तो आपने सभी ट्यूटोरियल देख लिए हैं। अब आप समझ गए हैं कि तंत्रिका नेटवर्क कैसे काम करता है। आपने एक बिल्ली और कुत्ते का वर्गीकरणकर्ता बनाया है। आपने आधे-सभ्य चरित्र-स्तर आरएनएन पर अपना हाथ आजमाया। तुम सिर्फ एक हो pip install tensorflow टर्मिनेटर के निर्माण से दूर, है ना? गलत।

गहन शिक्षण का एक बहुत ही महत्वपूर्ण हिस्सा सही हाइपरपैरामीटर ढूंढना है। ये वे संख्याएँ हैं जो मॉडल नही सकता सीखते हैं।
इस लेख में, मैं आपको कुछ सबसे सामान्य (और महत्वपूर्ण) हाइपरपैरामीटरों के बारे में बताऊंगा जिनका सामना आप कागल लीडरबोर्ड पर #1 स्थान तक पहुंचने की राह में करेंगे। इसके अलावा, मैं आपको कुछ शक्तिशाली एल्गोरिदम भी दिखाऊंगा जो आपके हाइपरपैरामीटर को बुद्धिमानी से चुनने में आपकी मदद कर सकते हैं।
डीप लर्निंग में हाइपरपैरामीटर
हाइपरपैरामीटर को आपके मॉडल के ट्यूनिंग नॉब के रूप में सोचा जा सकता है।
यदि आप अपने एवी रिसीवर को स्टीरियो पर सेट करते हैं तो सबवूफर के साथ एक फैंसी 7.1 डॉल्बी एटमॉस होम थिएटर सिस्टम जो मानव कान की श्रव्य सीमा से परे बास उत्पन्न करता है, बेकार है।

इसी प्रकार, यदि आपके हाइपरपैरामीटर बंद हैं तो एक ट्रिलियन पैरामीटर वाला इंसेप्शन_v3 आपको एमएनआईएसटी से आगे भी नहीं ले जाएगा।
तो अब, आइए सही सेटिंग्स में डायल करने से पहले ट्यून करने के लिए नॉब्स पर एक नज़र डालें।
सीखने की दर
संभवतः सबसे महत्वपूर्ण हाइपरपैरामीटर, सीखने की दर, मोटे तौर पर कहें तो, यह नियंत्रित करती है कि आपका तंत्रिका जाल कितनी तेजी से "सीखता है"।
तो क्यों न हम इसे बढ़ाएं और तेजी से जीवन जिएं?

इतना आसान नहीं है. याद रखें, गहन शिक्षा में हमारा लक्ष्य है हानि फ़ंक्शन को न्यूनतम करें. यदि सीखने की दर बहुत अधिक है, तो हमारा नुकसान हर जगह बढ़ना शुरू हो जाएगा और कभी भी एक साथ नहीं आएगा।

और यदि सीखने की दर बहुत छोटी है, तो मॉडल को अभिसरण होने में बहुत लंबा समय लगेगा, जैसा कि ऊपर दिखाया गया है।
गति
चूँकि यह लेख हाइपरपैरामीटर ऑप्टिमाइज़ेशन पर केंद्रित है, इसलिए मैं इसकी पूरी अवधारणा की व्याख्या नहीं करने जा रहा हूँ गति. लेकिन संक्षेप में, संवेग स्थिरांक को एक गेंद के द्रव्यमान के रूप में सोचा जा सकता है जो हानि फ़ंक्शन की सतह पर लुढ़क रहा है।
गेंद जितनी भारी होगी, वह उतनी ही तेजी से गिरेगी। लेकिन अगर यह बहुत भारी है, तो यह फंस सकता है या लक्ष्य से आगे निकल सकता है।

ड्रॉप आउट
यदि आप यहां किसी विषय को समझ रहे हैं, तो मैं अब आपको निर्देशित करने जा रहा हूं अमर बुद्धिराजाड्रॉपआउट पर लेख.

