Upotukset ovat avainasemassa luonnollisen kielen käsittelyssä (NLP) ja koneoppimisessa (ML). Tekstin upottaminen viittaa prosessiin, jossa teksti muunnetaan numeerisiksi esityksiksi, jotka sijaitsevat korkeaulotteisessa vektoriavaruudessa. Tämä tekniikka saavutetaan käyttämällä ML-algoritmeja, jotka mahdollistavat datan merkityksen ja kontekstin ymmärtämisen (semanttiset suhteet) ja monimutkaisten suhteiden ja mallien oppimisen datan sisällä (syntaktiset suhteet). Voit käyttää tuloksena saatuja vektoriesityksiä monenlaisiin sovelluksiin, kuten tiedonhakuun, tekstin luokitukseen, luonnollisen kielen käsittelyyn ja moniin muihin.
Amazon Titan -tekstin upotukset on tekstin upotusmalli, joka muuntaa luonnollisen kielen tekstin – joka koostuu yksittäisistä sanoista, lauseista tai jopa suurista asiakirjoista – numeerisiksi esityksiksi, joita voidaan käyttää tehostamaan käyttötapauksia, kuten hakua, personointia ja klusterointia semanttisen samankaltaisuuden perusteella.
Tässä viestissä käsittelemme Amazon Titan Text Embeddings -mallia, sen ominaisuuksia ja esimerkkikäyttötapauksia.
Joitakin keskeisiä käsitteitä ovat:
- Tekstin numeerinen esitys (vektorit) vangitsee semantiikan ja sanojen väliset suhteet
- Rich upotuksia voidaan käyttää vertaamaan tekstin samankaltaisuutta
- Monikieliset tekstin upotukset voivat tunnistaa merkityksen eri kielillä
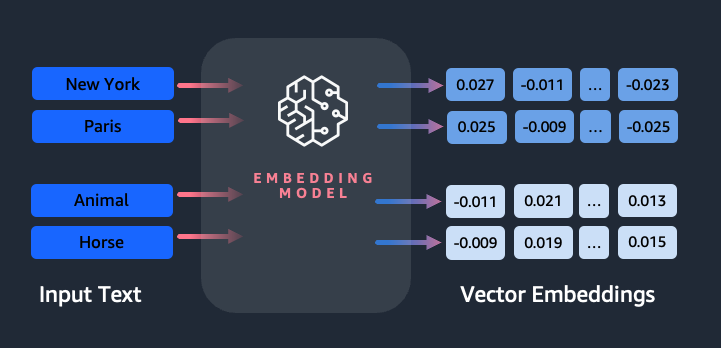
Kuinka pala tekstiä muunnetaan vektoriksi?
On olemassa useita tekniikoita lauseen muuntamiseksi vektoriksi. Eräs suosittu menetelmä on käyttää sanan upotusalgoritmeja, kuten Word2Vec, GloVe tai FastText, ja sitten yhdistää sanan upotukset muodostamaan lausetason vektoriesitys.
Toinen yleinen lähestymistapa on käyttää suuria kielimalleja (LLM), kuten BERT tai GPT, jotka voivat tarjota kontekstuaalisia upotuksia kokonaisille lauseille. Nämä mallit perustuvat syvään oppimisarkkitehtuureihin, kuten Transformers, jotka voivat vangita kontekstuaalisen tiedon ja lauseen sanojen väliset suhteet tehokkaammin.
Miksi tarvitsemme upotusmallin?
Vektori upotukset ovat tärkeitä LLM:ille, jotta he ymmärtävät kielen semanttisia asteita ja antavat LLM:ille myös mahdollisuuden suorittaa hyvin loppupään NLP-tehtäviä, kuten tunneanalyysia, nimettyjen entiteettien tunnistusta ja tekstin luokittelua.
Semanttisen haun lisäksi voit käyttää upotuksia täydentämään kehotteitasi tarkempiin tuloksiin Retrieval Augmented Generation (RAG) -toiminnon avulla, mutta käyttääksesi niitä sinun on tallennettava ne tietokantaan, jossa on vektoriominaisuudet.
