Kép Freepik
A társalgási mesterséges intelligencia olyan virtuális ügynökökre és chatbotokra utal, amelyek utánozzák az emberi interakciókat, és képesek beszélgetésbe bevonni az embereket. A társalgási mesterséges intelligencia használata gyorsan életmóddá válik – Alexa megkérdezésétől a „megtalálni a legközelebbi éttermet” megkérni Sirit, hogy "hozzon létre egy emlékeztetőt" A virtuális asszisztenseket és a chatbotokat gyakran használják a fogyasztók kérdéseinek megválaszolására, panaszok megoldására, foglalásokra és még sok másra.
Ezeknek a virtuális asszisztenseknek a fejlesztése jelentős erőfeszítést igényel. A kulcsfontosságú kihívások megértése és kezelése azonban racionalizálhatja a fejlesztési folyamatot. Első kézből szerzett tapasztalataimat egy kiforrott chatbot létrehozásában használtam fel egy toborzási platformhoz referenciapontként, hogy elmagyarázzam a legfontosabb kihívásokat és a megfelelő megoldásokat.
A társalgási AI chatbot felépítéséhez a fejlesztők olyan keretrendszereket használhatnak, mint a RASA, az Amazon Lex vagy a Google Dialogflow. A legtöbben a RASA-t részesítik előnyben, amikor egyéni változtatásokat terveznek, vagy a bot még kiforrott állapotban van, mivel nyílt forráskódú keretrendszerről van szó. Más keretek is alkalmasak kiindulópontnak.
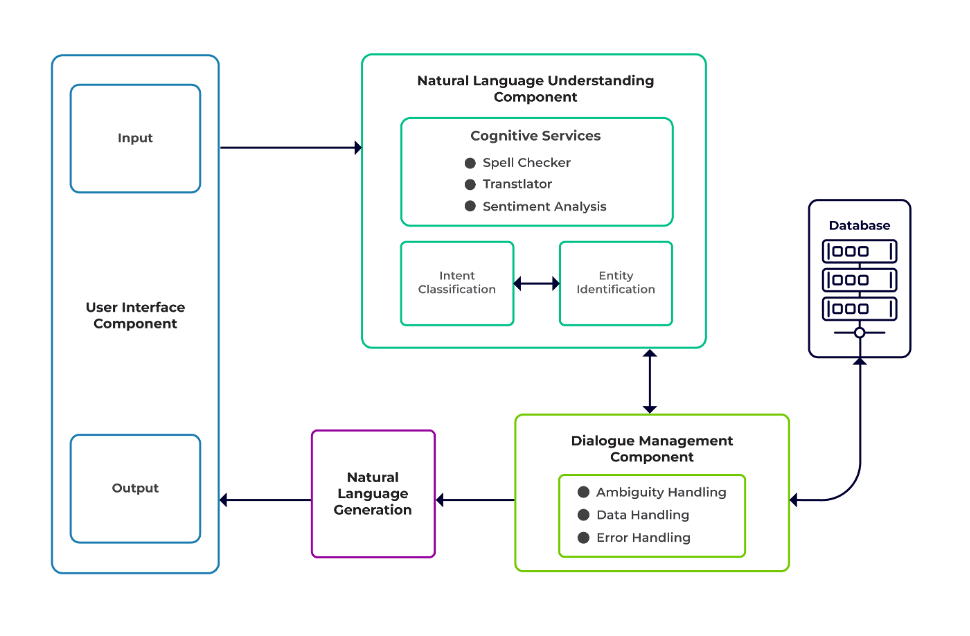
A kihívások a chatbot három fő összetevője közé sorolhatók.
Természetes nyelv megértése (NLU) egy bot azon képessége, hogy megértse az emberi párbeszédet. Szándékosztályozást, entitáskivonást és válaszok lekérését hajtja végre.
Dialógus menedzser felelős az aktuális és korábbi felhasználói bemenetek alapján végrehajtandó műveletekért. A szándékot és az entitásokat bemenetként veszi (az előző beszélgetés részeként), és azonosítja a következő választ.
Természetes nyelvgeneráció (NLG) az a folyamat, amely adott adatokból írott vagy beszélt mondatokat generál. Ez keretezi a választ, amelyet aztán bemutat a felhasználónak.
