Mis on dokumentide töötlemine?

Dokumenditöötlus on dokumentidest struktureeritud andmete väljavõtmise automatiseerimine. See võib olla mis tahes dokumendi jaoks, näiteks arve, CV, ID-kaartide jms jaoks. Väljakutsuv osa ei ole siin ainult optiline tekstituvastus. Seal on palju madalate kuludega valikuid, mis võimaldavad teksti eraldada ja asukoha määrata. Tõeline väljakutse on nende tekstiosade täpne ja automaatne sildistamine.
Dokumenditöötluse mõju ärile
Mitmed tööstusharud sõltuvad oma igapäevases tegevuses suuresti dokumentide töötlemisest. Finantsorganisatsioonid vajavad juurdepääsu SEC-i dokumentidele, kindlustusdokumentidele, e-kaubanduse või tarneahelaga tegelevatel ettevõtetel võib olla vaja juurdepääsu kasutatavatele arvetele, loetelu jätkub. Selle teabe täpsus on sama oluline kui aja kokkuhoid, mistõttu soovitame alati kasutada täiustatud süvaõppe meetodeid, mis üldistavad rohkem ja on täpsemad.
Selle PwC aruande kohaselt [link] isegi kõige algelisema mahuga struktureeritud andmete eraldamine võib aidata säästa 30–50% töötajate ajast, mis kulub PDF-failidest andmete käsitsi kopeerimisele ja kleepimisele Exceli arvutustabelitesse. Sellised mudelid nagu LayoutLM ei ole kindlasti algelised, need on loodud äärmiselt intelligentsete agentidena, mis on võimelised erinevatel kasutusjuhtudel mastaabis täpselt andmeid eraldama. Isegi paljude oma klientide puhul oleme vähendanud andmete käsitsi väljavõtmiseks kuluvat aega 20 minutilt dokumendi kohta alla 10 sekundini. See on tohutu nihe, mis võimaldab töötajatel olla tootlikumad ja suurendada üldist läbilaskevõimet.
Niisiis, kus saab LayoutLM-iga sarnast tehisintellekti rakendada? Oleme Nanonetsis sellist tehnoloogiat kasutanud
- Arvete töötlemise automatiseerimine
- Tabeliandmete ekstraheerimine
- Vormiandmete ekstraheerimine
- Jätkake parsimist
ja palju muid kasutusjuhtumeid.
Miks LayoutLM?
Kuidas saab süvaõppemudel aru, kas antud tekstiosa on arve kaubakirjeldus või arve number? Lihtsamalt öeldes, kuidas mudel õpib silte õigesti määrama?
Üks meetod on kasutada teksti manustamist massilisest keelemudelist, nagu BERT või GPT-3, ja käivitada see läbi klassifikaatori – kuigi see pole kuigi tõhus. Seal on palju teavet, mida ei saa ainult teksti abil hinnata. Või võiks kasutada pildipõhist teavet. See saavutati R-CNN ja Faster R-CNN mudelite abil. See ei kasuta siiski täielikult ära dokumentides sisalduvat teavet. Teine lähenemisviis, mida kasutati, oli Graph Convolutional Neural Networks, mis kombineeris nii asukoha- kui ka tekstiteavet, kuid ei võtnud pilditeavet arvesse.
Kuidas siis kasutada kõiki kolme informatsiooni mõõdet ehk teksti, pilti ja antud teksti asukohta ka? Siin tulevadki kasutusele sellised mudelid nagu LayoutLM. Hoolimata sellest, et LayoutLM oli aastaid varem aktiivne uurimisvaldkond, oli LayoutLM üks esimesi mudeleid, mis saavutas edu, ühendades need osad ainsusmudeli loomisel, mis teostab märgistamist asukohateabe, tekstipõhise teabe, ja ka pildiinfot.
LayoutLM-i õpetus
See artikkel eeldab, et saate aru, mis on keelemudel. Kui ei, siis ära muretse, kirjutasime ka sellest artikli! Kui soovite rohkem teada saada, millised on trafomudelid ja millele tähelepanu pööratakse, siis siin on Jay Alammari hämmastav artikkel.
Eeldades, et oleme need asjad teelt välja saanud, alustame õpetusega. Peamise viitena kasutame algset LayoutLM-i paberit.
