Willkommen im Zeitalter der Daten. Die schiere Menge der täglich erfassten Daten wächst weiter und erfordert die Weiterentwicklung von Plattformen und Lösungen. Dienstleistungen wie z Amazon Simple Storage-Service (Amazon S3) bieten eine skalierbare Lösung, die sich anpasst und dennoch kostengünstig für wachsende Datensätze bleibt. Der Amazon-Initiative für Nachhaltigkeitsdaten (ASDI) nutzt die Funktionen von Amazon S3, um Ihnen eine kostenlose Lösung zum Speichern und Teilen von klimawissenschaftlichen Workloads auf der ganzen Welt bereitzustellen. Das Open-Data-Sponsorship-Programm von Amazon ermöglicht es Organisationen, kostenlos auf AWS zu hosten.
In den letzten zehn Jahren haben wir eine Welle von Data-Science-Frameworks erlebt, die zum Tragen kamen, zusammen mit einer Massenakzeptanz durch die Data-Science-Community. Ein solcher Rahmen ist Instrumententafel, das sich durch seine Fähigkeit auszeichnet, eine Orchestrierung von Worker-Rechenknoten bereitzustellen und dadurch komplexe Analysen großer Datensätze zu beschleunigen.
In diesem Beitrag zeigen wir Ihnen, wie Sie eine benutzerdefinierte Datei bereitstellen AWS Cloud-Entwicklungskit (AWS CDK)-Lösung, die die Funktionalität von Dask erweitert, um interregional im globalen Netzwerk von Amazon zu arbeiten. Die AWS CDK-Lösung stellt ein Netzwerk von Dask-Mitarbeitern in zwei AWS-Regionen bereit und verbindet sich mit einer Client-Region. Weitere Informationen finden Sie unter Anleitung für verteiltes Computing mit Cross Regional Dask auf AWS und für GitHub Repo für Open-Source-Code.
Nach der Bereitstellung hat der Benutzer Zugriff auf ein Jupyter-Notebook, wo er mit zwei Datensätzen von ASDI auf AWS interagieren kann: Gekoppeltes Modell Vergleichsprojekt 6 (CMIP6) und ECMWF ERA5 Reanalyse. CMIP6 konzentriert sich auf die sechste Phase des globalen gekoppelten Modellensembles für die allgemeine Zirkulation zwischen Ozean und Atmosphäre; ERA5 ist die fünfte Generation atmosphärischer Reanalysen des EZMW zum globalen Klima und die erste Reanalyse, die als operativer Dienst erstellt wird.
Diese Lösung wurde durch die Arbeit mit einem wichtigen AWS-Kunden inspiriert, dem UK Met Office. Das Met Office wurde 1854 gegründet und ist der nationale meteorologische Dienst für das Vereinigte Königreich. Sie bieten Wetter- und Klimavorhersagen, damit Sie bessere Entscheidungen treffen können, um sicher zu bleiben und erfolgreich zu sein. Eine Zusammenarbeit zwischen dem Met Office und EUMETSAT, detailliert in Datennahe Berechnung auf einem zwischen Rechenzentren verteilten Dask-Cluster, unterstreicht die wachsende Notwendigkeit, eine nachhaltige, effiziente und skalierbare Data-Science-Lösung zu entwickeln. Diese Lösung erreicht dies, indem sie die Rechenleistung näher an die Daten bringt, anstatt die Daten zu zwingen, näher an die Rechenressourcen heranzukommen, was Kosten, Latenz und Energie erhöht.
Lösungsüberblick
Jeden Tag produziert das UK Met Office bis zu 300 TB an Wetter- und Klimadaten, von denen ein Teil an ASDI veröffentlicht wird. Diese Datensätze werden weltweit verteilt und für die öffentliche Nutzung gehostet. Das Met Office möchte es den Verbrauchern ermöglichen, mehr aus ihren Daten zu machen, um wichtige Entscheidungen bei der Bewältigung von Themen wie einer besseren Vorbereitung auf durch den Klimawandel verursachte Waldbrände und Überschwemmungen und die Verringerung der Ernährungsunsicherheit durch bessere Ernteertragsanalysen zu treffen.
Herkömmliche Lösungen, die heute verwendet werden, insbesondere bei Klimadaten, sind zeitaufwändig und nicht nachhaltig, da sie Datensätze über Regionen hinweg replizieren. Unnötige Datenübertragung im Petabyte-Bereich ist teuer, langsam und verbraucht Energie.
Wir schätzten, dass, wenn diese Praxis von den Met Office-Benutzern übernommen würde, jeden Tag das Äquivalent des täglichen Stromverbrauchs von 40 Haushalten eingespart werden könnte, und sie könnten auch den Datentransfer zwischen Regionen reduzieren.
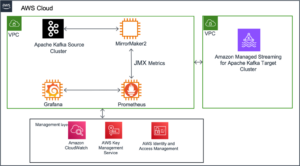
Das folgende Diagramm zeigt die Lösungsarchitektur.
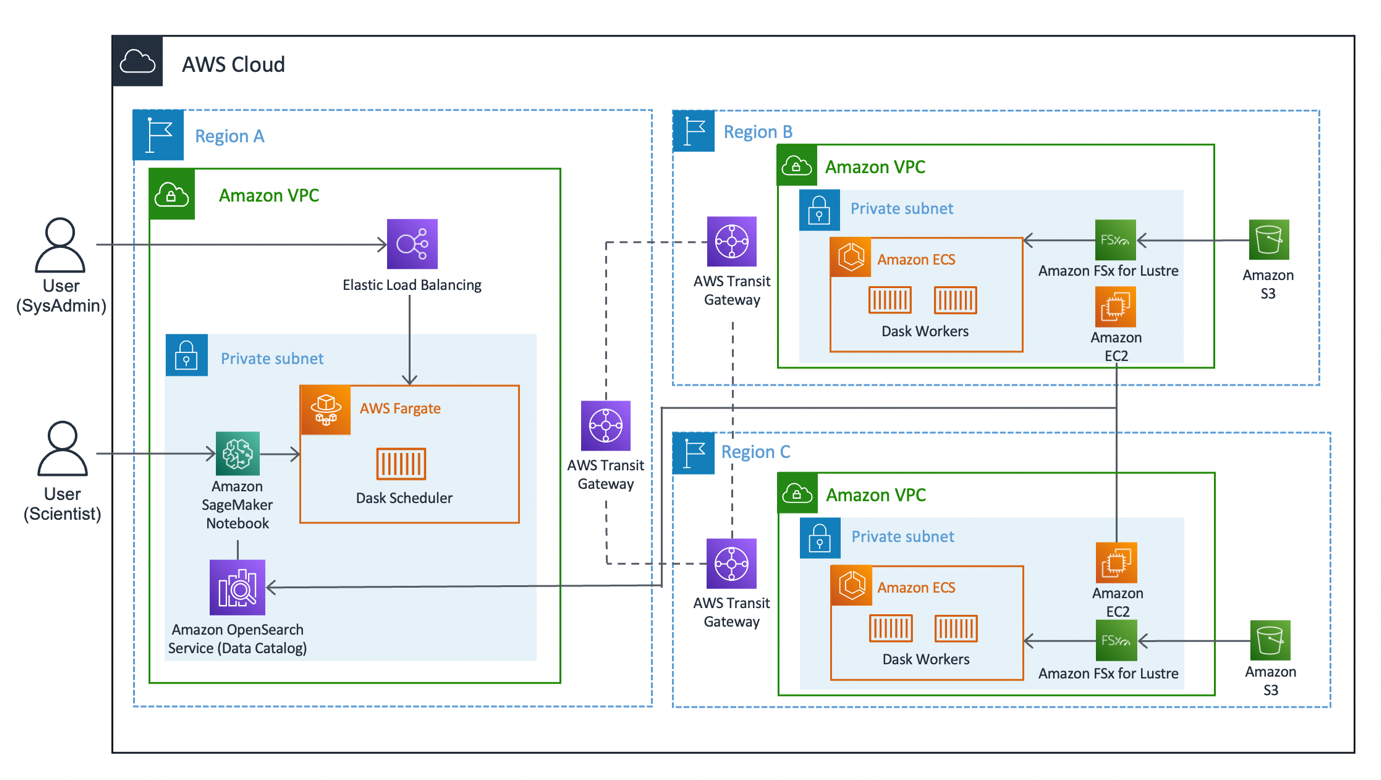
Die Lösung lässt sich in drei Hauptsegmente unterteilen: Client, Worker und Netzwerk. Lassen Sie uns in jedes eintauchen und sehen, wie sie zusammenkommen.