Kép a Talentica Software-től
Nincs elegendő adat
Amikor a fejlesztők lecserélik a GYIK-et vagy más támogató rendszereket egy chatbotra, megfelelő mennyiségű képzési adatot kapnak. De ugyanez nem történik meg, amikor a semmiből hozzák létre a botot. Ilyen esetekben a fejlesztők szintetikusan állítják elő a képzési adatokat.
Mit kell tenni?
Egy sablon alapú adatgenerátor megfelelő mennyiségű felhasználói lekérdezést generálhat a képzéshez. Amint a chatbot készen áll, a projekttulajdonosok korlátozott számú felhasználó számára elérhetővé tehetik azt, hogy javítsák a képzési adatokat és frissítsék egy bizonyos időszakon keresztül.
Nem megfelelő modellválasztás
A megfelelő modellválasztás és betanítási adatok kulcsfontosságúak a legjobb szándék- és entitáskivonási eredmények eléréséhez. A fejlesztők általában egy adott nyelven és tartományon képezik ki a chatbotokat, és a rendelkezésre álló előre betanított modellek többsége gyakran tartományspecifikus, és egyetlen nyelven van kiképezve.
A vegyes nyelvek esetében is előfordulhatnak olyan esetek, amikor az emberek többnyelvűek. Lehetséges, hogy vegyes nyelven írnak be lekérdezéseket. Például egy francia domináns régióban az emberek olyan típusú angolt használhatnak, amely a francia és az angol keveréke.
Mit kell tenni?
A több nyelven betanított modellek használata csökkentheti a problémát. Ilyen esetekben hasznos lehet egy előre betanított modell, mint például a LaBSE (Language-agnostic Bert mondatbeágyazás). A LaBSE több mint 109 nyelven van kiképezve egy mondathasonlósági feladatra. A modell már ismer hasonló szavakat egy másik nyelven. A mi projektünkben ez nagyon jól működött.
Nem megfelelő entitáskivonás
A chatbotokhoz entitásoknak kell azonosítaniuk, hogy a felhasználó milyen adatokat keres. Ezek az entitások magukban foglalják az időt, a helyet, a személyt, az elemet, a dátumot stb. A robotok azonban nem tudnak természetes nyelvből azonosítani egy entitást:
Ugyanaz a kontextus, de különböző entitások. Például a robotok összekeverhetnek egy helyet mint entitást, amikor a felhasználó beírja: „IIT Delhi diákjai”, majd „Bengaluru diákjainak neve”.
Azok a forgatókönyvek, amelyekben az entitásokat rosszul jósolják meg alacsony megbízhatósággal. Például egy bot alacsony bizalommal tudja azonosítani az IIT Delhit városként.
Részleges entitáskivonás gépi tanulási modellel. Ha a felhasználó azt írja be, hogy „diákok az IIT Delhiből”, a modell csak az „IIT”-t tudja azonosítani entitásként az „IIT Delhi” helyett.
A kontextus nélküli egyszavas bevitelek összetéveszthetik a gépi tanulási modelleket. Például egy olyan szó, mint a „Rishikesh”, egy személy és egy város nevét is jelentheti.
Mit kell tenni?
További képzési példák hozzáadása megoldást jelenthet. De van egy határ, amely után több hozzáadása nem segít. Ráadásul ez egy végtelen folyamat. Egy másik megoldás lehet a regex-minták előre definiált szavakkal történő definiálása, amelyek segítik az entitások kinyerését ismert lehetséges értékkészlettel, például várossal, országgal stb.
A modellek alacsonyabb bizalommal rendelkeznek, ha nem biztosak az entitás előrejelzésében. A fejlesztők ezt triggerként használhatják egy egyéni komponens meghívására, amely képes kijavítani az alacsony magabiztosságú entitást. Tekintsük a fenti példát. Ha IIT Delhi alacsony megbízhatóságú városnak jósolják, akkor a felhasználó mindig rákereshet az adatbázisban. Miután nem sikerült megtalálni a megjósolt entitást a Város táblázatban, a modell továbblépne más táblákra, és végül megtalálja a Intézet táblázat, ami entitáskorrekciót eredményez.
