Jos olet yritysanalyytikko, asiakkaiden käyttäytymisen ymmärtäminen on luultavasti yksi tärkeimmistä asioista, joista välität. Asiakkaiden ostopäätösten taustalla olevien syiden ja mekanismien ymmärtäminen voi edistää liikevaihdon kasvua. Kuitenkin asiakkaiden menetys (kutsutaan yleisesti ns asiakasvaurio) aiheuttaa aina riskin. Ymmärrys siitä, miksi asiakkaat lähtevät, voi olla yhtä tärkeää voittojen ja tulojen ylläpitämisen kannalta.
Vaikka koneoppiminen (ML) voi tarjota arvokkaita oivalluksia, ML-asiantuntijoita tarvittiin rakentamaan asiakkaiden vaihtuvuuden ennustusmalleja, kunnes Amazon SageMaker Canvas.
SageMaker Canvas on matalan koodin/kooditon hallintapalvelu, jonka avulla voit luoda ML-malleja, jotka voivat ratkaista monia liiketoimintaongelmia kirjoittamatta yhtä koodiriviä. Sen avulla voit myös arvioida malleja kehittyneillä mittareilla aivan kuin olisit tietotieteilijä.
Tässä viestissä näytämme, kuinka yritysanalyytikko voi arvioida ja ymmärtää luokitteluvaihtuvuusmallia, joka on luotu SageMaker Canvasilla käyttämällä Kehittyneet mittarit -välilehti. Selitämme mittareita ja näytämme tekniikoita tietojen käsittelemiseksi paremman mallin suorituskyvyn saavuttamiseksi.
Edellytykset
Jos haluat toteuttaa kaikki tai jotkut tässä viestissä kuvatuista tehtävistä, tarvitset AWS-tilin, jolla on pääsy SageMaker Canvasiin. Viitata Ennusta asiakkaiden vaihtuvuus koodittomalla koneoppimisella Amazon SageMaker Canvasin avulla kattaaksesi SageMaker Canvasin, churn-mallin ja tietojoukon perusasiat.
Johdatus mallin suorituskyvyn arviointiin
Yleisenä ohjeena, kun sinun on arvioitava mallin suorituskykyä, yrität mitata, kuinka hyvin malli ennustaa jotain, kun se näkee uutta tietoa. Tätä ennustetta kutsutaan päättely. Aloitat harjoittelemalla mallia käyttämällä olemassa olevaa dataa ja pyydät sitten mallia ennustamaan tulos datalla, jota se ei ole vielä nähnyt. Se, kuinka tarkasti malli ennustaa tämän tuloksen, on se, mitä tarkastelet mallin suorituskyvyn ymmärtämiseksi.
Jos malli ei ole nähnyt uutta dataa, mistä kukaan voisi tietää, onko ennuste hyvä vai huono? No, ideana on käyttää historiallista dataa, jossa tulokset ovat jo tiedossa, ja verrata näitä arvoja mallin ennustettuihin arvoihin. Tämä otetaan käyttöön asettamalla sivuun osa historiallisista harjoitustiedoista, jotta niitä voidaan verrata siihen, mitä malli ennustaa näille arvoille.
Asiakkaan vaihtuvuuden esimerkissä (joka on kategorinen luokitteluongelma) aloitat historiallisella tietojoukolla, joka kuvaa asiakkaita useilla määritteillä (yksi jokaisessa tietueessa). Yksi attribuuteista, nimeltään Churn, voi olla True tai False, ja se kuvaa, poistuiko asiakas palvelusta vai ei. Mallin tarkkuuden arvioimiseksi jaamme tämän tietojoukon ja koulutamme mallia käyttämällä yhtä osaa (harjoitustietojoukkoa) ja pyydämme mallia ennustamaan lopputulos (luokitetaan asiakas Churniksi tai ei) toisen osan (testitietojoukon) kanssa. Sen jälkeen vertaamme mallin ennustetta testiaineiston sisältämään perustotuuteen.
Kehittyneiden mittareiden tulkitseminen
Tässä osiossa käsittelemme SageMaker Canvasin edistyneitä mittareita, jotka voivat auttaa sinua ymmärtämään mallin suorituskykyä.
Hämmennysmatriisi
SageMaker Canvas käyttää hämmennysmatriiseja auttaakseen sinua visualisoimaan, milloin malli luo ennusteita oikein. Hämmennysmatriisissa tulokset on järjestetty vertaamaan ennustettuja arvoja todellisiin historiallisiin (tunnettuihin) arvoihin. Seuraava esimerkki selittää, kuinka sekaannusmatriisi toimii kaksiluokkaisessa ennustemallissa, joka ennustaa positiivisia ja negatiivisia tunnisteita:
- Tosi positiivista – Malli ennusti oikein positiivisen, kun todellinen merkki oli positiivinen
- Tosi negatiivinen – Malli ennusti oikein negatiivisen, kun todellinen merkki oli negatiivinen
- Väärä positiivinen – Malli ennusti väärin positiiviseksi, kun todellinen merkki oli negatiivinen
- Väärä negatiivinen – Malli ennusti väärin negatiiviseksi, kun todellinen merkki oli positiivinen
Seuraava kuva on esimerkki sekavuusmatriisista kahdelle kategorialle. Vaihtuvuusmallissamme todelliset arvot tulevat testitietojoukosta ja ennustetut arvot kysymällä malliamme.
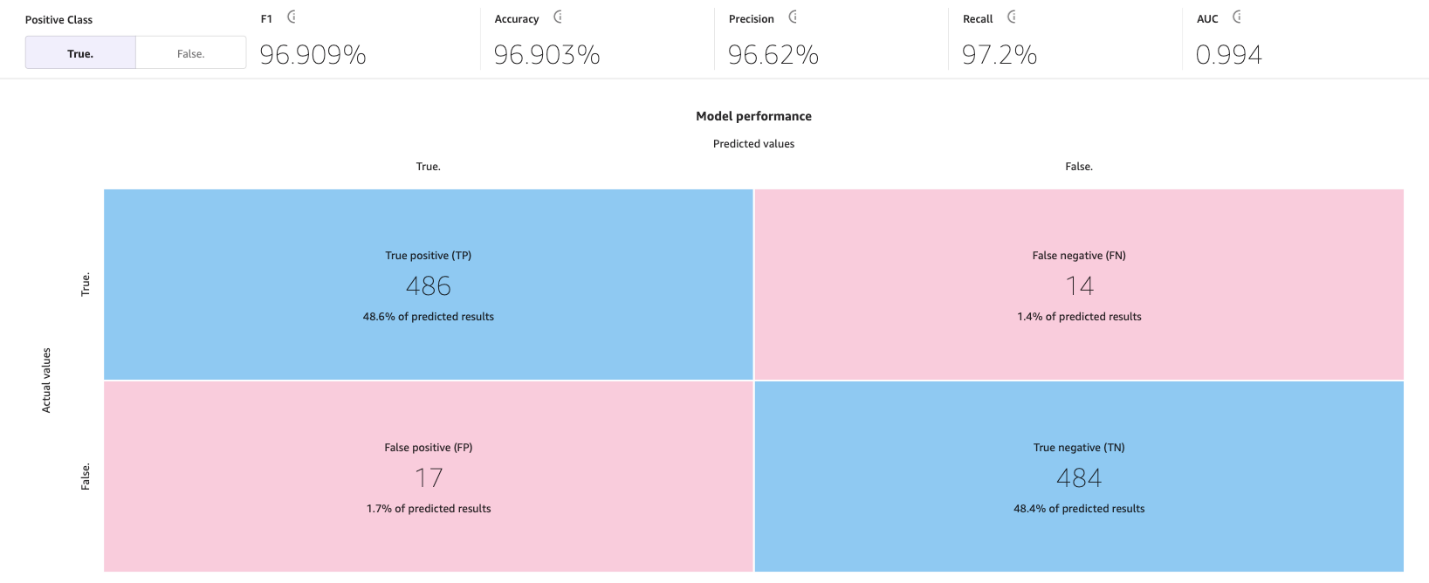
tarkkuus
Tarkkuus on oikeiden ennusteiden prosenttiosuus testijoukon kaikista riveistä tai näytteistä. Oikeat näytteet ennustettiin todeksi sekä väärät näytteet, jotka ennustettiin oikein vääriksi, jaettuna tietojoukon näytteiden kokonaismäärällä.
