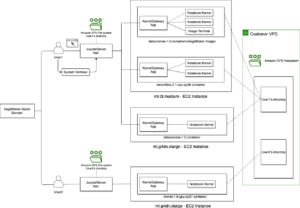
Dies ist ein gemeinsamer Beitrag, der von AWS und Voxel51 gemeinsam verfasst wurde. Voxel51 ist das Unternehmen hinter FiftyOne, dem Open-Source-Toolkit zum Erstellen hochwertiger Datensätze und Computer-Vision-Modelle.
Ein Einzelhandelsunternehmen entwickelt eine mobile App, um Kunden beim Kauf von Kleidung zu unterstützen. Um diese App zu erstellen, benötigen sie einen hochwertigen Datensatz mit Kleidungsbildern, die mit verschiedenen Kategorien gekennzeichnet sind. In diesem Beitrag zeigen wir, wie Sie einen vorhandenen Datensatz durch Datenbereinigung, Vorverarbeitung und Vorkennzeichnung mit einem Zero-Shot-Klassifizierungsmodell wiederverwenden können Einundfünfzig, und passen Sie diese Beschriftungen mit an Amazon Sagemaker Ground Truth.
Sie können Ground Truth und FiftyOne verwenden, um Ihr Datenkennzeichnungsprojekt zu beschleunigen. Wir veranschaulichen, wie Sie die beiden Anwendungen nahtlos zusammen verwenden können, um qualitativ hochwertige beschriftete Datensätze zu erstellen. Für unseren beispielhaften Anwendungsfall arbeiten wir mit der Fashion200K-Datensatz, veröffentlicht auf der ICCV 2017.
Lösungsüberblick
Ground Truth ist ein vollständig selbst bedienter und verwalteter Dienst zur Kennzeichnung von Daten, der Datenwissenschaftler, Ingenieure für maschinelles Lernen (ML) und Forscher in die Lage versetzt, qualitativ hochwertige Datensätze zu erstellen. Einundfünfzig by voxel51 ist ein Open-Source-Toolkit zum Kuratieren, Visualisieren und Auswerten von Computer-Vision-Datensätzen, damit Sie bessere Modelle trainieren und analysieren können, indem Sie Ihre Anwendungsfälle beschleunigen.
In den folgenden Abschnitten zeigen wir Ihnen, wie Sie Folgendes tun:
- Visualisieren Sie den Datensatz in FiftyOne
- Bereinigen Sie den Datensatz mit Filterung und Bilddeduplizierung in FiftyOne
- Kennzeichnen Sie die bereinigten Daten mit Zero-Shot-Klassifizierung in FiftyOne
- Beschriften Sie den kleineren kuratierten Datensatz mit Ground Truth
- Fügen Sie beschriftete Ergebnisse aus Ground Truth in FiftyOne ein und überprüfen Sie beschriftete Ergebnisse in FiftyOne
Anwendungsfallübersicht
Angenommen, Sie besitzen ein Einzelhandelsunternehmen und möchten eine mobile Anwendung erstellen, um personalisierte Empfehlungen zu geben, die den Benutzern helfen, zu entscheiden, was sie anziehen sollen. Ihre potenziellen Nutzer suchen nach einer Anwendung, die ihnen sagt, welche Kleidungsstücke in ihrem Kleiderschrank gut zusammenpassen. Hier sehen Sie eine Chance: Wenn Sie gute Outfits identifizieren können, können Sie dem Kunden neue Kleidungsstücke empfehlen, die die bereits vorhandene Kleidung ergänzen.
Sie möchten es dem Endbenutzer so einfach wie möglich machen. Im Idealfall braucht jemand, der Ihre Anwendung verwendet, nur Fotos von der Kleidung in seinem Kleiderschrank zu machen, und Ihre ML-Modelle entfalten ihre Magie hinter den Kulissen. Sie können ein Allzweckmodell trainieren oder ein Modell mit irgendeiner Form von Feedback an den einzigartigen Stil jedes Benutzers anpassen.
Zunächst müssen Sie jedoch feststellen, welche Art von Kleidung der Benutzer erfasst. Ist es ein Hemd? Eine Hose? Oder etwas anderes? Schließlich möchten Sie wahrscheinlich kein Outfit empfehlen, das mehrere Kleider oder mehrere Hüte enthält.
Um diese anfängliche Herausforderung anzugehen, möchten Sie einen Trainingsdatensatz generieren, der aus Bildern verschiedener Kleidungsstücke mit unterschiedlichen Mustern und Stilen besteht. Um mit einem begrenzten Budget einen Prototyp zu erstellen, möchten Sie mit einem vorhandenen Datensatz booten.
Um den Prozess in diesem Beitrag zu veranschaulichen und Sie durch den Prozess zu führen, verwenden wir den Fashion200K-Datensatz, der auf der ICCV 2017 veröffentlicht wurde. Es ist ein etablierter und häufig zitierter Datensatz, aber er ist nicht direkt für Ihren Anwendungsfall geeignet.
Obwohl Kleidungsstücke mit Kategorien (und Unterkategorien) gekennzeichnet sind und eine Vielzahl hilfreicher Tags enthalten, die aus den ursprünglichen Produktbeschreibungen extrahiert wurden, sind die Daten nicht systematisch mit Muster- oder Stilinformationen gekennzeichnet. Ihr Ziel ist es, diesen vorhandenen Datensatz in einen robusten Trainingsdatensatz für Ihre Kleidungsklassifizierungsmodelle umzuwandeln. Sie müssen die Daten bereinigen und das Beschriftungsschema mit Stilbeschriftungen erweitern. Und das möglichst schnell und mit möglichst wenig Aufwand.
Laden Sie die Daten lokal herunter
Laden Sie zunächst die ZIP-Datei women.tar und den Ordner labels (mit allen Unterordnern) herunter, indem Sie den Anweisungen in folgen GitHub-Repository für Fashion200K-Datensatz. Nachdem Sie beide entpackt haben, erstellen Sie ein übergeordnetes Verzeichnis fashion200k und verschieben Sie die Ordner label und women dorthin. Glücklicherweise wurden diese Bilder bereits auf die Begrenzungsrahmen der Objekterkennung zugeschnitten, sodass wir uns auf die Klassifizierung konzentrieren können, anstatt uns um die Objekterkennung zu kümmern.
Trotz des „200K“ in seinem Spitznamen enthält das von uns extrahierte Frauenverzeichnis 338,339 Bilder. Um den offiziellen Fashion200K-Datensatz zu generieren, haben die Autoren des Datensatzes mehr als 300,000 Produkte online gecrawlt, und nur Produkte mit Beschreibungen, die mehr als vier Wörter enthalten, wurden ausgewählt. Für unsere Zwecke, bei denen die Produktbeschreibung nicht unbedingt erforderlich ist, können wir alle gecrawlten Bilder verwenden.
Schauen wir uns an, wie diese Daten organisiert sind: Innerhalb des Frauenordners sind Bilder nach Artikeltyp der obersten Ebene (Röcke, Oberteile, Hosen, Jacken und Kleider) und Artikeltyp-Unterkategorie (Blusen, T-Shirts, Langarm) angeordnet Spitzen).