लेकिन एक त्वरित पुनश्चर्या के रूप में, ड्रॉपआउट ज्योफ हिंटन द्वारा प्रस्तावित एक नियमितीकरण तकनीक है जो तंत्रिका नेटवर्क में सक्रियता को (पी) की संभावना के साथ 0 पर यादृच्छिक रूप से सेट करती है। यह तंत्रिका जाल को सीखने के बजाय डेटा को ओवरफिट करने (याद रखने) से रोकने में मदद करता है।
(पी) एक हाइपरपैरामीटर है।
वास्तुकला - परतों की संख्या, प्रति परत न्यूरॉन्स, आदि।
एक और (काफी हालिया) विचार तंत्रिका नेटवर्क की वास्तुकला को स्वयं एक हाइपरपैरामीटर बनाना है।
हालाँकि हम आम तौर पर मशीनों को अपने मॉडलों की वास्तुकला का पता नहीं लगाते हैं (अन्यथा एआई शोधकर्ता अपनी नौकरी खो देंगे), कुछ नई तकनीकें जैसे तंत्रिका वास्तुकला खोज इस विचार को अलग-अलग सफलता की डिग्री के साथ लागू किया गया है।
यदि आपने . के बारे में सुना है ऑटो एम.एम.एल., मूल रूप से Google यह कैसे करता है: हर चीज़ को एक हाइपरपैरामीटर बनाएं और फिर समस्या पर एक अरब टीपीयू फेंकें और इसे स्वयं हल करने दें.
लेकिन हममें से अधिकांश लोग जो ब्लैक फ्राइडे की बिक्री के बाद बजट मशीन के साथ बिल्लियों और कुत्तों को वर्गीकृत करना चाहते हैं, अब समय आ गया है कि हम यह पता लगाएं कि उन गहन शिक्षण मॉडलों को वास्तव में कैसे काम करना है।
हाइपरपैरामीटर अनुकूलन एल्गोरिदम
ग्रिड खोज
अच्छे हाइपरपैरामीटर प्राप्त करने का यह सबसे सरल संभव तरीका है। यह वस्तुतः केवल पाशविक बल है।
एल्गोरिथम: हाइपरपैरामीटर के दिए गए सेट से हाइपरपैरामीटर का एक समूह आज़माएं और देखें कि क्या सबसे अच्छा काम करता है।
गुण: पांचवीं कक्षा के विद्यार्थी के लिए इसे लागू करना काफी आसान है। आसानी से समानांतर किया जा सकता है.
विपक्ष: जैसा कि आपने शायद अनुमान लगाया है, यह कम्प्यूटेशनल रूप से बेहद महंगा है (जैसा कि सभी क्रूर बल विधियां हैं)।
क्या मुझे इसका उपयोग करना चाहिए: शायद नहीं। ग्रिड खोज अत्यंत अक्षम है. भले ही आप इसे सरल रखना चाहते हों, फिर भी आपके लिए यादृच्छिक खोज का उपयोग करना बेहतर है।
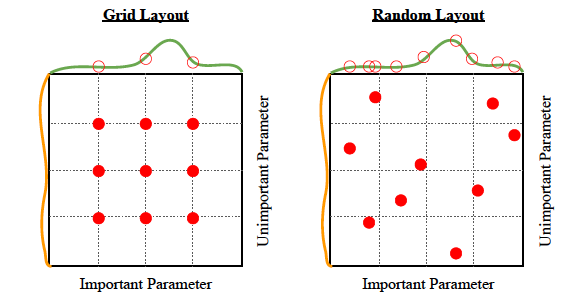
यादृच्छिक खोज
यह सब नाम में है - यादृच्छिक खोज खोजें। बेतरतीब।
एल्गोरिथम: कुछ हाइपरपैरामीटर स्थान पर एक समान वितरण से यादृच्छिक हाइपरपैरामीटर का एक समूह आज़माएं, और देखें कि सबसे अच्छा क्या काम करता है।
गुण: आसानी से समानांतर किया जा सकता है. ग्रिड खोज जितना ही सरल, लेकिन थोड़ा सा बेहतर प्रदर्शन, जैसा कि नीचे दिखाया गया है:

विपक्ष: हालाँकि यह ग्रिड खोज की तुलना में बेहतर प्रदर्शन देता है, फिर भी यह कम्प्यूटेशनल रूप से उतना ही गहन है।
क्या मुझे इसका उपयोग करना चाहिए: यदि तुच्छ समानता और सरलता अत्यंत महत्वपूर्ण है, तो इसे अपनाएँ। लेकिन यदि आप समय और प्रयास बचा सकते हैं, तो बायेसियन ऑप्टिमाइज़ेशन का उपयोग करके आपको बड़ा इनाम मिलेगा।
बायसियन ऑप्टिमाइज़ेशन
अब तक देखी गई अन्य विधियों के विपरीत, बायेसियन अनुकूलन एल्गोरिदम के पिछले पुनरावृत्तियों के ज्ञान का उपयोग करता है। ग्रिड खोज और यादृच्छिक खोज के साथ, प्रत्येक हाइपरपैरामीटर अनुमान स्वतंत्र है। लेकिन बायेसियन तरीकों के साथ, हर बार जब हम अलग-अलग हाइपरपैरामीटर चुनते हैं और आज़माते हैं, तो इंच पूर्णता की ओर बढ़ते हैं।

