Tämä on vieraspostaus, jonka ovat kirjoittaneet Taylor Names, Staff Machine Learning Engineer, Dev Gupta, koneoppimispäällikkö, ja Argie Angeleas, vanhempi tuotepäällikkö Ibottasta. Ibotta on yhdysvaltalainen teknologiayritys, jonka avulla käyttäjät voivat työpöytä- ja mobiilisovellustensa avulla ansaita käteistä takaisin myymälässä, mobiilisovelluksissa ja verkkoostoksilla lähettämällä kuitin, linkitetyillä jälleenmyyjän kanta-asiakastileillä, maksuilla ja ostovarmennuksella.
Ibotta pyrkii suosittelemaan räätälöityjä kampanjoita käyttäjiensä pitämiseksi ja sitouttamiseksi paremmin. Kampanjat ja käyttäjien mieltymykset kuitenkin kehittyvät jatkuvasti. Tämä jatkuvasti muuttuva ympäristö, jossa on monia uusia käyttäjiä ja uusia tarjouksia, on tyypillinen kylmäkäynnistysongelma – ei ole riittävästi historiallisia käyttäjien ja promootioiden välisiä vuorovaikutuksia, joista voisi tehdä johtopäätöksiä. Vahvistusoppiminen (RL) on koneoppimisen (ML) osa-alue, joka koskee sitä, kuinka älykkäiden agenttien tulisi toimia ympäristössä maksimoidakseen kumulatiivisten palkkioiden käsitteen. RL keskittyy löytämään tasapaino kartoittamattomien alueiden tutkimisen ja nykyisen tiedon hyödyntämisen välillä. Monikätinen rosvo (MAB) on klassinen vahvistusoppimisongelma, joka on esimerkki tutkimisen ja hyväksikäytön kompromissista: maksimoida palkkio lyhyellä aikavälillä (riisto) samalla kun uhrataan lyhyen aikavälin palkkio tiedosta, joka voi lisätä palkintoja pitkällä aikavälillä (tutkimus). ). MAB-algoritmi tutkii ja hyödyntää optimaalisia suosituksia käyttäjälle.
Ibotta teki yhteistyötä Amazon Machine Learning Solutions Lab käyttää MAB-algoritmeja käyttäjien sitoutumisen lisäämiseen, kun käyttäjä- ja mainostiedot ovat erittäin dynaamisia.
Valitsimme kontekstuaalisen MAB-algoritmin, koska se on tehokas seuraavissa käyttötapauksissa:
- Henkilökohtaisten suositusten tekeminen käyttäjien tilan (kontekstin) mukaan
- Kylmäkäynnistysnäkökohtien, kuten uusien bonuksien ja uusien asiakkaiden, käsittely
- Mukavia suosituksia, joissa käyttäjien mieltymykset muuttuvat ajan myötä
Päiväys
Bonusten lunastuksen lisäämiseksi Ibotta haluaa lähettää asiakkaille räätälöityjä bonuksia. Bonukset ovat Ibotan itse rahoittamia käteiskannustimia, jotka toimivat kontekstuaalisen monikätisen rosvomallin toimina.
Bandit-mallissa on kaksi ominaisuussarjaa:
- Toimintaominaisuudet – Nämä kuvaavat toimia, kuten bonustyyppiä ja bonuksen keskimääräistä määrää
- Asiakkaan ominaisuudet – Nämä kuvaavat asiakkaiden historiallisia mieltymyksiä ja vuorovaikutuksia, kuten viime viikkojen lunastuksia, napsautuksia ja näyttökertoja
Kontekstuaaliset ominaisuudet on johdettu historiallisista asiakaspoluista, jotka sisälsivät 26 viikoittaista aktiivisuusmittaria, jotka luotiin käyttäjien vuorovaikutuksesta Ibotta-sovelluksen kanssa.