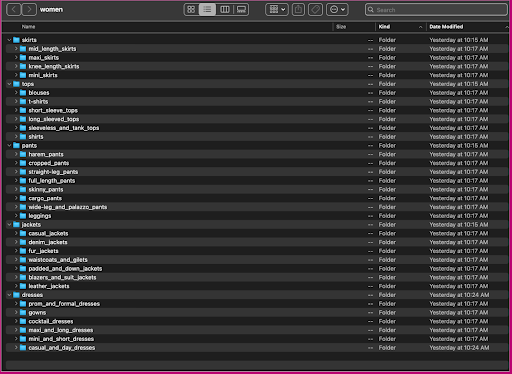
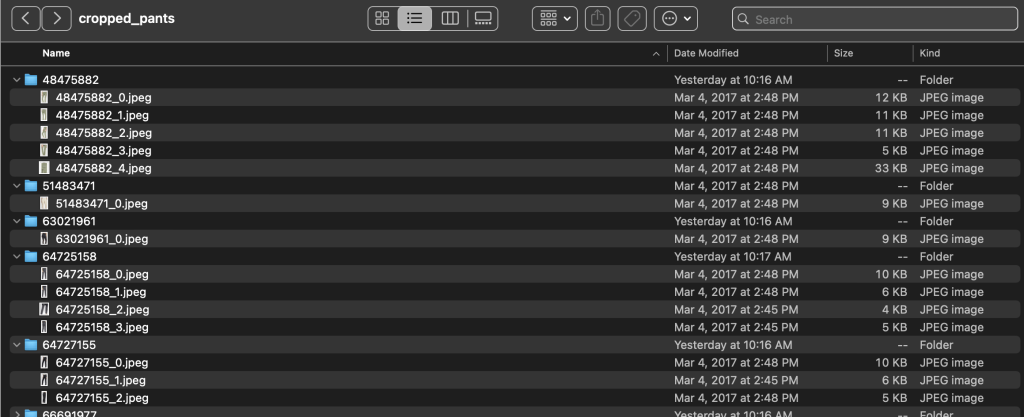
Innerhalb der Unterkategorieverzeichnisse gibt es ein Unterverzeichnis für jede Produktliste. Jedes davon enthält eine variable Anzahl von Bildern. Die Unterkategorie cropped_pants enthält beispielsweise die folgenden Produktlisten und zugehörigen Bilder.
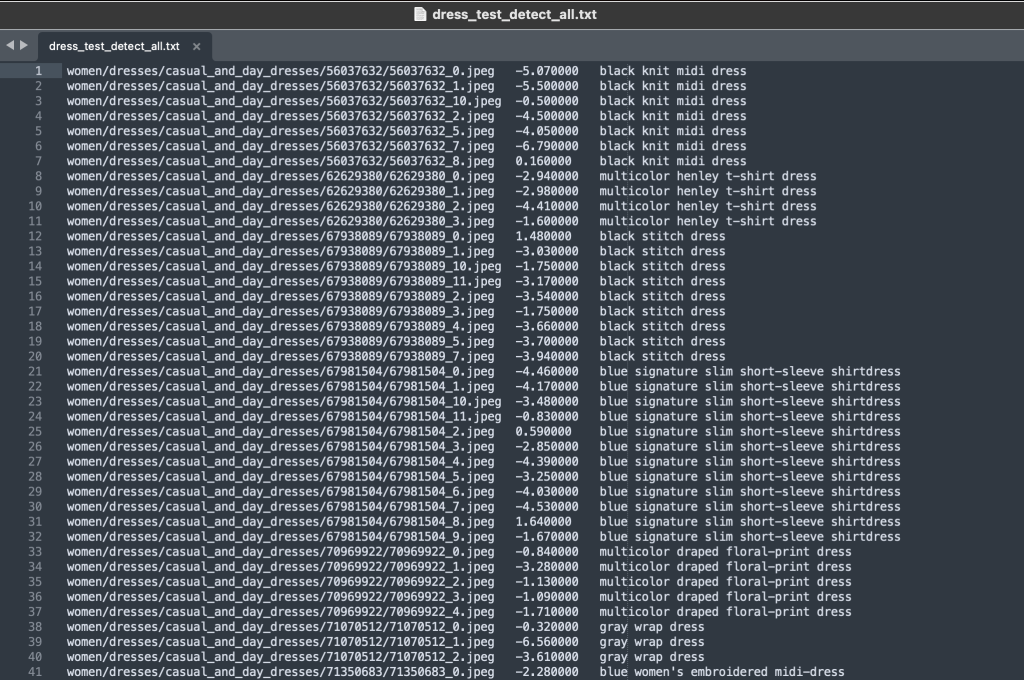
Der Etikettenordner enthält eine Textdatei für jeden Artikeltyp der obersten Ebene, sowohl für Trainings- als auch für Test-Splits. In jeder dieser Textdateien befindet sich für jedes Bild eine separate Zeile, die den relativen Dateipfad, eine Punktzahl und Tags aus der Produktbeschreibung angibt.
Da wir den Datensatz umfunktionieren, kombinieren wir alle Zug- und Testbilder. Daraus generieren wir einen qualitativ hochwertigen anwendungsspezifischen Datensatz. Nachdem wir diesen Vorgang abgeschlossen haben, können wir den resultierenden Datensatz nach dem Zufallsprinzip in neue Zug- und Testaufteilungen aufteilen.
Einfügen, Anzeigen und Kuratieren eines Datensatzes in FiftyOne
Wenn Sie dies noch nicht getan haben, installieren Sie Open-Source-FiftyOne mit pip:
Eine bewährte Methode besteht darin, dies in einer neuen virtuellen Umgebung (venv oder conda) zu tun. Importieren Sie dann die entsprechenden Module. Importieren Sie die Basisbibliothek FiftyOne, FiftyOne Brain mit integrierten ML-Methoden, FiftyOne Zoo, aus dem wir ein Modell laden, das Zero-Shot-Labels für uns generiert, und ViewField, mit dem wir effizient filtern können Daten in unserem Datensatz:
Sie möchten auch die Python-Module glob und os importieren, die uns bei der Arbeit mit Pfaden und Musterabgleich über Verzeichnisinhalte helfen:
Jetzt können wir den Datensatz in FiftyOne laden. Zuerst erstellen wir einen Datensatz namens fashion200k und machen ihn persistent, was es uns ermöglicht, die Ergebnisse rechenintensiver Operationen zu speichern, sodass wir diese Mengen nur einmal berechnen müssen.
Wir können jetzt alle Unterkategorieverzeichnisse durchlaufen und alle Bilder in den Produktverzeichnissen hinzufügen. Wir fügen jedem Muster ein FiftyOne-Klassifizierungslabel mit dem Feldnamen article_type hinzu, das von der Artikelkategorie der obersten Ebene des Bildes ausgefüllt wird. Wir fügen auch Informationen zu Kategorien und Unterkategorien als Tags hinzu:
An diesem Punkt können wir unseren Datensatz in der FiftyOne-App visualisieren, indem wir eine Sitzung starten:
Wir können auch eine Zusammenfassung des Datensatzes in Python ausdrucken, indem wir ausführen print(dataset):
Wir können auch die Tags von hinzufügen labels Verzeichnis zu den Proben in unserem Datensatz:
Betrachtet man die Daten, werden einige Dinge deutlich:
- Einige der Bilder sind ziemlich körnig und haben eine niedrige Auflösung. Dies liegt wahrscheinlich daran, dass diese Bilder durch Zuschneiden von Anfangsbildern in Objekterkennungs-Begrenzungsrahmen erzeugt wurden.
- Einige Kleidungsstücke werden von einer Person getragen, andere werden alleine fotografiert. Diese Details werden durch die gekapselt
viewpointEigentum. - Viele der Bilder desselben Produkts sind sehr ähnlich, so dass das Einfügen von mehr als einem Bild pro Produkt zumindest anfangs möglicherweise nicht viel Vorhersagekraft hinzufügt. Meistens ist das erste Bild jedes Produkts (mit der Endung
_0.jpeg) ist am saubersten.
Zunächst möchten wir unser Kleidungsstil-Klassifizierungsmodell vielleicht mit einer kontrollierten Teilmenge dieser Bilder trainieren. Dazu verwenden wir hochauflösende Abbildungen unserer Produkte und beschränken unsere Betrachtung auf ein repräsentatives Muster pro Produkt.
Zuerst filtern wir die Bilder mit niedriger Auflösung heraus. Wir benutzen das compute_metadata() Methode zum Berechnen und Speichern der Bildbreite und -höhe in Pixeln für jedes Bild im Datensatz. Wir setzen dann den FiftyOne ein ViewField um Bilder basierend auf den minimal zulässigen Werten für Breite und Höhe herauszufiltern. Siehe folgenden Code:
Diese hochauflösende Teilmenge umfasst knapp 200,000 Samples.
