Organisationen aller Branchen haben komplexe Datenverarbeitungsanforderungen für ihre analytischen Anwendungsfälle in verschiedenen Analysesystemen, wie z Datenseen auf AWS, Data Warehouse (Amazon RedShift), suchen (Amazon OpenSearch-Dienst), NoSQL (Amazon DynamoDB), maschinelles Lernen (Amazon Sage Maker), und mehr. Analytics-Experten haben die Aufgabe, aus den in diesen verteilten Systemen gespeicherten Daten einen Mehrwert zu ziehen, um bessere, sichere und kostenoptimierte Erlebnisse für ihre Kunden zu schaffen. Beispielsweise versuchen digitale Medienunternehmen, Datensätze in internen und externen Datenbanken zu kombinieren und zu verarbeiten, um einheitliche Ansichten ihrer Kundenprofile zu erstellen, Ideen für innovative Funktionen anzuregen und das Plattform-Engagement zu steigern.
In diesen Szenarien nutzen Kunden ein serverloses Datenintegrationsangebot AWS-Kleber als Kernkomponente zur Verarbeitung und Katalogisierung von Daten. AWS Glue ist gut in AWS-Services und Partnerprodukte integriert und bietet Low-Code/No-Code-Optionen zum Extrahieren, Transformieren und Laden (ETL), um Analysen, maschinelles Lernen (ML) oder Anwendungsentwicklungs-Workflows zu ermöglichen. AWS Glue ETL-Jobs können eine Komponente in einer komplexeren Pipeline sein. Die Orchestrierung des Ablaufs und die Verwaltung der Abhängigkeiten zwischen diesen Komponenten ist eine Schlüsselfunktion einer Datenstrategie. Von Amazon verwaltete Workflows für Apache Airflows (Amazon MWAA) orchestriert Datenpipelines mithilfe verteilter Technologien, einschließlich lokaler Ressourcen, AWS-Services und Komponenten von Drittanbietern.
In diesem Beitrag zeigen wir, wie Sie die Überwachung eines von Airflow orchestrierten AWS Glue-Auftrags mithilfe der neuesten Funktionen von Amazon MWAA vereinfachen können.
Lösungsübersicht
In diesem Beitrag wird Folgendes besprochen:
- So aktualisieren Sie eine Amazon MWAA-Umgebung auf Version 2.4.3.
- So orchestrieren Sie einen AWS Glue-Job über einen Airflow Gerichteter azyklischer Graph (DAG).
- Die Observability-Verbesserungen des Airflow Amazon-Anbieterpakets in Amazon MWAA. Sie können jetzt Ausführungsprotokolle von AWS Glue-Jobs in der Airflow-Konsole konsolidieren, um die Fehlerbehebung bei Datenpipelines zu vereinfachen. Die Amazon MWAA-Konsole wird zu einer einzigen Referenz zum Überwachen und Analysieren von AWS Glue-Auftragsausführungen. Bisher mussten Support-Teams darauf zugreifen AWS-Managementkonsole und ergreifen Sie manuelle Schritte für diese Sichtbarkeit. Diese Funktion ist standardmäßig ab Amazon MWAA Version 2.4.3 verfügbar.