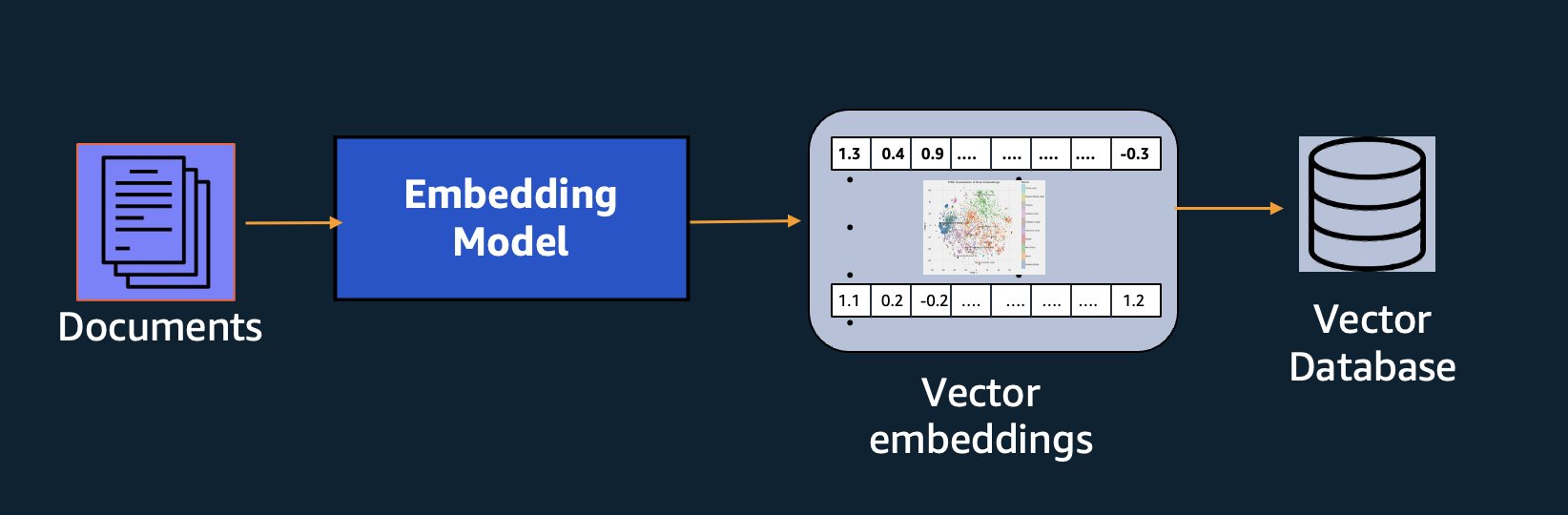
Amazon Titan Text Embeddings -malli on optimoitu tekstinhakuun mahdollistamaan RAG-käyttötapaukset. Sen avulla voit ensin muuntaa tekstitietosi numeerisiksi esityksiksi tai vektoreiksi ja käyttää sitten näitä vektoreita etsimään tarkasti asiaankuuluvia kohtia vektoritietokannasta, jolloin voit hyödyntää omaa dataasi parhaalla mahdollisella tavalla yhdessä muiden perusmallien kanssa.
Koska Amazon Titan Text Embeddings on hallittu malli Amazonin kallioperä, se tarjotaan täysin palvelimettomana kokemuksena. Voit käyttää sitä joko Amazon Bedrock RESTin kautta API tai AWS SDK. Pakolliset parametrit ovat teksti, jonka upotukset haluat luoda, ja modelID parametri, joka edustaa Amazon Titan Text Embeddings -mallin nimeä. Seuraava koodi on esimerkki Pythonin (Boto3) AWS SDK:n käyttämisestä:
Tulos näyttää jotain seuraavalta:
Mainita Amazon Bedrock boto3 -asennus saadaksesi lisätietoja tarvittavien pakettien asentamisesta muodostamalla yhteyden Amazon Bedrockiin ja käynnistämällä malleja.
Amazon Titan Text Embeddingsin ominaisuudet
Amazon Titan Text Embeddingsin avulla voit syöttää jopa 8,000 1536 merkkiä, joten se sopii hyvin yksittäisten sanojen, lauseiden tai kokonaisten asiakirjojen käsittelyyn käyttötapasi perusteella. Amazon Titan palauttaa ulostulovektorit, joiden ulottuvuus on XNUMX, mikä antaa sille suuren tarkkuuden ja optimoi samalla alhaisen latenssin ja kustannustehokkaita tuloksia.