Kunden
Der Client stellt die Quellregion dar, mit der sich Data Scientists verbinden. Diese Region (Region A im Diagramm) enthält eine Amazon SageMaker-Notizbuch, ein Amazon OpenSearch-Dienst Domäne und a Dask-Scheduler als Schlüsselkomponenten. Systemadministratoren haben Zugriff auf das integrierte Dask-Dashboard, das über eine angezeigt wird Elastischer Lastausgleicher.
Datenwissenschaftler haben Zugriff auf das auf SageMaker gehostete Jupyter-Notebook. Das Notebook kann Workloads mit dem Dask-Scheduler verbinden und ausführen. Die OpenSearch Service-Domain speichert Metadaten zu den Datensätzen, die in den Regionen verbunden sind. Notebook-Benutzer können diesen Dienst abfragen, um Details wie die richtige Region der Dask-Mitarbeiter abzurufen, ohne vorher den regionalen Standort der Daten kennen zu müssen.
Arbeitnehmer
Jede der Arbeiterregionen (Regionen B und C im Diagramm) besteht aus einer Amazon Elastic Container-Service (Amazon ECS)-Cluster von Dask-Arbeiter, ein Amazon FSx für Lustre Dateisystem und ein eigenständiges Amazon Elastic Compute-Cloud (Amazon EC2)-Instanz. FSx for Lustre ermöglicht Dask-Mitarbeitern den Zugriff auf und die Verarbeitung von Amazon S3-Daten aus einem Hochleistungsdateisystem, indem Ihre Dateisysteme mit S3-Buckets verknüpft werden. Es bietet Latenzen von weniger als einer Millisekunde, einen Durchsatz von bis zu Hunderten von GB/s und Millionen von IOPS. Ein Hauptmerkmal von Lustre ist, dass nur die Metadaten des Dateisystems synchronisiert werden. Lustre verwaltet das Gleichgewicht der Dateien, die geladen und warm gehalten werden, je nach Bedarf.
Worker-Cluster skalieren basierend auf der CPU-Auslastung, stellen zusätzliche Worker in längeren Bedarfszeiten bereit und werden herunterskaliert, wenn Ressourcen inaktiv werden.
Jede Nacht um 0:00 UTC fordert ein Datensynchronisierungsjob das Lustre-Dateisystem zur erneuten Synchronisierung mit dem angehängten S3-Bucket auf und ruft einen aktuellen Metadatenkatalog des Buckets ab. Anschließend überträgt die eigenständige EC2-Instanz diese Aktualisierungen in den OpenSearch-Dienst entsprechend dem Index dieser Region. OpenSearch Service liefert dem Kunden die notwendigen Informationen darüber, welcher Pool von Arbeitern für einen bestimmten Datensatz angefordert werden soll.
Netzwerk
Networking bildet den Kern dieser Lösung und nutzt das interne Backbone-Netzwerk von Amazon. Durch die Nutzung AWS Transit-Gateway, können wir jede der Regionen miteinander verbinden, ohne das öffentliche Internet durchqueren zu müssen. Jeder der Worker kann sich dynamisch mit dem Dask-Scheduler verbinden, sodass Data Scientists interregionale Abfragen über Dask ausführen können.
Voraussetzungen:
Das AWS CDK-Paket verwendet die Programmiersprache TypeScript. Folgen Sie den Schritten in Erste Schritte für AWS CDK um Ihre lokale Umgebung einzurichten und Ihr Entwicklungskonto zu booten (Sie müssen alle Regionen booten, die in der GitHub Repo).
Für eine erfolgreiche Bereitstellung benötigen Sie Docker installiert und läuft auf Ihrem lokalen Rechner.
Stellen Sie das AWS CDK-Paket bereit
Die Bereitstellung eines AWS CDK-Pakets ist unkompliziert. Nachdem Sie die Voraussetzungen installiert und Ihr Konto gebootet haben, können Sie mit dem Herunterladen der Codebasis fortfahren.
- Laden Sie die GitHub-Repository:
- Knotenmodule installieren:
- Stellen Sie das AWS CDK bereit:
Die Bereitstellung des Stapels kann über anderthalb Stunden dauern.
Code-Komplettlösung
In diesem Abschnitt untersuchen wir einige der Schlüsselfunktionen der Codebasis. Wenn Sie die vollständige Codebasis überprüfen möchten, lesen Sie die GitHub-Repository.
Konfigurieren und passen Sie Ihren Stack an
In der Datei bin/variables.tsfinden Sie zwei Variablendeklarationen: eine für den Client und eine für Arbeiter. Die Client-Deklaration ist ein Wörterbuch mit einem Verweis auf eine Region und einen CIDR-Bereich. Das Anpassen dieser Variablen ändert sowohl die Region als auch den CIDR-Bereich, in dem Clientressourcen bereitgestellt werden.