Se on yksi tärkeimmistä ymmärrettävistä mittareista, koska se kertoo kuinka suurella prosentilla malli ennusti oikein, mutta se voi joissain tapauksissa olla harhaanjohtava. Esimerkiksi:
- Luokka epätasapaino – Kun tietojoukossasi olevat luokat eivät ole jakautuneet tasaisesti (yhdestä luokasta on suhteettoman paljon näytteitä ja toisista hyvin vähän), tarkkuus voi olla harhaanjohtavaa. Tällaisissa tapauksissa jopa malli, joka yksinkertaisesti ennustaa kunkin esiintymän enemmistöluokan, voi saavuttaa suuren tarkkuuden.
- Kustannusherkkä luokitus – Joissakin sovelluksissa eri luokkien luokitteluvirheen kustannukset voivat olla erilaisia. Jos esimerkiksi ennustaisimme, voiko lääke pahentaa tilaa, väärä negatiivinen tulos (esimerkiksi ennustaminen, että lääke ei ehkä pahenna, kun se todella tekee) voi olla kalliimpaa kuin väärä positiivinen tulos (esimerkiksi ennustaminen, että lääke saattaa pahentaa kun ei todellakaan ole).
Tarkkuus, muistaminen ja F1-pisteet
Tarkkuus on todellisten positiivisten (TP) osuus kaikista ennustetuista positiivisista (TP + FP). Se mittaa niiden positiivisten ennusteiden osuutta, jotka ovat todella oikeita.
Recall on todellisten positiivisten (TP) osuus kaikista todellisista positiivisista (TP + FN). Se mittaa niiden positiivisten tapausten osuutta, jotka malli ennusti oikein positiivisiksi.
F1-pisteet yhdistävät tarkkuuden ja muistamisen muodostaen yhden pistemäärän, joka tasapainottaa niiden välisen kompromissin. Se määritellään tarkkuuden ja muistamisen harmoniseksi keskiarvoksi:
F1-pisteet = 2 * (tarkkuus * muistaminen) / (tarkkuus + muistaminen)
F1-pisteet vaihtelevat 0–1, ja korkeampi pistemäärä osoittaa parempaa suorituskykyä. Täydellinen F1-pistemäärä 1 osoittaa, että malli on saavuttanut sekä täydellisen tarkkuuden että täydellisen muistamisen, ja pistemäärä 0 osoittaa, että mallin ennusteet ovat täysin vääriä.
F1-pisteet tarjoavat tasapainoisen arvion mallin suorituskyvystä. Se ottaa huomioon tarkkuuden ja muistamisen tarjoamalla informatiivisemman arviointimittarin, joka kuvastaa mallin kykyä luokitella oikein positiiviset tapaukset ja välttää vääriä positiivisia ja vääriä negatiivisia.
Esimerkiksi lääketieteellisessä diagnoosissa, petosten havaitsemisessa ja mielialan analysoinnissa F1 on erityisen tärkeä. Lääketieteellisessä diagnoosissa tietyn sairauden tai tilan tarkka tunnistaminen on ratkaisevan tärkeää, ja väärillä negatiivisilla tai väärillä positiivisilla tuloksilla voi olla merkittäviä seurauksia. F1-pistemäärässä otetaan huomioon sekä tarkkuus (kyky tunnistaa positiiviset tapaukset oikein) että muistaminen (kyky löytää kaikki positiiviset tapaukset), mikä tarjoaa tasapainoisen arvion mallin suorituskyvystä taudin havaitsemisessa. Vastaavasti petosten havaitsemisessa, jossa todellisten petostapausten määrä on suhteellisen pieni verrattuna ei-petollisiin tapauksiin (epätasapainoiset luokat), tarkkuus voi yksinään olla harhaanjohtava, koska todellisia negatiivisia asioita on paljon. F1-pisteet tarjoavat kattavan mittauksen mallin kyvystä havaita sekä vilpilliset että ei-petolliset tapaukset, ottaen huomioon sekä tarkkuuden että muistamisen. Ja mielipideanalyysissä, jos tietojoukko on epätasapainossa, tarkkuus ei välttämättä heijasta tarkasti mallin suorituskykyä positiivisen ilmapiiriluokan tapausten luokittelussa.
AUC (käyrän alla oleva pinta-ala)
AUC-metriikka arvioi binäärisen luokitusmallin kykyä erottaa positiiviset ja negatiiviset luokat kaikilla luokituskynnyksillä. A kynnys on arvo, jota malli käyttää päätöksen tekemiseen kahden mahdollisen luokan välillä ja muuntaa todennäköisyyden, että otos on osa luokkaa, binääripäätökseksi. AUC:n laskemiseksi todellinen positiivinen määrä (TPR) ja väärä positiivinen määrä (FPR) piirretään eri kynnysasetuksille. TPR mittaa todellisten positiivisten osuutta kaikista todellisista positiivisista, kun taas FPR mittaa väärien positiivisten osuutta kaikista todellisista negatiivisista. Tuloksena oleva käyrä, jota kutsutaan vastaanottimen käyttöominaisuuksien (ROC) käyräksi, tarjoaa visuaalisen esityksen TPR:stä ja FPR:stä eri kynnysasetuksissa. AUC-arvo, joka vaihtelee välillä 0–1, edustaa aluetta ROC-käyrän alla. Korkeammat AUC-arvot osoittavat parempaa suorituskykyä, ja täydellinen luokitin saavuttaa AUC-arvon 1.
Seuraava kuvaaja näyttää ROC-käyrän, jossa TPR on Y-akseli ja FPR X-akselina. Mitä lähemmäs käyrä on kaavion vasenta yläkulmaa, sitä paremmin malli luokittelee tiedot luokkiin.