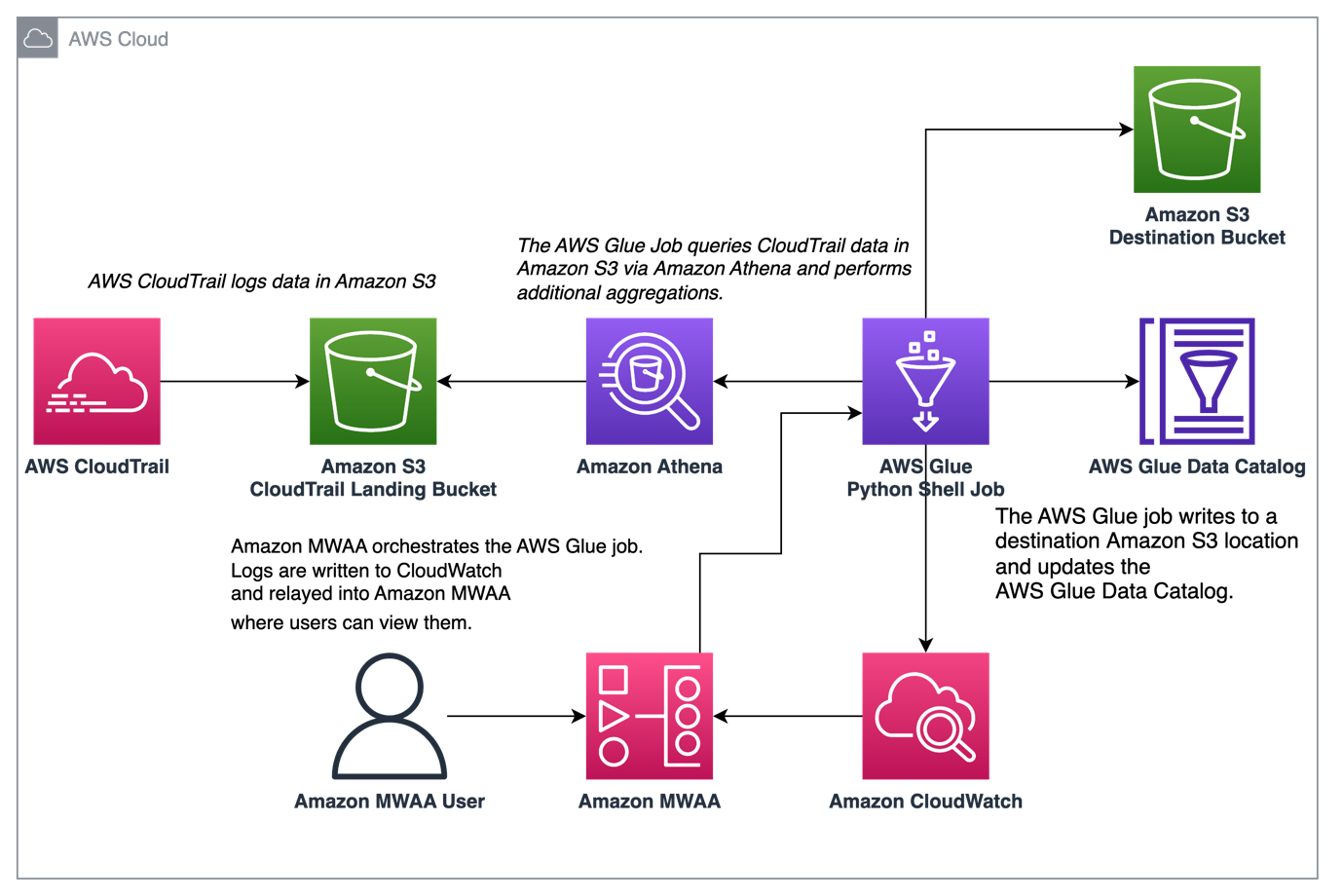
Das folgende Diagramm zeigt unsere Lösungsarchitektur.
Voraussetzungen:
Sie benötigen folgende Voraussetzungen:
Richten Sie die Amazon MWAA-Umgebung ein
Anweisungen zum Erstellen Ihrer Umgebung finden Sie unter Erstellen Sie eine Amazon MWAA-Umgebung. Für bestehende Benutzer empfehlen wir ein Upgrade auf Version 2.4.3, um von den in diesem Beitrag vorgestellten Observability-Verbesserungen zu profitieren.
Die Schritte zum Upgrade von Amazon MWAA auf Version 2.4.3 unterscheiden sich je nachdem, ob die aktuelle Version 1.10.12 oder 2.2.2 ist. Wir diskutieren beide Optionen in diesem Beitrag.
Voraussetzungen für die Einrichtung einer Amazon MWAA-Umgebung
Sie müssen folgende Voraussetzungen erfüllen:
Upgrade von Version 1.10.12 auf 2.4.3
Wenn Sie die Amazon MWAA-Version verwenden 1.10.12, beziehen auf Migration zu einer neuen Amazon MWAA-Umgebung auf 2.4.3 aktualisieren.
Upgrade von Version 2.0.2 oder 2.2.2 auf 2.4.3
Wenn Sie die Amazon MWAA-Umgebung Version 2.2.2 oder niedriger verwenden, führen Sie die folgenden Schritte aus:
- Erstellen Sie „requirements.txt“ für alle benutzerdefinierten Abhängigkeiten mit spezifischen Versionen, die für Ihre DAGs erforderlich sind.
- Laden Sie die Datei auf Amazon S3 hoch an der entsprechenden Stelle, an der die Amazon MWAA-Umgebung auf die Datei „requirements.txt“ für die Installation von Abhängigkeiten verweist.
- Befolgen Sie die Schritte in Migration zu einer neuen Amazon MWAA-Umgebung und wählen Sie Version 2.4.3.
