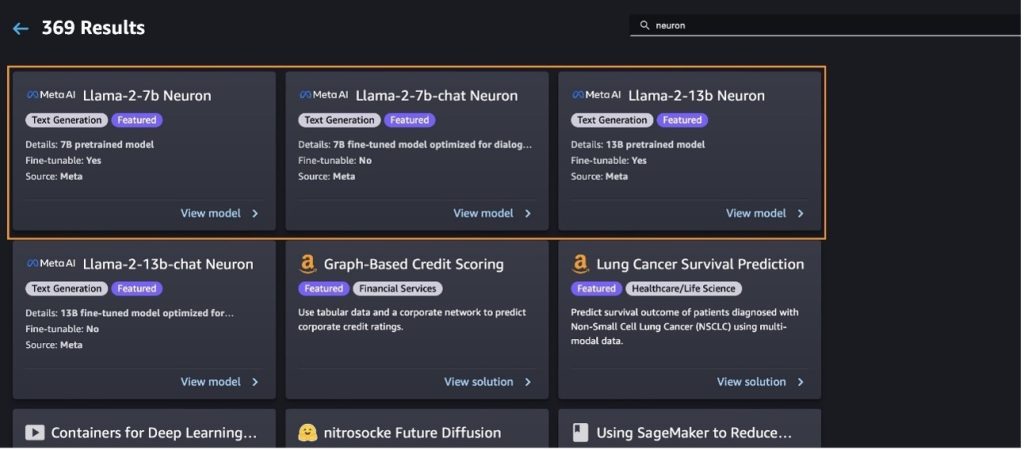
Telepítse a Llama-2-13b modellt a SageMaker Jumpstart segítségével
A modellkártya kiválasztásával megtekintheti a modell részleteit, például a licencet, a betanításhoz használt adatokat és a használat módját. Két gombot is találhat, Telepítése és a Nyissa meg a jegyzetfüzetet, amelyek segítenek a modell használatában ezzel a kód nélküli példával.
Ha bármelyik gombot választja, egy felugró ablakban megjelenik a végfelhasználói licencszerződés és az elfogadható használati szabályzat (AUP), amelyet tudomásul kell venni.
Miután jóváhagyta a házirendeket, telepítheti a modell végpontját, és használhatja azt a következő szakasz lépései szerint.
Telepítse a Llama 2 Neuron modellt a Python SDK-n keresztül
Ha úgy dönt Telepítése és nyugtázza a feltételeket, megkezdődik a modell bevezetése. Alternatív megoldásként a példajegyzetfüzeten keresztül is telepítheti, ha kiválasztja Nyissa meg a jegyzetfüzetet. A példajegyzetfüzet teljes körű útmutatást nyújt a modell telepítéséhez a következtetések levonásához és az erőforrások tisztításához.
Egy modell Trainium vagy AWS Inferentia példányokon való üzembe helyezéséhez vagy finomhangolásához először meg kell hívnia a PyTorch Neuron (fáklya-neuronx), hogy a modellt Neuron-specifikus gráfba állítsa, amely optimalizálja azt az Inferentia neuronmagjaira. A felhasználók utasíthatják a fordítót, hogy az alkalmazás céljaitól függően optimalizálja a legalacsonyabb késleltetést vagy a legnagyobb átviteli sebességet. A JumpStartban előre összeállítottuk a Neuron grafikonokat a különféle konfigurációkhoz, hogy a felhasználók áttekinthessék a fordítási lépéseket, lehetővé téve a modellek gyorsabb finomhangolását és üzembe helyezését.
Vegye figyelembe, hogy a Neuron előre lefordított grafikonja a Neuron Compiler verziójának egy adott verziója alapján jön létre.
Kétféleképpen telepítheti a LIama 2-t AWS Inferentia alapú példányokon. Az első módszer az előre beépített konfigurációt használja, és lehetővé teszi a modell telepítését mindössze két kódsorban. A másodikban nagyobb irányítása van a konfiguráció felett. Kezdjük az első módszerrel, az előre elkészített konfigurációval, és példaként használjuk az előre betanított Llama 2 13B Neuron modellt. A következő kód bemutatja, hogyan telepíthető a Llama 13B mindössze két sorral:
Ha ezekre a modellekre szeretne következtetést levonni, meg kell adnia az argumentumot accept_eula lenni True részeként model.deploy() hívás. Ha ezt az érvet igaznak állítja, akkor elismeri, hogy elolvasta és elfogadta a modell EULA-ját. Az EULA megtalálható a modellkártya leírásában vagy a Meta weboldal.
A Llama 2 13B alapértelmezett példánytípusa az ml.inf2.8xlarge. Kipróbálhat más támogatott modellazonosítókat is:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(chat modell)meta-textgenerationneuron-llama-2-13b-f(chat modell)
Alternatív megoldásként, ha jobban szeretné szabályozni a telepítési konfigurációkat, például a környezeti hosszt, a tenzor párhuzamos fokát és a maximális gördülő kötegméretet, módosíthatja azokat környezeti változókon keresztül, amint azt ebben a szakaszban bemutatjuk. A telepítés mögöttes Deep Learning Container (DLC) a Large Model Inference (LMI) NeuronX DLC. A környezeti változók a következők:
- OPTION_N_POSITIONS – A bemeneti és kimeneti tokenek maximális száma. Például, ha a modellt azzal állítod össze
OPTION_N_POSITIONSmint 512, akkor használhat egy 128-as bemeneti tokent (bemeneti prompt mérete), a maximális kimeneti tokent pedig 384-et (a bemeneti és kimeneti tokennek összesen 512-nek kell lennie). A maximális kimeneti tokenhez bármilyen 384 alatti érték megfelelő, de nem lépheti túl azt (például a 256-os bemenet és az 512-es kimenet). - OPTION_TENSOR_PARALLEL_DEGREE – A modell AWS Inferentia példányaiba való betöltéséhez szükséges NeuronCore-ok száma.