Selvyyden vuoksi käydään läpi esimerkki. Ajatellaanpa petosten havaitsemismallia. Yleensä nämä mallit on koulutettu epätasapainoisista tietojoukoista. Tämä johtuu siitä, että yleensä lähes kaikki tietojoukon tapahtumat eivät ole vilpillisiä, ja vain muutamat on merkitty petoksiksi. Tässä tapauksessa tarkkuus ei välttämättä riitä kaappaamaan mallin suorituskykyä riittävästi, koska siihen vaikuttaa todennäköisesti voimakkaasti muiden kuin vilpillisten tapausten runsaus, mikä johtaa harhaanjohtavan korkeisiin tarkkuuspisteisiin.
Tässä tapauksessa AUC olisi parempi mittari mallin suorituskyvyn arvioimiseen, koska se tarjoaa kattavan arvion mallin kyvystä erottaa vilpilliset ja ei-petolliset tapahtumat. Se tarjoaa vivahteikkaamman arvioinnin, jossa otetaan huomioon todellisen positiivisen määrän ja väärän positiivisen määrän välinen kompromissi eri luokituskynnyksillä.
Aivan kuten F1-pisteet, se on erityisen hyödyllinen, kun tietojoukko on epätasapainossa. Se mittaa TPR:n ja FPR:n välistä kompromissia ja näyttää kuinka hyvin malli pystyy erottamaan nämä kaksi luokkaa niiden jakautumisesta riippumatta. Tämä tarkoittaa, että vaikka yksi luokka on huomattavasti pienempi kuin toinen, ROC-käyrä arvioi mallin suorituskyvyn tasapainoisesti ottaen huomioon molemmat luokat tasapuolisesti.
Muita tärkeitä aiheita
Kehittyneet mittarit eivät ole ainoita käytettävissäsi olevia tärkeitä työkaluja ML-mallin suorituskyvyn arvioimiseen ja parantamiseen. Tietojen valmistelu, ominaisuussuunnittelu ja ominaisuuksien vaikutusanalyysi ovat tekniikoita, jotka ovat välttämättömiä mallin rakentamisessa. Näillä toiminnoilla on ratkaiseva rooli merkityksellisten oivallusten poimimisessa raakatiedoista ja mallin suorituskyvyn parantamisesta, mikä johtaa vankempiin ja oivaltavampiin tuloksiin.
Tietojen valmistelu ja ominaisuussuunnittelu
Ominaisuussuunnittelu on prosessi, jossa valitaan, muunnetaan ja luodaan uusia muuttujia (ominaisuuksia) raakatiedoista, ja sillä on keskeinen rooli ML-mallin suorituskyvyn parantamisessa. Oleellisimpien muuttujien tai ominaisuuksien valitseminen saatavilla olevista tiedoista sisältää epäolennaisten tai redundanttien ominaisuuksien poistamisen, jotka eivät vaikuta mallin ennustevoimaan. Tietoominaisuuksien muuntamiseen sopivaan muotoon kuuluu skaalaus, normalisointi ja puuttuvien arvojen käsittely. Ja lopuksi uusien ominaisuuksien luominen olemassa olevasta tiedosta tehdään matemaattisilla muunnoksilla, yhdistämällä tai vuorovaikuttamalla eri ominaisuuksia tai luomalla uusia ominaisuuksia toimialuekohtaisesta tiedosta.
Ominaisuuden tärkeysanalyysi
SageMaker Canvas luo ominaisuuden tärkeysanalyysin, joka selittää kunkin tietojoukon sarakkeen vaikutuksen malliin. Kun luot ennusteita, näet sarakkeen vaikutuksen, joka tunnistaa, mitkä sarakkeet vaikuttavat eniten kuhunkin ennusteeseen. Tämä antaa sinulle käsityksen siitä, mitkä ominaisuudet ansaitsevat olla osa lopullista malliasi ja mitkä niistä tulisi hylätä. Sarakkeen vaikutus on prosentuaalinen pistemäärä, joka osoittaa, kuinka paljon sarakkeella on painoarvoa ennusteiden tekemisessä suhteessa muihin sarakkeisiin. Jos sarakkeen vaikutus on 25 %, Canvas painaa ennusteen 25 % sarakkeelle ja 75 % muille sarakkeille.
Lähestymistapoja mallin tarkkuuden parantamiseksi
Vaikka mallien tarkkuuden parantamiseksi on useita menetelmiä, datatutkijat ja ML-harjoittajat noudattavat yleensä jompaakumpaa tässä osiossa käsitellystä lähestymistavasta käyttämällä aiemmin kuvattuja työkaluja ja mittareita.
Mallikeskeinen lähestymistapa
Tässä lähestymistavassa data pysyy aina samana ja sitä käytetään mallin iteratiiviseen parantamiseen haluttujen tulosten saavuttamiseksi. Tässä lähestymistavassa käytettyjä työkaluja ovat:
- Kokeile useita asiaankuuluvia ML-algoritmeja
- Algoritmien ja hyperparametrien viritys ja optimointi
- Erilaiset malliryhmämenetelmät
- Valmiiksi koulutettujen mallien käyttäminen (SageMaker tarjoaa erilaisia sisäänrakennetut tai esikoulutetut mallit auttamaan ML:n harjoittajia)
- AutoML, jota SageMaker Canvas tekee kulissien takana (käyttäen Amazon SageMaker -autopilotti), joka kattaa kaikki edellä mainitut
Tietokeskeinen lähestymistapa
Tässä lähestymistavassa painopiste on tietojen valmistelussa, tietojen laadun parantamisessa ja tietojen iteratiivisessa muokkaamisessa suorituskyvyn parantamiseksi:
- Mallin harjoittamiseen käytetyn tietojoukon tilastojen tutkiminen, joka tunnetaan myös nimellä exploratory data analysis (EDA)
- Tietojen laadun parantaminen (tietojen puhdistus, puuttuvien arvojen imputointi, poikkeamien havaitseminen ja hallinta)
- Ominaisuuden valinta
- Ominaisuuksien suunnittelu
- Tietojen lisääminen
Mallin suorituskyvyn parantaminen Canvasilla
Aloitamme datakeskeisellä lähestymistavalla. Käytämme mallin esikatselutoimintoa ensimmäisen EDA:n suorittamiseen. Tämä tarjoaa meille lähtötilanteen, jota voimme käyttää tietojen täydentämiseen, uuden perustason luomiseen ja lopulta parhaan mallin saamiseen mallikeskeisellä lähestymistavalla käyttämällä standardia koontitoimintoa.
Käytämme synteettinen tietojoukko matkapuhelinoperaattorilta. Tämä esimerkkitietojoukko sisältää 5,000 21 tietuetta, joissa jokainen tietue käyttää XNUMX attribuuttia asiakasprofiilin kuvaamiseen. Viitata Ennusta asiakkaiden vaihtuvuus koodittomalla koneoppimisella Amazon SageMaker Canvasin avulla täydellisen kuvauksen.
Mallin esikatselu tietokeskeisessä lähestymistavassa
Ensimmäisenä vaiheena avaamme tietojoukon, valitsemme sarakkeen, jonka haluat ennustaa Churn?-muodossa, ja luomme esikatselumallin valitsemalla Esikatselu malli.