Kontekstuaalinen monikätinen rosvo
Bandit on kehys peräkkäiselle päätöksenteolle, jossa päätöksentekijä valitsee peräkkäin toiminnan mahdollisesti nykyisen kontekstuaalisen tiedon perusteella ja tarkkailee palkkiosignaalia.
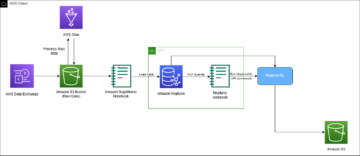
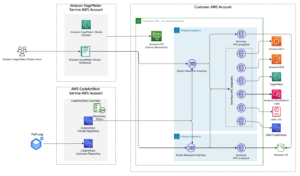
Otimme käyttöön kontekstuaalisen monikätisen rosvotyönkulun Amazon Sage Maker sisäänrakennettuna Vowpal Wabbit (VW) kontti. SageMaker auttaa datatieteilijöitä ja kehittäjiä valmistelemaan, rakentamaan, kouluttamaan ja ottamaan käyttöön korkealaatuisia ML-malleja nopeasti yhdistämällä laajan valikoiman ML:ää varten suunniteltuja ominaisuuksia. Mallin koulutus ja testaus perustuvat offline-kokeiluihin. Rosvo oppii käyttäjien mieltymykset aiemmista vuorovaikutuksista saadun palautteen perusteella eikä elävän ympäristön perusteella. Algoritmi voi siirtyä tuotantotilaan, jossa SageMaker pysyy tukiinfrastruktuurina.
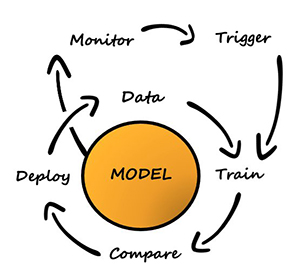
Tutkimus-/hyödyntämisstrategian toteuttamiseksi rakensimme iteratiivisen koulutus- ja käyttöönottojärjestelmän, joka suorittaa seuraavat toiminnot:
- Suosittelee toimintoa käyttämällä kontekstuaalista rosvomallia käyttäjän kontekstin perusteella
- Tallentaa implisiittisen palautteen ajan myötä
- Kouluttaa mallia jatkuvasti inkrementaalisilla vuorovaikutustiedoilla
Asiakassovelluksen työnkulku on seuraava:
- Asiakassovellus valitsee kontekstin, joka lähetetään SageMaker-päätepisteeseen toiminnon noutamiseksi.
- SageMaker-päätepiste palauttaa toiminnon, siihen liittyvän bonuksen lunastustodennäköisyyden ja
event_id. - Koska tämä simulaattori luotiin käyttämällä historiallisia vuorovaikutuksia, malli tietää todellisen luokan kyseiselle kontekstille. Jos agentti valitsee toiminnon lunastamalla, palkkio on 1. Muussa tapauksessa agentti saa palkinnon 0.
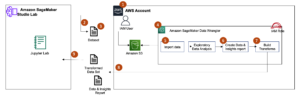
Siinä tapauksessa, että historialliset tiedot ovat saatavilla ja ovat muodossa <state, action, action probability, reward>, Ibotta voi aloittaa live-mallin lämpimästi oppimalla käytännöt offline-tilassa. Muuten Ibotta voi aloittaa satunnaisen politiikan ensimmäisenä päivänä ja alkaa oppia rosvopolitiikkaa sieltä.
Seuraavassa on koodinpätkä mallin kouluttamiseen:
Mallin suorituskyky
Jaoimme lunastetut vuorovaikutukset satunnaisesti harjoitustietoiksi (10,000 5,300 vuorovaikutusta) ja arviointidataksi (XNUMX XNUMX vuorovaikutusta).
Arviointimittarit ovat keskimääräinen palkkio, jossa 1 tarkoittaa, että suositeltu toimenpide on lunastettu, ja 0 tarkoittaa, että suositeltua toimintoa ei lunastettu.