Aus dieser Ansicht können wir eine neue Ansicht unseres Datensatzes erstellen, die nur (höchstens) eine repräsentative Probe für jedes Produkt enthält. Wir benutzen das ViewField noch einmal, Musterabgleich für Dateipfade, die mit enden _0.jpeg:
Sehen wir uns eine zufällig gemischte Reihenfolge der Bilder in dieser Teilmenge an:
Entfernen Sie redundante Bilder im Datensatz
Diese Ansicht enthält 66,297 Bilder oder etwas mehr als 19 % des ursprünglichen Datensatzes. Wenn wir uns jedoch die Ansicht ansehen, sehen wir, dass es viele sehr ähnliche Produkte gibt. Das Aufbewahren all dieser Kopien wird wahrscheinlich nur die Kosten für unsere Beschriftung und Modellschulung erhöhen, ohne die Leistung merklich zu verbessern. Lassen Sie uns stattdessen die Beinahe-Duplikate entfernen, um einen kleineren Datensatz zu erstellen, der immer noch die gleiche Schlagkraft hat.
Da diese Bilder keine exakten Duplikate sind, können wir sie nicht auf pixelweise Gleichheit prüfen. Glücklicherweise können wir das FiftyOne Brain verwenden, um unseren Datensatz zu bereinigen. Insbesondere berechnen wir eine Einbettung für jedes Bild – einen niedrigdimensionalen Vektor, der das Bild darstellt – und suchen dann nach Bildern, deren Einbettungsvektoren nahe beieinander liegen. Je näher die Vektoren, desto ähnlicher die Bilder.
Wir verwenden ein CLIP-Modell, um einen 512-dimensionalen Einbettungsvektor für jedes Bild zu generieren, und speichern diese Einbettungen im Feld Einbettungen auf den Proben in unserem Datensatz:
Dann berechnen wir die Nähe zwischen Einbettungen mit Kosinusähnlichkeit, und behaupten, dass alle zwei Vektoren, deren Ähnlichkeit größer als ein gewisser Schwellenwert ist, wahrscheinlich nahezu Duplikate sind. Cosinus-Ähnlichkeitswerte liegen im Bereich [0, 1], und wenn man sich die Daten ansieht, scheint ein Schwellenwert von thresh = 0.5 ungefähr richtig zu sein. Auch dies muss nicht perfekt sein. Ein paar nahezu doppelte Bilder werden unsere Vorhersagekraft wahrscheinlich nicht ruinieren, und das Wegwerfen einiger nicht doppelter Bilder wirkt sich nicht wesentlich auf die Modellleistung aus.
Wir können die angeblichen Duplikate anzeigen, um zu überprüfen, ob sie tatsächlich redundant sind:
Wenn wir mit dem Ergebnis zufrieden sind und glauben, dass es sich bei diesen Bildern tatsächlich um Duplikate handelt, können wir ein Beispiel aus jedem Satz ähnlicher Beispiele auswählen, um es zu behalten, und die anderen ignorieren:
Jetzt hat diese Ansicht 3,729 Bilder. Durch die Bereinigung der Daten und die Identifizierung einer qualitativ hochwertigen Teilmenge des Fashion200K-Datensatzes können wir mit FiftyOne unseren Fokus von mehr als 300,000 Bildern auf knapp 4,000 beschränken, was einer Reduzierung um 98 % entspricht. Allein die Verwendung von Einbettungen zum Entfernen von nahezu doppelten Bildern hat unsere Gesamtzahl der berücksichtigten Bilder um mehr als 90 % verringert, mit wenig oder gar keiner Auswirkung auf Modelle, die mit diesen Daten trainiert werden sollen.
Bevor wir diese Teilmenge vorbeschriften, können wir die Daten besser verstehen, indem wir die bereits berechneten Einbettungen visualisieren. Wir können das eingebaute FiftyOne Brain verwenden compute_visualization()-Methode, die die UMAP-Technik (Uniform Manifold Approximation) verwendet, um die 512-dimensionalen Einbettungsvektoren in den zweidimensionalen Raum zu projizieren, damit wir sie visualisieren können:
Wir eröffnen ein neues Bedienfeld „Einbettungen“. in der FiftyOne-App und Färbung nach Artikeltyp, und wir können sehen, dass diese Einbettungen ungefähr eine Vorstellung von Artikeltyp kodieren (unter anderem!).
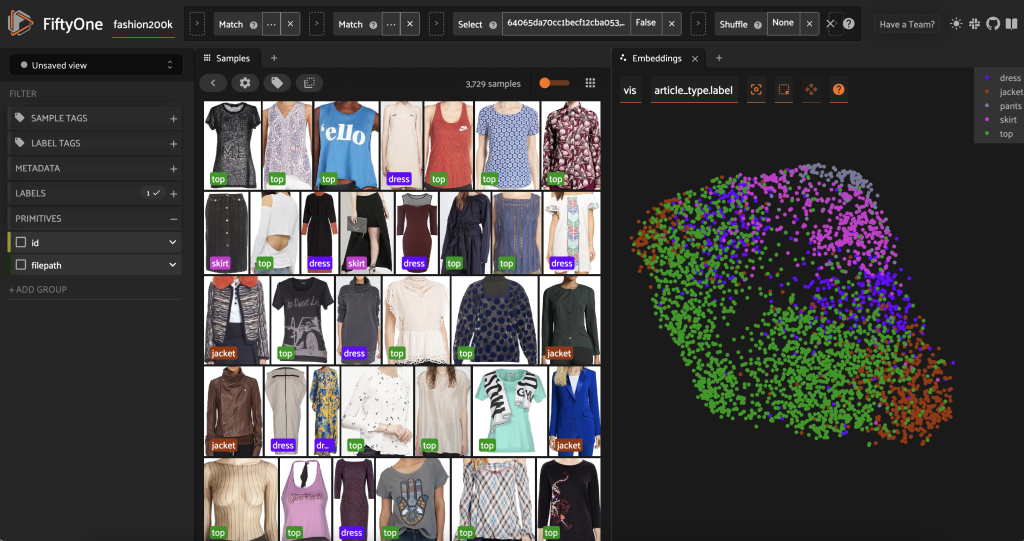
Jetzt können wir diese Daten vorbeschriften.
Durch die Untersuchung dieser höchst einzigartigen, hochauflösenden Bilder können wir eine anständige Anfangsliste von Stilen erstellen, die als Klassen in unserer Zero-Shot-Klassifizierung vor der Kennzeichnung verwendet werden können. Unser Ziel bei der Vorbeschriftung dieser Bilder ist nicht unbedingt, jedes Bild korrekt zu beschriften. Unser Ziel ist es vielmehr, einen guten Ausgangspunkt für menschliche Kommentatoren bereitzustellen, damit wir Zeit und Kosten für die Kennzeichnung reduzieren können.
Wir können dann ein Zero-Shot-Klassifizierungsmodell für diese Anwendung instanziieren. Wir verwenden ein CLIP-Modell, das ein Allzweckmodell ist, das sowohl mit Bildern als auch mit natürlicher Sprache trainiert wird. Wir instanziieren ein CLIP-Modell mit dem Text-Prompt „Kleidung im Stil“, sodass das Modell bei einem gegebenen Bild die Klasse ausgibt, für die „Kleidung im Stil [Klasse]“ am besten geeignet ist. CLIP ist nicht auf einzelhandels- oder modespezifische Daten trainiert, daher ist dies nicht perfekt, aber es kann Ihnen Kosten für Etikettierung und Anmerkungen ersparen.