- OPTION_MAX_ROLLING_BATCH_SIZE – Az egyidejű kérések maximális kötegmérete.
- OPTION_DTYPE – A modell betöltésének dátumtípusa.
A Neuron gráf összeállítása a környezet hosszától függ (OPTION_N_POSITIONS), tenzor párhuzamos fok (OPTION_TENSOR_PARALLEL_DEGREE), maximális tételméret (OPTION_MAX_ROLLING_BATCH_SIZE), és az adattípus (OPTION_DTYPE) a modell betöltéséhez. A SageMaker JumpStart előre összeállított Neuron gráfokat különféle konfigurációkhoz az előző paraméterekhez, hogy elkerülje a futásidejű fordítást. Az előre összeállított grafikonok konfigurációit a következő táblázat sorolja fel. Mindaddig, amíg a környezeti változók a következő kategóriák valamelyikébe tartoznak, a Neuron-gráfok összeállítása kimarad.
| LIama-2 7B és LIama-2 7B Chat | ||||
| Példánytípus | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B és LIama-2 13B Chat | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
A következő egy példa a Llama 2 13B telepítésére és az összes elérhető konfiguráció beállítására.
Most, hogy üzembe helyeztük a Llama-2-13b modellt, a végpont meghívásával következtetéseket vonhatunk le vele. A következő kódrészlet bemutatja a támogatott következtetési paraméterek használatát a szöveggenerálás szabályozására:
- max_length – A modell addig generál szöveget, amíg el nem éri a kimeneti hosszt (amely tartalmazza a bemeneti környezet hosszát).
max_length. Ha meg van adva, pozitív egész számnak kell lennie. - max_new_tokens – A modell addig generál szöveget, amíg el nem éri a kimeneti hosszt (a bemeneti kontextus hosszát kivéve).
max_new_tokens. Ha meg van adva, pozitív egész számnak kell lennie. - gerendák száma – Ez jelzi a mohó keresésben használt sugarak számát. Ha meg van adva, akkor nagyobbnak vagy egyenlőnek kell lennie, mint
num_return_sequences. - no_repeat_ngram_size – A modell biztosítja, hogy egy szósorozat a
no_repeat_ngram_sizenem ismétlődik a kimeneti sorrendben. Ha meg van adva, akkor 1-nél nagyobb pozitív egész számnak kell lennie. - hőmérséklet – Ez szabályozza a kimenet véletlenszerűségét. A magasabb hőmérséklet kis valószínűségű szavakat tartalmazó kimeneti sorozatot eredményez; az alacsonyabb hőmérséklet egy kimeneti sorozatot eredményez nagy valószínűségű szavakkal. Ha
temperatureegyenlő 0-val, ez mohó dekódolást eredményez. Ha meg van adva, pozitív lebegésnek kell lennie. - korai_megállás - Ha
True, a szöveggenerálás akkor fejeződik be, amikor az összes gerenda hipotézis eléri a mondat token végét. Ha meg van adva, akkor logikai értéknek kell lennie. - do_sample - Ha
True, a modell a valószínűség szerint mintát vesz a következő szóból. Ha meg van adva, akkor logikai értéknek kell lennie. - top_k – A szöveggenerálás minden lépésében a modell csak a
top_klegvalószínűbb szavak. Ha meg van adva, pozitív egész számnak kell lennie. - top_p – A szöveggenerálás minden lépésében a modell a lehető legkisebb szókészletből vesz mintát, halmozott valószínűséggel
top_p. Ha meg van adva, akkor 0–1 közötti úszónak kell lennie. - megáll – Ha meg van adva, akkor karakterláncok listájának kell lennie. A szöveggenerálás leáll, ha a megadott karakterláncok bármelyike létrejön.
A következő kód példát mutat:
teljesítmény:
A hasznos teher paramétereivel kapcsolatos további információkért lásd: Részletes paraméterek.
A paraméterek megvalósítását is felfedezheti a jegyzetfüzet hogy további információkat adjon meg a jegyzetfüzet hivatkozásáról.
Finomhangolja a Llama 2 modelleket Trainium példányokon a SageMaker Studio UI és a SageMaker Python SDK segítségével
A generatív AI-alapmodellek az ML és az AI elsődleges fókuszpontjává váltak, azonban széles körű általánosításuk elmaradhat bizonyos területeken, például az egészségügyben vagy a pénzügyi szolgáltatásokban, ahol egyedi adatkészletekről van szó. Ez a korlátozás rávilágít arra, hogy ezeket a generatív AI-modelleket tartomány-specifikus adatokkal kell finomítani, hogy javítsák teljesítményüket ezeken a speciális területeken.
Most, hogy bevezettük a Llama 2 modell előre betanított verzióját, nézzük meg, hogyan tudjuk ezt a tartomány-specifikus adatokra finomhangolni a pontosság növelése, a modell javítása a gyors befejezések szempontjából, és a modell adaptálása az Ön konkrét üzleti felhasználási esete és adatai. A modelleket a SageMaker Studio UI vagy a SageMaker Python SDK segítségével finomhangolhatja. Ebben a részben mindkét módszert tárgyaljuk.
Finomhangolja a Llama-2-13b Neuron modellt a SageMaker Studio segítségével
A SageMaker Stúdióban keresse meg a Llama-2-13b Neuron modellt. A Telepítése lapon rámutathat a Amazon egyszerű tárolási szolgáltatás (Amazon S3) vödör, amely a képzési és érvényesítési adatkészleteket tartalmazza a finomhangoláshoz. Ezenkívül konfigurálhatja a központi telepítési konfigurációt, a hiperparamétereket és a biztonsági beállításokat a finomhangoláshoz. Akkor válassz Vonat a betanítási feladat elindításához egy SageMaker ML példányon.

A Llama 2 modellek használatához el kell fogadnia az EULA-t és az AUP-t. Akkor jelenik meg, amikor választasz Vonat. Válaszd ki Elolvastam és elfogadom az EULA-t és az AUP-t a finomhangolási munka megkezdéséhez.