Amazon Titan Text Embeddings tukee tekstin upotusten luomista ja kyselyitä yli 25 eri kielellä. Tämä tarkoittaa, että voit soveltaa mallia käyttötapauksiin ilman, että sinun tarvitsee luoda ja ylläpitää erillisiä malleja jokaiselle tuettavalle kielelle.
Yhden upotusmallin opettelu useilla kielillä tarjoaa seuraavat keskeiset edut:
- Laajempi kattavuus – Tukemalla yli 25 kieltä heti käyttövalmiiksi voit laajentaa sovellustesi kattavuutta käyttäjiin ja sisältöön monilla kansainvälisillä markkinoilla.
- Johdonmukainen suoritus – Useita kieliä kattavan yhtenäisen mallin avulla saat johdonmukaisia tuloksia eri kielillä sen sijaan, että optimoit kielikohtaisesti. Malli on koulutettu kokonaisvaltaisesti, jotta saat edun eri kielillä.
- Monikielinen kyselytuki – Amazon Titan Text Embeddings mahdollistaa kyselyn tekstin upottamisesta millä tahansa tuetuista kielistä. Tämä tarjoaa joustavuutta semanttisesti samanlaisen sisällön hakemiseen eri kielillä ilman, että se on rajoitettu yhteen kieleen. Voit rakentaa sovelluksia, jotka kyselevät ja analysoivat monikielistä tietoa käyttämällä samaa yhdistettyä upotustilaa.
Tätä kirjoitettaessa seuraavia kieliä tuetaan:
- Arabialainen
- Yksinkertaistettu kiina)
- Kiinalainen perinteinen)
- Tšekki
- Dutch
- Englanti
- Ranskan
- Saksan
- Heprea
- hindi
- Italian
- Japanilainen
- kannada
- Korean
- malajalam
- marathi
- Kiillottaa
- Portugalin
- Venäläinen
- Espanjan
- verkkokauppa
- filippiiniläinen tagalog
- tamil
- telugu
- turkki
Amazon Titan -tekstiupotusten käyttäminen LangChainin kanssa
LangChain on suosittu avoimen lähdekoodin kehys luovien tekoälymallien ja niitä tukevien teknologioiden parissa työskentelemiseen. Se sisältää a BedrockEmbeddings-asiakas joka kääri Boto3 SDK:n kätevästi abstraktikerroksella. The BedrockEmbeddings asiakas antaa sinun työskennellä tekstin ja upotusten kanssa suoraan tietämättä JSON-pyynnön tai vastausrakenteiden yksityiskohtia. Seuraava on yksinkertainen esimerkki:
Voit myös käyttää LangChain'sia BedrockEmbeddings asiakasta Amazon Bedrock LLM -asiakkaan rinnalla RAG:n, semanttisen haun ja muiden upotuksiin liittyvien mallien toteuttamisen yksinkertaistamiseksi.
Käytä koteloita upottamiseen
Vaikka RAG on tällä hetkellä suosituin käyttötapa upotusten kanssa työskentelemiseen, on monia muita käyttötapauksia, joissa upotuksia voidaan käyttää. Seuraavassa on joitain lisäskenaarioita, joissa voit käyttää upotuksia tiettyjen ongelmien ratkaisemiseen joko yksinään tai yhteistyössä LLM:n kanssa:
- Kysymys ja vastaus – Upotukset voivat auttaa tukemaan kysymys- ja vastausrajapintoja RAG-mallin kautta. Embeddings-sukupolvi yhdistettynä vektoritietokantaan mahdollistaa läheisten vastaavuuksien löytämisen kysymysten ja sisällön välillä tietovarastossa.
- Henkilökohtaiset suositukset – Samoin kuin kysymys ja vastaus, voit käyttää upotuksia lomakohteiden, korkeakoulujen, ajoneuvojen tai muiden tuotteiden etsimiseen käyttäjän antamien kriteerien perusteella. Tämä voi olla yksinkertaisen vastaavuusluettelon muodossa tai voit sitten käyttää LLM:tä jokaisen suosituksen käsittelemiseen ja selittää, kuinka se täyttää käyttäjän kriteerit. Voit myös käyttää tätä lähestymistapaa luodaksesi mukautettuja "10 parasta" artikkelia käyttäjälle hänen erityistarpeidensa perusteella.