बायेसियन हाइपरपैरामीटर ट्यूनिंग के पीछे के विचार लंबे और विस्तार से समृद्ध हैं। इसलिए बहुत अधिक खरगोश बिलों से बचने के लिए, मैं आपको यहां सार बताऊंगा। लेकिन अवश्य पढ़ें गाऊसी प्रक्रियाएँ और सामान्य तौर पर बायेसियन अनुकूलन, यदि यह उस प्रकार की चीज़ है जिसमें आपकी रुचि है।
याद रखें, हम इन हाइपरपैरामीटर ट्यूनिंग एल्गोरिदम का उपयोग इसलिए कर रहे हैं क्योंकि वास्तव में व्यक्तिगत रूप से कई हाइपरपैरामीटर विकल्पों का मूल्यांकन करना संभव नहीं है। उदाहरण के लिए, मान लें कि हम मैन्युअल रूप से एक अच्छी सीखने की दर खोजना चाहते थे। इसमें सीखने की दर निर्धारित करना, अपने मॉडल को प्रशिक्षित करना, उसका मूल्यांकन करना, एक अलग सीखने की दर का चयन करना, अपने मॉडल को फिर से शुरू से प्रशिक्षित करना, उसका पुनर्मूल्यांकन करना और यह चक्र जारी रहेगा।
समस्या यह है कि, "अपने मॉडल को प्रशिक्षित करने" को पूरा होने में (समस्या की जटिलता के आधार पर) कई दिन लग सकते हैं। इसलिए आप सम्मेलन के लिए पेपर जमा करने की अंतिम तिथि समाप्त होने तक केवल कुछ सीखने की दरों का प्रयास करने में सक्षम होंगे। और आप क्या जानते हैं, आपने अभी तक गति के साथ खेलना शुरू भी नहीं किया है। उफ़.

एल्गोरिथम: बायेसियन विधियाँ एक फ़ंक्शन (अधिक सटीक रूप से, संभावित फ़ंक्शन पर संभाव्यता वितरण) बनाने का प्रयास करती हैं जो अनुमान लगाती है कि आपका मॉडल कितना अच्छा है हो सकता है हाइपरपैरामीटर की एक निश्चित पसंद के लिए हो। इस अनुमानित फ़ंक्शन (साहित्य में सरोगेट फ़ंक्शन कहा जाता है) का उपयोग करके, आपको सेट, ट्रेन, मूल्यांकन लूप से बहुत अधिक समय तक जाने की ज़रूरत नहीं है, क्योंकि आप हाइपरपैरामीटर को सरोगेट फ़ंक्शन में अनुकूलित कर सकते हैं।
उदाहरण के तौर पर, मान लें कि हम इस फ़ंक्शन को छोटा करना चाहते हैं (इसे अपने मॉडल के हानि फ़ंक्शन के लिए प्रॉक्सी की तरह समझें):

