Amazon SageMaker-Studio bietet Datenwissenschaftlern eine vollständig verwaltete Lösung zum interaktiven Erstellen, Trainieren und Bereitstellen von Modellen für maschinelles Lernen (ML). Amazon SageMaker Notebook-Jobs Ermöglichen Sie Datenwissenschaftlern, ihre Notebooks nach Bedarf oder nach einem Zeitplan mit wenigen Klicks in SageMaker Studio auszuführen. Mit dieser Einführung können Sie Notebooks mithilfe der von bereitgestellten APIs programmgesteuert als Jobs ausführen Amazon SageMaker-Pipelines, die ML-Workflow-Orchestrierungsfunktion von Amazon Sage Maker. Darüber hinaus können Sie mithilfe dieser APIs einen mehrstufigen ML-Workflow mit mehreren abhängigen Notebooks erstellen.
SageMaker Pipelines ist ein natives Workflow-Orchestrierungstool zum Erstellen von ML-Pipelines, die die Vorteile der direkten SageMaker-Integration nutzen. Jede SageMaker-Pipeline besteht aus Schritte, die einzelnen Aufgaben wie der Verarbeitung, Schulung oder Datenverarbeitung unter Verwendung entsprechen Amazon EMR. SageMaker-Notebook-Jobs sind jetzt als integrierter Schritttyp in SageMaker-Pipelines verfügbar. Mit diesem Notebook-Jobschritt können Sie Notebooks mit nur wenigen Codezeilen ganz einfach als Jobs ausführen Amazon SageMaker Python-SDK. Darüber hinaus können Sie mehrere abhängige Notizbücher zusammenfügen, um einen Workflow in Form von gerichteten azyklischen Diagrammen (DAGs) zu erstellen. Anschließend können Sie diese Notebook-Jobs oder DAGs ausführen und sie mit SageMaker Studio verwalten und visualisieren.
Datenwissenschaftler verwenden derzeit SageMaker Studio, um ihre Jupyter-Notebooks interaktiv zu entwickeln und verwenden dann SageMaker-Notebook-Jobs, um diese Notebooks als geplante Jobs auszuführen. Diese Jobs können sofort oder nach einem wiederkehrenden Zeitplan ausgeführt werden, ohne dass Datenarbeiter den Code als Python-Module umgestalten müssen. Zu den häufigsten Anwendungsfällen hierfür gehören:
- Laufende Langzeit-Notebooks im Hintergrund
- Regelmäßig ausgeführte Modellinferenz zum Generieren von Berichten
- Skalierung von der Vorbereitung kleiner Beispieldatensätze bis zur Arbeit mit Big Data im Petabyte-Bereich
- Umschulen und Bereitstellen von Modellen mit einer gewissen Kadenz
- Planen von Jobs zur Überwachung der Modellqualität oder Datendrift
- Erkundung des Parameterraums für bessere Modelle
Obwohl diese Funktionalität es Datenarbeitern erleichtert, eigenständige Notebooks zu automatisieren, bestehen ML-Workflows häufig aus mehreren Notebooks, die jeweils eine bestimmte Aufgabe mit komplexen Abhängigkeiten ausführen. Beispielsweise sollte ein Notebook, das die Abweichung von Modelldaten überwacht, über einen Vorschritt verfügen, der das Extrahieren, Transformieren und Laden (ETL) sowie die Verarbeitung neuer Daten ermöglicht, sowie über einen Nachschritt zur Modellaktualisierung und zum Training für den Fall, dass eine erhebliche Abweichung festgestellt wird . Darüber hinaus möchten Datenwissenschaftler möglicherweise diesen gesamten Workflow nach einem wiederkehrenden Zeitplan auslösen, um das Modell auf der Grundlage neuer Daten zu aktualisieren. Damit Sie Ihre Notizbücher einfach automatisieren und solch komplexe Arbeitsabläufe erstellen können, sind SageMaker-Notizbuchjobs jetzt als Schritt in SageMaker Pipelines verfügbar. In diesem Beitrag zeigen wir, wie Sie mit wenigen Codezeilen folgende Anwendungsfälle lösen können:
- Führen Sie ein eigenständiges Notebook programmgesteuert sofort oder nach einem wiederkehrenden Zeitplan aus
- Erstellen Sie mehrstufige Workflows von Notebooks als DAGs für Zwecke der kontinuierlichen Integration und kontinuierlichen Bereitstellung (CI/CD), die über die Benutzeroberfläche von SageMaker Studio verwaltet werden können
Lösungsüberblick
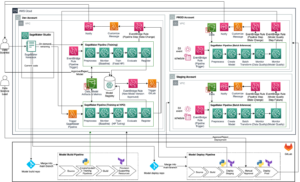
Das folgende Diagramm veranschaulicht unsere Lösungsarchitektur. Sie können das SageMaker Python SDK verwenden, um einen einzelnen Notebook-Job oder einen Workflow auszuführen. Diese Funktion erstellt einen SageMaker-Trainingsauftrag zum Ausführen des Notebooks.
