Abstrakti
Joka päivä Robloxilla, 65.5 miljoona käyttäjää hyödyntää miljoonia kokemuksia, yhteensä 14.0 miljardia tuntia neljännesvuosittain. Tämä vuorovaikutus luo petatavun mittakaavan datajärven, jota on rikastettu analytiikkaa ja koneoppimista (ML) varten. Tietojärvemme fakta- ja ulottuvuustaulukoiden yhdistäminen vaatii resursseja, joten optimoidaksemme tämän ja vähentääksemme tietojen sekoittamista otettiin käyttöön Learned Bloom Filters [1] – älykkäät tietorakenteet, joissa käytetään ML:ää. Ennakoimalla läsnäolon nämä suodattimet leikkaavat liitostietoja huomattavasti, mikä parantaa tehokkuutta ja alentaa kustannuksia. Matkan varrella paransimme myös malliarkkitehtuuriamme ja osoitimme niiden tarjoamat merkittävät edut muistin ja prosessoritunnin vähentämisessä sekä toiminnan vakauden lisäämisessä.
esittely
Datajärvessämme faktataulukot ja datakuutiot on osioitu väliaikaisesti tehokkaan käytön takaamiseksi, kun taas ulottuvuustaulukoista tällaiset osiot puuttuvat, ja niiden yhdistäminen faktataulukoihin päivitysten aikana on resurssivaltaista. Liitoksen avainavaruutta ohjaa yhdistettävän faktataulukon ajallinen osio. Tuossa ajallisessa osiossa olevat ulottuvuusentiteetit ovat pieni osajoukko niistä, jotka ovat koko ulottuvuustietojoukossa. Tämän seurauksena suurin osa näiden liitosten sekoitetuista mittatiedoista lopulta hylätään. Tämän prosessin optimoimiseksi ja tarpeettoman sekoituksen vähentämiseksi harkitsimme sen käyttöä Bloom suodattimet erillisillä liitosnäppäimillä, mutta kohtasivat suodattimen kokoon ja muistitilanteeseen liittyviä ongelmia.
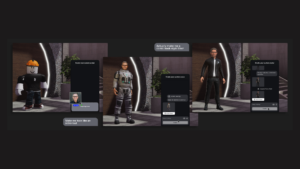
Niiden käsittelemiseksi tutkimme Oppineet Bloom-suodattimetML-pohjainen ratkaisu, joka pienentää Bloom-suodattimen kokoa säilyttäen samalla alhaiset vääriä positiivisia osia. Tämä innovaatio tehostaa join-toimintoja alentamalla laskentakustannuksia ja parantamalla järjestelmän vakautta. Seuraava kaavio havainnollistaa tavanomaisia ja optimoituja liitosprosesseja hajautetussa laskentaympäristössämme.

Paranna liitostehokkuutta opetetuilla kukintasuodattimilla
Otimme käyttöön Learned Bloom Filter -toteutuksen fakta- ja ulottuvuustaulukoiden välisen liitoksen optimoimiseksi. Rakensimme indeksin tietotaulukossa olevista avaimista ja otimme indeksin käyttöön dimensiotietojen esisuodattamiseen ennen yhdistämistoimintoa.
Evoluutio perinteisistä kukintasuodattimista opittuihin kukintasuodattimiin
Vaikka perinteinen Bloom-suodatin on tehokas, se lisää 15–25 % lisämuistia työntekijäsolmua kohden, joka joutuu lataamaan sen, jotta se saavuttaa halutun väärän positiivisuuden. Mutta käyttämällä Learned Bloom Filters -suodattimia saavutimme huomattavasti pienemmän indeksin koon säilyttäen samalla väärän positiivisen määrän. Tämä johtuu Bloom-suodattimen muuttumisesta binääriluokitteluongelmaksi. Positiiviset tunnisteet osoittavat arvojen läsnäolon indeksissä, kun taas negatiiviset tarrat tarkoittavat, että ne puuttuvat.
ML-mallin käyttöönotto helpottaa arvojen alustavaa tarkistusta, jota seuraa Bloom-varasuodatin väärien negatiivisten poistamiseksi. Pienennetty koko johtuu mallin pakatuista esityksistä ja Bloom-varasuodattimen vaatimien avainten määrästä. Tämä erottaa sen perinteisestä Bloom Filter -lähestymistavasta.
Osana tätä työtä loimme kaksi mittaria Learned Bloom Filter -lähestymistavan arvioimiseksi: indeksin lopullinen sarjoitetun objektin koko ja suorittimen kulutus liitoskyselyiden suorittamisen aikana.