- Tiedonhallinta – Jos sinulla on tietolähteitä, jotka eivät täsmää toisiinsa, mutta sinulla on tietuetta kuvaavaa tekstisisältöä, voit tunnistaa mahdolliset päällekkäiset tietueet upotusten avulla. Voit esimerkiksi käyttää upotuksia tunnistamaan päällekkäisiä ehdokkaita, jotka saattavat käyttää erilaisia muotoiluja, lyhenteitä tai jopa käännetty nimiä.
- Sovellusportfolion rationalisointi – Kun halutaan kohdistaa sovellusportfolioita emoyhtiön ja yrityskaupan välillä, ei aina ole selvää, mistä aloittaa mahdollisten päällekkäisyyksien löytäminen. Konfiguroinnin hallintatietojen laatu voi olla rajoittava tekijä, ja tiimien välinen koordinointi voi olla vaikeaa ymmärtää sovellusmaisemaa. Käyttämällä semanttista täsmäämistä upotusten kanssa, voimme tehdä nopean analyysin sovellussalkkujen välillä tunnistaaksemme korkean potentiaalin rationalisointia varten.
- Sisällön ryhmittely – Voit käyttää upotuksia helpottaaksesi samankaltaisen sisällön ryhmittelyä luokkiin, joita et ehkä tiedä etukäteen. Oletetaan esimerkiksi, että sinulla on kokoelma asiakkaiden sähköposteja tai online-tuotearvosteluja. Voit luoda upotuksia jokaiselle kohteelle ja suorittaa ne sitten läpi k- tarkoittaa klusterointia tunnistaa loogiset ryhmittelyt asiakkaiden huolenaiheista, tuotekiitoista tai -valituksista tai muista teemoista. Voit sitten luoda kohdennettuja yhteenvetoja näiden ryhmien sisällöstä LLM:n avulla.
Esimerkki semanttisesta hausta
Meidän esimerkkinä GitHubissa, esittelemme yksinkertaisen upotushakusovelluksen Amazon Titan Text Embeddingsin, LangChainin ja Streamlitin kanssa.
Esimerkki kohdistaa käyttäjän kyselyn muistissa olevan vektoritietokannan lähimpiin merkintöihin. Näytämme sitten osumat suoraan käyttöliittymässä. Tästä voi olla hyötyä, jos haluat tehdä vianmäärityksen RAG-sovelluksesta tai arvioida suoraan upotusmallia.
Käytämme yksinkertaisuuden vuoksi muistia FAISS tietokanta upotusvektoreiden tallentamiseen ja etsimiseen. Tosimaailman skenaariossa suuressa mittakaavassa haluat todennäköisesti käyttää pysyvää tietovarastoa, kuten vektorimoottori Amazon OpenSearch Serverlessille tai pgvector laajennus PostgreSQL:lle.
Kokeile muutamaa kehotetta verkkosovelluksesta eri kielillä, kuten seuraavia:
- Kuinka voin seurata käyttöäni?
- Kuinka voin mukauttaa malleja?
- Mitä ohjelmointikieliä voin käyttää?
- Kommentoi mes données sont-elles sécurisées ?
- 私のデータはどのように保護されていますか?
- Quais fornecedores de modelos estão disponíveis por meio do Bedrock?
- Onko welchenin alueella Amazon Bedrock verfügbar?
- 有哪些级别的支持?
Huomaa, että vaikka lähdemateriaali oli englanninkielinen, muilla kielillä tehdyt kyselyt yhdistettiin asiaankuuluviin merkintöihin.
Yhteenveto
Perusmallien tekstinluontimahdollisuudet ovat erittäin jännittäviä, mutta on tärkeää muistaa, että tekstin ymmärtäminen, relevantin sisällön löytäminen tietojoukosta ja yhteyksien luominen kohtien välillä ovat ratkaisevan tärkeitä generatiivisen tekoälyn täyden arvon saavuttamiseksi. Tulemme näkemään uusia ja mielenkiintoisia upotusten käyttötapauksia tulevina vuosina näiden mallien parantuessa.