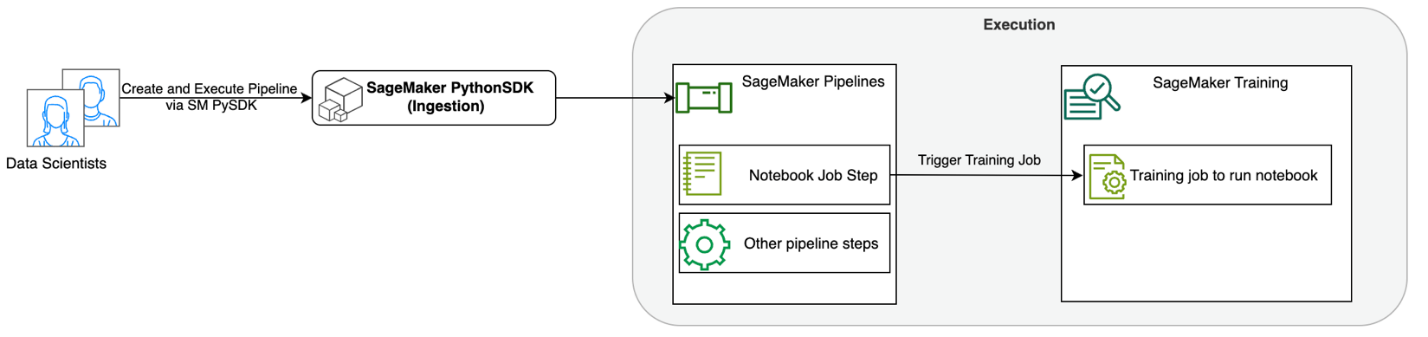
In den folgenden Abschnitten gehen wir einen Beispiel-ML-Anwendungsfall durch und zeigen die Schritte zum Erstellen eines Workflows von Notebook-Jobs, zum Übergeben von Parametern zwischen verschiedenen Notebook-Schritten, zum Planen Ihres Workflows und zum Überwachen über SageMaker Studio.
Für unser ML-Problem in diesem Beispiel erstellen wir ein Stimmungsanalysemodell, eine Art Textklassifizierungsaufgabe. Zu den häufigsten Anwendungen der Stimmungsanalyse gehören die Überwachung sozialer Medien, das Kundensupport-Management und die Analyse von Kundenfeedback. Der in diesem Beispiel verwendete Datensatz ist der Stanford Sentiment Treebank (SST2)-Datensatz, der aus Filmrezensionen sowie einer Ganzzahl (0 oder 1) besteht, die die positive oder negative Stimmung der Rezension angibt.
Das Folgende ist ein Beispiel für a data.csv Datei, die dem SST2-Datensatz entspricht, und zeigt Werte in den ersten beiden Spalten an. Beachten Sie, dass die Datei keinen Header haben sollte.
| Column 1 | Column 2 |
| 0 | neue Sekrete vor den Elterneinheiten verstecken |
| 0 | enthält keinen Witz, nur ausgeklügelte Gags |
| 1 | der seine Charaktere liebt und etwas ziemlich Schönes über die menschliche Natur vermittelt |
| 0 | bleibt vollkommen zufrieden damit, durchweg gleich zu bleiben |
| 0 | auf die schlimmsten Rache-der-Nerds-Klischees, die die Filmemacher ausbaggern konnten |
| 0 | das ist viel zu tragisch, um eine so oberflächliche Behandlung zu verdienen |
| 1 | beweist, dass der Regisseur von Hollywood-Blockbustern wie Patriot Games immer noch einen kleinen, persönlichen Film mit emotionaler Wucht drehen kann. |
In diesem ML-Beispiel müssen wir mehrere Aufgaben ausführen:
- Führen Sie Feature Engineering durch, um diesen Datensatz in einem Format vorzubereiten, das unser Modell verstehen kann.
- Führen Sie nach dem Feature-Engineering einen Trainingsschritt aus, der Transformers verwendet.
- Richten Sie Batch-Inferenz mit dem fein abgestimmten Modell ein, um die Stimmung für neu eingehende Bewertungen vorherzusagen.
- Richten Sie einen Datenüberwachungsschritt ein, damit wir unsere neuen Daten regelmäßig auf Qualitätsabweichungen überwachen können, die möglicherweise eine Neuschulung der Modellgewichte erforderlich machen.
Mit diesem Start eines Notebook-Jobs als Schritt in SageMaker-Pipelines können wir diesen Workflow orchestrieren, der aus drei verschiedenen Schritten besteht. Jeder Schritt des Workflows wird in einem anderen Notebook entwickelt, das dann in unabhängige Notebook-Auftragsschritte umgewandelt und als Pipeline verbunden wird:
- Anarbeitung – Laden Sie den öffentlichen SST2-Datensatz herunter von Amazon Simple Storage-Service (Amazon S3) und erstellen Sie eine CSV-Datei für die Ausführung des Notebooks in Schritt 2. Der SST2-Datensatz ist ein Textklassifizierungsdatensatz mit zwei Beschriftungen (0 und 1) und einer Textspalte zur Kategorisierung.
- Ausbildung – Nehmen Sie die geformte CSV-Datei und führen Sie mithilfe von Transformers-Bibliotheken eine Feinabstimmung mit BERT für die Textklassifizierung durch. Als Teil dieses Schritts verwenden wir ein Testdatenvorbereitungsnotizbuch, das eine Abhängigkeit für den Feinabstimmungs- und Batch-Inferenzschritt darstellt. Wenn die Feinabstimmung abgeschlossen ist, wird dieses Notebook mit Run Magic ausgeführt und bereitet einen Testdatensatz für die Beispielinferenz mit dem feinabgestimmten Modell vor.