Navigointi toteutuksen haasteissa
Alkuperäinen haasteemme oli käsitellä erittäin puolueellista harjoitustietojoukkoa, jossa oli muutamia ulottuvuustaulukon avaimia tietotaulukossa. Näin tehdessämme havaitsimme, että taulukoiden välillä oli noin yksi kolmesta avaimesta. Tämän ratkaisemiseksi hyödynsimme Sandwich Learned Bloom Filter -lähestymistapaa [2]. Tämä integroi alkuperäisen perinteisen Bloom-suodattimen tasapainottamaan tietojoukon jakautumista poistamalla suurimman osan faktataulukosta puuttuvista avaimista, mikä eliminoi tehokkaasti negatiiviset näytteet tietojoukosta. Myöhemmin vain alkuperäiseen Bloom Filteriin sisältyneet avaimet ja väärät positiiviset tulokset välitettiin ML-malliin, jota usein kutsutaan "oppituksi oraakkeliksi". Tämä lähestymistapa johti hyvin tasapainoiseen harjoitustietoaineistoon oppineelle oraakkelille, mikä ratkaisee harhaongelman tehokkaasti.

Toinen haaste keskittyi malliarkkitehtuuriin ja koulutusominaisuuksiin. Toisin kuin klassinen verkkourkinta-URL-osoitteiden ongelma [1], liittymisavaimemme (jotka useimmissa tapauksissa ovat käyttäjien/kokemusten yksilöllisiä tunnisteita) eivät olleet luonnostaan informatiivisia. Tämä sai meidät tutkimaan ulottuvuusattribuutteja mahdollisina mallin ominaisuuksina, jotka voivat auttaa ennustamaan, onko ulottuvuuskokonaisuus läsnä tietotaulukossa. Kuvittele esimerkiksi faktataulukko, joka sisältää käyttäjän istuntotiedot tietyn kielen kokemuksista. Käyttäjäulottuvuuden maantieteellinen sijainti tai kieliasetus on hyvä indikaattori siitä, onko yksittäinen käyttäjä läsnä tietotaulukossa vai ei.
Kolmas haaste – päätelmälatenssi – vaati malleja, jotka sekä minimoivat väärät negatiivit että tarjosivat nopeita vastauksia. Gradientilla tehostettu puumalli oli optimaalinen valinta näille keskeisille mittareille, ja karsimme sen ominaisuusjoukkoa tarkkuuden ja nopeuden tasapainottamiseksi.
Päivitetty liittymiskyselymme oppituilla Bloom-suodattimilla on seuraavanlainen:

tulokset
Tässä ovat tulokset kokeistamme Learned Bloom -suodattimilla datajärvessämme. Integroimme ne viiteen tuotantomäärään, joista jokaisella oli erilaiset dataominaisuudet. Laskennallisesti kallein osa näistä työkuormista on faktataulukon ja dimensiotaulukon välinen liitos. Faktataulukoiden avainavaruus on noin 30 % mittataulukosta. Aluksi keskustelemme siitä, kuinka Learned Bloom Filter suoritti perinteiset Bloom Filters -suodattimet lopullisen sarjoitetun objektikoon suhteen. Seuraavaksi esittelemme suorituskyvyn parannuksia, joita havaitsimme integroimalla Learned Bloom Filters -suodattimet työkuormituksen käsittelyputkiin.
Opittu Bloom-suodattimen koon vertailu
Kuten alla näytetään, kun tarkastellaan annettua väärää positiivista määrää, opitun Bloom-suodattimen kaksi muunnelmaa parantavat kohteen kokonaiskokoa 17-42 % verrattuna perinteisiin Bloom-suodattimiin.
Lisäksi, kun käytimme pienempää osajoukkoa ominaisuuksia gradienttitehostetussa puupohjaisessa mallissamme, menetimme vain pienen prosenttiosuuden optimoinnista ja nopeuttamme päättelyä.

Opitut Bloom-suodattimen käyttötulokset
Tässä osiossa vertaamme Bloom Filter -pohjaisten liitosten tehokkuutta useiden mittareiden tavallisiin liitoksiin.
Alla olevassa taulukossa verrataan työkuormien suorituskykyä Learned Bloom Filters -suodattimien kanssa ja ilman niitä. Learned Bloom Filter, jonka kokonaistodennäköisyys on 1 %, osoittaa alla olevan vertailun säilyttäen samalla saman klusterin kokoonpanon molemmille liitostyypeille.