Die Worker-Variable kopiert dieselbe Funktionalität; Es handelt sich jedoch um eine Liste von Wörterbüchern zum Hinzufügen oder Subtrahieren von Datensätzen, die der Benutzer aufnehmen möchte. Darüber hinaus enthält jedes Wörterbuch die hinzugefügten Felder von dataset und lustreFileSystemPath. Das Dataset wird verwendet, um den Verbindungs-S3-URI anzugeben, mit dem Lustre eine Verbindung herstellen soll. Der lustreFileSystemPath Die Variable wird als Zuordnung dafür verwendet, wie der Benutzer dieses Dataset lokal auf dem Worker-Dateisystem abbilden möchte. Siehe folgenden Code:
Veröffentlichen Sie die Planer-IP dynamisch
Eine dem überregionalen Charakter dieses Projekts innewohnende Herausforderung bestand darin, eine dynamische Verbindung zwischen den Dask-Mitarbeitern und dem Planer aufrechtzuerhalten. Wie könnten wir eine IP-Adresse, die sich ändern kann, über AWS-Regionen hinweg veröffentlichen? Dies gelang uns durch den Einsatz von AWS Cloud-Karte und vpc-mit-gehosteter-zone-assoziieren. Die Service-Abstracts ermöglichen es AWS, diesen DNS-Namespace privat zu verwalten. Siehe folgenden Code:
Jupyter-Notebook-Benutzeroberfläche
Das auf SageMaker gehostete Jupyter-Notebook bietet Wissenschaftlern eine vorgefertigte Umgebung für die Bereitstellung, um sich einfach mit den geladenen Datensätzen zu verbinden und zu experimentieren. Wir haben a Lebenszyklus-Konfigurationsskript um das Notebook mit einer vorkonfigurierten Entwicklerumgebung und Beispielcodebasis bereitzustellen. Siehe folgenden Code:
Dask-Worker-Knoten
Was die Dask-Worker angeht, wird eine größere Anpassbarkeit geboten, insbesondere in Bezug auf Instanztyp, Threads pro Container und Skalierungsalarme. Standardmäßig stellt die Worker-Bereitstellung auf der Instance den Typ m5d.4xlarge bereit, wird beim Start in das Lustre-Dateisystem eingebunden und unterteilt seine Worker und Threads dynamisch in Ports. All dies ist optional anpassbar. Siehe folgenden Code:
Leistung
Um die Leistung zu bewerten, verwenden wir eine Beispielberechnung und Darstellung der Lufttemperatur bei 2 Metern basierend auf der Differenz zwischen der CMIP6-Vorhersage für einen Monat und der mittleren ERA5-Lufttemperatur für 10 Jahre. Wir haben einen Maßstab von zwei Arbeitern in jeder Region festgelegt und den Unterschied in der Zeitverkürzung bewertet, wenn zusätzliche Arbeiter hinzugefügt wurden. Theoretisch sollte es bei der Skalierung der Lösung einen produktiven wesentlichen Unterschied bei der Reduzierung der Gesamtzeit geben.
Die folgende Tabelle fasst unsere Datensatzdetails zusammen.
| Datensatz | Variablen | Festplattengröße | Xarray-Datensatzgröße | Region |
| ERA5 | 2011–2020 (120 netcdf-Dateien) | 53.5GB | 364.1 GB | us-east-1 |
| CMIP6 | 1.13GB | 0.11 GB | US-West-2 |
Die folgende Tabelle zeigt die gesammelten Ergebnisse und zeigt die Zeit (in Sekunden) für jede Berechnung und Vorhersage in drei Stufen bei der Berechnung von CMIP6-Vorhersage, ERA5 und Differenz.
| . | . | Anzahl der Arbeiter | |||
| Berechnen | Region | 2(CMIP) + 2(ERA) | 2(CMIP) + 4(ERA) | 2(CMIP) + 8(ERA) |
2 (CMIP) + 12 (ERA) |
CMIP6 (predicted_tas_regridded) |
US-West-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
us-east-1 | 1512 | 711 | 427 | 202 |
Unterschied (propogated pool) |
us-west-2 und us-east-1 | 1527 | 906 | 469 | 251 |
Das folgende Diagramm visualisiert die Leistung und Skalierung.
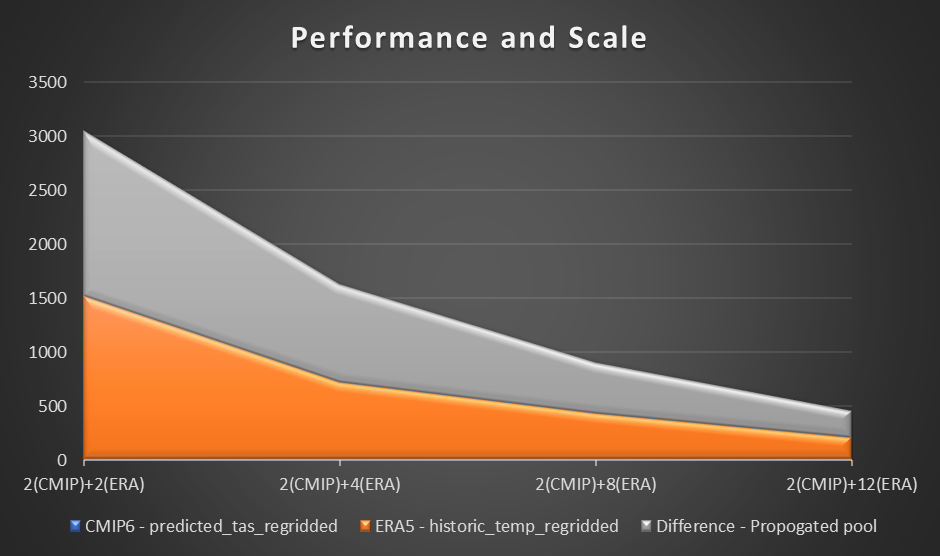
In unserem Experiment beobachteten wir eine lineare Verbesserung der Berechnung für den ERA5-Datensatz, wenn die Anzahl der Arbeiter zunahm. Mit zunehmender Zahl der Arbeiter wurden die Rechenzeiten zeitweise halbiert.
Jupyter Notizbuch
Als Teil der Einführung der Lösung stellen wir ein vorkonfiguriertes Jupyter-Notebook bereit, um beim Testen der regionsübergreifenden Dask-Lösung zu helfen. Das Notebook demonstriert die beseitigte Sorge, den regionalen Standort von Datensätzen kennen zu müssen, und fragt stattdessen einen Katalog über eine Reihe von Jupyter-Notebooks ab, die im Hintergrund ausgeführt werden.
Befolgen Sie zunächst die Anweisungen in diesem Abschnitt.
Den Code für die Notebooks finden Sie in lib/SagemakerCode wobei das primäre Notebook ist ux_notebook.ipynb. Dieses Notebook ruft andere Notebooks auf und löst Hilfsskripts aus. ux_notebook ist als Einstiegspunkt für Wissenschaftler konzipiert, ohne dass sie woanders hingehen müssen.