Voimme määrittää keskimääräisen palkkion seuraavasti:
Keskimääräinen palkkio (lunastusprosentti) = (suositeltujen toimintojen määrä lunastettuna)/(yhteensä # suositeltua toimintoa)
Seuraava taulukko näyttää keskimääräisen palkkion tuloksen:
| Keskimääräinen palkinto | Yhtenäinen satunnainen suositus | Asiayhteyteen perustuva MAB-pohjainen suositus |
| Juna | 11.44% | 56.44% |
| Testi | 10.69% | 59.09% |
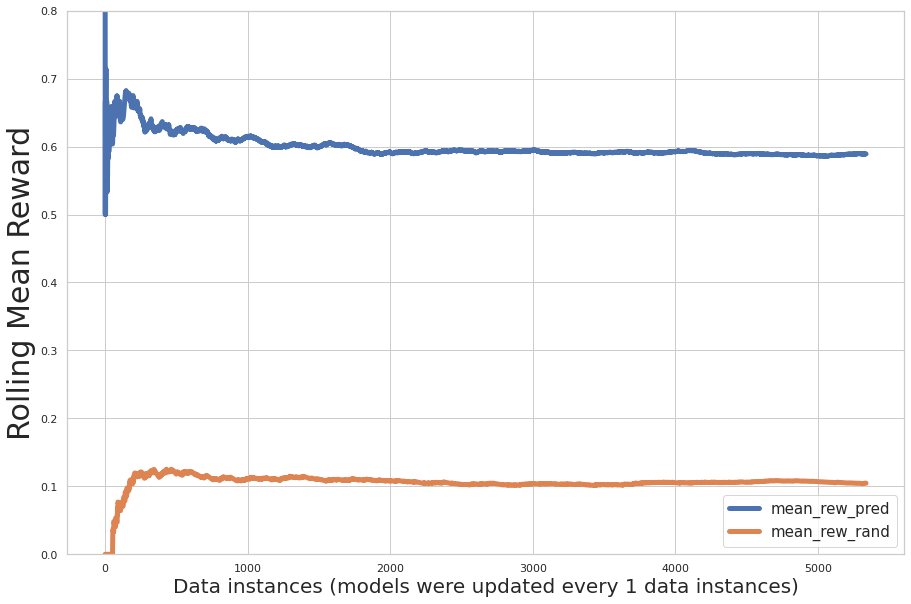
Seuraavassa kuvassa on esitetty koulutuksen aikana suoritettavan suorituskyvyn inkrementaalinen arviointi, jossa x-akseli on mallin oppimien tietueiden lukumäärä ja y-akseli on inkrementaalinen keskimääräinen palkkio. Sininen viiva osoittaa monikätistä rosvoa; oranssi viiva osoittaa satunnaisia suosituksia.

Kaavio osoittaa, että ennustettu keskimääräinen palkkio kasvaa iteraatioiden aikana ja ennustettu toimintapalkkio on huomattavasti suurempi kuin toimien satunnainen osoitus.
Voimme käyttää aiemmin koulutettuja malleja lämpiminä aloituksina ja eräkouluttaa mallia uusilla tiedoilla. Tässä tapauksessa mallin suorituskyky lähentyi jo alkukoulutuksen kautta. Uuden erän uudelleenkoulutuksessa ei havaittu merkittävää suorituskyvyn lisäparantumista, kuten seuraavasta kuvasta näkyy.