Aktualisieren Sie Ihre DAGs
Kunden, die ein Upgrade von einer älteren Amazon MWAA-Umgebung durchgeführt haben, müssen möglicherweise Aktualisierungen an vorhandenen DAGs vornehmen. In der Airflow-Version 2.4.3 verwendet die Airflow-Umgebung standardmäßig die Amazon-Anbieterpaketversion 6.0.0. Dieses Paket kann einige potenziell wichtige Änderungen enthalten, z. B. Änderungen an Operatornamen. Zum Beispiel die AWSGlueJobOperator wurde veraltet und durch ersetzt GlueJobOperator. Um die Kompatibilität aufrechtzuerhalten, aktualisieren Sie Ihre Airflow-DAGs, indem Sie alle veralteten oder nicht unterstützten Operatoren aus früheren Versionen durch die neuen ersetzen. Führen Sie die folgenden Schritte aus:
- Navigieren Amazon AWS-Betreiber.
- Wählen Sie die entsprechende Version aus, die in Ihrer Amazon MWAA-Instanz installiert ist (standardmäßig 6.0.0), um eine Liste der unterstützten Airflow-Operatoren zu finden.
- Nehmen Sie die erforderlichen Änderungen am vorhandenen DAG-Code vor und laden Sie die geänderten Dateien an den DAG-Speicherort in Amazon S3 hoch.
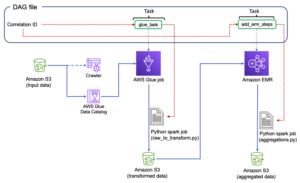
Orchestrieren Sie den AWS Glue-Auftrag von Airflow aus
In diesem Abschnitt werden die Details der Orchestrierung eines AWS Glue-Auftrags innerhalb von Airflow-DAGs behandelt. Airflow erleichtert die Entwicklung von Datenpipelines mit Abhängigkeiten zwischen heterogenen Systemen wie lokalen Prozessen, externen Abhängigkeiten, anderen AWS-Diensten und mehr.
Orchestrieren Sie die CloudTrail-Protokollaggregation mit AWS Glue und Amazon MWAA
In diesem Beispiel gehen wir einen Anwendungsfall der Verwendung von Amazon MWAA durch, um einen AWS Glue Python Shell-Job zu orchestrieren, der aggregierte Metriken basierend auf CloudTrail-Protokollen beibehält.
CloudTrail ermöglicht Einblick in AWS-API-Aufrufe, die in Ihrem AWS-Konto durchgeführt werden. Ein häufiger Anwendungsfall für diese Daten wäre die Erfassung von Nutzungsmetriken zu Auftraggebern, die aus Prüfungs- und Regulierungsgründen auf die Ressourcen Ihres Kontos zugreifen.
Während CloudTrail-Ereignisse protokolliert werden, werden sie als JSON-Dateien in Amazon S3 bereitgestellt, die für analytische Abfragen nicht ideal sind. Wir möchten diese Daten aggregieren und als Parquet-Dateien speichern, um eine optimale Abfrageleistung zu ermöglichen. Als ersten Schritt können wir Athena verwenden, um die erste Abfrage der Daten durchzuführen, bevor wir in unserem AWS Glue-Job weitere Aggregationen durchführen. Weitere Informationen zum Erstellen einer AWS Glue Data Catalog-Tabelle finden Sie unter Erstellen der Tabelle für CloudTrail-Protokolle in Athena mithilfe der Partitionsprojektion Daten. Nachdem wir die Daten über Athena untersucht und entschieden haben, welche Metriken wir in aggregierten Tabellen behalten möchten, können wir einen AWS Glue-Job erstellen.
Erstellen Sie eine CloudTrail-Tabelle in Athena
Zunächst müssen wir in unserem Datenkatalog eine Tabelle erstellen, die die Abfrage von CloudTrail-Daten über Athena ermöglicht. Die folgende Beispielabfrage erstellt eine Tabelle mit zwei Partitionen für die Region und das Datum (genannt snapshot_date). Ersetzen Sie unbedingt die Platzhalter für Ihren CloudTrail-Bucket, Ihre AWS-Konto-ID und Ihren CloudTrail-Tabellennamen:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Führen Sie die vorherige Abfrage auf der Athena-Konsole aus und notieren Sie sich den Tabellennamen und die AWS Glue Data Catalog-Datenbank, in der sie erstellt wurde. Wir verwenden diese Werte später im Airflow DAG-Code.