Öffnen Sie zunächst dieses Notebook in SageMaker, nachdem Sie das AWS CDK bereitgestellt haben. Das AWS CDK erstellt eine Notebook-Instance mit allen Dateien im Repository, die geladen und in einer gesichert werden AWS-CodeCommit Repository.
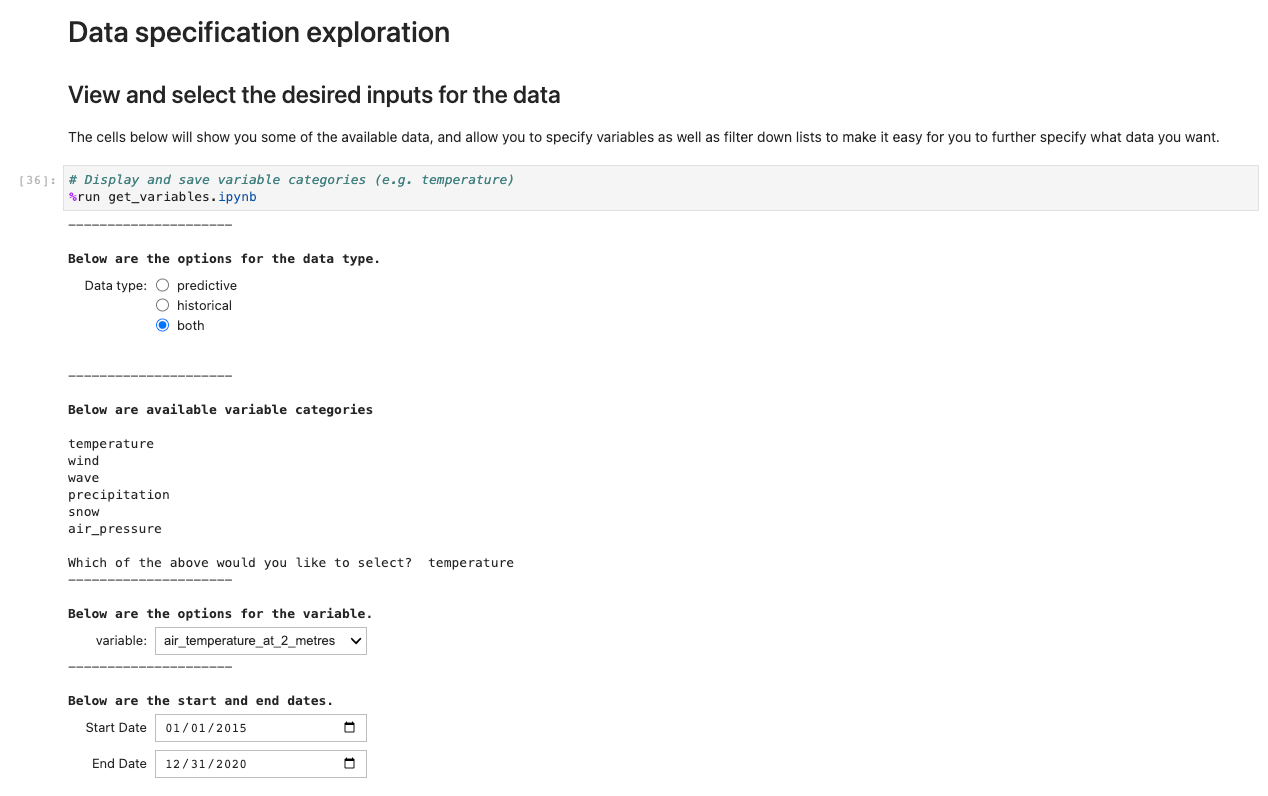
Um die Anwendung auszuführen, öffnen Sie die erste Zelle von und führen Sie sie aus ux_notebook. Diese Zelle betreibt die get_variables notebook im Hintergrund, das Sie zur Eingabe der Daten auffordert, die Sie auswählen möchten. Wir fügen ein Beispiel hinzu; Beachten Sie jedoch, dass Fragen erst angezeigt werden, nachdem die vorherige Option ausgewählt wurde. Dies ist beabsichtigt, um die Dropdown-Auswahlmöglichkeiten einzuschränken, und kann optional durch Bearbeiten der konfiguriert werden get_variables Notebook.
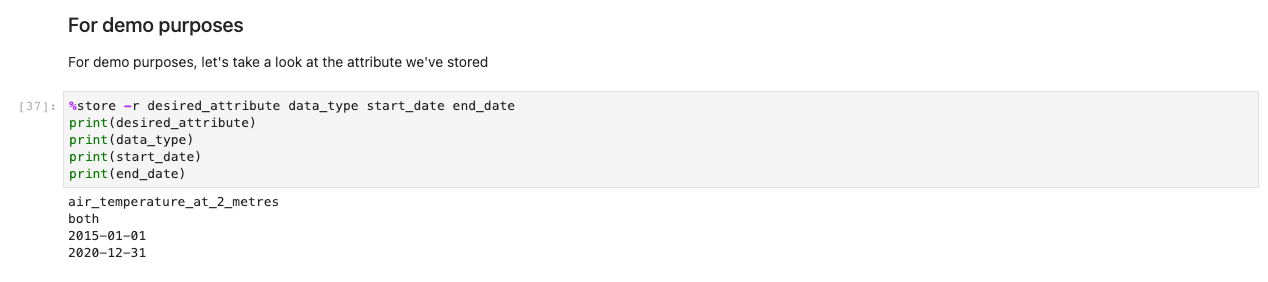
Der vorhergehende Code speichert Variablen global, sodass andere Notebooks Ihre Auswahl abrufen und laden können. Zur Demonstration sollte die nächste Zelle die Speichervariablen von vorher ausgeben.
Als nächstes erscheint eine Abfrage für weitere Datenangaben. Diese Zelle verfeinert die gewünschten Daten, indem sie die IDs von Tabellen in einem für Menschen lesbaren Format darstellt. Benutzer wählen aus, als wäre es ein Formular, aber die Titel werden Tabellen im Hintergrund zugeordnet, die dem System helfen, die entsprechenden Datensätze abzurufen.