OCR-teksti ekstraheerimine
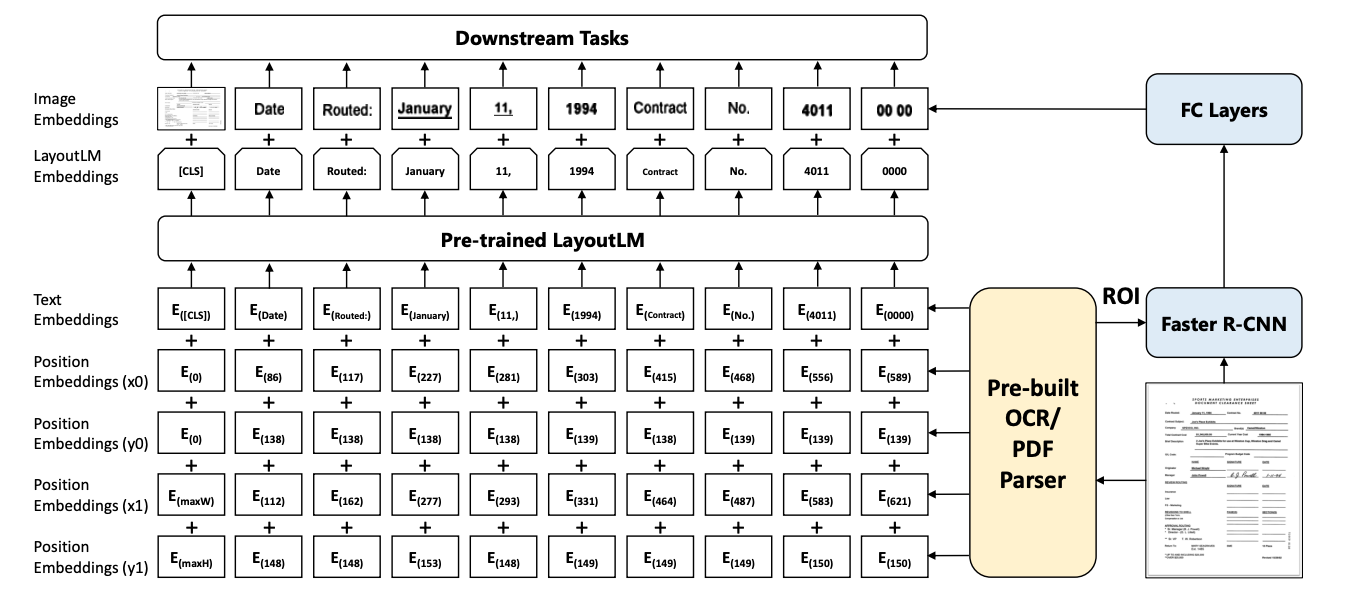
Kõige esimene asi, mida me dokumendiga teeme, on dokumendist tekstipõhise teabe eraldamine ja nende vastavate asukohtade leidmine. Asukoha järgi viitame millelegi, mida nimetatakse "piirdekastiks". Piirdekast on ristkülik, mis kapseldab lehel oleva tekstiosa.

Enamasti eeldatakse, et piirdekasti alguspunkt on vasakus ülanurgas ja positiivne x-telg on suunatud alguspunktist lehe paremale poole ja positiivne y-telg on suunatud lähtepunktist lehe allosas, kusjuures mõõtühikuks loetakse ühte pikslit.
Keele ja asukoha manused
Järgmisena kasutame viit erinevat manustamiskihti. Üks on keelega seotud teabe – st teksti manustamise – kodeerimine.
Ülejäänud neli on reserveeritud asukoha manustamiseks. Eeldades, et teame xmin, ymin, xmax ja ymax väärtused, saame määrata kogu piirdekasti (kui te ei suuda seda ette kujutada, siin on sulle link). Need koordinaadid edastatakse asukohateabe kodeerimiseks nende vastavate manustamiskihtide kaudu.
Seejärel liidetakse viis manustamist – üks teksti ja neli koordinaatide jaoks –, et luua LayoutLM-i kaudu edastatava manustamise lõplik väärtus. Väljundit nimetatakse paigutusLM-i manustamiseks.
Piltide manustamine
Olgu, meil õnnestus leida teksti ja asukohaga seotud teave, kombineerides nende manuseid ja edastades selle keelemudeli kaudu. Kuidas me nüüd pildiga seotud teabe kombineerimise protsessist mööda läheme?
Teksti ja paigutuse teabe kodeerimise ajal kasutame paralleelselt funktsiooni Faster R-CNN, et eraldada dokumendiga seotud tekstipiirkonnad. Kiirem R-CNN on pildimudel, mida kasutatakse objektide tuvastamiseks. Meie puhul kasutame seda erinevate tekstiosade tuvastamiseks (eeldusel, et iga fraas on objekt) ja seejärel edastame segmenteeritud pildid läbi täielikult ühendatud kihi, et aidata luua ka kujutiste manuseid.
LayoutLM-i ja kujutiste manustused kombineeritakse lõpliku manustamise loomiseks, mida saab seejärel kasutada allavoolu töötlemiseks.