A SageMaker konzolon megtekintheti a finomhangolt modellre vonatkozó betanítási feladatának állapotát, ha kiválasztja Képzési munkák a navigációs ablaktáblában.
Finomhangolhatja Llama 2 Neuron modelljét ezzel a kód nélküli példával, vagy finomhangolhatja a Python SDK-n keresztül, ahogy a következő részben bemutatjuk.
Finomhangolja a Llama-2-13b Neuron modellt a SageMaker Python SDK segítségével
Finomhangolhatja az adatkészletet a domain adaptációs formátummal vagy a utasítás alapú finomhangolás formátum. Az alábbiakban ismertetjük, hogyan kell formázni az edzési adatokat a finomhangolásba való elküldés előtt:
- Bemenet - A
trainJSON-sorokat (.jsonl) vagy szöveges (.txt) formázott fájlt tartalmazó könyvtár.- A JSON-vonalak (.jsonl) fájl esetében minden sor külön JSON-objektum. Minden JSON-objektumot kulcs-érték párként kell felépíteni, ahol a kulcsnak kell lennie
text, és az érték egy képzési példa tartalma. - A vonatkönyvtárban lévő fájlok számának 1-nek kell lennie.
- A JSON-vonalak (.jsonl) fájl esetében minden sor külön JSON-objektum. Minden JSON-objektumot kulcs-érték párként kell felépíteni, ahol a kulcsnak kell lennie
- teljesítmény – Egy betanított modell, amelyből következtetni lehet.
Ebben a példában a részhalmazát használjuk Dolly adatkészlet utasítás hangolási formátumban. A Dolly adatkészlet körülbelül 15,000 2.0 utasításkövető rekordot tartalmaz különböző kategóriákhoz, például kérdések megválaszolásához, összefoglaláshoz és információ kinyeréséhez. Az Apache XNUMX licenc alatt érhető el. Használjuk a information_extraction példák a finomhangoláshoz.
- Töltse be a Dolly adatkészletet, és ossza fel
train(finomhangoláshoz) éstest(értékeléshez):
- Használjon prompt sablont az adatok előfeldolgozásához a betanítási feladat utasításformátumában:
- Vizsgálja meg a hiperparamétereket, és írja felül őket saját felhasználási esetére:
- Finomhangolja a modellt, és kezdjen el egy SageMaker képzési munkát. A finomhangoló szkriptek a neuronx-nemo-megatron repository, amelyek a csomagok módosított változatai nemo és a Csúcs amelyeket a Neuron és EC2 Trn1 példányokkal való használatra adaptáltak. A neuronx-nemo-megatron Az adattár 3D (adat, tenzor és csővezeték) párhuzamossággal rendelkezik, amely lehetővé teszi az LLM-ek méretarányos finomhangolását. A támogatott Trainium példányok: ml.trn1.32xlarge és ml.trn1n.32xlarge.
- Végül helyezze üzembe a finomhangolt modellt egy SageMaker végpontban:
Hasonlítsa össze az előre betanított és a finomhangolt Llama 2 Neuron modellek válaszait
Most, hogy bevezettük a Llama-2-13b modell előre betanított verzióját és finomhangoltuk, megtekinthetjük a két modell azonnali befejezésének teljesítmény-összehasonlítását, amint az a következő táblázatban látható. Példát is kínálunk a Llama 2 finomhangolására egy .txt formátumú SEC-fájladatkészleten. A részletekért lásd a GitHub példajegyzetfüzet.
| Tétel | Bemenetek | Földi igazság | Válasz a nem finomhangolt modelltől | Válasz a finomhangolt modelltől |
| 1 | Az alábbiakban egy utasítás található, amely egy feladatot ír le, és egy további kontextust biztosító bemenettel párosul. Írjon egy választ, amely megfelelően kiegészíti a kérést.nn### Utasítás:nKivonja ki azokat az egyetemeket, ahol Moret tanult, és mindegyikre a diploma megszerzésének évét, és tegye fel őket egy felsorolásba.nn### Input:nMoret 1953-ban született Vevey Svájcban Egyetemi tanulmányait az École Polytechnique Fédérale de Lausanne-ban (EPFL) végezte, 1975-ben diplomázott. A Tennessee Egyetemen végzett, ahol Ph.D fokozatot szerzett. 1980-ban. Ezután csatlakozott a University of New Mexico karához, ahol 2006-ig maradt, amikor is az EPFL-hez költözött. 2016 decemberében vonult vissza az EPFL-től.nn1996-ban Moret megalapította az ACM Journal of Experimental Algorithmics-t, és 2003-ig a folyóirat főszerkesztője maradt. 2001-ben Moret megalapította a Workshop in Algorithms for Bioinformatics (WABI) nevű műhelyt, és továbbra is a A konferencia irányítóbizottsága.nn 2018-ban Moret a Számítógépes Biológia Nemzetközi Társaságának tagjává választották a számítógépes biológia és a bioinformatika területén végzett kiemelkedő hozzájárulásáért.nn### Válasz:n | * École Polytechnique Fédérale de Lausanne (EPFL) (1975-ben végzett)n* Tennessee Egyetem (1980-ban végzett) | Moret az École Polytechnique Fédérale de Lausanne-ban (EPFL) és a Tennessee Egyetemen tanult, 1975-ben, illetve 1980-ban végzett.nn### Tipp:nn- Használja a `split` funkciót a bemenet mondatlistára bontásához.n- Használja a "split" funkciót az egyes mondatok szavak listájára való felosztásához.n- Használja a "felosztás" funkciót a felosztáshoz | – École Polytechnique Fédérale de Lausanne (EPFL), 1975n- University of Tennessee, 1980n- University of New Mexicon- École Polytechnique Fédérale de Lausanne (EPFL), 2006nn Az alábbiakban egy olyan utasítás található, amely leír egy feladatot, párosítva egy bemenettel további kontextust biztosít. Írjon választ, amely megfelelően kiegészíti a kérést.n |