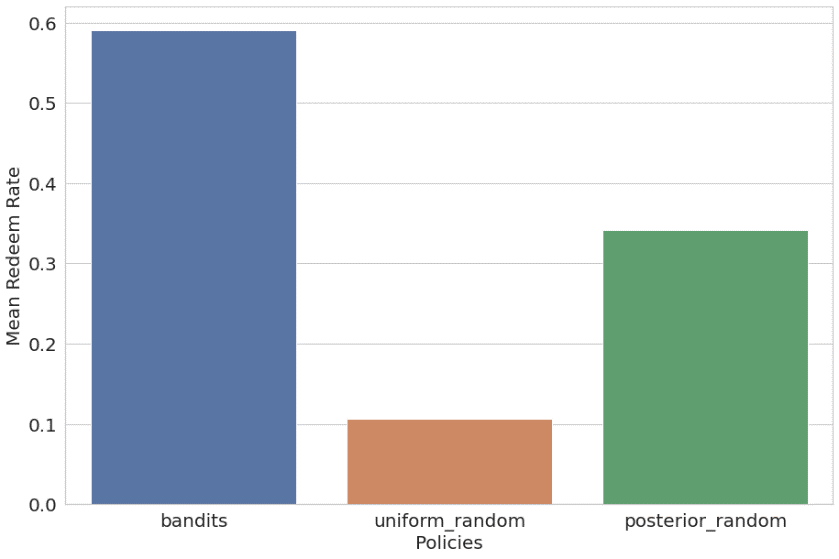
Vertasimme myös kontekstuaalista rosvoa tasaisen satunnaiseen ja jälkikäteen tapahtuvaan satunnaiseen (satunnainen suositus käyttäen historiallista käyttäjien mieltymysten jakautumista lämpimänä alkuna) käytäntöihin. Tulokset on listattu ja piirretty seuraavasti:
- Bandiitti – 59.09 % keskimääräinen palkkio (koulutus 56.44 %)
- Tasainen satunnainen – 10.69 % keskimääräinen palkkio (koulutus 11.44 %)
- Posteriorinen todennäköisyys satunnainen – 34.21 % keskimääräinen palkkio (koulutus 34.82 %)
Kontekstuaalinen monikätinen rosvoalgoritmi suoriutui huomattavasti kahdesta muusta käytännöstä.
Yhteenveto
Amazon ML Solutions Lab teki yhteistyötä Ibottan kanssa kehittääkseen kontekstuaalisen rosvo-oppimissuositusratkaisun käyttämällä SageMaker RL -säiliötä.
Tämä ratkaisu osoitti tasaisen asteittaisen lunastusprosentin nousun satunnaisten (viisinkertainen nousu) ja ei-kontekstuaalisten RL-suositusten (kaksikertainen nousu) perusteella offline-testin perusteella. Tämän ratkaisun avulla Ibotta voi luoda dynaamisen käyttäjäkeskeisen suositusmoottorin asiakkaiden sitoutumisen optimoimiseksi. Satunnaiseen suositukseen verrattuna ratkaisu paransi suositusten tarkkuutta (keskimääräistä palkkiota) 11 prosentista 59 prosenttiin offline-testin mukaan. Ibotta aikoo integroida tämän ratkaisun entistä yksilöllisempiin käyttötapauksiin.
"Amazon ML Solutions Lab teki tiivistä yhteistyötä Ibottan koneoppimistiimin kanssa rakentaakseen dynaamisen bonussuositusmoottorin lunastusten lisäämiseksi ja asiakkaiden sitoutumisen optimoimiseksi. Loimme vahvistusoppimista hyödyntävän suositusmoottorin, joka oppii ja mukautuu jatkuvasti muuttuvaan asiakastilaan ja käynnistää uudet bonukset automaattisesti. ML Solutions Lab -tutkijat kehittivät kahdessa kuukaudessa kontekstuaalisen monikätisen rosvovahvistuksen oppimisratkaisun käyttämällä SageMaker RL -säiliötä. Asiayhteyteen perustuva RL-ratkaisu osoitti tasaista nousua lunastusprosenteissa, mikä saavutti viisinkertaisen nousun bonusten lunastusprosentissa satunnaiseen suositukseen verrattuna ja kaksinkertaisen nousun ei-kontekstuaaliseen RL-ratkaisuun verrattuna. Suositustarkkuus parani satunnaisen suosituksen 2 prosentista 11 prosenttiin ML Solutions Lab -ratkaisulla. Tämän ratkaisun tehokkuuden ja joustavuuden vuoksi aiomme integroida tämän ratkaisun useimpiin Ibotan personointikäyttötapauksiin edistääksemme tavoitettamme tehdä jokaisesta ostoksesta käyttäjillemme palkitsevaa."