- Transformieren und überwachen – Führen Sie eine Batch-Inferenz durch und richten Sie die Datenqualität mit Modellüberwachung ein, um einen Basisdatensatzvorschlag zu erhalten.
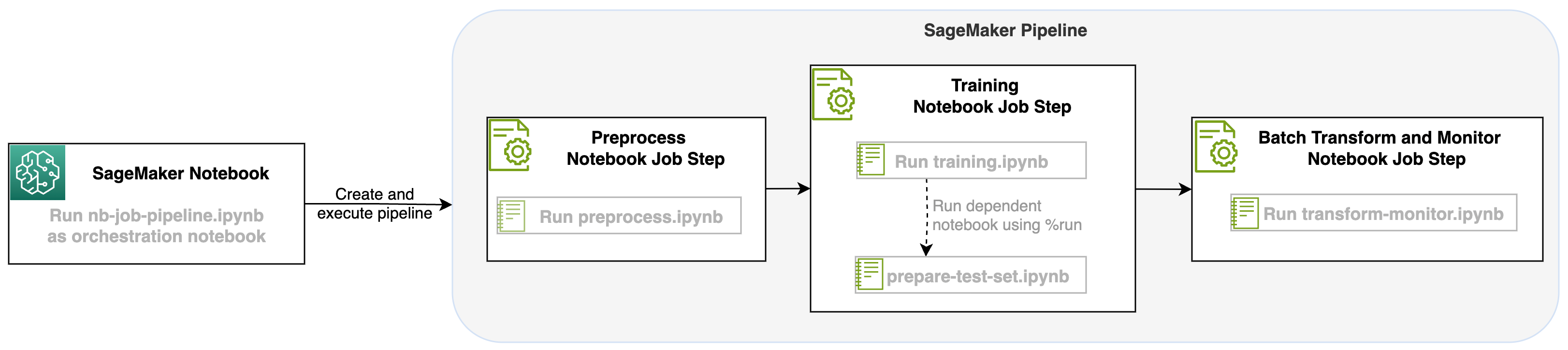
Führen Sie die Notebooks aus
Der Beispielcode für diese Lösung ist verfügbar unter GitHub.
Das Erstellen eines SageMaker-Notebook-Jobschritts ähnelt dem Erstellen anderer SageMaker-Pipeline-Schritte. In diesem Notebook-Beispiel verwenden wir das SageMaker Python SDK, um den Workflow zu orchestrieren. Um einen Notebook-Schritt in SageMaker Pipelines zu erstellen, können Sie die folgenden Parameter definieren:
- Eingabenotizbuch – Der Name des Notizbuchs, das dieser Notizbuchschritt orchestriert. Hier können Sie den lokalen Pfad zum Eingabenotizbuch übergeben. Wenn dieses Notebook über andere Notebooks verfügt, die es ausführt, können Sie diese optional im übergeben
AdditionalDependenciesParameter für den Notebook-Jobschritt. - Bild-URI – Das Docker-Image hinter dem Notebook-Jobschritt. Dies können die vordefinierten Bilder sein, die SageMaker bereits bereitstellt, oder ein benutzerdefiniertes Bild, das Sie definiert und per Push übertragen haben Amazon Elastic Container-Registrierung (Amazon ECR). Informationen zu unterstützten Bildern finden Sie im Abschnitt „Überlegungen“ am Ende dieses Beitrags.
- Kernelname – Der Name des Kernels, den Sie in SageMaker Studio verwenden. Diese Kernel-Spezifikation ist in dem von Ihnen bereitgestellten Image registriert.
- Instanztyp (optional) - Die Amazon Elastic Compute-Cloud (Amazon EC2)-Instanztyp hinter dem Notebook-Job, den Sie definiert haben und der ausgeführt werden soll.
- Parameter (optional) – Parameter, die Sie übergeben können und die für Ihr Notebook zugänglich sind. Diese können in Schlüssel-Wert-Paaren definiert werden. Darüber hinaus können diese Parameter zwischen verschiedenen Notebook-Job- oder Pipeline-Läufen geändert werden.
Unser Beispiel verfügt über insgesamt fünf Notizbücher:
- nb-job-pipeline.ipynb – Dies ist unser Hauptnotizbuch, in dem wir unsere Pipeline und unseren Workflow definieren.
- preprocess.ipynb – Dieses Notizbuch ist der erste Schritt in unserem Workflow und enthält den Code, der den öffentlichen AWS-Datensatz abruft und daraus eine CSV-Datei erstellt.
- training.ipynb – Dieses Notizbuch ist der zweite Schritt in unserem Workflow und enthält Code, um die CSV-Datei aus dem vorherigen Schritt zu übernehmen und lokale Schulungen und Feinabstimmungen durchzuführen. Dieser Schritt hat auch eine Abhängigkeit von der
prepare-test-set.ipynbNotebook, um einen Testdatensatz für die Stichprobeninferenz mit dem fein abgestimmten Modell abzurufen. - Prepare-test-set.ipynb – Dieses Notizbuch erstellt einen Testdatensatz, den unser Trainingsnotizbuch im zweiten Pipeline-Schritt verwendet und für die Stichprobeninferenz mit dem fein abgestimmten Modell verwendet.