- Esikatselu malli ruudussa näkyy edistyminen, kunnes esikatselumalli on valmis.

Kun malli on valmis, SageMaker Canvas luo ominaisuuden tärkeysanalyysin.

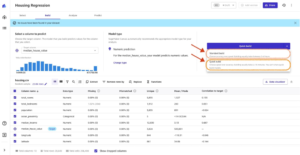
Lopuksi, kun se on valmis, ruutu näyttää luettelon sarakkeista ja sen vaikutuksista malliin. Nämä ovat hyödyllisiä ymmärtääksesi, kuinka tärkeitä ominaisuudet ovat ennusteissamme. Sarakkeen vaikutus on prosentuaalinen pistemäärä, joka osoittaa, kuinka paljon sarakkeella on painoarvoa ennusteiden tekemisessä suhteessa muihin sarakkeisiin. Seuraavassa esimerkissä Night Calls -sarakkeessa SageMaker Canvas painottaa ennusteen sarakkeelle 4.04 % ja muille sarakkeille 95.9 %. Mitä suurempi arvo, sitä suurempi vaikutus.
Kuten näemme, esikatselumallin tarkkuus on 95.6 %. Yritetään parantaa mallin suorituskykyä tietokeskeisellä lähestymistavalla. Valmistelemme tietoja ja käytämme ominaisuussuunnittelutekniikoita suorituskyvyn parantamiseksi.
Kuten seuraavassa kuvakaappauksessa näkyy, voimme havaita, että Puhelin- ja Tila-sarakkeilla on paljon vähemmän vaikutusta ennusteeseemme. Siksi käytämme näitä tietoja syötteenä seuraavaan vaiheeseen, tietojen valmisteluun.