Rossz szándék szerinti besorolás
Minden felhasználói üzenethez valamilyen szándék kapcsolódik. Mivel a szándékok a bot következő műveleteit vezetik le, kulcsfontosságú a felhasználói lekérdezések szándék szerinti helyes osztályozása. A fejlesztőknek azonban a szándékok minimális összetévesztésével kell azonosítaniuk a szándékokat. Ellenkező esetben előfordulhatnak zavart okozó esetek. Például, "Mutasd a nyitott pozíciókat” kontra "Mutasd meg a nyitott pozícióra jelölteket”.
Mit kell tenni?
Kétféleképpen lehet megkülönböztetni a zavaró lekérdezéseket. Először is, a fejlesztő bevezethet al-szándékot. Másodszor, a modellek képesek kezelni a lekérdezéseket az azonosított entitások alapján.
A domain-specifikus chatbotnak zárt rendszernek kell lennie, ahol egyértelműen meg kell határoznia, mire képes és mire nem. A fejlesztőknek a fejlesztést szakaszosan kell elvégezniük, miközben a domain-specifikus chatbotokat tervezik. Mindegyik fázisban azonosítani tudják a chatbot nem támogatott funkcióit (nem támogatott szándékon keresztül).
Azt is meg tudják határozni, hogy a chatbot mit nem tud kezelni „hatókörön kívüli” szándékkal. De előfordulhatnak olyan esetek, amikor a bot összezavarodik a támogatás nélküli és a hatókörön kívüli szándék miatt. Az ilyen forgatókönyvek esetében tartalék mechanizmust kell bevezetni, ahol ha a szándékbizalom egy küszöb alatt van, a modell kecsesen tud működni egy tartalék szándékkal a zavaros esetek kezelésére.
Amint a bot azonosítja a felhasználó üzenetének szándékát, választ kell küldenie. Bot meghatározott szabályok és történetek alapján dönti el a választ. Például egy szabály lehet olyan egyszerű, mint az abszolút "jó reggelt kívánok" amikor a felhasználó köszön "Szia". A chatbotokkal folytatott beszélgetések azonban leggyakrabban nyomon követési interakciót tartalmaznak, és válaszaik a beszélgetés általános kontextusától függenek.
Mit kell tenni?
Ennek kezelésére a chatbotokat valódi beszélgetési példákkal táplálják, amelyeket történeteknek neveznek. A felhasználók azonban nem mindig a szándéknak megfelelően lépnek kapcsolatba. Egy érett chatbotnak minden ilyen eltérést kecsesen kell kezelnie. A tervezők és fejlesztők ezt garantálhatják, ha nem csak a boldog útra koncentrálnak történetírás közben, hanem boldogtalan utakon is dolgoznak.
A chatbotokkal való felhasználói elköteleződés nagymértékben függ a chatbot válaszaitól. A felhasználók elveszíthetik érdeklődésüket, ha a válaszok túlságosan robotikusak vagy túl ismerősek. Előfordulhat például, hogy a felhasználónak nem tetszenek a rossz bemenetre adott válaszok, mint például: „Rossz lekérdezést írt be”, még akkor is, ha a válasz helyes. A válasz itt nem egyezik az asszisztens személyével.
Mit kell tenni?
A chatbot asszisztensként szolgál, és meghatározott személyiséggel és hangszínnel kell rendelkeznie. Üdvözlőnek és alázatosnak kell lenniük, a fejlesztőknek pedig ennek megfelelően kell kialakítaniuk a beszélgetéseket és a megnyilatkozásokat. A válaszok nem hangzanak robotszerűen vagy mechanikusan. Például a bot azt mondhatja:Sajnálom, de úgy tűnik, nincs információm. Meg tudnád kérni újra a kérdést?" hibás bevitel kezelésére.
Az LLM (Large Language Model) alapú chatbotok, mint például a ChatGPT és a Bard, a játékot megváltoztató újítások, és javították a társalgási AI-k képességeit. Nemcsak nyílt végű, emberszerű beszélgetések lebonyolításában jók, hanem különféle feladatokat is el tudnak látni, mint például szövegösszegzés, bekezdésírás stb., amelyeket korábban csak meghatározott modellekkel lehetett megvalósítani.
A hagyományos chatbot-rendszerekkel szemben támasztott egyik kihívás az egyes mondatok szándékok szerinti kategorizálása, és ennek megfelelő válaszadás. Ez a megközelítés nem praktikus. Az olyan válaszok, mint a „Sajnálom, nem tudtam elérni” gyakran irritálóak. A szándék nélküli chatbot-rendszerek jelentik az előremutató utat, és az LLM-ek ezt valóra válthatják.