Wir wenden dieses Modell dann auf unsere reduzierte Teilmenge an und speichern die Ergebnisse in einer article_style Feld:
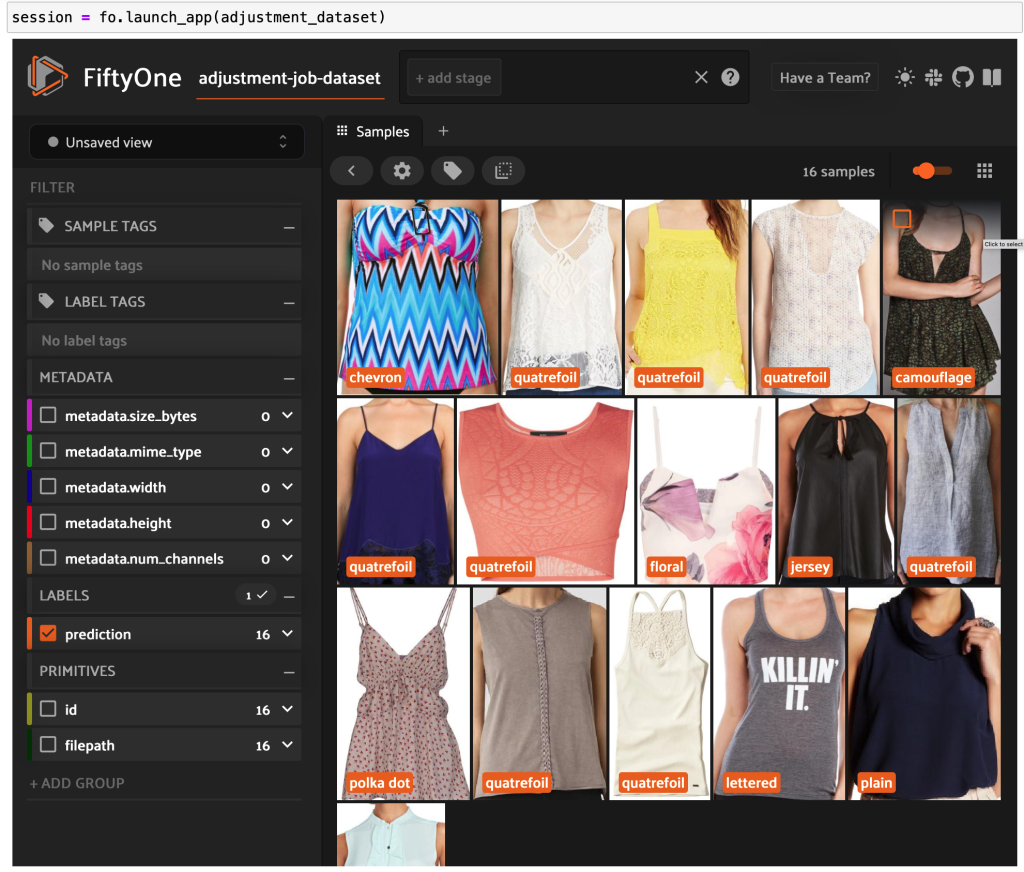
Wenn wir die FiftyOne-App erneut starten, können wir die Bilder mit diesen vorhergesagten Stilbezeichnungen visualisieren. Wir sortieren nach Vorhersagekonfidenz, sodass wir zuerst die zuverlässigsten Stilvorhersagen sehen:
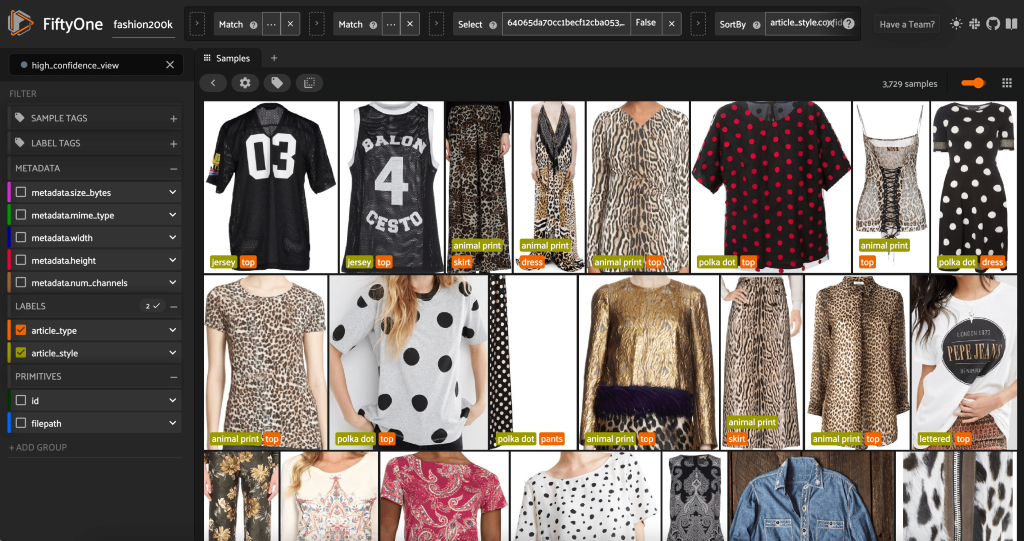
Wir können sehen, dass die Vorhersagen mit dem höchsten Vertrauen für die Stile „Jersey“, „Tiermuster“, „Tupfen“ und „Buchstaben“ zu gelten scheinen. Dies ist sinnvoll, da diese Stile relativ unterschiedlich sind. Es scheint auch, dass die vorhergesagten Stilbezeichnungen größtenteils korrekt sind.
Wir können uns auch die Stilvorhersagen mit dem geringsten Vertrauen ansehen:
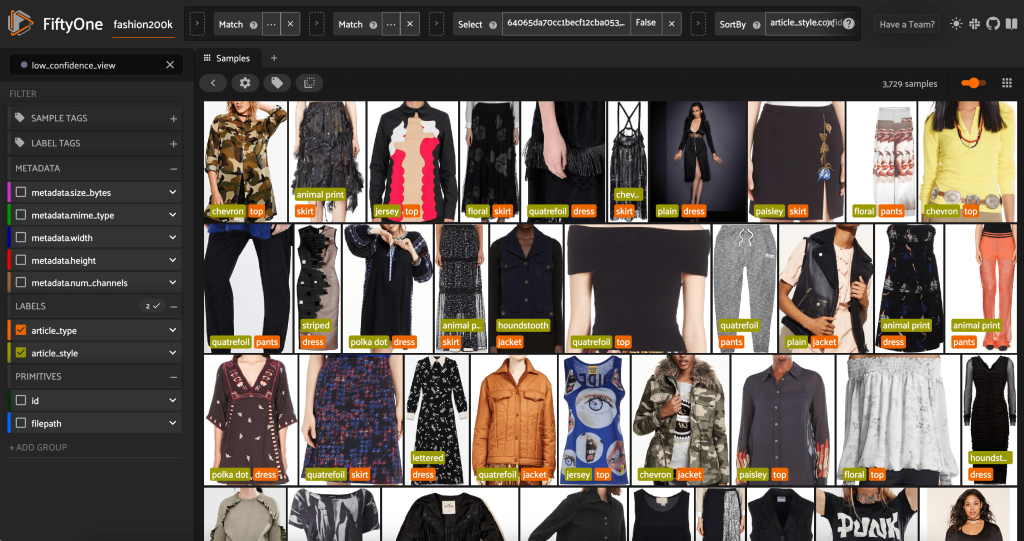
Bei einigen dieser Bilder befindet sich die entsprechende Stilkategorie in der bereitgestellten Liste, und das Kleidungsstück ist falsch gekennzeichnet. Das erste Bild im Raster sollte beispielsweise eindeutig „Camouflage“ und nicht „Chevron“ sein. In anderen Fällen passen die Produkte jedoch nicht genau in die Stilkategorien. Das Kleid im zweiten Bild in der zweiten Reihe ist beispielsweise nicht genau „gestreift“, aber bei denselben Beschriftungsoptionen könnte ein menschlicher Kommentator ebenfalls in Konflikt geraten sein. Beim Aufbau unseres Datensatzes müssen wir entscheiden, ob wir Randfälle wie diese entfernen, neue Stilkategorien hinzufügen oder den Datensatz erweitern.