| 2 | Az alábbiakban egy utasítás található, amely egy feladatot ír le, és egy további kontextust biztosító bemenettel párosul. Írjon egy választ, amely megfelelően befejezi a kérést.nn### Utasítás:nA szakaszból azonosítsa Dionüszosz attribútumait. Az eredmények megjelenítése vesszővel elválasztva színház. Zeusz és Szemele kétszer született fia, mivel Zeusz kiragadta őt anyja méhéből, és Dionüszoszt a saját combjába varrta, és addig vitte, amíg készen nem állt a születésre. A művészetben vagy idősebb szakállas istenként (különösen ie 430 előtt), vagy nőies, hosszú hajú fiatalként (különösen ie 430 után) ábrázolják. Tulajdonságai közé tartozik a thyrsus, az ivópohár, a szőlőtőke és a borostyán korona. Gyakran van tiászai társaságában, egy csoport kísérője, köztük szatírok, maenádok és régi tanítója, Silenus. Dionüszosz hitvese Ariadné volt. Egyszer azt tartották, hogy Dionysius a görög panteon későbbi kiegészítése volt, de a Lineáris B táblák felfedezése megerősíti isteni státuszát a korai időszakból. Bacchus volt a másik neve a görögben, és a rómaiak körében általánosan használt. Szent állatai közé tartoznak a delfinek, kígyók, tigrisek és szamarak.nn### Válasz:n | a thyrsus, egy ivópohár, a szőlő, egy borostyán korona | Dionüszosz (Διόνυσος, Diónusos)nnA bor, a termékenység, a bulik, a fesztiválok, az őrület, a káosz, a részegség, a növényzet, az eksztázis és a színház istene. Zeusz és Szemele kétszer született fia, mivel Zeusz kiragadta az anyja méhéből, és belevarrta Dionüszoszt a saját combjába. | thyrsus, ivópohár, szőlőtőke, ivynn korona Az alábbiakban egy feladatot leíró utasítás található, párosítva egy további kontextust biztosító bemenettel. Írjon egy választ, amely megfelelően kiegészíti a kérést.nn### Utasítás:nMi a különbség a Pártus és az Arsacid Birodalom között?nn### Input:nA Pártus Birodalom, más néven Arsacid Birodalom egy |
| 3 | Az alábbiakban egy utasítás található, amely egy feladatot ír le, és egy további kontextust biztosító bemenettel párosul. Írjon egy választ, amely megfelelően kiegészíti a kérést.nn### Utasítás:nMiért található Üzbegisztán fővárosában a legnagyobb görög közösség?nn### Bemenet:nAz üzbegisztáni görögök száma körülbelül 9,000. A közösséget Oroszországból származó görögök alkotják, akiket az 1940-es években erőszakkal deportáltak Üzbegisztánba, valamint Görögországból érkező politikai menekültek. Körülbelül 30,000 11,000 görög élt az országban a második világháború előtt, további 40,000 1960 pedig a görög polgárháború és a Görög Demokratikus Hadsereg veresége után érkezett. Számuk az 19-as években elért 571 XNUMX-es csúcsról lecsökkent. A fő ok a hidegháború utáni görögországi kivándorlás, amikor a törvények lehetővé tették a görög polgárháború után politikai okokból száműzetett összes görög nemzetiségű visszatérését. Az ország legnagyobb görög közössége a fővárosban, Taskentben található, ahová a legtöbb görög politikai menekültet áthelyezték a szovjet hatóságok. Az ókorban az ország déli része a hellenisztikus szeleukida királyság része volt, de az ottani néhány görög közösség azóta asszimilálódott. A görög nemzetiségűeket képviselő legfontosabb szervezet a Taskenti Görög Kulturális Egyesület. Ennek a szervezetnek a tevékenységei közé tartozik a görög nyelvoktatás (XNUMX osztály összesen XNUMX tanulóval, felnőtt órák), valamint görög táncok és zene oktatása.nn### Response:n | Az Üzbegisztánban tartózkodó görög politikai menekültek nagy részét a szovjet hatóságok a fővárosba, Taskentbe telepítették át. | n“`nÜzbegisztán fővárosában található a legnagyobb görög közösség, mivel a görögök száma Üzbegisztánban körülbelül 9,000. A közösséget Oroszországból származó görögök alkotják, akiket az 1940-es években erőszakkal hurcoltak el Üzbegisztánba, valamint Görögországból érkező politikai menekültek. A második világháború előtt körülbelül 30,000 11,00 görög élt az országban, és további XNUMX XNUMX | Üzbegisztán fővárosában található a legnagyobb görög közösség, mert oda telepítették át a legtöbb görög politikai menekültet a szovjet hatóságok, miután kiutasították őket Görögországból.nn Az alábbiakban egy utasítást találunk, amely egy feladatot ír le, és egy olyan bemenettel párosul további kontextus. Írjon egy választ, amely megfelelően kiegészíti a kérést.nn### Utasítás:nMi a különbség a Parthian és az Arsacid Empire között?nn### Input:n |
Láthatjuk, hogy a finomhangolt modell válaszai a pontosság, a relevancia és a tisztaság jelentős javulását mutatják az előre betanított modell válaszaihoz képest. Egyes esetekben előfordulhat, hogy az előre betanított modell használata nem elegendő, így ennek a technikának a finomhangolása a megoldást személyre szabottabbá teszi az adatkészlethez.
Tisztítsuk meg
Miután befejezte a képzési feladatot, és már nem kívánja használni a meglévő erőforrásokat, törölje az erőforrásokat a következő kóddal:
Következtetés
A Llama 2 Neuron modellek SageMakeren történő bevezetése és finomhangolása jelentős előrelépést jelent a nagyszabású generatív AI modellek kezelésében és optimalizálása terén. Ezek a modellek, beleértve az olyan változatokat, mint a Llama-2-7b és a Llama-2-13b, a Neuront használják a hatékony képzéshez és következtetésekhez az AWS Inferentia és Trainium alapú példányokon, javítva a teljesítményüket és a méretezhetőségüket.