सरोगेट फ़ंक्शन गॉसियन प्रक्रिया नामक चीज़ से आता है (ध्यान दें: सरोगेट फ़ंक्शन को मॉडल करने के अन्य तरीके हैं, लेकिन मैं गॉसियन प्रक्रिया का उपयोग करूंगा)। जैसे, मैंने कहा, मैं कोई गणित की भारी व्युत्पत्ति नहीं करूंगा, लेकिन बायेसियन और गॉसियन के बारे में जो कुछ भी बात हुई है वह यहां दी गई है:
$$ Mathbb{P} (F_n(X)|X_n) = frac{e^{-frac12 F_n^T Sigma_n^{-1} F_n}}{sqrt{(2pi)^n |Sigma_n|}} $$
जो, माना कि एक निवाला है। लेकिन आइए इसे तोड़ने का प्रयास करें।
बाईं ओर आपको बता रहा है कि एक संभाव्यता वितरण शामिल है (फैंसी लुकिंग (mathbb{P} ) की उपस्थिति को देखते हुए)। कोष्ठक के अंदर देखने पर, हम देख सकते हैं कि यह ( F_n(X) ) का संभाव्यता वितरण है, जो कुछ मनमाना फ़ंक्शन है। क्यों? क्योंकि याद रखें, हम सभी संभावित कार्यों पर संभाव्यता वितरण को परिभाषित कर रहे हैं, न कि केवल किसी विशेष फ़ंक्शन पर। संक्षेप में, बाईं ओर का कहना है कि संभावना है कि मॉडल के मेट्रिक्स (जैसे सत्यापन सटीकता, लॉग संभावना, परीक्षण त्रुटि दर इत्यादि) के लिए हाइपरपैरामीटर को मैप करने वाला वास्तविक फ़ंक्शन (F_n(X)) है, कुछ नमूना डेटा दिया गया है (X_n) दायीं ओर जो कुछ भी है उसके बराबर है।
अब जब हमारे पास अनुकूलन करने का कार्य है, तो हम इसे अनुकूलित करते हैं।
अनुकूलन प्रक्रिया शुरू करने से पहले गॉसियन प्रक्रिया इस प्रकार दिखेगी:

अपनी पसंद के पसंदीदा अनुकूलक का उपयोग करें (अपेक्षित सुधार को अधिकतम करने जैसे गुण), लेकिन किसी तरह, बस संकेतों (या ग्रेडिएंट्स) का पालन करें और इससे पहले कि आप इसे जानें, आप अपने स्थानीय न्यूनतम पर पहुंच जाएंगे।
कुछ पुनरावृत्तियों के बाद, गॉसियन प्रक्रिया लक्ष्य फ़ंक्शन का अनुमान लगाने में बेहतर हो जाती है:

भले ही आपने कोई भी तरीका इस्तेमाल किया हो, अब आपको `आर्गमिन` मिल गया है सरोगेट फ़ंक्शन का. उत्तर आश्चर्य, आश्चर्य, वे तर्क जो सरोगेट फ़ंक्शन को कम करते हैं (एक अनुमान) इष्टतम हाइपरपैरामीटर हैं! वाह।
अंतिम परिणाम इस तरह दिखना चाहिए:

अपने तंत्रिका नेटवर्क पर प्रशिक्षण चलाने के लिए इन "इष्टतम" हाइपरपैरामीटर का उपयोग करें, और आपको कुछ सुधार देखना चाहिए। लेकिन आप इस नई जानकारी का उपयोग संपूर्ण बायेसियन अनुकूलन प्रक्रिया को बार-बार दोबारा करने के लिए भी कर सकते हैं। बायेसियन लूप को आप जितनी बार चाहें बेझिझक चलाएँ, लेकिन सावधान रहें। आप वास्तव में सामान की गणना कर रहे हैं। आप जानते हैं, वे AWS क्रेडिट मुफ़्त में नहीं मिलते हैं। या फिर वे...
गुण: बायेसियन अनुकूलन ग्रिड खोज और यादृच्छिक खोज दोनों की तुलना में बेहतर परिणाम देता है।
विपक्ष: इसे समानांतर बनाना उतना आसान नहीं है.
क्या मुझे इसका उपयोग करना चाहिए: अधिकांश मामलों में, हाँ! एकमात्र अपवाद होगा यदि
- आप गहन शिक्षण विशेषज्ञ हैं और आपको मामूली सन्निकटन एल्गोरिदम की सहायता की आवश्यकता नहीं है।
- आपके पास विशाल कम्प्यूटेशनल संसाधनों तक पहुंच है और आप ग्रिड खोज और यादृच्छिक खोज को बड़े पैमाने पर समानांतर कर सकते हैं।
- यदि आप बारंबारवादी/बायेसियन-विरोधी सांख्यिकी विशेषज्ञ हैं।
सीखने की अच्छी दर ढूँढ़ने का एक वैकल्पिक तरीका
अब तक हमने जो भी तरीके देखे हैं, उनमें एक अंतर्निहित विषय है: मशीन लर्निंग इंजीनियर के काम को स्वचालित करना। जो महान् और सर्वस्व है; जब तक आपके बॉस को इसकी जानकारी नहीं मिल जाती और वह आपको 4 आरटीएक्स टाइटन कार्ड से बदलने का फैसला नहीं कर लेता। हुंह. मान लीजिए आपको मैन्युअल खोज पर अड़े रहना चाहिए था।