SageMaker Canvas tarjoaa ML-tietomuunnoksia, joiden avulla voit puhdistaa, muuntaa ja valmistella tietosi mallinrakennusta varten. Voit käyttää näitä muunnoksia tietojoukoissasi ilman koodia, ja ne lisätään mallireseptiin, joka on tietuellesi ennen mallin rakentamista suoritetusta tietojen valmistelusta.
Huomaa, että kaikki käyttämäsi datamuunnokset muokkaavat vain syöttödataa mallia rakennettaessa eivätkä muuta tietojoukkoasi tai alkuperäistä tietolähdettä.
Seuraavat muunnokset ovat saatavilla SageMaker Canvasissa, jotta voit valmistella tietosi rakentamista varten:
- Päivämäärän ja ajan poiminta
- Pudota sarakkeita
- Suodata rivit
- Toiminnot ja operaattorit
- Hallitse rivejä
- Nimeä sarakkeet uudelleen
- Poista rivit
- Korvaa arvot
- Ota uudelleen näyte aikasarjan tiedoista
Aloitetaan pudottamalla sarakkeet, jotka olemme löytäneet ja joilla on vain vähän vaikutusta ennusteeseemme.
Esimerkiksi tässä tietojoukossa puhelinnumero vastaa vain tilinumeroa – se on hyödytöntä tai jopa haitallista ennakoitaessa muiden tilien vaihtuvuuden todennäköisyyttä. Samoin asiakkaan tila ei juurikaan vaikuta malliimme. Poistetaan Puhelin- ja Osavaltio-sarakkeet poistamalla näiden ominaisuuksien valinnat kohdasta Sarakkeen nimi.

Suoritetaan nyt joitakin lisätietojen muunnoksia ja ominaisuuksien suunnittelua.
Esimerkiksi aiemmassa analyysissämme havaitsimme, että asiakkailta veloitetulla summalla on suora vaikutus vaihtumiseen. Luodaan siksi uusi sarake, joka laskee asiakkaidemme kokonaismaksut yhdistämällä Maksu, Minit ja Puhelut päivältä, Eveltä, Yöltä ja Intl. Käytämme tätä varten mukautettuja kaavoja SageMaker Canvasissa.

Aloitetaan valitsemalla Tehtävät, lisäämme kaavan tekstilaatikkoon seuraavan tekstin:
(Päiväpuhelut*Päivämaksu*Päiväminuutit)+(Aattopuhelut*Aattomaksu*Aattominuutit)+(Yöpuhelut*Yöveloitus*Yöminuutit)+(Kansainväliset puhelut*Kansainväliset maksut*Kansainväliset min.)
Anna uudelle sarakkeelle nimi (esimerkiksi Kokonaiskulut) ja valitse Lisää esikatselun luomisen jälkeen. Mallin reseptin pitäisi nyt näyttää seuraavan kuvakaappauksen mukaiselta.

Kun tämä tietojen valmistelu on valmis, koulutamme uuden esikatselumallin nähdäksemme, onko malli parantunut. Valita Esikatselu malli uudelleen, ja oikeassa alakulmassa näkyy edistyminen.

Kun koulutus on valmis, se laskee uudelleen ennustetun tarkkuuden ja luo myös uuden sarakkeen vaikutusanalyysin.

Ja lopuksi, kun koko prosessi on valmis, voimme nähdä saman ruudun, jonka näimme aiemmin, mutta uuden esikatselumallin tarkkuudella. Mallin tarkkuus on noussut 0.4 % (95.6 %:sta 96 %:iin).

Edellisten kuvien luvut voivat poiketa sinun, koska ML tuo jonkin verran stokastisuutta harjoitusmallien prosessiin, mikä voi johtaa erilaisiin tuloksiin eri rakennuksissa.
Mallikeskeinen lähestymistapa mallin luomiseen
Canvas tarjoaa kaksi vaihtoehtoa mallien rakentamiseen:
- Vakiorakenne – Rakentaa parhaan mallin optimoidusta prosessista, jossa nopeus vaihdetaan parempaan tarkkuuteen. Se käyttää Auto-ML:ää, joka automatisoi ML:n erilaisia tehtäviä, mukaan lukien mallin valinnan, erilaisten ML-käyttötapaukseesi liittyvien algoritmien kokeilemisen, hyperparametrien virityksen ja mallin selitettävyysraporttien luomisen.
- Nopea rakentaa – Rakentaa yksinkertaisen mallin murto-osassa ajasta verrattuna standardikoon, mutta tarkkuus vaihtuu nopeuteen. Pikamalli on hyödyllinen iteroitaessa ymmärtääksesi nopeammin tietojen muutosten vaikutusta mallin tarkkuuteen.
Jatketaan tavallisen koontimenetelmän käyttöä.
Vakiorakenne
Kuten näimme aiemmin, vakiorakenne rakentaa parhaan mallin optimoidusta prosessista tarkkuuden maksimoimiseksi.