Seuraavat vaiheet
Löydät lisää esimerkkejä upotuksista muistikirjoina tai esittelysovelluksina seuraavista työpajoista:
Tietoja Tekijät
 Jason Stehle on Senior Solutions Architect AWS:ssä, joka sijaitsee New Englandin alueella. Hän työskentelee asiakkaiden kanssa sovittaakseen AWS-ominaisuudet heidän suurimpiin liiketoimintahaasteisiinsa. Työn ulkopuolella hän viettää aikansa rakentaen asioita ja katsomalla sarjakuvaelokuvia perheensä kanssa.
Jason Stehle on Senior Solutions Architect AWS:ssä, joka sijaitsee New Englandin alueella. Hän työskentelee asiakkaiden kanssa sovittaakseen AWS-ominaisuudet heidän suurimpiin liiketoimintahaasteisiinsa. Työn ulkopuolella hän viettää aikansa rakentaen asioita ja katsomalla sarjakuvaelokuvia perheensä kanssa.
 Nitin Eusebius on AWS:n vanhempi yritysratkaisuarkkitehti, jolla on kokemusta ohjelmistosuunnittelusta, yritysarkkitehtuurista ja AI/ML:stä. Hän on syvästi intohimoinen luovan tekoälyn mahdollisuuksien tutkimiseen. Hän tekee yhteistyötä asiakkaiden kanssa auttaakseen heitä rakentamaan hyvin suunniteltuja sovelluksia AWS-alustalle, ja hän on omistautunut ratkaisemaan teknologian haasteita ja avustamaan heidän pilvimatkallaan.
Nitin Eusebius on AWS:n vanhempi yritysratkaisuarkkitehti, jolla on kokemusta ohjelmistosuunnittelusta, yritysarkkitehtuurista ja AI/ML:stä. Hän on syvästi intohimoinen luovan tekoälyn mahdollisuuksien tutkimiseen. Hän tekee yhteistyötä asiakkaiden kanssa auttaakseen heitä rakentamaan hyvin suunniteltuja sovelluksia AWS-alustalle, ja hän on omistautunut ratkaisemaan teknologian haasteita ja avustamaan heidän pilvimatkallaan.
 Raj Pathak on pääratkaisuarkkitehti ja tekninen neuvonantaja suurille Fortune 50 -yrityksille ja keskikokoisille rahoituspalvelulaitoksille (FSI) Kanadassa ja Yhdysvalloissa. Hän on erikoistunut koneoppimissovelluksiin, kuten generatiiviseen tekoälyyn, luonnollisen kielen käsittelyyn, älykkääseen asiakirjankäsittelyyn ja MLOps:iin.
Raj Pathak on pääratkaisuarkkitehti ja tekninen neuvonantaja suurille Fortune 50 -yrityksille ja keskikokoisille rahoituspalvelulaitoksille (FSI) Kanadassa ja Yhdysvalloissa. Hän on erikoistunut koneoppimissovelluksiin, kuten generatiiviseen tekoälyyn, luonnollisen kielen käsittelyyn, älykkääseen asiakirjankäsittelyyn ja MLOps:iin.
 Mani Khanuja on tekninen johtaja – Generative AI Specialists, kirjoittanut kirjan – Applied Machine Learning and High Performance Computing on AWS, ja hallituksen jäsen, Women in Manufacturing Education Foundation hallituksen. Hän johtaa koneoppimisprojekteja eri aloilla, kuten tietokonenäön, luonnollisen kielen käsittelyn ja generatiivisen tekoälyn aloilla. Hän auttaa asiakkaita rakentamaan, kouluttamaan ja ottamaan käyttöön suuria koneoppimismalleja mittakaavassa. Hän puhuu sisäisissä ja ulkoisissa konferensseissa, kuten Re:Invent, Women in Manufacturing West, YouTube webinaareissa ja GHC 23:ssa. Vapaa-ajallaan hän tykkää käydä pitkillä lenkillä rannalla.