- transform-monitor.ipynb – Dieses Notebook ist der dritte Schritt in unserem Workflow und verwendet das BERT-Basismodell und führt einen SageMaker-Batch-Transformationsauftrag aus, während es gleichzeitig die Datenqualität mit Modellüberwachung einrichtet.
Als nächstes gehen wir das Hauptnotizbuch durch nb-job-pipeline.ipynb, das alle Sub-Notebooks in einer Pipeline zusammenfasst und den End-to-End-Workflow ausführt. Beachten Sie, dass das folgende Beispiel das Notebook zwar nur einmal ausführt, Sie die Pipeline jedoch auch so planen können, dass das Notebook wiederholt ausgeführt wird. Beziehen auf SageMaker-Dokumentation Detaillierte Anweisungen.
Für unseren ersten Notebook-Jobschritt übergeben wir einen Parameter mit einem Standard-S3-Bucket. Mit diesem Bucket können wir alle Artefakte sichern, die für unsere anderen Pipeline-Schritte verfügbar sein sollen. Für das erste Notizbuch (preprocess.ipynb) ziehen wir den öffentlichen SST2-Zugdatensatz von AWS herunter und erstellen daraus eine Trainings-CSV-Datei, die wir in diesen S3-Bucket übertragen. Siehe den folgenden Code:
Wir können dieses Notebook dann in ein umwandeln NotebookJobStep mit dem folgenden Code in unserem Hauptnotizbuch:
Da wir nun eine CSV-Beispieldatei haben, können wir mit dem Training unseres Modells in unserem Trainingsnotizbuch beginnen. Unser Trainingsnotizbuch übernimmt denselben Parameter wie der S3-Bucket und ruft den Trainingsdatensatz von diesem Speicherort ab. Anschließend führen wir eine Feinabstimmung durch, indem wir das Transformers-Trainerobjekt mit dem folgenden Codeausschnitt verwenden:
Nach der Feinabstimmung möchten wir eine Batch-Inferenz ausführen, um zu sehen, wie das Modell funktioniert. Dies erfolgt über ein separates Notebook (prepare-test-set.ipynb) im selben lokalen Pfad, der einen Testdatensatz erstellt, um Rückschlüsse auf die Verwendung unseres trainierten Modells zu ziehen. Das Zusatznotizbuch können wir in unserem Schulungsnotizbuch mit folgender Zauberzelle betreiben:
Wir definieren diese zusätzliche Notebook-Abhängigkeit im AdditionalDependencies Parameter in unserem zweiten Notebook-Jobschritt:
Wir müssen auch angeben, dass der Jobschritt „Schulungsnotizbuch“ (Schritt 2) vom Jobschritt „Notizbuch vorverarbeiten“ (Schritt 1) abhängt, indem wir die verwenden add_depends_on API-Aufruf wie folgt:
Unser letzter Schritt besteht darin, dass das BERT-Modell eine SageMaker-Batch-Transformation ausführt und gleichzeitig die Datenerfassung und -qualität über SageMaker Model Monitor einrichtet. Beachten Sie, dass sich dies von der Verwendung der integrierten Funktion unterscheidet Transformieren or Erfassung Schritte über Pipelines. Unser Notebook für diesen Schritt führt dieselben APIs aus, wird jedoch als Notebook-Jobschritt verfolgt. Dieser Schritt ist vom zuvor definierten Trainingsauftragsschritt abhängig, daher erfassen wir ihn auch mit dem Flag depend_on.
Nachdem die verschiedenen Schritte unseres Workflows definiert wurden, können wir die End-to-End-Pipeline erstellen und ausführen:
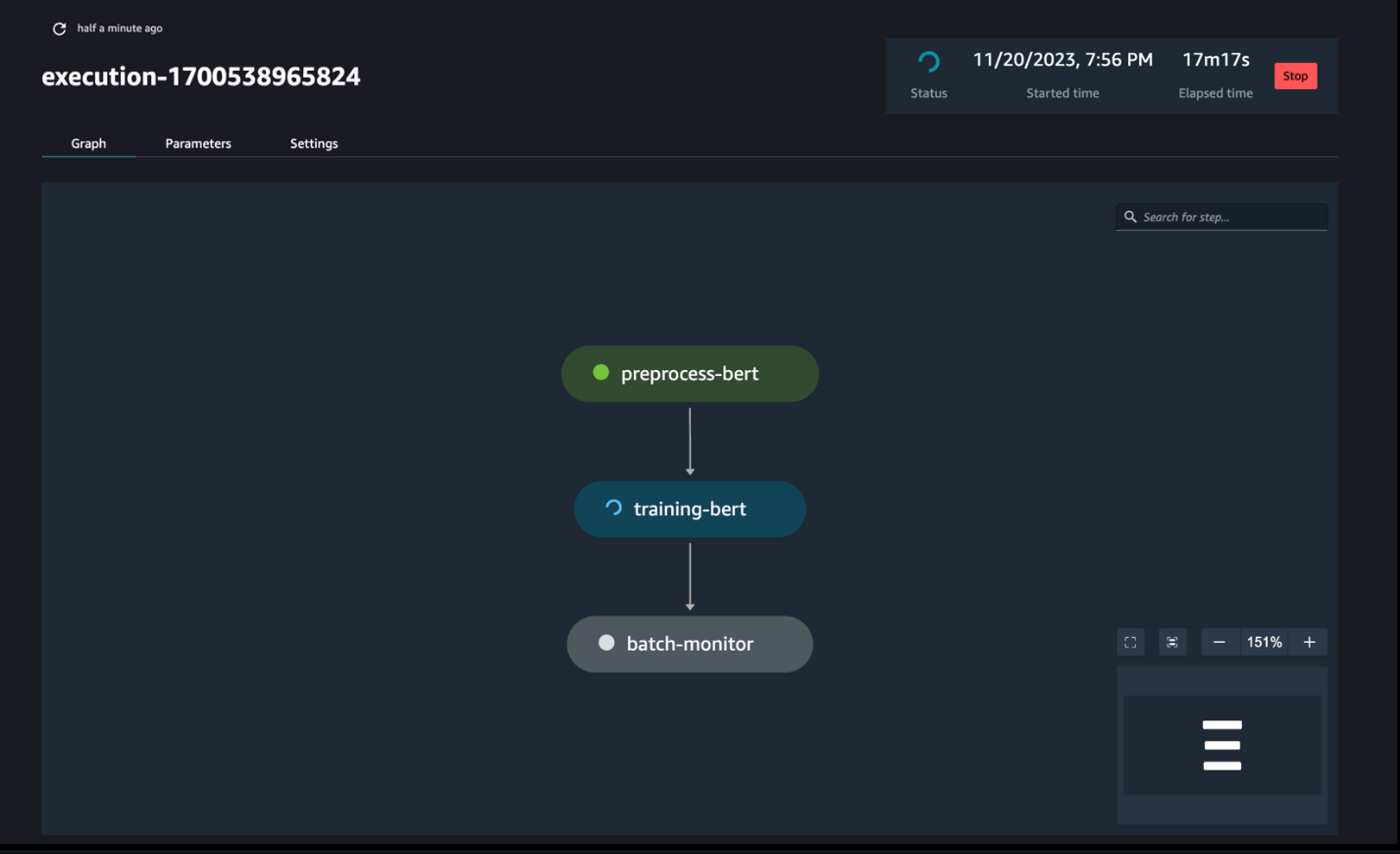
Überwachen Sie die Pipeline-Ausführungen
Sie können die Notebook-Schrittausführungen über die SageMaker Pipelines DAG verfolgen und überwachen, wie im folgenden Screenshot dargestellt.
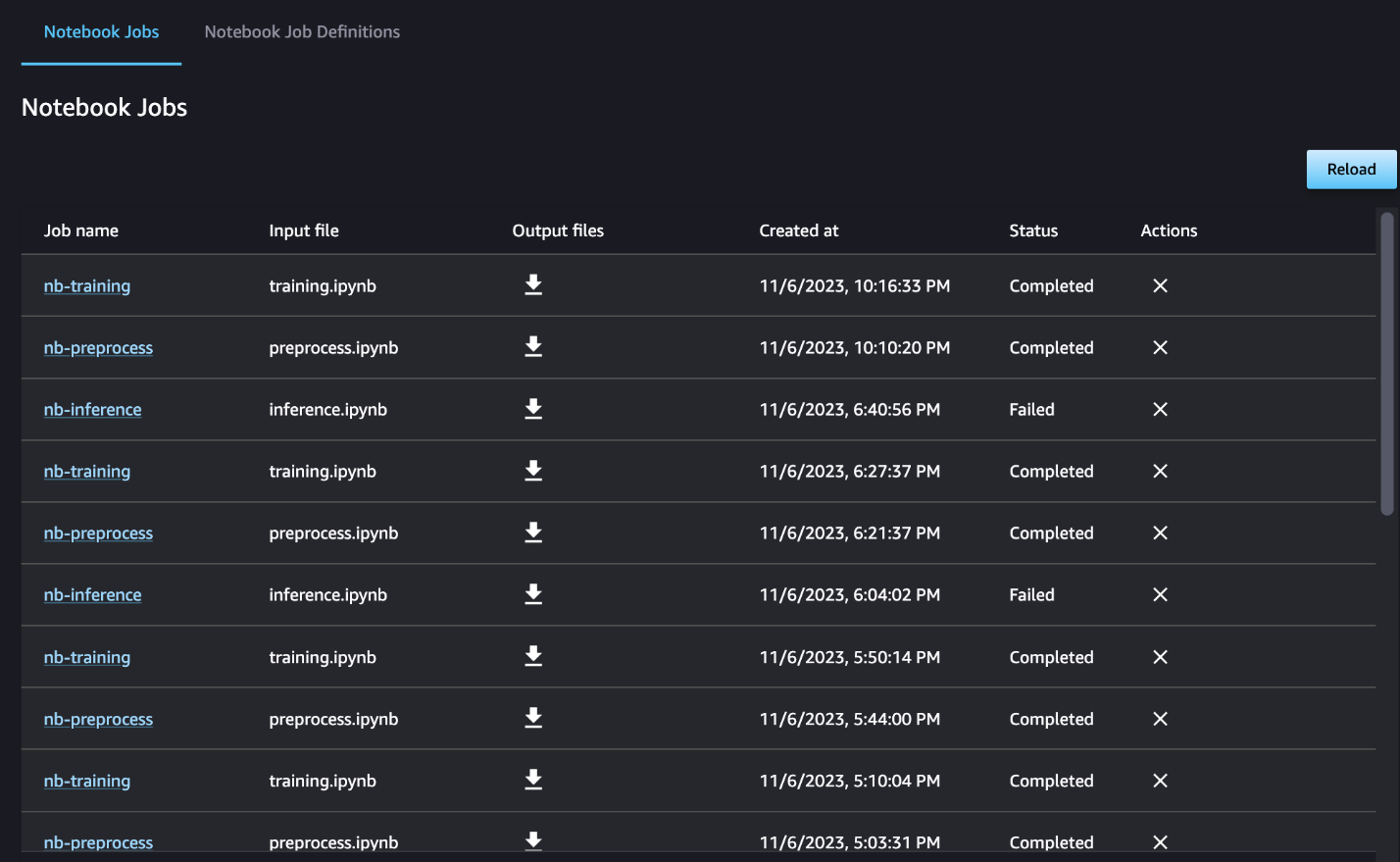
Sie können optional auch die einzelnen Notebook-Ausführungen im Notebook-Job-Dashboard überwachen und die Ausgabedateien umschalten, die über die Benutzeroberfläche von SageMaker Studio erstellt wurden. Wenn Sie diese Funktionalität außerhalb von SageMaker Studio verwenden, können Sie mithilfe von Tags die Benutzer definieren, die den Ausführungsstatus im Notebook-Job-Dashboard verfolgen können. Weitere Einzelheiten zu den einzuschließenden Tags finden Sie unter Sehen Sie sich Ihre Notebook-Jobs an und laden Sie Ausgaben im Studio-UI-Dashboard herunter.