लेकिन निराश न हों, इस क्षेत्र में सक्रिय अनुसंधान चल रहा है कि शोधकर्ता कम काम करें और साथ ही अधिक भुगतान भी प्राप्त करें। और एक विचार जिसने बहुत अच्छी तरह से काम किया है वह है सीखने की दर सीमा परीक्षण, जो, मेरी जानकारी के अनुसार, पहली बार एक में दिखाई दिया लेस्ली स्मिथ द्वारा पेपर.
पेपर वास्तव में समय के साथ सीखने की दर को शेड्यूल करने (बदलने) की एक विधि के बारे में है। एलआर (सीखने की दर) रेंज परीक्षण एक सोने की डली थी जिसे लेखक ने लापरवाही से किनारे पर गिरा दिया।
जब आप एक सीखने की दर अनुसूची का उपयोग कर रहे हैं जो सीखने की दर को न्यूनतम से अधिकतम मूल्य तक बदलती है, जैसे चक्रीय सीखने की दर or वार्म रीस्टार्ट के साथ स्टोकेस्टिक ग्रेडिएंट डिसेंट, लेखक प्रत्येक पुनरावृत्ति के बाद सीखने की दर को छोटे से बड़े मान तक रैखिक रूप से बढ़ाने का सुझाव देता है (जैसे, 1e-7 सेवा मेरे 1e-1), प्रत्येक पुनरावृत्ति पर हानि का मूल्यांकन करें, और लॉग स्केल पर सीखने की दर के विरुद्ध हानि (या परीक्षण त्रुटि या सटीकता) को प्लॉट करें। आपका प्लॉट कुछ इस तरह दिखना चाहिए:

जैसा कि कथानक पर अंकित है, फिर आप न्यूनतम और अधिकतम सीखने की दर के बीच बाउंस करने के लिए अपने सीखने की दर के शेड्यूल का उपयोग करेंगे, जो कि कथानक को देखकर और सबसे तीव्र ढाल वाले क्षेत्र पर नज़र डालने की कोशिश करके पाया जाता है।
यहां हमारे Colab से एक नमूना LR रेंज परीक्षण प्लॉट (DenseNet CIFAR10 पर प्रशिक्षित) है नोटबुक:

एक सामान्य नियम के रूप में, यदि आप कोई फैंसी सीखने की दर अनुसूची सामग्री नहीं कर रहे हैं, तो बस अपनी निरंतर सीखने की दर को प्लॉट पर न्यूनतम मूल्य से कम परिमाण के क्रम पर सेट करें। इस मामले में यह मोटे तौर पर होगा 1e-2.
इस विधि के बारे में सबसे बढ़िया बात, इसके अलावा यह वास्तव में अच्छी तरह से काम करती है और आपको अन्य एल्गोरिदम के साथ अच्छे हाइपरपैरामीटर खोजने के लिए आवश्यक समय, मानसिक प्रयास और गणना की बचत करती है, यह है कि इसमें वस्तुतः कोई अतिरिक्त गणना लागत नहीं होती है।
जबकि अन्य एल्गोरिदम, अर्थात् ग्रिड खोज, यादृच्छिक खोज, और बायसियन ऑप्टिमाइज़ेशन, आपको एक अच्छे तंत्रिका जाल को प्रशिक्षित करने के अपने लक्ष्य के अनुरूप एक संपूर्ण परियोजना चलाने की आवश्यकता है, एलआर रेंज परीक्षण सिर्फ एक सरल, नियमित प्रशिक्षण लूप निष्पादित कर रहा है, और रास्ते में कुछ चर का ट्रैक रख रहा है।
यहां अभिसरण गति का प्रकार है जिसकी आप इष्टतम सीखने की दर का उपयोग करते समय उम्मीद कर सकते हैं (उदाहरण से)। नोटबुक):

एलआर रेंज परीक्षण को टीम द्वारा कार्यान्वित किया गया है तेजी से, और आपको निश्चित रूप से एलआर रेंज परीक्षण (वे इसे कहते हैं) को लागू करने के लिए उनकी लाइब्रेरी पर एक नज़र डालनी चाहिए सीखने की दर खोजक) साथ ही कई अन्य एल्गोरिदम भी आसानी से।
अधिक परिष्कृत गहन शिक्षण अभ्यासकर्ता के लिए
यदि आप रुचि रखते हैं, तो शुद्ध भाषा में लिखी एक नोटबुक भी है pytorch जो उपरोक्त को लागू करता है। इससे आपको पर्दे के पीछे की प्रशिक्षण प्रक्रिया की बेहतर समझ मिल सकती है। इसकी जांच - पड़ताल करें यहाँ उत्पन्न करें.
अपने आप को बचाने का प्रयास करें