Mani Khanuja on tekninen johtaja – Generative AI Specialists, kirjoittanut kirjan – Applied Machine Learning and High Performance Computing on AWS, ja hallituksen jäsen, Women in Manufacturing Education Foundation hallituksen. Hän johtaa koneoppimisprojekteja eri aloilla, kuten tietokonenäön, luonnollisen kielen käsittelyn ja generatiivisen tekoälyn aloilla. Hän auttaa asiakkaita rakentamaan, kouluttamaan ja ottamaan käyttöön suuria koneoppimismalleja mittakaavassa. Hän puhuu sisäisissä ja ulkoisissa konferensseissa, kuten Re:Invent, Women in Manufacturing West, YouTube webinaareissa ja GHC 23:ssa. Vapaa-ajallaan hän tykkää käydä pitkillä lenkillä rannalla.
 Mark Roy on AWS:n koneoppimisarkkitehti, joka auttaa asiakkaita suunnittelemaan ja rakentamaan AI/ML-ratkaisuja. Markin työ kattaa laajan valikoiman ML-käyttötapauksia, ja hänen ensisijaisena kiinnostuksena ovat tietokonenäkö, syväoppiminen ja ML:n skaalaaminen koko yrityksessä. Hän on auttanut yrityksiä monilla toimialoilla, mukaan lukien vakuutus-, rahoitus-, media- ja viihde-, terveydenhuolto, yleishyödylliset palvelut ja valmistus. Markilla on kuusi AWS-sertifikaattia, mukaan lukien ML Specialty Certification. Ennen AWS:lle tuloaan Mark oli arkkitehti, kehittäjä ja teknologiajohtaja yli 25 vuoden ajan, joista 19 vuotta rahoituspalveluissa.
Mark Roy on AWS:n koneoppimisarkkitehti, joka auttaa asiakkaita suunnittelemaan ja rakentamaan AI/ML-ratkaisuja. Markin työ kattaa laajan valikoiman ML-käyttötapauksia, ja hänen ensisijaisena kiinnostuksena ovat tietokonenäkö, syväoppiminen ja ML:n skaalaaminen koko yrityksessä. Hän on auttanut yrityksiä monilla toimialoilla, mukaan lukien vakuutus-, rahoitus-, media- ja viihde-, terveydenhuolto, yleishyödylliset palvelut ja valmistus. Markilla on kuusi AWS-sertifikaattia, mukaan lukien ML Specialty Certification. Ennen AWS:lle tuloaan Mark oli arkkitehti, kehittäjä ja teknologiajohtaja yli 25 vuoden ajan, joista 19 vuotta rahoituspalveluissa.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :on
- :On
- :ei
- :missä
- $ YLÖS
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- Meistä
- abstraktio
- Hyväksyä
- tarkkuus
- tarkka
- tarkasti
- saavutettu
- saavuttamisessa
- hankinta
- poikki
- Lisäksi
- lisä-
- Etu
- neuvonantaja
- eteenpäin
- AI
- AI-mallit
- AI / ML
- algoritmit
- kohdista
- Kaikki
- sallia
- Salliminen
- mahdollistaa
- pitkin
- rinnalla
- Myös
- aina
- Amazon
- Amazon Web Services
- an
- analyysi
- analysoida
- ja
- vastaus
- Kaikki
- Hakemus
- sovellukset
- sovellettu
- käyttää
- lähestymistapa
- arkkitehtuuri
- arkkitehtuurit
- OVAT
- ALUE
- artikkelit
- AS
- avustaminen
- At
- lisätä
- täydennetty
- kirjoittaja
- saatavissa
- AWS
- perustua
- BE
- Ranta
- ovat
- Hyödyt
- välillä
- hallitus
- hallitus
- elin
- kirja
- Laatikko
- rakentaa
- Rakentaminen
- liiketoiminta
- mutta
- by
- CAN
- Kanada
- ehdokkaat
- ehdokkaat