Ensinnäkin havaitsimme, että Bloom Filter -toteutus suoritti tavallisen liitoksen jopa 60 % prosessoritunteina. Havaitsimme Learned Bloom Filter -lähestymistavan skannausvaiheen suorittimen käytön lisääntyneen Bloom-suodattimen arvioimiseen käytetyn lisälaskennan vuoksi. Tässä vaiheessa tehty esisuodatus kuitenkin pienensi sekoitettavien tietojen kokoa, mikä auttoi vähentämään jatkovaiheiden käyttämää CPU:ta, mikä vähensi prosessorin kokonaistunteja.
Toiseksi Learned Bloom Filters -suodattimilla on noin 80 % pienempi datan kokonaiskoko ja noin 80 % vähemmän kirjoitettuja sekoitustavuja kuin tavallisessa liitoksessa. Tämä johtaa vakaampaan liitossuorituskykyyn, kuten alla käsitellään.
Näimme myös vähentyneen resurssien käytön muissa kokeiluvaiheessa olevissa tuotantotyökuormissa. Kahden viikon aikana kaikilla viidellä työmäärällä Learned Bloom Filter -lähestymistapa tuotti keskiarvon päivittäisiä kustannussäästöjä of 25%, joka vastaa myös mallikoulutuksesta ja indeksien luomisesta.
Koska yhdistämisen aikana sekoitetun datan määrä väheni, pystyimme merkittävästi alentamaan analytiikkaputkistomme käyttökustannuksia samalla, kun samalla tekimme siitä vakaamman. Seuraava kaavio näyttää vaihtelua (käyttäen variaatiokerrointa) ajon kestojen (seinä) välillä. kelloaika) säännölliseen liittymistyökuormaan ja Learned Bloom Filter -pohjaiseen työmäärään kahden viikon aikana niille viidelle kokeilulle työmäärälle. Ajot, joissa käytettiin Learned Bloom Filters -suodattimia, olivat vakaampia – johdonmukaisempia kestoltaan – mikä avaa mahdollisuuden siirtää ne halvempiin ohimeneviin epäluotettaviin laskentaresursseihin.

Viitteet
[1] T. Kraska, A. Beutel, EH Chi, J. Dean ja N. Polyzotis. Opittujen indeksirakenteiden tapaus. https://arxiv.org/abs/1712.01208, 2017.
[2] M. Mitzenmacher. Opittujen kukintasuodattimien optimointi Sandwichingillä.
https://arxiv.org/abs/1803.01474, 2018.
¹ 3 päättyneeltä 30 kuukaudelta
² Kolmen kuukauden ajalta, joka päättyi 3
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://blog.roblox.com/2023/11/roblox-reduces-spark-join-query-costs-machine-learning-optimized-bloom-filters/
- :On
- :ei
- $ YLÖS
- 1
- 14
- 2017
- 2018
- 30
- 65
- a
- pystyy
- Meistä
- poissa
- pääsy
- Tilit
- saavutettu
- poikki
- Lisäksi
- lisä-
- osoite
- käsitellään
- Lisää
- hyväksytty
- Kaikki
- pitkin
- Myös
- määrä
- an
- Analytics
- ja
- lähestymistapa
- suunnilleen
- arkkitehtuuri
- OVAT
- AS
- At
- attribuutteja
- keskimäärin
- Varmuuskopiointi
- Balance
- perustua
- BE
- koska
- ennen
- alkaa
- ovat
- alle
- Hyödyt
- välillä
- puolueellisuus
- puolueellinen
- Miljardi
- Uutiset ja media
- Kukinta
- Boostatut
- sekä
- mutta
- by
- CAN
- tapaus
- tapauksissa
- keskitetty
- haaste
- ominaisuudet
- Kaavio
- halvempaa
- tarkastaa
- valinta
- klassinen
- luokittelu
- kello
- Cluster
- verrata
- verrattuna
- vertailu
- laskennallinen
- Laskea
- tietojenkäsittely
- Konfigurointi
- harkittu
- johdonmukainen
- kulutus
- sisältää
- tavanomainen
- Hinta
- kustannukset
- prosessori
- luominen
- tiedot
- Datajärvi
- päivä
- osoittivat
- osoittaa
- käyttöön
- haluttu
- eri
- Ulottuvuus
- pohtia
- keskusteltiin
- selvä
- jaettu
- hajautettu laskenta
- jakelu