– Heather Shannon, Ibottan suunnittelu- ja dataosaston johtaja.
Tietoja Tekijät
 Taylorin nimet on Ibotan henkilöstön koneoppimisinsinööri, joka keskittyy sisällön personointiin ja reaaliaikaiseen kysynnän ennustamiseen. Ennen Ibottaan liittymistään Taylor johti koneoppimistiimejä IoT:n ja puhtaan energian alueilla.
Taylorin nimet on Ibotan henkilöstön koneoppimisinsinööri, joka keskittyy sisällön personointiin ja reaaliaikaiseen kysynnän ennustamiseen. Ennen Ibottaan liittymistään Taylor johti koneoppimistiimejä IoT:n ja puhtaan energian alueilla.
 Dev Gupta on suunnittelupäällikkö Ibotta Inc:ssä, jossa hän johtaa koneoppimistiimiä. Ibottan ML-tiimin tehtävänä on tarjota korkealaatuisia ML-ohjelmistoja, kuten suosittelijoita, ennustajia ja sisäisiä ML-työkaluja. Ennen Ibottaan liittymistä Dev työskenteli Predikto Inc:ssä, koneoppimiskäynnistysyrityksessä, ja The Home Depotissa. Hän valmistui Floridan yliopistosta.
Dev Gupta on suunnittelupäällikkö Ibotta Inc:ssä, jossa hän johtaa koneoppimistiimiä. Ibottan ML-tiimin tehtävänä on tarjota korkealaatuisia ML-ohjelmistoja, kuten suosittelijoita, ennustajia ja sisäisiä ML-työkaluja. Ennen Ibottaan liittymistä Dev työskenteli Predikto Inc:ssä, koneoppimiskäynnistysyrityksessä, ja The Home Depotissa. Hän valmistui Floridan yliopistosta.
 Argie Angeleas on Senior Product Manager Ibottassa, jossa hän johtaa koneoppimis- ja selainlaajennusryhmiä. Ennen Ibottaan liittymistään Argie työskenteli tuotejohtajana iReportsourcessa. Argie suoritti tohtorin tietojenkäsittelytieteessä ja tekniikassa Wright State Universitystä.
Argie Angeleas on Senior Product Manager Ibottassa, jossa hän johtaa koneoppimis- ja selainlaajennusryhmiä. Ennen Ibottaan liittymistään Argie työskenteli tuotejohtajana iReportsourcessa. Argie suoritti tohtorin tietojenkäsittelytieteessä ja tekniikassa Wright State Universitystä.
 Fang Wang on vanhempi tutkija Amazon Machine Learning Solutions Lab, jossa hän johtaa Retail Verticalia ja työskentelee AWS-asiakkaiden kanssa eri toimialoilla ratkaistakseen heidän ML-ongelmansa. Ennen AWS:ään liittymistään Fang työskenteli Anthemin tietotieteen vanhempina johtajana johtaen lääketieteellisten vaatimusten käsittelyä tekoälyalustaa. Hän suoritti tilastotieteen maisterin tutkinnon Chicagon yliopistosta.
Fang Wang on vanhempi tutkija Amazon Machine Learning Solutions Lab, jossa hän johtaa Retail Verticalia ja työskentelee AWS-asiakkaiden kanssa eri toimialoilla ratkaistakseen heidän ML-ongelmansa. Ennen AWS:ään liittymistään Fang työskenteli Anthemin tietotieteen vanhempina johtajana johtaen lääketieteellisten vaatimusten käsittelyä tekoälyalustaa. Hän suoritti tilastotieteen maisterin tutkinnon Chicagon yliopistosta.