- kyvyt
- kaapata
- kaappaa
- tapaus
- tapauksissa
- luokat
- Certification
- sertifikaatit
- haasteet
- luokittelu
- asiakas
- lähellä
- pilvi
- klustereiden
- koodi
- kokoelma
- Korkeakoulut
- yhdistelmä
- Yhteinen
- Yritykset
- yritys
- verrata
- valitukset
- monimutkainen
- tietokone
- Tietokoneen visio
- tietojenkäsittely
- käsitteet
- huolenaiheet
- konferenssit
- Konfigurointi
- kytkeä
- liitäntä
- Liitännät
- johdonmukainen
- pitoisuus
- tausta
- asiayhteyteen
- jatkaa
- sopivasti
- muuntaa
- muunnetaan
- yhteistyö
- koordinoimalla
- kustannustehokas
- voisi
- päällyste
- kannet
- luoda
- Luominen
- kriteerit
- ratkaiseva
- Tällä hetkellä
- asiakassuhde
- asiakas
- Asiakkaat
- räätälöidä
- tiedot
- tietokanta
- de
- omistautunut
- syvä
- syvä oppiminen
- syvästi
- määritellä
- Aste
- esittely
- osoittaa
- sijoittaa
- kuvailee
- Malli
- kohteet
- yksityiskohdat
- Kehittäjä
- eri
- vaikea
- Ulottuvuus
- suoraan
- Ohjaajat
- pohtia
- näyttö
- do
- asiakirja
- asiakirjat
- verkkotunnuksia
- Dont
- kukin
- koulutus
- tehokkaasti
- myöskään
- sähköpostit
- upottamisen
- ilmaantua
- mahdollistaa
- mahdollistaa
- Moottori
- Tekniikka
- Englanti
- Englanti
- yritys
- Enterprise-ratkaisut
- Viihde
- Koko
- täysin
- kokonaisuus
- Eetteri (ETH)
- arvioida
- Jopa
- esimerkki
- Esimerkit
- jännittävä
- Laajentaa
- experience
- kokenut
- Selittää
- Tutkiminen
- laajentaminen
- ulkoinen
- helpottamaan
- tekijä
- perhe
- Ominaisuudet
- harvat
- taloudellinen
- rahoituspalvelut
- Löytää
- löytäminen
- Etunimi
- Joustavuus
- keskityttiin
- jälkeen
- varten
- muoto
- rikkaus
- perusta
- Puitteet
- Ilmainen
- alkaen
- koko
- perus-
- tuottaa
- sukupolvi
- generatiivinen
- Generatiivinen AI
- saada
- saada
- Antaminen
- käsine
- Go
- suurin
- HAD
- Olla
- he
- terveydenhuollon
- auttaa
- auttanut
- auttaa
- auttaa
- hänen
- Korkea
- High Performance Computing
- hänen
- pitää
- Miten
- Miten
- HTML
- HTTPS
- i
- tunnistaa
- if
- täytäntöönpanosta
- tuoda
- tärkeä
- parantaa
- in
- Muilla
- sisältää
- sisältää
- Mukaan lukien
- teollisuuden
- tiedot
- panos
- asentaa
- sen sijaan
- laitokset
- vakuutus
- Älykäs
- Älykäs asiakirjojen käsittely
- korko
- mielenkiintoinen
- liitäntä
- rajapinnat
- sisäinen
- kansainvälisesti
- tulee
- IT
- SEN
- tuloaan
- matka
- jpg
- json
- avain
- Tietää
- tietäen
- tuntemus
- Landschaft
- Kieli
- kielet
- suuri
- kerros
- johtaa
- johtaja
- Liidit
- oppiminen
- antaa
- pitää
- Todennäköisesti
- tykkää
- rajoittamalla
- Lista
- llm
- looginen
- Pitkät
- katso
- näköinen
- kone
- koneoppiminen
- ylläpitää
- tehdä
- Tekeminen
- onnistui
- johto
- valmistus
- monet
- kartta
- Merkitse
- Merkit
- markkinat
- Hyväksytty
- tulitikut
- matching
- materiaali
- me
- merkitys
- välineet
- Media
- jäsen
- menetelmä
- ehkä
- ML
- ML-algoritmit
- MLOps
- malli
- mallit
- monitori
- lisää
- eniten
- Suosituin
- Elokuvat