निःसंदेह, ये सभी एल्गोरिदम, चाहे वे कितने भी महान क्यों न हों, व्यवहार में हमेशा काम नहीं करते हैं। तंत्रिका जाल को प्रशिक्षित करते समय विचार करने के लिए कई और कारक हैं, जैसे कि आप अपने डेटा को कैसे प्रीप्रोसेस करेंगे, अपने मॉडल को कैसे परिभाषित करेंगे, और वास्तव में इस काम को चलाने के लिए पर्याप्त शक्तिशाली कंप्यूटर प्राप्त करेंगे।
नैनोनेट्स उपयोग में आसान एपीआई प्रदान करता है कस्टम डीप लर्निंग को प्रशिक्षित करें और तैनात करें मॉडल। यह डेटा संवर्द्धन, ट्रांसफर लर्निंग और हाँ, हाइपरपैरामीटर ऑप्टिमाइज़ेशन सहित सभी भारी भारोत्तोलन का ख्याल रखता है!
नैनोनेट्स नवीनतम ग्राफिक्स कार्ड पर नकदी उड़ाने की चिंता किए बिना हाइपरपैरामीटर का सही सेट खोजने के लिए अपने विशाल जीपीयू क्लस्टर पर बायेसियन खोज का उपयोग करता है और out of bounds for axis 0.
एक बार जब उसे सबसे अच्छा मॉडल मिल जाए, नैनोनेट्स यह आपके वेब इंटरफ़ेस का उपयोग करके मॉडल का परीक्षण करने या कोड की 2 पंक्तियों का उपयोग करके इसे आपके प्रोग्राम में एकीकृत करने के लिए आपके क्लाउड पर सेवा प्रदान करता है।
आदर्श से कम मॉडलों को अलविदा कहें।
निष्कर्ष
इस लेख में, हमने हाइपरपैरामीटर और उन्हें अनुकूलित करने के कुछ तरीकों के बारे में बात की है। लेकिन इस सब क्या मतलब है?
जैसे-जैसे हम एआई तकनीक को लोकतांत्रिक बनाने के लिए कड़ी मेहनत कर रहे हैं, स्वचालित हाइपरपैरामीटर ट्यूनिंग शायद सही दिशा में एक कदम है। यह आपके और मेरे जैसे नियमित लोगों को गणित में पीएचडी के बिना अद्भुत गहन शिक्षण अनुप्रयोग बनाने की अनुमति देता है।
जबकि आप तर्क दे सकते हैं कि कंप्यूटिंग शक्ति के लिए मॉडल को भूखा बनाने से सबसे अच्छे मॉडल उन लोगों के हाथों में रह जाते हैं जो उक्त कंप्यूटिंग शक्ति का खर्च उठा सकते हैं, एडब्ल्यूएस और नैनोनेट्स जैसी क्लाउड सेवाएं शक्तिशाली मशीनों तक पहुंच को लोकतांत्रिक बनाने में मदद करती हैं, जिससे गहन शिक्षा कहीं अधिक सुलभ हो जाती है।
लेकिन अधिक मौलिक रूप से, हम क्या हैं वास्तव में अधिक गणित को हल करने के लिए गणित का उपयोग करके यहां कर रहे हैं। जो न केवल इसलिए दिलचस्प है कि मेटा कैसा लगता है, बल्कि इसलिए भी दिलचस्प है कि कितनी आसानी से इसकी गलत व्याख्या की जा सकती है।