Eelkoolitus LayoutLM
Kõik ülaltoodu on mõttekas ainult siis, kui mõistame meetodit, mille järgi LayoutLM koolitati. Lõppude lõpuks, olenemata sellest, milliseid ühendusi me närvivõrgus loome, kuni ja välja arvatud juhul, kui seda koolitatakse õige õpieesmärgiga, pole see päris tark. LayoutLM-i autorid soovisid kasutada meetodit, mis on sarnane sellele, mida kasutati BERTi eelkoolituse jaoks.
Maskeeritud visuaalse keele mudel (MVLM)
Et aidata mudelil teada saada, milline tekst võis teatud kohas olla, maskeerisid autorid juhuslikult mõned tekstimärgid, säilitades samas asukohaga seotud teabe ja manustused. See võimaldas LayoutLM-il minna kaugemale lihtsast maskeeritud keele modelleerimisest ja aitas seostada teksti manustamist ka asukohaga seotud meetoditega.
Mitme sildiga dokumentide klassifikatsioon (MDC)
Kogu dokumendis sisalduva teabe kasutamine selle kategooriatesse liigitamiseks aitab mudelil mõista, milline teave on teatud dokumendiklassi jaoks asjakohane. Autorid märgivad aga, et suuremate andmekogumite puhul ei pruugi dokumendiklasside andmed olla kergesti kättesaadavad. Seega on nad pakkunud tulemuste baasi nii MVLM-i kui ka MVLM + MDC koolitusi.
LayoutLM peenhäälestus allavoolu ülesannete jaoks
LayoutLM-iga saab täita mitmeid allavoolu ülesandeid. Arutleme nende üle, mille autorid ette võtsid.
Vormi mõistmine
See ülesanne hõlmab silditüübi linkimist antud tekstiosaga. Seda kasutades saame struktureeritud andmeid ekstraheerida mis tahes tüüpi dokumentidest. Arvestades lõplikku väljundit, st LayouLM-i manustamist + kujutise manustamist, lastakse need läbi täielikult ühendatud kihi ja seejärel läbi softmaxi, et ennustada antud tekstiosa sildi klassi tõenäosusi.
Kviitungi mõistmine
Selle ülesande puhul jäeti kviitungitel mitu teabepesa tühjaks ja mudel pidi tekstilõigud nende vastavatesse pesadesse õigesti positsioneerima.
Dokumendi kujutise klassifikatsioon
Teave dokumendi tekstist ja pildist on kombineeritud, et aidata mõista dokumendi klassi, viies selle lihtsalt läbi softmaxi kihi.
Huggingface LayoutLM
Üks peamisi põhjusi, miks LayoutLM-i nii palju arutatakse, on see, et mudel oli mõnda aega tagasi avatud lähtekoodiga. see on saadaval Hugging Face'is, seega on LayoutLM-i kasutamine nüüd oluliselt lihtsam.
Enne kui sukeldume üksikasjalikult, kuidas saate LayoutLM-i oma vajadustele kohandada, tuleb arvestada mõne asjaga.
Teekide installimine
LayoutLM-i käitamiseks vajate Hugging Face'i trafoteeki, mis omakorda sõltub PyTorchi teegist. Nende installimiseks (kui pole veel installitud), käivitage järgmised käsud
Piirdekastidel
Ühtse manustamisskeemi loomiseks olenemata pildi suurusest normaliseeritakse piirdekasti koordinaadid skaalal 1000
konfiguratsioon
Kasutades klassi transformers.LayoutLMConfig, saate määrata mudeli suuruse nii, et see vastaks teie vajadustele kõige paremini, kuna need mudelid on tavaliselt rasked ja vajavad üsna vähe arvutusvõimsust. Väiksema mudeli seadistamine võib aidata teil seda kohapeal käitada. Sa saad Lisateavet klassi kohta leiate siit.
LayoutLM dokumentide klassifitseerimiseks (on siin)
Kui soovid teostada dokumentide klassifitseerimist, on sul vaja klassitrafosid.LayoutLMForSequenceClassification. See jada on välja võetud dokumendist tekstijada. Siin on Hugging Face.co väike koodinäidis, mis selgitab, kuidas seda kasutada
LayoutLM teksti märgistamiseks (on siin)
Semantilise märgistamise teostamiseks, st erinevatele tekstiosadele dokumendis siltide määramiseks vajate klassi transformers.LayoutLMForTokenClassification. Lisateavet leiate aadressilt sama siin.Siin on väike koodinäidis, et näha, kuidas see teie jaoks toimib
Mõned näpunäited kallistamise näo paigutuse LM kohta
- Praegu kasutab Hugging Face LayoutLM-mudel teksti ekstraheerimiseks avatud lähtekoodiga teeki Tesseract, mis pole kuigi täpne. Võib-olla soovite kaaluda mõne muu tasulise OCR-tööriista (nt AWS Textract või Google Cloud Vision) kasutamist
- Olemasolev mudel pakub ainult keelemudelit, st LayoutLM-i manuseid, mitte aga lõplikke kihte, mis kombineerivad visuaalseid funktsioone. LayoutLMv2 (arutatakse järgmises jaotises) kasutab Detectroni teeki, et võimaldada ka visuaalsete funktsioonide manustamist.