Exportieren Sie den endgültigen Datensatz aus FiftyOne
Exportieren Sie das endgültige Dataset mit dem folgenden Code:
Wir können einen kleineren Datensatz, beispielsweise 16 Bilder, in den Ordner exportieren 200kFashionDatasetExportResult-16Images. Wir erstellen damit einen Ground-Truth-Anpassungsjob:
Laden Sie den überarbeiteten Datensatz hoch, konvertieren Sie das Etikettenformat in Ground Truth, laden Sie ihn auf Amazon S3 hoch und erstellen Sie eine Manifestdatei für den Anpassungsauftrag
Wir können die Beschriftungen im Datensatz so konvertieren, dass sie mit der übereinstimmen Ausgabemanifestschema eines Bounding-Box-Jobs von Ground Truth und laden Sie die Bilder in eine hoch Amazon Simple Storage-Service (Amazon S3) Bucket zum Starten von a Ground Truth Anpassungsjob:
Laden Sie die Manifestdatei mit dem folgenden Code in Amazon S3 hoch:
Erstellen Sie mit Ground Truth korrigierte gestylte Etiketten
Um Ihre Daten mithilfe von Ground Truth mit Stilbeschriftungen zu versehen, führen Sie die erforderlichen Schritte aus, um einen Beschriftungsauftrag für Begrenzungsrahmen zu starten, indem Sie das in beschriebene Verfahren befolgen Erste Schritte mit Ground Truth guide mit dem Datensatz im selben S3-Bucket.
- Erstellen Sie auf der SageMaker-Konsole einen Ground Truth-Beschriftungsauftrag.
- Setze die Speicherort des Datensatzes eingeben das Manifest sein, das wir in den vorherigen Schritten erstellt haben.
- Geben Sie einen S3-Pfad für an Speicherort des Ausgabedatensatzes.
- Aussichten für IAM-Rolle, wählen Geben Sie eine benutzerdefinierte IAM-Rolle ein RNA, und geben Sie dann den Rollen-ARN ein.
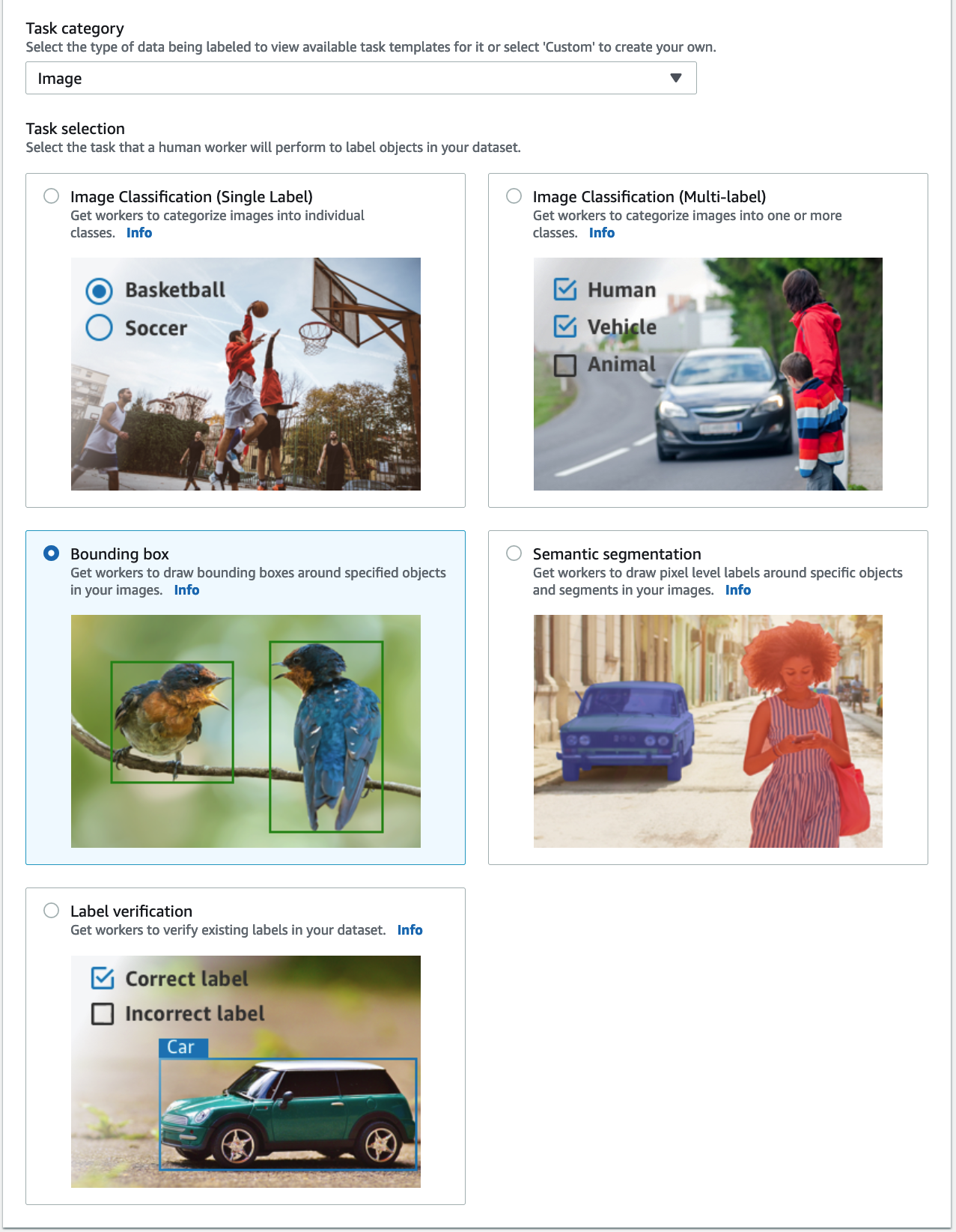
- Aussichten für Aufgabenkategorie, wählen Bild und wählen Sie Begrenzungsrahmen.
- Auswählen Weiter.
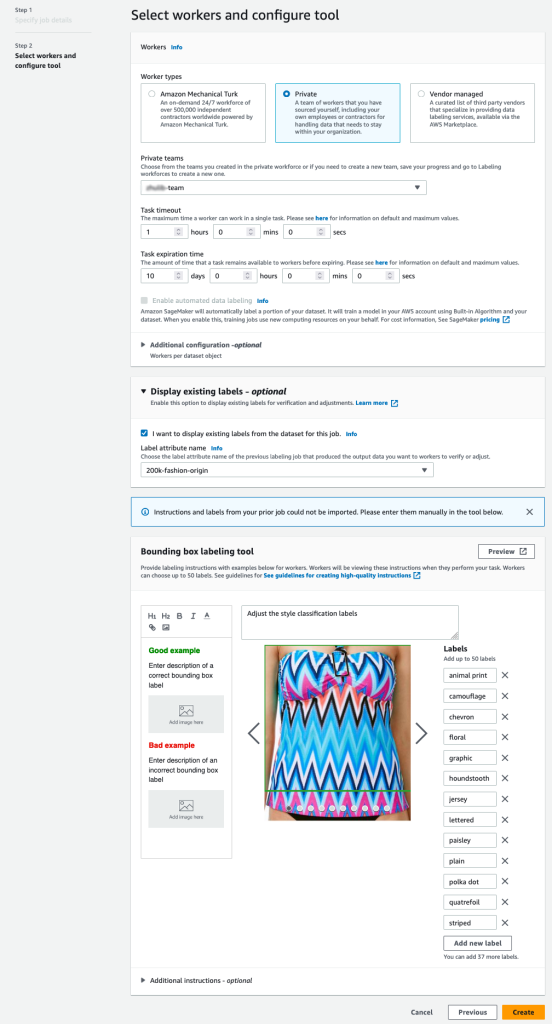
- Im Arbeitskräfte Wählen Sie im Abschnitt die Art der Arbeitskräfte aus, die Sie verwenden möchten.
Sie können eine Belegschaft über auswählen Amazon Mechanischer Türke, Drittanbieter oder Ihre eigene private Belegschaft. Weitere Einzelheiten zu Ihren Personaloptionen finden Sie unter Erstellen und Verwalten von Arbeitskräften. - Erweitern Sie die Funktionalität der Anzeigeoptionen für vorhandene Etiketten und wählen Sie Ich möchte vorhandene Labels aus dem Datensatz für diesen Job anzeigen.