Az a lehetőség, hogy ezeket a modelleket a SageMaker JumpStart UI-n és a Python SDK-n keresztül telepítheti, rugalmasságot és egyszerű használatot kínál. A Neuron SDK a népszerű ML keretrendszerek támogatásával és a nagy teljesítményű képességekkel lehetővé teszi ezeknek a nagy modelleknek a hatékony kezelését.
Ezeknek a modelleknek a tartományspecifikus adatokon történő finomhangolása kulcsfontosságú a relevanciájuk és pontosságuk növelése érdekében a speciális területeken. A SageMaker Studio felhasználói felületén vagy a Python SDK-n keresztül végrehajtható folyamat lehetővé teszi az egyedi igényekhez való testreszabást, ami javítja a modell teljesítményét a gyors befejezések és a válaszminőség tekintetében.
Összehasonlításképpen ezeknek a modelleknek az előre betanított verziói, bár erőteljesek, általánosabb vagy ismétlődő válaszokat adhatnak. A finomhangolás konkrét kontextusokhoz szabja a modellt, pontosabb, relevánsabb és változatosabb válaszokat eredményezve. Ez a testreszabás különösen szembetűnő az előre betanított és finomhangolt modellek válaszainak összehasonlításakor, ahol az utóbbi a kimenet minőségének és specifikusságának észrevehető javulását mutatja. Összefoglalva, a Neuron Llama 2 modellek telepítése és finomhangolása a SageMaker rendszeren robusztus keretrendszert jelent a fejlett mesterséges intelligencia modellek kezeléséhez, jelentős teljesítmény- és alkalmazhatóságjavulást kínálva, különösen, ha konkrét tartományokra vagy feladatokra szabják.
Kezdje el még ma a SageMaker minta hivatkozásával jegyzetfüzet.
Az előre betanított Llama 2 modellek GPU-alapú példányokon történő üzembe helyezésével és finomhangolásával kapcsolatos további információkért lásd: Finomhangolja a Llama 2-t a szöveggeneráláshoz az Amazon SageMaker JumpStarton és a A Meta Llama 2 alapozó modelljei már elérhetőek az Amazon SageMaker JumpStartban.
A szerzők szeretnének köszönetet mondani Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne és Mike James technikai közreműködéséért.
A szerzőkről
 Xin Huang az Amazon SageMaker JumpStart és az Amazon SageMaker beépített algoritmusainak vezető alkalmazott tudósa. A skálázható gépi tanulási algoritmusok fejlesztésére összpontosít. Kutatási területe a természetes nyelvi feldolgozás, a táblázatos adatok magyarázható mély tanulása és a nem-paraméteres tér-idő klaszterezés robusztus elemzése. Számos közleményt publikált az ACL-ben, az ICDM-ben, a KDD konferenciákon és a Royal Statistical Society: A sorozatban.
Xin Huang az Amazon SageMaker JumpStart és az Amazon SageMaker beépített algoritmusainak vezető alkalmazott tudósa. A skálázható gépi tanulási algoritmusok fejlesztésére összpontosít. Kutatási területe a természetes nyelvi feldolgozás, a táblázatos adatok magyarázható mély tanulása és a nem-paraméteres tér-idő klaszterezés robusztus elemzése. Számos közleményt publikált az ACL-ben, az ICDM-ben, a KDD konferenciákon és a Royal Statistical Society: A sorozatban.
 Nitin Eusebius Sr. Enterprise Solutions Architect az AWS-nél, tapasztalattal rendelkezik a szoftverfejlesztés, a vállalati architektúra és az AI/ML területén. Mélyen lelkesedik a generatív mesterséges intelligencia lehetőségeinek feltárásáért. Együttműködik az ügyfelekkel, hogy segítsen nekik jól megtervezett alkalmazásokat építeni az AWS platformon, és elkötelezett a technológiai kihívások megoldása és a felhőalapú utazásuk segítése iránt.
Nitin Eusebius Sr. Enterprise Solutions Architect az AWS-nél, tapasztalattal rendelkezik a szoftverfejlesztés, a vállalati architektúra és az AI/ML területén. Mélyen lelkesedik a generatív mesterséges intelligencia lehetőségeinek feltárásáért. Együttműködik az ügyfelekkel, hogy segítsen nekik jól megtervezett alkalmazásokat építeni az AWS platformon, és elkötelezett a technológiai kihívások megoldása és a felhőalapú utazásuk segítése iránt.
 Madhur Prashant az AWS generatív AI-terében dolgozik. Szenvedélyesen rajong az emberi gondolkodás és a generatív mesterséges intelligencia találkozási pontjaiért. Érdeklődése a generatív mesterséges intelligencia, különösen az olyan megoldások készítése, amelyek hasznosak és ártalmatlanok, és leginkább az ügyfelek számára optimálisak. A munkán kívül szeret jógázni, kirándulni, időt tölt ikertestvérével és gitározik.
Madhur Prashant az AWS generatív AI-terében dolgozik. Szenvedélyesen rajong az emberi gondolkodás és a generatív mesterséges intelligencia találkozási pontjaiért. Érdeklődése a generatív mesterséges intelligencia, különösen az olyan megoldások készítése, amelyek hasznosak és ártalmatlanok, és leginkább az ügyfelek számára optimálisak. A munkán kívül szeret jógázni, kirándulni, időt tölt ikertestvérével és gitározik.
 Dewan Choudhury az Amazon Web Services szoftverfejlesztő mérnöke. Az Amazon SageMaker algoritmusain és a JumpStart ajánlatain dolgozik. Az AI/ML infrastruktúrák építése mellett szenvedélyesen fejleszti a méretezhető elosztott rendszereket is.
Dewan Choudhury az Amazon Web Services szoftverfejlesztő mérnöke. Az Amazon SageMaker algoritmusain és a JumpStart ajánlatain dolgozik. Az AI/ML infrastruktúrák építése mellett szenvedélyesen fejleszti a méretezhető elosztott rendszereket is.