- Siltide klassifitseerimine toimub sõna tasemel, nii et OCR-i teksti ekstraheerimismootori ülesanne on tagada, et kõik väljal olevad sõnad oleksid pidevas järjestuses või ühe välja võib ennustada kahena.
PaigutusLMv2
LayoutLM tuli revolutsioonina dokumentidest andmete eraldamises. Mis aga puudutab süvaõppe uurimist, siis mudelid aja jooksul ainult paranevad. LayoutLM-ile järgnes sarnaselt LayoutLMv2, kus autorid tegid mudeli koolitamises mõned olulised muudatused.
Sealhulgas 1-D ruumilised manused ja visuaalsete märgide manustused
LayoutLMv2 sisaldas teavet 1-D suhtelise asukoha kohta, samuti üldist pildiga seotud teavet. Selle tähtsuse põhjuseks on uued koolituseesmärgid, mida me nüüd arutame
Uued koolituseesmärgid
LayoutLMv2 sisaldas mõningaid muudetud koolituseesmärke. Need on järgmised:
- Maskeeritud visuaalse keele modelleerimine: see on sama, mis LayoutLM-is
- Teksti kujutise joondamine: tekst kaeti pildilt juhuslikult, samal ajal kui mudelile anti tekstimärgid. Iga märgi puhul pidi mudel õppima, kas antud tekst on kaetud või mitte. Selle kaudu suutis mudel kombineerida teavet nii visuaalsest kui ka tekstilisest modaalsusest
- Teksti kujutise sobitamine: mudelil palutakse kontrollida, kas antud pilt vastab antud tekstile. Negatiivseid proove söödetakse valekujutistena või kujutiste manuseid ei pakuta üldse. Seda tehakse selleks, et mudel saaks rohkem teada, kuidas tekst ja pildid on omavahel seotud.
Kasutades neid uusi meetodeid ja manuseid, suutis mudel LayoutLM-ina saavutada peaaegu kõigis testiandmekogumites kõrgemad F1-skoorid.
- MEIST
- juurdepääs
- konto
- täpne
- saavutada
- üle
- aktiivne
- edasijõudnud
- ained
- AI
- Materjal: BPA ja flataatide vaba plastik
- juba
- Kuigi
- summa
- Teine
- lähenemine
- PIIRKOND
- ümber
- artikkel
- autorid
- saadaval
- AWS
- alus
- on
- BEST
- Natuke
- Kast
- Kaardid
- juhtudel
- väljakutse
- klassifikatsioon
- Cloud
- kood
- kombineeritud
- ettevõte
- Arvutama
- konfiguratsioon
- Side
- tasu
- kulud
- võiks
- Kliendid
- andmed
- päev
- Vaatamata
- Detection
- DID
- erinev
- dokumendid
- alla
- e-kaubandus
- Tõhus
- võimaldades
- looma
- Excel
- nägu
- kiiremini
- tunnusjoon
- FUNKTSIOONID
- Toidetud
- finants-
- esimene
- Järel
- tekitama
- GitHub
- aitama
- aitab
- siin
- Kuidas
- Kuidas
- HTTPS
- pilt
- mõju
- oluline
- parandama
- lisatud
- tööstusharudes
- info
- kindlustus
- Intelligentne
- IT
- märgistamine
- Labels
- keel
- suurem
- Õppida
- õppimine
- Tase
- Raamatukogu
- LINK
- nimekiri
- kohapeal
- liising
- kohad
- käsitsi
- suur
- sobitamine
- küsimus
- mudel
- mudelid
- kõige
- võrk
- võrgustikud
- avatud
- avatud lähtekoodiga
- Operations
- Valikud
- et
- organisatsioonid
- Muu
- makstud
- Paber
- tükk
- võim
- protsess
- annab
- PWC
- põhjustel
- soovitama
- aru
- nõutav
- Nõuded
- teadustöö
- Tulemused
- Jätka
- jooks
- Skaala
- kava
- SEC
- tunne
- komplekt
- kehtestamine
- suunata
- märkimisväärne
- sarnane
- lihtne
- SUURUS
- väike
- nutikas
- So
- midagi
- alustatud
- edu
- varustama
- tarneahelas
- ülesanded
- Tehnoloogia
- test
- Läbi
- aeg
- sümboolne
- märgid
- ülemine
- koolitus
- mõistma
- kasutama
- ära kasutama
- väärtus
- M
- kas
- sõnad
- Töö
- töötajate
- aastat