Beispiel für einen AWS Glue-Jobcode
Der folgende Code ist ein Beispiel AWS Glue Python Shell-Job das macht folgendes:
- Akzeptiert Argumente (die wir von unserem Amazon MWAA DAG weitergeben) zu den zu verarbeitenden Tagesdaten
- verwendet die AWS SDK für Pandas um eine Athena-Abfrage auszuführen, um die erste Filterung der CloudTrail-JSON-Daten außerhalb von AWS Glue durchzuführen
- Verwendet Pandas, um einfache Aggregationen der gefilterten Daten durchzuführen
- Gibt die aggregierten Daten in einer Tabelle an den AWS Glue Data Catalog aus
- Verwendet während der Verarbeitung Protokollierung, die in Amazon MWAA sichtbar ist
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Im Folgenden sind einige wichtige Vorteile dieses AWS Glue-Jobs aufgeführt:
- Wir verwenden eine Athena-Abfrage, um sicherzustellen, dass die anfängliche Filterung außerhalb unseres AWS Glue-Jobs erfolgt. Daher reicht ein Python-Shell-Job mit minimaler Rechenleistung immer noch aus, um einen großen CloudTrail-Datensatz zu aggregieren.
- Wir sorgen für die Analytics-Bibliotheksset-Option wird beim Erstellen unseres AWS Glue-Jobs aktiviert, um die AWS SDK for Pandas-Bibliothek zu verwenden.
Erstellen Sie einen AWS Glue-Auftrag
Führen Sie die folgenden Schritte aus, um Ihren AWS Glue-Auftrag zu erstellen:
- Kopieren Sie das Skript aus dem vorherigen Abschnitt und speichern Sie es in einer lokalen Datei. Für diesen Beitrag heißt die Datei
script.py. - Wählen Sie in der AWS Glue-Konsole aus ETL-Jobs im Navigationsbereich.
- Erstellen Sie einen neuen Job und wählen Sie ihn aus Python-Shell-Skripteditor.
- Auswählen Laden Sie ein vorhandenes Skript hoch und bearbeiten Sie es und laden Sie die Datei hoch, die Sie lokal gespeichert haben.
- Auswählen Erstellen.

- Auf dem Jobdetails Geben Sie auf der Registerkarte einen Namen für Ihren AWS Glue-Auftrag ein.
- Aussichten für IAM-Rolle, wählen Sie eine vorhandene Rolle aus oder erstellen Sie eine neue Rolle, die über die erforderlichen Berechtigungen für Amazon S3, AWS Glue und Athena verfügt. Die Rolle muss die zuvor erstellte CloudTrail-Tabelle abfragen und in einen Ausgabespeicherort schreiben.
Sie können den folgenden Beispielrichtliniencode verwenden. Ersetzen Sie die Platzhalter durch Ihren CloudTrail-Protokoll-Bucket, den Namen der Ausgabetabelle, die AWS Glue-Ausgabedatenbank, den S3-Ausgabe-Bucket, den Namen der CloudTrail-Tabelle, die AWS Glue-Datenbank mit der CloudTrail-Tabelle und Ihre AWS-Konto-ID.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Aussichten für Python-Version, wählen Python 3.9.
- Auswählen Laden Sie gängige Analysebibliotheken.
- Aussichten für Datenverarbeitungseinheiten, wählen 1 DPU.
- Belassen Sie die anderen Optionen als Standard oder passen Sie sie nach Bedarf an.

- Auswählen Speichern um Ihre Jobkonfiguration zu speichern.
Konfigurieren Sie einen Amazon MWAA DAG, um den AWS Glue-Auftrag zu orchestrieren
Der folgende Code ist für einen DAG, der den von uns erstellten AWS Glue-Auftrag orchestrieren kann. Wir nutzen die folgenden Hauptfunktionen in diesem DAG:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Erhöhen Sie die Beobachtbarkeit von AWS Glue-Jobs in Amazon MWAA
Die AWS Glue-Jobs schreiben Protokolle in Amazon CloudWatch. Mit den jüngsten Verbesserungen der Beobachtbarkeit des Amazon-Anbieterpakets von Airflow sind diese Protokolle jetzt in Airflow-Aufgabenprotokolle integriert. Diese Konsolidierung bietet Airflow-Benutzern eine durchgängige Sichtbarkeit direkt in der Airflow-Benutzeroberfläche, sodass keine Suche in CloudWatch oder der AWS Glue-Konsole erforderlich ist.