Az LLM-ek könnyen elérhetik a legkorszerűbb eredményeket az általános elnevezésű entitásfelismerésben, bizonyos tartomány-specifikus entitásfelismerés tiltásával. Az LLM-ek bármely chatbot keretrendszerrel való használatának vegyes megközelítése érettebb és robusztusabb chatbot-rendszert inspirálhat.
A társalgási mesterséges intelligencia legújabb fejlesztéseinek és folyamatos kutatásának köszönhetően a chatbotok minden nap egyre jobbak. Nagy figyelmet kapnak az olyan területek, mint a többcélú összetett feladatok kezelése, mint például: „Foglaljon repülőjegyet Mumbaiba, és gondoskodjon taxiról Dadarba”.
Hamarosan személyre szabott beszélgetésekre kerül sor a felhasználó jellemzői alapján, hogy fenntartsák a felhasználó elkötelezettségét. Például, ha egy bot úgy találja, hogy a felhasználó elégedetlen, átirányítja a beszélgetést egy valódi ügynökhöz. Ezenkívül az egyre növekvő chatbot-adatokkal az olyan mély tanulási technikák, mint a ChatGPT, automatikusan generálhatnak válaszokat a lekérdezésekre egy tudásbázis segítségével.
Suman Saurav adatkutató a Talentica Software szoftvertermékfejlesztő cégnél. A NIT Agartala öregdiákja, több mint 8 éves tapasztalattal az NLP, a Conversational AI és a Generative AI segítségével forradalmi AI megoldások tervezésében és megvalósításában.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :van
- :is
- :nem
- :ahol
- 8
- a
- képesség
- Rólunk
- felett
- Eszerint
- Elérése
- elért
- át
- cselekvések
- hozzáadásával
- Ezen kívül
- cím
- címzés
- fejlesztések
- Után
- Ügynök
- szerek
- AI
- AI chatbot
- Alexa
- Minden termék
- már
- Is
- volt diák
- mindig
- összeg
- an
- és a
- Másik
- válasz
- bármilyen
- megközelítés
- VANNAK
- területek
- AS
- kér
- Helyettes
- asszisztensek
- társult
- At
- figyelem
- automatikusan
- elérhető
- elkerülése érdekében
- vissza
- bázis
- alapján
- BE
- egyre
- lények
- lent
- BEST
- Jobb
- Bot
- mindkét
- botok
- épít
- de
- by
- hívás
- hívott
- TUD
- nem tud
- képességek
- képes
- esetek
- kategorizálása
- bizonyos
- kihívások
- Változások
- jellemzők
- chatbot
- chatbots
- ChatGPT
- Város
- besorolás
- osztályozott
- világosan
- zárt
- vállalat
- panaszok
- bonyolult
- összetevő
- alkatrészek
- megért
- bizalom
- zavaros
- zavaró
- zavar
- Fontolja
- kontextus
- folyamatos
- Beszélgetés
- társalgó
- társalgási AI
- beszélgetések
- kijavítására
- helyesen
- Megfelelő
- tudott
- ország
- tanfolyam
- teremt
- létrehozása
- kritikus
- Jelenlegi
- szokás
- dátum
- adattudós
- adatbázis
- találka
- nap
- megfelelő
- Döntés
- mély
- mély tanulás
- meghatározott
- meghatározott
- Delhi
- függ
- származik
- Design
- tervezők
- tervezés
- részletek
- Fejlesztő
- fejlesztők
- Fejlesztés
- párbeszédablak
- Párbeszéd
- különböző
- különbséget
- do
- Nem
- domain
- ne
- minden
- Korábban
- könnyen
- erőfeszítés
- beágyazás
- Végtelen
- vegyenek
- elkötelezett
- eljegyzés
- Angol
- növelése
- belép
- Szervezetek
- egység
- stb.