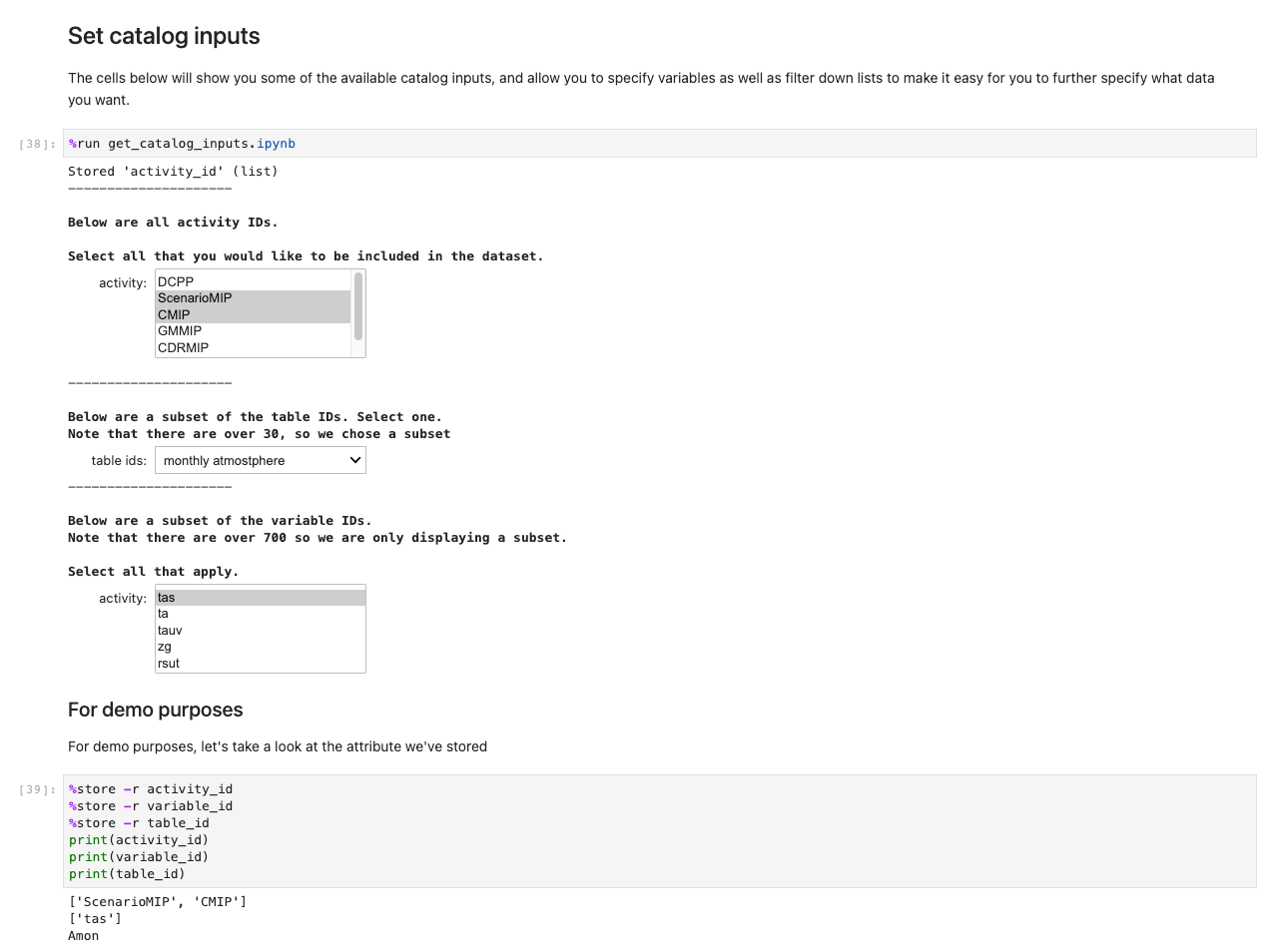
Nachdem Sie alle Ihre Auswahlen und Auswahlzellen gespeichert haben, laden Sie die Daten in die Regionen, indem Sie die Zelle in ausführen Daten abrufen kompensieren Abschnitt. Der Befehl %%capture unterdrückt unnötige Ausgaben von der get_data Notizbuch. Beachten Sie, dass Sie dies entfernen können, um die Ausgaben von anderen Notebooks zu überprüfen. Die Daten werden dann im Backend abgerufen.
Während andere Notebooks im Hintergrund laufen, ist der einzige Berührungspunkt für den Benutzer das ux_notebook. Dies soll den mühsamen Prozess des Importierens von Daten in ein Format abstrahieren, dem jeder Benutzer problemlos folgen kann.
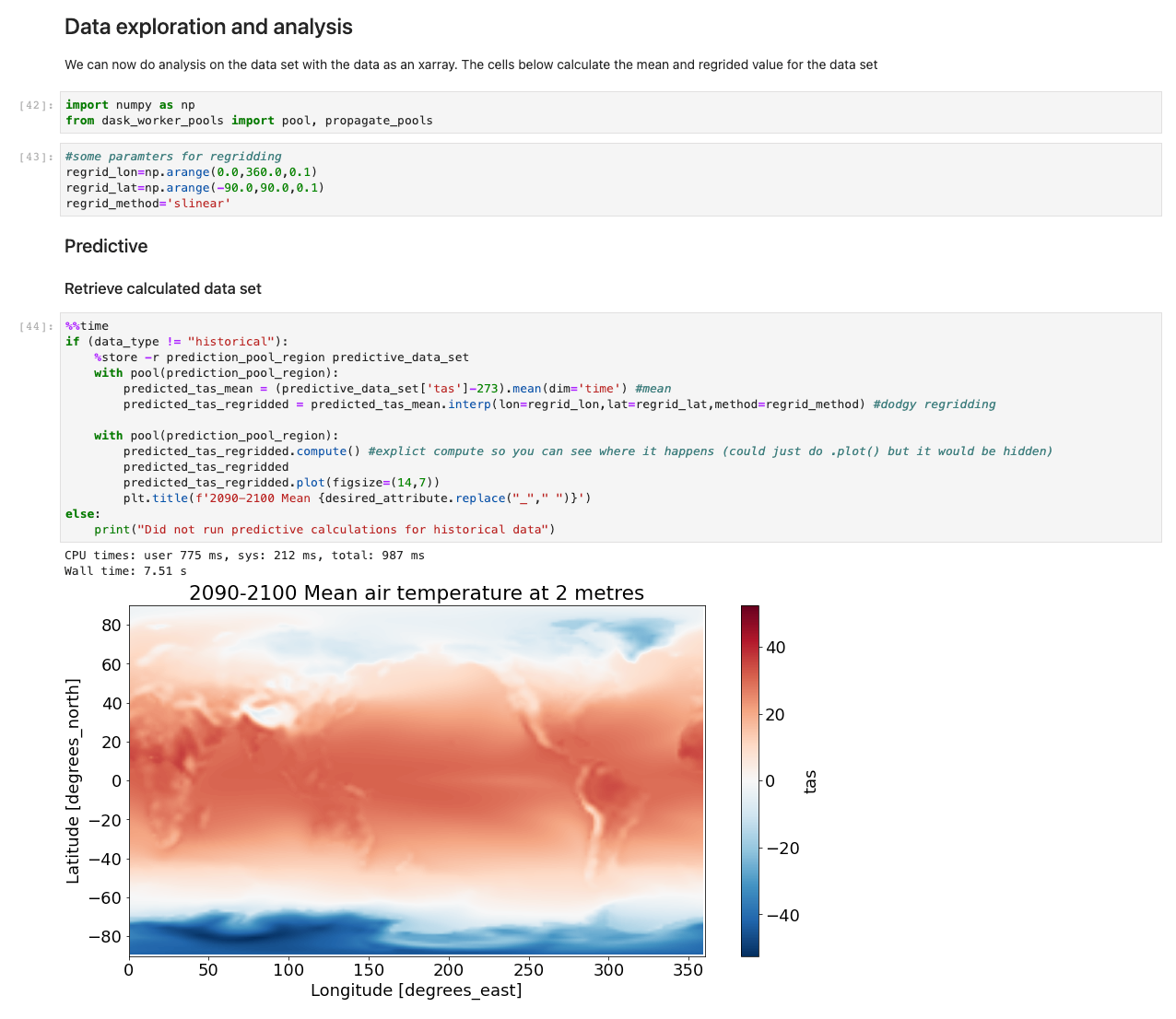
Wenn die Daten jetzt geladen sind, können wir damit beginnen, damit zu interagieren. Die folgenden Zellen sind Beispiele für Berechnungen, die Sie mit Wetterdaten ausführen können. Verwenden xarrays, importieren, berechnen und plotten wir diese Datensätze.