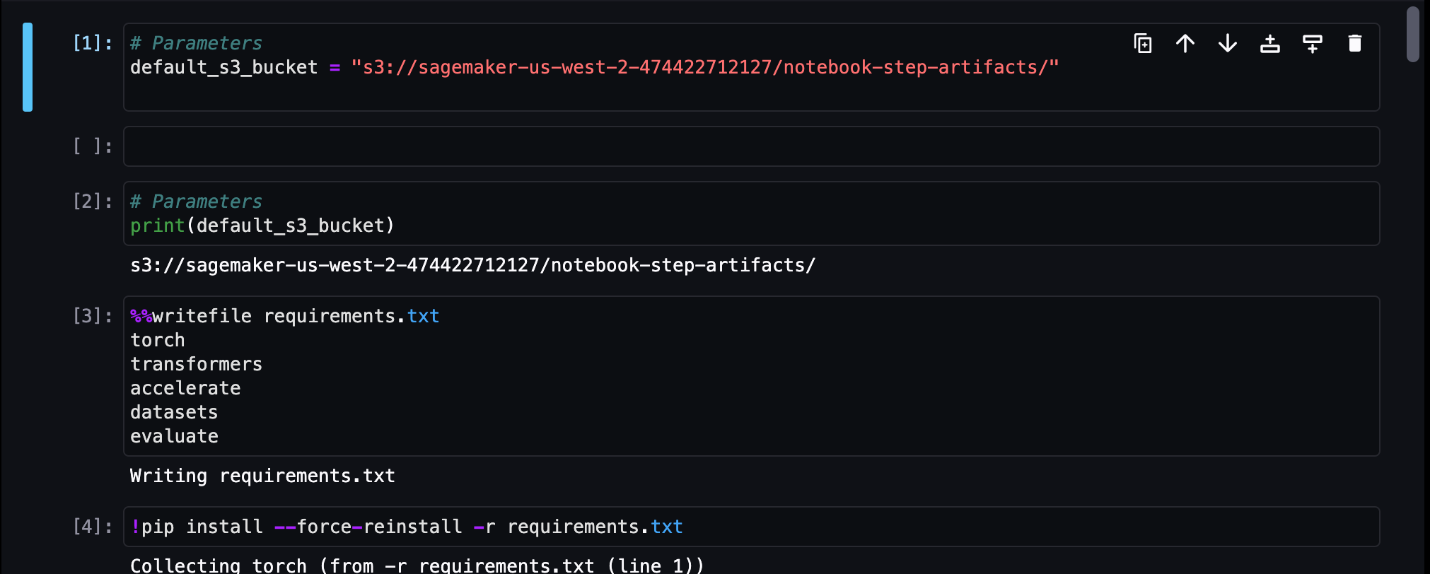
In diesem Beispiel geben wir die resultierenden Notebook-Jobs in ein Verzeichnis namens aus outputs in Ihrem lokalen Pfad mit Ihrem Pipeline-Ausführungscode. Wie im folgenden Screenshot gezeigt, können Sie hier die Ausgabe Ihres Eingabenotizbuchs sowie alle Parameter sehen, die Sie für diesen Schritt definiert haben.
Aufräumen
Wenn Sie unserem Beispiel gefolgt sind, müssen Sie unbedingt die erstellte Pipeline, die Notebook-Jobs und die von den Beispiel-Notebooks heruntergeladenen S3-Daten löschen.
Überlegungen
Im Folgenden sind einige wichtige Überlegungen zu dieser Funktion aufgeführt:
- SDK-Einschränkungen – Der Notebook-Jobschritt kann nur über das SageMaker Python SDK erstellt werden.