Um diese Funktion zu verwenden, stellen Sie sicher, dass die der Amazon MWAA-Umgebung zugeordnete IAM-Rolle über die folgenden Berechtigungen zum Abrufen und Schreiben der erforderlichen Protokolle verfügt:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Wenn verbose=true, werden die AWS Glue-Auftragsausführungsprotokolle in den Airflow-Aufgabenprotokollen angezeigt. Der Standardwert ist falsch. Weitere Informationen finden Sie unter Parameter.
Wenn diese Option aktiviert ist, lesen die DAGs aus dem CloudWatch-Protokollstream des AWS Glue-Auftrags und leiten sie an die Airflow DAG AWS Glue-Auftragsschrittprotokolle weiter. Dies bietet detaillierte Einblicke in die Ausführung eines AWS Glue-Jobs in Echtzeit über die DAG-Protokolle. Beachten Sie, dass AWS Glue-Jobs eine Ausgabe- und Fehler-CloudWatch-Protokollgruppe basierend auf STDOUT bzw. STDERR des Jobs generieren. Alle Protokolle in der Ausgabeprotokollgruppe und Ausnahme- oder Fehlerprotokolle aus der Fehlerprotokollgruppe werden an Amazon MWAA weitergeleitet.
AWS-Administratoren können jetzt den Zugriff eines Support-Teams nur auf Airflow beschränken, wodurch Amazon MWAA zur zentralen Anlaufstelle für die Job-Orchestrierung und das Job-Gesundheitsmanagement wird. Bisher mussten Benutzer den Ausführungsstatus des AWS Glue-Auftrags in den Airflow-DAG-Schritten überprüfen und die Auftragsausführungskennung abrufen. Anschließend mussten sie auf die AWS Glue-Konsole zugreifen, um den Auftragsausführungsverlauf zu finden, anhand der Kennung nach dem gewünschten Auftrag suchen und schließlich zur Fehlerbehebung zu den CloudWatch-Protokollen des Auftrags navigieren.
Erstellen Sie die DAG
Führen Sie die folgenden Schritte aus, um die DAG zu erstellen:
- Speichern Sie den vorangehenden DAG-Code in einer lokalen .py-Datei und ersetzen Sie dabei die angegebenen Platzhalter.
Die Werte für Ihre AWS-Konto-ID, den AWS Glue-Auftragsnamen, die AWS Glue-Datenbank mit CloudTrail-Tabelle und den CloudTrail-Tabellennamen sollten bereits bekannt sein. Sie können den Ausgabe-S3-Bucket, die Ausgabe-AWS-Glue-Datenbank und den Namen der Ausgabetabelle nach Bedarf anpassen. Stellen Sie jedoch sicher, dass die IAM-Rolle des AWS Glue-Jobs, die Sie zuvor verwendet haben, entsprechend konfiguriert ist.
- Navigieren Sie in der Amazon MWAA-Konsole zu Ihrer Umgebung, um zu sehen, wo der DAG-Code gespeichert ist.
Der DAGs-Ordner ist das Präfix im S3-Bucket, in dem Ihre DAG-Datei abgelegt werden soll.
- Laden Sie dort Ihre bearbeitete Datei hoch.

- Öffnen Sie die Amazon MWAA-Konsole, um zu bestätigen, dass die DAG in der Tabelle angezeigt wird.

Führen Sie den DAG . aus
Führen Sie die folgenden Schritte aus, um den DAG auszuführen:
- Wählen Sie aus folgenden Optionen:
- DAG auslösen – Dies führt dazu, dass die Daten von gestern als zu verarbeitende Daten verwendet werden
- DAG mit Konfiguration auslösen – Mit dieser Option können Sie ggf. für Backfills ein anderes Datum übergeben, das über abgerufen wird
dag_run.confim DAG-Code und dann als Parameter an den AWS Glue-Job übergeben

Der folgende Screenshot zeigt die zusätzlichen Konfigurationsoptionen, wenn Sie diese auswählen DAG mit Konfiguration auslösen.

- Überwachen Sie die DAG, während sie ausgeführt wird.
- Wenn die DAG abgeschlossen ist, öffnen Sie die Details der Ausführung.
Im rechten Bereich können Sie die Protokolle anzeigen oder auswählen Details zur Aufgabeninstanz für eine vollständige Ansicht.

- Zeigen Sie die AWS Glue-Auftragsausgabeprotokolle in Amazon MWAA an, ohne die AWS Glue-Konsole zu verwenden
GlueJobOperatorausführliche Flagge.