Unser Beispiel zeigt eine Darstellung von Vorhersagedaten, die Daten abrufen, die Berechnung ausführen und die Ergebnisse in weniger als 7.5 Sekunden darstellen – Größenordnungen schneller als ein typischer Ansatz.
Unter der Haube
Die Notizbücher get_catalog_input und get_variables die Bibliothek benutzen ipywidgets zum Anzeigen von Widgets wie Dropdown-Menüs und Auswahlfeldern. Diese Optionen werden global mit dem %%store-Befehl gespeichert, sodass von der aus auf sie zugegriffen werden kann ux_notebook. Eine der Optionen fragt Sie, ob Sie Verlaufsdaten, Vorhersagedaten oder beides wünschen. Diese Variable wird an die übergeben get_data notebook, um zu bestimmen, welche nachfolgenden Notebooks ausgeführt werden sollen.
Das get_data notebook ruft zuerst die gemeinsam genutzte OpenSearch-Dienstdomäne ab, in der gespeichert ist AWS Systems Manager-Parameterspeicher. Diese Domäne ermöglicht es unserem Notebook, eine Abfrage zum Sammeln von Informationen auszuführen, die angeben, wo die ausgewählten Datensätze regional gespeichert werden. Wenn sich diese Datensätze regional befinden, unternimmt das Notebook einen Verbindungsversuch mit dem Dask-Scheduler und leitet die vom OpenSearch-Dienst gesammelten Informationen weiter. Der Dask-Scheduler wiederum kann Arbeiter in den richtigen Regionen anfordern.
So passen Sie an und entwickeln sich weiter
Diese Notebooks sollen ein Beispiel dafür sein, wie Sie eine Möglichkeit für Benutzer schaffen können, mit den Daten zu kommunizieren und mit ihnen zu interagieren. Das Notizbuch in diesem Beitrag dient als Veranschaulichung dessen, was möglich ist, und wir laden Sie ein, weiter auf der Lösung aufzubauen, um die Benutzerinteraktion weiter zu verbessern. Der Kern dieser Lösung ist die Backend-Technologie, aber ohne einen Mechanismus zur Interaktion mit diesem Backend werden Benutzer das volle Potenzial der Lösung nicht ausschöpfen.
Löschen Sie die Ressourcen, um zukünftige Gebühren zu vermeiden. Lassen Sie uns unsere bereitgestellte Lösung mit dem folgenden Befehl zerstören:
Zusammenfassung
Dieser Beitrag zeigt die interregionale Erweiterung von Dask auf AWS und eine mögliche Integration mit öffentlichen Datensätzen auf AWS. Die Lösung wurde als generisches Muster erstellt, und weitere Datensätze können geladen werden, um High-I/O-Analysen für komplexe Daten zu beschleunigen.
Daten verändern jeden Bereich und jedes Unternehmen. Da die Daten jedoch schneller wachsen, als die meisten Unternehmen nachverfolgen können, ist das Sammeln von Daten und die Gewinnung von Wert aus diesen Daten eine Herausforderung. Eine moderne Datenstrategie kann Ihnen helfen, mit Daten bessere Geschäftsergebnisse zu erzielen. AWS bietet die umfassendste Reihe von Services für die End-to-End-Datenreise, um Ihnen dabei zu helfen, den Wert Ihrer Daten zu erschließen und sie in Erkenntnisse umzuwandeln.
Um mehr über die verschiedenen Möglichkeiten zur Nutzung Ihrer Daten in der Cloud zu erfahren, besuchen Sie die AWS Big Data-Blog. Wir laden Sie außerdem ein, diesen Beitrag mit Ihren Gedanken zu kommentieren und ob dies eine Lösung ist, die Sie ausprobieren möchten.
Über die Autoren
 Patrick O'Connor ist ein WWSO-Prototyping-Ingenieur mit Sitz in London. Er ist ein kreativer Problemlöser, der sich an eine Vielzahl von Technologien wie IoT, serverlose Technologie, 3D-Raumtechnologie und ML/KI anpassen lässt, zusammen mit einer unerbittlichen Neugier, wie Technologie alltägliche Ansätze weiterentwickeln kann.
Patrick O'Connor ist ein WWSO-Prototyping-Ingenieur mit Sitz in London. Er ist ein kreativer Problemlöser, der sich an eine Vielzahl von Technologien wie IoT, serverlose Technologie, 3D-Raumtechnologie und ML/KI anpassen lässt, zusammen mit einer unerbittlichen Neugier, wie Technologie alltägliche Ansätze weiterentwickeln kann.
 Chakra Nagarajan ist eine Principal Machine Learning Prototyping SA mit 21 Jahren Erfahrung in maschinellem Lernen, Big Data und Hochleistungsrechnen. In seiner derzeitigen Funktion hilft er Kunden bei der Lösung realer komplexer Geschäftsprobleme, indem er Prototypen mit End-to-End-KI/ML-Lösungen in Cloud- und Edge-Geräten erstellt. Seine ML-Spezialisierung umfasst Computer Vision, Verarbeitung natürlicher Sprache, Zeitreihenprognose und Personalisierung.
Chakra Nagarajan ist eine Principal Machine Learning Prototyping SA mit 21 Jahren Erfahrung in maschinellem Lernen, Big Data und Hochleistungsrechnen. In seiner derzeitigen Funktion hilft er Kunden bei der Lösung realer komplexer Geschäftsprobleme, indem er Prototypen mit End-to-End-KI/ML-Lösungen in Cloud- und Edge-Geräten erstellt. Seine ML-Spezialisierung umfasst Computer Vision, Verarbeitung natürlicher Sprache, Zeitreihenprognose und Personalisierung.