- Aussichten für Label-Attribut name, wählen Sie den Namen aus Ihrem Manifest aus, der den Labels entspricht, die Sie zur Anpassung anzeigen möchten.
Sie sehen nur Label-Attributnamen für Labels, die dem Aufgabentyp entsprechen, den Sie in den vorherigen Schritten ausgewählt haben. - Geben Sie die Beschriftungen für manuell ein Beschriftungstool für Begrenzungsrahmen.
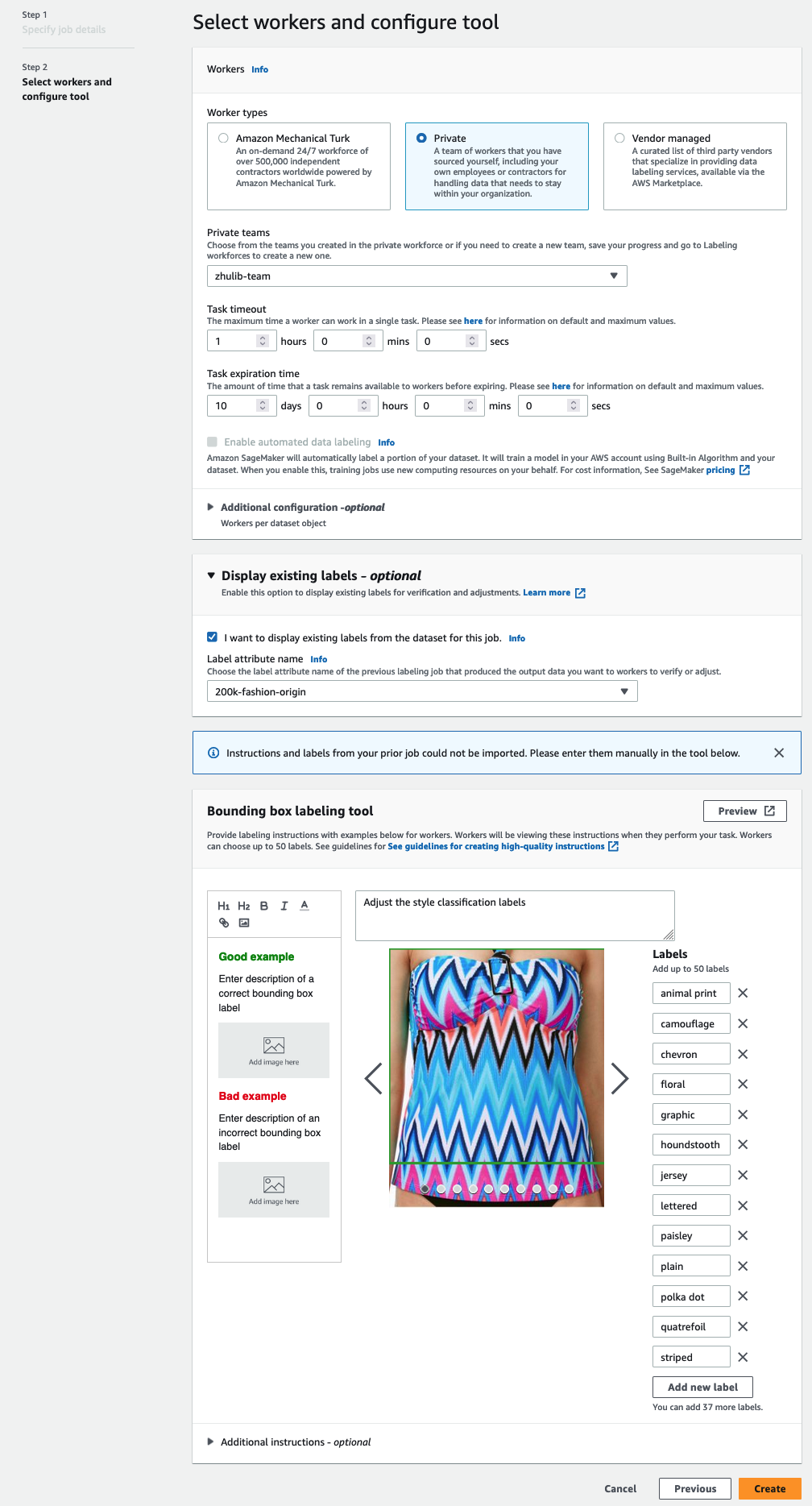 Die Labels müssen dieselben Labels enthalten, die im öffentlichen Dataset verwendet werden. Sie können neue Etiketten hinzufügen. Der folgende Screenshot zeigt, wie Sie die Arbeiter auswählen und das Werkzeug für Ihren Etikettierauftrag konfigurieren können.
Die Labels müssen dieselben Labels enthalten, die im öffentlichen Dataset verwendet werden. Sie können neue Etiketten hinzufügen. Der folgende Screenshot zeigt, wie Sie die Arbeiter auswählen und das Werkzeug für Ihren Etikettierauftrag konfigurieren können.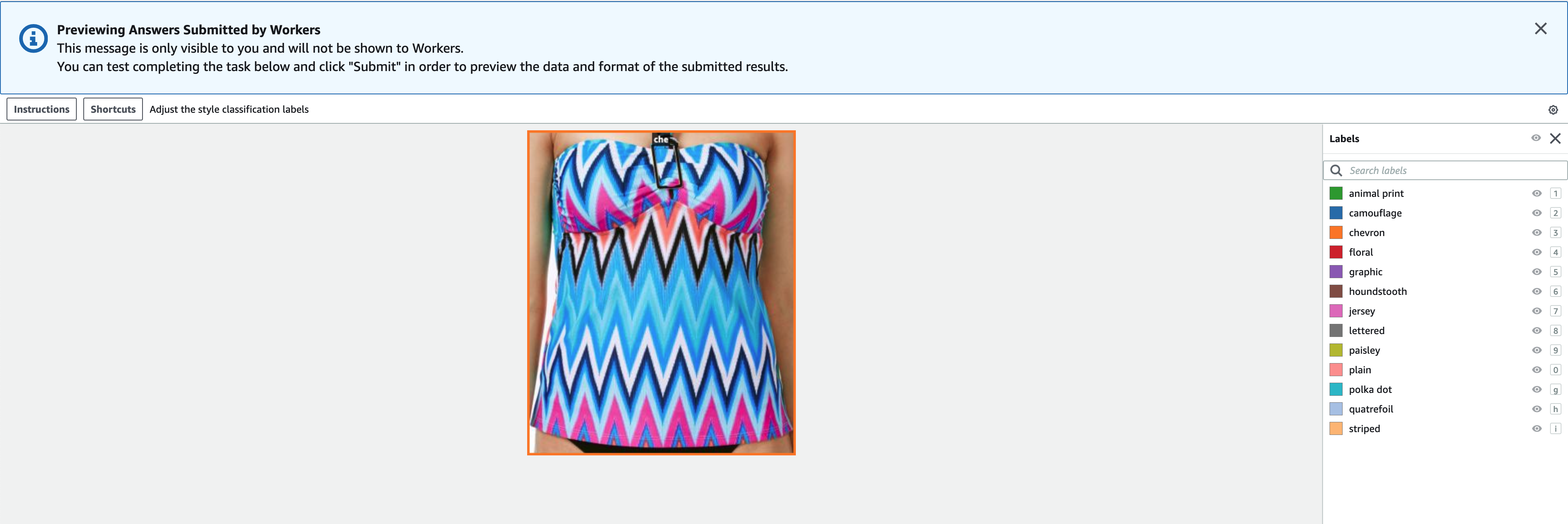
- Auswählen Vorspann , um eine Vorschau des Bilds und der ursprünglichen Anmerkungen anzuzeigen.