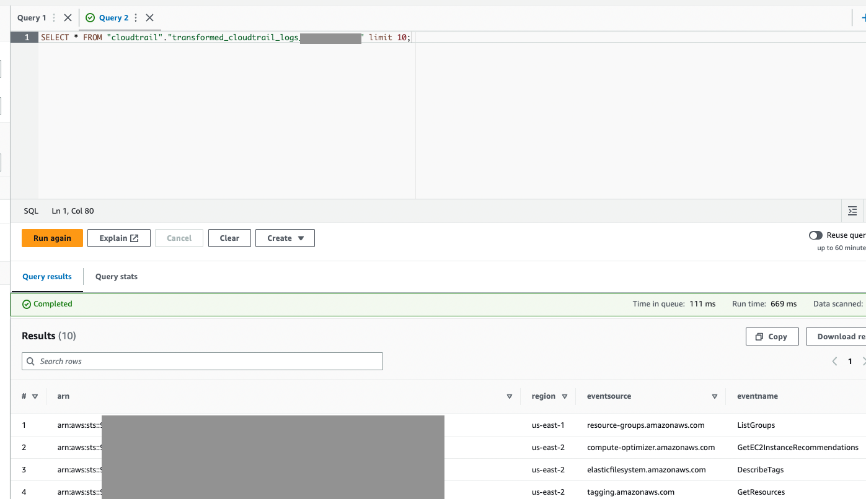
Der AWS Glue-Auftrag hat Ergebnisse in die von Ihnen angegebene Ausgabetabelle geschrieben.
- Fragen Sie diese Tabelle über Athena ab, um zu bestätigen, dass sie erfolgreich war.
Zusammenfassung
Amazon MWAA bietet jetzt einen zentralen Ort zur Verfolgung des AWS Glue-Auftragsstatus und ermöglicht Ihnen die Verwendung der Airflow-Konsole als zentrale Schnittstelle für die Auftragsorchestrierung und das Gesundheitsmanagement. In diesem Beitrag haben wir die Schritte zur Orchestrierung von AWS Glue-Jobs über Airflow mit besprochen GlueJobOperator. Mit den neuen Observability-Verbesserungen können Sie AWS Glue-Jobs in einem einheitlichen Erlebnis nahtlos beheben. Wir haben außerdem gezeigt, wie Sie Ihre Amazon MWAA-Umgebung auf eine kompatible Version aktualisieren, Abhängigkeiten aktualisieren und die IAM-Rollenrichtlinie entsprechend ändern.
Weitere Informationen zu allgemeinen Schritten zur Fehlerbehebung finden Sie unter Fehlerbehebung: Erstellen und Aktualisieren einer Amazon MWAA-Umgebung. Ausführliche Informationen zur Migration in eine Amazon MWAA-Umgebung finden Sie unter Upgrade von 1.10 auf 2. Weitere Informationen zu den Open-Source-Codeänderungen zur besseren Beobachtbarkeit von AWS Glue-Jobs im Airflow Amazon-Anbieterpaket finden Sie unter Weiterleiten von Protokollen von AWS Glue-Jobs.
Abschließend empfehlen wir einen Besuch im AWS Big Data-Blog Weiteres Material zu Analysen, ML und Datenverwaltung auf AWS.
Über die Autoren
 Rushabh Lokhande ist ein Daten- und ML-Ingenieur bei der AWS Professional Services Analytics Practice. Er unterstützt Kunden bei der Implementierung von Big Data-, maschinellen Lern- und Analyselösungen. Außerhalb der Arbeit verbringt er gerne Zeit mit der Familie, liest, läuft und spielt Golf.
Rushabh Lokhande ist ein Daten- und ML-Ingenieur bei der AWS Professional Services Analytics Practice. Er unterstützt Kunden bei der Implementierung von Big Data-, maschinellen Lern- und Analyselösungen. Außerhalb der Arbeit verbringt er gerne Zeit mit der Familie, liest, läuft und spielt Golf.
 Ryan Gomes ist ein Daten- und ML-Ingenieur bei der AWS Professional Services Analytics Practice. Es ist ihm eine Leidenschaft, Kunden dabei zu helfen, durch Analyse- und maschinelle Lernlösungen in der Cloud bessere Ergebnisse zu erzielen. Außerhalb der Arbeit treibt er gerne Fitness, kocht und verbringt viel Zeit mit Freunden und Familie.