 Xin Chen on ylempi johtaja yrityksessä Amazon Machine Learning Solutions Lab, jossa hän johtaa Keski-Yhdysvaltoja, Suur-Kiinan aluetta, LATAM:ia ja Automotive Verticalia. Hän auttaa AWS-asiakkaita eri toimialoilla tunnistamaan ja rakentamaan koneoppimisratkaisuja, jotka vastaavat heidän organisaationsa korkeimman sijoitetun pääoman tuottomahdollisuuksiin. Xin valmistui tietojenkäsittelytieteen ja tekniikan tohtoriksi Notre Damen yliopistosta.
Xin Chen on ylempi johtaja yrityksessä Amazon Machine Learning Solutions Lab, jossa hän johtaa Keski-Yhdysvaltoja, Suur-Kiinan aluetta, LATAM:ia ja Automotive Verticalia. Hän auttaa AWS-asiakkaita eri toimialoilla tunnistamaan ja rakentamaan koneoppimisratkaisuja, jotka vastaavat heidän organisaationsa korkeimman sijoitetun pääoman tuottomahdollisuuksiin. Xin valmistui tietojenkäsittelytieteen ja tekniikan tohtoriksi Notre Damen yliopistosta.
 Raj Biswas on datatieteilijä Amazon Machine Learning Solutions Lab. Hän auttaa AWS-asiakkaita kehittämään ML-pohjaisia ratkaisuja eri toimialoilla heidän kiireellisimpiin liiketoimintahaasteisiinsa. Ennen tuloaan AWS:ään hän oli jatko-opiskelija Columbian yliopistossa datatieteessä.
Raj Biswas on datatieteilijä Amazon Machine Learning Solutions Lab. Hän auttaa AWS-asiakkaita kehittämään ML-pohjaisia ratkaisuja eri toimialoilla heidän kiireellisimpiin liiketoimintahaasteisiinsa. Ennen tuloaan AWS:ään hän oli jatko-opiskelija Columbian yliopistossa datatieteessä.
 Xinghua Liang on soveltuva tutkija Amazon Machine Learning Solutions Lab, jossa hän työskentelee asiakkaiden kanssa eri toimialoilta, mukaan lukien valmistus ja autoteollisuus, ja auttaa heitä nopeuttamaan tekoälyn ja pilven käyttöönottoa. Xinghua valmistui tekniikan tohtoriksi Carnegie Mellonin yliopistosta.
Xinghua Liang on soveltuva tutkija Amazon Machine Learning Solutions Lab, jossa hän työskentelee asiakkaiden kanssa eri toimialoilta, mukaan lukien valmistus ja autoteollisuus, ja auttaa heitä nopeuttamaan tekoälyn ja pilven käyttöönottoa. Xinghua valmistui tekniikan tohtoriksi Carnegie Mellonin yliopistosta.
 Yi Liu on soveltava tutkija Amazonin asiakaspalvelussa. Hän on intohimoinen ML/AI:n tehon käyttämisestä optimoidakseen Amazon-asiakkaiden käyttökokemuksen ja auttaakseen AWS-asiakkaita rakentamaan skaalautuvia pilviratkaisuja. Hänen tiedetyönsä Amazonissa kattaa jäsensitoutumisen, online-suositusjärjestelmän ja asiakaskokemuksen vikojen tunnistamisen ja ratkaisemisen. Työn ulkopuolella Yi nauttii matkustamisesta ja luontoon tutustumisesta koiransa kanssa.
Yi Liu on soveltava tutkija Amazonin asiakaspalvelussa. Hän on intohimoinen ML/AI:n tehon käyttämisestä optimoidakseen Amazon-asiakkaiden käyttökokemuksen ja auttaakseen AWS-asiakkaita rakentamaan skaalautuvia pilviratkaisuja. Hänen tiedetyönsä Amazonissa kattaa jäsensitoutumisen, online-suositusjärjestelmän ja asiakaskokemuksen vikojen tunnistamisen ja ratkaisemisen. Työn ulkopuolella Yi nauttii matkustamisesta ja luontoon tutustumisesta koiransa kanssa.