Wir haben jetzt einen Labeling-Job in Ground Truth erstellt. Nachdem unser Job abgeschlossen ist, können wir die neu generierten beschrifteten Daten in FiftyOne laden. Ground Truth erzeugt Ausgabedaten in einem Ground Truth-Ausgabemanifest. Weitere Einzelheiten zur Ausgabemanifestdatei finden Sie unter Bounding-Box-Job-Ausgabe. Der folgende Code zeigt ein Beispiel für dieses Ausgabemanifestformat:
Sehen Sie sich gekennzeichnete Ergebnisse von Ground Truth in FiftyOne an
Laden Sie nach Abschluss des Auftrags das Ausgabemanifest des Kennzeichnungsauftrags von Amazon S3 herunter.
Lesen Sie die Ausgabemanifestdatei:
Erstellen Sie ein FiftyOne-Dataset und konvertieren Sie die Manifestzeilen in Samples im Dataset:
Sie können jetzt qualitativ hochwertige beschriftete Daten von Ground Truth in FiftyOne sehen.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie man qualitativ hochwertige Datensätze erstellt, indem man die Leistungsfähigkeit von kombiniert Einundfünfzig by voxel51, ein Open-Source-Toolkit, mit dem Sie Ihren Datensatz verwalten, nachverfolgen, visualisieren und kuratieren können, und Ground Truth, ein Datenkennzeichnungsdienst, mit dem Sie die für das Training von ML-Systemen erforderlichen Datensätze effizient und genau kennzeichnen können, indem Sie Zugriff auf mehrere erstellte -in-Aufgabenvorlagen und Zugriff auf eine vielfältige Belegschaft durch Mechanical Turk, Drittanbieter oder Ihre eigene private Belegschaft.
Wir empfehlen Ihnen, diese neue Funktion auszuprobieren, indem Sie eine FiftyOne-Instanz installieren und die Ground Truth-Konsole verwenden, um loszulegen. Weitere Informationen zu Ground Truth finden Sie unter Etikettendaten, Häufig gestellte Fragen zur Amazon SageMaker-Datenkennzeichnungund der AWS-Blog für maschinelles Lernen.
Verbinden Sie sich mit dem Community für maschinelles Lernen und KI Wenn Sie Fragen oder Feedback haben!
Treten Sie der FiftyOne-Community bei!
Schließen Sie sich den Tausenden von Ingenieuren und Datenwissenschaftlern an, die FiftyOne bereits verwenden, um einige der schwierigsten Probleme in der Computer Vision von heute zu lösen!
Über die Autoren
Shalendra Chhabra ist derzeit Head of Product Management für Amazon SageMaker Human-in-the-Loop (HIL) Services. Zuvor hat Shalendra Language and Conversational Intelligence für Microsoft Teams Meetings inkubiert und geleitet, war EIR bei Amazon Alexa Techstars Startup Accelerator, VP of Product and Marketing bei Diskutiere.io, Head of Product and Marketing bei Clipboard (übernommen von Salesforce) und Lead Product Manager bei Swype (übernommen von Nuance). Insgesamt hat Shalendra dazu beigetragen, Produkte zu entwickeln, zu versenden und zu vermarkten, die mehr als eine Milliarde Menschen berührt haben.
Jakob Markus ist Machine Learning Engineer und Developer Evangelist bei Voxel51, wo er dazu beiträgt, Transparenz und Klarheit in die Daten der Welt zu bringen. Bevor er zu Voxel51 kam, gründete Jacob ein Startup, um aufstrebenden Musikern zu helfen, sich mit Fans zu verbinden und kreative Inhalte mit ihnen zu teilen. Davor arbeitete er bei Google X, Samsung Research und Wolfram Research. In einem früheren Leben war Jacob theoretischer Physiker und promovierte in Stanford, wo er Quantenphasen von Materie untersuchte. In seiner Freizeit klettert, läuft und liest Jacob gerne Science-Fiction-Romane.
Jason Korso ist Mitbegründer und CEO von Voxel51, wo er die Strategie steuert, um durch hochmoderne flexible Software Transparenz und Klarheit in die Daten der Welt zu bringen. Er ist außerdem Professor für Robotik, Elektrotechnik und Informatik an der University of Michigan, wo er sich auf innovative Probleme an der Schnittstelle von Computer Vision, natürlicher Sprache und physischen Plattformen konzentriert. In seiner Freizeit verbringt Jason gerne Zeit mit seiner Familie, liest, ist in der Natur, spielt Brettspiele und unternimmt alle möglichen kreativen Aktivitäten.
Brian Moore ist Mitbegründer und CTO von Voxel51, wo er die technische Strategie und Vision leitet. Er promovierte in Elektrotechnik an der University of Michigan, wo sich seine Forschung auf effiziente Algorithmen für groß angelegte Probleme des maschinellen Lernens konzentrierte, mit besonderem Schwerpunkt auf Computer-Vision-Anwendungen. In seiner Freizeit spielt er gerne Badminton, Golf, wandert und spielt mit seinen Zwillings-Yorkshire-Terriern.
Zhuling Bai ist Softwareentwicklungsingenieur bei Amazon Web Services. Sie arbeitet an der Entwicklung großer verteilter Systeme zur Lösung von Problemen des maschinellen Lernens.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Die Zukunft prägen mit Adryenn Ashley. Hier zugreifen.
- Kaufen und verkaufen Sie Anteile an PRE-IPO-Unternehmen mit PREIPO®. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Über uns
- beschleunigen
- beschleunigend
- Beschleuniger
- Zugang
- genau
- genau
- erworben
- Aktivitäten
- hinzufügen
- Hinzufügen
- Adresse
- Bereinigt
- Einstellung
- Nach der
- aufs Neue
- AI
- Alexa
- Algorithmen
- Alle
- erlaubt
- allein
- bereits
- ebenfalls
- Amazon
- Amazonas alexa
- Amazon Sage Maker
- Amazon Sagemaker Ground Truth
- Amazon Web Services
- unter
- an
- analysieren
- und
- Tier
- jedem
- App
- Anwendung
- Anwendungen
- Jetzt bewerben
- angemessen
- SIND
- vereinbart worden
- Artikel
- Artikel
- AS
- damit verbundenen
- At
- Autoren
- ein Weg
- AWS
- Base
- basierend
- BE
- weil
- werden
- war
- Bevor
- hinter
- hinter den Kulissen
- Sein
- Glauben
- BESTE
- Besser
- zwischen
- Milliarde
- Tafel
- Brettspiele
- KNOCHEN
- Bootstrap
- beide
- Box
- Boxen
- Gehirn
- Break
- bringen
- gebracht
- Haushalt
- bauen
- Building
- eingebaut
- aber
- Kaufe
- by
- CAN
- Capturing
- Häuser
- Fälle
- Kategorien
- Kategorie
- CEO
- challenges
- herausfordernd
- aus der Ferne überprüfen
- Auswählen
- Clarity
- Klasse
- Unterricht
- Einstufung
- Reinigung
- klar
- Auftraggeber
- Klettern
- Menu
- näher
- Kleider
- Bekleidung
- Co-Gründer
- Code
- kombinieren
- Vereinigung
- Unternehmen
- Ergänzung
- abschließen
- Abschluss
- Berechnen
- Computer
- Computerwissenschaften
- Computer Vision
- Computer Vision-Anwendungen
- Vertrauen
- zuversichtlich
- Vernetz Dich
- Berücksichtigung
- Bestehend
- Konsul (Console)
- enthält
- Inhalt
- Inhalt
- gesteuert
- Konversations
- verkaufen
- Kopien
- Kernbereich