Ryan Gomes ist ein Daten- und ML-Ingenieur bei der AWS Professional Services Analytics Practice. Es ist ihm eine Leidenschaft, Kunden dabei zu helfen, durch Analyse- und maschinelle Lernlösungen in der Cloud bessere Ergebnisse zu erzielen. Außerhalb der Arbeit treibt er gerne Fitness, kocht und verbringt viel Zeit mit Freunden und Familie.
 Vishwa Gupta ist Senior Data Architect bei der AWS Professional Services Analytics Practice. Er unterstützt Kunden bei der Implementierung von Big-Data- und Analyselösungen. Außerhalb der Arbeit verbringt er gerne Zeit mit der Familie, reist und probiert neue Gerichte.
Vishwa Gupta ist Senior Data Architect bei der AWS Professional Services Analytics Practice. Er unterstützt Kunden bei der Implementierung von Big-Data- und Analyselösungen. Außerhalb der Arbeit verbringt er gerne Zeit mit der Familie, reist und probiert neue Gerichte.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Die Zukunft prägen mit Adryenn Ashley. Hier zugreifen.
- Kaufen und verkaufen Sie Anteile an PRE-IPO-Unternehmen mit PREIPO®. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 1
- 10
- 100
- 12
- 8
- a
- Über Uns
- Zugang
- entsprechend
- Konto
- Erreichen
- über
- Action
- azyklisch
- Zusätzliche
- Vorteil
- Vorteilen
- Nach der
- Anhäufung
- Alle
- erlauben
- erlaubt
- bereits
- ebenfalls
- Amazon
- Amazon Web Services
- an
- Analytische
- Analytik
- analysieren
- und
- jedem
- Apache
- Bienen
- Anwendung
- Anwendungsentwicklung
- angemessen
- Architektur
- SIND
- Argument
- Argumente
- AS
- At
- Attribute
- Wirtschaftsprüfung
- verfügbar
- AWS
- AWS-Kleber
- Professionelle AWS-Services
- basierend
- BE
- wird
- war
- Bevor
- Sein
- Besser
- zwischen
- Big
- Big Data
- beide
- Bruch
- bauen
- aber
- by
- namens
- Aufrufe
- CAN
- Häuser
- Fälle
- Katalog
- Ursachen
- Übernehmen
- Änderungen
- aus der Ferne überprüfen
- Auswählen
- Cloud
- Code
- COM
- kombinieren
- Kommentar
- gemeinsam
- Unternehmen
- Kompatibilität
- kompatibel
- abschließen
- Komplex
- Komponente
- Komponenten
- Berechnen
- Konfiguration
- Schichtannahme
- Konsul (Console)
- konsolidieren
- Festigung
- Kochen
- Kernbereich
- deckt
- erstellen
- erstellt
- schafft
- Erstellen
- Strom
- Original
- Kunde
- Kunden
- TAG
- technische Daten
- Datenintegration
- Datenverarbeitung
- Datenstrategie
- Data Warehouse
- Datenbase
- Datenbanken
- Datensätze
- Datum
- Datum
- datetime
- Tage
- entschieden
- Standard
- geliefert
- Synergie
- Abhängig
- veraltet
- detailliert
- Details
- Entwicklung
- abweichen
- anders
- digital
- Digitale Medien
- Direkt
- diskutieren
- verteilt
- verteilte Systeme
- do
- die
- Dabei
- erledigt
- im
- e
- Früher
- Erleichtert
- bewirken
- eliminieren
- sonst
- ermöglichen
- freigegeben
- ermöglicht
- End-to-End
- Engagement
- Ingenieur
- Verbesserungen
- gewährleisten
- Enter
- Arbeitsumfeld
- Fehler
- Äther (ETH)
- Veranstaltungen
- Beispiel
- Außer
- Ausnahme
- existieren
- vorhandenen
- existiert
- ERFAHRUNGEN
- Erfahrungen
- Erkundet
- Ausdruck
- extern
- Extrakt
- Gescheitert
- falsch
- Familie
- Merkmal
- funktions
- Eigenschaften
- Reichen Sie das
- Mappen
- Filterung
- Endlich
- Finden Sie
- Fitness
- Folgende
- Nahrung,
- Aussichten für
- Format
- Freunde
- für
- voller
- sammeln
- erzeugen
- Glas
- Go
- Golf
- Governance
- Gruppe an
- Hadoop
- Haben
- he
- Gesundheit
- Unternehmen
- hilft
- Geschichte
- Bienenstock
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- IAM
- ID
- ideal
- Ideen
- Kennzeichnung
- if
- zeigt
- implementieren
- importieren
- in
- eingehende
- das
- Einschließlich
- Erhöhung
- hat
- angegeben
- Branchen
- Info
- Information
- Anfangs-
- innovativ
- Einblicke
- Installieren
- Instanz
- Anleitung
- integriert
- Integration
- Interesse
- intern
- in
- IT
- Job
- Jobs
- jpg
- JSON
- Wesentliche
- bekannt
- grosse
- später
- neueste
- LERNEN
- lernen
- Bibliothek
- LIMIT
- Liste
- Belastung
- aus einer regionalen
- örtlich
- Standorte
- Log
- protokolliert
- Protokollierung
- suchen
- Maschine
- Maschinelles Lernen
- gemacht
- halten
- um
- Making
- verwaltet
- Management
- flächendeckende Gesundheitsprogramme
- manuell
- Ihres Materials
- Kann..