- tekee
- tehty
- ajanut
- kaksi
- aikana
- e
- kukin
- tehokkaasti
- tehokkuus
- tehokas
- poistamalla
- syleili
- päättyi
- sitoutua
- Parantaa
- parantaa
- rikastettu
- Koko
- yksiköt
- kokonaisuus
- ympäristö
- vakiintunut
- arviointiin
- lopulta
- esimerkki
- teloitus
- kallis
- Elämykset
- kokeiluja
- tutkia
- tutkitaan
- kohtasi
- Helpottaa
- tosiasia
- väärä
- nopeampi
- Ominaisuus
- Ominaisuudet
- harvat
- suodattaa
- suodattimet
- lopullinen
- viisi
- seurannut
- jälkeen
- Jalanjälki
- varten
- löytyi
- alkaen
- syntyy
- synnyttää
- maantieteellinen
- tietty
- hyvä
- valjastaminen
- Olla
- auttaa
- auttanut
- erittäin
- Osuma
- TUNTIA
- Miten
- Kuitenkin
- HTTPS
- tunnisteet
- if
- havainnollistaa
- kuvitella
- täytäntöönpano
- parantaa
- parani
- parannuksia
- parantaminen
- in
- mukana
- Kasvaa
- lisää
- indeksi
- osoittaa
- indikaattorit
- henkilökohtainen
- tiedot
- informatiivinen
- luonnostaan
- ensimmäinen
- Innovaatio
- integroitu
- integroi
- Integrointi
- vuorovaikutus
- tulee
- esittely
- kysymys
- kysymykset
- IT
- SEN
- yhdistää
- liittyi
- tuloaan
- Liitosten
- kesäkuu
- avain
- avaimet
- tarrat
- Lack
- järvi
- Kieli
- Liidit
- oppinut
- oppiminen
- Led
- vähemmän
- velkarahalla
- kuormitus
- sijainti
- näköinen
- menetetty
- Matala
- kone
- koneoppiminen
- ylläpitäminen
- Enemmistö
- Tekeminen
- max-width
- tarkoittaa
- Muisti
- Metrics
- miljoona
- miljoonia
- puuttuva
- ML
- malli
- mallit
- kk
- lisää
- eniten
- liikkuvat
- paljon
- tarvitsevat
- negatiivinen
- negatiiviset
- seuraava
- solmu
- numero
- objekti
- Havaittu
- of
- kampanja
- usein
- on
- vain
- avautuu
- toiminta
- toiminta-
- Operations
- optimaalinen
- optimointi
- Optimoida
- optimoitu
- optimoimalla
- or
- oraakkeli
- Muut
- meidän
- päihitti
- yli
- voittaminen
- osa
- erityinen
- varten
- osuus
- suorituskyky
- esittävä
- aika
- Phishing
- putki
- Platon
- Platonin tietotieto
- PlatonData
- positiivinen
- mahdollisuus
- mahdollinen
- Tarkkuus
- ennustaa
- ennustamiseen
- läsnäolo
- esittää
- todennäköisyys
- Ongelma
- prosessi
- Prosessit
- käsittely
- tuotanto
- mikäli
- tarkoituksiin
- kyselyt
- nopea
- hinta
- Hinnat
- tasapainottaa
- vähentää
- Vähentynyt
- vähentää
- vähentämällä
- tarkoitettuja
- säännöllinen
- poistamalla
- edustus
- tarvitaan
- resurssi
- resursseja kuluttava
- Esittelymateriaalit
- vasteet
- johtua
- johtanut
- tulokset
- Roblox
- ajaa
- toimii
- sama
- näki
- skannata
- Toinen
- Osa
- Istunto
- setti
- useat
- näyttää
- esitetty
- Näytä
- sekoittaa
- merkittävästi
- Koko
- pieni
- pienempiä
- So
- ratkaisu
- Tila
- Kipinä
- nopeus
- käytetty
- Pysyvyys
- vakaa
- varret
- Vaihe
- Askeleet
- rakenteet
- Myöhemmin
- merkittävä
- niin
- järjestelmä
- T
- taulukko
- puuttua
- ehdot
- kuin
- että
- -
- Niitä
- Nämä
- ne
- kolmas
- tätä
- Näin
- aika
- että
- Yhteensä
- perinteinen
- koulutus
- Muutos
- puu
- kaksi
- tyypit
- varten
- unique
- toisin kuin
- päivitetty
- Päivitykset
- us
- Käyttö
- käyttää
- käytetty
- käyttäjä
- Käyttäjät
- käyttämällä
- arvot
- Seinä
- oli
- Tapa..
- we
- viikkoa
- HYVIN
- olivat
- kun
- onko
- joka
- vaikka
- wikipedia
- with
- ilman
- Referenssit
- työntekijä
- olisi
- kirjallinen
- zephyrnet