हम निश्चित रूप से पंच कार्ड और ट्रेस टेबल के युग से उस युग तक एक लंबा सफर तय कर चुके हैं जहां हम उन कार्यों को अनुकूलित करते हैं जो कार्यों को अनुकूलित करते हैं जो कार्यों को अनुकूलित करते हैं। लेकिन हम ऐसी मशीनें बनाने के करीब भी नहीं हैं जो स्वयं "सोच" सकें।
और यह हतोत्साहित करने वाला नहीं है, बिल्कुल भी नहीं, क्योंकि यदि मानवता इतने कम में इतना कुछ कर सकती है, तो कल्पना करें कि भविष्य क्या होगा, जब हमारी दृष्टि कुछ ऐसी बन जाएगी जिसे हम वास्तव में देख सकते हैं।
और इसलिए हम एक गद्दीदार जालीदार कुर्सी पर बैठते हैं, एक खाली टर्मिनल स्क्रीन को घूरते हुए, हर कीस्ट्रोक हमें एक संकेत देता है sudo महाशक्ति जो डिस्क को साफ़ कर सकती है।
और इसलिए हम बैठे रहते हैं, हम सारा दिन वहीं बैठे रहते हैं, क्योंकि अगली बड़ी सफलता सिर्फ एक ही हो सकती है pip install दूर।
कोड करने में आलसी? क्या आप कंप्यूटिंग संसाधनों पर खर्च नहीं करना चाहते हैं? वहां जाओ नैनोनेट्स और एक मॉडल बनाना शुरू करें अब!
आपको हमारी नवीनतम पोस्ट में रुचि हो सकती है:
स्रोत: https://nanonets.com/blog/hyperparameter-optimization/
- 7
- 9
- पहुँच
- सक्रिय
- AI
- कलन विधि
- एल्गोरिदम
- सब
- amp
- एपीआई
- अनुप्रयोगों
- स्थापत्य
- तर्क
- लेख
- सुनाई देने योग्य
- स्वचालित
- AV
- एडब्ल्यूएस
- BEST
- बिलियन
- बिट
- काली
- ब्लैक फ्राइडे
- निर्माण
- इमारत
- गुच्छा
- कॉल
- कौन
- मामलों
- रोकड़
- बिल्ली की
- बादल
- क्लाउड सेवाएं
- कोड
- सामान्य
- गणना करना
- कंप्यूटिंग
- संगणन शक्ति
- सम्मेलन
- जारी
- लागत
- क्रेडिट्स
- तिथि
- दिन
- ध्यान लगा के पढ़ना या सीखना
- कुत्ते की
- गिरा
- इंजीनियर
- अनुमान
- आदि
- फास्ट
- आकृति
- पाता
- प्रथम
- फिट
- का पालन करें
- मुक्त
- शुक्रवार
- FS
- समारोह
- भविष्य
- gif
- GitHub
- देते
- सोना
- अच्छा
- गूगल
- GPU
- महान
- ग्रिड
- सिर
- यहाँ उत्पन्न करें
- हाई
- होम
- कैसे
- How To
- HTTPS
- भूखे पेट
- विचार
- इंच
- सहित
- करें-
- शामिल
- IT
- काम
- नौकरियां
- रखना
- ज्ञान
- बड़ा
- ताज़ा
- जानें
- सीख रहा हूँ
- पुस्तकालय
- साहित्य
- स्थानीय
- प्रतीक चिन्ह
- लंबा
- यंत्र अधिगम
- मशीनें
- बहुमत
- निर्माण
- मैप्स
- गणित
- मीडिया
- मध्यम
- मेम
- मेटा
- मेट्रिक्स
- आदर्श
- गति
- यानी
- जाल
- नेटवर्क
- तंत्रिका
- तंत्रिका नेटवर्क
- संख्या
- आदेश
- अन्य
- काग़ज़
- पीडीएफ
- प्रदर्शन
- पोस्ट
- बिजली
- कार्यक्रम
- परियोजना
- प्रतिनिधि
- पंच
- रेंज
- दरें
- RE
- अनुसंधान
- उपयुक्त संसाधन चुनें
- परिणाम
- रन
- बिक्री
- स्केल
- स्क्रीन
- Search
- सेवाएँ
- सेट
- की स्थापना
- कम
- लक्षण
- सरल
- छोटा
- So
- हल
- अंतरिक्ष
- गति
- बिताना
- Spot
- प्रारंभ
- शुरू
- आँकड़े
- सफलता
- सतह
- आश्चर्य
- प्रणाली
- लक्ष्य
- टेक्नोलॉजी
- परीक्षण
- भविष्य
- थिएटर
- विषय
- पहर
- ट्रैक
- प्रशिक्षण
- ट्यूटोरियल
- Unsplash
- us
- उपयोगिता
- मूल्य
- घड़ी
- वेब
- कौन
- हवा
- काम
- कार्य
- X







{kind=link}
{kind=link}
{kind=link}