- Bildbeschränkungen –Der Notebook-Jobschritt unterstützt die folgenden Bilder:
Zusammenfassung
Mit dieser Einführung können Datenarbeiter ihre Notebooks jetzt programmgesteuert mit ein paar Codezeilen ausführen SageMaker Python-SDK. Darüber hinaus können Sie mit Ihren Notebooks komplexe mehrstufige Workflows erstellen und so den Zeitaufwand für den Wechsel von einem Notebook zu einer CI/CD-Pipeline erheblich verkürzen. Nachdem Sie die Pipeline erstellt haben, können Sie SageMaker Studio verwenden, um DAGs für Ihre Pipelines anzuzeigen und auszuführen sowie die Ausführungen zu verwalten und zu vergleichen. Unabhängig davon, ob Sie End-to-End-ML-Workflows oder einen Teil davon planen, empfehlen wir Ihnen, es auszuprobieren Notebook-basierte Arbeitsabläufe.
Über die Autoren
 Anchit Gupta ist Senior Product Manager für Amazon SageMaker Studio. Ihr Schwerpunkt liegt auf der Ermöglichung interaktiver Data-Science- und Data-Engineering-Workflows innerhalb der SageMaker Studio-IDE. In ihrer Freizeit kocht sie gerne, spielt Brett-/Kartenspiele und liest.
Anchit Gupta ist Senior Product Manager für Amazon SageMaker Studio. Ihr Schwerpunkt liegt auf der Ermöglichung interaktiver Data-Science- und Data-Engineering-Workflows innerhalb der SageMaker Studio-IDE. In ihrer Freizeit kocht sie gerne, spielt Brett-/Kartenspiele und liest.
 Widder Vegiraju ist ML-Architekt im SageMaker-Serviceteam. Er konzentriert sich darauf, Kunden bei der Erstellung und Optimierung ihrer KI/ML-Lösungen auf Amazon SageMaker zu unterstützen. In seiner Freizeit liebt er es zu reisen und zu schreiben.
Widder Vegiraju ist ML-Architekt im SageMaker-Serviceteam. Er konzentriert sich darauf, Kunden bei der Erstellung und Optimierung ihrer KI/ML-Lösungen auf Amazon SageMaker zu unterstützen. In seiner Freizeit liebt er es zu reisen und zu schreiben.
 Eduard Sonne ist Senior SDE und arbeitet für SageMaker Studio bei Amazon Web Services. Er konzentriert sich auf den Aufbau interaktiver ML-Lösungen und die Vereinfachung der Kundenerfahrung, um SageMaker Studio mit gängigen Technologien im Data Engineering und ML-Ökosystem zu integrieren. In seiner Freizeit ist Edward ein großer Fan von Camping, Wandern und Angeln und genießt die Zeit, die er mit seiner Familie verbringt.
Eduard Sonne ist Senior SDE und arbeitet für SageMaker Studio bei Amazon Web Services. Er konzentriert sich auf den Aufbau interaktiver ML-Lösungen und die Vereinfachung der Kundenerfahrung, um SageMaker Studio mit gängigen Technologien im Data Engineering und ML-Ökosystem zu integrieren. In seiner Freizeit ist Edward ein großer Fan von Camping, Wandern und Angeln und genießt die Zeit, die er mit seiner Familie verbringt.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- :hast
- :Ist
- :Wo
- $UP
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- Über Uns
- zugänglich
- azyklisch
- Zusätzliche
- zusätzlich
- Vorteil
- Nach der
- AI / ML
- Alle
- erlaubt
- entlang
- bereits
- ebenfalls
- Obwohl
- Amazon
- Amazon EC2
- Amazon Sage Maker
- Amazon SageMaker-Studio
- Amazon Web Services
- an
- Analyse
- Analyse
- und
- jedem
- Bienen
- APIs
- Anwendungen
- Architektur
- SIND
- AS
- At
- automatisieren
- verfügbar
- AWS
- Base
- basierend
- Baseline
- BE
- schön
- war
- hinter
- Sein
- Besser
- zwischen
- Big
- bauen
- Building
- eingebaut
- aber
- by
- rufen Sie uns an!