 Val Cohen ist ein leitender WWSO-Prototyping-Ingenieur mit Sitz in London. Von Natur aus Problemlöserin, schreibt Val gerne Code, um Prozesse zu automatisieren, kundenorientierte Tools zu entwickeln und Infrastrukturen für verschiedene Anwendungen für ihren globalen Kundenstamm zu schaffen. Val hat Erfahrung mit einer Vielzahl von Technologien, wie z. B. Front-End-Webentwicklung, Back-End-Arbeit und KI/ML.
Val Cohen ist ein leitender WWSO-Prototyping-Ingenieur mit Sitz in London. Von Natur aus Problemlöserin, schreibt Val gerne Code, um Prozesse zu automatisieren, kundenorientierte Tools zu entwickeln und Infrastrukturen für verschiedene Anwendungen für ihren globalen Kundenstamm zu schaffen. Val hat Erfahrung mit einer Vielzahl von Technologien, wie z. B. Front-End-Webentwicklung, Back-End-Arbeit und KI/ML.
 Niall Robinson ist Head of Product Futures im UK Met Office. Er und sein Team erkunden neue Möglichkeiten, wie das Met Office durch Produktinnovation und strategische Partnerschaften Mehrwert schaffen kann. Er hat eine abwechslungsreiche Karriere hinter sich und leitete ein multidisziplinäres Forschungs- und Entwicklungsteam für Informatik, akademische Forschung in der Datenwissenschaft und Feldwissenschaftler sowie Erfahrung als Klimamodellierer.
Niall Robinson ist Head of Product Futures im UK Met Office. Er und sein Team erkunden neue Möglichkeiten, wie das Met Office durch Produktinnovation und strategische Partnerschaften Mehrwert schaffen kann. Er hat eine abwechslungsreiche Karriere hinter sich und leitete ein multidisziplinäres Forschungs- und Entwicklungsteam für Informatik, akademische Forschung in der Datenwissenschaft und Feldwissenschaftler sowie Erfahrung als Klimamodellierer.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Die Zukunft prägen mit Adryenn Ashley. Hier zugreifen.
- Kaufen und verkaufen Sie Anteile an PRE-IPO-Unternehmen mit PREIPO®. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- :hast
- :Ist
- :Wo
- $UP
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- Fähigkeit
- Fähig
- Über Uns
- oben
- ABSTRACT
- Abstracts
- akademisch
- akademische Forschung
- beschleunigen
- beschleunigend
- Zugang
- Zugriff
- unterbringen
- erreichen
- Konto
- Erreicht
- über
- passt sich an
- hinzugefügt
- Hinzufügen
- Zusätzliche
- zusätzlich
- Adresse
- Adressierung
- Fügt
- Administratoren
- angenommen
- Adoption
- Nach der
- AI / ML
- LUFT
- Alle
- Zulassen
- erlaubt
- entlang
- ebenfalls
- Amazon
- Amazon EC2
- an
- Analyse
- und
- jedem
- erscheinen
- Anwendung
- Anwendungen
- Ansatz
- Ansätze
- angemessen
- Architektur
- SIND
- AS
- At
- Atmosphäre
- atmosphärisch
- automatisieren
- vermeiden
- AWS
- AWS-Kunde
- Backbone (Rückgrat)
- unterstützt
- Backend
- Hintergrund
- Balance
- Base
- basierend
- BE
- werden
- war
- Bevor
- Sein
- unten
- Benchmark
- Besser
- zwischen
- Big
- Big Data
- Bootstrap
- beide
- Bringing
- Gebrochen
- bauen
- Building
- erbaut
- eingebaut
- Geschäft
- aber
- by
- Berechnen
- rufen Sie uns an!
- namens
- Aufruf
- Aufrufe
- CAN
- Fähigkeiten
- fähig
- Karriere
- Katalog
- CD
- Die Zellen
- challenges
- herausfordernd
- Übernehmen
- Ändern
- berechnen
- Gebühren
- Entscheidungen
- Die Durchblutung
- Auftraggeber
- Klimaschutz
- näher
- Cloud
- Cluster
- CO
- Code
- Codebasis
- Zusammenarbeit
- Das Sammeln
- wie die
- kommt
- Kommen
- Kommentar
- community
- Unternehmen
- abschließen
- Komplex
- Komponenten
- Bestehend
- Berechnung
- Berechnen
- Computer
- Computer Vision
- Computing
- Konfiguration
- Vernetz Dich
- Sie
- Sich zusammenschliessen
- Verbindung
- KUNDEN
- Verbrauch
- Container
- enthält
- fortsetzen
- weiter
- Kopien
- Kernbereich
- und beseitigen Muskelschwäche
- Kosten
- kostengünstiger
- könnte
- gekoppelt
- CPU
- erstellen
- schafft
- Kreativ (Creative)
- kritischem
- Ernte
- Cross
- Neugier
- Strom
- Original
- Kunde
- Kunden
- anpassbare
- anpassen
- Unterricht
- Armaturenbrett
- technische Daten
- Datenwissenschaft
- Datenstrategie
- Datensätze
- Tag
- Jahrzehnte
- Entscheidungen
- Standard
- Demand
- zeigt
- einsetzen
- Einsatz
- Einsatz
- setzt ein
- entworfen
- zerstören
- detailliert
- Details
- Bestimmen
- entwickeln
- Entwickler:in / Unternehmen
- Entwicklung
- Geräte
- Unterschied
- behindert
- Entdeckung
- Display
- verteilt
- Verteiltes rechnen
- dns
- Docker
- Domain
- nach unten
- dynamisch
- dynamisch
- jeder
- erleichtern
- leicht
- Edge
- Bearbeitung
- effizient
- anderswo
- ermöglichen
- End-to-End
- Energie
- Engagement
- Ingenieur
- Eintrag
- Arbeitsumfeld
- Äquivalent
- Era
- geschätzt
- Äther (ETH)
- Jedes
- jeden Tag
- jeden Tag
- entwickelt sich
- Beispiel
- Beispiele
- ERFAHRUNGEN
- Experiment
- Expertise
- ERKUNDEN
- exportieren
- ausgesetzt
- Erweiterung
- beschleunigt
- Merkmal
- Eigenschaften
- Feld
- Felder
- Reichen Sie das
- Mappen
- Finden Sie
- Vorname
- konzentriert
- folgen
- Folgende
- Nahrung,
- Aussichten für
- unten stehende Formular
- Format
- Formen
- gefunden
- Gründung
- Unser Ansatz
- Gerüste
- Frei
- für
- Früchte tragen
- voller
- Funktionalität
- weiter
- Zukunft
- Futures
- Allgemeines
- Generation
- bekommen
- bekommen
- Git
- Global
- globales Netzwerk
- Global
- Globus
- gehen
- Graph
- mehr
- Gitter
- Wachsen Sie über sich hinaus
- persönlichem Wachstum
- hätten
- Hälfte
- halbiert
- Haben
- he
- ganzer
- Hilfe
- hilft
- hier (auf dänisch)
- GUTE
- Hohe Leistungsfähigkeit
- Highlights
- seine
- historisch
- Gastgeber
- gehostet
- Stunde
- Ultraschall
- Hilfe
- aber
- HTML
- HTTPS
- für Menschen lesbar
- hunderte
- Leerlauf
- ids
- if
- zeigt
- importieren
- Einfuhr
- zu unterstützen,
- Verbesserung
- in
- das
- Dazu gehören
- hat
- Index
- zeigen
- informieren
- Information
- Infrastruktur
- inhärent
- Innovation
- Varianten des Eingangssignals:
- Unsicherheit
- Einblick
- inspirierte
- installieren
- Instanz
- beantragen müssen
- Anleitung
- Integration
- Vorsätzlich
- interagieren
- Interaktion
- Schnittstelle
- intern
- Internet
- in
- einladen
- iot
- IP
- IP Address
- Probleme
- IT
- SEINE
- Job
- Reise
- jpg
- Jupyter Notizbuch
- Behalten
- Wesentliche
- Wissen
- Sprache
- grosse
- Nachname
- Latency
- starten
- führenden
- LERNEN
- lernen
- Bibliothek
- Lebenszyklus
- Gefällt mir
- Linking
- Liste
- Belastung
- aus einer regionalen
- örtlich
- located
- Standorte
- London
- Maschine
- Maschinelles Lernen
- Dur
- um
- verwalten
- Manager
- Managed
- Karte
- Mapping
- Masse
- Massenadoption
- Ihres Materials
- Kann..