- "
- &
- 000
- 10
- 100
- 11
- 7
- 9
- Meistä
- kiihdyttää
- Mukaan
- poikki
- Toiminta
- toimet
- toiminta
- lisä-
- osoite
- Hyväksyminen
- aineet
- AI
- algoritmi
- algoritmit
- jo
- Amazon
- Amerikkalainen
- määrä
- sovelluksen
- Hakemus
- sovellukset
- ALUE
- Automotive
- saatavissa
- keskimäärin
- AWS
- Bonus
- selain
- rakentaa
- sisäänrakennettu
- liiketoiminta
- kyvyt
- Carnegie Mellon
- tapauksissa
- kassa
- haasteet
- muuttaa
- Chicago
- Kiina
- klassinen
- pilvi
- koodi
- yritys
- verrattuna
- Tietojenkäsittelyoppi
- Kontti
- pitoisuus
- Nykyinen
- asiakaskokemus
- Asiakaspalvelu
- Asiakkaat
- tiedot
- tietojenkäsittely
- tietojen tutkija
- päivä
- päätöksentekijä
- Kysyntä
- osoittivat
- sijoittaa
- käyttöönotto
- dev
- kehittää
- kehitetty
- kehittäjille
- eri
- Johtaja
- jakelu
- dynaaminen
- Tehokas
- päätepiste
- energia
- sitoumus
- Moottori
- insinööri
- Tekniikka
- ympäristö
- perustaa
- kehittyvä
- experience
- tutkimus
- Ominaisuudet
- palaute
- Kuva
- Joustavuus
- Florida
- keskittyy
- jälkeen
- muoto
- Puitteet
- edelleen
- valmistua
- vieras
- vieras Lähetä
- korkeus
- auttaa
- auttaa
- erittäin
- historiallinen
- Etusivu
- Miten
- HTTPS
- Tunnistaminen
- tunnistaa
- toteuttaa
- Mukaan lukien
- Kasvaa
- teollisuuden
- teollisuus
- tiedot
- Infrastruktuuri
- yhdistää
- Älykäs
- vuorovaikutus
- Esineiden internet
- tuntemus
- laboratorio
- johtava
- Liidit
- OPPIA
- oppinut
- oppiminen
- Led
- vipuvaikutuksen
- linja
- lueteltu
- Pitkät
- Uskollisuus
- kone
- koneoppiminen
- Tekeminen
- johtaja
- valmistus
- maisterin
- lääketieteellinen
- Metrics
- Tehtävä
- ML
- Puhelinnumero
- Mobiilisovellus
- malli
- mallit
- kk
- lisää
- eniten
- nimet
- luonto
- Käsite
- numero
- verkossa
- online-ostot
- Mahdollisuudet
- tilata
- Muut
- muuten
- maksut
- suorituskyky
- Personointi
- foorumi
- politiikkaa
- politiikka
- teho
- puheenjohtaja
- Ongelma
- ongelmia
- Tuotteet
- tuotanto
- edistäminen
- tarjoamalla
- osto
- ostot
- nopeasti
- Hinnat
- reaaliaikainen
- suositella
- asiakirjat
- tutkimus
- tulokset
- vähittäiskauppa
- jälleenmyyjä
- Tuotto
- Palkkiot
- skaalautuva
- tiede
- Tiedemies
- tutkijat
- valittu
- palvelu
- setti
- merkittävä
- Tuotteemme
- ratkaisu
- Ratkaisumme
- SOLVE
- tilat
- jakaa
- Alkaa
- alkaa
- käynnistyksen
- Osavaltio
- tilasto
- Strategia
- opiskelija
- Tukea
- Tukee
- Vaihtaa
- järjestelmä
- joukkue-
- Elektroniikka
- testi
- Testaus
- Kautta
- yhdessä
- työkalut
- koulutus
- junat
- yliopisto
- us
- käyttää
- Käyttäjät
- eri
- Vahvistus
- Varapresidentti
- viikoittain
- sisällä
- Referenssit
- työskenteli
- työskentely
- toimii