- moninkertainen
- my
- nimi
- nimetty
- nimet
- Luonnollinen
- Luonnollinen kieli
- Luonnollinen kielen käsittely
- Tarve
- tarvitsevat
- tarpeet
- Uusi
- seuraava
- NLP
- kannettavat tietokoneet
- Ilmeinen
- of
- tarjotaan
- on
- ONE
- verkossa
- avata
- avoimen lähdekoodin
- optimoitu
- optimoimalla
- or
- tilata
- Muut
- Muuta
- meidän
- ulos
- ulostulo
- ulkopuolella
- yli
- oma
- paketit
- pariksi
- parametri
- parametrit
- emoyhtiö
- kanavat
- intohimoinen
- Kuvio
- kuviot
- varten
- suorittaa
- suorituskyky
- Personointi
- lausekkeet
- kappale
- foorumi
- Platon
- Platonin tietotieto
- PlatonData
- Pelaa
- Ole hyvä
- Suosittu
- BY
- salkku
- salkut
- mahdollisuuksia
- Kirje
- PostgreSQL
- mahdollinen
- teho
- ensisijainen
- Pääasiallinen
- Painaa
- Aikaisempi
- ongelmia
- prosessi
- käsittely
- Tuotteet
- Tuotearvostelut
- Tuotteemme
- Ohjelmointi
- ohjelmointikielet
- hankkeet
- ohjeita
- patentoitu
- toimittaa
- mikäli
- tarjoaa
- Python
- laatu
- kyselyt
- kysymys
- kysymys
- kysymykset
- nopea
- rätti
- alue
- RE
- tavoittaa
- todellinen maailma
- tunnustaminen
- Suositus
- suosituksia
- ennätys
- asiakirjat
- viittaa
- Ihmissuhteet
- merkityksellinen
- muistaa
- säilytyspaikka
- edustus
- edustaa
- pyyntö
- tarvitaan
- vastaus
- REST
- rajoitettu
- Saatu ja
- tulokset
- haku
- Tuotto
- Arvostelut
- Rooli
- ajaa
- toimii
- s
- sama
- sanoa
- Asteikko
- skaalaus
- skenaario
- skenaariot
- sdk
- Haku
- nähdä
- semanttinen
- semantiikka
- vanhempi
- tuomita
- näkemys
- erillinen
- serverless
- Palvelut
- hän
- samankaltainen
- Yksinkertainen
- yksinkertaisuus
- yksinkertaistettu
- yksinkertaistaa
- single
- SIX
- So
- Tuotteemme
- ohjelmistotuotanto
- Ratkaisumme
- SOLVE
- Solving
- jonkin verran
- jotain
- lähde
- Lähteet
- Tila
- puhuu
- asiantuntijat
- erikoistunut
- Erikoisuus
- erityinen
- Alkaa
- alkoi
- Valtiot
- verkkokaupasta
- rakenteet
- niin
- tuki
- Tuetut
- Tukea
- Tukee
- ottaa
- tehtävät
- tiimit
- teknologia
- Tekninen
- tekniikka
- tekniikat
- Technologies
- Elektroniikka
- kertoa
- teksti
- Tekstiluokitus
- tekstin luominen
- että
- -
- Lähde
- heidän
- Niitä
- Teemat
- sitten
- Siellä.
- Nämä
- asiat
- tätä
- ne
- vaikka?
- Kautta
- aika
- Titaani
- että
- tokens
- perinteinen
- Juna
- koulutettu
- muuntajat
- muuttamassa
- ymmärtää
- ymmärtäminen
- yhdistynyt
- Yhtenäinen
- Yhdysvallat
- Käyttö
- käyttää
- käyttölaukku
- käytetty
- hyödyllinen
- käyttäjä
- Käyttöliittymä
- Käyttäjät
- käyttämällä
- apuohjelmia
- loma
- arvo
- eri
- Ajoneuvot
- hyvin
- kautta
- visio
- haluta
- oli
- katsomassa
- we
- verkko
- Web-sovellus
- verkkopalvelut
- Webinaarit
- HYVIN
- olivat
- Länsi
- kun
- joka
- vaikka
- leveä
- Laaja valikoima
- tulee
- with
- sisällä
- ilman
- Naiset
- sana
- sanoja
- Referenssit
- työskentely
- toimii
- Työpajat
- olisi
- kirjoittaa
- kirjoittaminen
- vuotta
- te
- Sinun
- youtube
- zephyrnet