Kierrosmallimme rakennusprosessi kestää noin 45 minuuttia. Tänä aikana Canvas testaa satoja ehdokasputkia ja valitsee parhaan mallin. Seuraavassa kuvakaappauksessa voimme nähdä odotetun rakennusajan ja edistymisen.
Standardin rakennusprosessin avulla ML-mallimme on parantanut mallin tarkkuutta 96.903 prosenttiin, mikä on merkittävä parannus.

Tutustu edistyneisiin mittareihin
Tutkitaan mallia käyttämällä Kehittyneet mittarit välilehti. Sen Pisteytys välilehti, valitse Kehittyneet mittarit.

Tällä sivulla näkyy seuraava sekavuusmatriisi yhdessä edistyneiden mittareiden kanssa: F1-pisteet, tarkkuus, tarkkuus, muistaminen, F1-pisteet ja AUC.

Luo ennusteita
Nyt kun mittarit näyttävät hyviltä, voimme tehdä interaktiivisen ennusteen Ennustaa -välilehti joko eränä tai yksittäisenä (reaaliaikaisena) ennusteena.
Meillä on kaksi vaihtoehtoa:
- Käytä tätä mallia suorittaaksesi erän tai yksittäisen ennusteen
- Lähetä malli osoitteeseen Amazon Sagemaker Studio jakaa datatieteilijöiden kanssa
Puhdistaa
Välttääksesi tulevaisuuden istuntomaksut, kirjaudu ulos SageMaker Canvasista.