- bedeuten
- Mechanismus
- Metadaten
- Millionen
- ML
- Modell
- modern
- Module
- Monat
- monatlich
- monatliche Daten
- mehr
- vor allem warme
- MOUNT
- multidisziplinär
- Name
- National
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- Natur
- notwendig,
- Need
- benötigen
- Netzwerk
- Neu
- weiter
- Nacht-
- Knoten
- Fiber Node
- Notizbuch
- Laptops
- jetzt an
- Anzahl
- Zahlen
- of
- bieten
- Office
- on
- EINEM
- einzige
- XNUMXh geöffnet
- offene Daten
- Open-Source-
- Open-Source-Code
- Betriebs-
- Option
- Optionen
- or
- Orchesterbearbeitung
- Organisationen
- Andere
- UNSERE
- Ergebnisse
- Möglichkeiten für das Ausgangssignal:
- übrig
- Gesamt-
- Paket
- Parameter
- Teil
- besondere
- besonders
- Partnerschaften
- Bestanden
- Bestehen
- Schnittmuster
- Leistung
- Zeiträume
- Personalisierung
- Petabyte
- Phase
- Plan
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Points
- Pool
- Häfen
- möglich
- Post
- Potenzial
- Werkzeuge
- größte treibende
- Praxis
- Prognose
- Prognosen
- Voraussetzungen
- früher
- primär
- Principal
- privat
- Aufgabenstellung:
- Probleme
- Prozessdefinierung
- anpassen
- Verarbeitung
- Produziert
- Produkt
- Produktinnovation
- produktiv
- Programm
- Programmierung
- Projekt
- Prototypen
- Prototyping
- die
- vorausgesetzt
- bietet
- Bereitstellung
- Öffentlichkeit
- veröffentlichen
- veröffentlicht
- Pullover
- Abfragen
- Fragen
- F&E
- Angebot
- lieber
- fertig
- realen Welt
- realisieren
- Veteran
- Reduzierung
- Reduktion
- Region
- regional
- Regionen
- unerbittlich
- bleibt bestehen
- entfernen
- Entfernt
- Quelle
- representiert
- Forschungsprojekte
- Downloads
- diejenigen
- Die Ergebnisse
- Rollen
- Führen Sie
- Laufen
- SA
- Safe
- sagemaker
- gleich
- Speichern
- skalierbaren
- Skalieren
- Waage
- Skalierung
- Wissenschaft
- Wissenschaftler
- Wissenschaftler
- Skripte
- Sekunden
- Abschnitt
- sehen
- gesehen
- Segmente
- ausgewählt
- Auswahl
- Senior
- Modellreihe
- Serverlos
- dient
- Lösungen
- kompensieren
- Teilen
- von Locals geführtes
- sollte
- erklären
- präsentiert
- Konzerte
- Einfacher
- einfach
- sechste
- langsam
- So
- Lösung
- Lösungen
- LÖSEN
- einige
- Quelle
- räumlich
- speziell
- Spezifikationen
- angegeben
- Patenschaftsprogramme
- Stapel
- Stufen
- standalone
- Anfang
- begonnen
- bleiben
- Shritte
- Lagerung
- speichern
- gelagert
- Läden
- einfach
- Strategisch
- Strategische Partnerschaften
- Strategie
- Folge
- Anschließend
- erfolgreich
- so
- Oberfläche
- Schwall
- Nachhaltigkeit
- nachhaltiger
- System
- Systeme und Techniken
- Tabelle
- Nehmen
- Team
- Tech
- Technologies
- Technologie
- Test
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- die Informationen
- Die Quelle
- Großbritannien
- die Welt
- ihr
- dann
- Dort.
- damit
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- diejenigen
- nach drei
- Entwickeln Sie
- Durch
- Durchsatz
- Zeit
- Zeitfolgen
- mal
- Titel
- zu
- heute
- gemeinsam
- Werkzeuge
- verfolgen sind
- Tracking
- privaten Transfer
- Transformieren
- Transit
- Auslösen
- WENDE
- XNUMX
- tippe
- Typoskript
- typisch
- Uk
- für
- öffnen
- nicht nachhaltig
- auf dem neusten Stand
- Updates
- auf
- URI
- Anwendungsbereich
- -
- benutzt
- Mitglied
- Nutzer
- Verwendung von
- UTC
- Verwendung
- VAL
- Wert
- Vielfalt
- verschiedene
- Seh-
- Besuchen Sie
- Volumen
- wollen
- will
- warm
- wurde
- Weg..
- Wege
- we
- Wetter
- Netz
- Web-Entwicklung
- waren
- ob
- welche
- breit
- Große Auswahl
- werden wir
- Wünsche
- mit
- ohne
- Arbeiten
- Arbeiter
- Arbeiter
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- Sorgen
- würde
- Schreiben
- Jahr
- noch
- Ausbeute
- U
- Ihr
- Zephyrnet