- Még
- végül is
- egyre növekvő
- Minden
- minden nap
- példa
- példák
- tapasztalat
- Magyarázza
- kivonat
- kitermelés
- FAIL
- hiányában
- ismerős
- GYORS
- Jellemzők
- Fed
- Találjon
- leletek
- repülés
- Összpontosít
- A
- Előre
- Keretrendszer
- keretek
- francia
- ból ből
- általános
- generál
- generáló
- generáció
- nemző
- Generatív AI
- generátor
- kap
- szerzés
- adott
- jó
- garancia
- fogantyú
- Kezelés
- történik
- boldog
- Legyen
- tekintettel
- he
- súlyosan
- segít
- hasznos
- itt
- Hogyan
- How To
- azonban
- HTTPS
- emberi
- szerény
- i
- azonosított
- azonosítja
- azonosítani
- if
- végrehajtási
- javított
- in
- tartalmaz
- újítások
- bemenet
- bemenet
- inspirál
- példa
- helyette
- szándékolt
- A szándék
- kölcsönhatásba
- kölcsönhatás
- kölcsönhatások
- kamat
- bele
- bevezet
- IT
- jpg
- éppen
- KDnuggets
- Tart
- Kulcs
- Kedves
- tudás
- ismert
- tudja
- nyelv
- Nyelvek
- nagy
- legutolsó
- tanulás
- élet
- mint
- LIMIT
- Korlátozott
- veszít
- Elő/Utó
- alacsonyabb
- gép
- gépi tanulás
- fontos
- csinál
- Gyártás
- Mérkőzés
- érett
- Lehet..
- me
- jelent
- mechanikai
- mechanizmus
- üzenet
- esetleg
- minimális
- keverje
- vegyes
- modell
- modellek
- több
- Ráadásul
- a legtöbb
- sok
- többszörös
- Mumbai
- kell
- my
- név
- Nevezett
- Természetes
- Természetes nyelv
- következő
- NLG
- NLP
- nlu
- nem
- szám
- of
- gyakran
- on
- egyszer
- csak
- nyitva
- nyílt forráskódú
- or
- Más
- másképp
- mi
- felett
- átfogó
- tulajdonosok
- rész
- ösvény
- utak
- minták
- Emberek (People)
- teljesít
- teljesített
- Előadja
- időszak
- person
- Személyre
- fázis
- fázisok
- Hely
- terv
- tervezés
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- kérem
- pont
- pozíció
- birtokol
- lehetséges
- Gyakorlati
- jósolt
- előrejelzés
- jobban szeret
- bemutatott
- előző
- Probléma
- folytassa
- folyamat
- Termékek
- termékfejlesztés
- program
- lekérdezések
- Kérdések
- R
- rasa
- kész
- igazi
- Valóság
- tényleg
- elismerés
- toborzás
- csökkenteni
- referencia
- kifejezés
- vidék
- támaszkodnak
- emlékeztető
- cserélni
- szükség
- megköveteli,
- kutatás
- megoldása
- válasz
- válaszok
- felelős
- kapott
- Eredmények
- forradalmi
- erős
- Szabály
- szabályok
- azonos
- azt mondják
- forgatókönyvek
- Tudós
- kaparni
- Keresés
- keres
- Úgy tűnik,
- kiválasztás
- küld
- mondat
- szolgálja
- készlet
- Megosztás
- kellene
- hasonló
- Egyszerű
- óta
- egyetlen
- Siri
- szoftver
- megoldások
- Megoldások
- néhány
- hang
- különleges
- beszélt
- Színpad
- Kezdve
- csúcs-
- TÖRTÉNETEK
- áramvonal
- Diákok
- lényeges
- ilyen
- megfelelő
- támogatás
- Támogató rendszerek
- biztos
- szintetikusan
- rendszer
- Systems
- T
- táblázat
- Vesz
- tart
- Feladat
- feladatok
- technikák
- szöveg
- mint
- hogy
- A
- azok
- Őket
- akkor
- Ott.
- Ezek
- ők
- ezt
- bár?
- három
- küszöb
- idő
- nak nek
- TONE
- Hangnem
- is
- hagyományos
- Vonat
- kiképzett
- Képzések
- kiváltó
- kettő
- típus
- típusok
- megértés
- frissítés
- használ
- használt
- használó
- Felhasználók
- segítségével
- rendszerint
- Értékek
- keresztül
- Tényleges
- Hang
- vs
- W
- Út..
- módon
- barátságos
- JÓL
- Mit
- amikor
- bármikor
- ami
- míg
- lesz
- val vel
- szó
- szavak
- Munka
- dolgozott
- lenne
- írás
- írott
- Rossz
- év
- te
- A te
- zephyrnet