Yhteenveto
SageMaker Canvas tarjoaa tehokkaita työkaluja, joiden avulla voit rakentaa ja arvioida mallien tarkkuutta ja parantaa niiden suorituskykyä ilman koodausta tai erikoistunutta datatiede- ja ML-asiantuntemusta. Kuten esimerkissä on nähty luomalla asiakasvaihtuvuusmalli, yhdistämällä nämä työkalut sekä data- että mallikeskeiseen lähestymistapaan kehittyneitä mittareita käyttäen, yritysanalyytikot voivat luoda ja arvioida ennustemalleja. Visuaalisen käyttöliittymän ansiosta sinulla on myös mahdollisuus luoda tarkkoja ML-ennusteita itse. Suosittelemme sinua käymään läpi viitteet ja katsomaan, kuinka monet näistä käsitteistä voivat päteä muun tyyppisissä ML-ongelmissa.
Viitteet
Tietoja Tekijät
 Marcos on AWS Sr. Machine Learning Solutions -arkkitehti Floridassa, Yhdysvalloissa. Tässä roolissa hän on vastuussa yhdysvaltalaisten startup-organisaatioiden ohjaamisesta ja avustamisesta niiden strategiassa kohti pilvipalvelua. Hän opastaa riskien ratkaisemisessa ja koneoppimistyökuormituksen optimoinnissa. Hänellä on yli 25 vuoden kokemus teknologiasta, mukaan lukien pilviratkaisujen kehittäminen, koneoppiminen, ohjelmistokehitys ja datakeskusinfrastruktuuri.
Marcos on AWS Sr. Machine Learning Solutions -arkkitehti Floridassa, Yhdysvalloissa. Tässä roolissa hän on vastuussa yhdysvaltalaisten startup-organisaatioiden ohjaamisesta ja avustamisesta niiden strategiassa kohti pilvipalvelua. Hän opastaa riskien ratkaisemisessa ja koneoppimistyökuormituksen optimoinnissa. Hänellä on yli 25 vuoden kokemus teknologiasta, mukaan lukien pilviratkaisujen kehittäminen, koneoppiminen, ohjelmistokehitys ja datakeskusinfrastruktuuri.
 Indrajit on AWS Enterprise Sr. Solutions -arkkitehti. Roolissaan hän auttaa asiakkaita saavuttamaan liiketoimintansa tuloksia pilvipalveluiden käyttöönoton kautta. Hän suunnittelee moderneja sovellusarkkitehtuureja, jotka perustuvat mikropalveluihin, palvelimettomiin, API:ihin ja tapahtumalähtöisiin malleihin. Hän työskentelee asiakkaiden kanssa toteuttaakseen data-analytiikka- ja koneoppimistavoitteensa ottamalla käyttöön DataOps- ja MLOps-käytäntöjä ja -ratkaisuja. Indrajit puhuu säännöllisesti AWS:n julkisissa tapahtumissa, kuten huippukokouksissa ja ASEAN-työpajoissa, on julkaissut useita AWS-blogiviestejä ja kehittänyt asiakkaille suunnattuja teknisiä työpajoja, jotka keskittyvät AWS:n dataan ja koneoppimiseen.
Indrajit on AWS Enterprise Sr. Solutions -arkkitehti. Roolissaan hän auttaa asiakkaita saavuttamaan liiketoimintansa tuloksia pilvipalveluiden käyttöönoton kautta. Hän suunnittelee moderneja sovellusarkkitehtuureja, jotka perustuvat mikropalveluihin, palvelimettomiin, API:ihin ja tapahtumalähtöisiin malleihin. Hän työskentelee asiakkaiden kanssa toteuttaakseen data-analytiikka- ja koneoppimistavoitteensa ottamalla käyttöön DataOps- ja MLOps-käytäntöjä ja -ratkaisuja. Indrajit puhuu säännöllisesti AWS:n julkisissa tapahtumissa, kuten huippukokouksissa ja ASEAN-työpajoissa, on julkaissut useita AWS-blogiviestejä ja kehittänyt asiakkaille suunnattuja teknisiä työpajoja, jotka keskittyvät AWS:n dataan ja koneoppimiseen.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. Autot / sähköautot, hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- BlockOffsets. Ympäristövastuun omistuksen nykyaikaistaminen. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/is-your-model-good-a-deep-dive-into-amazon-sagemaker-canvas-advanced-metrics/
- :on
- :On
- :ei
- :missä
- 000
- 1
- 100
- 1239
- 25
- 420
- a
- kyky
- Meistä
- runsaus
- pääsy
- Tili
- tarkkuus
- tarkka
- tarkasti
- Saavuttaa
- saavutettu
- saavuttamisessa
- poikki
- toiminta
- todellinen
- todella
- lisätä
- lisä-
- lisä-
- osoite
- asianmukaisesti
- Hyväksyminen
- kehittynyt
- Jälkeen
- uudelleen
- vastaan
- algoritmit
- Kaikki
- mahdollistaa
- yksin
- jo
- Myös
- aina
- Amazon
- Amazon Sage Maker
- Amazon SageMaker Canvas
- Amazon Web Services
- määrä
- an
- analyysi
- analyytikko
- analyytikot
- Analytics
- ja
- Kaikki
- API
- Hakemus
- sovellukset
- käyttää
- lähestymistapa
- lähestymistavat
- OVAT
- ALUE
- noin
- järjestetty
- AS
- Asean
- arvioida
- arviointi
- avustaminen
- At
- attribuutteja
- automaatti
- saatavissa
- välttää
- AWS
- Akseli
- Huono
- saldot
- perustua
- Lähtötilanne
- Perusasiat
- BE
- koska
- ollut
- ennen
- alkaa
- takana
- kulissien takana
- ovat
- PARAS
- Paremmin
- välillä
- Blogi
- Blogitekstit
- sekä
- rakentaa
- Rakentaminen
- rakentaa
- liiketoiminta
- mutta
- by
- laskea
- nimeltään
- Puhelut
- CAN
- ehdokkaat
- kangas
- kaapata
- joka
- tapaus
- tapauksissa
- luokat
- keskus
- Muutokset
- ominainen
- lataus
- peritään
- maksut
- Valita
- valita
- luokka
- luokat
- luokittelu
- luokitella
- Siivous
- lähempänä
- pilvi
- pilvien hyväksyminen
- koodi
- Koodaus
- Sarake
- Pylväät
- yhdistää
- yhdistely
- Tulla
- yleisesti
- verrata
- verrattuna
- täydellinen
- täysin
- kattava
- käsitteet
- ehto
- sekaannus
- Seuraukset
- ottaen huomioon
- pitää
- sisälsi
- sisältää
- jatkaa
- edistävät
- muuntaminen
- Kulma
- korjata
- Hinta
- kallis
- kattaa
- luoda
- luotu
- Luominen
- luominen
- ratkaiseva
- käyrä
- asiakassuhde
- asiakas
- asiakkaan käyttäytyminen
- Asiakkaat
- tiedot
- tietojen analysointi
- Data Analytics
- Data Center
- Tietojen valmistelu
- tiedon laatu
- tietojenkäsittely
- tietojen tutkija
- aineistot
- päivä
- sopimus
- päätös
- päätökset
- syvä
- syväsukellus
- määritelty
- kuvata
- on kuvattu
- kuvaus
- ansaita
- mallit