- korrigiert
- entspricht
- Kosten
- Kosten
- erstellen
- erstellt
- Kreativ (Creative)
- Referenzen
- CTO
- kuratiert
- kuratieren
- Zur Zeit
- Original
- Kunde
- Kunden
- Schneiden
- innovativ, auf dem neuesten Stand
- technische Daten
- Datensätze
- entscheidet
- zeigen
- Denim
- Tiefe
- Beschreibung
- Details
- Entdeckung
- Entwickler:in / Unternehmen
- Entwicklung
- Entwicklung
- anders
- Direkt
- Verzeichnisse
- Display
- deutlich
- verteilt
- verteilte Systeme
- verschieden
- do
- Tut nicht
- Hund
- Dabei
- erledigt
- Nicht
- DOT
- nach unten
- herunterladen
- Duplikate
- e
- jeder
- Einfache
- Edge
- bewirken
- effizient
- effizient
- Elektrotechnik
- Einbettung
- aufstrebenden
- Betonung
- beschäftigt
- befähigt
- gekapselt
- ermutigen
- Ende
- Ingenieur
- Entwicklung
- Ingenieure
- Enter
- Arbeitsumfeld
- Gleichheit
- essential
- etablierten
- Äther (ETH)
- Auswerten
- Evangelist
- genau
- Beispiel
- vorhandenen
- exportieren
- ziemlich
- Familie
- Fans
- Feedback
- wenige
- Fiktion
- Feld
- Felder
- Reichen Sie das
- Mappen
- Filter
- Filterung
- Finale
- Vorname
- passen
- flexibel
- Setzen Sie mit Achtsamkeit
- konzentriert
- konzentriert
- Folgende
- Aussichten für
- unten stehende Formular
- Format
- Zum Glück
- Gründung
- vier
- Frei
- für
- voll
- Funktionalität
- Games
- allgemeiner Zweck
- erzeugen
- erzeugt
- bekommen
- GitHub
- ABSICHT
- gegeben
- Kundenziele
- Golf
- gut
- mehr
- Gitter
- Boden
- Gruppe an
- Guide
- glücklich
- Haben
- he
- ganzer
- Höhe
- Hilfe
- dazu beigetragen,
- hilfreich
- hilft
- hier
- hochwertige
- hochauflösenden
- höchste
- hoch
- Wandern
- seine
- hält
- Ultraschall
- Hilfe
- aber
- HTML
- http
- HTTPS
- human
- i
- IAM
- ID
- identifizieren
- Identifizierung
- ids
- if
- Image
- Bilder
- Impact der HXNUMXO Observatorien
- importieren
- Verbesserung
- in
- In anderen
- Einschließlich
- falsch
- inkubiert
- Information
- Anfangs-
- anfänglich
- installieren
- Installieren
- Instanz
- beantragen müssen
- Anleitung
- Intelligenz
- Überschneidung
- in
- IT
- SEINE
- Jersey
- Job
- Beitritt
- dank
- JSON
- nur
- Behalten
- Aufbewahrung
- Label
- Beschriftung
- Etiketten
- Sprache
- großflächig
- starten
- Start
- führen
- umwandeln
- LERNEN
- lernen
- am wenigsten
- geführt
- links
- Lasst uns
- Bibliothek
- Lebensdauer
- Gefällt mir
- wahrscheinlich
- LIMIT
- Limitiert
- Line
- Linien
- Liste
- listing
- Liste
- wenig
- Leben
- Belastung
- aussehen
- suchen
- Los
- Sneaker
- Maschine
- Maschinelles Lernen
- gemacht
- Magie
- um
- MACHT
- verwalten
- verwaltet
- Management
- Manager
- viele
- Karte
- Markt
- Marketing
- Spiel
- Abstimmung
- wesentlich
- Materie
- Kann..
- mechanisch
- Medien
- Tagungen
- Meta
- Metadaten
- Methode
- Methoden
- Michigan
- Microsoft
- Microsoft-Teams
- könnte
- Minimum
- ML
- Mobil
- App
- Modell
- für
- Module
- mehr
- vor allem warme
- schlauer bewegen
- viel
- mehrere
- Musiker
- sollen
- Name
- Namens
- Namen
- Natürliche
- Natürliche Sprache
- Natur
- In der Nähe von
- Notwendig
- notwendig,
- Need
- Bedürfnisse
- Neu
- deutlich
- Notion
- jetzt an
- Nuance
- Anzahl
- Objekt
- Objekterkennung
- Objekte
- of
- offiziell
- on
- einmal
- EINEM
- Online
- einzige
- XNUMXh geöffnet
- Open-Source-
- Einkauf & Prozesse
- Gelegenheit
- Optionen
- or
- Organisiert
- Original
- OS
- Andere
- Anders
- UNSERE
- skizzierte
- Signalausgangsmöglichkeiten:
- übrig
- besitzen
- Besitzt
- Packs
- gepaart
- Teil
- besondere
- passt
- Weg
- Schnittmuster
- Muster
- perfekt
- Leistung
- person
- Personalisiert
- Phasen der Materie
- physikalisch
- wählen
- Fotos
- PLAID
- Ebene
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielend
- Points
- besiedelt
- möglich
- Post
- Werkzeuge
- Praxis
- vorhergesagt
- Prognose
- Prognosen
- Vorspann
- früher
- vorher
- Vor
- privat
- wahrscheinlich
- Probleme
- Prozessdefinierung
- Produkt
- Produktmanagement
- Produkt-Manager
- Produkte
- Professor
- Projekt
- Resorts
- prospektiv
- Prototyp
- die
- vorausgesetzt
- Bereitstellung
- Öffentlichkeit
- Punsch
- Zwecke
- Python
- Quant
- Fragen
- schnell
- Angebot
- lieber
- Lesebrillen
- bereit
- empfehlen
- Empfehlungen
- Veteran
- Reduziert
- Reduktion
- verhältnismäßig
- freigegeben
- relevant
- entfernen
- Vertreter
- Darstellen
- falls angefordert
- Forschungsprojekte
- Forscher
- Auflösung
- eine Beschränkung
- Folge
- was zu
- Die Ergebnisse
- Einzelhandel
- Rückkehr
- Überprüfen
- Loswerden
- Robotik
- robust
- Rollen
- rund
- REIHE
- Verderben
- Laufen
- sagemaker
- Said
- salesforce
- gleich
- Samsung
- Speichern
- Szenen
- Wissenschaft
- Science-Fiction
- Wissenschaftler
- Ergebnis
- nahtlos
- Zweite
- Abschnitt
- Abschnitte
- sehen
- scheinen
- scheint
- ausgewählt
- Sinn
- getrennte
- Leistungen
- Sitzung
- kompensieren
- Teilen
- sie
- sollte
- erklären
- Konzerte
- JA
- ähnlich
- Einfacher
- kleinere
- So
- Software
- Software-Entwicklung
- LÖSEN
- einige
- Jemand,
- etwas
- Raumfahrt
- verbringen
- Ausgabe
- gespalten
- Spagat
- Stanford
- Anfang
- begonnen
- Beginnen Sie
- Anfang
- Startbeschleuniger
- State-of-the-art
- Shritte
- Immer noch
- Lagerung
- speichern
- Strategie
- Stil
- Stile
- ZUSAMMENFASSUNG
- Unterstützte
- Systeme und Techniken
- Nehmen
- Aufgabe
- Teams
- Technische
- TechStars
- erzählt
- Vorlagen
- Test
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- theoretisch
- Dort.
- Diese
- vom Nutzer definierten
- think
- basierte Online-to-Offline-Werbezuordnungen von anderen gab.
- fehlen uns die Worte.
- Tausende
- Schwelle
- Durch
- Wurf
- Zeit
- zu
- gemeinsam
- Werkzeug
- Toolkit
- Top
- Top-Level
- Tops & Pullover
- Gesamt
- gerührt
- verfolgen sind
- Training
- trainiert
- Ausbildung
- Transformieren
- Transparenz
- was immer dies auch sein sollte.
- Wahrheit
- WENDE
- XNUMX
- tippe
- Typen
- für
- verstehen
- einzigartiges
- Universität
- University of Michigan
- Aktualisierung
- us
- -
- Anwendungsfall
- benutzt
- Mitglied
- Nutzer
- Verwendung von
- Werte
- Vielfalt
- verschiedene
- Anbieter
- überprüfen
- sehr
- Anzeigen
- Assistent
- Seh-
- wollen
- wurde
- we
- Netz
- Web-Services
- GUT
- waren
- Was
- wann
- ob
- welche
- Wikipedia
- werden wir
- mit
- .
- ohne
- Damen
- Worte
- Arbeiten
- gearbeitet
- Arbeiter
- Belegschaft
- Werk
- weltweit
- Sorgen
- würde
- schreiben
- X
- U
- Ihr
- Zephyrnet
- PLZ
- ZOO