 Hao Zhou az Amazon SageMaker kutatója. Ezt megelőzően gépi tanulási módszerek fejlesztésén dolgozott az Amazon Fraud Detector csalásfelderítésére. Szenvedélye a gépi tanulás, az optimalizálás és a generatív AI technikák alkalmazása különféle valós problémákra. A Northwestern Egyetemen szerzett villamosmérnöki PhD fokozatot.
Hao Zhou az Amazon SageMaker kutatója. Ezt megelőzően gépi tanulási módszerek fejlesztésén dolgozott az Amazon Fraud Detector csalásfelderítésére. Szenvedélye a gépi tanulás, az optimalizálás és a generatív AI technikák alkalmazása különféle valós problémákra. A Northwestern Egyetemen szerzett villamosmérnöki PhD fokozatot.
 Qing Lan az AWS szoftverfejlesztő mérnöke. Számos kihívást jelentő terméken dolgozott az Amazonban, beleértve a nagy teljesítményű ML következtetési megoldásokat és a nagy teljesítményű naplózási rendszert. Qing csapata sikeresen elindította az Amazon Advertising első milliárdos paraméterű modelljét, nagyon alacsony késleltetéssel. Qing mélyreható ismeretekkel rendelkezik az infrastruktúra optimalizálásával és a Deep Learning gyorsításával kapcsolatban.
Qing Lan az AWS szoftverfejlesztő mérnöke. Számos kihívást jelentő terméken dolgozott az Amazonban, beleértve a nagy teljesítményű ML következtetési megoldásokat és a nagy teljesítményű naplózási rendszert. Qing csapata sikeresen elindította az Amazon Advertising első milliárdos paraméterű modelljét, nagyon alacsony késleltetéssel. Qing mélyreható ismeretekkel rendelkezik az infrastruktúra optimalizálásával és a Deep Learning gyorsításával kapcsolatban.
 Dr. Ashish Khetan vezető alkalmazott tudós az Amazon SageMaker beépített algoritmusaival, és segít gépi tanulási algoritmusok fejlesztésében. PhD fokozatát az Illinois Urbana-Champaign Egyetemen szerezte. A gépi tanulás és a statisztikai következtetések aktív kutatója, és számos közleményt publikált NeurIPS, ICML, ICLR, JMLR, ACL és EMNLP konferenciákon.
Dr. Ashish Khetan vezető alkalmazott tudós az Amazon SageMaker beépített algoritmusaival, és segít gépi tanulási algoritmusok fejlesztésében. PhD fokozatát az Illinois Urbana-Champaign Egyetemen szerezte. A gépi tanulás és a statisztikai következtetések aktív kutatója, és számos közleményt publikált NeurIPS, ICML, ICLR, JMLR, ACL és EMNLP konferenciákon.
 Dr. Li Zhang az Amazon SageMaker JumpStart és az Amazon SageMaker beépített algoritmusainak fő termékmenedzsere, egy olyan szolgáltatás, amely segíti az adattudósokat és a gépi tanulással foglalkozó szakembereket a modellek betanításában és bevezetésében, valamint megerősítő tanulást használ az Amazon SageMakerrel. Az IBM Research fő kutatójaként és mesterfeltalálóként végzett korábbi munkája elnyerte az IEEE INFOCOM-nál az időpróba papír díjat.
Dr. Li Zhang az Amazon SageMaker JumpStart és az Amazon SageMaker beépített algoritmusainak fő termékmenedzsere, egy olyan szolgáltatás, amely segíti az adattudósokat és a gépi tanulással foglalkozó szakembereket a modellek betanításában és bevezetésében, valamint megerősítő tanulást használ az Amazon SageMakerrel. Az IBM Research fő kutatójaként és mesterfeltalálóként végzett korábbi munkája elnyerte az IEEE INFOCOM-nál az időpróba papír díjat.
 Kamran kán, Sr műszaki üzletfejlesztési menedzser az AWS Inferentina/Trianiumnál, az AWS-nél. Több mint egy évtizedes tapasztalattal rendelkezik abban, hogy az AWS Inferentia és az AWS Trainium használatával segítse ügyfeleit a mély tanulási tréningek telepítésében és optimalizálása, valamint a következtetési munkaterhelésben.
Kamran kán, Sr műszaki üzletfejlesztési menedzser az AWS Inferentina/Trianiumnál, az AWS-nél. Több mint egy évtizedes tapasztalattal rendelkezik abban, hogy az AWS Inferentia és az AWS Trainium használatával segítse ügyfeleit a mély tanulási tréningek telepítésében és optimalizálása, valamint a következtetési munkaterhelésben.
 Joe Senerchia az AWS vezető termékmenedzsere. Amazon EC2-példányokat határoz meg és készít a mély tanuláshoz, a mesterséges intelligenciához és a nagy teljesítményű számítási feladatokhoz.
Joe Senerchia az AWS vezető termékmenedzsere. Amazon EC2-példányokat határoz meg és készít a mély tanuláshoz, a mesterséges intelligenciához és a nagy teljesítményű számítási feladatokhoz.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :van
- :is
- :nem
- :ahol
- $ UP
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- képesség
- Képes
- Rólunk
- gyorsulás
- Elfogad!