- Medien
- Triff
- Nachricht
- Metrik
- Migration
- minimal
- ML
- geändert
- Modulen
- Überwachen
- Überwachung
- mehr
- sollen
- Name
- Namen
- Navigieren
- Menü
- notwendig,
- Need
- erforderlich
- Bedürfnisse
- Neu
- nichts
- jetzt an
- of
- bieten
- on
- EINEM
- Einsen
- einzige
- XNUMXh geöffnet
- Open-Source-
- Open-Source-Code
- Operator
- Betreiber
- optimal
- Option
- Optionen
- or
- orchestriert
- Orchesterbearbeitung
- Andere
- UNSERE
- Ergebnisse
- Möglichkeiten für das Ausgangssignal:
- aussen
- Paket
- Pandas
- Brot
- Parameter
- Partner
- passieren
- Bestanden
- leidenschaftlich
- Leistung
- Berechtigungen
- besteht fort
- Pipeline
- Ort
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Punkte
- Datenschutzrichtlinien
- Post
- möglicherweise
- Praxis
- Voraussetzungen
- früher
- vorher
- Prozessdefinierung
- anpassen
- Verarbeitung
- Produkte
- Professionell
- Profis
- Profil
- Projektion
- Versorger
- Anbieter
- bietet
- Python
- Qualität
- Abfragen
- erhöhen
- Angebot
- Lesen Sie mehr
- Lesebrillen
- echt
- Echtzeit
- kürzlich
- empfehlen
- Region
- Regulierungsbehörden
- Relais
- ersetzen
- ersetzt
- falls angefordert
- Voraussetzungen:
- Ressourcen
- Downloads
- beziehungsweise
- Antwort
- Die Ergebnisse
- behalten
- Recht
- Rollen
- REIHE
- Führen Sie
- Laufen
- s
- Speichern
- Szenarien
- Sdk
- nahtlos
- Suche
- Abschnitt
- Verbindung
- sehen
- Suchen
- Senior
- Serverlos
- Lösungen
- Einstellung
- Setup
- Schale
- sollte
- erklären
- Konzerte
- Einfacher
- vereinfachen
- da
- Single
- Schnappschuss
- Lösung
- Lösungen
- einige
- spezifisch
- angegeben
- Ausgabe
- Erklärung
- Status
- Schritt
- Shritte
- Immer noch
- Lagerung
- gelagert
- Strategie
- Strom
- Schnur
- erfolgreich
- so
- ausreichend
- Support
- Unterstützte
- Systeme und Techniken
- Tabelle
- Nehmen
- Einnahme
- Aufgabe
- Teams
- Technologies
- Vorlage
- dank
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- Dort.
- Diese
- vom Nutzer definierten
- basierte Online-to-Offline-Werbezuordnungen von anderen gab.
- fehlen uns die Worte.
- Durch
- Zeit
- zu
- verfolgen sind
- Transformieren
- Reise
- was immer dies auch sein sollte.
- versuchen
- Dienstag
- Turned
- XNUMX
- tippe
- ui
- einheitlich
- Einheit
- Aktualisierung
- Updates
- Aktualisierung
- mehr Stunden
- Upgrade
- Uploading
- Anwendungsbereich
- -
- Anwendungsfall
- benutzt
- Nutzer
- Verwendung von
- Wert
- Werte
- Version
- Anzeigen
- Ansichten
- Sichtbarkeit
- sichtbar
- ging
- wollen
- wurde
- we
- Netz
- Web-Services
- GUT
- Was
- wann
- ob
- welche
- WHO
- werden wir
- mit
- .
- ohne
- Arbeiten
- Workflows
- würde
- schreiben
- geschrieben
- U
- Ihr
- Zephyrnet