- namens
- Camping
- CAN
- Erfassung
- Häuser
- Fälle
- Zelle
- Zeichen
- Einstufung
- Code
- Kolonne
- Spalten
- vereint
- wie die
- gemeinsam
- vergleichen
- abschließen
- Komplex
- zusammengesetzt
- Bestehend
- Berechnen
- Leiten
- Sie
- Überlegungen
- besteht
- Container
- enthält
- kontinuierlich
- verkaufen
- umgewandelt
- Kochen
- Dazugehörigen
- könnte
- erstellen
- erstellt
- schafft
- Erstellen
- Zur Zeit
- Original
- Kunde
- Customer Experience
- Kundensupport
- Kunden
- TAG
- Armaturenbrett
- technische Daten
- Datenüberwachung
- Datenaufbereitung
- Datenverarbeitung
- Datenqualität
- Datenwissenschaft
- Datensätze
- Standard
- definieren
- definiert
- Lieferanten
- Demand
- Abhängigkeiten
- Abhängigkeit
- abhängig
- hängt
- einsetzen
- Bereitstellen
- detailliert
- Details
- entwickeln
- entwickelt
- anders
- Direkt
- gerichtet
- Direktor
- deutlich
- Docker
- Dabei
- erledigt
- nach unten
- herunterladen
- abladen
- jeder
- leicht
- Ökosystem
- Ludwig
- ermöglichen
- ermöglichen
- ermutigen
- Ende
- End-to-End
- Entwicklung
- Ganz
- Epoche
- Äther (ETH)
- Beispiel
- ausführen
- Ausführung
- ERFAHRUNGEN
- extra
- Extrakt
- Familie
- Fan
- weit
- Merkmal
- Feedback
- wenige
- Reichen Sie das
- Mappen
- Filme
- Filmemacher
- Vorname
- Fischen
- fünf
- konzentriert
- konzentriert
- gefolgt
- Folgende
- folgt
- Aussichten für
- unten stehende Formular
- Format
- für
- voll
- Funktionalität
- Außerdem
- Games
- erzeugen
- Graphen
- Haben
- he
- Hilfe
- Unternehmen
- hier (auf dänisch)
- hier
- Wandern
- seine
- Hollywood
- Ultraschall
- HTML
- http
- HTTPS
- human
- if
- zeigt
- Image
- Bilder
- sofort
- importieren
- wichtig
- in
- das
- unabhängig
- zeigt
- Krankengymnastik
- Varianten des Eingangssignals:
- Instanz
- Anleitung
- integrieren
- Integration
- interaktive
- in
- IT
- SEINE
- Job
- Jobs
- jpg
- nur
- Label
- Etiketten
- Nachname
- starten
- lernen
- Bibliotheken
- Line
- Linien
- Belastung
- aus einer regionalen
- Standorte
- Lang
- liebt
- Maschine
- Maschinelles Lernen
- Magie
- Main
- MACHT
- verwalten
- verwaltet
- Management
- Manager
- Medien
- Verdienst
- könnte
- ML
- Modell
- für
- geändert
- Module
- Überwachen
- Überwachung
- Monitore
- mehr
- vor allem warme
- schlauer bewegen
- Film
- mehrere
- sollen
- Name
- nativen
- Need
- erforderlich
- Negativ
- Neu
- nicht
- beachten
- Notizbuch
- Laptops
- jetzt an
- Objekt
- of
- vorgenommen,
- on
- EINEM
- einzige
- Optimieren
- or
- Orchesterbearbeitung
- Andere
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- Ausgänge
- aussen
- Paare
- Parameter
- Parameter
- Teil
- passieren
- Bestehen
- Weg
- ausführen
- Durchführung
- persönliche
- Pipeline
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielend
- Beliebt
- positiv
- Post
- vorhersagen
- Vorbereitung
- Danach
- Bereitet sich vor
- Vorbereitung
- früher
- vorher
- Aufgabenstellung:
- Verarbeitung
- Produkt
- Produkt-Manager
- die
- vorausgesetzt
- bietet
- Öffentlichkeit
- Pullover
- Zwecke
- Push
- geschoben
- Python
- Qualität
- schneller
- R
- lieber
- Lesen Sie mehr
- Lesebrillen
- wiederkehrend
- Reduzierung
- Refaktorieren
- siehe
- eingetragen
- regelmäßig
- bleiben
- WIEDERHOLT
- erfordern
- was zu
- Überprüfen
- Bewertungen
- Führen Sie
- Laufen
- läuft
- sagemaker
- SageMaker-Pipelines
- gleich
- zufrieden
- Zeitplan
- vorgesehen
- Geplante Jobs
- Planung
- Wissenschaft
- Wissenschaftler
- Sdk
- Zweite
- Abschnitt
- Abschnitte
- sehen
- gesehen
- Senior
- Gefühl
- getrennte
- Lösungen
- Sitzung
- kompensieren
- Einstellung
- mehrere
- geformt
- sie
- sollte
- erklären
- Vitrine
- gezeigt
- Konzerte
- signifikant
- bedeutend
- ähnlich
- Einfacher
- Vereinfachung
- Single
- klein
- kleinere
- Schnipsel
- So
- Social Media
- Social Media
- Lösung
- Lösungen
- LÖSEN
- einige
- etwas
- Raumfahrt
- spezifisch
- Ausgabe
- standalone
- Stanford
- Anfang
- Status
- Schritt
- Shritte
- Immer noch
- Lagerung
- einfach
- Studio Adressen
- so
- Sun
- Support
- Unterstützte
- Unterstützt
- sicher
- Nehmen
- nimmt
- Aufgabe
- und Aufgaben
- Team
- Technologies
- Test
- Text
- Textklassifizierung
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- Diese
- Dritte
- fehlen uns die Worte.
- diejenigen
- nach drei
- Durch
- Zeit
- zu
- gemeinsam
- auch
- Werkzeug
- Gesamt
- verfolgen sind
- Training
- trainiert
- Ausbildung
- Transformieren
- Transformer
- Reise
- auslösen
- WENDE
- XNUMX
- tippe
- ui
- verstehen
- Aktualisierung
- us
- -
- Anwendungsfall
- benutzt
- Nutzer
- verwendet
- Verwendung von
- Verwendung
- Werte
- verschiedene
- Anzeigen
- visualisieren
- Spaziergang
- wollen
- we
- Netz
- Web-Services
- wann
- ob
- welche
- während
- WHO
- werden wir
- mit
- .
- ohne
- Arbeiter
- Arbeitsablauf.
- Workflows
- arbeiten,
- Wurst
- Schreiben
- U
- Ihr
- Zephyrnet