- elfogadható
- elfogadott
- hozzáférés
- pontosság
- pontos
- elismerni
- ACM
- aktív
- tevékenységek
- Ádám
- alkalmazkodni
- alkalmazkodás
- igazítani
- hozzá
- mellett
- felnőttek
- fejlett
- haladás
- Hirdetés
- Után
- Megállapodás
- AI
- AI modellek
- AI / ML
- algoritmusok
- Minden termék
- lehetővé
- megengedett
- lehetővé teszi, hogy
- Is
- amazon
- Amazon EC2
- Amazon csalásészlelő
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Az Amazon Web Services
- között
- an
- elemzés
- Ősi
- és a
- állatok
- bejelent
- Másik
- bármilyen
- Már
- Apache
- külön
- alkalmazható
- Alkalmazás
- alkalmazások
- alkalmazott
- Alkalmazása
- megfelelő
- körülbelül
- építészet
- VANNAK
- TERÜLET
- területek
- érv
- Hadsereg
- megérkezett
- Művészet
- mesterséges
- mesterséges intelligencia
- AS
- segítő
- Egyesület
- At
- Kisérők
- attribútumok
- Hatóság
- szerzők
- Automatizált
- elérhetőség
- elérhető
- elkerülése érdekében
- AWS
- AWS Inferentia
- b
- alapján
- BE
- Gerenda
- mert
- válik
- óta
- előtt
- hogy
- Hisz
- lent
- között
- Túl
- Legnagyobb
- biológia
- Blog
- született
- mindkét
- Doboz
- széles
- épít
- Épület
- épít
- beépített
- üzleti
- üzlet fejlesztés
- de
- gomb
- gombok
- by
- hívás
- jött
- TUD
- képességek
- tőke
- kártya
- végrehajtott
- eset
- esetek
- kategóriák
- Kategória
- kihívások
- kihívást
- változik
- Káosz
- csevegés
- fő
- választás
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- választja
- Christopher
- Város
- civil
- világosság
- osztályok
- klasszikus
- besorolás
- ragadozó ölyv
- felhő
- csoportosítás
- kód
- hideg
- bizottság
- Közös
- Közösségek
- közösség
- vállalat
- képest
- összehasonlítva
- összehasonlítások
- Befejezett
- Befejezi
- számítási
- számítástechnika
- következtetés
- egyidejű
- Magatartás
- Konferencia
- konferenciák
- Configuration
- megerősít
- Konzol
- tartalmaz
- Konténer
- tartalmaz
- tartalom
- kontextus
- kontextusok
- hozzájárulások
- ellenőrzés
- ellenőrzések
- Költség
- drága
- kiadások
- ország
- készítette
- Korona
- kritikus
- kulturális
- Csésze
- vevő
- Vásárlói élmény
- Ügyfelek
- testreszabás
- dátum
- adatkészletek
- találka
- de
- évtized
- december
- Dekódolás
- elszánt
- mély
- mély tanulás
- mélyen
- alapértelmezett
- Annak meghatározása,
- Fok
- szállít
- demokratikus
- bizonyítani
- igazolták
- mutatja
- attól
- függ
- telepíteni
- telepített
- bevezetéséhez
- bevetés
- körülír
- leírás
- kijelölt
- tervezett
- részletes
- részletek
- Érzékelés
- Fejleszt
- fejlesztése
- Fejlesztés
- Párbeszéd
- DID
- különbség
- különböző
- felfedez
- felfedezés
- megvitatni
- kijelző
- megosztott
- elosztott rendszerek
- számos
- nem
- Ennek
- Dolly
- domain
- domainek
- ne
- le-
- minden
- Korai
- bevételt hozó
- könnyű
- egyszerű használat
- szerkesztő
- Hatékony
- hatékonyság
- hatékony
- bármelyik
- megválasztott
- villamosmérnök
- Empire
- engedélyezve
- lehetővé teszi
- lehetővé téve
- végén
- végtől végig
- Endpoint
- mérnök
- Mérnöki
- növelése
- fokozása
- elég
- biztosítja
- Vállalkozás
- Vállalati megoldások
- Környezet
- környezeti
- egyenlő
- Egyenlő
- különösen
- Eter (ETH)
- értékelni
- értékelés
- nyilvánvaló
- példa
- példák
- izgatott
- kizárás
- létező
- tapasztalat
- tapasztalt
- kísérleti
- feltárása
- Feltárása
- kitermelés
- Esik
- hamis
- gyorsabb
- fickó
- fesztiválok
- kevés
- Fields
- filé
- Fájlok
- Benyújtás
- pénzügyi
- pénzügyi szolgáltatások
- Találjon
- végén
- vezetéknév
- Rugalmasság
- Úszó
- Összpontosít
- koncentrál
- következő
- következik
- A
- Kényszer
- formátum
- talált
- Alapítvány
- Alapított
- Keretrendszer
- keretek
- csalás
- csalások felderítése
- ból ből
- funkció
- további
- generált
- generál
- generáció
- nemző
- Generatív AI
- kap
- Go
- Jó
- jó
- kapott
- diplomás
- grafikon
- grafikonok
- nagyobb
- Görögország
- Kapzsi
- görög
- Csoport
- útmutatást
- gitár
- kellett
- Kezelés
- kezek
- boldog
- Legyen
- he
- egészségügyi
- hős
- segít
- hasznos
- segít
- segít
- Magas
- nagy teljesítményű
- <p></p>
- legnagyobb
- kiemeli
- turisztika
- őt
- övé
- tart
- Hogyan
- How To
- azonban
- HTML
- http
- HTTPS
- emberi
- i
- IBM
- ICLR
- azonosítani
- ids
- IEEE
- if
- ii
- Illinois
- végrehajtás
- importál
- fontos
- javul
- javított
- javulás
- fejlesztések
- in
- mélyreható
- tartalmaz
- magában foglalja a
- Beleértve
- Növelje
- jelzi
- információ
- információ kinyerése
- Infrastruktúra
- infrastruktúrák
- bemenet
- bemenet
- példa
- példányok
- utasítás
- integrált
- Intelligencia
- érdekek
- Felület
- Nemzetközi
- útkereszteződés
- bele
- részt
- IT
- ITS
- james
- Munka
- Állások
- csatlakozott
- Jonatán
- folyóirat
- utazás
- jpg
- json
- éppen
- Kulcs
- Királyság
- készlet
- Kit (SDK)
- tudás
- ismert
- leszállási
- a nyitóoldal
- nyelv
- nagy
- nagyarányú
- Késleltetés
- a későbbiekben
- indított
- törvények
- vezető
- tanulás
- Hossz
- li
- Engedély
- engedélyek
- fekszik
- élet
- mint
- valószínűség
- Valószínű
- korlátozás
- vonal
- vonalak
- LINK
- Lista
- Listázott
- Láma
- kiszámításának
- helyi
- fakitermelés
- Hosszú
- néz
- szeret
- Elő/Utó
- alacsonyabb
- leeresztés
- legalacsonyabb
- gép
- gépi tanulás
- készült
- Fő
- csinál
- Gyártás
- menedzser
- kezelése
- Manan Shah
- sok
- mester
- maximális
- Lehet..