- haluttu
- Detection
- kehitetty
- Kehitys
- diagnoosi
- erota
- eri
- eriyttää
- ohjata
- pohtia
- keskusteltiin
- Sairaus
- erottaa
- jaettu
- jakelu
- jaettu
- do
- ei
- ei
- tehty
- pudottamalla
- huume
- kaksi
- aikana
- kukin
- Aikaisemmin
- myöskään
- valtuudet
- mahdollistaa
- käytössä
- mahdollistaa
- kattaa
- kannustaa
- Tekniikka
- parantaa
- yritys
- yhtä
- Vastaava
- erityisesti
- olennainen
- Eetteri (ETH)
- arvioida
- arviointiin
- arviointi
- Eeva
- Jopa
- tasaisesti
- Tapahtumat
- Joka
- esimerkki
- vaihdetaan
- olemassa
- odotettu
- experience
- asiantuntemus
- asiantuntijat
- Selittää
- Selitettävyys
- selittää
- Tutkimusaineistoanalyysi
- tutkia
- f1
- helpottamaan
- tosiasia
- väärä
- Ominaisuus
- Ominaisuudet
- harvat
- lopullinen
- Vihdoin
- Löytää
- Etunimi
- Florida
- Keskittää
- keskityttiin
- seurata
- jälkeen
- varten
- muoto
- kaava
- löytyi
- jae
- petos
- petosten havaitseminen
- vilpillinen
- alkaen
- koko
- toiminnallisuus
- tulevaisuutta
- saamassa
- general
- tuottaa
- syntyy
- synnyttää
- tuottaa
- saada
- Antaa
- Go
- Tavoitteet
- hyvä
- Maa
- Kasvu
- ohjaus
- Käsittely
- Olla
- he
- raskaasti
- auttaa
- auttaa
- Korkea
- suuri riski
- korkeampi
- hänen
- historiallinen
- Miten
- Miten
- Kuitenkin
- HTML
- HTTPS
- Sadat
- Hyperparametrien viritys
- ajatus
- tunnistaa
- tunnistaa
- tunnistaminen
- if
- kuva
- kuvien
- Vaikutus
- toteuttaa
- merkitys
- tärkeä
- parantaa
- parani
- parannus
- parantaminen
- in
- Muilla
- sisältää
- sisältää
- Mukaan lukien
- virheellisesti
- kasvoi
- osoittaa
- ilmaisee
- ilmaisee
- vaikuttaneet
- tiedot
- informatiivinen
- Infrastruktuuri
- ensimmäinen
- panos
- oivaltava
- oivalluksia
- esimerkki
- vuorovaikutuksessa
- vuorovaikutteinen
- liitäntä
- tulee
- Esittelee
- esittely
- kysymykset
- IT
- SEN
- jpg
- vain
- avain
- Tietää
- tuntemus
- tunnettu
- Merkki
- tarrat
- johtaa
- johtava
- oppiminen
- jättää
- vasemmalle
- vähemmän
- pitää
- todennäköisyys
- linja
- Lista
- vähän
- log
- katso
- pois
- Matala
- alentaa
- kone
- koneoppiminen
- Enemmistö
- tehdä
- Tekeminen
- onnistui
- johto
- tapa
- monet
- matemaattinen
- Matriisi
- Maksimoida
- Saattaa..
- tarkoittaa
- mielekäs
- välineet
- mitata
- toimenpiteet
- mekanismit
- lääketieteellinen
- Tavata
- menetelmät
- metrinen
- Metrics
- microservices
- ehkä
- pöytäkirja
- harhaanjohtava
- puuttuva
- ML
- MLOps
- Puhelinnumero
- kännykkä
- malli
- mallit
- Moderni
- muokata
- lisää
- eniten
- paljon
- moninkertainen
- nimi
- Tarve
- tarvitaan
- negatiivinen
- negatiiviset
- Uusi
- Uudet ominaisuudet
- seuraava
- yön
- Ilmoitus..
- nyt
- numero
- numerot
- tarkkailla
- saada
- of
- Tarjoukset
- on
- ONE
- yhdet
- vain
- avata
- toiminta
- Optimoida
- optimoitu
- Vaihtoehdot
- or
- organisaatioiden
- alkuperäinen
- Muut
- Muuta
- meidän
- ulos
- Tulos
- tuloksiin
- yli
- oma
- sivulla
- lasi
- osa
- erityisesti
- kuviot
- osuus
- täydellinen
- suorittaa
- suorituskyky
- suoritettu
- vaihe
- puhelin
- Platon
- Platonin tietotieto
- PlatonData
- Pelaa
- soittaa
- plus
- aiheuttaa
- positiivinen
- mahdollinen
- Kirje
- Viestejä
- teho
- voimakas
- käytännöt
- Tarkkuus
- ennustaa
- ennusti
- ennustamiseen
- ennustus
- Ennusteet
- ennustaa
- valmistelu
- Valmistella
- läsnäolo
- preview
- edellinen
- todennäköisyys
- todennäköisesti
- Ongelma
- ongelmia
- prosessi
- Profiili
- voitot
- Edistyminen
- osa
- toimittaa
- tarjoaa
- tarjoamalla
- julkinen
- julkaistu
- osto
- laatu
- nopea
- nopeasti
- hinta
- raaka
- raakadata
- valmis
- reaaliaikainen
- ymmärtää
- syistä
- resepti
- ennätys
- asiakirjat
- viittaukset
- tarkoitettuja
- heijastaa
- heijastaa
- riippumatta
- säännöllisesti
- suhde
- suhteellisesti
- merkityksellinen
- jäännökset
- poistaa
- poistamalla
- Raportit
- edustus
- edustaa
- vastuullinen
- Saatu ja
- tulokset
- tulot
- liikevaihdon kasvu
- oikein
- Riski
- luja
- Rooli
- ajaa
- sagemaker
- sama
- Esimerkkitietojoukko
- näki
- skaalaus
- kohtaukset
- tiede
- Tiedemies
- tutkijat
- pisteet
- tulokset
- Osa
- nähdä
- nähneet
- näkee
- valitsemalla
- valinta
- näkemys
- Sarjat
- serverless
- palvelu
- Palvelut
- setti
- asetus
- settings
- useat
- Jaa:
- shouldnt
- näyttää
- esitetty
- Näytä
- merkittävä
- merkittävästi
- samalla lailla
- Yksinkertainen
- yksinkertaisesti
- single
- pienempiä
- So
- Tuotteemme
- ohjelmistokehitys
- ratkaisu
- Ratkaisumme
- SOLVE
- jonkin verran
- jotain
- lähde
- puhuu
- erikoistunut
- erityinen
- nopeus
- jakaa
- standardi
- Alkaa
- käynnistyksen
- Osavaltio
- tilasto
- Vaihe
- Strategia
- niin
- sopiva
- Huippukokouksissa
- vie
- ottaen
- tehtävät
- Tekninen
- tekniikat
- Elektroniikka
- tietoliikenne
- kertoa
- testi
- testit
- kuin
- että
- -
- Alue
- Perusteet
- heidän
- Niitä
- sitten
- Siellä.
- siksi
- Nämä
- ne
- asiat
- ajatella
- tätä
- ne
- kynnys
- Kautta
- aika
- Aikasarja
- että
- työkalut
- ylin
- Yhteensä
- kohti
- tp
- TPR
- Juna
- koulutettu
- koulutus
- Liiketoimet
- Muuttaa
- Muutos
- muunnokset
- muuttamassa
- muunnoksia
- totta
- Totuus
- yrittää
- kaksi
- tyypit
- varten
- ymmärtää
- ymmärtäminen
- asti
- us
- käyttää
- käyttölaukku
- käytetty
- käyttötarkoituksiin
- käyttämällä
- yleensä
- arvokas
- arvo
- arvot
- eri
- hyvin
- oli
- we
- verkko
- verkkopalvelut
- painaa
- paino
- HYVIN
- olivat
- Mitä
- kun
- joka
- vaikka
- koko
- miksi
- tulee
- with
- ilman
- toimii
- Työpajat
- olisi
- kirjoittaminen
- Väärä
- X
- vuotta
- te
- Sinun
- zephyrnet