- jelenti
- Találkozik
- tag
- meta
- módszer
- mód
- Mexikó
- esetleg
- mikrofon
- bánja
- ML
- modell
- modellezés
- modellek
- módosított
- módosítása
- több
- a legtöbb
- áthelyezve
- zene
- kell
- név
- Természetes
- Természetes nyelv
- Természetes nyelvi feldolgozás
- Keresse
- Navigáció
- Szükség
- igények
- NeurIPS
- Új
- következő
- NLP
- Northwestern University
- jegyzetfüzet
- laptopok
- Most
- szám
- számok
- tárgy
- célok
- of
- ajánlat
- felajánlás
- Ajánlat
- Ajánlatok
- gyakran
- Régi
- idősebb
- on
- egyszer
- ONE
- csak
- optimálisan
- optimalizálás
- Optimalizálja
- optimalizált
- optimalizálása
- opció
- or
- szervezet
- Más
- teljesítmény
- kívül
- kiemelkedő
- felett
- saját
- csomagok
- oldal
- pár
- párosított
- üvegtábla
- Papír
- papírok
- Párhuzamos
- paraméterek
- rész
- különösen
- fél
- átjáró
- szenvedélyes
- múlt
- mert
- teljesít
- teljesítmény
- időszak
- Személyre
- phd
- csővezeték
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- játék
- kérem
- pont
- Politikák
- politika
- politikai
- pop-up
- Népszerű
- pozitív
- lehetőségek
- lehetséges
- állás
- erős
- megelőző
- Pontosság
- előkészítése
- elsődleges
- Fő
- valószínűség
- problémák
- folyamat
- feldolgozás
- Termékek
- termék menedzser
- Termékek
- szabadalmazott
- ad
- szolgáltatók
- biztosít
- nyilvánosan
- közzétett
- tesz
- Piton
- pytorch
- világítás
- kérdés
- véletlenszerűség
- el
- Elér
- Olvass
- kész
- igazi
- való Világ
- real-time
- ok
- miatt
- nyilvántartások
- utal
- referenciái
- menekültek
- felszabaduló
- relevancia
- Áthelyezve
- maradt
- maradványok
- megismételt
- ismétlő
- cserélni
- raktár
- képvisel
- képviselő
- kérni
- kéri
- kötelező
- kutatás
- kutató
- Tudástár
- illetőleg
- válasz
- válaszok
- felelős
- kapott
- Eredmények
- visszatérés
- Kritika
- felülvizsgálata
- erős
- Gördülő
- királyi
- futás
- Oroszország
- sagemaker
- skálázhatóság
- skálázható
- Skála
- forgatókönyvek
- Tudós
- tudósok
- szkriptek
- sdk
- Keresés
- keres
- SEC
- SEC bejelentés
- Második
- Rész
- biztonság
- lát
- idősebb
- küldött
- mondat
- érzés
- különálló
- Sorozat
- Series of
- A sorozat
- szolgáltatás
- Szolgáltatások
- készlet
- beállítás
- beállítások
- számos
- rövid
- kellene
- előadás
- mutatott
- Műsorok
- jelentős
- Egyszerű
- óta
- egyetlen
- Méret
- töredék
- So
- Társadalom
- szoftver
- szoftverfejlesztés
- szoftverfejlesztői csomag
- szoftverfejlesztés
- megoldások
- Megoldások
- Megoldása
- néhány
- a
- forrás
- Dél
- szovjet
- Hely
- specializált
- különleges
- kifejezetten
- sajátosság
- meghatározott
- Költési
- osztott
- Személyzet
- kezdet
- kezdődött
- Állami
- statisztikai
- Állapot
- kormányzó
- Lépés
- Lépései
- Leállítja
- tárolás
- szerkesztett
- Diákok
- tanult
- tanulmányok
- stúdió
- sikeresen
- ilyen
- támogatás
- Támogatott
- biztos
- svájc
- rendszer
- Systems
- táblázat
- szabott
- Feladat
- feladatok
- Tanítási
- csapat
- Műszaki
- technika
- technikák
- Technológia
- sablon
- tennessee
- feltételek
- teszt
- szöveg
- Szöveg osztályozása
- szöveggenerálás
- mint
- hogy
- A
- A terület
- Főváros
- Színház
- azok
- Őket
- akkor
- Ott.
- Ezek
- ők
- Gondolkodás
- harmadik fél
- ezt
- azok
- Keresztül
- áteresztőképesség
- tigrisek
- idő
- alkalommal
- nak nek
- Ma
- jelképes
- tokenek
- szerszámok
- Végösszeg
- Vonat
- kiképzett
- Képzések
- transzformátor
- Fordítás
- igaz
- megpróbál
- iker
- kettő
- típus
- ui
- alatt
- mögöttes
- egyedi
- Egyetemek
- egyetemi
- -ig
- Frissítések
- Frissítés
- Használat
- használ
- használati eset
- használt
- használó
- Felhasználók
- használ
- segítségével
- hasznosítja
- Üzbegisztán
- érvényesítés
- érték
- fajta
- különféle
- változat
- nagyon
- keresztül
- Megnézem
- szőlőtőke
- vizuális
- séta
- akar
- háború
- volt
- módon
- we
- háló
- webes szolgáltatások
- web-alapú
- ment
- voltak
- amikor
- ami
- míg
- WHO
- lesz
- BOR
- val vel
- Nyerte
- szó
- szavak
- Munka
- dolgozott
- dolgozó
- művek
- műhely
- világ
- lenne
- ír
- év
- Jóga
- te
- A te
- ifjúság
- zephyrnet
- Zeusz